
著者による画像
多くの組織が、ビジネス上の意思決定を行うために膨大な量のデータを収集しています。 Data Visualization この情報をさまざまなチャートやグラフの形で提示するプロセスです。 複雑なデータを簡素化して、パターンの特定、傾向の分析、実用的な洞察の発見を容易にします。 matplotlib Python のマルチプラットフォーム データ視覚化ライブラリです。 当初は MATLAB のプロット機能をエミュレートするために作成されましたが、堅牢で使いやすいです。 Matplotlib の長所のいくつかは次のとおりです。
- カスタマイズが容易
- 簡単に始められる
- 高品質な出力
- すぐにアクセス可能
- Figure のさまざまな要素を適切に制御できます
Matplotlib のインストール
Matplotlib をインストールするには、Windows、Mac OS、および Linux のターミナルで次のコマンドを実行します。
pip install matplotlib
Jupyter ノートブックの場合:
!pip install matplotlib
アナコンダ環境の場合:
conda install matplotlibライブラリのインポート
import numpy as np
import pandas as pd #If you are reading data from CSV
import matplotlib.pyplot as pltプロットの作成
matplotlib でプロットを作成するには、次の XNUMX つの方法があります。
1) 機能的アプローチ
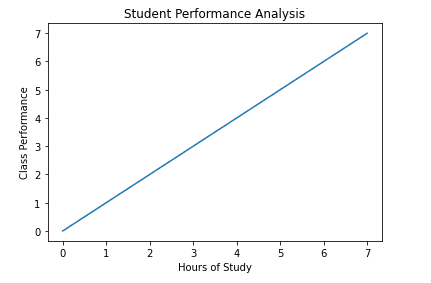
使い方は簡単ですが、高度な制御はできません。 それは利用します py.plot(x,y) 関数。 チュートリアルの他の場所ではこれを使用しませんが、どのように機能するかを知っている必要があるため、その例の XNUMX つを見てみましょう。
x = np.arange(0,8)
y = x plt.plot(x, y)
plt.xlabel('Hours of Study')
plt.ylabel('Class Performance')
plt.title('Student Performance Analysis')
plt.show() # For non-jupyter users
2) OOPアプローチ
OOP アプローチは、プロットを作成するための推奨される方法です。 Figure オブジェクトの作成を利用し、次に軸を追加します。 軸を追加しない限り、Figure オブジェクトは表示されません。
fig = plt.figure()
軸を描く前に、その構文を理解しましょう。
figureobject.add_axes([a,b,c,d])
ここで a,b は原点の位置を表します。 (0,0) は左下隅を意味し、c,d はプロットの幅と高さを設定します。 両方の値の範囲は 0 ~ 1 です。
fig = plt.figure() # blank canvas
axes = fig.add_axes([0, 0, 0.5, 0.5]) axes.plot(x, y)
plt.show()
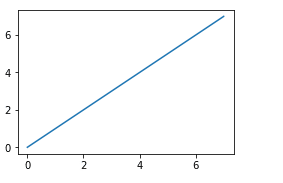
Figure オブジェクトは、dpi や Figure サイズなどのいくつかの追加パラメーターを受け取ることができます。 Dpi は XNUMX インチあたりのドット数を指し、図がぼやけている場合は図の解像度を上げます。 Figure のサイズは、Figure のサイズをインチ単位で制御します。
fig = plt.figure(figsize=(0.5,0.5),dpi=200) # blank canvas
axes = fig.add_axes([0, 0, 0.5, 0.5])
axes.plot(x, y)
plt.show()
次のように、複数の軸を Figure オブジェクトに追加することもできます。
a = np.arange(0,50)
b = a**3
fig = plt.figure()
outer_axes = fig.add_axes([0,0,1,1])
inner_axes = fig.add_axes([0.25,0.5,0.25,0.25])
outer_axes.plot(a,b)
inner_axes.set_xlim(10,20) #sets the range on x-axis
inner_axes.set_ylim(0,10000) #sets the range on y-axis
inner_axes.set_title("Zoomed Version")
inner_axes.plot(a,b)
plt.show()
Figure オブジェクトのさまざまな軸を手動で管理する代わりに、subplots() 関数を使用して複数のプロットを作成できます。 その構文を調べてみましょう。
fig, axes = plt.subplots(nrows=1, ncols=2)
