Pandas는 Python을 사용한 데이터 조작 및 분석을 위한 강력하고 널리 사용되는 오픈 소스 라이브러리입니다. 주요 기능 중 하나는 DataFrame을 하나 이상의 열을 기준으로 그룹으로 분할한 다음 각각에 다양한 집계 함수를 적용하여 groupby 함수를 사용하여 데이터를 그룹화하는 기능입니다.

이미지 출처 : Unsplash
XNUMXD덴탈의 groupby 기능은 대규모 데이터 세트를 빠르게 요약하고 분석할 수 있으므로 매우 강력합니다. 예를 들어 특정 열을 기준으로 데이터 세트를 그룹화하고 각 그룹에 대한 나머지 열의 평균, 합계 또는 개수를 계산할 수 있습니다. 또한 여러 열로 그룹화하여 데이터를 보다 세부적으로 이해할 수 있습니다. 또한 복잡한 데이터 분석 작업을 위한 매우 강력한 도구가 될 수 있는 사용자 지정 집계 함수를 적용할 수 있습니다.
이 자습서에서는 Pandas의 groupby 기능을 사용하여 다양한 유형의 데이터를 그룹화하고 다양한 집계 작업을 수행하는 방법을 배웁니다. 이 자습서가 끝나면 이 기능을 사용하여 다양한 방식으로 데이터를 분석하고 요약할 수 있습니다.
개념은 잘 연습될 때 내면화되며 이것이 우리가 다음에 할 것입니다. 즉, Pandas groupby 기능을 직접 사용해 볼 것입니다. 다음을 사용하는 것이 좋습니다. 주피터 수첩 이 자습서에서는 각 단계에서 출력을 볼 수 있습니다.
샘플 데이터 생성
다음 라이브러리를 가져옵니다.
- Pandas: 데이터 프레임을 만들고 그룹 기준을 적용하려면
- Random – 무작위 데이터 생성
- Pprint – 사전을 인쇄하려면
import pandas as pd
import random
import pprint
다음으로 빈 데이터 프레임을 초기화하고 아래와 같이 각 열의 값을 채웁니다.
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
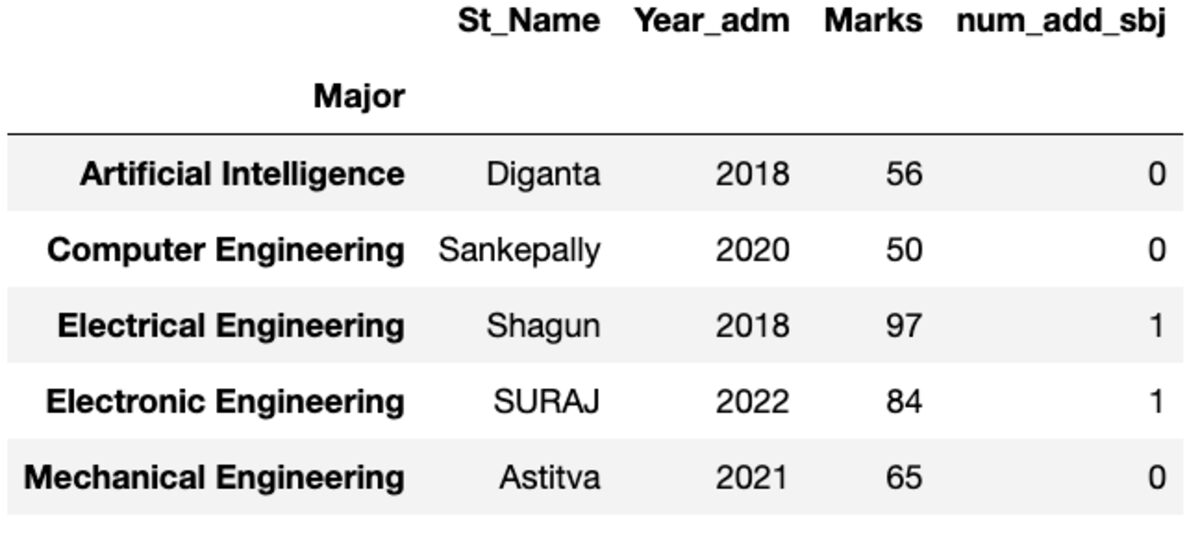
df.head()
보너스 팁 – 동일한 작업을 수행하는 더 깔끔한 방법은 모든 변수와 값의 사전을 만들고 나중에 이를 데이터 프레임으로 변환하는 것입니다.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
데이터 프레임은 아래에 표시된 것과 같습니다. 이 코드를 실행할 때 무작위 샘플을 사용하기 때문에 일부 값이 일치하지 않습니다.
