개요
오늘날 끊임없이 발전하는 기술 세계에서는 고급 다중 모드 생성 AI(Advanced Multi-modal Generative AI)라는 흥미로운 개발이 곧 다가오고 있습니다. 이 최첨단 기술은 컴퓨터를 더욱 혁신적이고 훌륭하게 만들고 콘텐츠를 만들고 이해하는 것입니다. 텍스트, 이미지, 사운드와 원활하게 작동하고 정보를 생성하는 디지털 어시스턴트를 상상해 보세요. 이 기사에서는 이 기술이 실시간/실제 응용 프로그램 및 예제에서 어떻게 작동하는지 살펴보고 모든 것을 사용하고 이해할 수 있도록 단순화된 코드 조각도 제공합니다. 이제 Advanced Multimodal Generative AI의 세계에 대해 알아보고 살펴보겠습니다.

다음 섹션에서는 입력부터 융합, 출력까지 멀티모달 AI의 핵심 모듈을 살펴보고 이 기술이 원활하게 작동하도록 협업하는 방법을 보다 명확하게 이해합니다. 또한 해당 기능과 실제 사용 사례를 보여주는 실용적인 코드 예제를 살펴보겠습니다. 고급 다중 모드 제너레이티브 AI 기계가 우리가 상상했던 방식으로 우리를 이해하고 소통하는 보다 상호작용적이고 창의적이며 효율적인 디지털 시대를 향한 도약입니다.
학습 목표
- Advanced Multimodal Generative AI의 기본 사항을 간단한 용어로 이해합니다.
- 멀티모달 AI가 입력, 융합 및 출력 모듈을 통해 어떻게 작동하는지 살펴보세요.
- 실용적인 코드 예제를 통해 Multimodal AI의 내부 작동에 대한 통찰력을 얻으세요.
- 실제 사용 사례를 통해 멀티모달 AI의 실제 애플리케이션을 알아보세요.
- 단일 모달 AI와 다중 모달 AI 및 그 기능을 구별합니다.
- 실제 시나리오에서 멀티모달 AI를 배포할 때 이러한 사항을 자세히 살펴보세요.
이 기사는 데이터 과학 블로그.
차례
고급 멀티모달 생성 AI 이해
믿을 수 없을 정도로 똑똑하고 다양한 방식으로 당신을 이해할 수 있는 로봇 친구 로비가 있다고 상상해 보세요. 로비에게 해변에서의 하루에 대한 재미있는 이야기를 들려주고 싶을 때 로비에게 말을 걸거나 그림/그림을 그리거나 심지어 사진을 보여줄 수도 있습니다. 그러면 로비는 당신의 말, 그림 등을 이해/얻을 수 있습니다. 의사소통하고 이해하기 위해 다양한 방법을 이해하고 사용하는 능력이 "멀티모달"의 핵심입니다.
멀티모달 AI는 어떻게 작동하나요?
멀티모달 AI는 텍스트, 이미지, 오디오와 같은 다양한 데이터 모드로 콘텐츠를 이해하고 생성하도록 설계되었습니다. 이는 세 가지 핵심 모듈을 통해 달성됩니다.

- 입력 모듈
- 융합 모듈
- 출력 모듈
Multimodal AI의 작동 방식을 이해하기 위해 이러한 모듈을 자세히 살펴보겠습니다.
입력 모듈
입력 모듈은 다양한 데이터 유형이 입력되는 문과 같습니다. 그 기능은 다음과 같습니다.
- 텍스트 데이터: 단어와 구를 살펴보고, 언어 이해와 같이 문장에서 이들이 어떻게 관련되는지 살펴봅니다.
- 이미지 데이터: 사진을 확인하고 사물, 장면, 패턴 등 그 안에 무엇이 들어 있는지 파악합니다.
- 오디오 데이터: 소리를 듣고 AI가 이해할 수 있도록 단어로 변환합니다.
입력 모듈은 이러한 모든 데이터를 가져와 AI가 이해할 수 있는 언어로 변환합니다. 중요한 내용을 찾아 다음 단계를 준비합니다.
융합 모듈
Fusion Module은 모든 것이 하나로 모이는 곳입니다.
- 텍스트-이미지 융합: 단어와 그림을 함께 모아 놓은 것입니다. 이는 용어와 그림의 내용을 이해하는 데 도움이 되며 모든 내용을 이해하게 해줍니다.
- 텍스트-오디오 퓨전: 소리로 단어를 구성합니다. 이렇게 하면 누군가의 말투나 기분 등 소리만으로는 놓칠 수 있는 정보를 파악하는 데 도움이 됩니다.