これは、すべての軸オブジェクトを保持する numpy 配列と共に Figure オブジェクトを含むタプルを返します。 実際の軸セットに必要な行と列の数を指定する必要があります。 各軸オブジェクトは個別に返され、個別にアクセスできます。
exercise_hrs = np.arange(0, 5)
male_cal = exercise_hrs
female_cal = 0.70 * exercise_hrs
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].plot(exercise_hrs, male_cal)
axes[0].set_ylim(0, 5) # Sets range of y
axes[0].set_title("Male")
axes[1].plot(exercise_hrs, female_cal)
axes[1].set_ylim(0, 5)
axes[1].set_title("Female")
fig.suptitle( "Calories Burnt vs Workout Hours Analysis", fontsize=16
) # Displays the main title
fig.tight_layout() # Prevents overlapping of subplots
サブプロットの間隔は、次の方法を使用して手動で調整できます。
fig.subplots_adjust(left=None,top=None,right=None,top=None,wspace=None, hspace=None)
- left = Figure のサブプロットの左側
- right = Figure のサブプロットの右側
- bottom = Figure のサブプロットの下部
- top = Figure のサブプロットの上部
- wspace = サブプロット間のスペース用に予約された幅の量
- hspace = サブプロット間のスペース用に予約された高さの量
fig.subplots_adjust(left=0.2,top=0.8,wspace=0.9, hspace=0.1)
これを上記のプロットに適用します。
プロットのカスタマイズ
1) 凡例
Figure オブジェクトに複数のプロットを作成している場合、どのプロットが何を表しているのかを識別するのが混乱することがあります。 したがって、追加します ラベル=「テキスト」 の属性 軸.プロット() 関数を呼び出してから、後で 軸.凡例() キーを表示する機能。
axes.legend(loc=0) or axes.legend() #Default - Matplotlib decides position
axes.legend(loc=1) # upper right
axes.legend(loc=2) # upper left
axes.legend(loc=3) # lower left
axes.legend(loc=4) # lower right axes.legend(loc=(x,y)) # At (x,y) position
axes.legend() には、配置する場所を決定する引数 loc もあります。
x = np.arange(0,11)
fig = plt.figure()
ax = fig.add_axes([0,0,0.75,0.75])
ax.plot(x, x**2, label="X^2")
ax.plot(x, x**3, label="X^3")
ax.legend(loc=0) #Let matplotlib decide
2) ラインスタイリング
Matplotlib には多くのカスタマイズ オプションがあります。 構文を分析して、線の色、幅、およびスタイルを変更してみましょう。
axes.plot(x, y, color or c = 'red',alpha= ‘0.5’, linestyle or ls = ':', linewidth or lw= 5)
色: 名前または RGB 値を使用して色を定義するか、r が赤などを意味する Matlab 型の構文を使用できます。アルファ属性を使用して透明度を設定することもできます。
線種: カスタム スタイルも作成できますが、主に視覚化に関心があるため、シンプルなスタイルが適しています。 それらは次のとおりです。
linestyle = “-” or linestyle = “solid”
linestyle = “:” or linestyle = “dotted”
linestyle = “--” or linestyle = “dashed”
linestyle = “-.” or linestyle = “dashdot”
線幅: デフォルト値は 1 ですが、必要に応じて変更できます。
fig, ax = plt.subplots()
ax.plot(x, x-2, color="#000000", linewidth=1 , linestyle='solid')
ax.plot(x, x-4, color="red", lw=2 ,ls=":")
ax.plot(x, x-6, color="blue",alpha=0.4,lw=4 , ls="-.")
