개요
인공 지능 많은 사용 사례가 있으며 가장 좋은 사례 중 일부는 건강 산업에 있습니다. 이는 사람들이 더 건강한 삶을 유지하는 데 실제로 도움이 될 수 있습니다. 점점 더 붐이 일면서 생성 적 AI, 요즘에는 덜 복잡하게 특정 애플리케이션이 만들어집니다. 구축할 수 있는 매우 유용한 애플리케이션 중 하나는 Calorie Advisor App입니다. 이번 글에서는 건강 관리에 영감을 받아 이것만 살펴보겠습니다. 우리는 음식의 이미지를 입력할 수 있는 간단한 칼로리 조언자 앱을 구축할 것이며, 이 앱은 음식에 존재하는 각 항목의 칼로리를 계산하는 데 도움을 줄 것입니다. 본 프로젝트는 AI를 통한 건강에 초점을 맞춘 NutriGen의 일환입니다.

학습 목표
- 이 기사에서 만들 앱은 기본적인 Prompt 엔지니어링 및 이미지 처리 기술을 기반으로 합니다.
- 우리는 사용 사례에 Google Gemini Pro Vision API를 사용할 것입니다.
- 그런 다음 이미지 처리 및 프롬프트 엔지니어링을 수행하는 코드 구조를 생성합니다. 마지막으로 Streamlit을 사용하여 사용자 인터페이스 작업을 진행하겠습니다.
- 그런 다음 앱을 다음 위치에 배포하겠습니다. 포옹하는 얼굴 무료 플랫폼.
- 또한 Gemini가 음식 항목을 묘사하지 못하고 해당 음식에 대해 잘못된 칼로리 수를 제공하는 출력에서 직면하게 될 몇 가지 문제도 살펴보겠습니다. 또한 이 문제에 대한 다양한 솔루션에 대해서도 논의하겠습니다.
사전 요구 사항
프로젝트 구현부터 시작해 보겠습니다. 그 전에 생성 AI 및 LLM에 대한 기본 이해가 있는지 확인하십시오. 이 문서에서는 처음부터 모든 것을 구현할 것이기 때문에 아는 바가 거의 없어도 괜찮습니다.
필수 Python 프롬프트 엔지니어링을 위해서는 Generative AI에 대한 기본적인 이해와 Google Gemini에 대한 지식이 필요합니다. 추가적으로, 기본적인 지식은 스트림릿, 깃허브및 포옹하는 얼굴 도서관이 필요합니다. 이미지 전처리 목적으로 PIL과 같은 라이브러리에 익숙해지는 것도 도움이 됩니다.
이 기사는 데이터 과학 블로그.
차례
프로젝트 파이프 라인
이 기사에서는 영양사와 개인이 음식 선택에 대해 정보에 입각한 결정을 내리고 건강한 생활 방식을 유지할 수 있도록 지원하는 AI 도우미를 구축하는 작업에 대해 설명합니다.
흐름은 다음과 같습니다: 입력 이미지 -> 이미지 처리 -> 신속한 엔지니어링 -> 음식의 입력 이미지 출력을 얻기 위한 최종 함수 호출. 이것은 우리가 이 문제 진술에 접근하는 방법에 대한 간략한 개요입니다.
Gemini Pro Vision 개요
제미니 프로 다중 모드입니다 LLM Google이 만들었습니다. 처음부터 다중 모드로 훈련되었습니다. 이미지 캡션 작성, 분류, 요약, 질문 답변 등. 이에 대한 흥미로운 사실 중 하나는 유명한 Transformer Decoder Architecture를 사용한다는 것입니다. 여러 종류의 데이터에 대해 훈련되어 다중 모드 입력 해결의 복잡성을 줄이고 고품질 출력을 제공합니다.
1단계: 가상 환경 생성
가상 환경을 만드는 것은 프로젝트와 해당 종속성이 다른 프로젝트와 일치하지 않도록 격리하는 좋은 방법이며, 다양한 가상 환경에서 필요한 라이브러리의 버전이 항상 다를 수 있습니다. 이제 프로젝트를 위한 가상 환경을 만들어 보겠습니다. 이렇게 하려면 아래에 언급된 단계를 따르세요.
- 프로젝트의 바탕 화면에 빈 폴더를 만듭니다.
- VS Code에서 이 폴더를 엽니다.
- 터미널을 엽니 다.
