개요
컴퓨터 비전에는 Faster를 포함하여 실시간 객체 감지를 위한 다양한 기술이 존재합니다. R-CNN, SSD및 YOLO. 각 기술에는 한계와 장점이 있습니다. Faster R-CNN은 정확성이 뛰어날 수 있지만 실시간 시나리오에서는 성능이 좋지 않을 수 있으므로 YOLO 알고리즘.
객체 감지는 컴퓨터 비전의 기본으로, 기계가 프레임이나 화면 내에서 객체를 식별하고 찾을 수 있도록 해줍니다. 수년에 걸쳐 다양한 객체 감지 알고리즘이 개발되었으며 YOLO가 가장 성공적인 알고리즘 중 하나로 부상했습니다. 최근에는 YOLOv8이 도입되어 알고리즘의 기능이 더욱 향상되었습니다.
이 포괄적인 가이드에서는 Faster R-CNN, SSD(Single Shot MultiBox Detector) 및 YOLOv8의 세 가지 주요 객체 감지 알고리즘을 살펴봅니다. 가상 환경 설정 및 Streamlit 애플리케이션 개발을 포함하여 이러한 알고리즘 구현의 실제적인 측면을 논의합니다.
학습 목표
- Faster R-CNN, SSD, YOLO를 이해하고 이들 간의 차이점을 분석해 보세요.
- OpenCV, Supervision 및 YOLOv8을 사용하여 실시간 객체 감지 시스템을 구현하는 실무 경험을 쌓으세요.
- Roboflow 주석을 사용한 이미지 분할 모델 이해
- 쉬운 사용자 인터페이스를 위한 Streamlit 애플리케이션을 만듭니다.
YOLOv8을 사용하여 이미지 분할을 수행하는 방법을 살펴보겠습니다!
차례
이 기사는 데이터 과학 블로그.
빠른 R-CNN
Faster R-CNN(Faster Region-based Convolutional Neural Network)은 딥러닝 기반 객체 감지 알고리즘입니다. 이는 R-CNN 및 Fast R-CNN 프레임워크를 사용하여 평가되며 Fast R-CNN의 확장으로 간주될 수 있습니다.
이 알고리즘은 RPN(Region Proposal Network)을 도입하여 지역 제안을 생성하고 R-CNN에서 사용되는 선택적 검색을 대체합니다. RPN은 감지 네트워크와 컨볼루션 레이어를 공유하므로 효율적인 엔드투엔드 훈련이 가능합니다.
생성된 영역 제안은 경계 상자 개선 및 객체 분류를 위해 Fast R-CNN 네트워크에 공급됩니다.
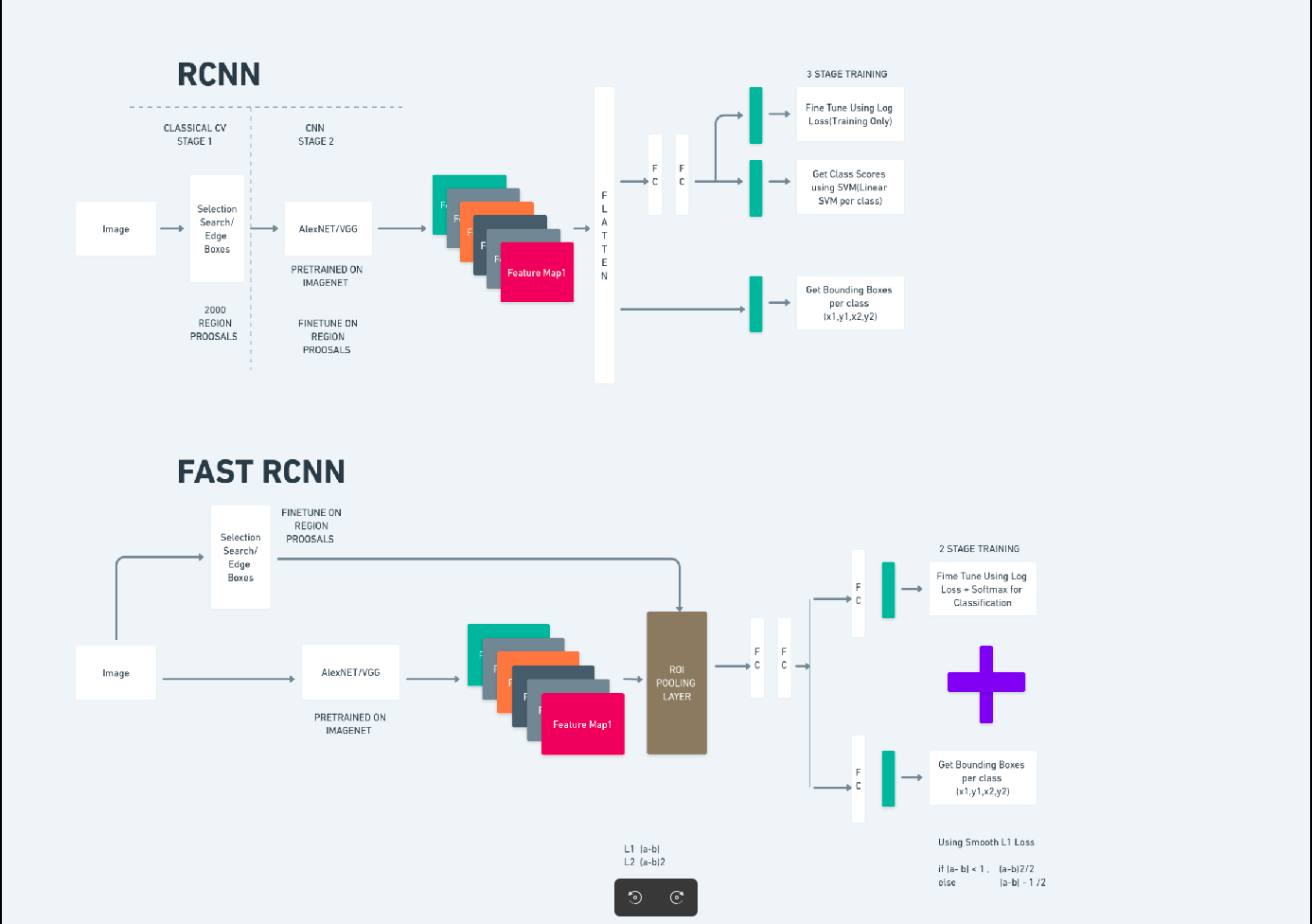
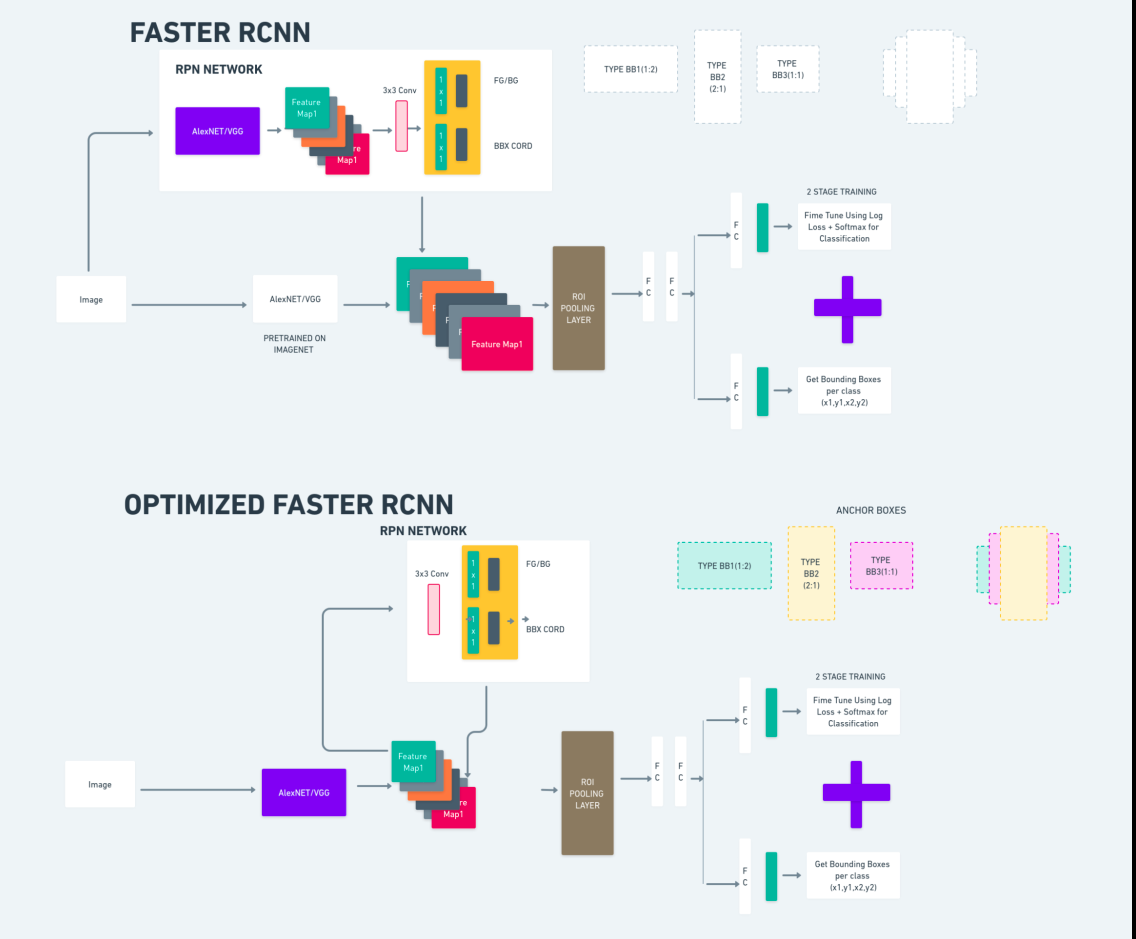
위의 다이어그램은 Faster R-CNN 계열을 포괄적으로 보여주며 각 알고리즘을 평가하는 데 이해하기 쉽습니다.
싱글샷 멀티박스 감지기(SSD)
XNUMXD덴탈의 단일 샷 멀티박스 감지기(SSD)은 객체 감지에 널리 사용되며 주로 컴퓨터 비전 작업에 사용됩니다. 이전 방법인 Faster R-CNN에서는 두 단계를 따랐습니다. 첫 번째 단계는 탐지 부분을 포함하고 두 번째 단계는 회귀를 포함했습니다. 그러나 SSD에서는 단일 감지 단계만 수행합니다. SSD는 빠르고 정확한 객체 감지 모델에 대한 요구를 해결하기 위해 2016년에 도입되었습니다.

SSD는 Faster R-CNN과 같은 이전 객체 감지 방법에 비해 몇 가지 장점이 있습니다.
- 효율성: SSD는 단일 단계 감지기입니다. 즉, 별도의 제안 생성 단계 없이 경계 상자와 클래스 점수를 직접 예측합니다. 이는 Faster R-CNN과 같은 2단계 검출기에 비해 속도가 더 빠릅니다.
