문제 소개
고용은 여러 가지 이유로 포착하기 가장 어려운 시장 부문 중 하나입니다. 채용 단계에서 직면하는 문제 중 하나는 특정 직무 설명에 대한 관련 프로필을 최종 후보에 올리는 것입니다. 이것은 채용 프로세스의 주요 단계 중 하나입니다. 회사는 일반적으로 직업에 대한 수요가 높기 때문에 많은 양의 프로필을 받습니다. 제한된 리소스로 이력서를 수동으로 처리하는 것은 매우 어려운 작업입니다. 수동 개입 없이 작업 설명을 기반으로 관련 프로필을 선정하려면 자동화된 시스템이 필요합니다. 이 기사에서는 직업 및 재개 매칭 문제를 해결하는 다양한 접근 방식에 대해 논의하고 NLP 기술을 사용하여 정확한 솔루션을 구현합니다.
문제 해결을 위한 다양한 접근 방식 이해
문제를 해결하는 가장 간단한 방법 중 하나는 직무 설명의 스킬 세트와 이력서를 직접 비교하는 것입니다. 예를 들어, 직무 기술서에 언급된 기술이 "Support Vector Machine, Python 및 AWS,” 및 이력서에는 “Support Vector Machine, Python 및 AWS” 기술 세트가 있습니다. 이력서와 직업 설명이 완벽하게 일치합니다. "결정 트리, Python 및 AWS" 기술 세트가 있는 또 다른 이력서를 고려해 보겠습니다. 이 접근 방식은 SVM이 의사 결정 트리와 일치하지 않기 때문에 이 프로필을 관련 있는 것으로 반환하지 못합니다. 이 프로필은 SVM 및 의사 결정 트리가 머신 러닝에 포함되기 때문에 관련이 있습니다. 따라서 이력서의 기술과 직무 설명 기술 간의 순진한 교차는 적절한 결과를 제공하지 않습니다.
이 문제를 해결하기 위해 NLP 기반 기술이 제안됩니다. 이제 이에 대해 자세히 논의하겠습니다.
솔루션으로서의 임베딩 기술
워드 임베딩은 대부분의 NLP 기반 솔루션의 기본 단계입니다. 단어 임베딩은 텍스트의 숫자 표현입니다. 단어의 의미론적 의미와 구문론적 의미를 모두 포착합니다. 임베딩이라는 단어를 깊이 이해하려면 아래 기사를 살펴보는 것이 좋습니다.
Word2Vec 및 Doc2Vec은 널리 사용되는 텍스트 임베딩 알고리즘입니다. 둘의 차이점은 word2vec의 경우 단어에 대한 임베딩이 파생되는 반면 doc2vec의 경우 문서에 대한 임베딩이 파생된다는 것입니다. 임베딩 기술을 모두 사용하여 논의된 문제를 해결할 것입니다. 이러한 임베딩이 문제를 어떻게 해결할지 궁금하십니까? 지금 살펴보겠습니다.
워드투벡의 경우,
- 단어 임베딩은 작업 설명에서 각 기술에 대해 파생됩니다.
- 이력서의 각 고유 단어에 대해 단어 임베딩이 파생됩니다.
- 이력서의 각 단어와 기술에 대해 코사인 유사도가 파생됩니다.
- 유사도 > 임계값이면 스킬이 발견됩니다.
Doc2Vec의 경우 이력서와 직무 설명에 대해 단일 임베딩을 얻은 다음 두 임베딩 간에 코사인 유사도를 계산합니다. 일정 임계값보다 큰 경우 이력서는 작업 설명과 관련이 있습니다.
다음 섹션에서는 Doc2Vec 알고리즘의 작동을 이해하고 Doc2Vec을 사용하여 스킬 매칭 알고리즘을 구현합니다.
Doc2Vec의 작동 이해
이름 자체에서 알 수 있듯이 Doc2Vec은 단락/문서의 임베딩을 가져오는 것입니다. 단어 벡터 학습은 문서 벡터 학습 개념에 영감을 줍니다. Doc2Vec 모델을 사용하여 수행할 수 있는 기본 작업 중 일부는 감정 분석, 정보 검색, 문서 유사성 등과 같은 텍스트 분류 작업입니다.