다음 명령을 작성합니다.
pip install virtualenv
python -m venv genai_projectsa et 실행 정책 오류가 발생하는 경우 다음 명령을 사용할 수 있습니다.
Set-ExecutionPolicy RemoteSigned -Scope Process이제 다음 명령을 사용하여 가상 환경을 활성화해야 합니다.
.genai_projectScriptsactivate가상 환경을 성공적으로 만들었습니다.
Google Colab에서 가상 환경 만들기 단계
Google Colab에서 가상 환경을 만들 수도 있습니다. 이를 수행하는 단계별 절차는 다음과 같습니다.
- 새 Colab 노트북 만들기
- 아래 명령을 단계별로 사용하십시오.
!which python
!python --version
#to check if python is installed or not%env PYTHONPATH=
# setting python path environment variable in empty value ensuring that python
# won't search for modules and packages in additional directory. It helps
# in avoiding conflicts or unintended module loading.!pip install virtualenv # create virtual environment
!virtualenv genai_project!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
#This will help download the miniconda installer script which is used to create
# and manage virtual environments in python!chmod +x Miniconda3-latest-Linux-x86_64.sh
# this command is making our mini conda installer script executable within
# the colab environment. !./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
# this is used to run miniconda installer script and
# specify the path where miniconda should be installed!conda install -q -y --prefix /usr/local python=3.8 ujson
#this will help install ujson and python 3.8 installation in our venv.import sys
sys.path.append('/usr/local/lib/python3.8/site-packages/')
#it will allow python to locate and import modules from a venv directoryimport os
os.environ['CONDA_PREFIX'] = '/usr/local/envs/myenv'
# used to activate miniconda enviornment
!python --version
#checks the version of python within the activated miniconda environment그래서 우리는 Google Colab에서 가상 환경도 만들었습니다. 이제 거기에서 기본 .py 파일을 어떻게 만들 수 있는지 확인하고 살펴보겠습니다.
!source myenv/bin/activate
#activating the virtual environment!echo "print('Hello, world!')" >> my_script.py
# writing code using echo and saving this code in my_script.py file!python my_script.py
#running my_script.py file그러면 출력에 Hello World가 인쇄됩니다. 그래서 그게 다입니다. 이것이 바로 Google Colab의 가상 환경 작업에 관한 것입니다. 이제 프로젝트를 계속 진행해 보겠습니다.
2단계: 필요한 라이브러리 가져오기
import streamlit as st
import google.generativeaias genai
import os
from dotenv import load_dotenv
load_dotenv()
from PIL import Image위 라이브러리를 가져오는 데 문제가 있는 경우 언제든지 "pip install library_name" 명령을 사용하여 설치할 수 있습니다.
우리는 기본 사용자 인터페이스를 만들기 위해 Streamlit 라이브러리를 사용하고 있습니다. 사용자는 이미지를 업로드하고 해당 이미지를 기반으로 한 출력을 얻을 수 있습니다.
우리는 Google Generative를 사용하여 LLM을 얻고 이미지를 분석하여 음식의 항목별 칼로리 계산을 얻습니다.
이미지는 몇 가지 기본적인 이미지 전처리를 수행하는 데 사용됩니다.
3단계: API 키 설정
동일한 디렉터리에 새 .env 파일을 만들고 API 키를 저장합니다. 구글을 얻을 수 있다 제미니 API 키에서 Google MakerSuite.
4단계: 응답 생성기 기능
여기서는 응답 생성기 함수를 생성하겠습니다. 단계별로 분석해 보겠습니다.
첫째, 우리는 유전자를 사용했습니다. Google MakerSuite 웹사이트에서 생성한 API를 구성하도록 구성합니다. 그런 다음 입력 프롬프트와 이미지라는 두 가지 입력 매개변수를 사용하는 get_gemini_response 함수를 만들었습니다. 이는 출력을 텍스트로 반환하는 기본 함수입니다.
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
def get_gemini_response(input_prompt, image):
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content([input_prompt, image[0]])
return response여기서는 다중 모드이기 때문에 'Gemini-pro-vision' 모델을 사용하고 있습니다. genie.GenerativeModel 종속성에서 모델을 호출한 후 프롬프트와 이미지 데이터를 모델에 전달하기만 하면 됩니다. 마지막으로, 프롬프트에 제공된 지침과 우리가 제공한 이미지 데이터를 기반으로 모델은 이미지에 있는 다양한 음식 항목의 칼로리 수를 나타내는 텍스트 형식으로 출력을 반환합니다.