- 엔드투엔드 훈련: SSD는 엔드투엔드 훈련이 가능하여 기본 네트워크와 감지 헤드를 공동으로 최적화하여 훈련 프로세스를 단순화합니다.
- 다중 규모 기능 융합: SSD는 다양한 규모의 기능 맵에서 작동하므로 다양한 크기의 개체를 보다 효과적으로 감지할 수 있습니다.
SSD는 속도와 정확성 사이의 적절한 균형을 유지하므로 성능과 효율성이 모두 중요한 실시간 애플리케이션에 적합합니다.
한 번만 보세요(YOLOv8)
2015년 Joseph Redmon, Santosh Divvala, Ross Girshick 및 Ali Farhadi의 연구 논문에서 객체 감지 알고리즘으로 YOLO(You Only Look Once)가 도입되었습니다. YOLO는 하나의 신경망만이 전체 이미지를 입력으로 사용하여 경계 상자 및 클래스 확률을 예측하도록 하여 단일 패스에서 객체를 직접 분류하는 싱글샷 알고리즘입니다.
이제 YOLOv8을 향상된 정확도와 속도로 실시간 개체 감지의 최첨단 발전으로 이해해 보겠습니다. YOLOv8을 사용하면 COCO(Common Objects in Context)와 같은 방대한 데이터세트에서 이미 훈련된 사전 훈련된 모델을 활용할 수 있습니다. 이미지 분할은 각 개체에 대한 픽셀 수준 정보를 제공하므로 이미지 내용을 보다 자세히 분석하고 이해할 수 있습니다.
이미지 분할은 계산 비용이 많이 들 수 있지만 YOLOv8은 이 방법을 신경망 아키텍처에 통합하여 효율적이고 정확한 개체 분할을 가능하게 합니다.
YOLOv8의 작동 원리
OLO 로브 8 먼저 입력 이미지를 그리드 셀로 나누어 작동합니다. 이러한 그리드 셀을 사용하여 YOLOv8은 클래스 확률로 경계 상자(bbox)를 예측합니다.
이후 YOLOv8은 NMS 알고리즘을 사용하여 중복을 줄입니다. 예를 들어, 이미지에 여러 대의 자동차가 있어 경계 상자가 겹치는 경우 NMS 알고리즘은 이러한 중복을 줄이는 데 도움이 됩니다.
Yolo V8 변형 간의 차이점: YOLOv8은 YOLOv8, YOLOv8-L 및 YOLOv8-X의 세 가지 변형으로 제공됩니다. 변형 간의 주요 차이점은 백본 네트워크의 크기입니다. YOLOv8은 가장 작은 백본 네트워크를 갖고 있는 반면 YOLOv8-X는 가장 큰 백본 네트워크를 가지고 있습니다.
차이 더 빠른 R-CNN, SSD, YOLO 사이
| 양상 | 빠른 R-CNN | SSD | YOLO |
|---|---|---|---|
| 아키텍처 | RPN 및 Fast R-CNN을 갖춘 2단계 검출기 | 단일 스테이지 검출기 | 단일 스테이지 검출기 |
| 지역 제안 | 가능 | 아니 | 아니 |
| 감지 속도 | SSD 및 YOLO에 비해 속도가 느림 | Faster R-CNN에 비해 빠르며 YOLO보다 느림 | 매우 빠른 |
| 정확성 | 일반적으로 정확도가 더 높음 | 정확성과 속도의 균형 | 특히 실시간 애플리케이션의 경우 상당한 정확도 |
| 유연성 | 유연하며 다양한 물체 크기와 종횡비를 처리할 수 있습니다. | 다양한 규모의 물체를 처리할 수 있습니다. | 작은 물체의 정확한 위치 파악에 어려움을 겪을 수 있음 |
| 통합 탐지 | 아니 | 아니 | 가능 |
| 속도와 정확성의 절충 | 일반적으로 정확성을 위해 속도를 희생합니다. | 속도와 정확성의 균형 | 적절한 정확도를 유지하면서 속도를 우선시합니다. |
세분화 란 무엇입니까?
