概要
分野における精度と信頼性の絶え間ない探求 Artificial Intelligence (AI)は革新的なイノベーションをもたらしました。 これらの戦略は、さまざまな質問に対して適切な答えを提供する生成モデルをリードする上で重要です。 さまざまな高度なアプリケーションで Generative AI を使用する際の最大の障壁の XNUMX つは幻覚です。 Meta AI Research が最近発表した「検証の連鎖により大規模な言語モデルにおける幻覚が軽減される」では、テキスト生成時に幻覚を直接軽減するための簡単なテクニックについて説明しています。
この記事では、幻覚の問題について学び、論文で言及されている CoVe の概念と、LLM、LangChain フレームワーク、および LangChain Expression Language (LCEL) を使用してカスタム チェーンを作成して CoVe を実装する方法について説明します。
学習目標
- LLM における幻覚の問題を理解する。
- 幻覚を軽減するための Chain of Verification (CoVe) メカニズムについて学びます。
- CoVe の長所と短所について知ってください。
- LangChain を使用して CoVe を実装し、LangChain 式言語を理解する方法を学びます。
この記事は、の一部として公開されました データサイエンスブログ。
目次
LLM における幻覚問題とは何ですか?
まず、LLM における幻覚の問題について学んでみましょう。 LLM モデルは、自己回帰生成アプローチを使用して、前のコンテキストを考慮して次の単語を予測します。 頻繁に使用されるテーマについては、モデルは、正しいトークンに高い確率を自信を持って割り当てるのに十分な例を確認しています。 ただし、モデルは珍しいトピックやなじみのないトピックについてトレーニングされていないため、高い信頼度で不正確なトークンを配信する可能性があります。 その結果、もっともらしく聞こえるが間違った情報が幻聴されることになります。
以下は、Open AI の ChatGPT における幻覚の例の 2020 つです。インドの著者が XNUMX 年に出版した本「Economics of Small Things」について私が質問しましたが、モデルは自信満々に間違った答えを吐き出し、それを別の本の本と混同しました。ノーベル賞受賞者アビジット・バナジー著「貧しい経済学」。

検証連鎖 (CoVe) 手法
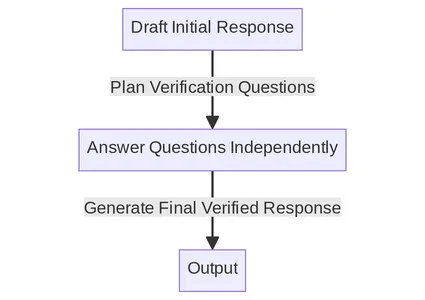
CoVe メカニズムは、プロンプトと一貫性チェックを組み合わせて、LLM の自己検証システムを作成します。 以下は、論文に記載されている主な手順です。 各ステップを XNUMX つずつ詳しく理解していきます。
チェーンプロセスの概要
- ベースライン応答の生成: クエリが与えられた場合、LLM を使用して応答を生成します。
- 計画の検証: クエリとベースライン応答の両方を考慮して、元の応答に間違いがあるかどうかを自己分析するのに役立つ確認用の質問のリストを生成します。
- 検証の実行: 各確認質問に順番に回答し、その回答を元の回答と照合して矛盾や間違いがないか確認します。
- 最終検証済み応答を生成します。 発見された矛盾 (存在する場合) を考慮して、検証結果を組み込んだ改訂された応答を生成します。
詳細な例を使用したチェーン プロセスの理解
初期応答の生成
最初に、初期応答を生成するための特別なプロンプトを表示せずに、クエリを LLM に渡します。 これは CoVe プロセスの開始点として機能します。 このようなベースライン反応は幻覚を起こしやすいことが多いため、CoVe 技術は後の段階でこれらのエラーを発見して修正しようとします。
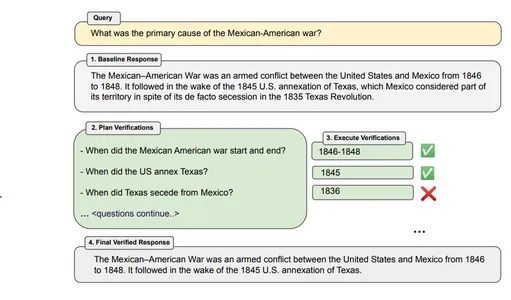
例– 「米墨戦争の主な原因は何ですか?」
ボットの応答 – 米墨戦争は、1846 年から 1848 年にかけて米国とメキシコの間で起きた武力紛争です。この戦争は、1845 年の米国によるテキサス併合の後に続きました。テキサス州は、事実上のテキサス州であるにもかかわらず、テキサス州の領土の一部と見なされていました。 1835年のテキサス革命で脱退。
計画の検証
クエリとベースライン回答に基づいて確認用の質問を作成し、ベースライン回答の事実主張を調査できるようにします。 これを実装するには、クエリとベースライン応答の両方に基づいて一連の確認質問をモデル化するようプロンプトを作成します。 確認の質問は柔軟であり、元のテキストと正確に一致する必要はありません。
例 – メキシコとアメリカの戦争はいつ始まり、いつ終わりましたか? アメリカがテキサスを併合したのはいつですか? テキサスはいつメキシコから分離しましたか?