5단계: 이미지 전처리
이 함수는 upload_file 매개변수가 None(사용자가 파일을 업로드했음을 의미)인지 확인합니다. 파일이 업로드된 경우 코드는 upload_file 객체의 getvalue() 메서드를 사용하여 파일 내용을 바이트로 읽습니다. 그러면 업로드된 파일의 원시 바이트가 반환됩니다.
업로드된 파일에서 얻은 바이트 데이터는 키-값 쌍 "mime_type" 및 "data" 아래 사전 형식으로 저장됩니다. "mime_type" 키는 콘텐츠 유형(예: image/jpeg, image/png)을 나타내는 업로드된 파일의 MIME 유형을 저장합니다. '데이터' 키는 업로드된 파일의 원시 바이트를 저장합니다.
그런 다음 이미지 데이터는 업로드된 파일의 MIME 유형 및 데이터가 포함된 사전을 포함하는 image_parts라는 목록에 저장됩니다.
def input_image_setup(uploaded_file):
if uploaded_file isnotNone:
#Read the file into bytes
bytes_data = uploaded_file.getvalue()
image_parts = [
{
"mime_type":uploaded_file.type,
"data":bytes_data
}
]
return image_parts
else:
raise FileNotFoundError("No file uploaded")
6단계: UI 만들기
이제 마지막으로 프로젝트의 사용자 인터페이스를 생성할 차례입니다. 앞서 언급했듯이 우리는 Streamlit 라이브러리를 사용하여 프런트 엔드용 코드를 작성할 것입니다.
## initialising the streamlit app
st.set_page_config(page_title="Calories Advisor App")
st.header("Calories Advisor App")
uploaded_file = st.file_uploader("Choose an image...", type=["jpg", "jpeg", "png"])
image = ""
if uploaded_file isnotNone:
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image", use_column_width=True)
submit = st.button("Tell me about the total calories")처음에는 set_page_config를 사용하여 페이지 구성을 설정하고 앱 제목을 지정했습니다. 그런 다음 헤더를 만들고 사용자가 이미지를 업로드할 수 있는 파일 업로더 상자를 추가했습니다. St. Image는 사용자가 UI에 업로드한 이미지를 보여줍니다. 마지막으로 제출 버튼이 있으며, 그 후 대규모 언어 모델인 Gemini Pro Vision의 출력을 얻습니다.
7단계: 시스템 프롬프트 작성
이제 창의력을 발휘할 시간입니다. 여기서는 모델이 전문 영양사 역할을 하도록 요청하는 입력 프롬프트를 만듭니다. 아래 프롬프트를 사용할 필요는 없습니다. 사용자 정의 프롬프트를 제공할 수도 있습니다. 우리는 모델이 지금은 특정 방식으로 작동하도록 요청하고 있습니다. 제공된 음식의 입력 이미지를 기반으로 우리는 모델에 해당 이미지 데이터를 읽고 출력을 생성하도록 요청합니다. 이를 통해 이미지에 있는 음식 항목의 칼로리 수를 제공하고 음식이 건강한지 판단할 수 있습니다. 아니면 건강에 해롭습니다. 음식이 해롭다면 우리는 이미지에 있는 음식에 대해 더 영양가 있는 대안을 제공하도록 요청합니다. 귀하의 필요에 따라 더 많은 것을 맞춤 설정할 수 있으며 귀하의 건강을 추적할 수 있는 훌륭한 방법을 얻을 수 있습니다.
때로는 이미지 데이터를 제대로 읽지 못할 수도 있습니다. 이 기사 마지막 부분에서 이에 대한 해결 방법도 논의하겠습니다.
input_prompt = """
You are an expert nutritionist where you need to see the food items from the
image and calculate the total calories, also give the details of all
the food items with their respective calorie count in the below fomat.
1. Item 1 - no of calories
2. Item 2 - no of calories
----
----
Finally you can also mention whether the food is healthy or not and also mention
the percentage split ratio of carbohydrates, fats, fibers, sugar, protein and
other important things required in our diet. If you find that food is not healthy
then you must provide some alternative healthy food items that user can have
in diet.
"""
if submit:
image_data = input_image_setup(uploaded_file)
response = get_gemini_response(input_prompt, image_data)
st.header("The Response is: ")
st.write(response)마지막으로 사용자가 제출 버튼을 클릭하면 다음에서 이미지 데이터를 가져오는지 확인합니다.
