2023 was een druk jaar voor Amazon OpenSearch-service! Lees meer over de releases die OpenSearch Service heeft gelanceerd in de eerste helft van 2023.
In de tweede helft van 2023 voegde OpenSearch Service de ondersteuning toe van twee nieuwe OpenSearch versies: 2.9 en 2.11 Deze twee versies introduceren nieuwe functies in de zoekruimte, machine learning (ML) zoekruimte, migraties en de operationele kant van de service.
Met de release van zero-ETL-integratie met Amazon eenvoudige opslagservice (Amazon S3), kunt u uw gegevens in uw datameer analyseren met behulp van OpenSearch Service om dashboards te bouwen en de gegevens op te vragen zonder dat u uw gegevens van Amazon S3 hoeft te verplaatsen.
OpenSearch Service kondigde ook een nieuwe zero-ETL-integratie aan met Amazon DynamoDB via de DynamoDB-plug-in voor Amazon OpenSearch-opname. OpenSearch Ingestion zorgt voor het opstarten en streamt continu gegevens vanuit uw DynamoDB-bron.
OpenSearch Serverless heeft de algemene beschikbaarheid aangekondigd van de Vector-engine voor Amazon OpenSearch serverloos samen met andere functies om uw ervaring met tijdreeksverzamelingen te verbeteren, uw kosten voor ontwikkelomgevingen te beheren en uw bronnen snel te schalen om aan uw werklastvereisten te voldoen.
In dit bericht bespreken we de nieuwe releases in OpenSearch Service om uw bedrijf te voorzien van zoeken, observatie, beveiligingsanalyses en migraties.
Bouw kosteneffectieve oplossingen met OpenSearch Service
Met de zero-ETL-integratie voor Amazon S3 kunt u met OpenSearch Service nu ter plekke uw gegevens opvragen, waardoor u kosten op opslag bespaart. Het verplaatsen van gegevens is een dure operatie omdat u gegevens over verschillende gegevensopslagplaatsen moet repliceren. Dit vergroot uw datavoetafdruk en verhoogt de kosten. Het verplaatsen van gegevens voegt ook de overhead toe van het beheer van pijplijnen om de gegevens van de ene bron naar een nieuwe bestemming te migreren.
OpenSearch Service heeft ook nieuwe exemplaartypen toegevoegd voor dataknooppunten (Im4gn en OR1) om u te helpen uw infrastructuurkosten verder te optimaliseren. Met maximaal 30 TB niet-vluchtig geheugen (NVMe) solid state drives (SSD) biedt de Im4gn-instantie compacte opslag en betere prestaties. OR1-instances maken gebruik van segmentreplicatie en op afstand ondersteunde opslag om de doorvoer voor zware indexeringswerklasten aanzienlijk te verhogen.
Zero-ETL van DynamoDB naar OpenSearch-service
In november 2023 introduceerden DynamoDB en OpenSearch Ingestion een nul-ETL-integratie voor OpenSearch Service. OpenSearch Service-domeinen en OpenSearch Serverless-collecties bieden geavanceerde zoekmogelijkheden, zoals zoeken in volledige tekst en vector, op uw DynamoDB-gegevens. Met een paar klikken op de AWS-beheerconsole, kunt u uw gegevens nu naadloos laden en synchroniseren van DynamoDB naar OpenSearch Service, waardoor u geen aangepaste code hoeft te schrijven om de gegevens te extraheren, transformeren en laden.
Directe query (nul-ETL voor Amazon S3-gegevens, in preview)
OpenSearch Service heeft een nieuwe manier aangekondigd waarmee u operationele logboeken in Amazon S3 en op S3 gebaseerde datameren kunt opvragen zonder dat u hoeft te schakelen tussen tools om operationele gegevens te analyseren. Voorheen moest u gegevens van Amazon S3 naar OpenSearch Service kopiëren om te profiteren van de rijke analyse- en visualisatiefuncties van OpenSearch om uw gegevens te begrijpen, afwijkingen te identificeren en potentiële bedreigingen te detecteren.
Het voortdurend repliceren van gegevens tussen services kan echter duur zijn en vereist operationeel werk. Met de directe queryfunctie van de OpenSearch Service heeft u toegang tot operationele loggegevens die zijn opgeslagen in Amazon S3, zonder dat u de gegevens zelf hoeft te verplaatsen. Nu kunt u complexe query's en visualisaties op uw gegevens uitvoeren zonder enige gegevensverplaatsing.
Ondersteuning van Im4gn met OpenSearch-service
Im4gn-instances zijn geoptimaliseerd voor workloads die grote datasets beheren en een hoge opslagdichtheid per vCPU nodig hebben. Im4gn-instanties zijn verkrijgbaar in de maten groot tot en met 16xgroot, met maximaal 30 TB aan NVMe SSD-schijfgrootte. Im4gn-instanties zijn gebouwd op AWS Nitro-systeem SSD's, die schijftoegang met hoge doorvoer en lage latentie bieden voor de beste prestaties. OpenSearch Service Im4gn-instanties ondersteunen alle OpenSearch-versies en Elasticsearch-versies 7.9 en hoger. Voor meer details, zie Ondersteunde exemplaartypen in Amazon OpenSearch Service.