検証の実行
確認用の質問を計画したら、これらの質問に個別に答えることができます。 この文書では、検証を実行するための 4 つの異なる方法について説明します。
1. ジョイント – この場合、確認用の質問の計画と実行は XNUMX つのプロンプトで行われます。 質問とその回答は、同じ LLM プロンプトで提供されます。 検証応答が幻覚に見える可能性があるため、この方法は通常推奨されません。
2. 2ステップ – 計画と実行は、別個の LLM プロンプトを使用して XNUMX つのステップで別々に行われます。 まず、確認用の質問を生成し、次にそれらの質問に答えます。
3. 因数分解 – ここでは、各検証質問は同じ大きな応答ではなく独立して回答され、ベースラインの元の応答は含まれません。 これにより、異なる確認用の質問間の混乱を避けることができ、より多くの質問を処理できるようになります。
4. 因数分解 + 修正 – この方法では追加のステップが追加されます。 すべての検証質問に回答した後、CoVe メカニズムはその回答が元のベースライン応答と一致するかどうかをチェックします。 これは、追加のプロンプトを使用して別の手順で実行されます。
外部ツールまたは自己 LLM: 私たちの応答を検証し、検証回答を提供するツールが必要です。 これは、LLM 自体または外部ツールを使用して実行できます。 より高い精度が必要な場合は、LLM に依存する代わりに、ユースケースに応じて、インターネット検索エンジン、参照ドキュメント、Web サイトなどの外部ツールを使用できます。
最終検証済み応答
この最後のステップでは、改善され検証された応答が生成されます。 数回のプロンプトが使用され、ベースライン応答と検証質問の回答の以前のすべてのコンテキストが含まれます。 「因子+改訂」方法が使用された場合、クロスチェックされた不一致の出力も提供されます。
CoVe 技術の限界
Chain of Verification はシンプルだが効果的な手法のように見えますが、それでもいくつかの制限があります。
- 幻覚が完全に除去されていない: 回答から幻覚が完全に除去されることを保証するものではないため、誤解を招く情報が生成される可能性があります。
- コンピューティング集中型: 応答の生成とともに検証を生成および実行すると、計算のオーバーヘッドとコストが増加する可能性があります。 したがって、プロセスが遅くなったり、コンピューティングコストが増加したりする可能性があります。
- モデル固有の制限: この CoVe 手法の成功は、モデルの機能と、間違いを特定して修正する能力に大きく依存します。
CoVe の LangChain 実装
アルゴリズムの基本概要
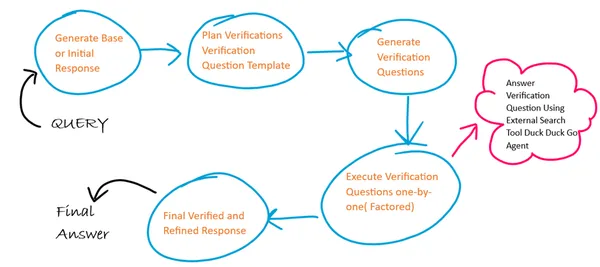
ここでは、CoVe の 4 つのステップのそれぞれに 4 つの異なるプロンプト テンプレートを使用し、各ステップで前のステップの出力が次のステップの入力として機能します。 また、確認質問の実行には因数分解アプローチに従います。 当社では、外部のインターネット検索ツール エージェントを使用して、確認用の質問に対する回答を生成します。
ステップ 1: ライブラリのインストールとロード
!pip install langchain duckduckgo-searchステップ 2: LLM インスタンスを作成して初期化する
ここでは、無料で入手できるため、Langchain で Google Palm LLM を使用しています。 これを使用して Google Palm の API キーを生成できます Google アカウントを使用してログインします。
from langchain import PromptTemplate
from langchain.llms import GooglePalm
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
API_KEY='Generated API KEY'
llm=GooglePalm(google_api_key=API_KEY)
llm.temperature=0.4
llm.model_name = 'models/text-bison-001'
llm.max_output_tokens=2048
ステップ 3: 初期ベースライン応答を生成する
ここで、最初のベースライン応答を生成するためのプロンプト テンプレートを作成します。このテンプレートを使用すると、ベースライン応答 LLM チェーンが作成されます。
LLM チェーンは、LangChain 式言語を使用してチェーンを構成します。 ここでは、プロンプト テンプレートを LLM モデル (|) でチェーン (|) し、最後に出力パーサーを指定します。
BASELINE_PROMPT = """Answer the below question which is asking for a concise factual answer. NO ADDITIONAL DETAILS.
