개요
운송 및 물류, 음식 및 쇼핑, 결제, 일상용품, 비즈니스, 뉴스 및 엔터테인먼트 등 인도네시아 기업인 Gojek은 이 모든 것을 모바일 앱을 통해 수행하여 경제에 7억 달러 이상을 기여합니다. 900개의 등록된 판매자, 190개 이상의 앱 다운로드, 2분 이내에 180개 이상의 주문을 배달하는 120백만 이상의 드라이버가 있습니다. 그것은 베히모스입니다! 비즈니스 분석을 사용하여 사례 연구를 해결할 것입니다. 다음은 제공하는 20개 이상의 서비스 중 마지막입니다.

- 운송 및 물류
- Go-ride – 당신의 이륜차, 토착 Ojek
- Go-car – 바퀴의 편안함. 앉아서. 잠. 코를 골다.
- Go-send – 몇 시간 안에 패키지를 보내거나 받을 수 있습니다.
- 고박스 – 이사를 가나요? 우리는 가중치를 할 것입니다.
- Go-bluebird – Bluebird와 함께 독점적인 라이딩을 즐겨보세요.
- Go-transit - Gojek 유무에 관계없이 통근 도우미
- 음식 및 쇼핑
- Go-mall – 온라인 마켓플레이스에서 쇼핑하기
- Go-mart - 가까운 매장에서 택배로
- Go-med – 면허가 있는 약국에서 의약품, 비타민 등을 구입합니다.
- 결제 수단
- Go-pay – 지갑을 버리고 무현금화
- Go-bills – 청구서를 빠르고 간단하게 지불
- Paylater – 지금 주문하고 나중에 지불하세요.
- Go-pulsa – 데이터 또는 통화 시간, 이동 중에 충전.
- Go-sure – 소중한 것을 보장하십시오.
- Go-give – 중요한 것을 위해 기부하고 삶을 만져보세요.
- Go-investasi – 현명하게 투자하고 더 잘 절약하십시오.
- 일상적인 필요
- GoFitness를 통해 사용자는 요가, 필라테스, 파운드 핏, 바레, 무에타이 및 줌바와 같은 운동에 액세스할 수 있습니다.
- 근무지에서 발생
- Go-biz – 비즈니스를 운영하고 성장시키는 상인 #SuperApp.
- 뉴스 및 엔터테인먼트
- Go-tix – 쇼를 예약하고 대기열을 건너뜁니다.
- Go-play – 영화 및 시리즈용 앱.
- Go-games – 게임 팁 트렌드 등
- Go-news – 상위 애그리게이터의 주요 뉴스.
이러한 서비스를 통해 생성된 데이터는 방대하며 GO 팀은 일상적인 데이터 엔지니어링 문제를 해결할 수 있는 엔지니어링 솔루션을 보유하고 있습니다. 중앙 분석 및 과학 팀(캐스트)는 Gojek 생태계 내의 여러 제품이 앱 작업과 관련된 풍부한 데이터를 효율적으로 사용할 수 있도록 합니다. 이 팀에는 분석가, 데이터 과학자, 데이터 엔지니어, 비즈니스 분석가 및 의사 결정 과학자가 사내 심층 분석 솔루션 및 기타 ML 시스템을 개발하고 있습니다.
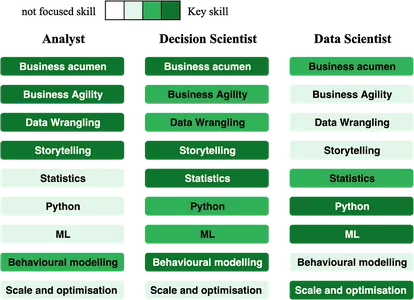
분석가의 역할은 일상적인 비즈니스 문제를 해결하고, 좋은 비즈니스 지식을 갖고, 영향을 미치고, 통찰력을 얻고, RCA(근본 원인 분석)를 도출하고, 최고 경영진에게 미시적 및 거시적 지표와 제품 결정에 대한 정보를 제공하는 데 집중되어 있습니다. 비즈니스 문제를 해결하기 위해.
학습 목표
- 조직이 직면한 성장 동인 및 역풍에 대한 RCA.
- EDA, 슬라이싱 및 다이싱에 Pandas 사용.
- 마케팅 예산 최적화
- 북극성 지표(L0 지표)로서의 이익
- 펄프 솔버를 사용하여 LP를 해결합니다.
- 명확하고 선명한 지침과 함께 Pulps를 사용하여 LP 문제 작성.
- 선형 회귀 및 교차 검증
- 설문지에 제공된 단계를 사용한 간단한 회귀 연습.
이 기사는 데이터 과학 블로그.
차례
문제 정책
제 1 부
GOJEK 이사는 BI 분석가에게 1년 2016분기 동안 발생한 일과 2년 2016분기 수익을 극대화하기 위해 무엇을 해야 하는지 이해하기 위해 데이터를 살펴보도록 요청했습니다.
- 문제 A의 데이터를 고려할 때 집중해야 할 주요 문제는 무엇입니까?
- 표 B의 데이터를 고려할 때 예산이 IDR 40,000,000,000뿐인 경우 어떻게 수익을 극대화할 수 있습니까?
- 경영진 회의를 위해 조사 결과와 구체적인 해결책을 제시하십시오.
파트 II
- 문제 다중 선형 회귀를 사용하여 total_cbv를 예측합니다.
- 각 서비스에 대해 1개의 모델을 만듭니다.
- 예측 기간 = 2016-03-30, 2016-03-31 및 2016-04-01
- 학습 기간 = 사용할 나머지 예측자 목록:
- 날짜
- 달
- 요일
- 주말/주중 플래그(주말=토요일&일요일)
- 사전 처리(이 순서대로 수행):
- GO-TIX 제거
- `Cancelled` order_status만 유지
- 날짜와 서비스의 완전한 조합(데카르트 곱)이 있는지 확인합니다.
- 누락된 값을 0으로 대치
- is_weekend 플래그 예측자 생성(토요일/일요일인 경우 1, 다른 날인 경우 0)
- 원-핫 인코딩 월 및 요일 예측기
- 훈련 기간 데이터의 평균 및 표준 편차만을 사용하여 모든 예측 변수를 z-점수로 표준화
- 평가 지표: MAPE 검증: 3중 체계. 각 검증 접기는 예측 기간과 동일한 길이를 가집니다.
- 질문 1 – 모든 사전 처리 단계 후 서비스 = GO-FOOD, 날짜 = 2016-02-28에 대한 모든 예측 변수의 값은 무엇입니까?