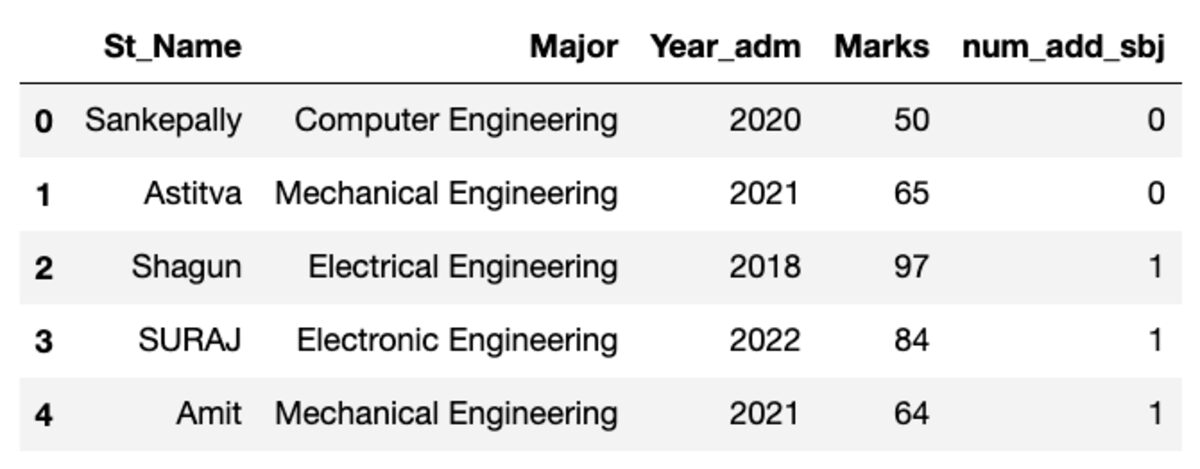
그룹 만들기
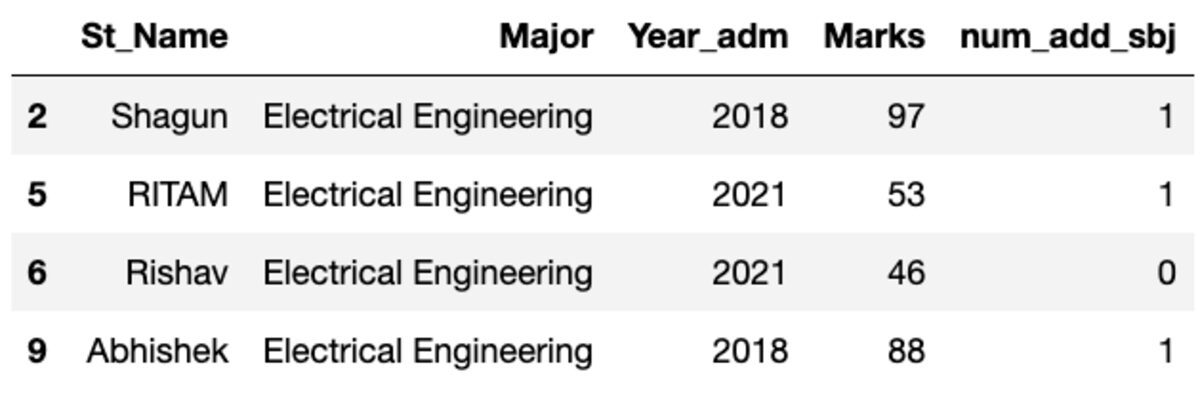
"주요" 주제별로 데이터를 그룹화하고 그룹 필터를 적용하여 이 그룹에 속하는 레코드 수를 확인합니다.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
그래서 XNUMX명의 학생이 전기공학과에 속해 있습니다.
