
Python은 세계에서 가장 많이 사용되는 프로그래밍 언어 중 하나이며 개발자에게 다양한 라이브러리를 제공합니다.
어쨌든 데이터 조작 및 과학적 계산에 관해서는 일반적으로 다음과 같은 라이브러리를 생각합니다. Numpy, Pandas및 SciPy.
이 기사에서는 관심을 가질 만한 3가지 Python 라이브러리를 소개합니다.
Dask 소개
Dask는 대규모 데이터 처리를 위한 분산 컴퓨팅 및 병렬 처리를 지원하는 유연한 병렬 컴퓨팅 라이브러리입니다.
그렇다면 왜 Dask를 사용해야 할까요? 그들이 말했듯이 그들의 웹사이트:
Python은 데이터 분석과 일반 프로그래밍 모두에서 지배적인 언어로 성장했습니다. 이러한 성장은 NumPy, pandas, scikit-learn과 같은 컴퓨팅 라이브러리에 의해 촉진되었습니다. 그러나 이러한 패키지는 단일 시스템 이상으로 확장되도록 설계되지 않았습니다. Dask는 데이터 세트가 메모리를 초과할 때 기본적으로 이러한 패키지와 주변 생태계를 멀티 코어 시스템 및 분산 클러스터로 확장하기 위해 개발되었습니다.
그래서 Dask의 일반적인 용도 중 하나는 그들이 말하는 것처럼입니다 :
Dask DataFrame은 pandas가 일반적으로 필요한 상황, 일반적으로 데이터 크기 또는 계산 속도로 인해 pandas가 실패하는 경우에 사용됩니다.
– 데이터 세트가 메모리에 맞지 않는 경우에도 대규모 데이터 세트 조작
– 많은 코어를 사용하여 긴 계산 가속화
– 그룹화, 조인 및 시계열 계산과 같은 표준 팬더 작업을 사용하여 대규모 데이터 세트에 대한 분산 컴퓨팅
따라서 Dask는 거대한 Pandas 데이터 프레임을 처리해야 할 때 좋은 선택입니다. 다스크 때문입니다.
사용자가 노트북에서 100GB 이상의 데이터 세트를 조작하거나 워크스테이션에서 1TB 이상의 데이터 세트를 조작할 수 있습니다.
꽤 인상적인 결과입니다.
내부적으로 일어나는 일은 다음과 같습니다.
Dask DataFrames는 색인을 따라 배열된 많은 pandas DataFrames/Series를 조정합니다. Dask DataFrame이 분할됨 행 방향, 효율성을 위해 인덱스 값별로 행을 그룹화합니다. 이러한 팬더 개체는 디스크나 다른 컴퓨터에 있을 수 있습니다.
그래서 우리는 다음과 같은 것을 가지고 있습니다:
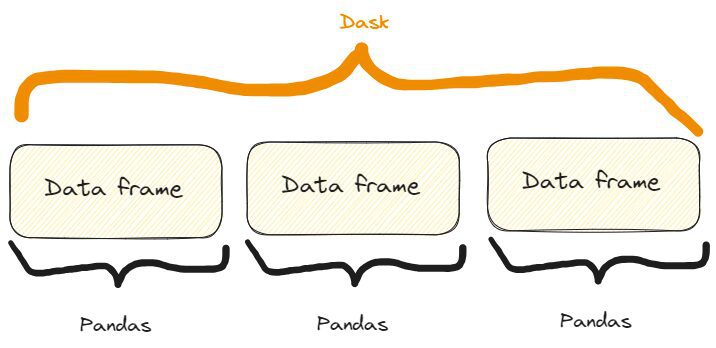
Dask와 Pandas 데이터 프레임의 차이점. 이미 인용된 Dask 웹사이트의 이미지에서 자유롭게 영감을 얻은 저자의 이미지입니다.
Dask의 일부 기능이 작동 중입니다.