우리가 알고 있듯이 분할은 특정 특성에 따라 큰 이미지를 더 작은 그룹으로 나누는 것을 의미합니다. 이미지를 서로 다른 여러 세그먼트 또는 영역으로 분할하는 데 사용되는 컴퓨터 비전 기술인 이미지 분할을 이해해 보겠습니다. 이미지는 픽셀로 구성되며 이미지 분할에서는 색상, 강도, 질감 또는 기타 시각적 속성의 유사성에 따라 픽셀이 그룹화됩니다.
예를 들어 이미지에 나무, 자동차 또는 사람이 포함된 경우 이미지 분할은 이미지를 의미 있는 개체나 이미지의 일부를 나타내는 여러 클래스로 나눕니다. 이미지 분할은 의료 영상, 위성 이미지 분석, 컴퓨터 비전의 객체 인식 등과 같은 다양한 분야에서 널리 사용됩니다.

분할 부분에서는 처음에 Robflow를 사용하여 첫 번째 YOLOv8 분할 모델을 생성합니다. 그런 다음 분할 모델을 가져와 분할 작업을 수행합니다. 질문이 생깁니다. 감지 알고리즘만으로 작업을 완료할 수 있는데 왜 분할 모델을 생성합니까?
분할을 통해 클래스의 전신 이미지를 얻을 수 있습니다. 감지 알고리즘은 객체의 존재 여부를 감지하는 데 중점을 두는 반면, 분할은 객체의 정확한 경계를 묘사하여 보다 정확한 이해를 제공합니다. 이를 통해 이미지에 존재하는 객체를 보다 정확하게 위치 파악하고 이해할 수 있습니다.
그러나 세분화에는 주석 분리 및 모델 생성과 같은 추가 단계가 필요하기 때문에 일반적으로 감지 알고리즘에 비해 시간 복잡성이 더 높습니다. 이러한 단점에도 불구하고 분할을 통해 제공되는 향상된 정밀도는 정확한 객체 묘사가 중요한 작업에서 계산 비용보다 클 수 있습니다.
YOLOv8을 사용한 단계별 실시간 감지 및 이미지 분할
이 개념에서는 conda를 사용하여 가상 환경을 생성하고, venv를 활성화하고, pip를 사용하여 요구 사항 패키지를 설치하는 단계를 탐색합니다. 먼저 일반 Python 스크립트를 만든 다음 스트림라이트 애플리케이션을 만듭니다.
1단계: Conda를 사용하여 가상 환경 생성
conda create -p ./venv python=3.8 -y2단계: 가상 환경 활성화
conda activate ./venv
3단계: 요구 사항.txt 만들기
터미널을 열고 아래 스크립트를 붙여넣습니다.
touch requirements.txt4단계: Nano 명령을 사용하고 요구 사항.txt를 편집합니다.
요구사항.txt를 생성한 후 요구사항.txt를 편집하려면 다음 명령을 작성하십시오.
nano requirements.txt위 스크립트를 실행하면 이 UI를 볼 수 있습니다.
그녀에게 필요한 패키지를 작성하십시오.
ultralytics==8.0.32
supervision==0.2.1
streamlit그런 다음 “ctrl+O”(이 명령은 편집 부분을 저장합니다) 그런 다음 "시작하다"
"를 누른 후Ctrl+x”. 파일을 종료할 수 있습니다. 그리고 메인 경로로 갑니다.
5단계: 요구사항.txt 설치
pip install -r requirements.txt6단계: Python 스크립트 만들기
터미널에서 다음 스크립트를 작성하거나 명령을 말할 수 있습니다.
touch main.pymain.py를 생성한 후 터미널에서 write 명령을 사용하여 vs 코드를 엽니다.
code 7단계: Python 스크립트 작성
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
이 명령을 실행하면 카메라가 열려 있고 자신의 일부가 감지되는 것을 볼 수 있습니다. 성별 및 배경 부분과 같습니다.
7단계: 간소화된 앱 만들기
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
이 스크립트에서는 버튼을 누른 후 장치 카메라가 열리고 프레임의 일부를 감지하도록 스트림라이트 애플리케이션을 만들고 버튼을 만듭니다.
이 명령을 사용하여 이 스크립트를 실행하십시오.
streamlit run app.py
# first create the app.py then paste the above code and run this script.위 명령을 실행한 후 다음과 같은 연결 오류가 발생했다고 가정해 보겠습니다.
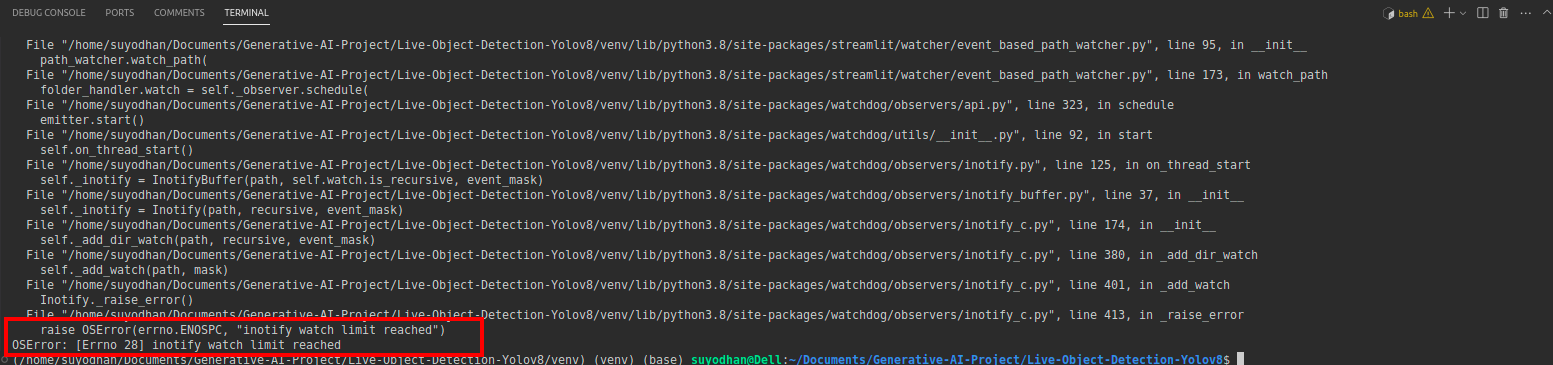
그런 다음 이 명령을 누르세요.
sudo sysctl fs.inotify.max_user_watches=524288sudo 명령을 사용하고 있으므로 비밀번호를 쓰려는 명령을 누른 후 sudo is god:)
스크립트를 다시 실행하십시오. 스트림라이트 애플리케이션을 볼 수 있습니다.