둘 이상의 열(이 경우 Major 및 num_add_sbj)로 그룹화할 수도 있습니다.
groups = df.groupby(['Major', 'num_add_sbj'])
열이 하나인 그룹에 적용할 수 있는 모든 집계 함수는 여러 열이 있는 그룹에 적용할 수 있습니다. 자습서의 나머지 부분에서는 단일 열을 예로 사용하여 다양한 유형의 집계에 중점을 두겠습니다.
"Major" 열에 groupby를 사용하여 그룹을 만들어 봅시다.
groups = df.groupby('Major')직접 함수 적용
각 전공의 평균 점수를 찾고 싶다고 가정해 보겠습니다. 어떻게 하시겠습니까?
- 마크 열 선택
- 평균 함수 적용
- 반올림 기능을 적용하여 소수점 이하 두 자리까지 표시를 반올림합니다(선택 사항).
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
골재
동일한 결과를 얻는 또 다른 방법은 아래와 같이 집계 함수를 사용하는 것입니다.
groups['Marks'].aggregate('mean').round(2)
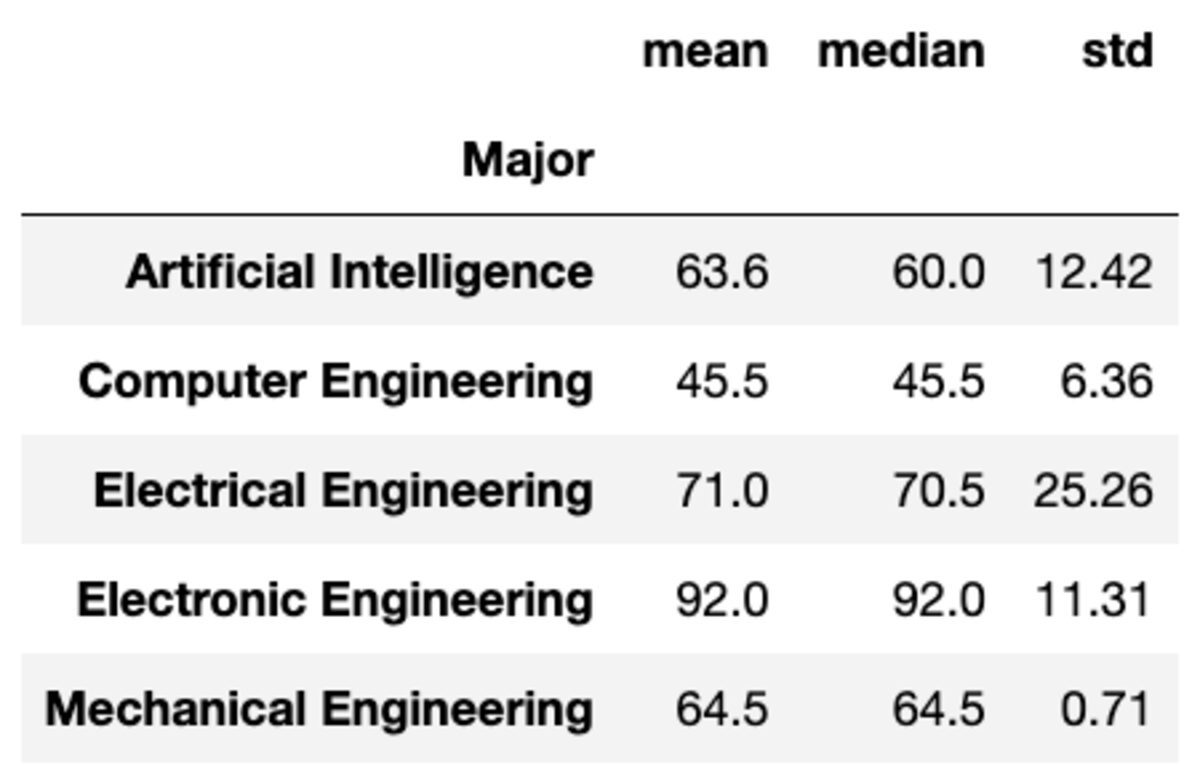
함수를 문자열 목록으로 전달하여 여러 집계를 그룹에 적용할 수도 있습니다.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
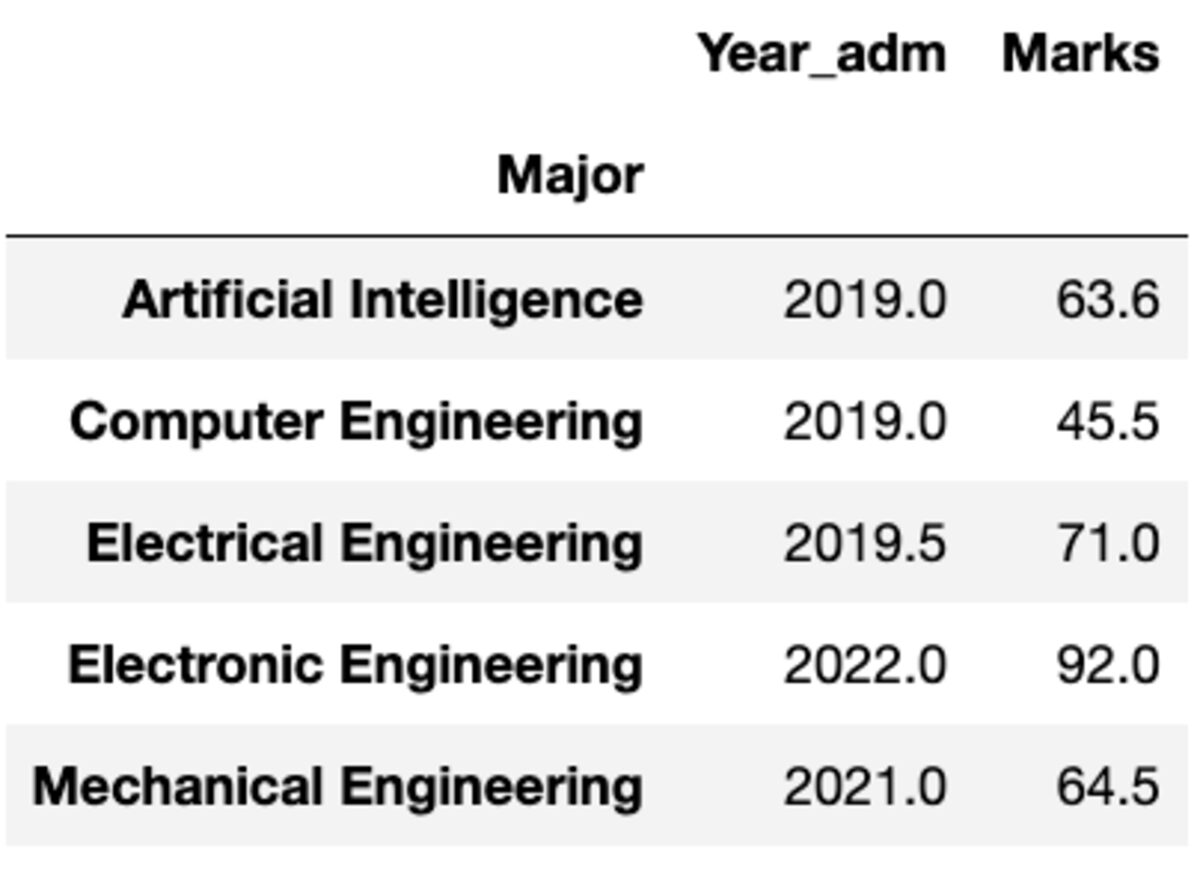
그러나 다른 열에 다른 기능을 적용해야 하는 경우에는 어떻게 해야 합니까? 