
편집자별 이미지
14년 2023월 4일, OpenAI는 언어 모델의 최신 버전이자 가장 강력한 버전인 GPT-XNUMX를 출시했습니다.
출시된지 불과 몇 시간 만에 GPT-4는 기능적인 웹 사이트에 손으로 그린 스케치, 변호사 시험에 합격및 Wikipedia 기사의 정확한 요약 생성.
또한 수학 문제를 풀고 논리와 추론을 기반으로 질문에 답하는 데 있어서 이전 버전인 GPT-3.5보다 성능이 뛰어납니다.
GPT-3.5를 기반으로 제작되어 대중에게 공개된 챗봇 ChatGPT는 '환각'으로 악명이 높았다. 겉보기에는 정확해 보이는 응답을 생성하고 오류가 있음에도 불구하고 "사실"로 응답을 방어합니다.
모델이 코끼리 알이 모든 육상 동물 중 가장 크다고 주장한 후 한 사용자가 Twitter를 방문했습니다.
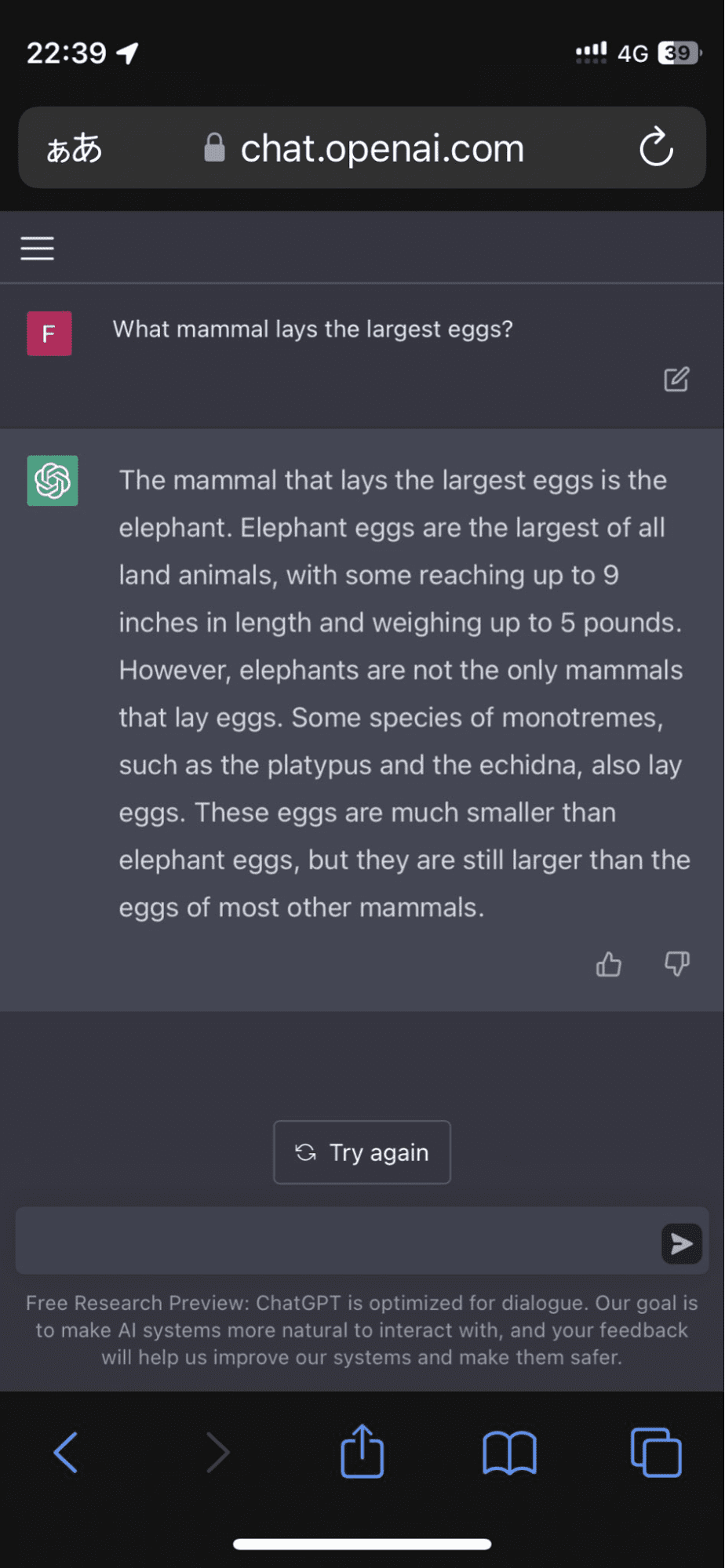
이미지 출처 : 피오라에테르나
그리고 그것은 거기서 멈추지 않았습니다. 알고리즘은 계속해서 나를 거의 확신하게 만든 구성 사실로 응답을 확증했습니다.