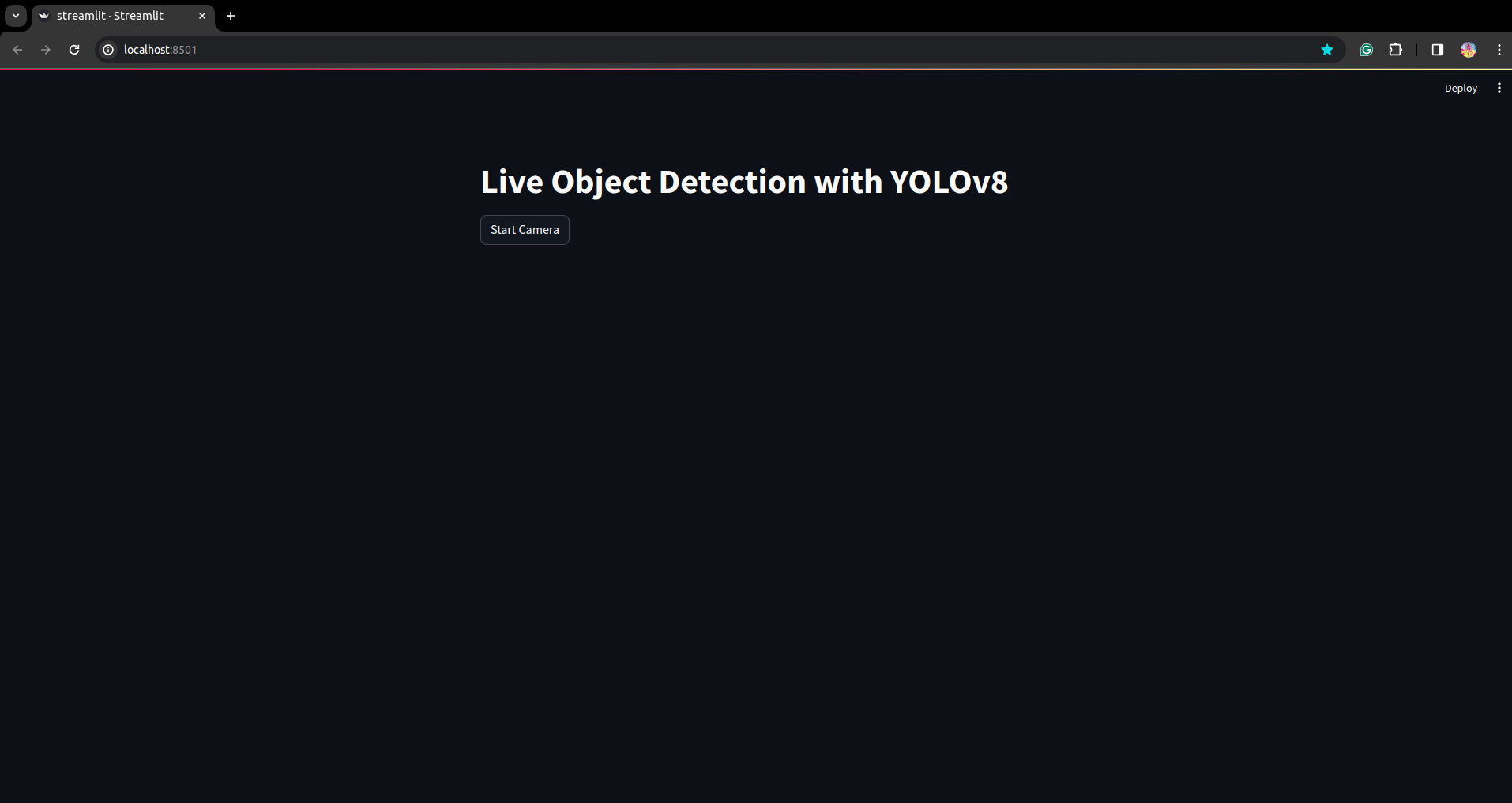
다음 부분에서는 분할 부분을 살펴보며 성공적인 실시간 감지 애플리케이션을 만들 수 있습니다.
주석 단계
1단계: Roboflow 설정
로그인 후 "프로젝트 생성'을 참조하세요. 여기에서 프로젝트와 주석 그룹을 생성할 수 있습니다.

2단계: 데이터세트 다운로드
여기서는 간단한 예를 고려하지만 문제 설명에 이를 사용하기를 원하므로 여기서는 duck 데이터세트를 사용하겠습니다.
이거 가세요 링크 그리고 오리 데이터세트를 다운로드하세요.

거기에서 폴더를 추출하면 세 개의 폴더를 볼 수 있습니다. 훈련, 테스트 및 평가.
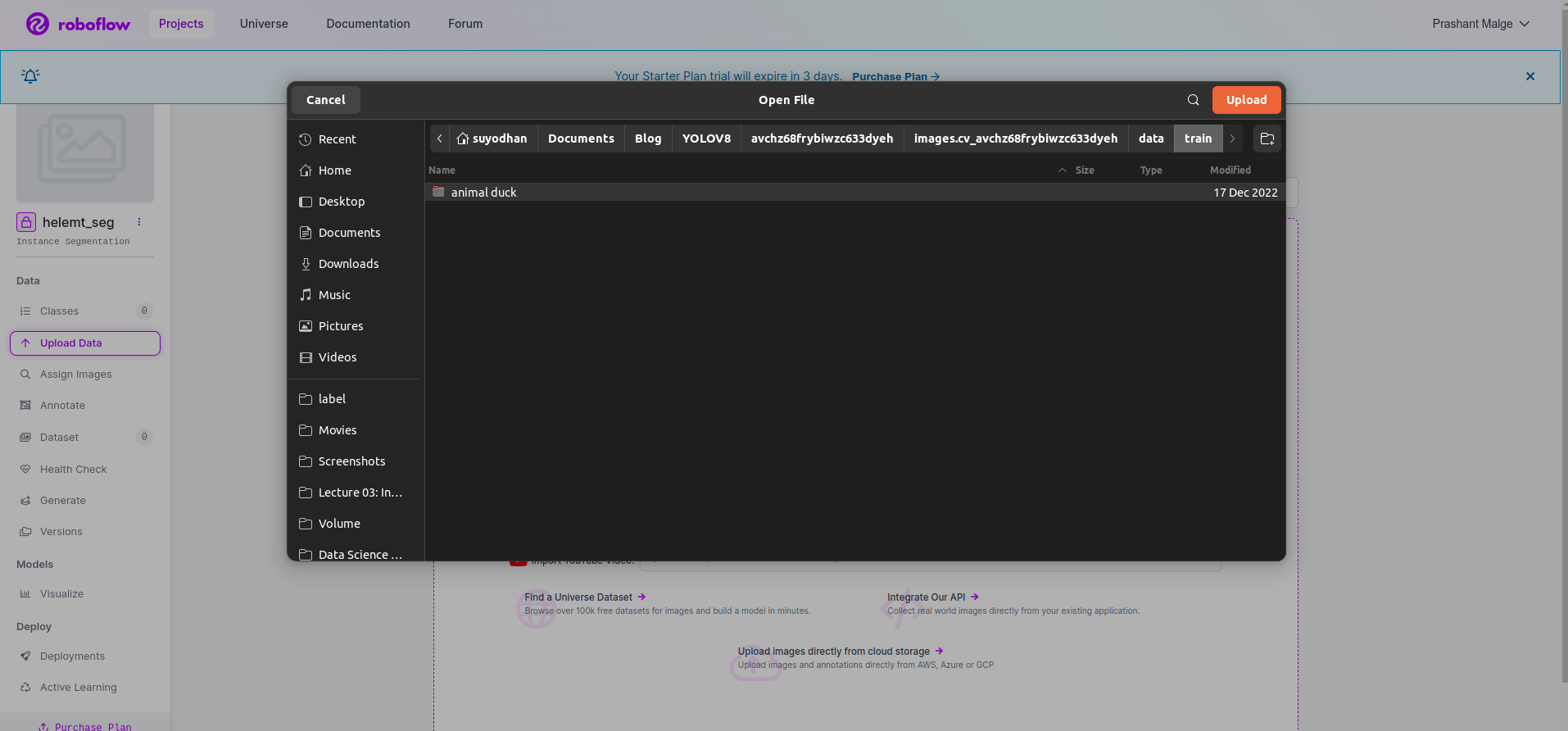