- 질문 2 – one-hot 인코딩된 변수의 처음 6개 행 표시(월 및 요일)
- 질문 3 – 서비스 전처리 후 데이터의 처음 6개 행 인쇄 = GO-KILAT. 날짜순으로 오름차순 정렬
- 질문 4 – 각 서비스에 대한 예측 기간 MAPE를 계산합니다. MAPE를 기준으로 오름차순으로 표시
- 질문 5 – 각 검증 폴드의 성능을 보여주는 그래프를 만드세요. 하나의 그래프 하나의 서비스. x = 날짜, y = total_cbv. 색상: 검은색 = 실제 total_cbv, 다른 색상 = 접기 예측(다른 3가지 색상이 있어야 함). 유효 기간만 표시합니다. 예를 들어 행 11, 12 및 13이 유효성 검사에 사용된 경우 그래프에 다른 행을 표시하지 마십시오. x축에 월과 날짜를 명확하게 표시
파트 III
수라바야의 GO-FOOD 서비스는 지난 달 매우 좋은 성과를 거두었습니다. 지난 달 완료된 주문이 전 달보다 20% 더 많았습니다. 수라바야의 GO-FOOD 관리자는 다음 달에도 이러한 성공을 지속적으로 유지하기 위해 무슨 일이 일어나고 있는지 확인해야 합니다.
- 급격한 성장을 평가하기 위해 어떤 정량적 방법을 사용하시겠습니까? 고객의 행동을 어떻게 평가하시겠습니까?
데이터 세트
- 파트 1
- 2 부 [(링크)]
파트 XNUMX의 솔루션
해결을 시작하기 전에 회사 웹 사이트에 있는 블로그 및 백서를 조사하십시오(링크는 아래에 추가됨). 회사 기록 보관소는 가이드 역할을 하는 유용한 리소스를 제공하고 회사가 상징하는 바 또는 회사가 이 역할에서 기대하는 바를 이해하는 데 도움을 줍니다. 질문 XNUMX과 XNUMX은 개방형 문제로 간주될 수 있습니다. 두 번째 질문은 회귀에 대한 간단한 연습이며 반드시 최상의 모델에 초점을 맞추는 것은 아니지만 초점은 모델 구축과 관련된 프로세스에 있습니다.
조직이 직면한 성장 동인 및 역풍에 관한 RCA
데이터 가져 오기 :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
#import csv sales_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/sales_data_all.csv') print("Shape of the df")
display(sales_df.shape) print("HEAD")
display(sales_df.head()) print("NULL CHECK")
display(sales_df.isnull().any().sum()) print("NULL CHECK")
display(sales_df.isnull().sum()) print("df INFO")
display(sales_df.info()) print("DESCRIBE")
display(sales_df.describe())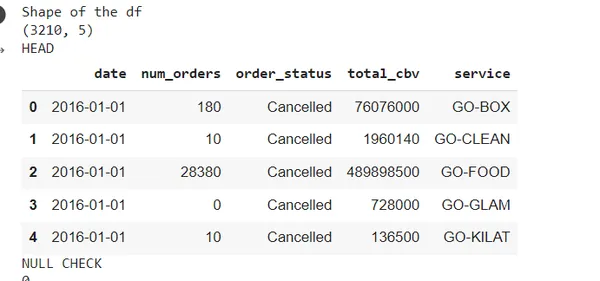
개체 형식에서 pandas datetime을 만듭니다. Pandas datetimes는 날짜로 작업하고 조작하기 쉬운 형식입니다. datetime에서 월 열을 파생합니다. 4월(XNUMX월)도 필터링합니다. 월 이름을 XNUMX월, XNUMX월, XNUMX월로 바꿉니다.
## convert to date time # convert order_status to strinf
## time_to_pandas_time = ["date"] for cols in time_to_pandas_time: sales_df[cols] = pd.to_datetime(sales_df[cols]) sales_df.dtypes sales_df['Month'] = sales_df['date'].dt.month sales_df.head() sales_df['Month'].drop_duplicates() sales_df[sales_df['Month'] !=4] Q1_2016_df = sales_df[sales_df['Month'] !=4] Q1_2016_df['Month'] = np.where(Q1_2016_df['Month'] == 1,"Jan",np.where(Q1_2016_df['Month'] == 2,"Feb",np.where(Q1_2016_df['Month'] == 3,"Mar","Apr"))) print(Q1_2016_df.head(1)) display(Q1_2016_df.order_status.unique()) display(Q1_2016_df.service.unique())
#import csv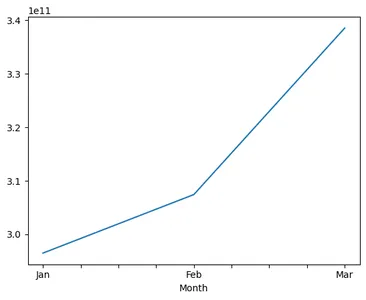

그룹 차원에서 전체 수익은 14% 증가했습니다. 이것은 긍정적인 결과입니다. 이를 다양한 서비스로 분류하고 잘 수행되고 있는 서비스를 식별해 보겠습니다.
revenue_total.sort_values(["Jan"], ascending=[False],inplace=True) revenue_total.head() revenue_total['cummul1'] = revenue_total["Jan"].cumsum()
revenue_total['cummul2'] = revenue_total["Feb"].cumsum()
revenue_total['cummul3'] = revenue_total["Mar"].cumsum() top_95_revenue = revenue_total[revenue_total["cummul3"]<=95 ] display(top_95_revenue)
ninety_five_perc_gmv = list(top_95_revenue.service.unique())
print(ninety_five_perc_gmv) top_95_revenue_plot = top_95_revenue[["Jan", "Feb", "Mar"]]
top_95_revenue_plot.index = top_95_revenue.service
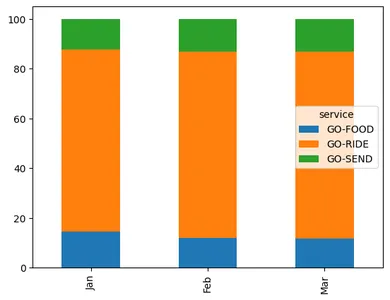
top_95_revenue_plot.T.plot.line(figsize=(5,3)) ## share of revenue is changed but has the overall revenue changed for these top 4 services#import csv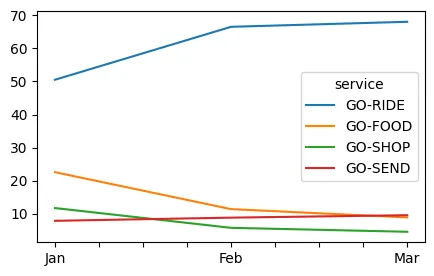

- 90개월 내내 Ride, Food, Shop, Send가 순수익 점유율의 51% 이상을 차지했습니다.(XNUMX월에는 Ride가 순수익의 XNUMX%를 차지했습니다.)
- 따라서 가장 최근 달의 80:20 규칙에 따라 이 분석을 상위 3개 서비스, 즉 Ride, Food, Send로 제한할 수 있습니다.
- 사용 가능한 11개의 서비스 중 3개만이 수익의 90% 이상을 차지합니다. 이것은 우려의 원인이며 나머지 서비스가 성장할 수 있는 엄청난 기회가 있습니다.