Question: {query}
Answer:"""
# Chain to generate initial response
baseline_response_prompt_template = PromptTemplate.from_template(BASELINE_PROMPT)
baseline_response_chain = baseline_response_prompt_template | llm | StrOutputParser()ステップ 4: 確認質問用の質問テンプレートを生成する
ここで、次のステップで確認質問を生成するのに役立つ確認質問テンプレートを構築します。
VERIFICATION_QUESTION_TEMPLATE = """Your task is to create a verification question based on the below question provided.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things] ?
Explanation: In the above example the verification question focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (book name).
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and generate verification question.
Actual Question: {query}
Final Verification Question:"""
# Chain to generate a question template for verification answers
verification_question_template_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_TEMPLATE)
verification_question_template_chain = verification_question_template_prompt_template | llm | StrOutputParser()ステップ 5: 確認用の質問を生成する
次に、上で定義した確認質問テンプレートを使用して確認質問を生成します。
VERIFICATION_QUESTION_PROMPT= """Your task is to create a series of verification questions based on the below question, the verfication question template and baseline response.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question Template: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things]?
Example Baseline Response: Jhumpa Lahiri
Example Verification Question: 1. Was God of Small Things written by Jhumpa Lahiri? If not who wrote God of Small Things ?
Explanation: In the above example the verification questions focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (name of book) based on the template and substitutes entity values from the baseline response.
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and substitute the entity values from the baseline response to generate verification questions.
Actual Question: {query}
Baseline Response: {base_response}
Verification Question Template: {verification_question_template}
Final Verification Questions:"""
# Chain to generate the verification questions
verification_question_generation_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_PROMPT)
verification_question_generation_chain = verification_question_generation_prompt_template | llm | StrOutputParser()
ステップ 6: 確認用の質問を実行する
ここでは、外部検索ツール エージェントを使用して確認質問を実行します。 このエージェントは、LangChain の Agent and Tools モジュールと DuckDuckGo 検索モジュールを使用して構築されます。
注 – 検索エージェントには時間制限があり、複数のリクエストを実行するとリクエスト間の時間制限によりエラーが発生する可能性があるため、注意して使用してください。
from langchain.agents import ConversationalChatAgent, AgentExecutor
from langchain.tools import DuckDuckGoSearchResults
#create search agent
search = DuckDuckGoSearchResults()
tools = [search]
custom_system_message = "Assistant assumes no knowledge & relies on internet search to answer user's queries."
max_agent_iterations = 5
max_execution_time = 10
chat_agent = ConversationalChatAgent.from_llm_and_tools(
llm=llm, tools=tools, system_message=custom_system_message
)
search_executor = AgentExecutor.from_agent_and_tools(
agent=chat_agent,
tools=tools,
return_intermediate_steps=True,
handle_parsing_errors=True,
max_iterations=max_agent_iterations,
max_execution_time = max_execution_time
)
# chain to execute verification questions
verification_chain = RunnablePassthrough.assign(
split_questions=lambda x: x['verification_questions'].split("n"), # each verification question is passed one by one factored approach
) | RunnablePassthrough.assign(
answers = (lambda x: [{"input": q,"chat_history": []} for q in x['split_questions']])| search_executor.map() # search executed for each question independently
) | (lambda x: "n".join(["Question: {} Answer: {}n".format(question, answer['output']) for question, answer in zip(x['split_questions'], x['answers'])]))# Create final refined response
ステップ 7: 最終的な洗練された応答を生成する
ここで、プロンプト テンプレートと LLM チェーンを定義する最終的な洗練された回答を生成します。
FINAL_ANSWER_PROMPT= """Given the below `Original Query` and `Baseline Answer`, analyze the `Verification Questions & Answers` to finally provide the refined answer.
