の新しいバージョンを発表できることを嬉しく思います。 Kubernetes 用の Amazon SageMaker オペレーター Kubernetes 用 AWS コントローラー (ACK)。 ACK は、Kubernetes カスタム コントローラーを構築するためのフレームワークであり、各コントローラーは AWS サービス API と通信します。これらのコントローラーを使用すると、Kubernetes ユーザーは Kubernetes API を使用するだけで、バケット、データベース、メッセージ キューなどの AWS リソースをプロビジョニングできます。
リリース v1.2.9 SageMaker ACK Operators のサポートが追加されました。 推論コンポーネント、これまでは SageMaker API と AWS ソフトウェア開発キット (SDK) を通じてのみ利用可能でした。推論コンポーネントは、展開コストを最適化し、遅延を削減するのに役立ちます。新しい推論コンポーネント機能を使用すると、1 つ以上の基盤モデル (FM) を同じサーバー上にデプロイできます。 アマゾンセージメーカー エンドポイントを管理し、各 FM に確保されるアクセラレータの数とメモリの量を制御します。これにより、リソースの使用率が向上し、モデルのデプロイメント コストが平均 50% 削減され、ユースケースに合わせてエンドポイントを拡張できるようになります。詳細については、を参照してください。 Amazon SageMaker は、基盤モデルのデプロイメントコストとレイテンシーの削減に役立つ新しい推論機能を追加します.
SageMaker コントローラーを介して推論コンポーネントを利用できるため、Kubernetes をコントロール プレーンとして使用する顧客は、モデルを SageMaker にデプロイする際に推論コンポーネントを利用できるようになります。
この投稿では、SageMaker ACK Operator を使用して SageMaker 推論コンポーネントをデプロイする方法を示します。
ACK の仕組み
デモンストレーションする ACK の仕組みを使用した例を見てみましょう Amazon シンプル ストレージ サービス (アマゾンS3)。次の図では、Alice が Kubernetes ユーザーです。彼女のアプリケーションは、という名前の S3 バケットの存在に依存しています。 my-bucket.
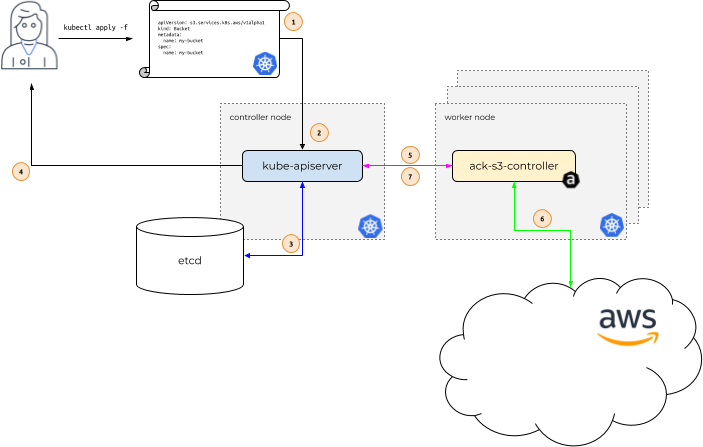
ワークフローは次の手順で構成されます。
- アリスは次の宛先に電話をかけます。
kubectl apply、Kubernetes を記述するファイルを渡します。 カスタム リソース 彼女の S3 バケットについて説明します。kubectl applyと呼ばれるこのファイルを渡します マニフェスト、Kubernetes コントローラー ノードで実行されている Kubernetes API サーバーに送信します。 - Kubernetes API サーバーは、S3 バケットを説明するマニフェストを受信し、Alice が パーミッション のカスタムリソースを作成するには 種類
s3.services.k8s.aws/Bucket、カスタム リソースが適切にフォーマットされていることを確認します。 - Alice が承認され、カスタム リソースが有効な場合、Kubernetes API サーバーはカスタム リソースをそのサーバーに書き込みます。
etcdデータストア。 - 次に、カスタム リソースが作成されたことをアリスに応答します。
- この時点で、ACK サービスは コントローラ 通常の Kubernetes のコンテキスト内の Kubernetes ワーカー ノードで実行されている Amazon S3 の場合 ポッド、新しいカスタム リソースの種類が通知されます。
s3.services.k8s.aws/Bucket作成されています。 - 次に、Amazon S3 の ACK サービス コントローラーは Amazon S3 API と通信し、 S3 CreateBucket API AWS にバケットを作成します。
- Amazon S3 API と通信した後、ACK サービス コントローラーは Kubernetes API サーバーを呼び出してカスタム リソースの status Amazon S3 から受け取った情報を使用します。
主要監視コンポーネント
新しい推論機能は、SageMaker のリアルタイム推論エンドポイントに基づいて構築されています。前と同様に、エンドポイントのインスタンス タイプと初期インスタンス数を定義するエンドポイント設定を使用して SageMaker エンドポイントを作成します。モデルは、新しい構成要素である推論コンポーネントで構成されます。ここでは、モデルの各コピーに割り当てるアクセラレータの数とメモリ量を、モデル アーティファクト、コンテナ イメージ、デプロイするモデル コピーの数とともに指定します。
新しい推論機能を次から使用できます。 Amazon SageMakerスタジオ SageMaker Python SDK, AWSSDK, AWSコマンドラインインターフェイス (AWS CLI)。それらもサポートされています AWS CloudFormation。で使用することもできるようになりました。 KubernetesのSageMakerオペレーター.