완료된 타기
## NET - completed rides
Q1_2016_df_pivot_cbv_4 = Q1_2016_df[Q1_2016_df["order_status"] == "Completed"]
Q1_2016_df_pivot_cbv_4 = Q1_2016_df_pivot_cbv_4[Q1_2016_df_pivot_cbv_4.service.isin(ninety_five_perc_gmv)] Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv_4.pivot_table(index='service', columns=['Month' ], values='total_cbv', aggfunc= 'sum')
# display(Q1_2016_df_pivot_cbv.head())
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv[["Jan", "Feb", "Mar"]] for cols in Q1_2016_df_pivot_cbv.columns: Q1_2016_df_pivot_cbv[cols]=(Q1_2016_df_pivot_cbv[cols]/1000000000) display(Q1_2016_df_pivot_cbv) display(Q1_2016_df_pivot_cbv.T.plot()) ## We see that go shop as reduced its revenue but others the revenue is constant. Q1_2016_df_pivot_cbv_4 = Q1_2016_df_pivot_cbv
Q1_2016_df_pivot_cbv_4.reset_index(inplace = True) Q1_2016_df_pivot_cbv_4["Feb_jan_growth"] = (Q1_2016_df_pivot_cbv_4.Feb / Q1_2016_df_pivot_cbv_4.Jan -1)*100
Q1_2016_df_pivot_cbv_4["Mar_Feb_growth"] = (Q1_2016_df_pivot_cbv_4.Mar / Q1_2016_df_pivot_cbv_4.Feb -1)*100 display(Q1_2016_df_pivot_cbv_4)#import csv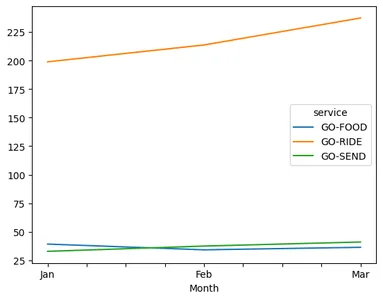

- 수익 창출 엔진인 Ride는 19% 성장한 Send에 비해 25%(XNUMX~XNUMX월) 성장했습니다.
- 비즈니스가 전 세계적으로 성장함에 따라 음식 배달이 7% 감소했으며 이것이 주요 우려 원인입니다.
취소된 탑승(기회 상실)
Q1_2016_df_pivot_cbv = Q1_2016_df[Q1_2016_df["order_status"] != "Completed"]
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv.pivot_table(index='service', columns=['Month' ], values='total_cbv', aggfunc= 'sum')
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv[["Jan", "Feb", "Mar"]] revenue_total = pd.DataFrame() for cols in Q1_2016_df_pivot_cbv.columns: revenue_total[cols]=(Q1_2016_df_pivot_cbv[cols]/Q1_2016_df_pivot_cbv[cols].sum())*100 revenue_total.reset_index(inplace = True)
display(revenue_total.head()) overall_cbv = Q1_2016_df_pivot_cbv.sum()
print(overall_cbv)
overall_cbv.plot()
plt.show() overall_cbv = Q1_2016_df_pivot_cbv.sum()
overall_cbv_df = pd.DataFrame(data = overall_cbv).T
display(overall_cbv_df) overall_cbv_df["Feb_jan_growth"] = (overall_cbv_df.Feb / overall_cbv_df.Jan -1)*100
overall_cbv_df["Mar_Feb_growth"] = (overall_cbv_df.Mar / overall_cbv_df.Feb -1)*100 display(overall_cbv_df) revenue_total.sort_values(["Jan"], ascending=[False],inplace=True) revenue_total.head() revenue_total['cummul1'] = revenue_total["Jan"].cumsum()
revenue_total['cummul2'] = revenue_total["Feb"].cumsum()
revenue_total['cummul3'] = revenue_total["Mar"].cumsum() top_95_revenue = revenue_total[revenue_total["cummul3"]<=95 ] display(top_95_revenue)
ninety_five_perc_gmv = list(top_95_revenue.service.unique())
print(ninety_five_perc_gmv)
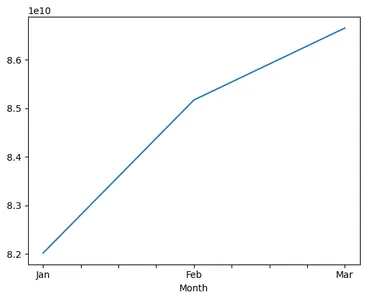

- 손실된 수익은 6% 증가했습니다.
- 이사는 이를 5% 미만으로 줄이기 위한 노력을 높일 수 있습니다.
주문 분석
Q1_2016_df_can_com = Q1_2016_df[Q1_2016_df.order_status.isin(["Cancelled", "Completed"])]
Q1_2016_df_can_com = Q1_2016_df_can_com[Q1_2016_df_can_com.service.isin(ninety_five_perc_gmv)] Q1_2016_df_pivot = Q1_2016_df_can_com.pivot_table(index='service', columns=['order_status','Month' ], values='num_orders', aggfunc= 'sum')
Q1_2016_df_pivot.fillna(0, inplace = True) multi_tuples =[ ('Cancelled', 'Jan'), ('Cancelled', 'Feb'), ('Cancelled', 'Mar'), ('Completed', 'Jan'), ('Completed', 'Feb'), ('Completed', 'Mar')] multi_cols = pd.MultiIndex.from_tuples(multi_tuples, names=['Experiment', 'Lead Time']) Q1_2016_df_pivot = pd.DataFrame(Q1_2016_df_pivot, columns=multi_cols) display(Q1_2016_df_pivot.columns)
display(Q1_2016_df_pivot.head(3)) Q1_2016_df_pivot.columns = ['_'.join(col) for col in Q1_2016_df_pivot.columns.values] display(Q1_2016_df_pivot)
#import csv Q1_2016_df_pivot["jan_total"] = Q1_2016_df_pivot.Cancelled_Jan + Q1_2016_df_pivot.Completed_Jan
Q1_2016_df_pivot["feb_total"] = Q1_2016_df_pivot.Cancelled_Feb + Q1_2016_df_pivot.Completed_Feb
Q1_2016_df_pivot["mar_total"] = Q1_2016_df_pivot.Cancelled_Mar + Q1_2016_df_pivot.Completed_Mar Q1_2016_df_pivot[ "Cancelled_Jan_ratio" ] =Q1_2016_df_pivot.Cancelled_Jan/Q1_2016_df_pivot.jan_total
Q1_2016_df_pivot[ "Cancelled_Feb_ratio" ]=Q1_2016_df_pivot.Cancelled_Feb/Q1_2016_df_pivot.feb_total
Q1_2016_df_pivot[ "Cancelled_Mar_ratio" ]=Q1_2016_df_pivot.Cancelled_Mar/Q1_2016_df_pivot.mar_total
Q1_2016_df_pivot[ "Completed_Jan_ratio" ]=Q1_2016_df_pivot.Completed_Jan/Q1_2016_df_pivot.jan_total
Q1_2016_df_pivot[ "Completed_Feb_ratio" ]=Q1_2016_df_pivot.Completed_Feb/Q1_2016_df_pivot.feb_total
Q1_2016_df_pivot[ "Completed_Mar_ratio" ] =Q1_2016_df_pivot.Completed_Mar/Q1_2016_df_pivot.mar_total Q1_2016_df_pivot_1 = Q1_2016_df_pivot[["Cancelled_Jan_ratio"
,"Cancelled_Feb_ratio"
,"Cancelled_Mar_ratio"
,"Completed_Jan_ratio"
,"Completed_Feb_ratio"
,"Completed_Mar_ratio"]] Q1_2016_df_pivot_1
- 17월에는 Food, Ride, Send가 각각 총 주문의 15%, 13%, XNUMX%를 취소했습니다.