Maak kennis met OR1, een OpenSearch Optimized Instance-familie voor het indexeren van zware werklasten
In november 2023 werd de OpenSearch-service gelanceerd OR1, de OpenSearch Optimized Instance-familie, dat tot 30% prijs-prestatieverbetering oplevert ten opzichte van bestaande exemplaren in interne benchmarks en Amazon S3 gebruikt om 11 9s duurzaamheid te bieden. Een domein met OR1-instanties gebruikt Amazon elastische blokwinkel (Amazon EBS) volumes voor primaire opslag, waarbij de gegevens synchroon worden gekopieerd naar Amazon S3 zodra deze binnenkomen. OR1-instanties gebruiken die van OpenSearch functie voor segmentreplicatie om replica-shards in staat te stellen gegevens rechtstreeks uit Amazon S3 te lezen, waardoor de resourcekosten van indexering in zowel primaire als replica-shards worden vermeden. De OR1-instantiefamilie ondersteunt ook automatisch gegevensherstel in geval van een storing. Voor meer informatie over opties voor het OR1-instantietype raadpleegt u Instantietypen van de huidige generatie in de OpenSearch-service.
Ondersteun uw bedrijf met beveiligingsanalysefuncties
De Security Analytics-plug-in in OpenSearch Service ondersteunt out-of-the-box voorverpakte logtypen en biedt beveiligingsdetectieregels (SIGMA-regels) om potentiële beveiligingsincidenten te detecteren.
In OpenSearch 2.9 heeft de Security Analytics-plug-in ondersteuning toegevoegd voor klantlogboektypen en native ondersteuning voor Open Cybersecurity Schema Framework (OCSF) data formaat. Met deze nieuwe ondersteuning kunt u detectoren bouwen waarin OCSF-gegevens zijn opgeslagen Amazon Beveiligingsmeer om beveiligingsbevindingen te analyseren en elk potentieel incident te beperken. De Security Analytics-plug-in heeft ook de mogelijkheid toegevoegd om uw eigen aangepaste logtypen te maken en aangepaste detectieregels te maken.
Bouw ML-aangedreven zoekoplossingen
In 2023 investeerde OpenSearch Service in het elimineren van het zware werk dat nodig is om zoekapplicaties van de volgende generatie te bouwen. Met functies zoals zoekpijplijnen, zoekprocessors en AI/ML-connectoren maakte OpenSearch Service een snelle ontwikkeling mogelijk van zoekapplicaties die worden aangedreven door neuraal zoeken, hybride zoeken en gepersonaliseerde resultaten. Bovendien hebben verbeteringen aan de kNN-plug-in de opslag en het ophalen van vectorgegevens verbeterd. Nieuw gelanceerde optionele plug-ins voor OpenSearch Service maken naadloze integratie mogelijk met extra taalanalysatoren en Amazon personaliseren.
Zoek pijpleidingen
Zoek pijpleidingen nieuwe manieren bieden om zoekopdrachten te verbeteren en zoekresultaten te verbeteren. U definieert een zoekpijplijn en verzendt vervolgens uw zoekopdrachten ernaartoe. Wanneer u de zoekpijplijn definieert, geeft u deze op processors die uw zoekopdrachten transformeren en aanvullen, en uw resultaten opnieuw rangschikken. De vooraf gebouwde queryprocessors omvatten datumconversie, aggregatie, tekenreeksmanipulatie en conversie van gegevenstypen. De resultatenprocessor in de zoekpijplijn onderschept en past de resultaten direct aan voordat deze naar de volgende fase worden weergegeven. Zowel de aanvraag- als de responsverwerking voor de pijplijn worden uitgevoerd op het coördinatorknooppunt, dus er vindt geen verwerking op Shard-niveau plaats.
Optionele plug-ins
Met de OpenSearch-service kunt u vooraf geïnstalleerde bestanden koppelen optionele OpenSearch-plug-ins te gebruiken met uw domein. Een optioneel plug-inpakket is compatibel met een specifieke OpenSearch-versie en kan alleen worden gekoppeld aan domeinen met die versie. Beschikbare plug-ins worden vermeld op de Pakketten pagina op de OpenSearch Service-console. De optionele plug-in omvat de Amazon Personalize-plug-in, die OpenSearch Service integreert met Amazon Personalize, en nieuwe taalanalysatoren zoals Nori, Sudachi, STConvert en Pinyin.
Ondersteuning voor nieuwe taalanalysatoren
OpenSearch Service heeft ondersteuning toegevoegd voor vier nieuwe plug-ins voor taalanalyse: Nori (Koreaans), Sudachi (Japans), Pinyin (Chinees) en STConvert Analysis (Chinees). Deze zijn in alle AWS-regio's beschikbaar als optionele plug-ins die u kunt koppelen aan domeinen waarop elke OpenSearch-versie draait. U kunt gebruik maken van de Pakketten pagina op de OpenSearch Service-console om deze plug-ins aan uw domein te koppelen, of gebruik de Associate Package API.