단락 벡터를 학습할 수 있는 두 가지 아키텍처가 사용됩니다.
- PV-DM(단락 벡터 – 분산 메모리) 모델
- PV-DBOW(Paragraph Vector – Distributed Bag of Words) 모델
지금 살펴보겠습니다.
PV-DM(단락 벡터 – 분산 메모리) 모델
PV-DM 모델은 Word2Vec의 CBOW(Continuous Bag of Words) 모델과 유사합니다. 그림 1은 분산 메모리 모델의 기본 아키텍처를 보여줍니다.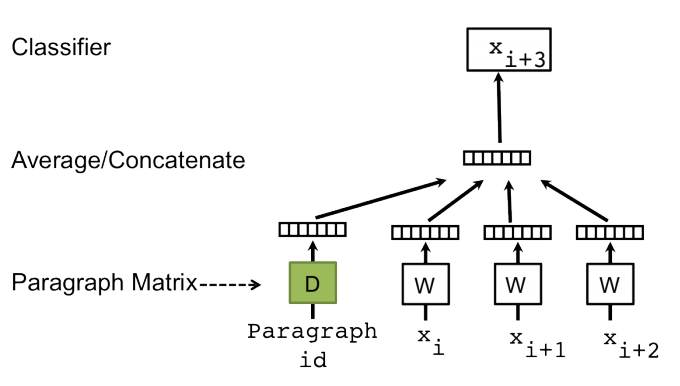
그림 1. 단락 벡터 - 분산 메모리 모델문장의 다음 단어를 예측하는 단어 벡터 학습 작업과 유사하게 단락 벡터는 단락에서 샘플링된 많은 컨텍스트가 주어지면 다음 단어를 예측하여 학습됩니다. 그림 1에 묘사된 단락 벡터에서 단락 벡터는 행렬 D의 열로 표시되는 고유 벡터에 매핑되고 모든 단어는 행렬 W의 열로 표시되는 고유 벡터에 매핑됩니다. 여기서 단락 토큰은 임의로 초기화된 벡터로 간주됩니다. 단락 벡터와 단어 벡터는 최종적으로 평균화되거나 컨텍스트에서 다음 단어를 예측하기 위해 연결됩니다. 역전파 동안 단락 벡터는 다음 단어를 예측하도록 조정됩니다.
PV-DM 모델의 작동을 더 잘 이해하려면 그림 1을 고려하십시오. 단어 x를 입력하면i, Xi + 1, 및 xi + 2 "the", "cat" 및 "sat"인 경우 단어 벡터와 단락 벡터(무작위로 초기화됨)를 연결하면 출력 xi + 3 "켜져" 있을 것입니다. 다음 단어를 예측하는 방법은 역전파를 통해 단락 벡터 ID를 학습하는 데 도움이 됩니다. 이러한 방식으로 단락 벡터는 단락 벡터 분산 메모리 아키텍처에서 학습됩니다.
PV-DBOW(Paragraph Vector – Distributed Bag of Words) 모델
PV-DBOW 모델은 Word2Vec의 Skip-Gram 모델과 유사하게 작동합니다. 그림 2는 PV-DBOW 모델의 아키텍처입니다. Skipgram이 대상 단어가 주어진 컨텍스트 단어 세트를 예측하여 훈련 말뭉치에 있는 벡터 표현을 학습하는 방법과 유사하게 PV-DBOW 모델은 단락 벡터를 입력으로 받아 단락에 존재할 수 있는 단어 세트를 제공합니다. 간접적인 결과로 단어와 단락의 벡터 표현을 학습합니다.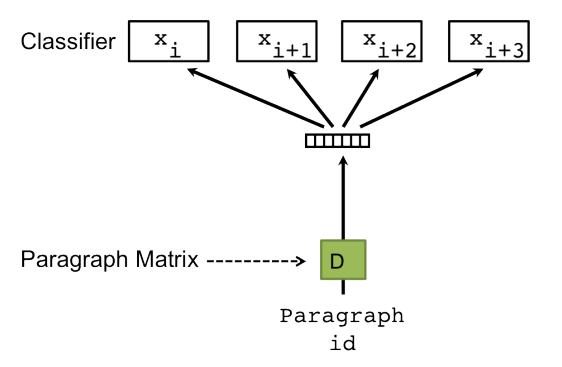
그림 2. 단락 벡터 – 분산된 단어 모음 모델
Doc2Vec을 이용한 Job Resume 매칭 알고리즘 구현
Doc2Vec의 작동 방식과 아키텍처를 이해했으므로 이제 Resume-Job Description 일치 문제에서 Doc2Vec이 구현되는 방식을 살펴보겠습니다. Doc2Vec 모델은 Gensim 라이브러리에서 사용할 수 있으며 구현은 Word2Vec 모델과 동일합니다.