- 푸드는 주문 완료율이 69월 83%에서 XNUMX월 XNUMX%로 높아졌다. 이것은 상당한 개선입니다.
## column wise cancellation check if increased
perc_of_cols_orders = pd.DataFrame() for cols in Q1_2016_df_pivot.columns: perc_of_cols_orders[cols]=(Q1_2016_df_pivot[cols]/Q1_2016_df_pivot[cols].sum())*100 perc_of_cols_orders perc_of_cols_cbv.T.plot(kind='bar', stacked=True)
perc_of_cols_orders.T.plot(kind='bar', stacked=True)
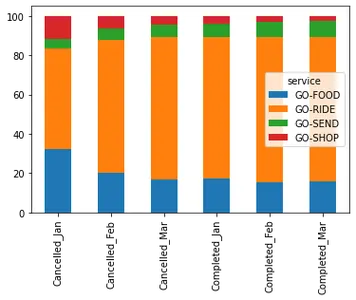

- 72월에 취소된 모든 놀이기구 중 Ride는 주문의 17%를 차지했으며, Food(6%)와 Send(XNUMX%)가 그 뒤를 이었습니다.
비즈니스 분석에 대한 조사 결과 및 권장 사항 요약

- 라이드 –
- 수익의 최고 기여자.
- 42월 취소(GMV)는 XNUMX% 증가했습니다.
- 제품 개입 및 새로운 제품 기능을 통해 취소를 줄입니다.
- 음식 -
- 취소된 주문이 증가했지만 비용 최적화로 인해 GMV 손실이 성공적으로 억제되었습니다.
- 비용과 취소를 줄임으로써 순수익을 높입니다.
- 더 높은 고객 확보를 유도합니다.
- 보내다 -
- 취소된 GMV 및 주문은 모두 타격을 입었고 우려의 주요 원인입니다.
- 좋은 라이딩 완료 경험으로 유지율을 높이고 유지율을 통해 수익 성장을 촉진합니다.
예산 지출을 최적화하여 이익 극대화
비즈니스 팀은 40분기에 2억의 예산을 가지고 있으며 각 서비스에 대한 성장 목표를 설정했습니다. 각 서비스에 대해 100회 증가 비용과 2분기 최대 성장 목표는 다음과 같습니다. Go-Box의 경우 100건의 추가 예약을 얻으려면 40천만 달러의 비용이 들고 2분기 최대 성장 목표는 7%입니다.

예산 데이터를 가져오고 위의 분석에서 판매 데이터를 사용합니다.
budget_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/optimization_budge.csv') print("Shape of the df")
display(budget_df.shape) print("HEAD")
display(budget_df.head()) print("NULL CHECK")
display(budget_df.isnull().any().sum()) print("NULL CHECK")
display(budget_df.isnull().sum()) print("df INFO")
display(budget_df.info()) print("DESCRIBE")
display(budget_df.describe()) ## convert to date time # convert order_status to string
## time_to_pandas_time = ["date"] for cols in time_to_pandas_time: sales_df[cols] = pd.to_datetime(sales_df[cols]) sales_df.dtypes sales_df['Month'] = sales_df['date'].dt.month sales_df.head() sales_df['Month'].drop_duplicates() sales_df_q1 = sales_df[sales_df['Month'] !=4]
## Assumptions
sales_df_q1 = sales_df_q1[sales_df_q1["order_status"] == "Completed"] # Q1_2016_df_pivot = Q1_2016_df.pivot_table(index='service', columns=['order_status','Month' ], values='num_orders', aggfunc= 'sum') sales_df_q1_pivot = sales_df_q1.pivot_table(index='service', columns=['order_status'], values='total_cbv', aggfunc= 'sum')
sales_df_q1_pivot_orders = sales_df_q1.pivot_table(index='service', columns=['order_status'], values='num_orders', aggfunc= 'sum') sales_df_q1_pivot.reset_index(inplace = True)
sales_df_q1_pivot.columns = ["Service","Q1_revenue_completed"]
sales_df_q1_pivot sales_df_q1_pivot_orders.reset_index(inplace = True)
sales_df_q1_pivot_orders.columns = ["Service","Q1_order_completed"] optimization_Df = pd.merge( sales_df_q1_pivot, budget_df, how="left", on="Service", ) optimization_Df = pd.merge( optimization_Df, sales_df_q1_pivot_orders, how="left", on="Service", ) optimization_Df.columns = ["Service", "Q1_revenue_completed", "Cost_per_100_inc_booking", "max_q2_growth_rate","Q1_order_completed"]
optimization_Df.head(5)
#import csv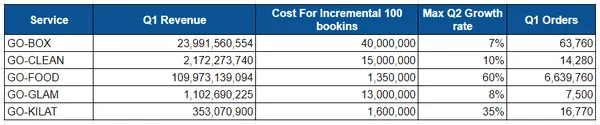
- Box의 경우 1분기 수익은 23억, 100회 추가 승차 비용은 40천만, 최대 예상 성장률은 7%이며 총 63회의 승차는 주문당 370회 완료되었습니다.
40B의 가용 예산으로 모든 서비스에 대해 최대 성장률을 달성할 수 있습니까?
## If all service max growth is to be achived what is the budget needed? and whats the deficiet?
optimization_Df["max_q2_growth_rate_upd"] = optimization_Df['max_q2_growth_rate'].str.extract('(d+)').astype(int) ## extract int from string
optimization_Df["max_growth_q2_cbv"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.max_q2_growth_rate_upd/100)) ## Q2 max orders based on Q1 orders
optimization_Df["abs_inc_orders"] = optimization_Df.max_growth_q2_cbv-optimization_Df.Q1_order_completed ## Total increase in orders optimization_Df["cost_of_max_inc_q2_order"] = optimization_Df.abs_inc_orders * optimization_Df.Cost_per_100_inc_booking /100 ## Total Cost to get maximum growth for each serivce display(optimization_Df) display(budget_df[budget_df["Service"] == "Budget:"].reset_index())
budget_max = budget_df[budget_df["Service"] == "Budget:"].reset_index()
budget_max = budget_max.iloc[:,2:3].values[0][0]
print("Budget difference by")
display(budget_max-optimization_Df.cost_of_max_inc_q2_order.sum() ) ## Therefore max of the everything cannot be achieved#import csv답은 모든 서비스의 성장 목표를 달성하기 위해 247B(247,244,617,204) 더 많은 예산이 필요하다는 것입니다.
