Ahrefs Blog は WordPress を利用していますが、サイトの残りの部分の多くは React などの JavaScript を利用していることをご存知ですか?
現在の Web の現実は、JavaScript があらゆる場所に存在していることです。 ほとんどの Web サイトは、対話性を追加し、ユーザー エクスペリエンスを向上させるために、ある種の JavaScript を使用しています。
しかし、非常に多くの Web サイトで使用されている JavaScript のほとんどは SEO にまったく影響を与えません。 多くのカスタマイズを行わずに通常の WordPress をインストールしている場合は、おそらくどの問題も当てはまらないでしょう。
問題が発生するのは、JavaScript を使用してページ全体を構築したり、要素を追加または削除したり、ページ上にすでにある内容を変更したりする場合です。 一部のサイトでは、これをメニュー、製品や価格の取得、複数のソースからのコンテンツの取得、または場合によってはサイト上のあらゆるものに使用しています。 これがあなたのサイトのように思われる場合は、読み続けてください。
私たちは、JavaScript フレームワークで構築されたシステムとアプリ全体、さらにはヘッドレスまたは分離された JavaScript のセンスを備えた一部の従来の CMS を目にしています。 CMS はデータのバックエンド ソースとして使用されますが、フロントエンドのプレゼンテーションは JavaScript によって処理されます。
私は、SEO 担当者が JavaScript のプログラミング方法を学ぶ必要があると言っているのではありません。 コードに触れる可能性は低いので、実際にはお勧めしません。 SEO が知っておく必要があるのは、Google が JavaScript をどのように処理するか、そして問題のトラブルシューティングを行う方法です。
JavaScript SEO はの一部です 技術的なSEO (検索エンジン最適化) により、JavaScript を多用した Web サイトのクロールとインデックス作成が容易になり、検索も容易になります。 目標は、これらの Web サイトを見つけてもらい、 検索エンジンで上位に表示される.
JavaScript は SEO にとって悪ではありませんし、悪でもありません。 これは多くの SEO 担当者が慣れ親しんでいるものとは異なり、少し学習曲線が必要です。
プロセスの多くは、SEO 担当者がすでに見慣れているものと似ていますが、若干の違いがある場合があります。 実際には JavaScript ではなく、主に HTML コードを参照することになります。
通常のページ上の SEO のベスト プラクティスはすべて引き続き適用されます。 見る オンページSEOに関するガイド.
使用しているフレームワークにまだ組み込まれていない場合は、多くの基本的な SEO 要素を処理するための使い慣れたプラグイン タイプのオプションも見つかります。 JavaScript フレームワークの場合、これらはモジュールと呼ばれ、モジュールをインストールするためのパッケージ オプションが多数見つかります。