괜찮아요. {column: function} 쌍을 전달하여 이를 수행할 수도 있습니다.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
변환
groupby()를 사용하여 쉽게 얻을 수 있는 특정 열에 대한 사용자 지정 변환을 수행해야 할 수도 있습니다. sklearn의 전처리 모듈에서 사용할 수 있는 것과 유사한 표준 스칼라를 정의해 보겠습니다. transform 메서드를 호출하고 사용자 지정 함수를 전달하여 모든 열을 변환할 수 있습니다.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
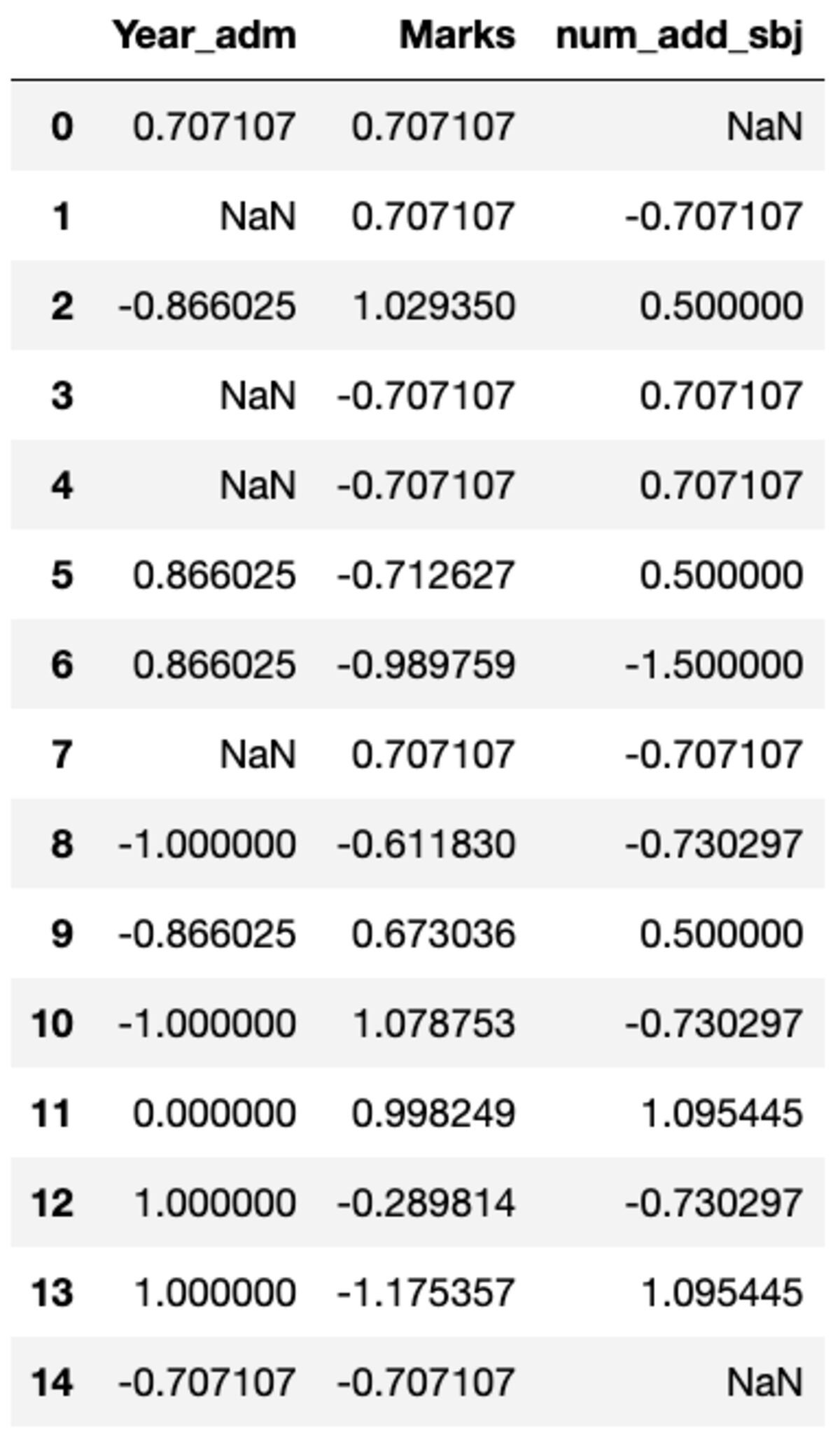
"NaN"은 표준 편차가 XNUMX인 그룹을 나타냅니다.