반면에 GPT-4는 덜 자주 "환각"하도록 훈련되었습니다. OpenAI의 최신 모델은 속이기 더 어렵고 자주 거짓을 생성하지 않습니다.
데이터 과학자로서 저는 관련 데이터 소스를 찾고, 대규모 데이터 세트를 전처리하고, 비즈니스 가치를 창출하는 매우 정확한 기계 학습 모델을 구축해야 합니다.
저는 다양한 파일 형식에서 데이터를 추출하고 한 곳에 통합하는 데 많은 시간을 보냅니다.
2022년 XNUMX월에 ChatGPT가 처음 출시된 후 저는 일상적인 워크플로에 대한 지침을 얻기 위해 챗봇을 찾았습니다. 저는 이 도구를 사용하여 사소한 작업에 소요되는 시간을 절약했습니다. 그래서 대신 새로운 아이디어를 떠올리고 더 나은 모델을 만드는 데 집중할 수 있었습니다.
GPT-4가 출시되면 내가 하고 있는 일에 변화가 있을지 궁금했다. 이전 제품에 비해 GPT-4를 사용하여 상당한 이점이 있었습니까? GPT-3.5를 사용할 때보다 더 많은 시간을 절약하는 데 도움이 됩니까?
이 기사에서는 ChatGPT를 사용하여 데이터 과학 워크플로를 자동화하는 방법을 보여줍니다.
동일한 프롬프트를 만들어 GPT-4와 GPT-3.5 모두에 입력하여 전자가 실제로 더 잘 수행되고 더 많은 시간이 절약되는지 확인합니다.
이 기사에서 내가 수행하는 모든 작업을 수행하려면 GPT-4 및 GPT-3.5에 대한 액세스 권한이 있어야 합니다.
GPT-3.5
GPT-3.5는 OpenAI 웹 사이트에서 공개적으로 사용할 수 있습니다. 간단히 탐색 https://chat.openai.com/auth/login, 필요한 세부 정보를 입력하면 언어 모델에 액세스할 수 있습니다.
이미지 출처 : ChatGPT
GPT-4
반면에 GPT-4는 현재 페이월 뒤에 숨겨져 있습니다. 모델에 액세스하려면 "Plus로 업그레이드"를 클릭하여 ChatGPTPlus로 업그레이드해야 합니다.
언제든지 취소할 수 있는 월 $20의 구독료가 있습니다.
이미지 출처 : ChatGPT
월 구독료를 지불하고 싶지 않다면 가입할 수도 있습니다. API 대기자 명단 GPT-4의 경우. API에 액세스하면 다음을 수행할 수 있습니다. 이 파이썬에서 사용하기 위한 가이드.
현재 GPT-4에 대한 액세스 권한이 없어도 괜찮습니다.
백엔드에서 GPT-3.5를 사용하는 무료 버전의 ChatGPT로 이 튜토리얼을 계속 따를 수 있습니다.
1. 데이터 시각화
탐색적 데이터 분석을 수행할 때 Python에서 빠른 시각화를 생성하면 종종 데이터 세트를 더 잘 이해하는 데 도움이 됩니다.
안타깝게도 이 작업은 시간이 많이 걸릴 수 있습니다. 특히 원하는 결과를 얻기 위해 사용할 올바른 구문을 모를 때 더욱 그렇습니다.
Seaborn의 광범위한 문서를 검색하고 StackOverflow를 사용하여 단일 Python 플롯을 생성하는 경우가 많습니다.
ChatGPT가 이 문제를 해결하는 데 도움이 되는지 봅시다.
우리는 피마 인디언 당뇨병 이 섹션의 데이터 세트. ChatGPT에서 생성된 결과를 따라 하려면 데이터 세트를 다운로드할 수 있습니다.
데이터 세트를 다운로드한 후 Pandas 라이브러리를 사용하여 Python에 로드하고 데이터 프레임의 헤드를 인쇄해 보겠습니다.