라이브러리 가져오기:
from gensim.models.doc2vec import Doc2Vec, TaggedDocument from nltk.tokenize import word_tokenize from bs4 import BeautifulSoup import pandas as pd import numpy as np import requests import PyPDF2 import re
아이디어는 대규모 블로그 데이터 코퍼스에서 Doc2vec 모델을 훈련시키는 것입니다. 작업을 수행하기 위해 pandas 라이브러리를 사용하여 데이터 세트를 로드합니다. 딸깍 하는 소리 여기에서 지금 확인해 보세요. 샘플 말뭉치에 액세스합니다. 모델은 문제의 맥락에 따라 모든 말뭉치에서 훈련될 수 있습니다.
기사 = pd.read_csv('/content/data.csv') 인쇄(기사.헤드())
출력: 
그런 다음 Gensim 라이브러리에서 사용할 수 있는 TaggedDocument 모듈을 사용하여 데이터에 태그를 지정합니다.
data = list(articles['data']) tagged_data = [TaggedDocument(words = word_tokenize(_d.lower()), tags = [str(i)]) for i, _d in enumerate(data)]
이제 데이터가 필요한 형식으로 되어 있으므로 모델을 초기화하고 어휘를 구축하고 모델을 교육할 차례입니다.
모델 초기화:
Doc2vec 모델은 다음과 같이 초기화됩니다.
모델 = Doc2Vec(vector_size = 50, min_count = 10, epochs = 50 )
관련된 매개변수는 vector_size, min_count, epochs, min_alpha, alpha 등입니다. 매개변수에 대해 자세히 알아봅시다.
- 벡터_크기 – 특징 벡터의 차원.
- min_count – 총 빈도가 이보다 낮은 모든 단어를 무시합니다.
- 신기원 – 말뭉치에 대한 반복(에포크) 수. Doc10Vec의 경우 기본값은 2입니다.
- 알파 - 초기 학습률입니다.
- min_alpha - 학습률은 학습이 진행됨에 따라 선형적으로 min_alpha로 떨어집니다.
- 창문 - 창은 기본 컨텍스트 창 크기를 나타냅니다.
- 디엠 – 학습 알고리즘을 정의합니다. dm = 1이면 분산 메모리(PV-DM) 모델이 사용됩니다. 그렇지 않으면 PV-DBOW(Distributed Bag of Words) 모델이 사용됩니다.
- hs - hs = 1이면 계층적 softmax 활성화 함수가 사용됩니다.
어휘 건물:
모델이 초기화된 후 훈련 말뭉치에서 추출된 모든 고유 단어의 목록인 어휘가 다음과 같이 빌드됩니다.
model.build_vocab(tagged_data) k = model.wv.vocab.keys() 인쇄(len(k))
출력: 15422
우리의 경우 어휘의 크기는 15422입니다. 위의 스크립트를 실행하면 적절한 결과를 얻을 수 있습니다.