次のような人気のあるフレームワークの多くにはバージョンがあります。 反応する, 「React Helmet」のようにフレームワーク + モジュール名で検索すると見つかる Vue、Angular、Svelte です。 メタ タグ、ヘルメット、およびヘッドはすべて、同様の機能を持つ人気のあるモジュールであり、SEO に必要な多くの人気のあるタグを設定できます。
JavaScript は、構築の容易さやパフォーマンスなど、いくつかの点で従来の HTML よりも優れています。 JavaScript は、(HTML や CSS のように) 段階的に解析できず、ページの読み込みやパフォーマンスに負荷がかかる可能性があるなど、ある意味、より悪いです。 多くの場合、パフォーマンスと引き換えに機能が求められることがあります。
JavaScript は完璧ではなく、常に仕事に適したツールであるとは限りません。 開発者は、おそらくより良い解決策がある場合にそれを過剰に使用します。 しかし時には、与えられたものを使って働かなければならないこともあります。
これらは、JavaScript サイトを操作するときに遭遇する可能性のある一般的な SEO 問題の多くです。
固有のタイトルタグとメタディスクリプションを持つ
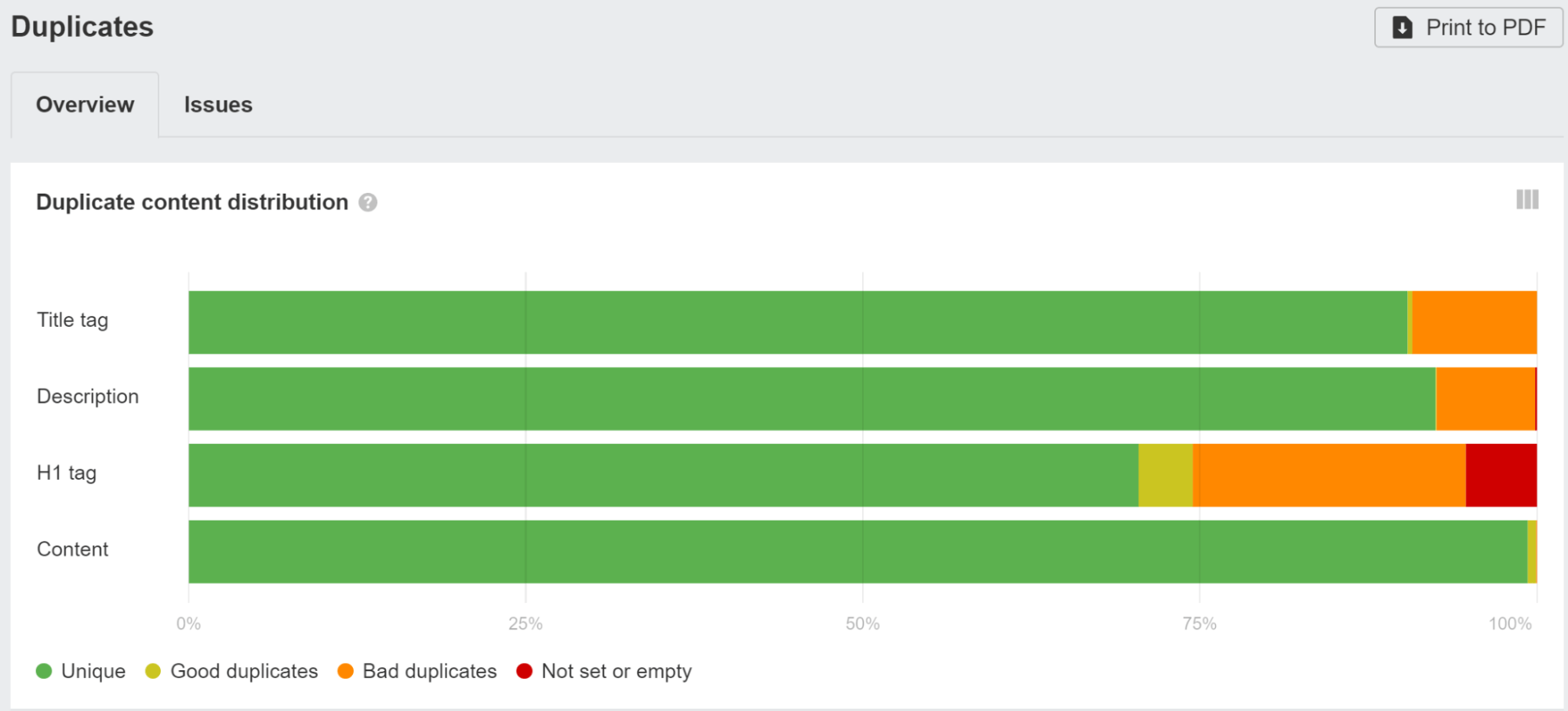
あなたはまだユニークなものを持ちたいと思うでしょう タイトルタグ & メタ記述 ページ全体にわたって。 JavaScript フレームワークの多くはテンプレート化されているため、すべてのページまたはページのグループに同じタイトルまたはメタディスクリプションが使用される状況に簡単に陥る可能性があります。
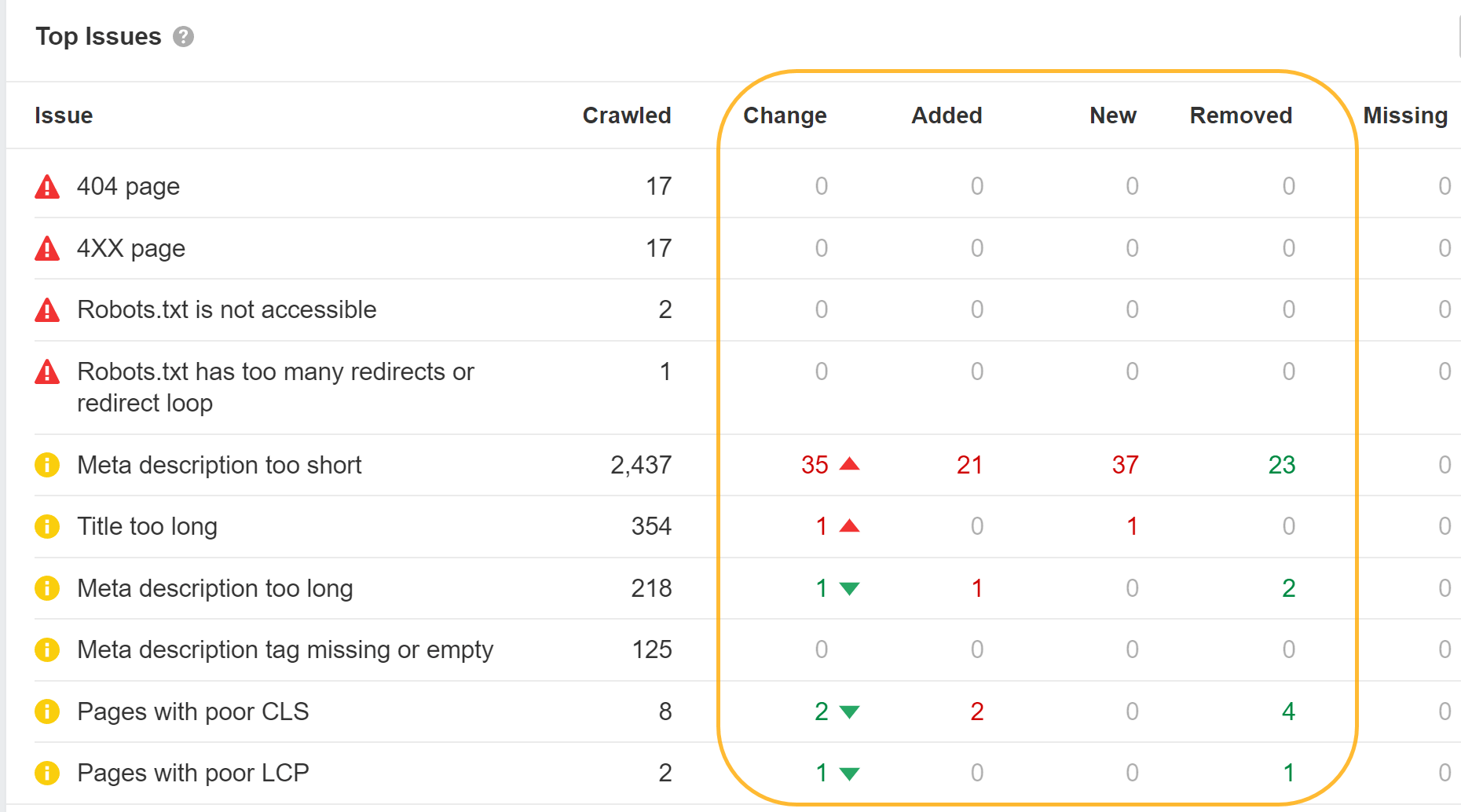
チェック 重複 Ahrefsのレポート サイト監査 いずれかのグループをクリックすると、見つかった問題に関する詳細データが表示されます。
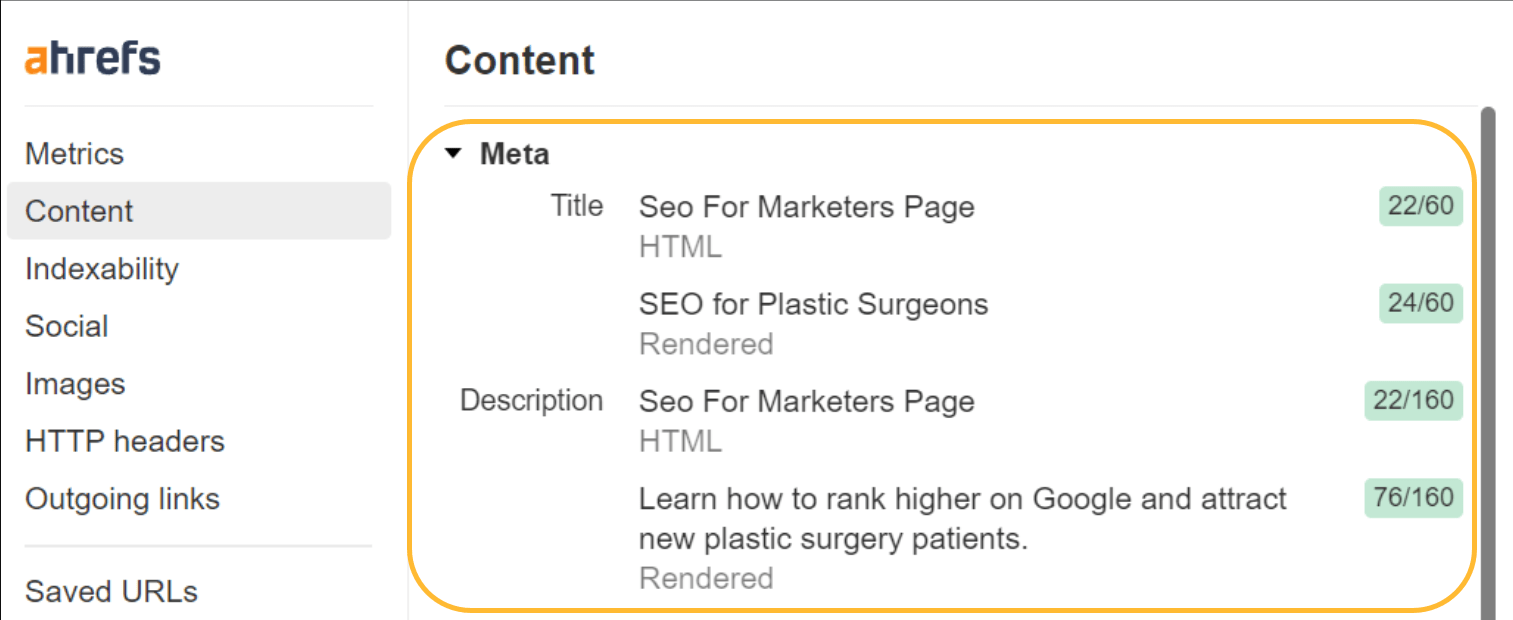
Helmet などの SEO モジュールの XNUMX つを使用して、各ページにカスタム タグを設定できます。
JavaScript を使用して、設定したデフォルト値を上書きすることもできます。 Google はこれを処理し、上書きされたタイトルまたは説明を使用します。 ただし、ユーザーにとってタイトルは問題となる可能性があります。ブラウザに XNUMX つのタイトルが表示され、上書きされるとフラッシュに気づくことがあります。
タイトルが点滅している場合は、Ahrefs の SEOツールバー 生の HTML とレンダリングされたバージョンの両方を表示します。
いずれにせよ、Google はあなたのタイトルやメタ ディスクリプションを使用することはできません。 先ほども述べたように、タイトルはユーザーにとってクリーンアップする価値があります。 ただし、メタディスクリプションのこれを修正しても、実際には違いはありません。
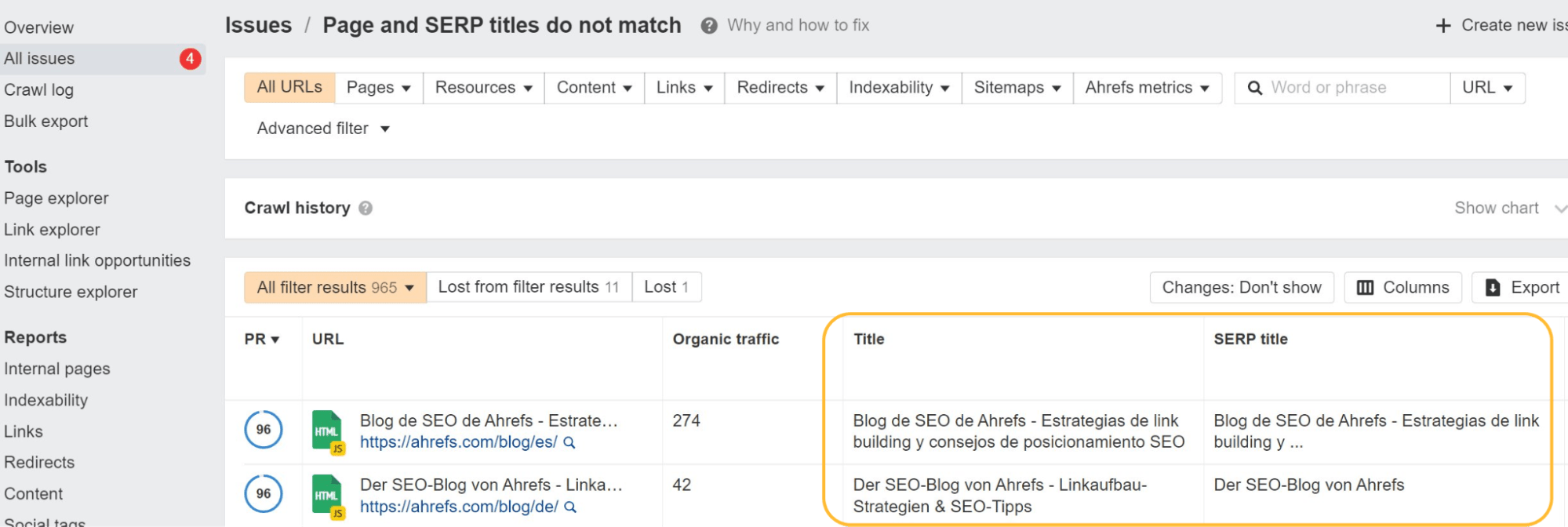
Google の書き換えを研究したところ、次のことがわかりました。 Google は 33.4% の確率でタイトルを上書きします & 62.78% の確率でメタ ディスクリプション。 Site Audit では、Google が変更したタイトル タグも表示されます。
正規タグの問題