- 이미지-오디오 융합: 이 부분은 당신이 보는 것과 듣는 것을 연결합니다. 무슨 일이 일어나고 있는지 설명하거나 비디오 등을 좀 더 편안하게 만드는 데 유용합니다.
Fusion Module은 이 모든 정보를 모아서 더 쉽게 얻을 수 있도록 해줍니다.
출력 모듈
출력 모듈은 토크백 부분과 같습니다. 배운 내용을 바탕으로 내용을 말합니다. 방법은 다음과 같습니다.
- 텍스트 생성: 질문에 답하는 것부터 환상적인 이야기를 만드는 것까지 단어를 사용하여 문장을 만듭니다.
- 이미지 생성: 장면이나 사물과 같이 현재 일어나고 있는 상황에 맞는 사진을 만듭니다.
- 음성 생성: 자연인처럼 말과 소리를 사용해 대답해주기 때문에 이해하기 쉽습니다.
출력 모듈은 AI의 답변이 정확하고 듣는 내용과 일치하는지 확인합니다.
간단히 말해서, Multimodal AI는 입력 모듈의 여러 위치에서 데이터를 모으고, Fusion 모듈에서 큰 그림을 얻고, 출력 모듈에서 학습한 내용에 맞는 내용을 말합니다. 이는 AI가 어떤 데이터를 얻더라도 우리를 더 잘 이해하고 대화하는 데 도움이 됩니다.
# Import the Multimodal AI library
from multimodal_ai import MultimodalAI # Initialize the Multimodal AI model
model = MultimodalAI() # Input data for each modality
text_data = "A cat chasing a ball."
image_data = load_image("cat_chasing_ball.jpg")
audio_data = load_audio("cat_sound.wav") # Process each modality separately
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Combine information from different modalities
combined_embedding = model.combine_modalities(text_embedding, image_embedding, audio_embedding) # Generate a response based on the combined information
response = model.generate_response(combined_embedding) # Print the generated response
print(response)
이 코드에서는 Multimodal AI가 다양한 양식의 정보를 처리하고 결합하여 의미 있는 응답을 생성하는 방법을 보여줍니다. 불필요한 복잡함 없이 개념을 이해하는 데 도움이 되는 간단한 예입니다.
내부 작업
내부 동작을 이해하고 싶으신가요? 다양한 부분을 살펴보겠습니다.

다중 모드 입력
입력은 텍스트, 이미지, 오디오일 수 있으며 이러한 모델도 이들의 조합을 허용할 수 있습니다. 이는 전용 하위 네트워크를 통해 각 양식을 처리하는 동시에 이들 간의 상호 작용을 허용함으로써 달성됩니다.
from multimodal_generative_ai import MultiModalModel # Initialize a Multi-Modal Model
model = MultiModalModel() # Input data in the form of text, image, and audio
text_data = "A beautiful sunset at the beach."
image_data = load_image("beach_sunset.jpg")
audio_data = load_audio("ocean_waves.wav") # Process each modality through dedicated sub-networks
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Allow interactions between modalities
output = model.generate_multi_modal_output(text_embedding, image_embedding, audio_embedding)이 코드에서는 텍스트, 이미지, 오디오와 같은 다양한 입력을 처리할 수 있는 다중 모드 모델을 개발합니다.
크로스 모달 이해
주요 기능 중 하나는 다양한 양식 간의 관계를 이해하는 모델의 능력입니다. 예를 들어 텍스트 설명을 기반으로 이미지를 설명하거나 텍스트 형식에서 관련 이미지를 생성할 수 있습니다.
from multimodal_generative_ai import CrossModalModel # Initialize a Cross-Modal Model
model = CrossModalModel() # Input textual description and image
description = "A cabin in the snowy woods."
image_data = load_image("snowy_cabin.jpg") # Generating text based on the image
generated_text = model.generate_text_from_image(image_data)
generated_image = model.generate_image_from_text(description)이 코드에서는 다양한 양식에 걸쳐 콘텐츠를 이해하고 생성하는 데 탁월한 Cross-Modal 모델을 사용합니다. 마치 "눈 덮인 숲 속의 오두막"과 같은 텍스트 입력을 기반으로 이미지를 설명할 수 있는 것과 같습니다. 또는 텍스트 설명에서 이미지를 생성할 수 있으므로 이미지 캡션 작성이나 콘텐츠 생성과 같은 작업에 매우 중요한 도구가 됩니다.