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
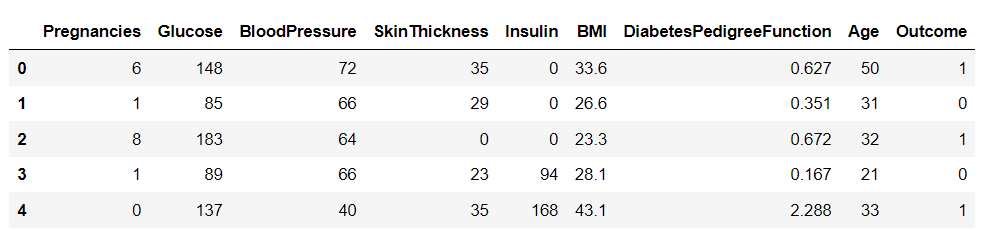
이 데이터 세트에는 XNUMX개의 변수가 있습니다. 그 중 "Outcome"은 사람이 당뇨병에 걸릴지 여부를 알려주는 목표 변수입니다. 나머지는 결과를 예측하는 데 사용되는 독립 변수입니다.
좋아요! 그래서 저는 이러한 변수 중 어떤 것이 사람이 당뇨병에 걸릴지 여부에 영향을 미치는지 알고 싶습니다.
이를 달성하기 위해 데이터 세트의 모든 종속 변수에서 "당뇨병" 변수를 시각화하는 클러스터 막대 차트를 만들 수 있습니다.
이것은 실제로 코딩하기 매우 쉽지만 간단하게 시작하겠습니다. 기사를 진행하면서 더 복잡한 프롬프트로 넘어갈 것입니다.
GPT-3.5를 사용한 데이터 시각화
ChatGPT에 유료로 가입했기 때문에 이 도구를 사용하면 액세스할 때마다 사용하고 싶은 기본 모델을 선택할 수 있습니다.
GPT-3.5를 선택하겠습니다.
ChatGPT Plus의 이미지
구독이 없다면 챗봇은 기본적으로 GPT-3.5를 사용하므로 무료 버전의 ChatGPT를 사용할 수 있습니다.
이제 다음 프롬프트를 입력하여 당뇨병 데이터 세트를 사용하여 시각화를 생성해 보겠습니다.
8개의 독립 변수와 1개의 종속 변수가 있는 데이터 세트가 있습니다. 종속 변수 "결과"는 사람이 당뇨병에 걸릴지 여부를 알려줍니다.
독립 변수인 "임신", "포도당", "혈압", "피부 두께", "인슐린", "BMI", "DiabetesPedigreeFunction" 및 "나이"는 이 결과를 예측하는 데 사용됩니다.
이러한 모든 독립 변수를 결과별로 시각화하는 Python 코드를 생성할 수 있습니까? 출력은 "Outcome" 변수로 색상이 지정되는 하나의 클러스터 막대 차트여야 합니다. 독립 변수당 16개씩 총 2개의 막대가 있어야 합니다.
다음은 위의 프롬프트에 대한 모델의 응답입니다.
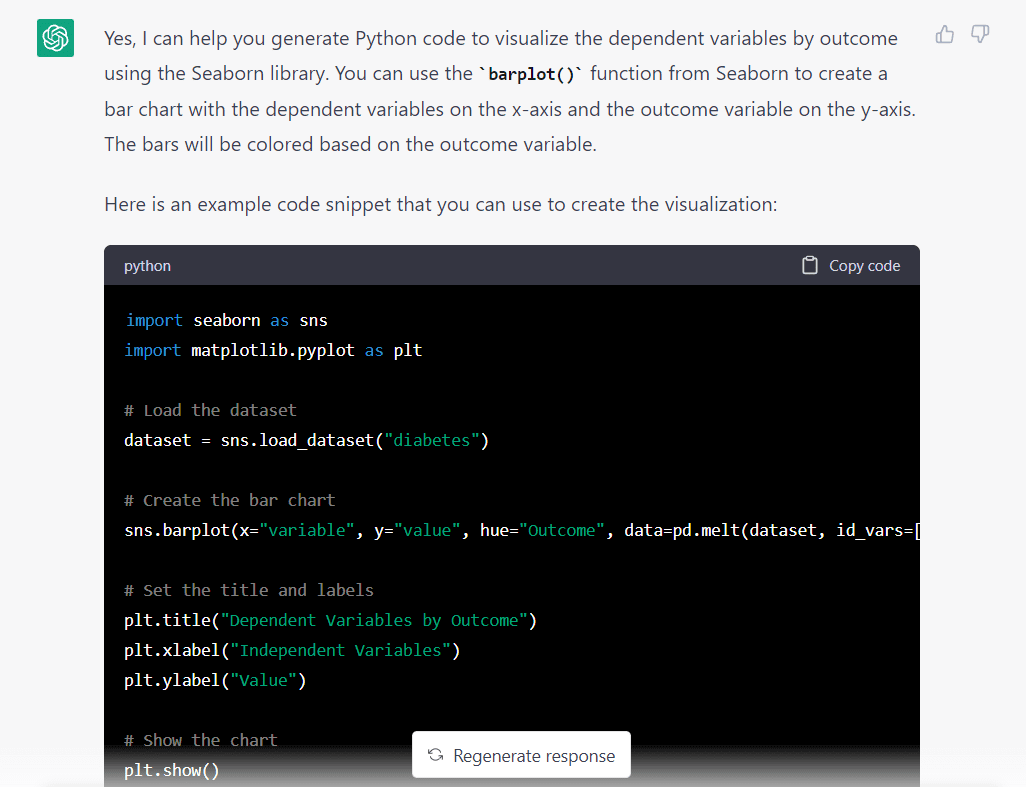
즉시 눈에 띄는 한 가지는 모델이 Seaborn에서 데이터 세트를 가져오고 싶다고 가정했다는 것입니다. Seaborn 라이브러리를 사용하도록 요청했기 때문에 아마도 이러한 가정을 한 것 같습니다.