Neurale zoekfunctie
Neurale zoektocht is algemeen beschikbaar met OpenSearch Service versie 2.9 en hoger. Met neuraal zoeken kunt u integreren met ML-modellen die op afstand worden gehost met behulp van het modelservingframework. Wanneer u tijdens het zoeken een neurale zoekopdracht gebruikt, converteert neurale zoekopdrachten de zoektekst naar vectorinsluitingen, gebruikt vectorzoekopdrachten om de zoekopdracht en de documentinsluiting te vergelijken, en retourneert de resultaten die er het dichtst bij liggen. Tijdens opname transformeert neurale zoekactie documenttekst in vectorinbedding en indexeert zowel de tekst als de vectorinbedding ervan in een vectorindex.
Integratie met Amazon Personaliseren
OpenSearch Service introduceerde een optionele plug-in om te integreren met Amazon Personalize in OpenSearch-versies 2.9 of hoger. Met de OpenSearch Service-plug-in voor Amazon Personalize Search Ranking kunt u de betrokkenheid en conversie van uw website en applicaties verbeteren door te profiteren van de diepgaande leermogelijkheden die worden aangeboden door Amazon Personalize. Als optionele plug-in kan de pakket is compatibel met OpenSearch versie 2.9 of hoger, en kan alleen worden gekoppeld aan domeinen met die versie.
Efficiënt filteren van zoekopdrachten met k-NN FAISS van OpenSearch
OpenSearch Service introduceerde efficiënte zoekopdrachtfiltering met OpenSearch's k-NN FAISS in versie 2.9 en hoger. OpenSearch's efficiënte vectorqueryfilters mogelijkheid evalueert op intelligente wijze optimale filterstrategieën (voorfilteren met geschatte dichtstbijzijnde buur (ANN) of filteren met exacte k-dichtstbijzijnde buur (k-NN)) om de beste strategie te bepalen voor het leveren van nauwkeurige vectorzoekopdrachten met lage latentie. In eerdere OpenSearch-versies maakten vectorquery's op de FAISS-engine gebruik van post-filteringtechnieken, waardoor gefilterde query's op schaal mogelijk waren, maar mogelijk minder dan het gevraagde 'k'-aantal resultaten opleverden. Efficiënte vectorqueryfilters leveren lage latentie en nauwkeurige resultaten, waardoor u hybride zoeken kunt toepassen in vector- en lexicale technieken.
Byte-gekwantiseerde vectoren in OpenSearch Service
Met de nieuwe byte-gekwantiseerde vector geïntroduceerd met 2.9, kunt u de geheugenvereisten met een factor 4 verminderen en de zoeklatentie aanzienlijk verminderen, met minimaal kwaliteitsverlies (recall). Met deze functie worden de gebruikelijke 32-bits floats die voor vectoren worden gebruikt, gekwantiseerd of geconverteerd naar 8-bits gehele getallen met teken. Voor veel toepassingen kunnen bestaande floatvectorgegevens worden gekwantiseerd met weinig kwaliteitsverlies. Als u benchmarks vergelijkt, zult u zien dat het gebruik van bytevectoren in plaats van 32-bits floats resulteert in een aanzienlijke vermindering van het opslag- en geheugengebruik, terwijl ook de indexeringsdoorvoer wordt verbeterd en de latentie van query's wordt verminderd. Een interne benchmark- toonde aan dat het opslaggebruik met maximaal 78% was verminderd en het RAM-gebruik met maximaal 59% (voor de dataset met 200 hoeken). Recall-waarden voor hoekige datasets waren lager dan die van Euclidische datasets.
AI/ML-connectoren
OpenSearch 2.9 en hoger ondersteunt integraties met ML-modellen gehost op AWS-services of platforms van derden. Hierdoor kunnen systeembeheerders en datawetenschappers ML-workloads uitvoeren buiten hun OpenSearch Service-domein. De ML-connectors worden geleverd met een ondersteunde set ML-blauwdrukken: sjablonen die de set parameters definiëren die u moet opgeven wanneer u API-aanvragen naar een specifieke connector verzendt. OpenSearch Service biedt connectoren voor verschillende platforms, zoals Amazon SalieMaker, Amazonebodem, OpenAI ChatGPT en Samenhangen.
OpenSearch Service-console-integraties
OpenSearch 2.9 en later hebben een nieuwe integratiefunctie op de console toegevoegd. Integraties biedt u een AWS CloudFormatie sjabloon om uw semantisch zoeken use case door verbinding te maken met uw ML-modellen die worden gehost op SageMaker of Amazon Bedrock. De CloudFormation-sjabloon genereert het modeleindpunt en registreert de model-ID bij het OpenSearch Service-domein dat u opgeeft als invoer voor de sjabloon.
Hybride zoeken en bereiknormalisatie
De normalisatie processor en hybride vraag bouwt voort op de twee functies die eerder in 2023 zijn uitgebracht:neurale zoektocht en pijpleidingen zoeken. Omdat lexicale en semantische zoekopdrachten relevantiescores op verschillende schalen opleveren, was het verfijnen van hybride zoekopdrachten lastig.