상황 인식
이러한 AI 시스템은 상황을 포착하는 데 탁월합니다. 그들은 미묘한 차이를 이해하고 상황에 맞는 콘텐츠를 생성할 수 있습니다. 이러한 상황 인식은 콘텐츠 생성 및 추천 시스템 작업에서 중요합니다.
from multimodal_generative_ai import ContextualModel # Initialize a Contextual Model
model = ContextualModel() # Input contextual data
context = "In a bustling city street, people rush to respective homes." # Generate contextually relevant content
generated_content = model.generate_contextual_content(context)이 코드는 컨텍스트를 효과적으로 캡처하도록 설계된 컨텍스트 모델을 보여줍니다. 문맥 = "번화한 도시 거리에서 사람들은 각자의 집으로 달려갑니다."와 같은 입력이 필요합니다. 제공된 컨텍스트에 맞는 콘텐츠를 생성합니다. 상황에 맞는 콘텐츠를 생성하는 이러한 기능은 적절한 응답을 생성하기 위해 상황을 이해하는 것이 중요한 콘텐츠 생성 및 추천 시스템과 같은 작업에 유용합니다.
훈련 데이터
이러한 모델에는 다중 모드 훈련 데이터가 필요하며 훈련 데이터는 더 무거워야 합니다. 여기에는 이미지와 짝을 이루는 텍스트, 비디오와 짝을 이루는 오디오 및 기타 조합이 포함되어 모델이 의미 있는 교차 모달 표현을 학습할 수 있습니다.
from multimodal_generative_ai import MultiModalTrainer # Initialize a Multi-Modal Trainer
trainer = MultiModalTrainer() # Load multimodal training data (text paired with images, audio paired with video, etc.)
training_data = load_multi_modal_data() # Train the Multi-Modal Model
model = trainer.train_model(training_data)이 코드 예제는 다양한 훈련 데이터를 사용하여 다중 모드 모델의 훈련을 용이하게 하는 다중 모드 트레이너를 보여줍니다.
실제 애플리케이션
고급 다중 모드 생성 AI는 수요가 많으며 다양한 분야에서 많은 실제 사용에 도움이 됩니다. 코드 조각 및 설명과 함께 이 기술이 어떻게 적용될 수 있는지에 대한 몇 가지 간단한 예를 살펴보겠습니다.
컨텐츠 생성
간단한 설명을 기반으로 기사, 이미지, 오디오 등의 콘텐츠를 생성할 수 있는 시스템을 상상해 보세요. 이는 콘텐츠 제작, 광고 및 창조 산업의 판도를 바꿀 수 있습니다. 다음은 코드 조각입니다.
from multimodal_generative_ai import ContentGenerator # Initialize the Content Generator
generator = ContentGenerator() # Input a description
description = "A beautiful sunset at the beach." # Generate content
generated_text = generator.generate_text(description)
generated_image = generator.generate_image(description)
generated_audio = generator.generate_audio(description)이 예에서 콘텐츠 생성기는 설명을 입력으로 사용하고 해당 설명과 관련된 텍스트, 이미지 및 오디오 콘텐츠를 생성합니다.
보조 건강 관리
의료 분야에서 멀티모달 AI는 텍스트, 의료 이미지, 오디오 메모 및 이 세 가지의 조합을 포함하여 환자의 과거, 현재 데이터를 분석할 수 있습니다. 모든 관련 데이터를 수집하여 질병 진단, 치료 계획 수립, 환자의 향후 결과 예측까지 지원할 수 있습니다.
from multimodal_generative_ai import HealthcareAssistant # Initialize the Healthcare Assistant
assistant = HealthcareAssistant() # Input a patient record
patient_record = { "text": "Patient complains of persistent cough and fatigue.", "images": ["xray1.jpg", "mri_scan.jpg"], "audio_notes": ["heartbeat.wav", "breathing_pattern.wav"]
} # Analyze the patient record
diagnosis = assistant.diagnose(patient_record)
treatment_plan = assistant.create_treatment_plan(patient_record)
predicted_outcome = assistant.predict_outcome(patient_record)이 코드는 Healthcare Assistant가 환자의 기록을 처리하고 텍스트, 이미지 및 오디오를 결합하여 의료 진단 및 치료 계획을 지원하는 방법을 보여줍니다.
대화형 챗봇
챗봇은 멀티모달 AI 기능을 통해 더욱 매력적이고 유용해졌습니다. 텍스트와 이미지를 모두 이해할 수 있어 사용자와의 상호 작용이 더욱 자연스럽고 효과적으로 이루어집니다. 다음은 코드 조각입니다.
from multimodal_generative_ai import Chatbot # Initialize the Chatbot
chatbot = Chatbot() # User input
user_message = "Show me images of cute cats." # Engage with the user
response = chatbot.interact(user_message)이 코드는 Multimodal AI로 구동되는 Chatbot이 텍스트와 이미지 요청을 모두 포함하는 사용자 입력에 효과적으로 응답할 수 있는 방법을 보여줍니다.