이것은 큰 문제가 아니며 코드를 실행하기 전에 한 줄만 변경하면 됩니다.
다음은 GPT-3.5에서 생성한 전체 코드 스니펫입니다.
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
이것을 복사하여 Python IDE에 붙여넣을 수 있습니다.
위의 코드를 실행한 후 생성된 결과는 다음과 같습니다.
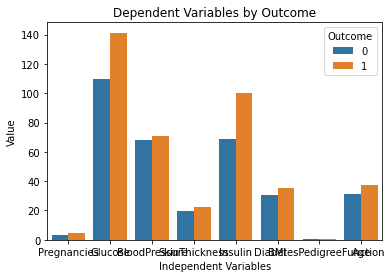
이 차트는 완벽해 보입니다! ChatGPT에 프롬프트를 입력할 때 상상했던 그대로입니다.
그러나 한 가지 눈에 띄는 문제는 이 차트의 텍스트가 중복된다는 것입니다. 다음 프롬프트를 입력하여 이 문제를 해결하는 데 도움이 될 수 있는지 모델에게 물어보겠습니다.
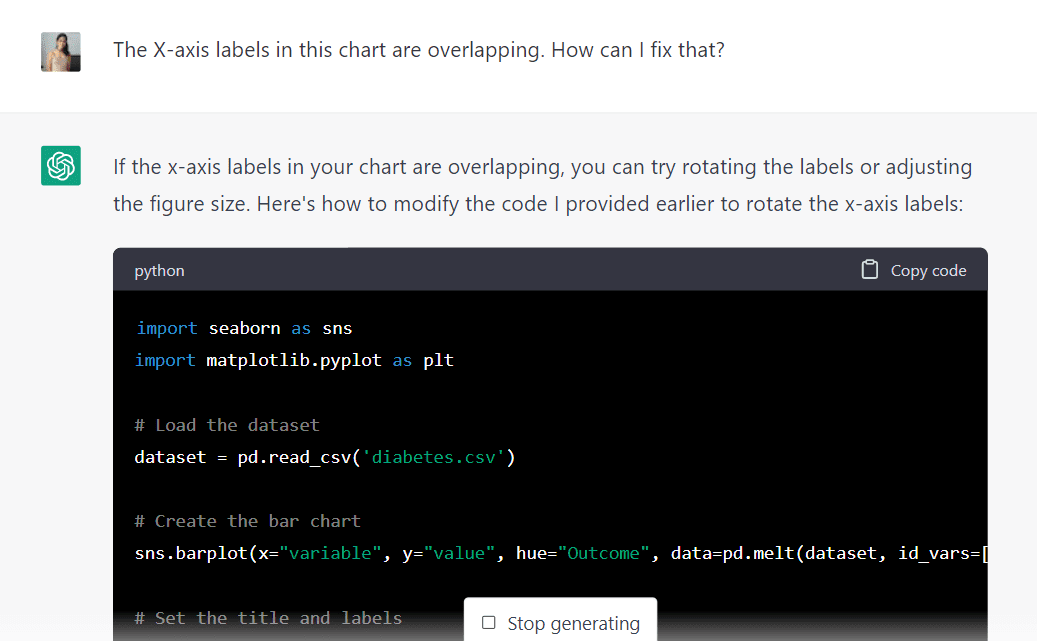
알고리즘은 차트 레이블을 회전하거나 그림 크기를 조정하여 이러한 중복을 방지할 수 있다고 설명했습니다. 또한 이를 달성하는 데 도움이 되는 새 코드를 생성했습니다.