3단계: roboflow에 데이터세트 업로드
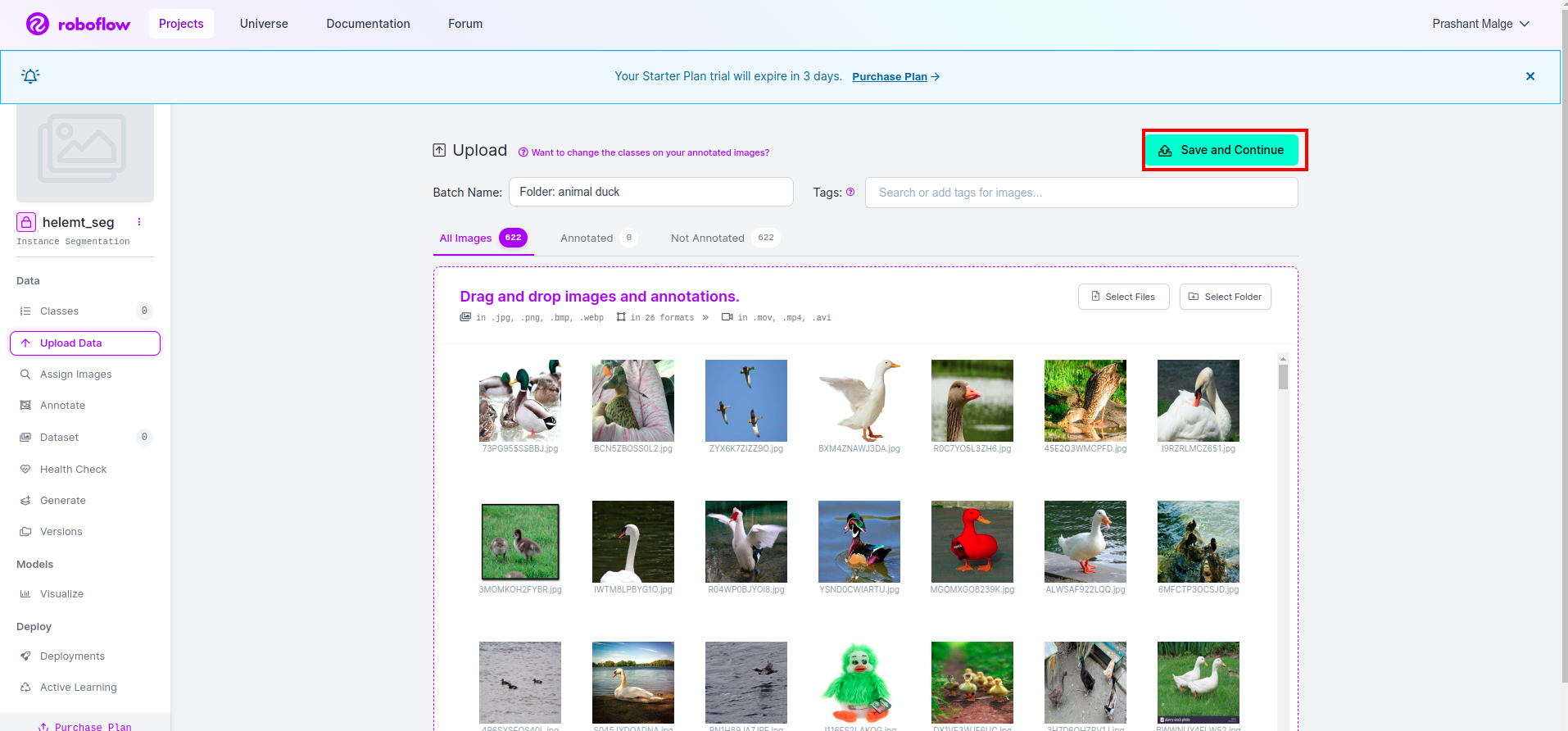
roboflow에서 프로젝트를 생성한 후 여기에서 이 UI를 볼 수 있습니다. 데이터 세트를 업로드할 수 있으므로 기차 부품 이미지만 업로드하려면 "폴더 선택” 옵션을 선택합니다.
그런 다음 "저장하고 계속" 빨간색 직사각형 상자에 표시한 옵션
4단계: 클래스 이름 추가
그런 다음 수업 부분 왼쪽의 빨간색 상자를 확인하세요. 클래스 이름을 다음과 같이 작성하십시오. 오리, 녹색 상자를 클릭한 후
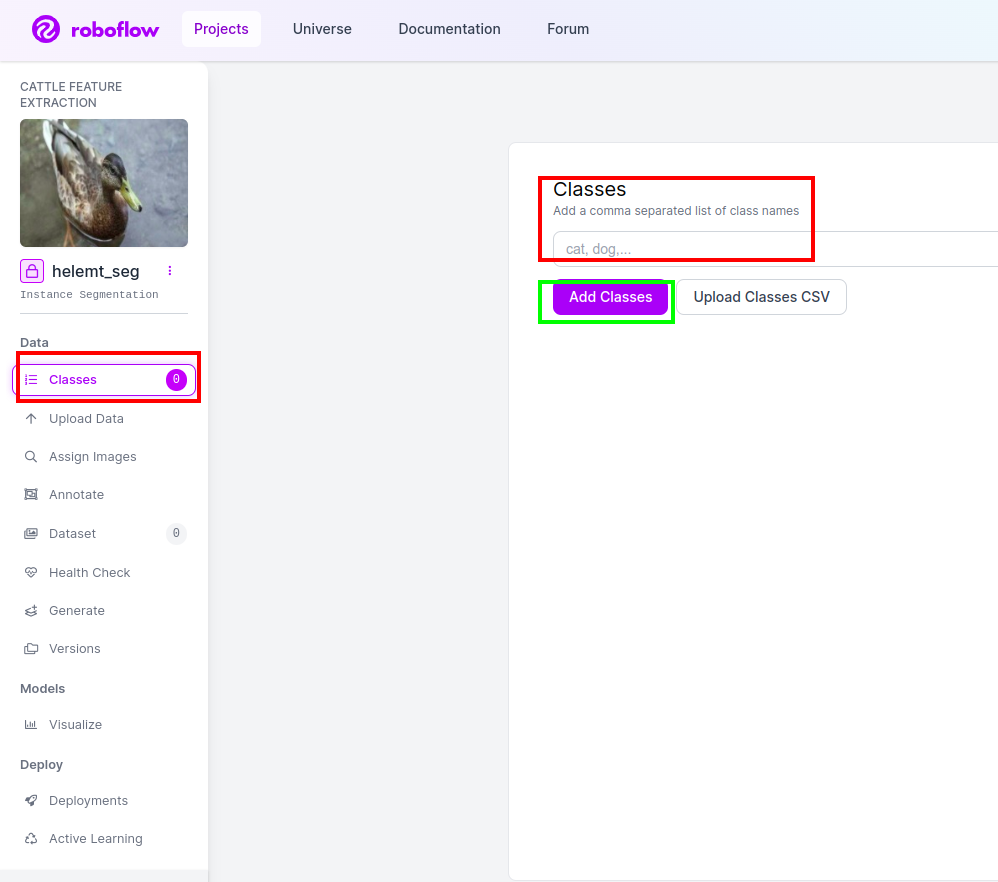
이제 설정이 완료되었으며 주석 부분과 같은 다음 부분도 간단합니다.