콘텐츠 조정
멀티모달 AI는 텍스트와 시각적 또는 청각적 요소를 모두 분석하여 온라인 플랫폼에서 부적절한 콘텐츠의 감지 및 조정을 개선할 수 있습니다. 다음은 코드 조각입니다.
from multimodal_generative_ai import ContentModerator # Initialize the Content Moderator
moderator = ContentModerator() # User-generated content
user_content = { "text": "Inappropriate text message.", "image": "inappropriate_image.jpg", "audio": "offensive_audio.wav"
} # Moderate the user-generated content
moderated = moderator.moderate_content(user_content)이 예에서 Content Moderator는 사용자 생성 콘텐츠를 분석하여 다양한 양식을 모두 고려하여 보다 안전한 온라인 환경을 보장할 수 있습니다.
이러한 실제 사례는 고급 다중 모드 생성 AI의 실제 적용을 보여줍니다. 이 기술은 다양한 데이터 모드에서 콘텐츠를 이해하고 생성함으로써 수많은 산업에서 잠재력을 가지고 있습니다.
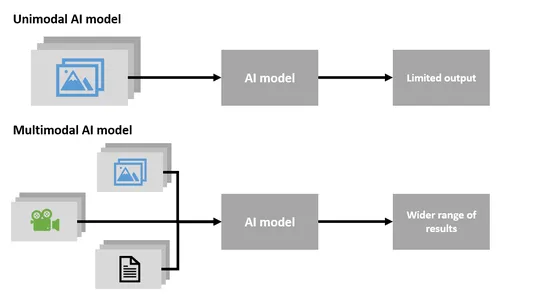
단일 모달과 다중 모달

멀티모달 AI
- 멀티모달 AI는 텍스트, 이미지, 오디오 등 다양한 유형의 데이터를 동시에 처리할 수 있는 매우 독특하고 중요한 기술입니다.
- 이러한 다양한 데이터 유형을 결합한 콘텐츠를 이해하고 생성하는 데 탁월합니다.
- 멀티모달 AI는 이미지를 기반으로 텍스트를 생성하거나 텍스트 설명에서 이미지를 생성할 수 있어 적응성이 뛰어납니다.
- 이 기술은 다양한 정보를 처리하고 이해할 수 있습니다.
단일 모달 AI
- 단일 모달 AI는 텍스트나 이미지 등 한 가지 유형의 데이터만 다루는 데 특화되어 있습니다.
- 여러 데이터 유형을 동시에 처리하거나 다양한 양식을 결합한 콘텐츠를 생성할 수 없습니다.
- 단일 모달 AI는 특정 데이터 유형으로 제한되며 다중 모달 AI의 적응성이 부족합니다.
요약하면, 멀티모달 AI는 여러 유형의 데이터를 동시에 작업할 수 있어 더욱 다양해지고 다양한 방식으로 콘텐츠를 이해하고 생성할 수 있습니다. 반면에 단일 모달 AI는 하나의 데이터 유형에 특화되어 다중 모달 AI의 다양성을 처리할 수 없습니다.
윤리적 고려 사항
개인 정보 보호 관련 문제
- 특히 의료 애플리케이션에서 민감한 사용자 데이터를 적절하게 처리하도록 보장합니다.
- 사용자 개인 정보를 보호하기 위해 강력한 데이터 암호화 및 익명화 기술을 구현합니다.
편견과 공정성
- 불공정한 결과를 방지하기 위해 훈련 데이터의 잠재적인 편향을 해결합니다.
- 콘텐츠 생성 시 편견을 최소화하기 위해 모델을 정기적으로 감사하고 업데이트합니다.
콘텐츠 조정
- AI가 생성한 부적절하거나 유해한 콘텐츠를 필터링하기 위해 효과적인 콘텐츠 조정을 배포합니다.
- 사용자가 윤리적 기준을 준수할 수 있도록 명확한 지침과 정책을 수립합니다.
투명도
- 투명성을 유지하기 위해 AI 생성 콘텐츠를 인간 생성 콘텐츠와 구별할 수 있게 만듭니다.
- 콘텐츠 제작에 AI가 관여한다는 명확한 정보를 사용자에게 제공합니다.
책임
- 멀티모달 AI의 사용 및 배포에 대한 책임을 정의하여 해당 작업에 대한 책임을 보장합니다.
- AI 생성 콘텐츠에서 발생할 수 있는 문제나 오류를 해결하기 위한 메커니즘을 확립합니다.