10B의 가용 예산으로 모든 서비스에 대해 최대 성장률의 40% 이상을 달성할 수 있습니까?
## Then what is the budget needed and what will the extra budget at hand??
optimization_Df["min_10_max_growth_q2_cbv"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.max_q2_growth_rate_upd/1000)) ## atleast 10% of max if achieved, this is orders optimization_Df["min_10_abs_inc_orders"] = optimization_Df.min_10_max_growth_q2_cbv-optimization_Df.Q1_order_completed ## what is the increase in orders needed to achieve 10% orders growth
optimization_Df["min_10_cost_of_max_inc_q2_order"] = optimization_Df.min_10_abs_inc_orders * optimization_Df.Cost_per_100_inc_booking /100 ## Cost associatedfor 10% increase in orders display(budget_max-optimization_Df.min_10_cost_of_max_inc_q2_order.sum() ) ## Total budget remaining display((budget_max-optimization_Df.min_10_cost_of_max_inc_q2_order.sum())/budget_max) ## Budget utilization percentage optimization_Df["perc_min_10_max_growth_q2_cbv"] =( ( optimization_Df.max_q2_growth_rate_upd/1000)) ## atleast 10% of max if achieved, 7 to percent divide by 100, 10% of this number. divide by 10, so 1000
optimization_Df["perc_max_growth_q2_cbv"] =( ( optimization_Df.max_q2_growth_rate_upd/100)) ## Max growth to be achieved optimization_Df["q1_aov"] = optimization_Df.Q1_revenue_completed/optimization_Df.Q1_order_completed ## Q1 average order value
optimization_Df["order_profitability"] = 0.1 ## this is assumption that 10% will be profit optimization_Df["a_orders_Q2"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.perc_min_10_max_growth_q2_cbv)) ## based on 10% growth, total new orders for qc optimization_Df["a_abs_inc_orders"] = optimization_Df.a_orders_Q2-optimization_Df.Q1_order_completed optimization_Df["a_Q2_costs"] = optimization_Df.Cost_per_100_inc_booking* optimization_Df.a_abs_inc_orders/100 ##There is scope for improvement here, so This can be adjusted based on revenue or ranking from Q1
display(budget_max - optimization_Df.a_Q2_costs.sum()) optimization_Df#import csv답은 예입니다. 사용 가능한 28억 예산의 40%만으로 이를 달성할 수 있습니다. 사용 가능한 예산을 충분히 활용하지 않는 것은 결코 선택 사항이 아니며 어떤 비즈니스 리더도 사용 가능한 예산의 28%만 사용하지 않을 것입니다.
따라서 모든 서비스에서 최대 성장률을 달성할 수 없으며 최대 성장률의 10%를 달성하면 예산이 충분히 활용되지 않습니다. 따라서 여기서 필요한 것은 다음과 같이 지출을 최적화하는 것입니다.
- 전체 현금 소진은 40B를 넘지 않습니다.
- 서비스 전반의 2분기 전체 성장률은 최대 성장률과 같거나 그 이하입니다.
- 선형 최적화에는 제약 조건이라는 것이 있습니다.
- 목표는 이익을 극대화하는 것입니다.
여기에 사용된 가정:
- 모든 서비스에는 10%의 이익이 있습니다.
- AOV(수익/주문)는 1분기와 동일하게 유지됩니다.
사전 최적화 데이터 파이프라인:
## Data prep for pulp optimization
perc_all_df = pd.DataFrame(data = list(range(1,optimization_Df.max_q2_growth_rate_upd.max()+1)), columns = ["growth_perc"]) ## create a list of all percentage growth, from 1 to max to growth expected, this is to create simulation for optimization
display(perc_all_df.head(1)) optimization_Df_2 = optimization_Df.merge(perc_all_df, how = "cross") ## cross join with opti DF ## Filter and keeping all percentgaes upto maximum for each service
## Minimum percentage kept is 1
optimization_Df_2["filter_flag"] = np.where(optimization_Df_2.max_q2_growth_rate_upd >= (optimization_Df_2.growth_perc),1,0)
optimization_Df_2["abs_profit"] = (optimization_Df_2.q1_aov)*(optimization_Df_2.order_profitability)
optimization_Df_3 = optimization_Df_2[optimization_Df_2["filter_flag"] == 1] display(optimization_Df_3.head(1))
display(optimization_Df_3.columns) ## Filter columns needed
optimization_Df_4 = optimization_Df_3[[ 'Service', ## services offered 'Cost_per_100_inc_booking', ## cost of additional 100 orders 'Q1_order_completed', ## to calculate q2 growth based on q1 orders 'perc_min_10_max_growth_q2_cbv', ## minimum growth percent need 'perc_max_growth_q2_cbv', ## max growth percent allowed 'abs_profit', ## profit per order 'growth_perc' ## to simulative growth percet across ]] display(optimization_Df_4.head(2)) optimization_Df_4["orders_Q2"] = (optimization_Df_4.Q1_order_completed *(1+ optimization_Df_4.growth_perc/100)) ## based on growth, total new orders for qc
optimization_Df_4["abs_inc_orders"] = optimization_Df_4.orders_Q2-optimization_Df_4.Q1_order_completed
optimization_Df_4["profit_Q2_cbv"] = optimization_Df_4.orders_Q2 * optimization_Df_4.abs_profit
optimization_Df_4["growth_perc"] = optimization_Df_4.growth_perc/100
optimization_Df_4["Q2_costs"] = optimization_Df_4.Cost_per_100_inc_booking* optimization_Df_4.abs_inc_orders/100 display(optimization_Df_4.head()) optimization_Df_5 = optimization_Df_4[[ 'Service', ## services offered 'Q2_costs', ## cost total for the growth expected 'perc_min_10_max_growth_q2_cbv', ## minimum growth percent need 'perc_max_growth_q2_cbv', ## max growth percent allowed 'profit_Q2_cbv', ## total profit at the assumed order_profitability rate 'growth_perc' ## to simulative growth percet across ]] optimization_Df_5 display(optimization_Df_5.head(10))
display(optimization_Df_5.shape)
최적화 데이터 세트 이해
- 서비스 – Go 제품.
- 최대 성장의 10%는 각 서비스가 달성해야 하는 최소 성장입니다. 따라서 Box는 최소한 0.7%의 성장을 달성해야 합니다.
- 이것은 제약 조건입니다.
- Box의 비즈니스 리더가 결정한 최대 성장률은 7%입니다.
- 이것은 제약 조건입니다.