Googleは何年もの間、尊重していないと主張してきた 正規タグ JavaScript で挿入されます。 最終的に、タグがまだ存在しない場合の例外をドキュメントに追加しました。 その変化を引き起こしたのは私です。 Google がうまくいかないと言っていたときに、私はこれがうまくいくことを示すためにテストを実行しました。
すでに正規タグが存在しており、別のタグを追加するか、既存のタグを JavaScript で上書きすると、XNUMX つの正規タグが与えられることになります。 この場合、Google はどれを使用するか、他のタグを優先して正規タグを無視するかを判断する必要があります。 正規化シグナル.
「すべてのページに自己参照の正規タグを含める」という標準的な SEO アドバイスは、多くの SEO を悩ませます。 開発者はその要件を受け入れ、末尾にスラッシュがあるページとないページを自己正規ページにします。
example.com/page 正規化された example.com/page & example.com/page/ 正規化された example.com/page/。 おっと、それは違います! おそらく、これらのバージョンの XNUMX つを別のバージョンにリダイレクトする必要があるでしょう。
組み合わせたいパラメータ化されたバージョンでも同じことが発生する可能性がありますが、それぞれが自己参照です。
Googleは最も制限の厳しいメタロボットタグを使用しています
メタロボットのタグ, Google は、場所に関係なく、常に最も制限の厳しいオプションを選択します。
生の HTML にインデックス タグがあり、レンダリングされた HTML に noindex タグがある場合、Google はそれを noindex として扱います。 生の HTML に noindex タグがあり、それを JavaScript を使用してインデックス タグで上書きした場合でも、そのページは noindex として扱われます。
nofollow タグでも同様に機能します。 Googleは最も制限的な選択肢を取るつもりだ。
画像に alt 属性を設定する
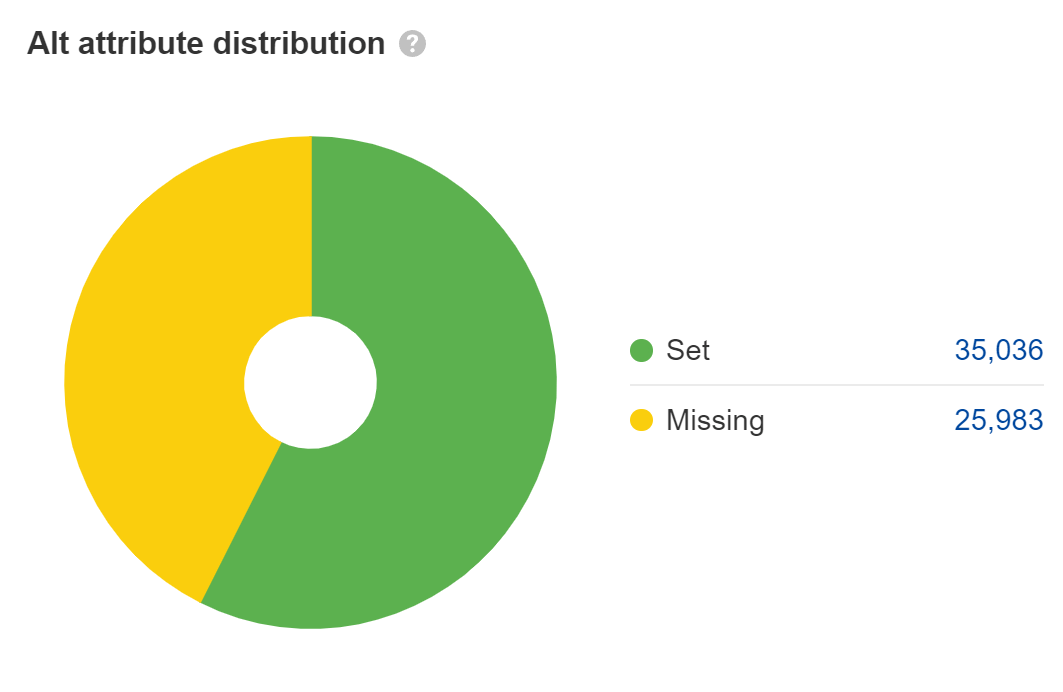
見つけて下さい alt属性 アクセシビリティの問題であり、法的問題に発展する可能性があります。 ほとんどの大企業はウェブサイト上の ADA コンプライアンス問題で訴えられており、中には年に複数回訴えられる企業もあります。 メインコンテンツ画像についてはこの問題を修正したいと思いますが、プレースホルダーや装飾画像など、alt 属性を空白のままにできるものについては修正しません。
Web 検索の場合、alt 属性のテキストはページ上のテキストとしてカウントされますが、実際に果たす役割はそれだけです。 私の意見では、SEO におけるその重要性は過大評価されがちです。 ただし、画像検索や画像ランキングには役立ちます。
多くの JavaScript 開発者は alt 属性を空白のままにしているため、自分の属性がそこにあることを再確認してください。 見てください 画像 中で報告する サイト監査 これらを見つけるために。
JavaScript ファイルのクロールを許可する
ページの一部を構築したりコンテンツに追加したりするためにリソースが必要な場合は、リソースへのアクセスをブロックしないでください。 ページを適切に表示できるように、Google はリソースにアクセスしてダウンロードする必要があります。 あなたの中で robots.txtの、必要なリソースをクロールできるようにする最も簡単な方法は、以下を追加することです。