동의
- AI 모델 교육 및 개선을 위해 데이터를 수집하고 활용할 때는 사용자 동의를 구하세요.
- 사용자와의 신뢰를 구축하기 위해 사용자 데이터가 어떻게 사용될 것인지 명확하게 전달합니다.
접근 용이성
- 접근성 표준을 준수하여 장애가 있는 사용자가 AI 생성 콘텐츠에 액세스할 수 있도록 보장합니다.
- 시각 장애가 있는 사용자를 위한 화면 판독기와 같은 기능을 구현합니다.
지속적인 모니터링
- AI 생성 콘텐츠가 윤리 지침을 준수하는지 정기적으로 모니터링하세요.
- 진화하는 윤리 표준에 맞춰 AI 모델을 조정하고 개선하세요.
이러한 윤리적 고려 사항은 고급 멀티모달 생성 AI의 책임감 있는 개발 및 배포에 필수적이며, 윤리 표준과 사용자 권리를 유지하면서 사회에 이익이 되도록 보장합니다.
결론
우리가 현대 기술의 복잡한 환경을 헤쳐나가는 동안, 고급 다중 모드 생성 AI(Advanced Multimodal Generative AI)라는 매혹적인 개발이 지평선에 다가왔습니다. 이 획기적인 기술은 컴퓨터가 콘텐츠를 생성하고 우리의 다면적인 세계를 이해하는 방식에 혁명을 가져올 것을 약속합니다. 텍스트, 이미지, 사운드로 원활하게 작업하고, 여러 언어로 소통하고, 혁신적인 콘텐츠를 제작하는 디지털 비서를 상상해 보세요. 이 기사를 통해 고급 멀티모달 생성 AI의 복잡성을 살펴보고 실용적인 응용 프로그램, 명확성을 위한 코드 조각, 디지털 상호 작용을 재구성할 수 있는 잠재력을 탐색할 수 있기를 바랍니다.
“멀티모달 AI는 컴퓨터가 텍스트, 이미지, 오디오를 이해하고 처리할 수 있도록 도와 인간이 기계와 상호 작용하는 방식을 혁신하는 가교 역할을 합니다.”
주요 요점
- Advanced Multimodal Generative AI는 컴퓨터가 텍스트, 이미지, 오디오 전반에 걸쳐 콘텐츠를 이해하고 생성할 수 있도록 지원하는 기술의 판도를 바꾸는 기술입니다.
- 세 가지 핵심 모듈인 입력(Input), 융합(Fusion), 출력(Output)이 원활하게 함께 작동하여 정보를 효과적으로 처리하고 생성합니다.
- 멀티모달 AI는 콘텐츠 생성, 의료 지원, 대화형 챗봇, 콘텐츠 조정 분야에서 애플리케이션을 찾아 다양하고 실용적으로 만들 수 있습니다.
- 교차 모달 이해, 상황 인식 및 광범위한 교육 데이터는 기능을 향상시키는 중추적인 측면입니다.
- 멀티모달 AI는 기계와 상호 작용하고 콘텐츠를 보다 창의적으로 생성하는 새로운 방법을 제공함으로써 산업에 혁명을 일으킬 수 있는 잠재력을 가지고 있습니다.
- 여러 데이터 모드를 결합하는 기능은 적응성과 실제 사용성을 향상시킵니다.
자주 묻는 질문
A. 고급 멀티모달 생성 AI는 텍스트, 이미지, 오디오 등 다양한 데이터 유형을 사용하여 콘텐츠를 이해하고 생성하는 능력이 뛰어난 반면, 기존 AI는 한 가지 데이터 유형에만 집중하는 경우가 많습니다.
A. 고급 멀티모달 생성 AI는 텍스트, 이미지, 오디오 등 다양한 데이터 유형을 사용하여 콘텐츠를 이해하고 생성하는 능력으로 차별화되는 반면, 기존 AI는 일반적으로 단일 데이터 유형에 특화되어 있습니다.
A. 멀티모달 AI는 원하는 언어로 된 텍스트를 처리하고 이해하여 여러 언어로 능숙하게 작동합니다.
A. 네, 멀티모달 AI는 텍스트, 이미지, 오디오를 포함하는 텍스트 설명이나 프롬프트를 기반으로 창의적인 콘텐츠를 제작할 수 있습니다.
A. 멀티모달 AI는 다양한 데이터 모드에서 콘텐츠를 이해하고 생성하는 능력 덕분에 콘텐츠 생성, 의료, 챗봇, 콘텐츠 조정 등 다양한 도메인에 걸쳐 이점을 제공합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/10/exploring-the-advanced-multi-modal-generative-ai/