우선 Dask를 설치해야 합니다. 우리는 그것을 통해 할 수 있습니다 pip or conda 이렇게 :
$ pip install dask[complete] or $ conda install dask기능 XNUMX: CSV 파일 열기
Dask의 첫 번째 기능은 CSV를 여는 방법입니다. 우리는 다음과 같이 할 수 있습니다:
import dask.dataframe as dd # Load a large CSV file using Dask
df_dask = dd.read_csv('my_very_large_dataset.csv') # Perform operations on the Dask DataFrame
mean_value_dask = df_dask['column_name'].mean().compute()따라서 코드에서 볼 수 있듯이 Dask를 사용하는 방식은 Pandas와 매우 유사합니다. 특히:
- 우리는 방법을 사용합니다
read_csv()정확히 Pandas에서와 같이 - Pandas에서와 똑같이 열을 가로챕니다. 실제로 다음과 같은 Pandas 데이터 프레임이 있다면
df다음과 같은 방법으로 열을 가로챕니다.df['column_name']. - 우리는
mean()메소드를 Pandas와 유사하게 차단된 열에 추가하지만 여기서도 메소드를 추가해야 합니다.compute().
또한 CSV 파일을 여는 방법은 Pandas와 동일하더라도 Dask의 내부에서는 단일 시스템의 메모리 용량을 초과하는 대규모 데이터 세트를 손쉽게 처리하고 있습니다.
즉, Pandas에서는 큰 데이터 프레임을 열 수 없지만 Dask에서는 열 수 있다는 사실을 제외하면 실제 차이점을 볼 수 없습니다.
기능 XNUMX: 머신러닝 워크플로 확장
Dask를 사용하여 엄청난 수의 샘플이 포함된 분류 데이터 세트를 만들 수도 있습니다. 그런 다음 이를 학습 세트와 테스트 세트로 분할하고, 학습 세트를 ML 모델로 맞추고, 테스트 세트에 대한 예측을 계산할 수 있습니다.
우리는 다음과 같이 할 수 있습니다:
import dask_ml.datasets as dask_datasets
from dask_ml.linear_model import LogisticRegression
from dask_ml.model_selection import train_test_split # Load a classification dataset using Dask
X, y = dask_datasets.make_classification(n_samples=100000, chunks=1000) # Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y) # Train a logistic regression model in parallel
model = LogisticRegression()
model.fit(X_train, y_train) # Predict on the test set
y_pred = model.predict(X_test).compute()이 예는 기계 학습 문제가 있는 경우에도 여러 코어에 계산을 분산하여 방대한 데이터 세트를 처리하는 Dask의 기능을 강조합니다.
특히 분류 사례에 대한 "Dask 데이터 세트"를 생성할 수 있습니다. dask_datasets.make_classification(), 그리고 샘플과 청크의 수를 지정할 수 있습니다(심지어 매우 큽니다!).
이전과 유사하게 다음 방법을 사용하여 예측을 얻습니다. compute().
NOTE: in this case, you may need to intsall the module dask_ml. You can do it like so: $ pip install dask_ml기능 XNUMX: 효율적인 이미지 처리
Dask가 활용하는 병렬 처리 능력은 이미지에도 적용될 수 있습니다.
특히 여러 이미지를 열고 크기를 조정하고 크기를 조정하여 저장할 수 있습니다. 다음과 같이 할 수 있습니다.
import dask.array as da
import dask_image.imread
from PIL import Image # Load a collection of images using Dask
images = dask_image.imread.imread('image*.jpg') # Resize the images in parallel
resized_images = da.stack([da.resize(image, (300, 300)) for image in images]) # Compute the result
result = resized_images.compute() # Save the resized images
for i, image in enumerate(result): resized_image = Image.fromarray(image) resized_image.save(f'resized_image_{i}.jpg')프로세스는 다음과 같습니다.