ソリューションの概要
このデモでは、SageMaker コントローラーを使用して、 ドリーv2 7Bモデル そしてそのコピー FLAN-T5 XXLモデル フェイスモデルハブを抱き締める 新しい推論機能を使用して、SageMaker リアルタイム エンドポイント上で。
前提条件
手順を進めるには、SageMaker ACK コントローラー v1.2.9 以降がインストールされた Kubernetes クラスターが必要です。プロビジョニング方法については、 Amazon Elastic Kubernetesサービス (Amazon EKS) クラスター アマゾン エラスティック コンピューティング クラウド (Amazon EC2) eksctl を使用した Linux 管理対象ノード、を参照してください。 Amazon EKS の使用開始 – eksctl。 SageMaker コントローラーのインストール手順については、以下を参照してください。 ACK SageMaker コントローラーを使用した機械学習.
LLM をホストするには、アクセラレーションされたインスタンス (GPU) にアクセスする必要があります。このソリューションでは、ml.g5.12xlarge のインスタンスを XNUMX つ使用します。次のスクリーンショットに示すように、AWS アカウントでこれらのインスタンスの可用性を確認し、必要に応じてサービス クォータ増加リクエストを通じてこれらのインスタンスをリクエストできます。

推論コンポーネントを作成する
推論コンポーネントを作成するには、 EndpointConfig, Endpoint, Model, InferenceComponent このセクションで示したものと同様の YAML ファイル。使用 kubectl apply -f <yaml file> Kubernetes リソースを作成します。
リソースのステータスを一覧表示するには、 kubectl describe <resource-type>; 例えば、 kubectl describe inferencecomponent.
モデル リソースを使用せずに推論コンポーネントを作成することもできます。に記載されているガイダンスを参照してください。 APIドキュメント のガイドをご参照ください。
EndpointConfig YAML
EndpointConfig ファイルのコードは次のとおりです。
エンドポイント YAML
エンドポイント ファイルのコードは次のとおりです。
モデルYAML
モデル ファイルのコードは次のとおりです。
推論コンポーネントの YAML
次の YAML ファイルでは、ml.g5.12xlarge インスタンスに 4 つの GPU が付属していることを考慮して、2 つの GPU、2 つの CPU、および 1,024 MB のメモリを各モデルに割り当てます。
モデルの呼び出し
これで、次のコードを使用してモデルを呼び出すことができます。
推論コンポーネントを更新する
既存の推論コンポーネントを更新するには、YAML ファイルを更新してから、 kubectl apply -f <yaml file>。以下は更新されたファイルの例です。
推論コンポーネントを削除する
既存の推論コンポーネントを削除するには、次のコマンドを使用します。 kubectl delete -f <yaml file>.
可用性と価格
新しい SageMaker 推論機能は、米国東部 (オハイオ、バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (ジャカルタ、ムンバイ、ソウル、シンガポール、シドニー、東京)、カナダ (中部)、ヨーロッパ (フランクフルト、アイルランド、ロンドン、ストックホルム)、中東(UAE)、南米(サンパウロ)。価格の詳細については、次のサイトをご覧ください。 Amazon SageMakerの価格.