- Box의 경우 1%에서 7%가 성장의 범위입니다. 1%는 0.7% 이상이고 7%가 최대입니다. 옵티마이저는 제약 조건에 따라 최상의 성장률을 선택합니다.
- 이것은 결정 변수입니다. 알고리즘은 7개 중 하나를 선택합니다.
- 1% 성장(Incremental)의 경우 현금 소진은 255억 XNUMX만입니다.
- 이것은 제약 조건입니다.
- 증분 성장이 1%이면 전체 이익(유기적 + 무기적)은 2.4억입니다.
- 이것이 목표입니다.
## Best optimization for our case case. This is good. prob = LpProblem("growth_maximize", LpMaximize) ## Initialize optimization problem - Maximization problem optimization_Df_5.reset_index(inplace = True, drop = True) markdowns = list(optimization_Df_5['growth_perc'].unique()) ## List of all growth percentages
cost_v = list(optimization_Df_5['Q2_costs']) ## List of all incremental cost to achieve the growth % needed perc_min_10_max_growth_q2_cbv = list(optimization_Df_5['perc_min_10_max_growth_q2_cbv'])
growth_perc = list(optimization_Df_5['growth_perc']) ## lp variables
low = LpVariable.dicts("l_", perc_min_10_max_growth_q2_cbv, lowBound = 0, cat = "Continuous")
growth = LpVariable.dicts("g_", growth_perc, lowBound = 0, cat = "Continuous")
delta = LpVariable.dicts ("d", markdowns, 0, 1, LpBinary)
x = LpVariable.dicts ("x", range(0, len(optimization_Df_5)), 0, 1, LpBinary) ## objective function - Maximise profit, column name - profit_Q2_cbv
## Assign value for each of the rows -
## For all rows in the table each row will be assidned x_0, x_1, x_2 etc etc
## This is later used to filter the optimal growth percent prob += lpSum(x[i] * optimization_Df_5.loc[i, 'profit_Q2_cbv'] for i in range(0, len(optimization_Df_5))) ## one unique growth percentahe for each service
## Constraint one for i in optimization_Df_5['Service'].unique(): prob += lpSum([x[idx] for idx in optimization_Df_5[(optimization_Df_5['Service'] == i) ].index]) == 1 ## Do not cross total budget
## Constraint two
prob += (lpSum(x[i] * optimization_Df_5.loc[i, 'Q2_costs'] for i in range(0, len(optimization_Df_5))) - budget_max) <= 0 ## constraint to say minimum should be achived
for i in range(0, len(optimization_Df_5)): prob += lpSum(x[i] * optimization_Df_5.loc[i, 'growth_perc'] ) >= lpSum(x[i] * optimization_Df_5.loc[i, 'perc_min_10_max_growth_q2_cbv'] ) prob.writeLP('markdown_problem') ## Write Problem name
prob.solve() ## Solve Problem
display(LpStatus[prob.status]) ## Problem status - Optimal, if problem solved successfully
display(value(prob.objective)) ## Objective, in this case what is the maximized profit with availble budget - 98731060158.842 @ 10% profit per order #import csv
print(prob)
print(growth)LP 문제를 작성하는 방법을 이해하는 것이 문제 해결의 열쇠입니다.
- 문제 초기화
- prob = LpProblem("성장_최대화", Lp최대화)
- growth_maximize는 문제의 이름입니다.
- LpMaximize는 최대화 문제임을 솔버에게 알리고 있습니다.
- 결정 함수의 변수 생성
- growth = LpVariable.dicts("g_", growth_perc, lowBound = 0, cat = "Continuous")
- Pulp의 경우 펄프 dicts를 만들어야 합니다.
- g_는 변수의 접두어입니다.
- growth_perc는 목록의 이름입니다.
- 하한은 최소 성장률이며 0부터 시작할 수 있습니다.
- 변수는 연속적입니다.
- 60%(최소)에서 1%(최대)까지 60가지의 고유한 증가율이 있습니다. (음식의 최대 성장률은 60%입니다.)
- 변수 - 0 <= x_0 <= 1 정수 행을 위해 0 ~ 0 <= x_279 <= 1 정수 행 279.
- 문제에 목적 함수 추가
- prob += lpSum(x[i] * optimization_Df_5.loc[i, 'profit_Q2_cbv'] for i in range(0, len(optimization_Df_5)))
- 펄프 -> 2423147615.954*x_0 + 2447139176.5080004*x_1 + 225916468.96*x_3+ … + 8576395.965000002*x_279. 데이터 세트에는 280개의 행이 있으므로 각 이익 값에 대해 변수가 생성됩니다.
- 제약 조건 추가:
- XNUMX – 각 서비스에 대한 XNUMX% 성장
- for i in optimization_Df_5['Service'].unique(): prob += lpSum([x[idx] for idx in optimization_Df_5[(optimization_Df_5['Service'] == i) ].index]) == 1
- 각 서비스에 대해 하나의 증가율만 선택합니다.
- Box는 1~7개 중 하나만 선택합니다.
- 상자 – _C1의 방정식: x_0 + x_1 + x_2 + x_3 + x_4 + x_5 + x_6 = 1
- GLAM – _C2의 방정식: x_10 + x_11 + x_12 + x_13 + x_14 + x_15 + x_16 + x_7 + x_8 + x_9 = 1
- 11개의 서비스가 있으므로 각 서비스에 대해 하나씩 11개의 제약 조건이 생성됩니다.
- 40 – 총 예산 XNUMX억을 넘지 않음
- prob += (lpSum(x[i] * optimization_Df_5.loc[i, ‘Q2_costs’] for i inrange(0, len(optimization_Df_5))) – budget_max) <= 0
- 모든 비용의 합계에서 총 예산을 뺀 값은 XNUMX보다 작거나 같아야 합니다.
- 방정식 _C12: 255040000 x_0 + 510080000 x_1 + … + 16604 x_279 <= 0
- _C12: 총 예산이 40억이고 각 서비스가 지출할 수 있는 금액에 대한 제약이 없기 때문에 여기서 유일한 제약입니다.
- XNUMX – 최소값을 달성해야 한다는 제약 조건
- for i in range(0, len(optimization_Df_5)): prob += lpSum(x[i] * optimization_Df_5.loc[i, 'growth_perc'] ) >= lpSum(x[i] * optimization_Df_5.loc[i, ' perc_min_10_max_growth_q2_cbv'] )
- 각 행에 대해 최소 성장률 제약 조건 방정식이 생성됩니다. 279개의 행이 있으므로 279개의 제약 조건이 생성됩니다.
- _C13: 0.003 x_0 >= 0 행 0에서 _C292까지: 0.315 x_279 >= 0에서 행 279.
- "최적의'”는 원하는 출력입니다.
- 디스플레이(LpStatus[prob.status])
- 98731060158.842 최대 이익이다.