- 다음 메소드를 사용하여 현재 폴더(또는 지정할 수 있는 폴더)에 있는 모든 ".jpg" 이미지를 엽니다.
dask_image.imread.imread("image*.jpg"). - 메서드에서 목록 이해를 사용하여 모두 300×300 크기로 조정합니다.
da.stack(). - 방법으로 결과를 계산합니다.
compute(), 우리가 전에 그랬던 것처럼. - for 주기를 사용하여 크기가 조정된 모든 이미지를 저장합니다.
심피 소개
수학적 계산과 계산이 필요하고 Python을 고수하고 싶다면 Sympy를 사용해 볼 수 있습니다.
실제로, 우리가 사랑하는 Python을 사용할 수 있는데 왜 다른 도구와 소프트웨어를 사용해야 할까요?
그들이 쓰는대로 자신의 웹 사이트에, Sympy는 다음과 같습니다.
기호 수학을 위한 Python 라이브러리입니다. 이해하기 쉽고 쉽게 확장할 수 있도록 코드를 가능한 한 단순하게 유지하면서 완전한 기능을 갖춘 컴퓨터 대수 시스템(CAS)이 되는 것을 목표로 합니다. SymPy는 전적으로 Python으로 작성되었습니다.
그런데 왜 SymPy를 사용하는가? 그들은 다음을 제안합니다:
심파이는…
- 무료: BSD 라이선스를 받은 SymPy는 연설과 맥주 모두에서 무료입니다.
– Python 기반: SymPy는 전적으로 Python으로 작성되었으며 언어로 Python을 사용합니다.
– 경량: SymPy는 임의의 부동 소수점 산술을 위한 순수한 Python 라이브러리인 mpmath에만 의존하므로 사용하기 쉽습니다.
- 도서관: 대화형 도구로 사용하는 것 외에도 SymPy는 다른 응용 프로그램에 내장되고 사용자 정의 기능으로 확장될 수 있습니다.
그래서 기본적으로 Python 중독자들이 사랑할 수 있는 모든 특성을 갖추고 있습니다!
이제 몇 가지 기능을 살펴보겠습니다.
작동 중인 SymPy의 일부 기능
먼저 다음과 같이 설치해야 합니다.
$ pip install sympyPAY ATTENTION: if you write $ pip install simpy you'll install another (completely different!) library. So, the second letter is a "y", not an "i".기능 XNUMX: 대수 방정식 풀기
대수 방정식을 풀어야 한다면 다음과 같이 SymPy를 사용할 수 있습니다.
from sympy import symbols, Eq, solve # Define the symbols
x, y = symbols('x y') # Define the equation
equation = Eq(x**2 + y**2, 25) # Solve the equation
solutions = solve(equation, (x, y)) # Print solution
print(solutions) >>> [(-sqrt(25 - y**2), y), (sqrt(25 - y**2), y)]이것이 프로세스입니다.
- 방법으로 방정식의 기호를 정의합니다.
symbols(). - 우리는 방법으로 대수 방정식을 씁니다.
Eq. - 우리는 방법으로 방정식을 풉니 다
solve().
제가 대학에 있을 때 이런 종류의 문제를 해결하기 위해 다양한 도구를 사용했는데, 보시다시피 SymPy는 매우 읽기 쉽고 사용자 친화적이라고 말하고 싶습니다.
그러나 실제로는 Python 라이브러리이므로 어떻게 다를 수 있습니까?
기능 XNUMX: 파생상품 계산
파생 상품을 계산하는 것은 데이터를 분석할 때 여러 가지 이유로 수학적으로 필요한 또 다른 작업입니다. 종종 어떤 이유로든 계산이 필요할 수 있으며 SympY는 이 프로세스를 실제로 단순화합니다. 실제로 다음과 같이 할 수 있습니다.
from sympy import symbols, diff # Define the symbol
x = symbols('x') # Define the function
f = x**3 + 2*x**2 + 3*x + 4 # Calculate the derivative
derivative = diff(f, x) # Print derivative
print(derivative) >>> 3*x**2 + 4*x + 3따라서 보시다시피 프로세스는 매우 간단하고 설명할 수 있습니다.