User-Agent: GooglebotAllow: .jsAllow: .css
また、robots.txt ファイルで、API 呼び出しなどのリクエストを行っている可能性のあるサブドメインまたは追加のドメインがないか確認してください。
robots.txt でリソースをブロックした場合は、Chrome デベロッパー ツールの [ネットワーク] タブにあるブロック オプションを使用して、ページ コンテンツに影響があるかどうかを確認できます。 ファイルを選択してブロックし、ページを再ロードして変更が加えられたかどうかを確認します。
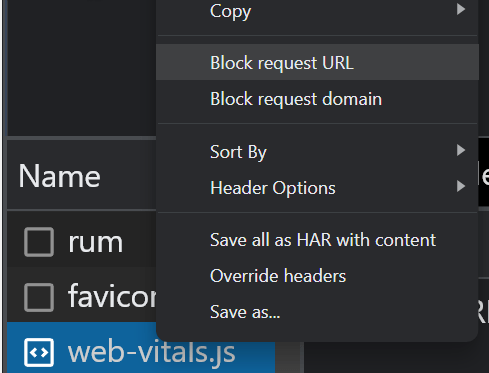
Google があなたのコンテンツを認識しているかどうかを確認する
JavaScript 機能を備えた多くのページでは、デフォルトではすべてのコンテンツが Google に表示されない場合があります。 開発者に相談すると、これをドキュメント オブジェクト モデル (DOM) が読み込まれていないと言うかもしれません。 これは、コンテンツがデフォルトでは読み込まれず、クリックなどのアクションによって後で読み込まれる可能性があることを意味します。
簡単なチェックとしては、Google で引用符で囲まれたコンテンツのスニペットを検索するだけです。 「コンテンツの一部のフレーズ」を検索し、そのページが検索結果に返されるかどうかを確認します。 表示されている場合は、コンテンツが閲覧された可能性があります。
サイドノート。
デフォルトで非表示になっているコンテンツは、 SERPs。 モバイル バージョンはユーザー エクスペリエンスを重視して機能が削られていることが多いため、確認することが特に重要です。
右クリックして「検査」オプションを使用することもできます。 「要素」タブ内でテキストを検索します。
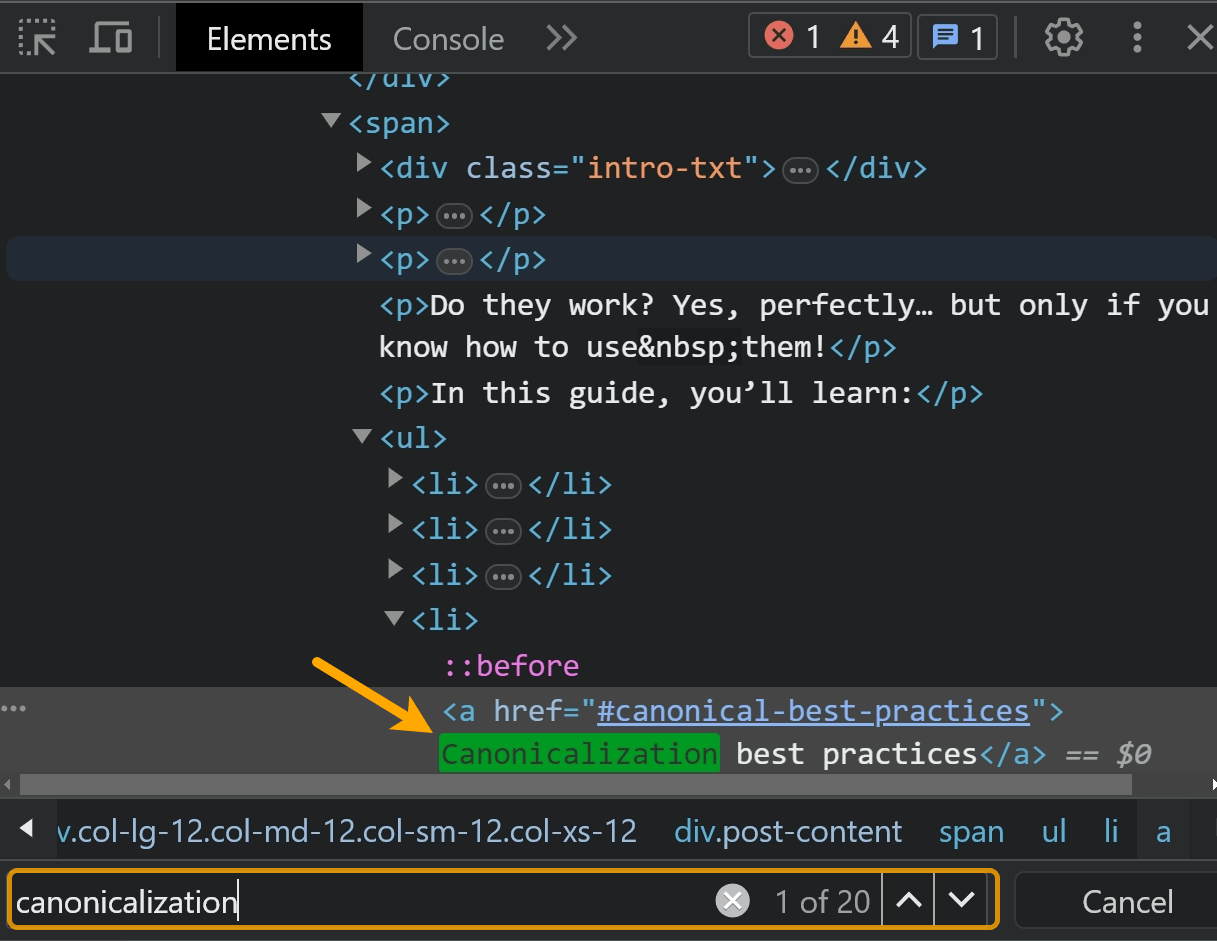
最良のチェックは、Google Search Console の URL 検査ツールなど、Google のテスト ツールの XNUMX つのコンテンツ内を検索することです。 これについては後ほど詳しく説明します。
アコーディオンやドロップダウンの背後にあるものは必ずチェックします。 多くの場合、これらの要素は、クリックされたときにコンテンツをページに読み込むリクエストを作成します。 Google はクリックしないので、コンテンツは表示されません。
Inspect メソッドを使用してコンテンツを検索する場合は、必ずコンテンツをコピーしてからページをリロードするか、検索する前にページをシークレット ウィンドウで開いてください。
要素をクリックし、そのアクションが実行されたときにコンテンツが読み込まれている場合は、そのコンテンツが表示されます。 ページを新たにロードすると、同じ結果が表示されない場合があります。
重複するコンテンツの問題
JavaScript では、同じコンテンツに対して複数の URL が存在する可能性があり、 コンテンツを複製する 問題。 これは、大文字、末尾のスラッシュ、ID、ID を持つパラメータなどが原因である可能性があります。したがって、これらはすべて存在する可能性があります。