OpenSearch Service 2.11 ondersteunt nu een combinatie- en normalisatieprocessor voor hybride zoeken. U kunt nu hybride zoekopdrachten uitvoeren, waarbij u lexicale en op natuurlijke taal gebaseerde k-NN-vectorzoekopdrachten combineert. Met de OpenSearch Service kunt u ook uw hybride zoekresultaten afstemmen op maximale relevantie met behulp van meerdere scorecombinaties en normalisatietechnieken.
Multimodaal zoeken met Amazon Bedrock
OpenSearch Service 2.11 lanceert de ondersteuning van multimodaal zoeken waarmee u tekst- en afbeeldingsgegevens kunt doorzoeken met behulp van multimodale inbeddingsmodellen. Om vectorinsluitingen te genereren, moet u een ingest-pijplijn maken die een text_image_embedding-processor, waarmee de binaire tekst- of afbeeldingsbestanden in een documentveld worden geconverteerd naar vectorinsluitingen. U kunt de neurale queryclausule gebruiken in de k-NN-plug-in-API or Vraag DSL aan zoekopdrachten, om een combinatie van tekst- en afbeeldingenzoekopdrachten uit te voeren. U kunt de nieuwe OpenSearch Service-integratiefuncties gebruiken om snel aan de slag te gaan met multimodaal zoeken.
Neuraal schaars ophalen
Neuraal sparse zoeken, een nieuwe efficiënte methode voor semantisch ophalen, is beschikbaar in OpenSearch Service 2.11. Neuraal spaarzaam zoeken werkt in twee modi: bi-encoder en alleen document. Met de bi-encodermodus worden zowel documenten als zoekopdrachten via diepe encoders doorgegeven. In de alleen-documentmodus worden alleen documenten door diepe encoders gevoerd, terwijl zoekopdrachten worden getokeniseerd. Een sparse-encoder voor alleen documenten genereert een index die 10.4% van de grootte van een compacte coderingsindex bedraagt. Voor een bi-encoder is de indexgrootte 7.2% van de grootte van een dichte coderingsindex. Neuraal sparse zoeken wordt mogelijk gemaakt door sparse coderingsmodellen die schaarse vectorinbedding creëren: een set van <token: weight> paren die de tekstinvoer en het bijbehorende gewicht in de verspreide vector vertegenwoordigen. Voor meer informatie over de vooraf getrainde modellen voor sparse neurale zoekopdrachten raadpleegt u Schaarse coderingsmodellen.
Neuraal spaarzaam zoeken verlaagt de kosten, verbetert de zoekrelevantie en heeft een lagere latentie. U kunt de nieuwe OpenSearch Service-integratiefuncties gebruiken om snel aan de slag te gaan met neuraal sparse zoeken.
OpenSearch-opname-updates
OpenSearch-opname is een volledig beheerde en automatisch geschaalde opnamepijplijn die uw gegevens levert aan OpenSearch Service-domeinen en OpenSearch Serverless-collecties. Sinds de release in 2023 blijft OpenSearch Ingestion nieuwe functies toevoegen om het eenvoudig te maken uw gegevens te transformeren en te verplaatsen van ondersteunde bronnen naar downstream-bestemmingen zoals OpenSearch Service, OpenSearch Serverless en Amazon S3.
Nieuwe migratiefuncties in OpenSearch Ingestion
In november 2023 kondigde OpenSearch Ingestion de release aan van nieuwe functies ter ondersteuning van gegevensmigratie van zelfbeheerde Elasticsearch versie 7.x-domeinen naar de nieuwste versies van OpenSearch Service.
OpenSearch Ingestion ondersteunt ook de migratie van gegevens van door OpenSearch Service beheerde domeinen met OpenSearch versie 2.x naar OpenSearch Serverloze collecties.
Ontdek hoe u OpenSearch Ingestion kunt gebruiken migreer uw gegevens naar de OpenSearch Service.