- 우리는 파생되는 함수의 기호를 정의합니다.
symbols(). - 우리는 함수를 정의합니다.
- 우리는 다음과 같이 미분을 계산합니다.
diff()도함수를 계산하는 함수와 기호를 지정합니다. (이것은 절대 도함수이지만 다음과 같은 함수의 경우 부분 도함수도 수행할 수 있습니다.x과y변수).
그리고 테스트를 해보면 2~3초 안에 결과가 나오는 것을 볼 수 있습니다. 그래서 속도도 꽤 빠릅니다.
기능 XNUMX: 적분 계산
물론 SymPy가 미분을 계산할 수 있다면 적분도 계산할 수 있습니다. 해보자:
from sympy import symbols, integrate, sin # Define the symbol
x = symbols('x') # Perform symbolic integration
integral = integrate(sin(x), x) # Print integral
print(integral) >>> -cos(x)그래서 여기서는 다음과 같은 방법을 사용합니다. integrate(), 적분할 함수와 적분 변수를 지정합니다.
이보다 더 쉬울 순 없나요?!
Xarray 소개
Xarray는 NumPy의 특징과 기능을 확장하는 Python 라이브러리로 레이블이 지정된 배열 및 데이터 세트로 작업할 수 있는 가능성을 제공합니다.
그들이 말했듯이 자신의 웹 사이트에, 사실은:
Xarray를 사용하면 Python에서 레이블이 지정된 다차원 배열을 간단하고 효율적이며 재미있게 작업할 수 있습니다!
Audiencegain과 또한:
Xarray는 원시 NumPy와 유사한 다차원 배열 위에 차원, 좌표 및 속성 형태의 레이블을 도입하여 보다 직관적이고 간결하며 오류가 덜 발생하는 개발자 환경을 제공합니다.
즉, 배열 크기에 레이블이나 좌표를 추가하여 NumPy 배열의 기능을 확장합니다. 이러한 레이블은 메타데이터를 제공하고 다차원 데이터에 대한 고급 분석 및 조작을 가능하게 합니다.
예를 들어 NumPy에서는 정수 기반 인덱싱을 사용하여 배열에 액세스합니다.
대신 Xarray에서는 각 차원에 관련 레이블이 있을 수 있으므로 의미 있는 이름을 기반으로 데이터를 더 쉽게 이해하고 조작할 수 있습니다.
예를 들어 다음을 사용하여 데이터에 액세스하는 대신 arr[0, 1, 2], 우리는 사용할 수 있습니다 arr.sel(x=0, y=1, z=2) Xarray에서, 여기서 x, y및 z 차원 레이블입니다.
이렇게 하면 코드를 훨씬 더 쉽게 읽을 수 있습니다!
이제 Xarray의 몇 가지 기능을 살펴보겠습니다.
Xarray의 일부 기능 작동
평소와 같이 설치하려면 다음을 수행하십시오.
$ pip install xarray기능 XNUMX: 라벨이 붙은 좌표로 작업하기
온도와 관련된 일부 데이터를 만들고 위도 및 경도와 같은 좌표로 레이블을 지정하려고 한다고 가정합니다. 다음과 같이 할 수 있습니다.
import xarray as xr
import numpy as np # Create temperature data
temperature = np.random.rand(100, 100) * 20 + 10 # Create coordinate arrays for latitude and longitude
latitudes = np.linspace(-90, 90, 100)
longitudes = np.linspace(-180, 180, 100) # Create an Xarray data array with labeled coordinates
da = xr.DataArray( temperature, dims=['latitude', 'longitude'], coords={'latitude': latitudes, 'longitude': longitudes}
) # Access data using labeled coordinates
subset = da.sel(latitude=slice(-45, 45), longitude=slice(-90, 0))그리고 이를 인쇄하면 다음과 같은 결과를 얻습니다.