Original Query: {query}
Baseline Answer: {base_response}
Verification Questions & Answer Pairs:
{verification_answers}
Final Refined Answer:"""
# Chain to generate the final answer
final_answer_prompt_template = PromptTemplate.from_template(FINAL_ANSWER_PROMPT)
final_answer_chain = final_answer_prompt_template | llm | StrOutputParser()ステップ 8: すべてのチェーンをまとめる
ここで、前に定義したすべてのチェーンをまとめて、一度に順番に実行できるようにします。
chain = RunnablePassthrough.assign(
base_response=baseline_response_chain
) | RunnablePassthrough.assign(
verification_question_template=verification_question_template_chain
) | RunnablePassthrough.assign(
verification_questions=verification_question_generation_chain
) | RunnablePassthrough.assign(
verification_answers=verification_chain
) | RunnablePassthrough.assign(
final_answer=final_answer_chain
)
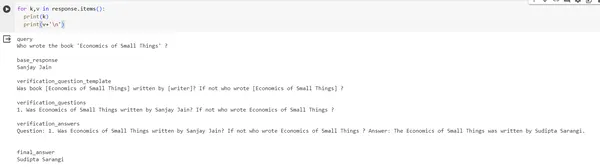
response = chain.invoke({"query": "Who wrote the book 'Economics of Small Things' ?"})
print(response)#output of response
{'query': "Who wrote the book 'Economics of Small Things' ?", 'base_response': 'Sanjay Jain', 'verification_question_template': 'Was book [Economics of Small Things] written by [writer]? If not who wrote [Economics of Small Things] ?', 'verification_questions': '1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ?', 'verification_answers': 'Question: 1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ? Answer: The Economics of Small Things was written by Sudipta Sarangi n', 'final_answer': 'Sudipta Sarangi'}出力画像:
まとめ
この研究で提案されている検証連鎖 (CoVe) 手法は、大きな言語モデルを構築し、応答についてより批判的に考え、必要に応じて修正することを目的とした戦略です。 これは、この方法では検証がより小規模で管理しやすいクエリに分割されるためです。 また、モデルが以前の応答をレビューすることを禁止すると、エラーや「幻覚」の繰り返しを避けるのに役立つことが示されています。 モデルに答えを再確認するよう要求するだけで、結果が大幅に向上します。 外部ソースから情報を取得できるようにするなど、CoVe にさらなる機能を与えることは、その有効性を高める XNUMX つの方法かもしれません。
主要な取り組み
- チェーン プロセスは、応答のさまざまな部分を検証できるようにするテクニックをさまざまに組み合わせた便利なツールです。
- 多くの利点とは別に、チェーン プロセスには特定の制限があり、さまざまなツールやメカニズムを使用して軽減できます。
- LangChain パッケージを利用して、この CoVe プロセスを実装できます。
よくある質問
A. 幻覚をさまざまなレベルで軽減するには複数の方法があります。プロンプト レベル (思考のツリー、思考の連鎖)、モデル レベル (コントラスト層による DoLa デコード)、およびセルフチェック (CoVe)。
A. Google Search API などの外部検索ツールのサポートを使用することで、CoVe での検証プロセスを改善できます。また、ドメインやカスタムのユースケースでは、RAG などの取得技術を使用できます。
A. 現在、このメカニズムを実装したすぐに使用できるオープンソース ツールはありませんが、Serp API、Google 検索、Lang Chains を使用して独自にツールを構築することはできます。
A. 検索拡張生成 (RAG) 技術は、LLM がこのドメイン固有のデータからの検索に基づいて事実として正しい応答を生成できる、ドメイン固有のユースケースに使用されます。
A. この論文では Llama 65B モデルを LLM として使用し、その後、数ショットの例を使用したプロンプト エンジニアリングを使用して質問を生成し、モデルにガイダンスを与えました。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/12/chain-of-verification-implementation-using-langchain-expression-language-and-llm/