- 디스플레이(값(prob.objective))
- XNUMX – 각 서비스에 대한 XNUMX% 성장
var_name = []
var_values = []
for variable in prob.variables(): if 'x' in variable.name: var_name.append(variable.name) var_values.append(variable.varValue) results = pd.DataFrame() results['variable_name'] = var_name
results['variable_values'] = var_values
results['variable_name_1'] = results['variable_name'].apply(lambda x: x.split('_')[0])
results['variable_name_2'] = results['variable_name'].apply(lambda x: x.split('_')[1])
results['variable_name_2'] = results['variable_name_2'].astype(int)
results.sort_values(by='variable_name_2', inplace=True)
results.drop(columns=['variable_name_1', 'variable_name_2'], inplace=True)
results.reset_index(inplace=True)
results.drop(columns='index', axis=1, inplace=True) # results.head() optimization_Df_5['variable_name'] = results['variable_name'].copy()
optimization_Df_5['variable_values'] = results['variable_values'].copy()
optimization_Df_5['variable_values'] = optimization_Df_5['variable_values'].astype(int)# optimization_Df_6.head() #import csv## with no budget contraint
optimization_Df_10 = optimization_Df_5[optimization_Df_5['variable_values'] == 1].reset_index() optimization_Df_10["flag"] = np.where(optimization_Df_10.growth_perc >= optimization_Df_10.perc_min_10_max_growth_q2_cbv,1,0) display(optimization_Df_10) display(budget_max - optimization_Df_10.Q2_costs.sum())
display( optimization_Df_10.Q2_costs.sum())
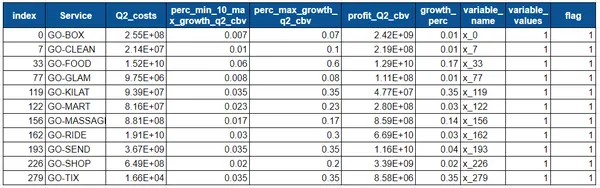
- 각 서비스의 최대 증가율은 위 차트에 나와 있습니다. Box의 경우 1%, Clean의 경우 1%, Food의 경우 17% 등입니다.
- 총 현금 소각은 – 39999532404.0입니다.
- 활용도가 낮은 예산 – 467596.0
- 최대 이익 – 98731060158.0
파트 XNUMX의 솔루션
sales_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/model_analytics__data.csv') time_to_pandas_time = ["date"] for cols in time_to_pandas_time: sales_df[cols] = pd.to_datetime(sales_df[cols]) sales_df['Month'] = sales_df['date'].dt.month Q1_2016_df = sales_df[sales_df['Month'] !=900] Q1_2016_df['Month'] = np.where(Q1_2016_df['Month'] == 1,"Jan",np.where(Q1_2016_df['Month'] == 2,"Feb",np.where(Q1_2016_df['Month'] == 3,"Mar","Apr"))) Q1_2016_df['test_control'] = np.where(Q1_2016_df['date'] <= "2016-03-30","train", "test") display(Q1_2016_df.head(5)) display(Q1_2016_df.order_status.unique()) display(Q1_2016_df.service.unique()) display(Q1_2016_df.date.max())
#import csv- 데이터 세트 가져 오기
- 날짜를 pandas datetime으로 변환
- 월 열 파생
- 기차 및 테스트 열 파생
display(Q1_2016_df.head())
display(Q1_2016_df.date.max()) Q1_2016_df_2 = Q1_2016_df[Q1_2016_df["date"] <= "2016-04-01"]
display(Q1_2016_df_2.date.max()) Q1_2016_df_2 = Q1_2016_df_2[Q1_2016_df["order_status"] == "Cancelled"] Q1_2016_df_date_unique = Q1_2016_df_2[["date"]].drop_duplicates()
Q1_2016_df_date_service = Q1_2016_df_2[["service"]].drop_duplicates() Q1_2016_df_CJ = Q1_2016_df_date_unique.merge(Q1_2016_df_date_service, how = "cross") ## cross join with opti DF display(Q1_2016_df_date_unique.head())
display(Q1_2016_df_date_unique.shape)
display(Q1_2016_df_date_unique.max())
display(Q1_2016_df_date_unique.min()) display(Q1_2016_df_2.shape)
Q1_2016_df_3 = Q1_2016_df_CJ.merge(Q1_2016_df_2, on=['date','service'], how='left', suffixes=('_x', '_y')) display(Q1_2016_df_3.head())
display(Q1_2016_df_3.shape)
display(Q1_2016_df_CJ.shape) Q1_2016_df_3["total_cbv"].fillna(0, inplace = True)
print("Null check ",Q1_2016_df_3.isnull().values.any()) nan_rows = Q1_2016_df_3[Q1_2016_df_3['total_cbv'].isnull()]
nan_rows display(Q1_2016_df_3[Q1_2016_df_3.isnull().any(axis=1)]) Q1_2016_df_3["dayofweek"] = Q1_2016_df_3["date"].dt.dayofweek
Q1_2016_df_3["dayofmonth"] = Q1_2016_df_3["date"].dt.day Q1_2016_df_3["Is_Weekend"] = Q1_2016_df_3["date"].dt.day_name().isin(['Saturday', 'Sunday']) Q1_2016_df_3.head()- 취소된 주문만 필터링합니다.
- 모든 서비스에 대해 01월 01일부터 XNUMX월 XNUMX일까지의 날짜와 교차 조인하여 모든 날짜에 대한 예측을 사용할 수 있습니다.
- NULL을 0으로 바꿉니다.
- 해당 월의 날짜 구하기
- 요일을 구합니다.
- 바이너리 주말/주중 컬럼 생성

Q1_2016_df_4 = Q1_2016_df_3[Q1_2016_df_3["service"] != "GO-TIX"] Q1_2016_df_5 = pd.get_dummies(Q1_2016_df_4, columns=["Month","dayofweek"]) display(Q1_2016_df_5.head()) import numpy as np
import pandas as pd
# from sklearn.datasets import load_boston
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from numpy import mean
from numpy import std
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_predict Q1_2016_df_5.columns all_columns = ['date', 'service', 'num_orders', 'order_status', 'total_cbv', 'test_control', 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb', 'Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2', 'dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6'] model_variables = [ 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb', 'Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2', 'dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6'] target_Variable = ["total_cbv"] all_columns = ['service', 'test_control', 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb', 'Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2', 'dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6']- GO-TIX 필터링
- 하나의 핫 인코딩 – 월 및 요일
- 필요한 모든 라이브러리 가져오기
- 열, 기차, 예측자 등의 목록을 만듭니다.
model_1 = Q1_2016_df_5[Q1_2016_df_5["service"] =="GO-FOOD"] test = model_1[model_1["test_control"]!="train"]
train = model_1[model_1["test_control"]=="train"] X = train[model_variables]
y = train[target_Variable] train_predict = model_1[model_1["test_control"]=="train"]
x_ = X[model_variables] sc = StandardScaler()
X_train = sc.fit_transform(X)
X_test = sc.transform(x_)
- 하나의 서비스에 대한 데이터 필터링 – GO-FOOD
- 학습 및 테스트 데이터 프레임 만들기
- 열차 열이 있는 X –를 만들고 예측자 열이 있는 y를 만듭니다.
