Afbeelding door auteur
Csvkit is een koning van tabelgegevens. Het heeft een verzameling tools die kunnen worden gebruikt om CSV-bestanden te converteren, de gegevens te manipuleren en gegevensanalyse uit te voeren.
U kunt installeren csvkit pip gebruiken.
$ pip install csvkitVoorbeeld 1
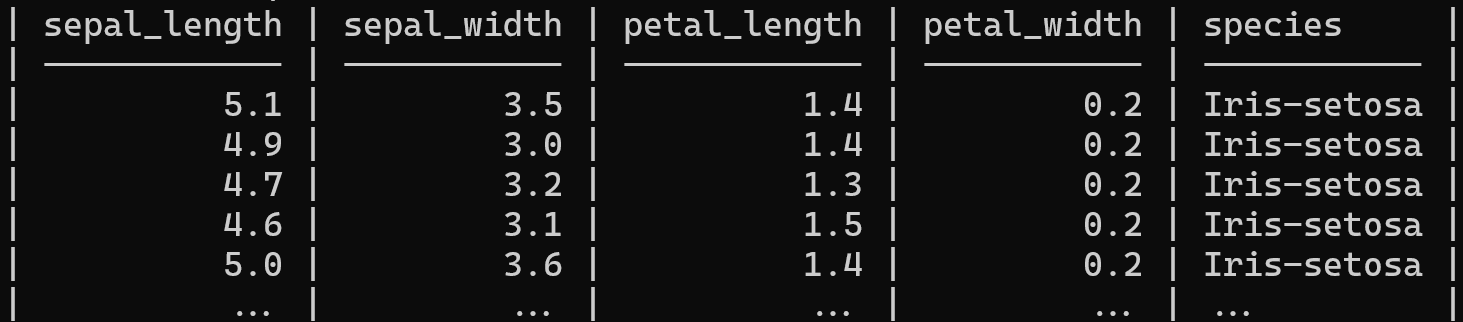
In dit voorbeeld gebruiken we csvcut om slechts twee kolommen te selecteren en gebruiken we csvlook om de resultaten in tabelvorm weer te geven.
csvcut -c sepal_length,species iris.csv | csvlook --max-rows 5
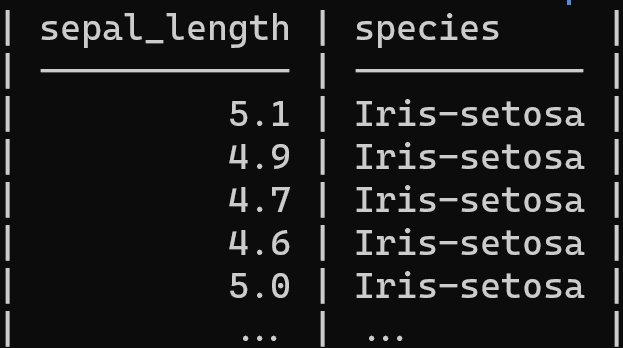
Opmerking: u kunt het aantal rijen beperken met het argument --max-rows
Voorbeeld 2
We zullen een CSV-bestand converteren naar een JSON-bestand met behulp van csvjson.
csvjson iris.csv > iris.json
Opmerking: csvkit biedt ons ook tools voor Excel naar CSV en JSON naar CSV.
Voorbeeld 3
We kunnen ook gegevensanalyse uitvoeren op een CSV-bestand met behulp van SQL-query. Csvsql vereist SQL-query en CSV-bestandspad U kunt de resultaten weergeven of opslaan in CSV.