5단계: 시작 주석 부분
로 이동 주석 옵션 빨간색 상자에 표시한 다음 녹색 상자에 표시한 대로 주석 부분 시작을 클릭합니다.
이 UI를 볼 수 있는 첫 번째 이미지를 클릭하세요. 이 내용을 확인한 후 수동 주석 옵션을 클릭하세요.
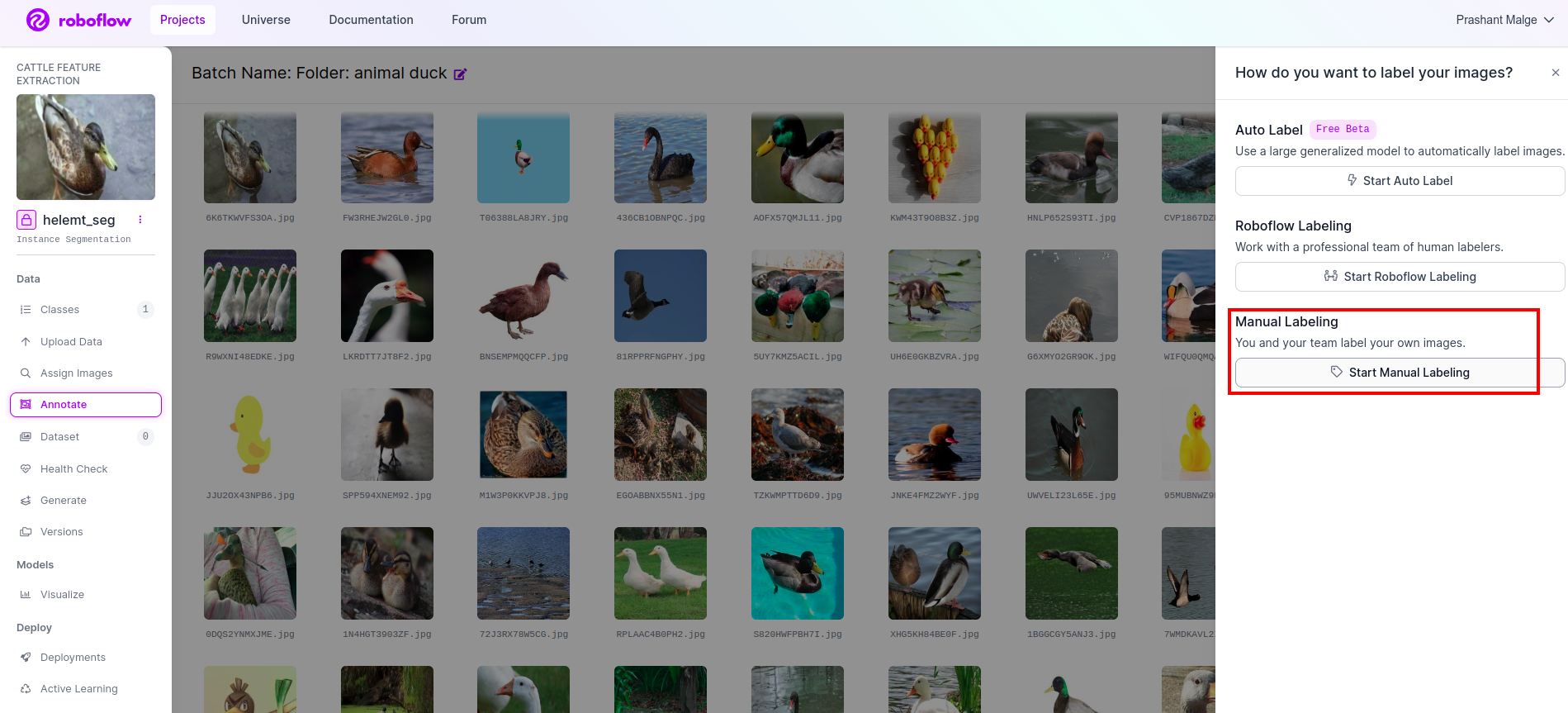
그런 다음 작업을 할당할 수 있도록 이메일 ID나 팀원의 이름을 추가하세요.
이 UI를 볼 수 있는 첫 번째 이미지를 클릭하세요. 여기서 빨간색 상자를 클릭하면 다중 다항식 모델을 선택할 수 있습니다.
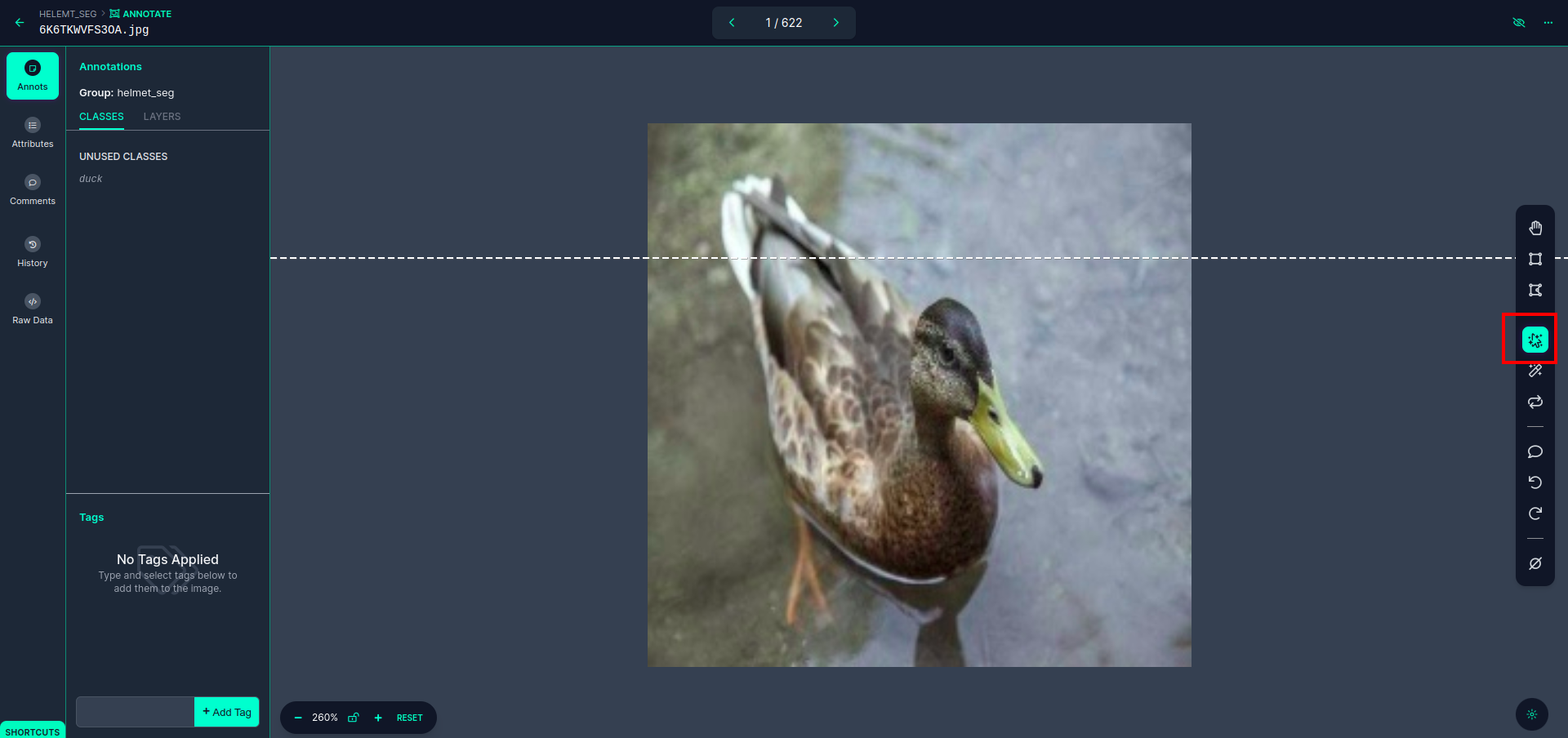
빨간색 상자를 클릭한 후 기본 모델을 선택하고 오리 개체를 클릭합니다. 그러면 이미지가 자동으로 분할됩니다. 그런 다음 다음 부분을 클릭하고 저장하십시오. 그러면 왼쪽에 빨간색 상자로 표시된 클래스 이름이 표시됩니다.