domain.com/Abcdomain.com/abcdomain.com/123domain.com/?id=123
XNUMX つのバージョンのみをインデックス付けしたい場合は、自己参照の正規タグと、メイン バージョンを参照する他のバージョンの正規タグを設定するか、理想的には他のバージョンをメイン バージョンにリダイレクトする必要があります。
チェック 重複 中で報告する サイト監査。 どの重複クラスターに正規タグが設定されており、どのクラスターに問題があるのかを分析します。
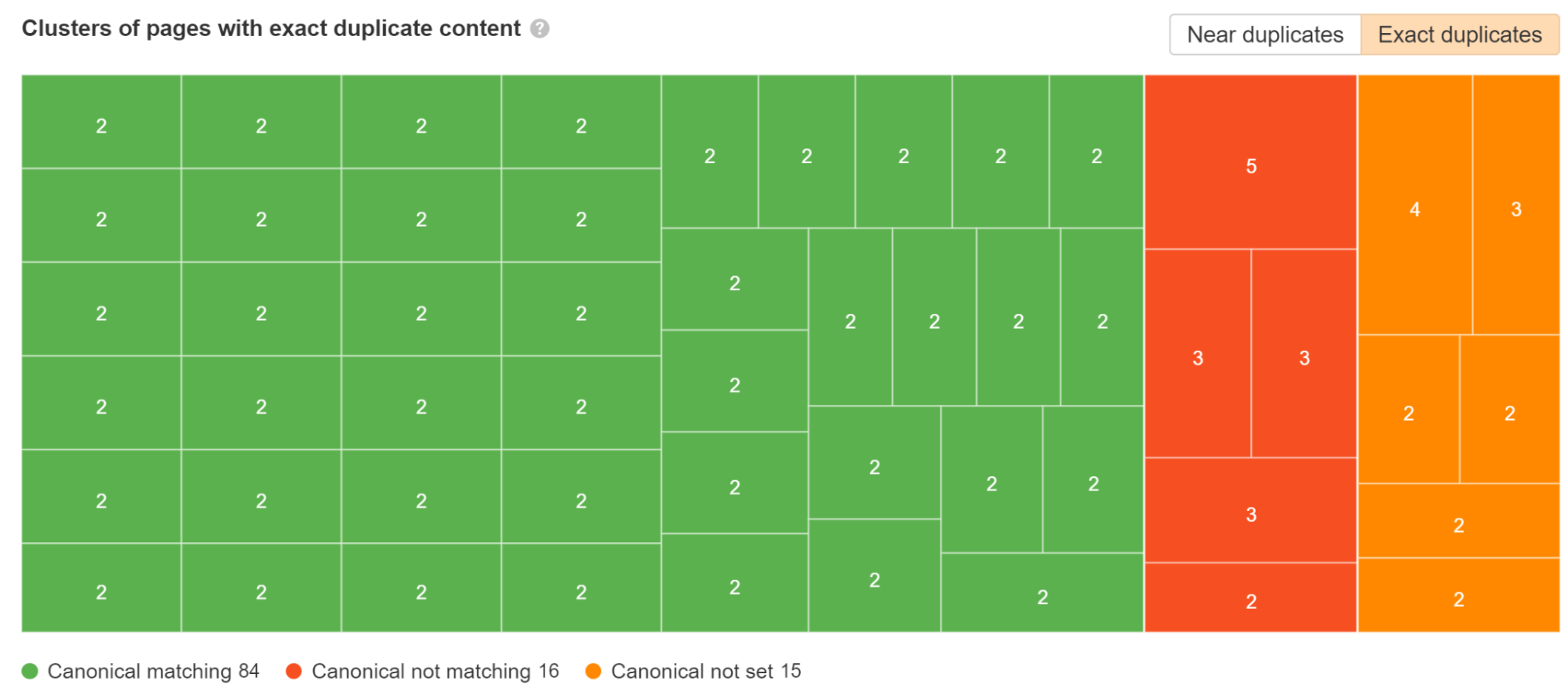
JavaScript フレームワークに関する一般的な問題は、ページが末尾のスラッシュの有無にかかわらず存在できることです。 理想的には、好みのバージョンを選択し、そのバージョンに自己参照正規タグがあることを確認してから、他のバージョンを好みのバージョンにリダイレクトします。
App Shell モデルでは、最初の HTML 応答に表示されるコンテンツとコードはほとんどない場合があります。 実際、サイト上のすべてのページに同じコードが表示される場合があり、このコードは他の Web サイトのコードとまったく同じである可能性があります。
Site Audit で単語数の少ない URL が多数表示される場合は、この問題が発生している可能性があります。
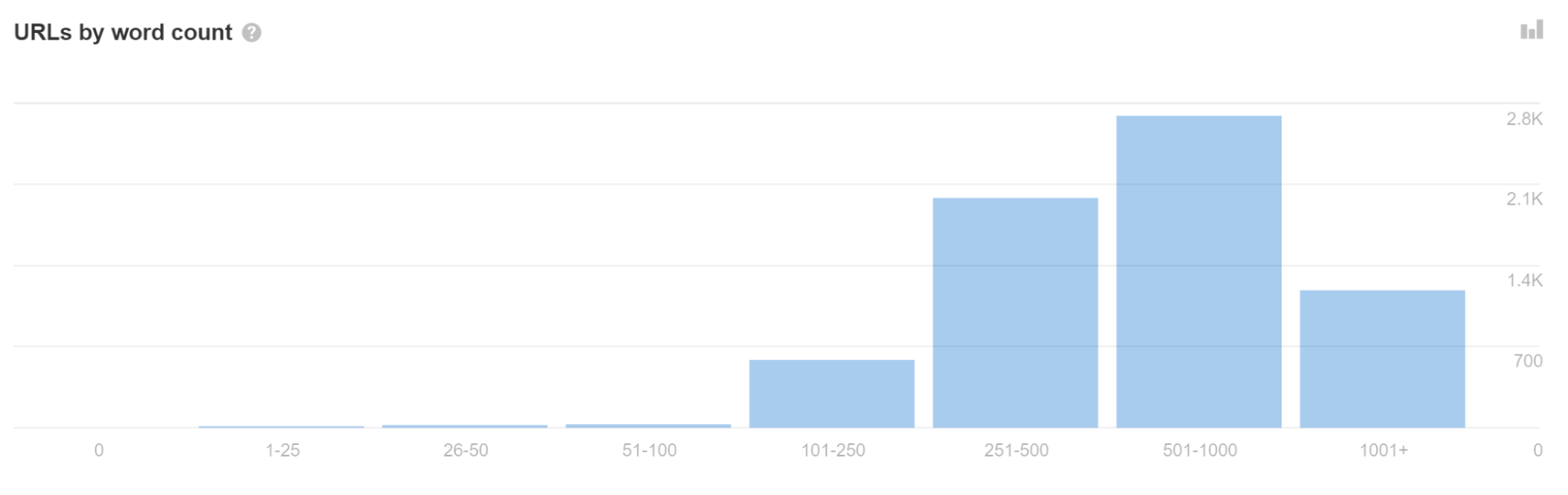
これにより、ページが重複として扱われ、すぐにレンダリングされなくなる場合があります。 さらに悪いことに、間違ったページや間違ったサイトが検索結果に表示される可能性があります。 これは時間の経過とともに解決されるはずですが、特に新しい Web サイトでは問題が発生する可能性があります。
URL ではフラグメント (#) を使用しないでください
# ブラウザ用に定義された機能がすでにあります。 クリックすると、ブログの「目次」機能のように、ページの別の部分にリンクします。 通常、サーバーは # の後には何も処理しません。 したがって、次のような URL の場合 abc.com/#something、# の後のものは通常無視されます。
JavaScript 開発者は、# をさまざまな目的のトリガーとして使用することを決定しており、それが混乱を引き起こします。 悪用される最も一般的な方法は、ルーティングと URLパラメータ。 はい、機能します。 いいえ、そうすべきではありません。
JavaScript フレームワークには通常、ルート (パス) と呼ばれるものをマップするルーターがあります。 クリーンURL。 多くの JavaScript 開発者はルーティングにハッシュ (#) を使用します。 これは、Vue と一部の Angular の以前のバージョンで特に問題になります。
Vue でこれを修正するには、開発者と協力して以下を変更します。
Vue router: Use ‘History’ Mode instead of the traditional ‘Hash’ Mode.
const router = new VueRouter ({mode: ‘history’,router: [] //the array of router links)}