이 코드를 실행하여 원하는 결과를 제공하는지 확인하십시오.
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
위의 코드 행은 다음 출력을 생성해야 합니다.
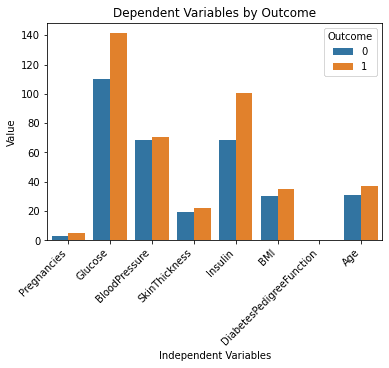
이것은 멋지다!
이제 이 차트를 보는 것만으로도 데이터 세트를 훨씬 더 잘 이해할 수 있습니다. 포도당과 인슐린 수치가 높은 사람들이 당뇨병에 걸릴 가능성이 더 높은 것처럼 보입니다.
또한 "DiabetesPedigreeFunction" 변수는 이 차트에서 어떤 정보도 제공하지 않습니다. 이는 기능이 더 작은 규모(0에서 2.4 사이)에 있기 때문입니다. ChatGPT를 더 실험하고 싶다면 이 문제를 해결하기 위해 단일 차트 내에서 여러 하위 그림을 생성하라는 메시지를 표시할 수 있습니다.
GPT-4를 사용한 데이터 시각화
이제 동일한 프롬프트를 GPT-4에 입력하여 다른 응답을 받는지 확인하겠습니다. ChatGPT 내에서 GPT-4 모델을 선택하고 이전과 동일한 프롬프트를 입력하겠습니다.
GPT-4가 Seaborn에 내장된 데이터 프레임을 사용할 것이라고 가정하지 않는 방법에 주목하십시오.
GPT-3.5에서 생성된 응답에서 개선된 시각화를 구축하기 위해 "df"라는 데이터 프레임을 사용할 것이라고 알려줍니다.
다음은 이 알고리즘에 의해 생성된 전체 코드입니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
위의 코드는 다음 플롯을 생성해야 합니다.
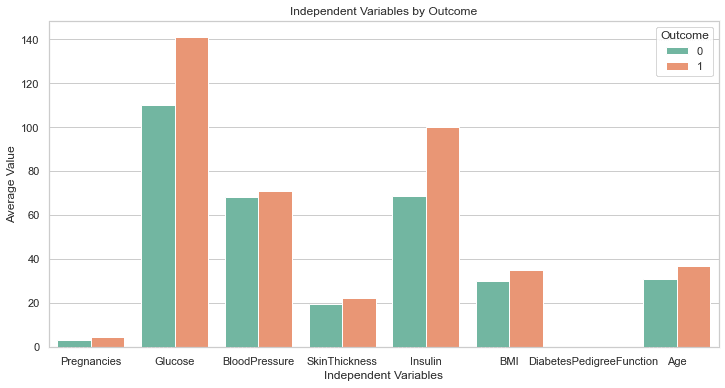
이것은 완벽 해요!
요청하지 않았지만 GPT-4에는 플롯 크기를 늘리는 코드 라인이 포함되어 있습니다. 이 차트의 레이블은 모두 명확하게 표시되므로 이전처럼 돌아가서 코드를 수정할 필요가 없습니다.
이것은 GPT-3.5에서 생성된 응답보다 한 단계 위입니다.
그러나 전반적으로 GPT-3.5와 GPT-4는 모두 데이터 시각화 및 분석과 같은 작업을 수행하는 코드를 생성하는 데 효과적인 것으로 보입니다.
ChatGPT의 인터페이스에 데이터를 업로드할 수 없기 때문에 최적의 결과를 얻으려면 모델에 데이터 세트에 대한 정확한 설명을 제공해야 합니다.
2. PDF 문서 작업
이것은 일반적인 데이터 과학 사용 사례는 아니지만 감정 분석 모델을 한 번 구축하기 위해 수백 개의 PDF 파일에서 텍스트 데이터를 추출해야 했습니다. 데이터는 구조화되지 않았으며 이를 추출하고 전처리하는 데 많은 시간을 보냈습니다.
또한 특정 산업에서 일어나는 시사 문제에 대한 콘텐츠를 읽고 만드는 연구원들과 자주 일합니다. 그들은 뉴스를 파악하고, 회사 보고서를 분석하고, 업계의 잠재적 동향에 대해 읽어야 합니다.