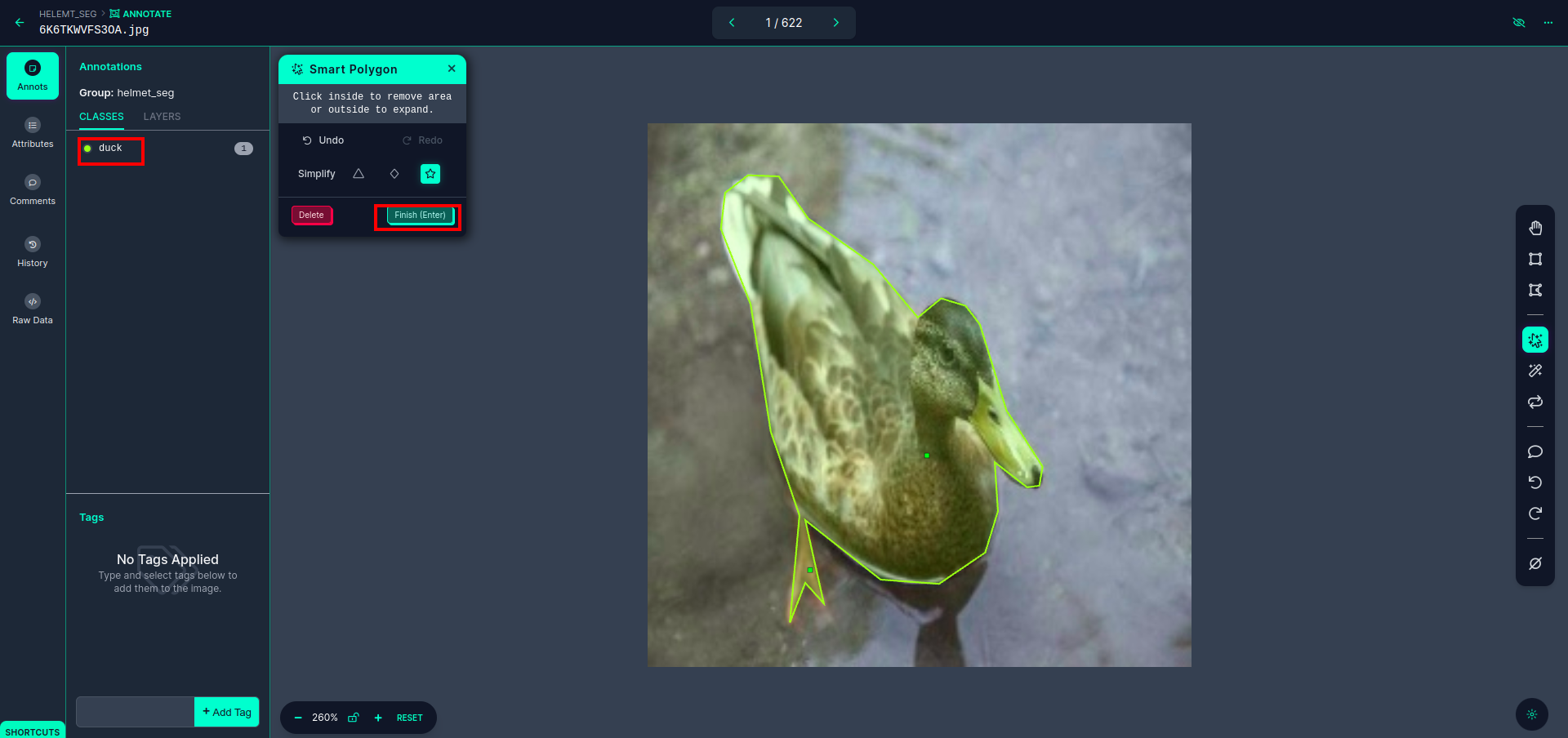
클릭 저장&입력 옵션. 모든 이미지에 주석을 답니다.
YOLOv8 형식의 이미지를 추가합니다. 오른쪽에는 주석 섹션에 이미지를 추가하는 옵션이 표시됩니다. 여기서는 두 부분이 생성됩니다. 하나는 주석이 달린 이미지용이고 다른 하나는 주석이 없는 이미지용입니다.
- 먼저 왼쪽 '주석을 달다” 다음 옵션 더하다 이미지들 데이터 세트에.
- 그런 다음 다음 "을 클릭하십시오.이미지 추가".
이제 마지막으로 데이터 세트를 생성하므로 왼쪽의 "Generate" 옵션을 클릭한 다음 옵션을 확인하고 conitune 옵션을 누릅니다.