앞에서 만든 input_image_setup 함수입니다. 그런 다음 입력 프롬프트와 이 이미지 데이터를 이전에 생성한 get_gemini_response 함수에 전달합니다. 응답으로 저장된 최종 출력을 얻기 위해 이전에 생성한 모든 함수를 호출합니다.
8단계: Hugging Face에 앱 배포
이제 배포할 시간입니다. 의 시작하자.
우리가 만든 이 앱을 배포하는 가장 간단한 방법을 설명합니다. 앱을 배포하려는 경우 살펴볼 수 있는 두 가지 옵션이 있습니다. 하나는 Streamlit Share이고 다른 하나는 Hugging Face입니다. 여기서는 Hugging Face를 배포에 사용하겠습니다. 원하는 경우 Streamlit Share iFaceu에서 배포를 탐색해 볼 수 있습니다. 이에 대한 참조 링크는 다음과 같습니다. Streamlit Share에 배포
먼저 배포에 필요한 요구사항.txt 파일을 빠르게 생성해 보겠습니다.
터미널을 열고 아래 명령을 실행하여 요구 사항.txt 파일을 만듭니다.
pip freeze > requirements.txt1plainText이렇게 하면 요구사항이라는 새 텍스트 파일이 생성됩니다. 모든 프로젝트 종속성을 여기에서 사용할 수 있습니다. 이로 인해 오류가 발생하더라도 괜찮습니다. 언제든지 작업 디렉터리에 새 텍스트 파일을 만들고 다음에 제공할 GitHub 링크에서 요구사항.txt 파일을 복사하여 붙여넣을 수 있습니다.
이제 다음 파일이 준비되어 있는지 확인하세요(배포에 필요한 파일이기 때문입니다).
- 앱.파이
- .env(API 자격 증명용)
- requirements.txt
없으시면 이 파일들을 모두 가져가서 포옹하는 얼굴에 계정을 만들어주세요. 그런 다음 새 공간을 만들고 거기에 파일을 업로드하세요. 그게 다야. 이러한 방식으로 앱이 자동으로 배포됩니다. 또한 배포가 어떻게 진행되고 있는지 실시간으로 확인할 수 있습니다. 오류가 발생하면 간단한 인터페이스와 포옹하는 얼굴 커뮤니티를 통해 언제든지 문제를 해결할 수 있습니다. 포옹하는 얼굴 커뮤니티에는 배포 중 몇 가지 일반적인 버그를 해결하는 방법에 대한 많은 콘텐츠가 있습니다.
잠시 후 앱이 작동하는 것을 볼 수 있습니다. 우후! 마침내 칼로리 예측 앱을 만들고 배포했습니다. 축하합니다!! 방금 만든 친구 및 가족과 앱의 작업 링크를 공유할 수 있습니다.
방금 만든 앱에 대한 작업 링크는 다음과 같습니다. 앱
입력 이미지를 제공하여 앱을 테스트해 보겠습니다.
전에:
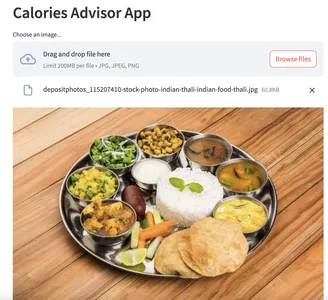
후 :

프로젝트 GitHub 링크 완료
여기에 완전한 github 저장소 링크 여기에는 프로젝트에 관한 소스 코드 및 기타 유용한 정보가 포함됩니다.
저장소를 복제하고 요구 사항에 따라 사용자 정의할 수 있습니다. 프롬프트를 더욱 창의적이고 명확하게 작성하면 모델이 정확하고 적절한 출력을 생성하는 데 더 많은 힘을 실어줄 수 있습니다.
개선 범위
모델과 해당 솔루션에 의해 생성된 출력에서 발생할 수 있는 문제:
때로는 모델에서 올바른 출력을 얻지 못하는 상황이 있을 수 있습니다. 이는 모델이 이미지를 올바르게 예측하지 못했기 때문에 발생할 수 있습니다. 예를 들어, 음식의 입력 이미지를 제공하고 음식 항목에 피클이 포함되어 있는 경우 모델은 이를 다른 것으로 간주할 수 있습니다. 이것이 여기서 주요 관심사입니다.