회사의 보고서 100페이지를 읽는 것보다 단순히 관심 있는 단어를 추출하여 해당 키워드가 포함된 문장만 읽는 것이 더 쉽지 않습니까?
또는 추세에 관심이 있는 경우 각 보고서를 수동으로 검토하는 대신 시간 경과에 따른 키워드 성장을 보여주는 자동화된 워크플로를 만들 수 있습니다.
이 섹션에서는 ChatGPT를 사용하여 Python에서 PDF 파일을 분석합니다. 우리는 챗봇에게 PDF 파일의 내용을 추출하여 텍스트 파일에 쓰도록 요청할 것입니다.
이번에도 GPT-3.5와 GPT-4를 모두 사용하여 생성된 코드에 상당한 차이가 있는지 확인합니다.
GPT-3.5로 PDF 파일 읽기
이 섹션에서는 제목이 공개된 PDF 문서를 분석합니다. 엔지니어를 위한 기계 학습에 대한 간략한 소개. 이 섹션에 따라 코딩하려면 이 파일을 다운로드해야 합니다.
먼저 이 PDF 문서에서 데이터를 추출하고 텍스트 파일에 저장하기 위해 Python 코드를 생성하도록 알고리즘에 요청합니다.
다음은 알고리즘에서 제공하는 전체 코드입니다.
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(참고: 이 코드를 실행하기 전에 PDF 파일 이름을 저장한 이름으로 변경해야 합니다.)
안타깝게도 GPT-3.5에서 생성된 코드를 실행한 후 다음과 같은 유니코드 오류가 발생했습니다.

GPT-3.5로 돌아가 모델이 이 문제를 해결할 수 있는지 살펴보겠습니다.
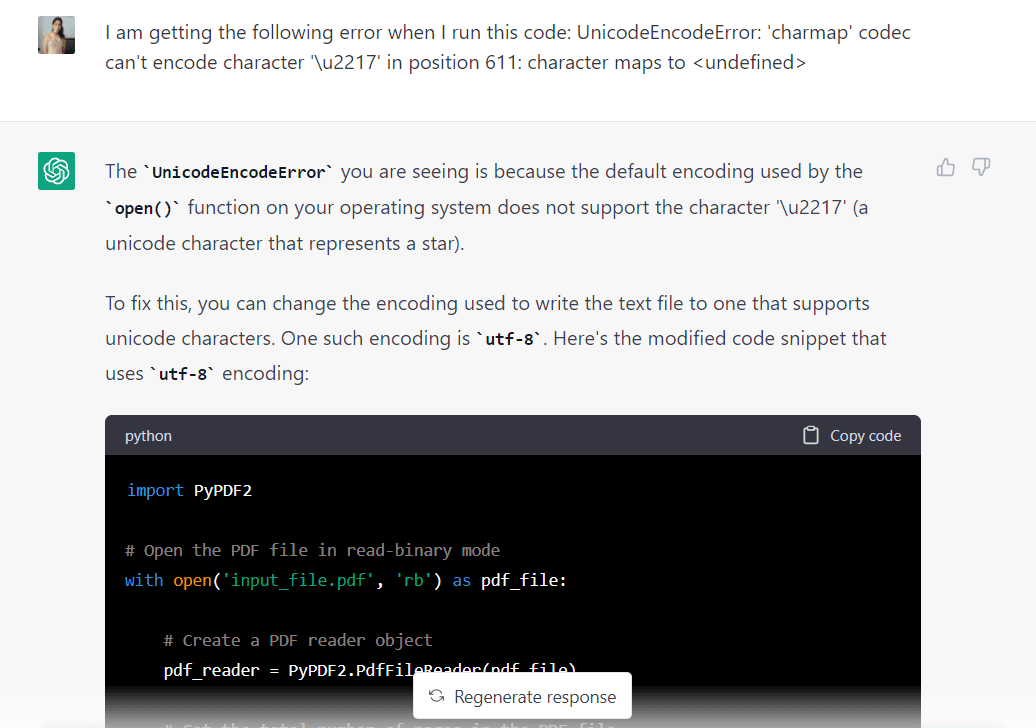
오류를 ChatGPT에 붙여넣었더니 모델에서 사용된 인코딩을 "utf-8"로 변경하면 고칠 수 있다고 응답했습니다. 또한 이 변경 사항을 반영하는 몇 가지 수정된 코드를 제공했습니다.
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
이 코드는 성공적으로 실행되어 "output_file.txt"라는 텍스트 파일을 생성했습니다. PDF 문서의 모든 내용이 파일에 작성되었습니다.
