
Google의 사진 Deepmind
딥 러닝은 다음을 기반으로 하는 머신 러닝 모델의 한 분야입니다. 신경망. 다른 기계 모델에서는 의미 있는 기능을 찾기 위한 데이터 처리가 수동으로 수행되거나 도메인 전문 지식에 의존하여 수행되는 경우가 많습니다. 그러나 딥 러닝은 인간의 두뇌를 모방하여 필수 기능을 발견하고 모델 성능을 높일 수 있습니다.
얼굴 인식, 사기 탐지, 음성-텍스트 변환, 텍스트 생성 등을 포함하여 딥 러닝 모델을 위한 다양한 애플리케이션이 있습니다. 딥 러닝은 많은 고급 기계 학습 애플리케이션에서 표준 접근 방식이 되었으며 이에 대해 학습해도 잃을 것이 없습니다.
이 딥 러닝 모델을 개발하기 위해 처음부터 작업하는 대신 의존할 수 있는 다양한 라이브러리 프레임워크가 있습니다. 이 기사에서는 딥 러닝 모델을 개발하는 데 사용할 수 있는 두 가지 라이브러리인 PyTorch와 Lighting AI에 대해 설명합니다. 그것에 들어가 보자.
PyTorch는 딥러닝 신경망을 훈련하기 위한 오픈 소스 라이브러리 프레임워크입니다. PyTorch는 2016년 Meta 그룹에 의해 개발되었으며 인기가 높아졌습니다. 인기가 높아진 것은 GPU 백엔드 라이브러리를 결합한 PyTorch 기능 덕분이었습니다. 토치 파이썬 언어로. 이 조합을 통해 사용자는 패키지를 쉽게 따라갈 수 있지만 딥 러닝 모델 개발에는 여전히 강력합니다.
눈에 띄는 몇 가지가 있습니다 파이토치 기능 이는 훌륭한 프런트 엔드, 분산 교육, 빠르고 유연한 실험 프로세스를 포함하여 라이브러리를 통해 가능해졌습니다. PyTorch 사용자가 많기 때문에 커뮤니티 개발과 투자도 엄청났습니다. 그렇기 때문에 PyTorch를 배우는 것이 장기적으로 도움이 될 것입니다.
PyTorch 빌딩 블록은 텐셔너, 모든 입력, 출력 및 모델 매개변수를 인코딩하는 데 사용되는 다차원 배열입니다. NumPy 배열과 유사하지만 GPU에서 실행되는 기능을 갖춘 텐서를 상상할 수 있습니다.
PyTorch 라이브러리를 시험해 보겠습니다. GPU 시스템에 액세스할 수 없는 경우(CPU에서는 계속 작동할 수 있지만) Google Colab과 같은 클라우드에서 튜토리얼을 수행하는 것이 좋습니다. 하지만 로컬에서 시작하려면 다음을 통해 라이브러리를 설치해야 합니다. 이 페이지. 귀하가 보유하고 있는 적절한 시스템과 사양을 선택하십시오.
예를 들어, 아래 코드는 CUDA 지원 시스템이 있는 경우 pip 설치를 위한 것입니다.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
설치가 완료되면 PyTorch 기능을 사용해 딥 러닝 모델을 개발해 보겠습니다. 이 튜토리얼에서는 웹 튜토리얼을 기반으로 PyTorch를 사용하여 간단한 이미지 분류 모델을 수행할 것입니다. 우리는 코드를 살펴보고 코드 내에서 무슨 일이 일어났는지 설명했습니다.
먼저 PyTorch를 사용하여 데이터 세트를 다운로드합니다. 이 예에서는 손으로 쓴 숫자 분류 데이터세트인 MNIST 데이터세트를 사용합니다.
from torchvision import datasets train = datasets.MNIST( root="image_data", train=True, download=True
) test = datasets.MNIST( root="image_data", train=False, download=True,
)
MNIST 열차 및 테스트 데이터 세트를 모두 루트 폴더에 다운로드합니다. 데이터 세트가 어떻게 보이는지 살펴보겠습니다.
import matplotlib.pyplot as plt for i, (img, label) in enumerate(list(train)[:10]): plt.subplot(2, 5, i+1) plt.imshow(img, cmap="gray") plt.title(f'Label: {label}') plt.axis('off') plt.show()

모든 이미지는 XNUMX에서 XNUMX 사이의 한 자리 숫자로, 이는 XNUMX개의 라벨이 있음을 의미합니다. 다음으로 이 데이터세트를 기반으로 이미지 분류기를 개발해 보겠습니다.