3) マーカーのスタイリング
matplotlib では、プロットされたすべての点はマーカーと呼ばれます。 デフォルトでは、最後の行のみが表示されますが、マーカーの種類とそのサイズを独自の選択に従って設定できます。
axes.plot(x, y,marker =”+” , markersize or ms= 20)
マーカーには、言及されている多くの種類があります こちら ただし、主要なものだけを説明します。
marker='+' # plus
marker='o' # circle
marker='s' # square
marker='.' # point
例:
fig, ax = plt.subplots()
ax.plot(x, x+2,marker='+',markersize=20)
ax.plot(x, x+4,marker='o',ms=10) ax.plot(x, x+6,marker='s',ms=15,lw=0) ax.plot(x, x+8,marker='.',ms=10)
すべてのタイプのデータが同じ形式の表現を必要としないため、Matplotlib はさまざまな特別なプロットを提供します。 プロットの選択は、分析中の問題によって異なります。 たとえば、部分対全体の関係に関心がある場合は円グラフ、値またはグループを比較するための棒グラフ、異なる変数間の対応を観察するための散布図などを使用できます。このチュートリアルでは、例について説明します。最も頻繁に使用される 5 つのプロットのみについて説明します。 始めましょう:
1) 折れ線グラフ
これは、データを表す最も単純な形式です。 それらは主に時間に関するデータを分析するために使用されるため、時系列プロットとしても知られています。 上昇傾向は、変数間の正の相関を表し、逆もまた同様です。 天気予報や株式市場の予測から、日々の顧客や売上の監視など、幅広い用途があります。
# Data is collected from worldometer
years = ["1980", "1990", "2000", "2010", "2020"]
Asia = [2649578300, 3226098962, 3741263381, 4209593693, 4641054775]
Europe = [693566517, 720858450, 725558036, 736412989, 747636026]
fig, ax = plt.subplots()
ax.set_title("Population Analysis (1980 - 2020)")
ax.set_xlabel("Years")
ax.set_ylabel("Population in billions")
ax.plot(years, Asia, label="Asia")
ax.plot(years, Europe, label="Europe")
ax.legend()
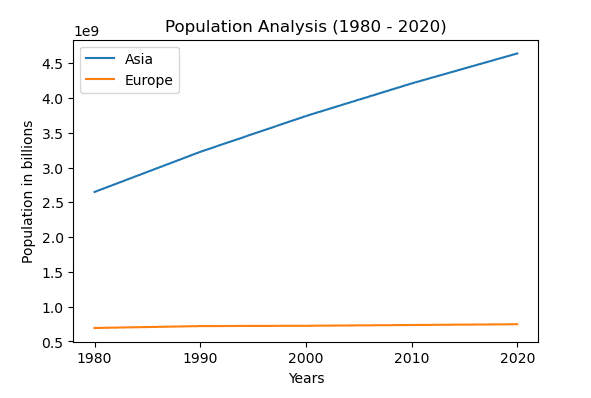
1980 年以降、アジアの人口が指数関数的に増加していることがわかります。
2) 円グラフ
円グラフは、円を部分と全体の関係を表す比例セグメントに分割します。 各部分は合計で 100% になります。 スライスの領域はウェッジとも呼ばれます。
matplotlib.pyplot.pie(data,explode=None,labels=None,colors=None,autopct=None, shadow=False)
- data = プロットする値の配列
- 爆発=プロットのウェッジを分離します
- labels = 異なるスライスを表す文字列
- colors = くさびを上記の色で塗りつぶします
- autopct = ウェッジのラベル数値
- shadow = くさびに影を追加します
labels = [ "Rent", "Utility bills", "Transport", "University fees", "Grocery", "Savings",
]
expenses = [200, 100, 80, 500, 100, 60]
explode = [0.0, 0.0, 0.0, 0.0, 0.0, 0.4]
colors = [ "lightblue", "orange", "lightgreen", "purple", "crimson", "red",
]
fig, ax = plt.subplots()
ax.set_title("University Student Expenses")