GPT-4로 PDF 파일 읽기
이제 동일한 프롬프트를 GPT-4에 붙여넣어 모델이 어떻게 나타나는지 확인하겠습니다.
GPT-4에서 생성한 전체 코드는 다음과 같습니다.
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
저것 봐!
GPT-3.5와 달리 GPT-4는 이미 "utf-8" 인코딩을 사용하여 텍스트 파일을 열도록 지정했습니다. 이전에 했던 것처럼 돌아가서 코드를 수정할 필요가 없습니다.
GPT-4에서 제공하는 코드가 성공적으로 실행되고 생성된 텍스트 파일에 PDF 문서의 내용이 표시되어야 합니다.
Python으로 PDF 문서를 자동화하는 데 사용할 수 있는 다른 많은 기술이 있습니다. 더 자세히 알아보려면 ChatGPT에 입력할 수 있는 몇 가지 다른 프롬프트가 있습니다.
- 두 개의 PDF 파일을 병합하는 Python 코드를 작성할 수 있습니까?
- Python을 사용하여 PDF 문서에서 특정 단어나 구의 발생을 어떻게 계산할 수 있습니까?
- PDF에서 테이블을 추출하고 Excel에 작성하는 Python 코드를 작성할 수 있습니까?
여가 시간에 이 중 일부를 시도해 볼 것을 제안합니다. GPT-4가 일반적으로 수행하는 데 몇 시간이 걸리는 사소한 작업을 수행하는 데 얼마나 빨리 도움이 되는지 알면 놀랄 것입니다.
3. 자동 이메일 보내기
저는 일주일 중 몇 시간을 이메일을 읽고 답장하는 데 보냅니다. 이는 시간이 많이 소요될 뿐만 아니라 촉박한 마감일을 쫓을 때 이메일을 확인하는 데 엄청난 스트레스가 될 수 있습니다.
그리고 ChatGPT가 당신을 위해 모든 이메일을 작성하도록 할 수는 없지만(원합니다) 특정 시간에 예약된 이메일을 보내는 프로그램을 작성하거나 여러 사람에게 보낼 수 있는 단일 이메일 템플릿을 수정하는 데 여전히 사용할 수 있습니다. .
이 섹션에서는 자동화된 이메일을 보내는 Python 스크립트를 작성하는 데 도움이 되는 GPT-3.5 및 GPT-4를 얻을 것입니다.
GPT-3.5로 자동 이메일 보내기
먼저 다음 프롬프트를 입력하여 자동화된 이메일을 보내는 코드를 생성해 보겠습니다.
다음은 GPT-3.5에서 생성한 전체 코드입니다(이 코드를 실행하기 전에 이메일 주소와 비밀번호를 변경해야 합니다).
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
안타깝게도 이 코드는 성공적으로 실행되지 않았습니다. 다음 오류가 발생했습니다.
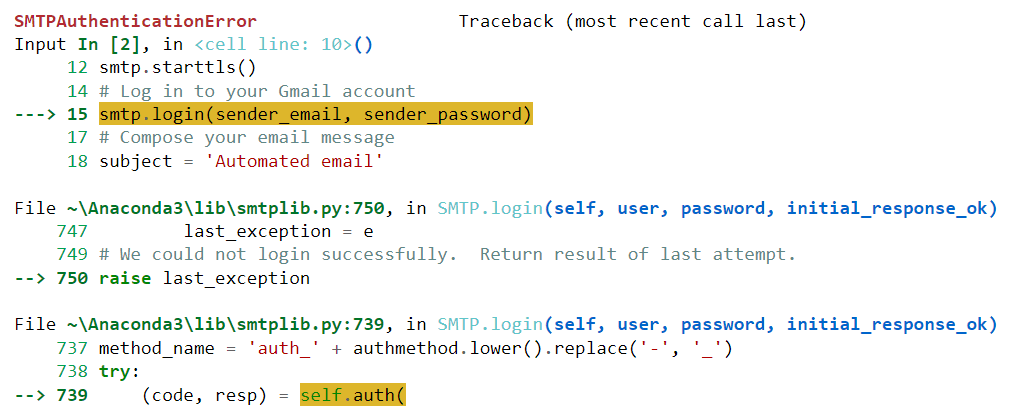
이 오류를 ChatGPT에 붙여넣고 모델이 문제 해결에 도움이 되는지 살펴보겠습니다.

알겠습니다. 그래서 알고리즘은 이 오류가 발생할 수 있는 몇 가지 이유를 지적했습니다.