まとめ
この投稿では、SageMaker ACK Operator を使用して SageMaker 推論コンポーネントをデプロイする方法を説明しました。今すぐ Kubernetes クラスターを起動し、新しい SageMaker 推論機能を使用して FM をデプロイしてください。
著者について
 ラジェシュ・ラムチャンダー は、AWS のプロフェッショナル サービスの主任 ML エンジニアです。彼は、AI/ML と GenAI の取り組みを始めたばかりの顧客から、AI ファースト戦略でビジネスをリードしている顧客まで、AI/ML と GenAI の取り組みのさまざまな段階で顧客を支援しています。
ラジェシュ・ラムチャンダー は、AWS のプロフェッショナル サービスの主任 ML エンジニアです。彼は、AI/ML と GenAI の取り組みを始めたばかりの顧客から、AI ファースト戦略でビジネスをリードしている顧客まで、AI/ML と GenAI の取り組みのさまざまな段階で顧客を支援しています。
 アミット・アロラ は、アマゾン ウェブ サービスの AI および ML スペシャリスト アーキテクトであり、企業顧客がクラウドベースの機械学習サービスを使用してイノベーションを迅速に拡張できるよう支援しています。 彼は、ワシントン DC のジョージタウン大学で修士課程のデータ サイエンスおよび分析プログラムの非常勤講師でもあります。
アミット・アロラ は、アマゾン ウェブ サービスの AI および ML スペシャリスト アーキテクトであり、企業顧客がクラウドベースの機械学習サービスを使用してイノベーションを迅速に拡張できるよう支援しています。 彼は、ワシントン DC のジョージタウン大学で修士課程のデータ サイエンスおよび分析プログラムの非常勤講師でもあります。
 スリアンシュ・シン は AWS SageMaker のソフトウェア開発エンジニアであり、AWS の顧客向けに大規模な ML 分散インフラストラクチャ ソリューションの開発に取り組んでいます。
スリアンシュ・シン は AWS SageMaker のソフトウェア開発エンジニアであり、AWS の顧客向けに大規模な ML 分散インフラストラクチャ ソリューションの開発に取り組んでいます。
 サウラブ・トリカンデ Amazon SageMaker Inference のシニア プロダクト マネージャーです。 彼は顧客と協力することに情熱を傾けており、機械学習を民主化するという目標に動機付けられています。 彼は、複雑な ML アプリケーションのデプロイ、マルチテナント ML モデル、コストの最適化、およびディープ ラーニング モデルのデプロイをよりアクセスしやすくすることに関連する主要な課題に焦点を当てています。 余暇には、ハイキング、革新的なテクノロジーの学習、TechCrunch のフォロー、家族との時間を楽しんでいます。
サウラブ・トリカンデ Amazon SageMaker Inference のシニア プロダクト マネージャーです。 彼は顧客と協力することに情熱を傾けており、機械学習を民主化するという目標に動機付けられています。 彼は、複雑な ML アプリケーションのデプロイ、マルチテナント ML モデル、コストの最適化、およびディープ ラーニング モデルのデプロイをよりアクセスしやすくすることに関連する主要な課題に焦点を当てています。 余暇には、ハイキング、革新的なテクノロジーの学習、TechCrunch のフォロー、家族との時間を楽しんでいます。
 ジョナ・リュー Amazon SageMaker チームのソフトウェア開発エンジニアです。 彼女の現在の仕事は、開発者が機械学習モデルを効率的にホストし、推論パフォーマンスを向上させるのを支援することに重点を置いています。 彼女は、空間データ分析と AI を使用して社会問題を解決することに情熱を注いでいます。
ジョナ・リュー Amazon SageMaker チームのソフトウェア開発エンジニアです。 彼女の現在の仕事は、開発者が機械学習モデルを効率的にホストし、推論パフォーマンスを向上させるのを支援することに重点を置いています。 彼女は、空間データ分析と AI を使用して社会問題を解決することに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/use-kubernetes-operators-for-new-inference-capabilities-in-amazon-sagemaker-that-reduce-llm-deployment-costs-by-50-on-average/