필터
평균 학생 "점수"가 60 미만인 "전공"이 저조한지 확인하고 싶을 수 있습니다. 내부에 함수가 있는 그룹에 필터 방법을 적용해야 합니다. 아래 코드는 람다 함수 필터링된 결과를 얻기 위해.
groups.filter(lambda x: x['Marks'].mean() 60)

먼저,
색인별로 정렬된 첫 번째 인스턴스를 제공합니다.
groups.first()
설명
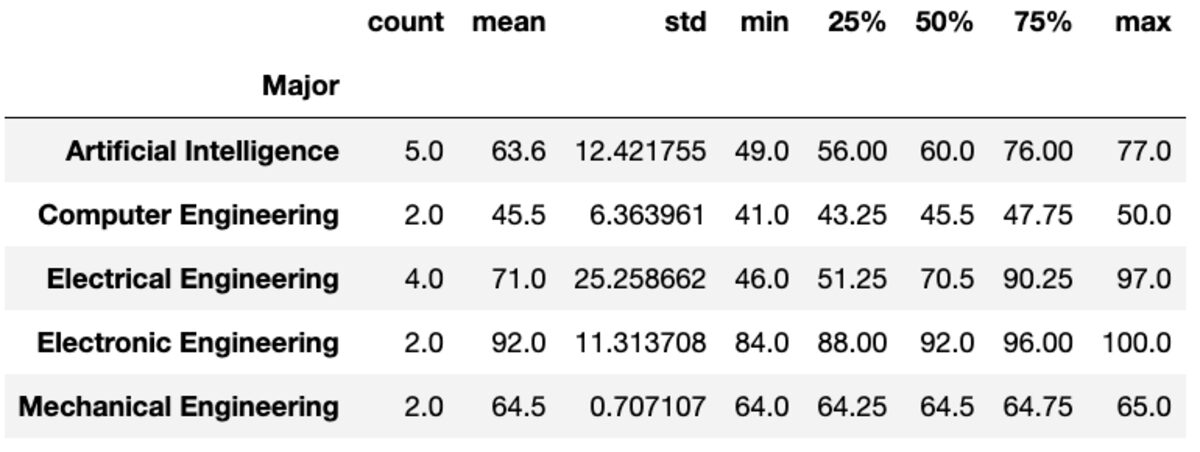
"describe" 메소드는 주어진 열에 대한 count, mean, std, min, max 등과 같은 기본 통계를 반환합니다.