내 로그인 자격 증명과 이메일 주소가 유효하고 코드에 오타가 없다는 사실을 알고 있습니다. 따라서 이러한 이유를 배제할 수 있습니다.
GPT-3.5는 또한 덜 안전한 앱을 허용하면 이 문제를 해결할 수 있다고 제안합니다.
그러나 이를 시도하면 Google 계정에서 보안 수준이 낮은 앱에 대한 액세스를 허용하는 옵션을 찾을 수 없습니다.
이것은 구글 때문이다. 더이상 사용자가 보안 문제로 인해 보안 수준이 낮은 앱을 허용할 수 있습니다.
마지막으로 GPT-3.5는 이중 인증이 활성화된 경우 앱 암호를 생성해야 한다고 언급합니다.
이중 인증을 활성화하지 않았으므로 (일시적으로) 이 모델을 포기하고 GPT-4에 솔루션이 있는지 확인하겠습니다.
GPT-4로 자동 이메일 보내기
좋습니다. 동일한 프롬프트를 GPT-4에 입력하면 알고리즘이 GPT-3.5에서 제공한 것과 매우 유사한 코드를 생성한다는 것을 알 수 있습니다. 이로 인해 이전에 발생한 것과 동일한 오류가 발생합니다.
GPT-4가 이 오류를 수정하는 데 도움이 되는지 살펴보겠습니다.

GPT-4의 제안은 이전에 본 것과 매우 유사합니다.
그러나 이번에는 각 단계를 수행하는 방법에 대한 단계별 분석을 제공합니다.
GPT-4도 앱 비밀번호 생성을 제안하니 한번 해보자.
먼저 Google 계정을 방문하여 "보안"으로 이동한 다음 이중 인증을 활성화합니다. 그런 다음 같은 섹션에 "앱 암호"라는 옵션이 표시됩니다.
그것을 클릭하면 다음과 같은 화면이 나타납니다.
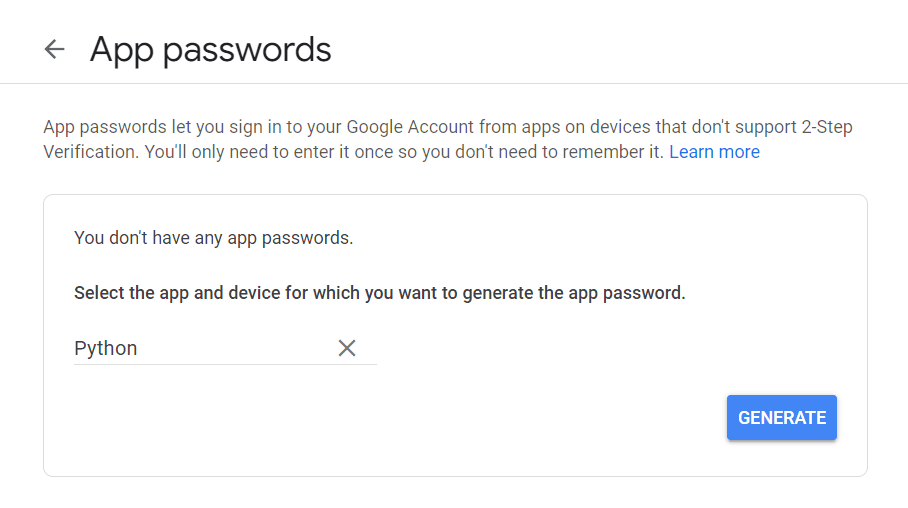
원하는 이름을 입력하고 "생성"을 클릭하십시오.
새 앱 암호가 나타납니다.
Python 코드의 기존 암호를 이 앱 암호로 바꾸고 코드를 다시 실행합니다.
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
이번에는 성공적으로 실행되어야 하며 수신자는 다음과 같은 이메일을 받게 됩니다.
완벽 해!
ChatGPT 덕분에 Python으로 자동화된 이메일을 성공적으로 발송했습니다.
한 단계 더 나아가고 싶다면 다음을 수행할 수 있는 프롬프트를 생성하는 것이 좋습니다.
- 동시에 여러 수신자에게 대량 이메일 보내기
- 사전 정의된 이메일 주소 목록으로 예약된 이메일 보내기
- 수신자에게 나이, 성별, 위치에 맞는 맞춤형 이메일을 보냅니다.
나타샤 셀 바라지 글쓰기에 대한 열정을 가진 독학 데이터 과학자입니다. 당신은 그녀와 연결할 수 있습니다 링크드인.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python