PyTorch로 딥러닝 모델을 개발하려면 이미지 데이터세트를 텐서로 변환해야 합니다. 이미지는 PIL 객체이므로 PyTorch ToTensor 함수를 사용하여 변환을 수행할 수 있습니다. 또한 데이터 세트 기능을 사용하여 이미지를 자동으로 변환할 수 있습니다.
from torchvision.transforms import ToTensor
train = datasets.MNIST( root="data", train=True, download=True, transform=ToTensor()
) test = datasets.MNIST( root="data", train=False, download=True, transform=ToTensor()
)
변환 함수를 변환 매개변수에 전달하면 데이터가 어떤 모습일지 제어할 수 있습니다. 다음으로 PyTorch 모델이 이미지 데이터에 액세스할 수 있도록 데이터를 DataLoader 객체로 래핑합니다.
from torch.utils.data import DataLoader
size = 64 train_dl = DataLoader(train, batch_size=size)
test_dl = DataLoader(test, batch_size=size) for X, y in test_dl: print(f"Shape of X [N, C, H, W]: {X.shape}") print(f"Shape of y: {y.shape} {y.dtype}") break
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
위 코드에서는 열차 및 테스트 데이터에 대한 DataLoader 객체를 생성합니다. 각 데이터 배치 반복은 위 객체에서 64개의 기능과 라벨을 반환합니다. 또한 이미지의 모양은 28 * 28(높이 * 너비)입니다.
다음으로 신경망 모델 객체를 개발하겠습니다.
from torch import nn #Change to 'cuda' if you have access to GPU
device = 'cpu' class NNModel(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.lr_stack = nn.Sequential( nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): x = self.flatten(x) logits = self.lr_stack(x) return logits model = NNModel().to(device)
print(model)
NNModel( (flatten): Flatten(start_dim=1, end_dim=-1) (lr_stack): Sequential( (0): Linear(in_features=784, out_features=128, bias=True) (1): ReLU() (2): Linear(in_features=128, out_features=128, bias=True) (3): ReLU() (4): Linear(in_features=128, out_features=10, bias=True) )
)
위의 객체에서는 레이어 구조가 거의 없는 신경 모델을 생성합니다. Neural Model 객체를 개발하기 위해 우리는 nn.module 함수와 함께 서브클래싱 방법을 사용하고 the__init__ 내에 신경망 레이어를 생성합니다.
처음에는 flatten 기능을 사용하여 2D 이미지 데이터를 레이어 내부의 픽셀 값으로 변환합니다. 그런 다음 순차 함수를 사용하여 레이어를 일련의 레이어로 래핑합니다. 순차 함수 내부에는 모델 레이어가 있습니다.
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
순서대로 위에서 일어나는 일은 다음과 같습니다.
- 먼저 28*28 특징인 데이터 입력을 선형 레이어의 선형 함수를 사용하여 변환하고 128개의 특징을 출력합니다.
- ReLU는 비선형성을 도입하기 위해 모델 입력과 출력 사이에 존재하는 비선형 활성화 함수입니다.
- 128개의 특징이 선형 레이어에 입력되고 128개의 특징이 출력됩니다.
- 또 다른 ReLU 활성화 함수
- 선형 레이어의 입력으로 128개의 기능이 있고 출력으로 10개의 기능이 있습니다(데이터 세트 레이블에는 레이블이 10개만 있습니다).
마지막으로 모델의 실제 입력 프로세스를 위한 전달 기능이 있습니다. 다음으로 모델에는 손실 함수와 최적화 함수가 필요합니다.
from torch.optim import SGD loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-3)
다음 코드에서는 모델링 활동을 실행하기 전에 교육 및 테스트 준비만 준비합니다.
import torch
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) model.train() for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) loss.backward() optimizer.step() optimizer.zero_grad() if batch % 100 == 0: loss, current = loss.item(), (batch + 1) * len(X) print(f"loss: {loss:>2f} [{current:>5d}/{size:>5d}]") def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() test_loss, correct = 0, 0 with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches correct /= size print(f"Test Error: n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>2f} n")
이제 모델 학습을 실행할 준비가 되었습니다. 우리는 모델을 사용하여 수행할 에포크(반복) 수를 결정합니다. 이 예에서는 XNUMX번 실행한다고 가정해 보겠습니다.
epoch = 5
for i in range(epoch): print(f"Epoch {i+1}n-------------------------------") train(train_dl, model, loss_fn, optimizer) test(test_dl, model, loss_fn)
print("Done!")
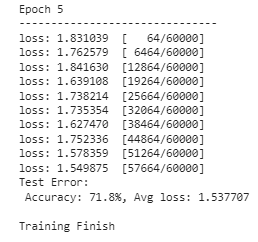
이제 모델은 훈련을 마쳤으며 모든 이미지 예측 활동에 사용할 수 있습니다. 결과는 다양할 수 있으므로 위 이미지와는 다른 결과가 나올 것으로 예상됩니다.
PyTorch가 할 수 있는 일은 몇 가지에 불과하지만, PyTorch를 사용하여 모델을 구축하는 것이 쉽다는 것을 알 수 있습니다. 사전 훈련된 모델에 관심이 있다면 PyTorch에는 허브 액세스할 수 있습니다.