csvsql --query "select * from iris where species like 'Iris-setosa'" iris.csv | csvlook --max-rows 5
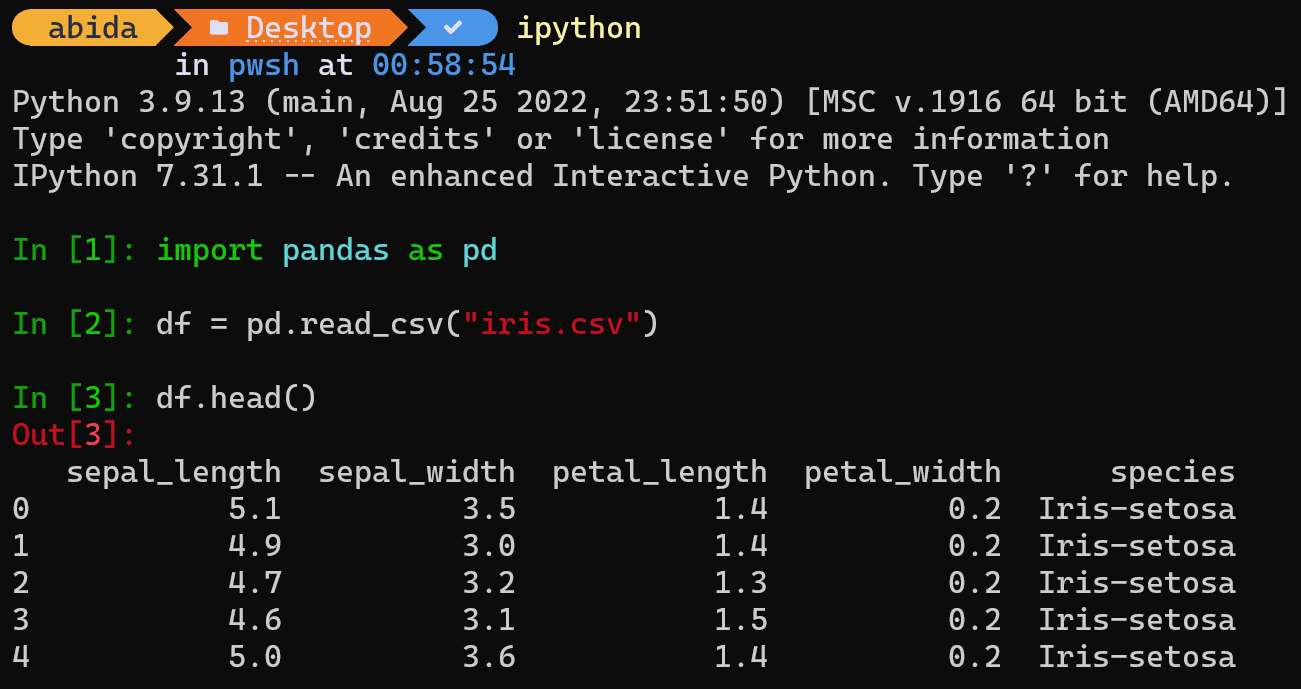
IPython is een interactieve Python-shell die enkele functionaliteiten van een jupyter-notebook in uw terminal brengt. Hiermee kunt u ideeën sneller testen zonder een Python-bestand te maken.
Install ipython pip-installatie gebruiken.
$ pip install ipython
Opmerking: Ipython wordt ook geleverd met Anaconda en Jupyter Notebook. U hoeft het dus in de meeste gevallen niet te installeren.
Typ na de installatie gewoon ipython in de terminal en begin met het uitvoeren van gegevensanalyse, net zoals u doet in Jupyter-notebooks. Het is gemakkelijk en snel.
Krul staat voor client-URL en is een CLI-tool voor het overbrengen van gegevens van en naar de server met behulp van URL's. U kunt het gebruiken om de snelheid te beperken, fouten te loggen, voortgang weer te geven en eindpunten te testen.
In het voorbeeld downloaden we de machine learning-gegevens van de Universiteit van Californië en slaan deze op als een CSV-bestand.
curl -o blood.csv https://archive.ics.uci.edu/ml/machine-learning-databases/blood-transfusion/transfusion.data
Output:
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed
100 12843 100 12843 0 0 7772 0 0:00:01 0:00:01 --:--:-- 7769
U kunt cURL gebruiken voor toegang tot API's met tokens, push-bestanden en het automatiseren van de gegevenspijplijnen.
Awk is een terminal-scripttaal die we kunnen gebruiken om de gegevens te manipuleren en gegevensanalyse uit te voeren. Het vereist geen klagen. We kunnen variabelen, numerieke functies, tekenreeksfuncties en logische operatoren gebruiken om elk type script te schrijven.
In het voorbeeld geven we de eerste en laatste kolom van het CSV-bestand weer en de laatste 10 rijen. De $1 in het script betekent de eerste kolommen. U kunt het ook wijzigen in $3 om de derde kolom weer te geven. De $NF vertegenwoordigt de laatste kolommen.
awk -F "," '{print $1 " | " $NF}' iris.csv | tail

Kaggle-API kunt u allerlei datasets downloaden van de Kaggle-website. Bovendien kunt u uw openbare dataset bijwerken, het bestand indienen bij de wedstrijd en Jupyter Notebook uitvoeren en beheren. Het is een superopdrachtregelprogramma.