Verbeter de duurzaamheid van gegevens met OpenSearch Ingestion
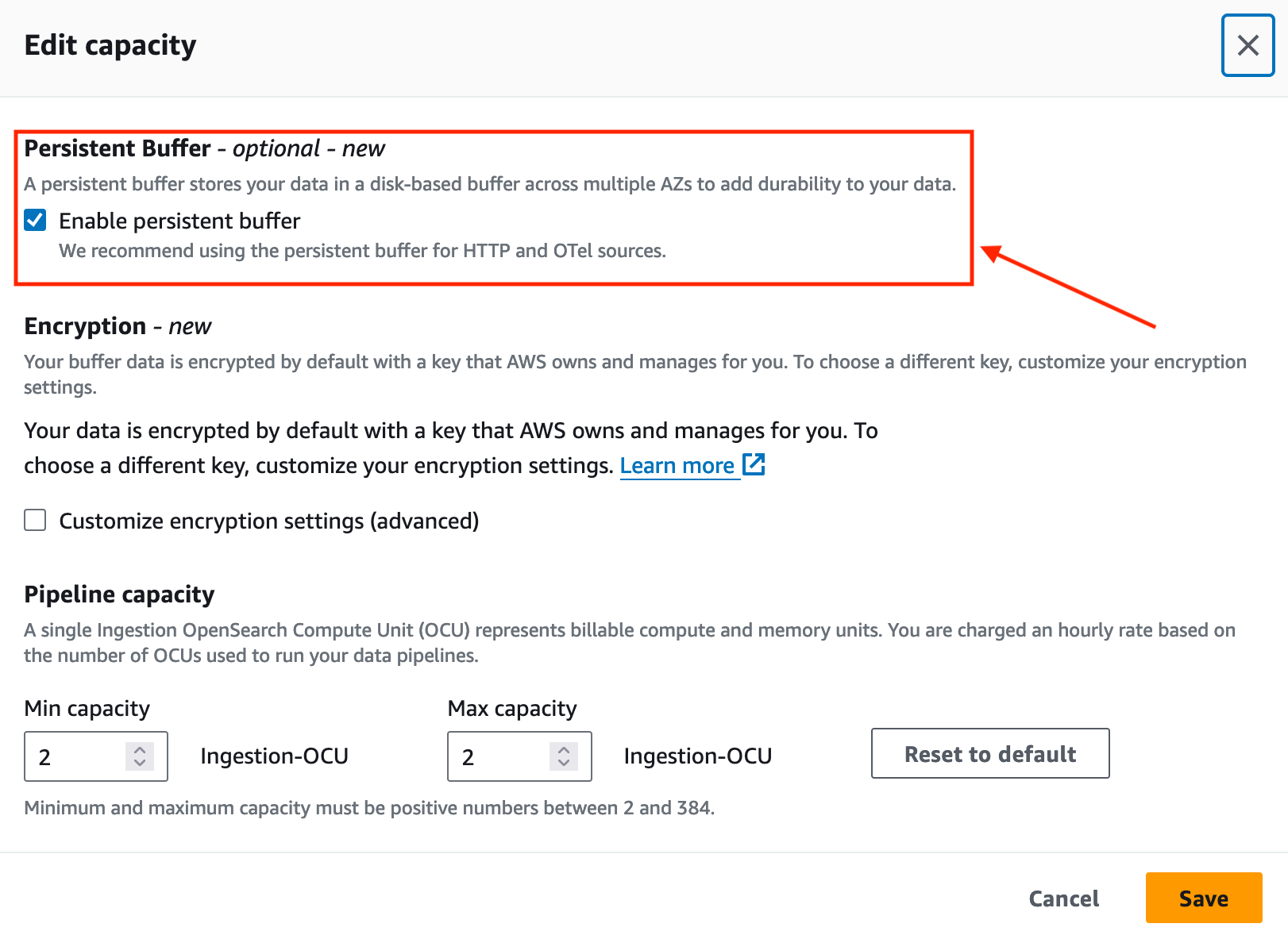
In november 2023 introduceerde OpenSearch Ingestion permanente buffering voor push-gebaseerde bronnen zoals HTTP-bronnen (HTTP, Fluentd, FluentBit) en OpenTelemetry-verzamelaars.
Standaard gebruikt OpenSearch Ingestion buffering in het geheugen. Met permanente buffering slaat OpenSearch Ingestion uw gegevens op in een op schijven gebaseerde opslag die veerkrachtiger is. Als u bestaande opnamepijplijnen heeft, kunt u permanente buffering voor deze pijpleidingen inschakelen, zoals weergegeven in de volgende schermafbeelding.
Ondersteuning van nieuwe plug-ins
Begin 2023 heeft OpenSearch Ingestion ondersteuning toegevoegd voor Amazon Managed Streaming voor Apache Kafka (Amazone MSK). OpenSearch Ingestion maakt gebruik van de Kafka-plug-in om gegevens van Amazon MSK naar door OpenSearch Service beheerde domeinen of OpenSearch Serverless-collecties te streamen. Voor meer informatie over het instellen van Amazon MSK als gegevensbron, zie Een OpenSearch Ingestion-pijplijn gebruiken met Amazon Managed Streaming voor Apache Kafka.
OpenSearch Serverloze updates
OpenSearch Serverless bleef uw serverloze ervaring met OpenSearch verbeteren door de ondersteuning van een nieuwe verzameling type vectorzoekopdrachten te introduceren om insluitingen op te slaan en overeenkomstenzoekopdrachten uit te voeren. OpenSearch Serverless ondersteunt nu het schalen van Shard-replica's om pieken in de doorvoer van query's op te vangen. En als u een tijdreeksverzameling gebruikt, kunt u nu uw aangepaste gegevensbewaarbeleid instellen dat aansluit bij uw gegevensbewaarvereisten.
Vector-engine voor OpenSearch serverloos
In november 2023 lanceerden we de vector-engine voor Amazon OpenSearch Serverless. De vectorengine maakt het eenvoudig om moderne ML-augmented zoekervaringen en generatieve kunstmatige intelligentie (generatieve AI)-applicaties te bouwen zonder de onderliggende vectordatabase-infrastructuur te hoeven beheren. Het stelt u ook in staat om hybride zoekopdrachten uit te voeren, waarbij vectorzoekopdrachten en zoekopdrachten in volledige tekst in dezelfde zoekopdracht worden gecombineerd, waardoor het niet meer nodig is om afzonderlijke gegevensarchieven of een complexe applicatiestapel te beheren en onderhouden.