조명 AI 는 PyTorch 딥러닝 모델을 학습시키는 시간을 최소화하고 단순화하기 위한 다양한 제품을 제공하는 회사입니다. 오픈 소스 제품 중 하나는 파이토치 조명는 PyTorch 모델을 훈련하고 배포하기 위한 프레임워크를 제공하는 라이브러리입니다.
조명은 코드 유연성, 상용구 없음, 최소한의 API, 향상된 팀 협업 등 몇 가지 기능을 제공합니다. 조명은 다중 GPU 활용 및 신속하고 정밀도가 낮은 교육과 같은 기능도 제공합니다. 이로 인해 조명은 PyTorch 모델을 개발하기 위한 좋은 대안이 되었습니다.
조명을 활용한 모델 개발을 시도해 보겠습니다. 시작하려면 패키지를 설치해야 합니다.
pip install lightning
조명이 설치되면 다음과 같은 또 다른 조명 AI 제품도 설치합니다. 토치메트릭스 측정항목 선택을 단순화합니다.
pip install torchmetrics
모든 라이브러리가 설치되면 조명 래퍼를 사용하여 이전 예와 동일한 모델을 개발해 보겠습니다. 아래는 모델 개발을 위한 전체 코드입니다.
import torch
import torchmetrics
import pytorch_lightning as pl
from torch import nn
from torch.optim import SGD # Change to 'cuda' if you have access to GPU
device = 'cpu' class NNModel(pl.LightningModule): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.lr_stack = nn.Sequential( nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10) ) self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10) self.valid_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10) def forward(self, x): x = self.flatten(x) logits = self.lr_stack(x) return logits def training_step(self, batch, batch_idx): x, y = batch x, y = x.to(device), y.to(device) pred = self(x) loss = nn.CrossEntropyLoss()(pred, y) self.log('train_loss', loss) # Compute training accuracy acc = self.train_acc(pred.softmax(dim=-1), y) self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True) return loss def configure_optimizers(self): return SGD(self.parameters(), lr=1e-3) def test_step(self, batch, batch_idx): x, y = batch x, y = x.to(device), y.to(device) pred = self(x) loss = nn.CrossEntropyLoss()(pred, y) self.log('test_loss', loss) # Compute test accuracy acc = self.valid_acc(pred.softmax(dim=-1), y) self.log('test_acc', acc, on_step=True, on_epoch=True, prog_bar=True) return loss
위의 코드에서 어떤 일이 발생하는지 분석해 보겠습니다. 이전에 개발한 PyTorch 모델과의 차이점은 NNModel 클래스가 이제 LightingModule의 하위 클래스를 사용한다는 것입니다. 또한 TorchMetrics를 사용하여 평가할 정확도 측정항목을 할당합니다. 그런 다음 클래스 내에 훈련 및 테스트 단계를 추가하고 최적화 기능을 설정했습니다.
모든 모델이 설정되면 변환된 DataLoader 개체를 사용하여 모델 교육을 실행하여 모델을 교육합니다.
# Create a PyTorch Lightning trainer
trainer = pl.Trainer(max_epochs=5) # Create the model
model = NNModel() # Fit the model
trainer.fit(model, train_dl) # Test the model
trainer.test(model, test_dl) print("Training Finish")
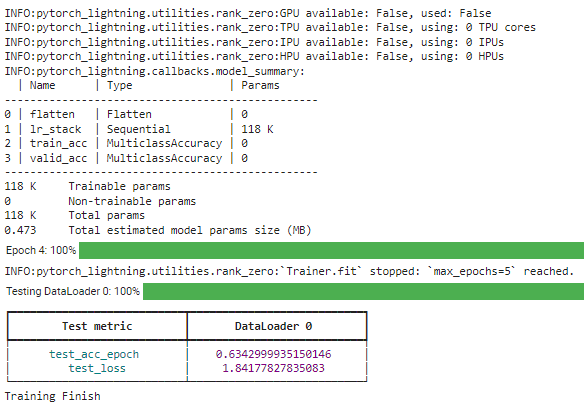
조명 라이브러리를 사용하면 필요한 구조를 쉽게 조정할 수 있습니다. 더 자세한 내용을 보려면 다음을 읽어보세요. 선적 서류 비치.
PyTorch는 딥 러닝 모델 개발을 위한 라이브러리이며 다양한 고급 API에 액세스할 수 있는 쉬운 프레임워크를 제공합니다. Lighting AI는 모델 개발을 단순화하고 개발 유연성을 향상시키는 프레임워크를 제공하는 라이브러리도 지원합니다. 이 기사에서는 라이브러리의 기능과 간단한 코드 구현을 모두 소개했습니다.
코넬리우스 유다 위자야 데이터 과학 보조 관리자 및 데이터 작성자입니다. Allianz Indonesia에서 풀타임으로 일하는 동안 그는 소셜 미디어와 글쓰기 미디어를 통해 Python 및 데이터 팁을 공유하는 것을 좋아합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/introduction-to-deep-learning-libraries-pytorch-and-lightning-ai?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-deep-learning-libraries-pytorch-and-lightning-ai