ax.pie( expenses, labels=labels, explode=explode, colors=colors, autopct="%.1f%%", shadow=True,
)
plt.show()
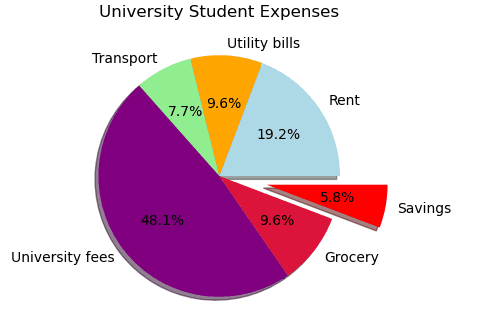
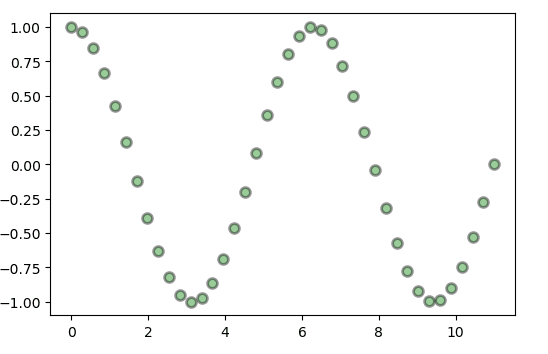
3) 散布図
XY プロットとも呼ばれる散布図は、従属変数と独立変数の間の関係を観察するために使用されます。 傾向分析のために個々のデータ ポイントをプロットします。 外れ値の検出と相関関係は、散布図を使用して簡単に検出できます。
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None,alpha=None, linewidths=None, edgecolors=None)
- (x,y) = データ位置
- s= マーカーのサイズ
- c= マーカーの色のシーケンス
- マーカー=マーカースタイル
- alpha= 透明度
- linewidth= マーカー エッジの線幅
- edgecolors= マーカー エッジの色
x = np.linspace(0, 11, 40)
y = np.cos(x)
fig, ax = plt.subplots()
ax.scatter( x, y, s=50, c="green", marker="o", alpha=0.4, linewidth=2, edgecolor="black",
)
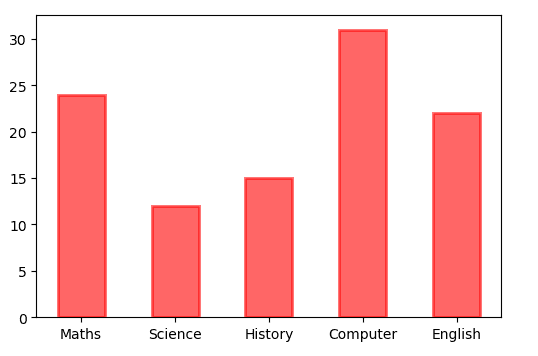
4) 棒グラフ
棒グラフは、垂直または水平に配置された長方形の棒でカテゴリ データを視覚化するために使用されます。 縦棒グラフであるか横棒グラフであるかに応じて、バーの長さまたは高さはその数値を表します。 棒グラフは、特定のグループを比較する場合に非常に役立ちます。
matplotlib.pyplot.bar(x, height, width, bottom, align)
- x= カテゴリ変数
- 高さ=対応する数値
- width= 棒グラフの幅 (デフォルト値は 0.8)
- bottom= バーのベースの開始点 (デフォルト値は 0)
- align= カテゴリ名の配置 (デフォルト値は中央)
注: color、edgecolor、linewidth もカスタマイズできます。
fig,ax = plt.subplots()
courses = ['Maths', 'Science', 'History', 'Computer', 'English']
students = [24,12,15,31,22]
ax.bar(courses,students,width=0.5,color="red",alpha=0.6,edgecolor="red",linewidth=2)
また、bottom 属性を調整して、カテゴリを積み重ねることもできます。
# For Horizontal Bar Chart
ax.barh( courses, students, height=0.7, color="red", alpha=0.6, edgecolor="red", linewidth=2,
)
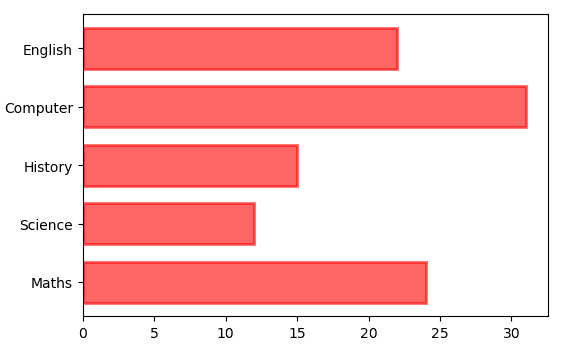
また、bottom 属性を調整して、カテゴリを積み重ねることもできます。
fig,ax = plt.subplots()
courses = ['Maths', 'Science', 'History', 'Computer', 'English']
students = [[24,12,15,31,22],[19,14,19,26,18]] #Male array then female array
ax.bar(courses,students[0],width=0.5,label="male")
ax.bar(courses,students[1],width=0.5,bottom=students[0],label="female")
ax.set_ylabel("No of Students")
ax.legend()
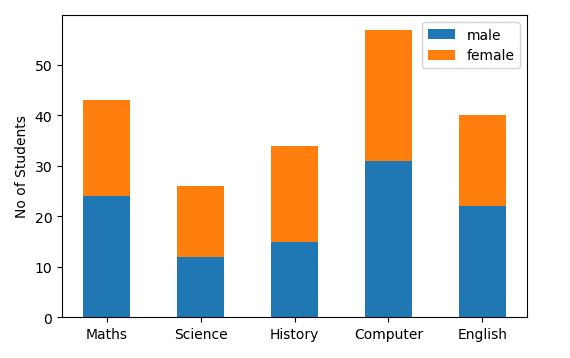
バーの太さと位置をいじって、複数のバーをプロットすることもできます。
fig,ax = plt.subplots()
courses = ['Maths', 'Science', 'History', 'Computer', 'English']
males = (24,12,15,31,22)