? の代わりに # を使用する傾向が高まっています。 特にトラッキングに使用されるようなパッシブ URL パラメーターの場合、フラグメント識別子として使用されます。 混乱と問題があるため、私はそれをお勧めしない傾向があります。 状況によっては、多くの不要なパラメータを削除しても問題ないかもしれません。
サイトマップを作成する
クリーンな URL を可能にするルーター オプションには、通常、サイトマップも作成できる追加モジュールがあります。 「Vue ルーター サイトマップ」など、システム + ルーターのサイトマップを検索すると見つかります。
レンダリング ソリューションの多くには、サイトマップ オプションがある場合もあります。 繰り返しますが、使用しているシステムを見つけて、「Gatsby sitemap」などのシステム + サイトマップを Google で検索するだけで、既存のソリューションが必ず見つかります。
ステータス コードとソフト 404
JavaScript フレームワークはサーバー側ではないため、404 などのサーバー エラーを実際にスローすることはできません。エラー ページには、次のようないくつかの異なるオプションがあります。
- JavaScript を使用して、404 ステータス コードで応答するページにリダイレクトします。
- 「404 ページが見つかりません」などのエラー メッセージとともに失敗するページに noindex タグを追加します。 返される実際のステータス コードは 404 OK であるため、これはソフト 200 として扱われます。
JavaScript リダイレクトは問題ありませんが、推奨されません
SEO 担当者はこれに慣れています 301/302 リダイレクト、サーバー側です。 JavaScript は通常、クライアント側で実行されます。 サーバーサイドのリダイレクトやメタ更新リダイレクトは、JavaScript リダイレクトよりも処理が簡単です。これは、それらを表示するためにページをレンダリングする必要がないためです。
JavaScript リダイレクトはレンダリング中に表示および処理されるため、ほとんどの場合問題ありませんが、他のリダイレクト タイプほど理想的ではありません。 これらは永続的なリダイレクトとして扱われ、引き続き次のようなすべてのシグナルを渡します。 PageRankの.
多くの場合、コード内で「window.location.href」を検索すると、これらのリダイレクトを見つけることができます。 リダイレクトは構成ファイルにも含まれる可能性があります。 Next.js 構成には、リダイレクトを設定するために使用できるリダイレクト関数があります。 他のシステムでは、ルーター内にそれらが存在する場合があります。
国際化の問題
通常、さまざまなフレームワークに対して、国際化に必要ないくつかの機能をサポートするモジュール オプションがいくつかあります。 hreflang。 これらは通常、さまざまなシステムに移植されており、i18n、intl、または多くの場合、Helmet などのヘッダー タグに使用される同じモジュールを使用して、必要なタグを追加できます。
hreflang の問題については、 ローカライゼーション 中で報告する サイト監査。 また、調査を行ったところ、次のことがわかりました。 hreflang を使用しているドメインの 67% に問題がある.