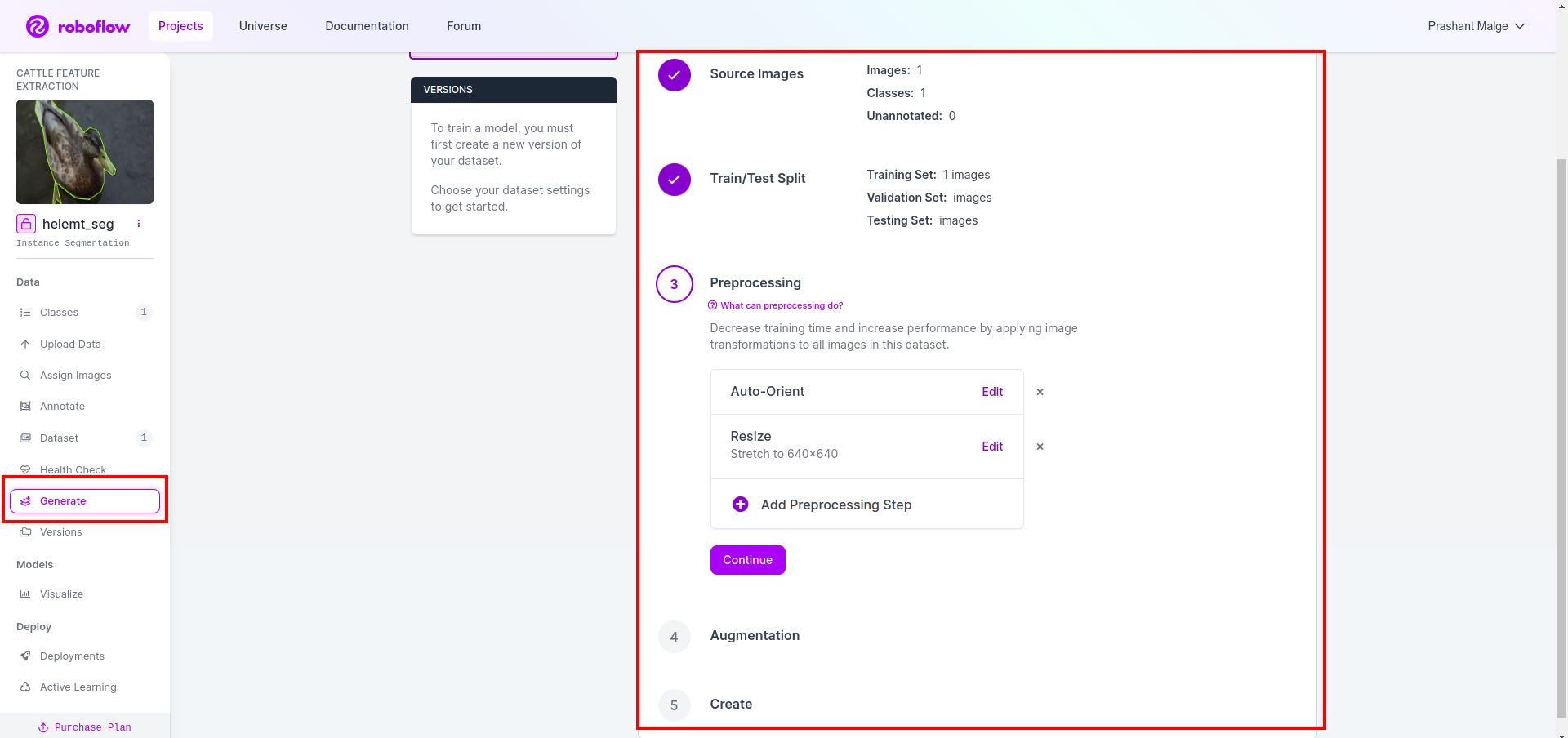
그런 다음 여기서 데이터 세트 분할 옵션의 UI를 얻으면 이미지가 자동으로 분할되는 train, test 및 val 폴더를 확인할 수 있습니다. 그리고 위의 빨간색 박스를 클릭하세요 데이터세트 내보내기 옵션 그리고 zip 파일을 다운로드하세요. zip 파일 폴더 구조는 다음과 같습니다.
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
6단계: 이미지 분할 모델 학습을 위한 스크립트 작성
이 부분에서는 먼저 Drive를 사용하여 Google Collab 파일을 만든 다음 데이터세트를 업로드합니다. Google Collab을 사용하여 Google 드라이브를 이동합니다.
1. 다음 용도로 이 명령을 사용하세요. Google 드라이브 마운트
from google.colab import drive
drive.mount('/content/gdrive')2. 데이터 디렉터리 정의 상수 변수를 사용하십시오.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. 필수 패키지를 설치하고, 울트라리틱스 설치
!pip install ultralytics4. 라이브러리 가져오기
import os
from ultralytics import YOLO5.로드 사전 훈련된 YOLOv8 모델(여기에는 다른 모델이 있습니다. 또한 공식 문서를 확인하면 다른 모델을 볼 수 있습니다)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. 모델 훈련
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together 아니요, 드라이브를 확인하세요. 모델 이름 폴더가 생성되고 이 모델을 원하는 예측을 위해 모델이 저장됩니다.
7. 모델 예측
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)여기서 분할 이미지가 저장되는 것을 볼 수 있습니다.

이제 마침내 실시간 감지 및 이미지 분할 모델을 모두 구축할 수 있습니다.
결론
이 블로그에서는 YOLOv8을 사용한 실시간 객체 감지 및 이미지 분할을 살펴봅니다. 실시간 감지를 위해 사전 훈련된 YOLOv8 모델을 가져오고 컴퓨터 비전 라이브러리인 OpenCV를 활용하여 카메라를 열고 객체를 감지합니다. 또한 매력적인 사용자 인터페이스를 위한 Streamlit 애플리케이션을 만듭니다.
다음으로 YOLOv8을 사용한 이미지 분할을 살펴보겠습니다. 사전 훈련된 모델을 가져오고 사용자 정의 데이터세트에 대해 전이 학습을 수행합니다. 이에 앞서 우리는 데이터 세트 주석을 위한 Roboflow를 탐색하여 다음과 같은 도구에 대한 사용하기 쉬운 대안을 제공했습니다. 레이블Img.
마지막으로 오리가 포함된 이미지를 예측합니다. 이미지의 객체는 새처럼 보이지만 클래스 이름을 "피하다" 시연 목적으로.
주요 요점
- Faster R-CNN, SSD 및 최신 YOLOv8과 같은 객체 감지 모델에 대해 알아봅니다.
- 주석 도구 Roboflow와 YOLOv8 분할 모델용 데이터 세트 생성 시 해당 역할을 이해합니다.
- OpenCV(cv2) 및 Supervision을 사용하여 실시간 객체 감지를 탐색하고 실용적인 기술을 향상시킵니다.
- YOLOv8을 사용하여 세분화 모델을 교육 및 배포하고 실습 경험을 쌓습니다.
자주하는 질문
A. 객체 감지에는 일반적으로 객체 주위에 경계 상자를 그려 이미지 내의 여러 객체를 식별하고 찾는 작업이 포함됩니다. 반면, 이미지 분할은 픽셀 유사성을 기준으로 이미지를 세그먼트 또는 영역으로 나누어 객체 경계를 보다 자세히 이해할 수 있도록 해줍니다.
A. YOLOv8은 네트워크 아키텍처, 교육 기술 및 최적화의 발전을 통합하여 이전 버전을 개선합니다. YOLOv3에 비해 더 나은 정확성, 속도 및 효율성을 제공할 수 있습니다.
A. YOLOv8은 하드웨어 기능 및 모델 최적화에 따라 임베디드 장치에서 실시간 객체 감지에 사용될 수 있습니다. 그러나 리소스가 제한된 장치에서 실시간 성능을 달성하려면 모델 정리 또는 양자화와 같은 최적화가 필요할 수 있습니다.
A. Roboflow는 직관적인 주석 도구, 데이터 세트 관리 기능, 다양한 주석 형식 지원을 제공합니다. 주석 프로세스를 간소화하고, 협업을 가능하게 하며, 버전 제어를 제공하므로 컴퓨터 비전 프로젝트를 위한 데이터 세트를 더 쉽게 생성하고 관리할 수 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