OpenSearch Serverloze, goedkopere ontwikkel- en testomgevingen
OpenSearch Serverless ondersteunt nu ontwikkelings- en testwerklasten doordat u het uitvoeren van een replica kunt vermijden. Door replica's te verwijderen, is het niet meer nodig om redundante OCU's in een andere beschikbaarheidszone te hebben, uitsluitend voor beschikbaarheidsdoeleinden. Als u OpenSearch Serverless gebruikt voor ontwikkelen en testen, waarbij beschikbaarheid geen probleem is, kunt u uw minimale OCU's verlagen van 4 naar 2.
OpenSearch Serverless ondersteunt geautomatiseerde, op tijd gebaseerde gegevensverwijdering met behulp van gegevenslevenscyclusbeleid
In december 2023 kondigde OpenSearch Serverless ondersteuning aan voor het beheren van gegevensretentie van tijdreeksverzamelingen en indexen. Met de nieuwe automatische tijdgebaseerde gegevensverwijderingsfunctie kunt u opgeven hoe lang u gegevens wilt bewaren. OpenSearch Serverless beheert automatisch de levenscyclus van de gegevens op basis van deze configuratie. Raadpleeg voor meer informatie Amazon OpenSearch Serverless ondersteunt nu geautomatiseerde, op tijd gebaseerde gegevensverwijdering.
OpenSearch Serverless heeft ondersteuning aangekondigd voor het opschalen van replica's op shard-niveau
Bij de lancering ondersteunde OpenSearch Serverless automatisch het vergroten van de capaciteit als reactie op de groeiende gegevensgrootte. Met de nieuwe Shard-replica-schaling Met deze functie detecteert OpenSearch Serverless automatisch shards onder dwang als gevolg van plotselinge pieken in de querysnelheid en worden dynamisch nieuwe shardreplica's toegevoegd om de verhoogde querydoorvoer aan te kunnen, terwijl snelle responstijden behouden blijven. Deze aanpak blijkt kostenefficiënter te zijn dan simpelweg het toevoegen van nieuwe indexreplica's.
AWS-gebruikersmeldingen om uw OCU-gebruik te controleren
Met deze lancering kunt u het systeem configureren om meldingen te verzenden wanneer het OCU-gebruik de maximale geconfigureerde limieten voor zoeken of verwerken nadert of heeft bereikt. Met de nieuwe AWS User Notification-integratie kunt u het systeem configureren om meldingen te verzenden wanneer de capaciteitsdrempel wordt overschreden. Dankzij de functie Gebruikersmelding is het niet meer nodig om de service voortdurend te controleren. Voor meer informatie, zie Monitoring van Amazon OpenSearch Serverless met behulp van AWS-gebruikersmeldingen.
Verbeter uw ervaring met OpenSearch Dashboards
OpenSearch 2.9 in OpenSearch Service introduceerde nieuwe functies om het eenvoudig te maken om uw gegevens snel te analyseren in OpenSearch Dashboards. Deze nieuwe functies omvatten de nieuwe kant-en-klare, vooraf geconfigureerde dashboards met OpenSearch-integraties en de mogelijkheid om waarschuwingen en afwijkingsdetectie te creëren op basis van een bestaande visualisatie in uw dashboards.
OpenSearch Dashboard-integraties
OpenSearch 2.9 heeft ondersteuning toegevoegd voor OpenSearch-integraties in OpenSearch Dashboards. OpenSearch-integraties omvatten vooraf geconfigureerde dashboards, zodat u snel kunt beginnen met het analyseren van uw gegevens afkomstig uit populaire bronnen zoals AWS CloudFront, AWS WAF, AWS CloudTrail en Amazon virtuele privécloud (Amazon VPC) stroomlogboeken.
Waarschuwingen en afwijkingen in OpenSearch Dashboards
In OpenSearch Service 2.9 kunt u rechtstreeks vanuit uw visualisatie van lijndiagrammen in OpenSearch-dashboards. U kunt ook de bestaande monitoren of detectoren die eerder in OpenSearch zijn gemaakt, koppelen aan de dashboardvisualisatie.
Deze nieuwe functie helpt het wisselen van context tussen dashboards en zowel de Alerting- als de Anomaly Detection-plug-ins te verminderen. Raadpleeg het volgende dashboard om een waarschuwingsmonitor toe te voegen om dalingen in het gemiddelde gegevensvolume in uw services te detecteren.

OpenSearch breidt de ondersteuning voor georuimtelijke aggregaties uit
Met OpenSearch versie 2.9 heeft OpenSearch Service de ondersteuning van drie typen toegevoegd geovorm gegevensaggregatie via API: geo_bounds, geo_hash en geo_tegel.