groups['Marks'].describe()
크기
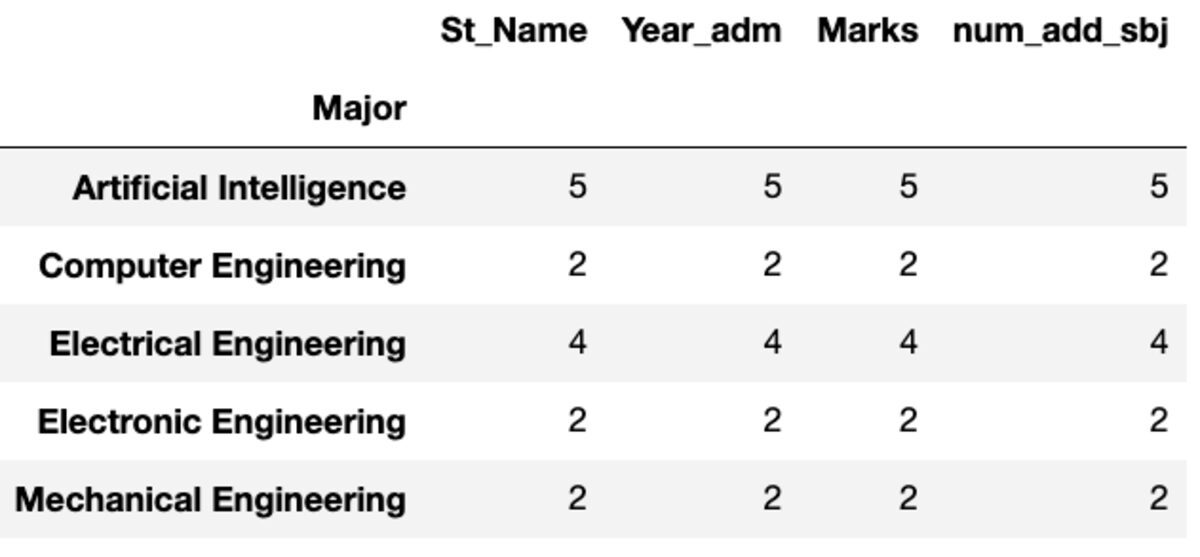
크기는 이름에서 알 수 있듯이 레코드 수 측면에서 각 그룹의 크기를 반환합니다.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64백작과 누니크
"개수"는 모든 값을 반환하는 반면 "Nunique"는 해당 그룹의 고유한 값만 반환합니다.
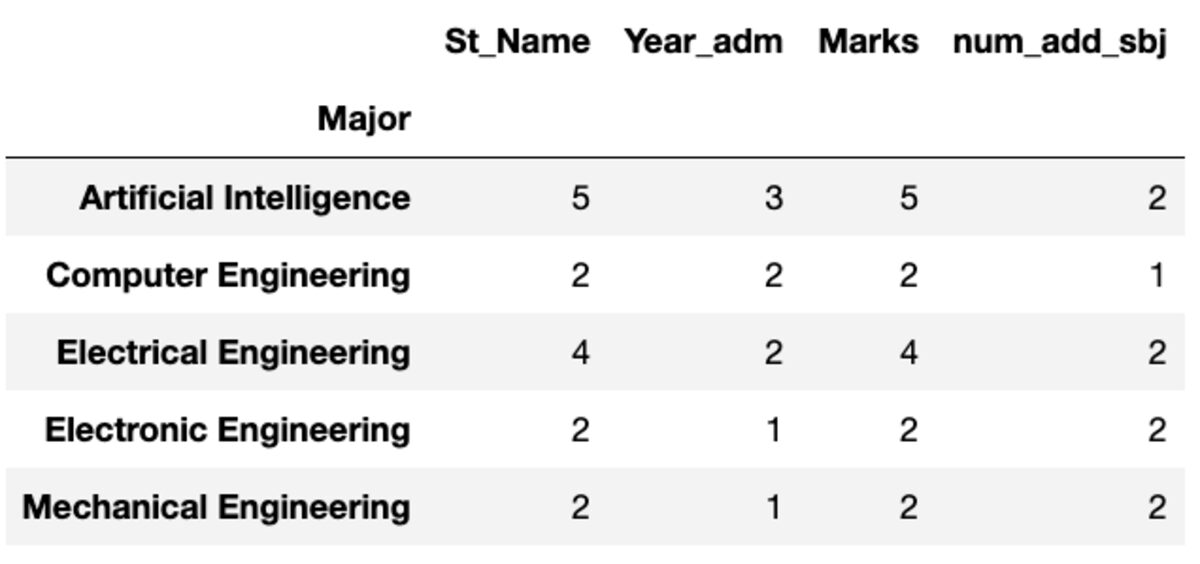
groups.count()
groups.nunique()
이름 바꾸기
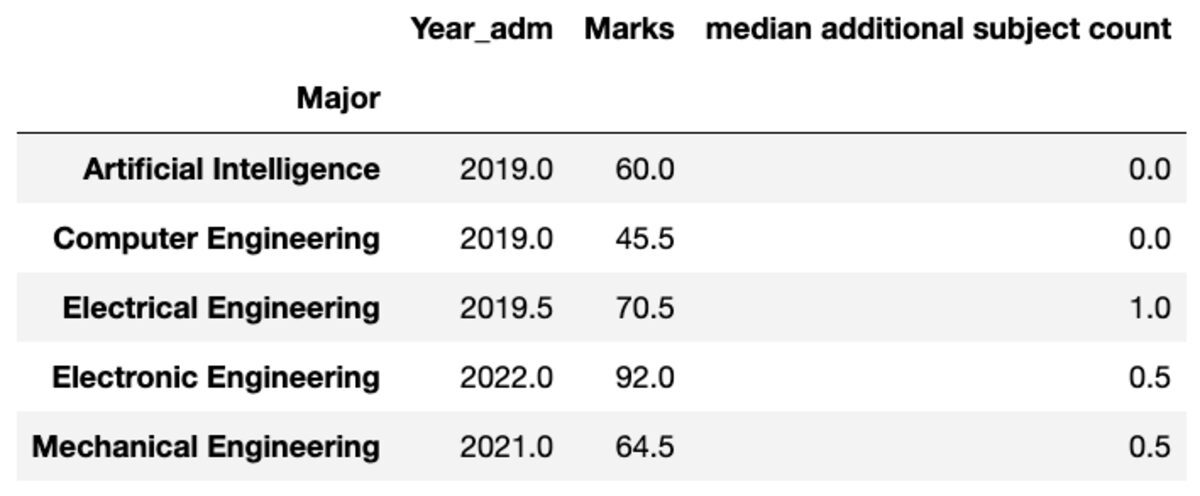
원하는 대로 집계된 열의 이름을 바꿀 수도 있습니다.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- groupby의 목적을 명확히 하십시오. 다른 열의 평균을 얻기 위해 한 열로 데이터를 그룹화하려고 합니까? 또는 각 그룹의 행 수를 얻기 위해 여러 열로 데이터를 그룹화하려고 합니까?
- 데이터 프레임의 인덱싱 이해: groupby 함수는 인덱스를 사용하여 데이터를 그룹화합니다. 열로 데이터를 그룹화하려면 열이 인덱스로 설정되어 있는지 확인하거나 .set_index()를 사용할 수 있습니다.