# Print data
print(subset) >>>
array([[13.45064786, 29.15218061, 14.77363206, ..., 12.00262833, 16.42712411, 15.61353963], [23.47498117, 20.25554247, 14.44056286, ..., 19.04096482, 15.60398491, 24.69535367], [25.48971105, 20.64944534, 21.2263141 , ..., 25.80933737, 16.72629302, 29.48307134], ..., [10.19615833, 17.106716 , 10.79594252, ..., 29.6897709 , 20.68549602, 29.4015482 ], [26.54253304, 14.21939699, 11.085207 , ..., 15.56702191, 19.64285595, 18.03809074], [26.50676351, 15.21217526, 23.63645069, ..., 17.22512125, 13.96942377, 13.93766583]])
Coordinates: * latitude (latitude) float64 -44.55 -42.73 -40.91 ... 40.91 42.73 44.55 * longitude (longitude) float64 -89.09 -85.45 -81.82 ... -9.091 -5.455 -1.818이제 프로세스를 단계별로 살펴보겠습니다.
- NumPy 배열로 온도 값을 생성했습니다.
- 위도와 경도 값을 NumPy 배열로 정의했습니다.
- 메서드를 사용하여 모든 데이터를 Xarray 배열에 저장했습니다.
DataArray(). - 방법으로 위도와 경도의 하위 집합을 선택했습니다.
sel()하위 집합에 대해 원하는 값을 선택합니다.
결과도 쉽게 읽을 수 있으므로 라벨링은 많은 경우에 정말 도움이 됩니다.
기능 XNUMX: 누락된 데이터 처리
연중 온도와 관련된 데이터를 수집한다고 가정합니다. 배열에 null 값이 있는지 알고 싶습니다. 방법은 다음과 같습니다.
import xarray as xr
import numpy as np
import pandas as pd # Create temperature data with missing values
temperature = np.random.rand(365, 50, 50) * 20 + 10
temperature[0:10, :, :] = np.nan # Set the first 10 days as missing values # Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50) # Create an Xarray data array with missing values
da = xr.DataArray( temperature, dims=['time', 'latitude', 'longitude'], coords={'time': times, 'latitude': latitudes, 'longitude': longitudes}
) # Count the number of missing values along the time dimension
missing_count = da.isnull().sum(dim='time') # Print missing values
print(missing_count) >>>
array([[10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], ..., [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0그래서 우리는 10개의 null 값을 갖게 됩니다.
또한 코드를 자세히 살펴보면 다음과 같이 Pandas의 메서드를 Xarray에 적용할 수 있음을 알 수 있습니다. isnull.sum(), 이 경우와 같이 누락된 값의 총 수를 계산합니다.
기능 XNUMX: 다차원 데이터 처리 및 분석
배열에 레이블을 지정할 가능성이 있을 때 다차원 데이터를 처리하고 분석하려는 유혹이 높습니다. 그러니 시도해 보지 않겠습니까?
예를 들어 특정 위도와 경도의 온도와 관련된 데이터를 계속 수집하고 있다고 가정해 보겠습니다.
평균, 최대 및 중간 온도를 계산할 수 있습니다. 다음과 같이 할 수 있습니다.