Installeer Kaggle API met behulp van pip.
$ pip install kaggle
Ga daarna naar het Kaggle website en ontvang uw inloggegevens. Je kunt volgen dit handleiding om uw gebruikersnaam en privésleutel in te stellen.
export KAGGLE_USERNAME=kingabzpro
export KAGGLE_KEY=xxxxxxxxxxxxxxVoorbeeld 1
Na het instellen van authenticatie kunt u zoeken naar willekeurige datasets. In ons geval gebruiken we de Enquête over werkgelegenheidstrends gegevensset.
Afbeelding van Enquête over werkgelegenheidstrends
U kunt het downloadscript uitvoeren met -d argument GEBRUIKERSNAAM/DATASET.
$ kaggle datasets download -d revathyta/survey-on-employment-trends
Of,
U kunt eenvoudig een API-opdracht krijgen door op drie stippen te klikken en de optie "API-opdracht kopiëren" te selecteren.
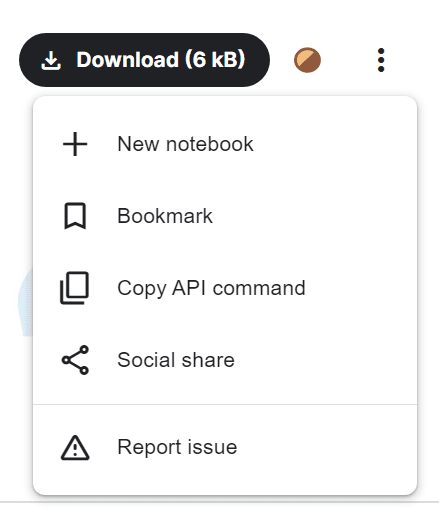
Afbeelding van Enquête over werkgelegenheidstrends
Het zal de dataset downloaden in de vorm van een zip-bestand. U kunt het script ook pipen met de unzip opdracht om de gegevens te extraheren.
Downloading survey-on-employment-trends.zip to C:Usersabida 0%| | 0.00/6.22k [00:00<?, ?B/s] 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 6.22k/6.22k [00:00<?, ?B/s]Voorbeeld 2
Om uw dataset op Kaggle te maken en te delen, moet u eerst een metadatabestand starten door het pad van de dataset op te geven.
$ kaggle datasets init -p /work/Kaggle/World-Vaccine-Progress
Maak daarna de dataset en push het bestand naar de Kaggle-server.
$ kaggle datasets create -p /work/Kaggle/World-Vaccine-Progress
U kunt uw dataset ook bijwerken met behulp van de version commando. Het vereist een bestandspad en bericht. Net als Git.
$ kaggle datasets version -p /work/Kaggle/World-Vaccine-Progress -m "second version"
Je kunt ook mijn project bekijken Dashboard voor vaccinupdates die met succes Kaggle API heeft geïmplementeerd om de dataset regelmatig bij te werken.
Er zijn zoveel geweldige CLI-tools die ik gebruik en ze hebben mijn productiviteit verbeterd en me geholpen het meeste van mijn werk te automatiseren. U kunt zelfs uw eigen CLI-tool in Python maken met behulp van click of argparse.
In dit artikel hebben we geleerd over CLI-tools om de dataset te downloaden, te manipuleren, analyses uit te voeren, scripts uit te voeren en rapporten te genereren.
Ik ben een fan van de Kaalgle API en csvkit. Ik gebruik het regelmatig om mijn notitieboekjes en analyse te automatiseren. Als u wilt leren hoe u opdrachtregelprogramma's kunt gebruiken in uw data science-workflow, lees dan Data Science op de commandoregel boek gratis online.
Abid Ali Awan (@1abidaliawan) is een gecertificeerde datawetenschapper-professional die dol is op het bouwen van machine learning-modellen. Momenteel richt hij zich op het creëren van content en het schrijven van technische blogs over machine learning en data science-technologieën. Abid heeft een Master in Technologie Management en een Bachelor in Telecommunicatie Engineering. Zijn visie is om een AI-product te bouwen met behulp van een grafisch neuraal netwerk voor studenten die worstelen met een psychische aandoening.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/03/5-command-line-tools-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=5-more-command-line-tools-for-data-science