- 적절한 집계 함수 사용: mean(), sum(), count(), min(), max()와 같은 다양한 집계 함수와 함께 사용할 수 있습니다.
- as_index 매개변수를 사용합니다. False로 설정하면 이 매개변수는 그룹화된 열을 인덱스 대신 일반 열로 사용하도록 pandas에 지시합니다.
또한 pivot_table(), crosstab() 및 cut()과 같은 다른 pandas 함수와 함께 groupby()를 사용하여 데이터에서 더 많은 통찰력을 추출할 수 있습니다.
groupby 함수는 하나 이상의 열을 기반으로 데이터 행을 그룹화한 다음 그룹에서 집계 계산을 수행할 수 있으므로 데이터 분석 및 조작을 위한 강력한 도구입니다. 튜토리얼에서는 코드 예제를 통해 groupby 함수를 사용하는 다양한 방법을 보여주었습니다. 함께 제공되는 다양한 옵션과 데이터 분석에 어떻게 도움이 되는지 이해하는 데 도움이 되기를 바랍니다.
비디 추 확장 가능한 기계 학습 시스템을 구축하기 위해 제품, 과학 및 엔지니어링의 교차점에서 일하는 AI 전략가이자 디지털 혁신 리더입니다. 그녀는 수상 경력이 있는 혁신 리더이자 작가이자 국제 연사입니다. 그녀는 기계 학습을 민주화하고 모든 사람이 이 변화의 일부가 될 수 있도록 전문 용어를 깨는 임무를 수행하고 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby