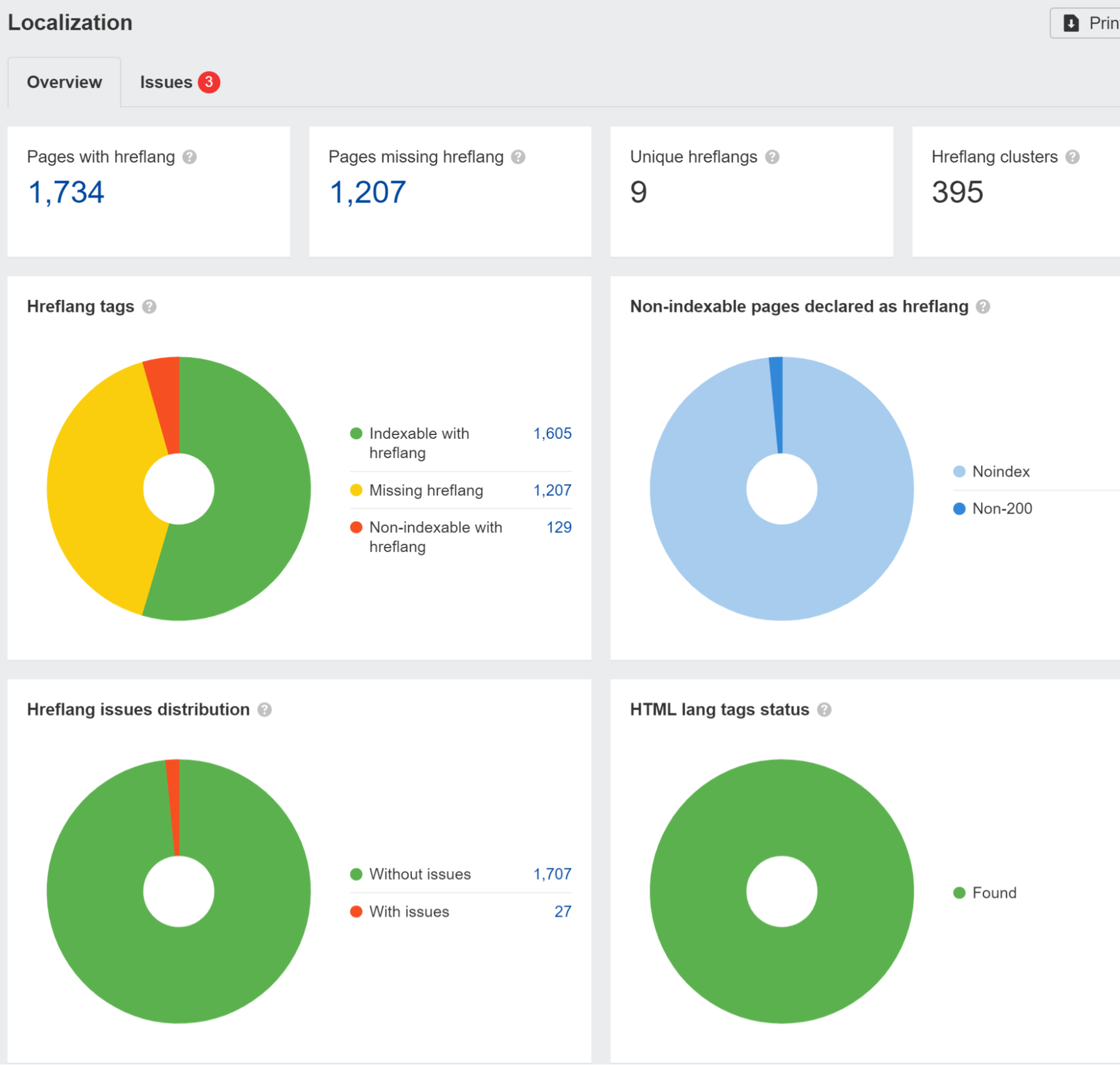
また、サイトが特定の国からの訪問者をブロックしたり扱ったりしている場合や、特定の IP をさまざまな方法で使用している場合にも注意する必要があります。 これにより、コンテンツが表示されなくなる可能性があります。 Googlebotが。 ユーザーをリダイレクトするロジックがある場合は、このロジックからボットを除外することができます。
Site Audit でプロジェクトを設定するときにこの問題が発生するかどうかをお知らせします。

構造化データを使用する
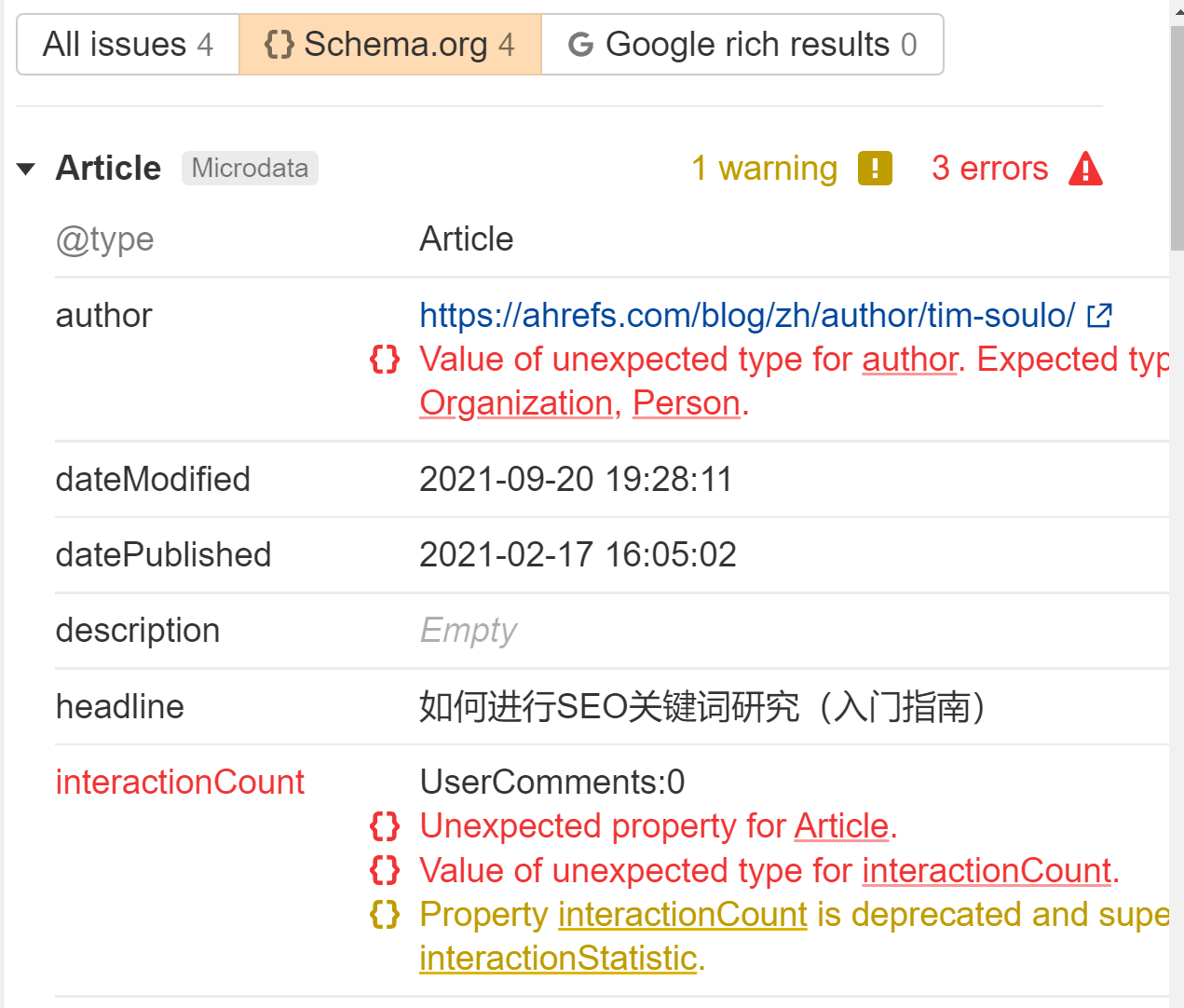
JavaScript を使用して、ページに構造化データを生成または挿入できます。 これを JSON-LD で行うのは非常に一般的であり、問題が発生する可能性はほとんどありませんが、いくつかのテストを実行して、すべてが期待どおりに動作することを確認してください。
構造化データにフラグを付けます。 問題 中で報告する サイト監査。 「構造化データには schema.org 検証があります」というエラーを探します。 各ページで何が間違っているかを正確に説明します。
標準形式のリンクを使用する
他のページへのリンクは、Web 標準形式である必要があります。 内部リンクと外部リンクは、 <a> タグに href 属性。 検索に適さない JavaScript を使用してリンクをユーザーに対して機能させる方法はたくさんあります。
こだわり:
<a href=”/page”>simple is good</a>
<a href=”/page” onclick=”goTo(‘page’)”>still okay</a>
バート:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>
<a href=”javascript:void(0)”>nope, missing link</a>
<span onclick=”goTo(‘page’)”>not the right HTML element</span>
<option value="page">nope, wrong HTML element</option>
<a href=”#”>no link</a>
ボタン、NG-クリックなど、これを誤って実行する可能性のある方法は他にもたくさんあります。
私の経験では、Google は依然として多くの不正なリンクを処理し、クロールしていますが、それらを PageRank のような遠くを通過する信号としてどのように扱うのかはわかりません。 ウェブは厄介な場所ですが、Google のパーサーは多くの場合かなり寛容です。
それも注目に値する 内部リンク JavaScript で追加されたものは、レンダリング後まで取得されません。 これは比較的早く完了するはずで、ほとんどの場合、心配する必要はありません。
ファイルのバージョン管理を使用して、インデックス付けが不可能な状態を解決します
Google はすべてのリソースを自社側で大量にキャッシュします。 これについては後ほど詳しく説明しますが、そのシステムにより、いくつかの不可能な状態がインデックス付けされる可能性があることを知っておく必要があります。 これはそのシステムの癖です。 このような場合、以前のファイル バージョンがレンダリング プロセスで使用され、ページのインデックス付きバージョンには古いファイルの一部が含まれる可能性があります。
ファイルのバージョン管理またはフィンガープリント (file.12345.js) を使用すると、重要な変更が行われたときに新しいファイル名を生成できるため、Google はレンダリング用にリソースの更新バージョンをダウンロードする必要があります。
Googlebot に表示される内容が表示されない場合があります
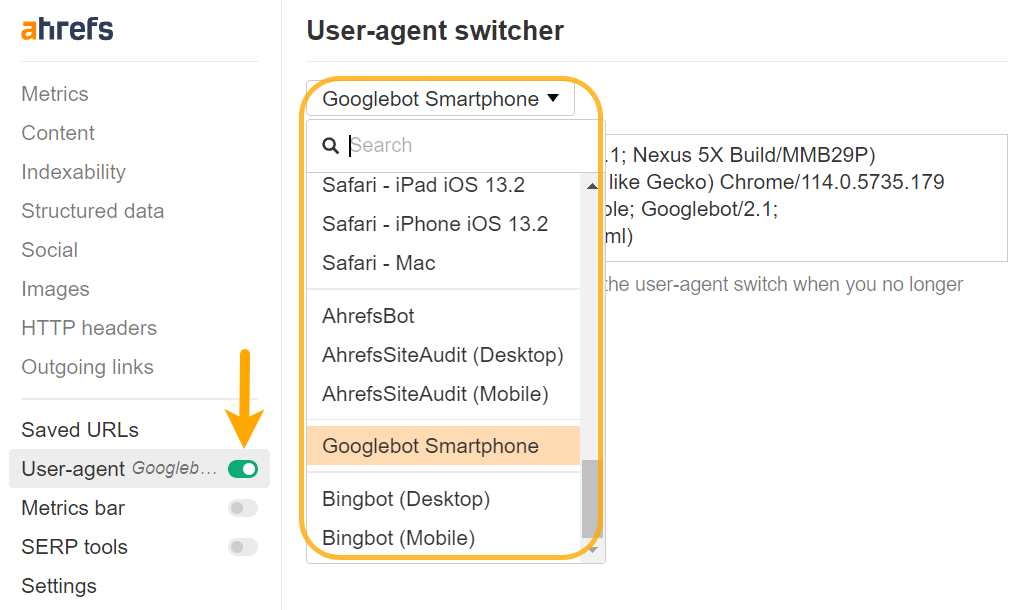
一部の問題を適切に診断するには、ユーザー エージェントを変更する必要がある場合があります。 コンテンツは、ユーザー エージェントや IP ごとに異なる方法でレンダリングできます。 Google がテスト ツールで実際に何を確認しているのかを確認する必要があります。これについては後ほど説明します。