females = (19,14,19,26,18)
index=np.arange(5)
bar_width=0.4
ax.bar(index,males,bar_width,alpha=.9,label="Male")
# We will adjust the bar_width so it is placed side to side ax.bar(index + bar_width ,females,bar_width,alpha=.9,label="Female") ax.set_xticks(index + 0.2,courses) # Show labels
ax.legend()

5) ヒストグラム
多くの人は棒グラフと似ているため、棒グラフと混同することがよくありますが、それが表す情報は異なります。 データ ポイントのグループを X 軸にプロットされたビンと呼ばれる範囲に整理し、Y 軸には頻度に関する情報を含めます。 棒グラフとは異なり、数値データのみを表すために使用されます。
matplotlib.pyplot.hist(x,bins=None,cumulative=False,range=None,bottom=None,histtype=’bar’,rwidth=None, color=None, label=None, stacked=False)
- bins = int の場合は等幅のビン、それ以外の場合はシーケンスに依存
- 累積=最後のビンは合計データポイントを提供します(累積頻度に基づく)
- ボトム = ビンの位置
- range = データを切り出す
- histtype= bar,barstacked, step,stepfilled (デフォルト= bar)
- rwidth= ビンの相対的な幅
- stacked= True の場合、複数のデータが互いに積み上げられます
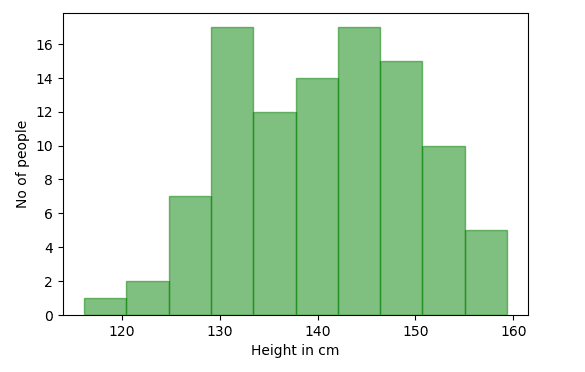
- data = np.random.normal(140, 10,100) # 100人の身長を生成
- ビン = 10
data = np.random.normal(140, 10,100) # Generating height of 100 people
bins = 10
fig,ax = plt.subplots()
ax.set_xlabel("Height in cm")
ax.set_ylabel("No of people")
ax.hist(data,bins=bins, color="green",alpha=0.5,edgecolor="green")
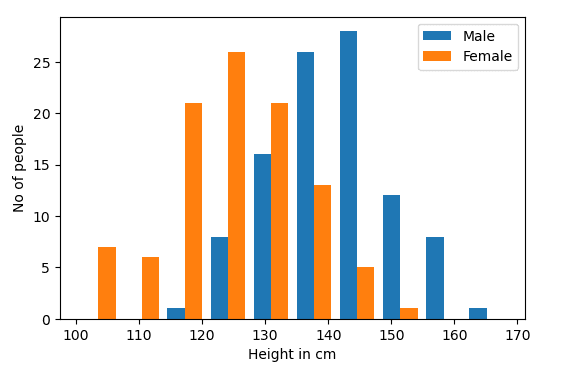
male = np.random.normal(140, 10,100) # Generating height of 100 males
female = np.random.normal(125,10,100) # Generating height of 100 females
bins = 10
fig,ax = plt.subplots()
ax.set_xlabel("Height in cm")
ax.set_ylabel("No of people")
ax.hist([male,female],bins=bins,label=["Male","Female"])
ax.legend()
この記事をお読みいただき、Matplotlib を使用してさまざまな視覚化を実行できるようになったことを願っています。 コメント欄でご意見やご感想をお聞かせください。 ここにリンクがあります Matplotlib ドキュメント、さらに深く掘り下げることに興味がある場合。
カンワル・メーリーン は、データ サイエンスと医療における AI の応用に強い関心を持つ意欲的なソフトウェア開発者です。 Kanwal は、APAC 地域の Google Generation Scholar 2022 に選ばれました。 Kanwal は、流行のトピックに関する記事を書いて技術知識を共有することを好み、技術業界における女性の割合を改善することに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2022/12/introduction-data-visualization-matplotlib.html?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-data-visualization-using-matplotlib