import xarray as xr
import numpy as np
import pandas as pd # Create synthetic temperature data
temperature = np.random.rand(365, 50, 50) * 20 + 10 # Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50) # Create an Xarray dataset
ds = xr.Dataset( { 'temperature': (['time', 'latitude', 'longitude'], temperature), }, coords={ 'time': times, 'latitude': latitudes, 'longitude': longitudes, }
) # Perform statistical analysis on the temperature data
mean_temperature = ds['temperature'].mean(dim='time')
max_temperature = ds['temperature'].max(dim='time')
min_temperature = ds['temperature'].min(dim='time') # Print values print(f"mean temperature:n {mean_temperature}n")
print(f"max temperature:n {max_temperature}n")
print(f"min temperature:n {min_temperature}n") >>> mean temperature:
array([[19.99931701, 20.36395016, 20.04110699, ..., 19.98811842, 20.08895803, 19.86064693], [19.84016491, 19.87077812, 20.27445405, ..., 19.8071972 , 19.62665953, 19.58231185], [19.63911165, 19.62051976, 19.61247548, ..., 19.85043831, 20.13086891, 19.80267099], ..., [20.18590514, 20.05931149, 20.17133483, ..., 20.52858247, 19.83882433, 20.66808513], [19.56455575, 19.90091128, 20.32566232, ..., 19.88689221, 19.78811145, 19.91205212], [19.82268297, 20.14242279, 19.60842148, ..., 19.68290006, 20.00327294, 19.68955107]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0 max temperature:
array([[29.98465531, 29.97609171, 29.96821276, ..., 29.86639343, 29.95069558, 29.98807808], [29.91802049, 29.92870312, 29.87625447, ..., 29.92519055, 29.9964299 , 29.99792388], [29.96647016, 29.7934891 , 29.89731136, ..., 29.99174546, 29.97267052, 29.96058079], ..., [29.91699117, 29.98920555, 29.83798369, ..., 29.90271746, 29.93747041, 29.97244906], [29.99171911, 29.99051943, 29.92706773, ..., 29.90578739, 29.99433847, 29.94506567], [29.99438621, 29.98798699, 29.97664488, ..., 29.98669576, 29.91296382, 29.93100249]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0 min temperature:
array([[10.0326431 , 10.07666029, 10.02795524, ..., 10.17215336, 10.00264909, 10.05387097], [10.00355858, 10.00610942, 10.02567816, ..., 10.29100316, 10.00861792, 10.16955806], [10.01636216, 10.02856619, 10.00389027, ..., 10.0929342 , 10.01504103, 10.06219179], ..., [10.00477003, 10.0303088 , 10.04494723, ..., 10.05720692, 10.122994 , 10.04947012], [10.00422182, 10.0211205 , 10.00183528, ..., 10.03818058, 10.02632697, 10.06722953], [10.10994581, 10.12445222, 10.03002468, ..., 10.06937041, 10.04924046, 10.00645499]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0그리고 우리는 우리가 원하는 것을 명확하게 읽을 수 있는 방식으로 얻었습니다.
그리고 이전과 마찬가지로 온도의 최대값, 최소값, 평균값을 계산하기 위해 배열에 적용된 Pandas 함수를 사용했습니다.
이 문서에서는 과학적 계산 및 계산을 위한 세 가지 라이브러리를 보여 주었습니다.
SymPy는 다른 도구 및 소프트웨어를 대체할 수 있으므로 Python 코드를 사용하여 수학적 계산을 계산할 수 있는 가능성을 제공하지만 Dask 및 Xarray는 다른 라이브러리의 기능을 확장하여 가장 잘 알려진 다른 Python 라이브러리에 어려움을 겪을 수 있는 상황에서 도움을 줍니다. 데이터 분석 및 조작을 위해.
페데리코 트로타 학교에서 어린 시절부터 글쓰기를 좋아했으며 수업 시험으로 탐정 이야기를 썼습니다. 호기심 덕분에 그는 프로그래밍과 AI를 발견했습니다. 글쓰기에 대한 불타는 열정을 가진 그는 이러한 주제에 대해 글을 쓰기 시작하는 것을 피할 수 없었기 때문에 기술 작가가 되기 위해 경력을 바꾸기로 결정했습니다. 그의 목적은 글쓰기를 통해 Python 프로그래밍, 기계 학습 및 데이터 과학에 대해 사람들을 교육하는 것입니다. 그에 대해 더 알아보기 federicotrotta.com.
실물. 허가를 받아 다시 게시했습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 차트프라임. ChartPrime으로 트레이딩 게임을 향상시키십시오. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/08/beyond-numpy-pandas-unlocking-potential-lesserknown-python-libraries.html?utm_source=rss&utm_medium=rss&utm_campaign=beyond-numpy-and-pandas-unlocking-the-potential-of-lesser-known-python-libraries