모델 교육 :
Doc2Vec 모델은 기본적으로 토큰 목록인 tagged_data, total_examples는 문서 수, epochs는 훈련 코퍼스에 대한 반복 횟수와 같은 매개변수로 훈련됩니다.
model.train(tagged_data, total_examples = model.corpus_count, epochs = model.epochs) model.save('doc2vec.model') print("모델 저장됨")
출력: 모델 저장됨
JD와 이력서 매칭:
모델을 평가하는 데 필요한 데이터는 이력서와 작업 설명입니다. PDF 형식의 이력서 데이터는 PyPDF2 라이브러리를 사용하여 추출됩니다. 딸깍 하는 소리 여기에서 지금 확인해 보세요. 이력서 샘플에 액세스하고 그에 따라 resume_path를 변경합니다.
resume_path = 'resume.pdf' resume = '' pdfReader = PyPDF2.PdfFileReader(resume_path) for i in range(pdfReader.numPages): pageObj = pdfReader.getPage(i) resume += pageObj.extractText()
대소문자를 낮추고 구두점과 숫자를 제거하는 것과 같은 몇 가지 전처리 작업은 regex 라이브러리를 사용하여 수행됩니다.
재개 = resume.lower() 재개 = re.sub('[^az]', ' ', 재개)
다음 단계는 작업 설명을 로드하고 전처리하는 것입니다. 작업 설명 데이터를 얻으려면. Analytics Vidhya 웹 사이트의 작업 설명 링크 중 하나를 선택하고 extract_data 기능을 사용하여 데이터를 스크랩합니다.
def extract_data(url): list1 = [] count = 0 resp = requests.get(url) if resp.status_code == 200: soup = BeautifulSoup(resp.text,'html.parser') l = soup.find(class_ = 'av-company-description-page mb-2') web = ''.join([i.text for i in l.find_all(['p', 'li'])]) list1.append(web) return web else: print("오류")
jd_links = ['https://datahack.analyticsvidhya.com/jobathon/clix-capital/senior-manager-growthrisk-analytics-2', 'https://datahack.analyticsvidhya.com/jobathon/clix-capital/manager- 성장-분석-2', 'https://datahack.analyticsvidhya.com/jobathon/clix-capital/manager-risk-analytics-2', 'https://datahack.analyticsvidhya.com/jobathon/cropin/data- Scientific-85'] jd_df = pd.DataFrame(columns = ['links', 'data']) jd_df['links'] = jd_links 링크에서 JD 데이터 추출: for i in range(len(jd_df)): jd_df['데이터'][i] = extract_data(jd_df['링크'][i])
JD 데이터 전처리:
# 텍스트를 소문자로 변환 jd_df.loc[:,"data"] = jd_df.data.apply(lambda x : str.lower(x)) # 텍스트에서 구두점 제거 jd_df.loc[:,"data" ] = jd_df.data.apply(lambda x : " ".join(re.findall('[w]+',x)) ) #Removing the numerics present in the text jd_df.loc[:,"data"] = jd_df.data.apply(람다 x : re.sub(r'd+','',x))
모델 평가:
따라서 이력서와 작업 설명이 로드되고 전처리됩니다. 이제 이력서와 작업 설명 간의 유사성을 계산해 보겠습니다. 훈련된 doc2vec 모델이 먼저 로드된 다음 토큰 목록이 전달된 개체의 벡터를 제공하는 infer_vector() 함수의 매개 변수로 전송됩니다. v1은 이력서의 벡터이고 v2는 작업 설명의 벡터입니다. 벡터가 있으면 cos(a, b) = ab/||a|| 공식을 사용하여 코사인 유사도를 계산합니다. ||ㄴ||
모델 = Doc2Vec.load('doc2vec.모델') v1 = model.infer_vector(resume.split()) v2 = model.infer_vector(jd['data'][0].split()) cosine_similarity = (np.dot (np.array(v1), np.array(v2))) / (norm(np.array(v1)) * norm(np.array(v2))) print(round(cosine_similarity, 3))
출력: 0.398
결론
이 블로그에서는 직업 기술 일치 알고리즘에 대한 다양한 접근 방식, 즉 기술 세트와 NLP 기술 간의 직접 비교에 대해 논의했습니다. 우리는 doc2vec의 작동 방식과 작업 재개 매칭 알고리즘을 구축하는 데 어떻게 사용할 수 있는지에 대해 자세히 논의했습니다.
이 기사가 도움이 되었기를 바랍니다. 아래 의견란에 귀하의 생각을 알려주십시오. 행복한 학습 🙂
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2022/12/build-accurate-job-resume-matching-algorithm-using-doc2vec/