- z-점수 변환에 Standardscalar를 사용합니다.
#define custom function which returns single output as metric score
def NMAPE(y_true, y_pred): return 1 - np.mean(np.abs((y_true - y_pred) / y_true)) * 100 #make scorer from custome function
nmape_scorer = make_scorer(NMAPE) # prepare the cross-validation procedure
cv = KFold(n_splits=3, random_state=1, shuffle=True)
# create model
model = LinearRegression()
# evaluate model
scores = cross_val_score(model, X, y, scoring=nmape_scorer, cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) y_pred = cross_val_predict(model, X, y, cv=cv)
- cross_val_score에는 MAPE가 내장 스코어러로 포함되어 있지 않으므로 MAPE를 정의하십시오.
- CV 인스턴스 만들기
- LR 인스턴스 만들기
- cross_val_score를 사용하여 GO-Foods의 CV Folds에서 평균 MAPE 점수를 얻습니다.
- 각 서비스에 대해 이 코드를 잘라낼 수 있습니다.
def go_model(Q1_2016_df_5, go_service,model_variables,target_Variable): """ Q1_2016_df_5 go_service model_variables target_Variable """ model_1 = Q1_2016_df_5[Q1_2016_df_5["service"] ==go_service] test = model_1[model_1["test_control"]!="train"] train = model_1[model_1["test_control"]=="train"] X = train[model_variables] y = train[target_Variable] train_predict = model_1[model_1["test_control"]=="train"] x_ = X[model_variables] X_train = sc.fit_transform(X) X_test = sc.transform(x_) # prepare the cross-validation procedure cv = KFold(n_splits=3, random_state=1, shuffle=True) # create model model = LinearRegression() # evaluate model scores = cross_val_score(model, X, y, scoring=nmape_scorer, cv=cv, n_jobs=-1) # report performance print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) y_pred = cross_val_predict(model, X, y, cv=cv) return y_pred,mean(scores), std(scores) a,b,c = go_model(Q1_2016_df_5, "GO-FOOD",model_variables,target_Variable) b- 함수로 변환된 모델링 단계:
- Q1_2016_df_5 – 기본 데이터
- go_service – go-tix, go-send 등
- model_variables – 모델 학습에 사용되는 변수
- target_Variable – 예측 변수(total_cbv).
- 각 서비스에 대해 방법을 실행하여 11개 서비스 모두에서 평균 예측 MAPE를 얻을 수 있습니다.
파트 XNUMX의 솔루션
질문 3은 개방형 질문이며 독자가 스스로 해결하도록 권장됩니다. 몇 가지 가설은 다음과 같습니다.
- 이것은 하나의 입자 영역과 지리에 따라 다르므로 APP가 거의 동일하게 유지되고 제품 개입이 사소한 역할만 수행했을 수 있다고 가정하는 것이 안전합니다. 그리고 제품 개입이 있었다면 이 특정 영역에만 국한되었습니다.
- 양질의/유명한 레스토랑과 푸드 체인이 온보딩되었으며, 사용자는 이제 친숙한 레스토랑에서 주문하거나 주문할 수 있는 좋은 선택이 많이 있습니다.
- 더 많은 수의 배송 에이전트를 온보딩하여 배송 속도가 크게 향상되었습니다.
- 취소를 줄이기 위해 배달 에이전트를 효과적으로 재교육했습니다.
- 레스토랑 파트너와 협력하여 혼잡한 피크타임을 더 나은 방식으로 처리했습니다.
유용한 리소스 및 참조
- 일 '중앙 분석 및 과학 팀'에서
- 방법 우리는 'Tensoba'로 음식 퇴치 시간을 추정합니다
- 근무지에서 발생 초급 데이터 분석가를 위한 사례 연구 과제
- 해결 데이터 과학자를 위한 비즈니스 사례 연구 과제
- 사용 고객에게 감사하는 데이터
- $XNUMX Million 미만 Gojek의 자동 예측 도구 후드
- 실험 고젝에서
- 고젝의 인도네시아에 미치는 영향
- 빠르게: 라마단 이면의 데이터
- 펄프 최적화.
- 선의 펄프를 사용한 프로그래밍.
- 마케팅 캠페인 최적화.
- 단순, 간단, 편리 파이썬을 사용하여 무언가를 최적화하는 방법.
결론
위에 제시된 단계에 따라 올바르게 수행된 사례 연구는 비즈니스에 긍정적인 영향을 미칠 것입니다. 채용 담당자는 답변을 찾는 것이 아니라 해당 답변에 대한 접근 방식, 따라가는 구조, 사용된 추론, 비즈니스 분석을 사용하는 비즈니스 및 실용적인 지식을 찾고 있습니다. 이 문서는 실제 비즈니스 사례 연구를 예로 사용하여 데이터 분석가가 쉽게 따라할 수 있는 프레임워크를 제공합니다.
주요 요점:
- 이 사례 연구에 답하는 데는 상향식과 하향식의 두 가지 접근 방식이 있습니다. 여기서는 데이터에 대한 생소함과 비즈니스 컨텍스트의 가용성이 없기 때문에 상향식 접근 방식을 고려했습니다.
- 여러 차원에서 판매 수치를 쪼개고 자르고 서비스 전반에서 추세와 패턴을 식별하는 것이 성장을 위한 과제를 파악하는 가장 좋은 접근 방식입니다.
- 추천을 제공하면서 선명하고 요점을 말하십시오.
- 데이터 포인트를 증명하는 대신 데이터가 스토리를 말하게 하십시오. 예: 상위 90개 서비스가 수익의 2% 이상에 기여합니다. 그룹 수준에서 성장은 긍정적인 측면이지만 다양한 서비스에서는 승차 완료, 운전자 취소 등과 같은 문제가 있습니다. 음식의 경우 - 취소를 Y% 줄이면 XNUMX분기 매출이 x% 증가할 것입니다.
- 펄프를 사용한 최적화는 제약 조건이 3개 이상일 때 위협적입니다. LP 문제를 종이에 적고 코딩하면 확실히 작업이 더 쉬워집니다.
행운을 빕니다! 여기 내 링크드 인 저와 연결하고 싶거나 기사를 개선하는 데 도움이 되고 싶다면 프로필을 확인하세요. 저에게 핑을 보내주세요. 탑메이트/멘트로; 당신은 당신의 쿼리와 함께 나에게 메시지를 삭제할 수 있습니다. 연결되어 기쁩니다. 데이터 과학 및 분석에 대한 다른 기사를 확인하십시오. 여기에서 지금 확인해 보세요..
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- PREIPO®로 PRE-IPO 회사의 주식을 사고 팔 수 있습니다. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/05/business-analytics-solving-business-case-studies-assignments/