Het geoshape-veldtype biedt de mogelijkheid om locatiegegevens in verschillende geografische formaten te indexeren, zoals een punt, een polygoon of een lijnstring. Met de nieuwe aggregatietypen hebt u meer flexibiliteit bij het aggregeren van documenten uit een index met behulp van georuimtelijke aggregaties met metrische gegevens en meerdere buckets.
Operationele updates van de OpenSearch-service
Met de OpenSearch Service is het niet meer nodig om een blauw/groene implementatie uit te voeren bij het wijzigen van de door het domein beheerde knooppunten. Bovendien heeft de service de Auto-Tune-gebeurtenissen verbeterd met de ondersteuning van nieuwe Auto-Tune-statistieken om de wijzigingen binnen uw OpenSearch Service-domein bij te houden.
Met de OpenSearch Service kunt u nu domeinbeheerknooppunten bijwerken zonder blauw/groene implementatie
Vanaf het begin van de tweede helft van 2 kunt u met de OpenSearch Service het exemplaartype of het aantal exemplaren van speciale clustermanagerknooppunten wijzigen zonder dat een blauw/groene implementatie nodig is. Deze verbetering maakt snellere updates mogelijk met minimale verstoring van uw domeinactiviteiten, terwijl gegevensverplaatsing wordt vermeden.
Voorheen betekende het bijwerken van uw specifieke clustermanagerknooppunten op de OpenSearch Service het gebruik van een blauw/groene implementatie om de wijziging door te voeren. Hoewel blauw/groene implementaties bedoeld zijn om verstoring van uw domeinen te voorkomen, wordt het aanbevolen om deze tijdens perioden met weinig verkeer uit te voeren, omdat de implementatie gebruikmaakt van extra bronnen op het domein. Nu kunt u de exemplaartypen of het aantal exemplaren van clustermanager bijwerken zonder dat een blauw/groene implementatie nodig is, zodat deze updates sneller kunnen worden voltooid en mogelijke verstoring van uw domeinactiviteiten wordt voorkomen. In gevallen waarin u zowel het exemplaartype als het aantal van de domeinmanager wijzigt, zal OpenSearch Service nog steeds een blauw/groene implementatie gebruiken om de wijziging door te voeren. Met de dry-run optie kunt u controleren of uw wijziging een blauw/groene implementatie vereist.
Verbeterde Auto-Tune-ervaring
In september 2023 heeft OpenSearch Service nieuwe Auto-Tune-statistieken toegevoegd en verbeterde Auto-Tune-gebeurtenissen die u beter inzicht geven in de domeinprestatie-optimalisaties die door Auto-Tune zijn doorgevoerd.
Auto-Tune is een adaptief systeem voor resourcebeheer dat automatisch OpenSearch Service-domeinbronnen bijwerkt om de efficiëntie en prestaties te verbeteren. Auto-Tune optimaliseert bijvoorbeeld geheugengerelateerde configuraties, zoals wachtrijgroottes, cachegroottes en Java Virtual Machine (JVM)-instellingen op uw knooppunten.
Met deze lancering kunt u nu de geschiedenis van de wijzigingen controleren en deze in realtime volgen vanaf de Amazon Cloud Watch console.
Bovendien publiceert OpenSearch Service nu details van de wijzigingen in Amazon EventBridge wanneer Auto-Tune-instellingen worden aanbevolen of toegepast op een OpenSearch Service-domein. Deze Auto-Tune-gebeurtenissen zijn ook zichtbaar op de meldingen pagina op de OpenSearch Service-console.
Versnel uw migratie naar OpenSearch Service met de nieuwe Migration Assistant-oplossing
In november 2023 lanceerde het OpenSearch-team een nieuwe open-sourceoplossing:Migratieassistent voor Amazon OpenSearch Service. De oplossing ondersteunt datamigratie van zelfbeheerde Elasticsearch- en OpenSearch-domeinen naar OpenSearch Service, waarbij Elasticsearch 7.x (<=7.10), OpenSearch 1.x en OpenSearch 2.x als migratiebronnen worden ondersteund. De oplossing vergemakkelijkt de migratie van de bestaande en live data tussen bron en bestemming.
Conclusie
In dit bericht hebben we de nieuwe releases in OpenSearch Service besproken om u te helpen uw bedrijf te innoveren met zoeken, observatie, beveiligingsanalyses en migraties. We hebben u informatie gegeven over wanneer u elke nieuwe functie in OpenSearch Service, OpenSearch Ingestion en OpenSearch Serverless moet gebruiken.
Lees meer over OpenSearch Dashboards en OpenSearch-plug-ins en de nieuwe, opwindende OpenSearch-assistent die u gebruikt OpenSearch-speeltuin.
Bekijk de functies die in dit bericht worden beschreven en we stellen het op prijs dat u ons uw waardevolle feedback geeft.
Over de auteurs
 Jon Handler is een Senior Principal Solutions Architect bij Amazon Web Services, gevestigd in Palo Alto, CA. Jon werkt nauw samen met OpenSearch en Amazon OpenSearch Service en biedt hulp en begeleiding aan een breed scala aan klanten die zoek- en loganalyseworkloads hebben die ze naar de AWS Cloud willen verplaatsen. Voordat Jon bij AWS kwam, omvatte Jon's carrière als softwareontwikkelaar vier jaar lang het coderen van een grootschalige e-commerce zoekmachine. Jon heeft een Bachelor of the Arts behaald aan de Universiteit van Pennsylvania, en een Master of Science en een PhD in Computerwetenschappen en Kunstmatige Intelligentie aan de Northwestern University.