- 이 문제를 해결하는 한 가지 방법은 모델에 예제를 제공할 수 있는 몇 번의 프롬프트 엔지니어링과 같은 효과적인 프롬프트 엔지니어링 기술을 사용하는 것입니다. 그런 다음 해당 예제에서 학습한 내용과 사용자가 제공한 프롬프트를 기반으로 출력을 생성합니다.
- 여기서 고려할 수 있는 또 다른 솔루션은 사용자 정의 데이터를 생성하고 이를 미세 조정하는 것입니다. 한 열에는 식품 항목의 이미지가 포함되고 다른 열에는 식품 항목에 대한 설명이 포함된 데이터를 생성할 수 있습니다. 이는 모델이 기본 패턴을 학습하고 제공된 이미지에서 항목을 올바르게 예측하는 데 도움이 됩니다. 따라서 음식 사진에 대한 보다 정확한 칼로리 계산 출력을 얻는 것이 필수적입니다.
- 사용자에게 영양 목표에 대해 질문하고 이를 기반으로 출력을 생성하도록 모델에 요청함으로써 더 나아갈 수 있습니다. (이렇게 하면 모델에서 생성된 출력을 맞춤화하고 더 많은 사용자별 출력을 제공할 수 있습니다.)
결론
우리는 Calorie Advisor 앱 제작에 중점을 두고 의료 분야에서 Generative AI의 실제 적용을 탐구했습니다. 이 프로젝트는 개인이 음식 선택에 대해 정보에 입각한 결정을 내리고 건강한 생활 방식을 유지하도록 돕는 AI의 잠재력을 보여줍니다. 환경 설정부터 이미지 처리 및 신속한 엔지니어링 기술 구현까지 필수 단계를 다루었습니다. Hugging Face에 앱을 배포하면 더 많은 사용자에게 앱의 접근성이 입증됩니다. 이미지 인식 부정확성과 같은 문제는 효과적인 프롬프트 엔지니어링과 같은 솔루션을 통해 해결되었습니다. 결론적으로 Calorie Advisor 앱은 웰빙 증진에 있어서 Generative AI의 혁신적인 힘을 보여주는 증거입니다.
주요 요점
- 우리는 지금까지 프로젝트 파이프라인부터 시작하여 대규모 언어 모델 Gemini Pro Vision에 대한 기본 소개에 대해 많은 논의를 했습니다.
- 그런 다음 실습 구현을 시작했습니다. Google MakerSuite에서 가상 환경과 API 키를 만들었습니다.
- 그런 다음 생성된 가상 환경에서 모든 코딩을 수행했습니다. 또한 Hugging Face 및 Streamlit Share와 같은 여러 플랫폼에 앱을 배포하는 방법에 대해서도 논의했습니다.
- 그 외에도 발생할 수 있는 문제에 대해 고려하고, 해당 문제에 대한 해결책을 논의했습니다.
- 그래서 이번 프로젝트 작업은 즐거웠습니다. 이 기사가 끝날 때까지 기다려 주셔서 감사합니다. 나는 당신이 새로운 것을 배웠기를 바랍니다.
자주 묻는 질문
Google은 다중 모드 기능으로 유명한 LLM인 Gemini Pro Vision을 개발했습니다. 이미지 캡션 작성, 생성 및 요약과 같은 작업을 수행합니다. 사용자는 MakerSuite 웹사이트에서 API 키를 생성하여 Gemini Pro Vision에 액세스할 수 있습니다.
A. 제너레이티브 AI는 실제 문제를 해결할 수 있는 많은 잠재력을 가지고 있습니다. 건강/영양 영역에 적용할 수 있는 몇 가지 방법은 의사가 증상에 따라 약을 처방하고 사용자가 자신의 식단에 대한 건강한 권장 사항을 얻을 수 있는 영양 조언자 역할을 하는 데 도움이 될 수 있다는 것입니다.
A. 신속한 엔지니어링은 요즘 꼭 익혀야 할 기술입니다. 기초부터 고급까지 트롬프트 엔지니어링을 배울 수 있는 가장 좋은 곳은 바로 여기 – https://www.promptingguide.ai/
A. 보다 정확한 출력을 생성하는 모델의 능력을 높이기 위해 효과적인 프롬프트, 미세 조정 및 검색 증강 생성(RAG)과 같은 전술을 사용할 수 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/04/how-to-build-a-calorie-advisor-app-using-genai/