Jon Handler is een Senior Principal Solutions Architect bij Amazon Web Services, gevestigd in Palo Alto, CA. Jon werkt nauw samen met OpenSearch en Amazon OpenSearch Service en biedt hulp en begeleiding aan een breed scala aan klanten die zoek- en loganalyseworkloads hebben die ze naar de AWS Cloud willen verplaatsen. Voordat Jon bij AWS kwam, omvatte Jon's carrière als softwareontwikkelaar vier jaar lang het coderen van een grootschalige e-commerce zoekmachine. Jon heeft een Bachelor of the Arts behaald aan de Universiteit van Pennsylvania, en een Master of Science en een PhD in Computerwetenschappen en Kunstmatige Intelligentie aan de Northwestern University.
 Hajer Bouafif is een Analytics Specialist Solutions Architect bij Amazon Web Services. Ze richt zich op Amazon OpenSearch Service en helpt klanten bij het ontwerpen en bouwen van goed ontworpen analytics-workloads in diverse sectoren. Hajer brengt graag tijd buitenshuis door en ontdekt graag nieuwe culturen.
Hajer Bouafif is een Analytics Specialist Solutions Architect bij Amazon Web Services. Ze richt zich op Amazon OpenSearch Service en helpt klanten bij het ontwerpen en bouwen van goed ontworpen analytics-workloads in diverse sectoren. Hajer brengt graag tijd buitenshuis door en ontdekt graag nieuwe culturen.
 Aruna Govindaraju is een Amazon OpenSearch Specialist Solutions Architect en heeft met veel commerciële en open source zoekmachines gewerkt. Ze heeft een passie voor zoeken, relevantie en gebruikerservaring. Haar expertise in het correleren van signalen van eindgebruikers met het gedrag van zoekmachines heeft veel klanten geholpen hun zoekervaring te verbeteren.
Aruna Govindaraju is een Amazon OpenSearch Specialist Solutions Architect en heeft met veel commerciële en open source zoekmachines gewerkt. Ze heeft een passie voor zoeken, relevantie en gebruikerservaring. Haar expertise in het correleren van signalen van eindgebruikers met het gedrag van zoekmachines heeft veel klanten geholpen hun zoekervaring te verbeteren.
 Prashant Agrawal is een Sr. Search Specialist Solutions Architect met Amazon OpenSearch Service. Hij werkt nauw samen met klanten om hen te helpen hun workloads naar de cloud te migreren en helpt bestaande klanten hun clusters te verfijnen om betere prestaties te bereiken en kosten te besparen. Voordat hij bij AWS kwam, hielp hij verschillende klanten bij het gebruik van OpenSearch en Elasticsearch voor hun gebruiksscenario's voor zoek- en loganalyse. Als hij niet aan het werk is, kun je hem zien reizen en nieuwe plaatsen ontdekken. Kortom, hij doet graag Eten → Reizen → Herhalen.
Prashant Agrawal is een Sr. Search Specialist Solutions Architect met Amazon OpenSearch Service. Hij werkt nauw samen met klanten om hen te helpen hun workloads naar de cloud te migreren en helpt bestaande klanten hun clusters te verfijnen om betere prestaties te bereiken en kosten te besparen. Voordat hij bij AWS kwam, hielp hij verschillende klanten bij het gebruik van OpenSearch en Elasticsearch voor hun gebruiksscenario's voor zoek- en loganalyse. Als hij niet aan het werk is, kun je hem zien reizen en nieuwe plaatsen ontdekken. Kortom, hij doet graag Eten → Reizen → Herhalen.
 Moslim Abu Taha is een Sr. OpenSearch Specialist Solutions Architect die zich toelegt op het begeleiden van klanten bij naadloze migraties van zoekwerklasten, het afstemmen van clusters voor topprestaties en het garanderen van kosteneffectiviteit. Met een achtergrond als technisch accountmanager (TAM) brengt Muslim een schat aan ervaring met zich mee in het assisteren van zakelijke klanten bij de adoptie van de cloud en het optimaliseren van hun verschillende werklasten. Moslim brengt graag tijd door met zijn gezin, reist en ontdekt graag nieuwe plaatsen.
Moslim Abu Taha is een Sr. OpenSearch Specialist Solutions Architect die zich toelegt op het begeleiden van klanten bij naadloze migraties van zoekwerklasten, het afstemmen van clusters voor topprestaties en het garanderen van kosteneffectiviteit. Met een achtergrond als technisch accountmanager (TAM) brengt Muslim een schat aan ervaring met zich mee in het assisteren van zakelijke klanten bij de adoptie van de cloud en het optimaliseren van hun verschillende werklasten. Moslim brengt graag tijd door met zijn gezin, reist en ontdekt graag nieuwe plaatsen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/amazon-opensearch-h2-2023-in-review/