Chrome DevTools を使用してカスタム ユーザー エージェントを設定して、特定のユーザー エージェントに基づいて事前レンダリングされるサイトのトラブルシューティングを行うことができます。また、これを次のコマンドで簡単に行うこともできます。 私たちのツールバー 同様に。
サポートされていないフィーチャにはポリフィルを使用する
Googlebot がサポートしていない機能が開発者によって使用されている可能性があります。 開発者が使用できるのは、 特徴検出。 不足している機能がある場合は、その機能をスキップするか、フォールバック方法を使用するかを選択できます。 ポリフィル 彼らがそれを機能させることができるかどうかを確認します。
これは主に SEO のための参考情報です。 Google が表示しているはずのものが表示されていない場合は、実装が原因である可能性があります。
遅延読み込みを使用する
最初にこれを書いて以来、遅延読み込みは主に JavaScript 主導からブラウザによって処理されるようになりました。
依然として、JavaScript 主導の遅延読み込みセットアップが発生する可能性があります。 ほとんどの場合、遅延読み込みが画像の場合はおそらく問題ありません。 主にチェックするのは、コンテンツが遅延読み込みされているかどうかを確認することです。 上記の「Google がコンテンツを認識しているかどうかを確認する」セクションを参照してください。 このような設定により、コンテンツが正しく取得されないという問題が発生します。
無限スクロールの問題
無限スクロールを設定している場合でも、Google が適切にクロールできるように、ページ分割されたページ バージョンをお勧めします。
この設定で私が見たもう XNUMX つの問題は、XNUMX つのページが XNUMX つのページとしてインデックス付けされる場合があることです。 ページのインデックスを取得できないという人を私は何度か見てきました。 しかし、私は彼らのコンテンツが別のページの一部としてインデックス付けされていることに気付きました。通常、そのページは以前の投稿です。
私の理論では、Google がビューポートのサイズを変更してより長くしたとき (これについては後で詳しく説明します)、レンダリング中に無限スクロールがトリガーされ、別の記事が読み込まれたのではないかと考えています。 この場合、無限スクロールを処理する JavaScript ファイルをブロックして、機能がトリガーされないようにすることをお勧めします。
パフォーマンスの問題
多くの JavaScript フレームワークは、最新のパフォーマンス最適化を大量に処理します。
従来のパフォーマンスに関するベスト プラクティスはすべて引き続き適用されますが、いくつかの新しいオプションも利用できます。 コードを分割すると、ファイルが小さなファイルに分割されます。 ツリーシェイキングにより必要な部分が分割されるため、従来のモノリシックセットアップで見られるように、すべてのページをすべて読み込むことはできません。
JavaScript のセットアップが適切に行われることは素晴らしいことです。 JavaScript のセットアップが適切に行われていないと、肥大化して読み込み時間が長くなる可能性があります。
ご確認ください> コアウェブバイタルガイド ウェブサイトのパフォーマンスについて詳しくは、こちらをご覧ください。
JavaScript サイトはより多くのクロール バジェットを使用します
JavaScript XHR リクエストが食べる クロールの予算、つまり、彼らはそれをむさぼり食うということです。 キャッシュされる他のほとんどのリソースとは異なり、これらはレンダリング プロセス中にライブでフェッチされます。
もう XNUMX つの興味深い詳細は、レンダリング サービスがページのコンテンツに寄与しないリソースを取得しないようにしていることです。 これが間違っている場合は、一部のコンテンツが欠落している可能性があります。
労働者はサポートされていませんよね?
Google は歴史的に、サービス ワーカーを拒否し、サービス ワーカーは DOM を編集できないと言っていますが、Google 自身の Martin Splitt は、場合によっては Web ワーカーを使用しても問題がない可能性があると示唆しました。
HTTP接続を使用する
Googlebot は HTTP リクエストをサポートしていますが、次のような他の接続タイプはサポートしていません。 WebSocketを or WebRTC。 これらを使用している場合は、HTTP 接続を使用するフォールバックを提供します。
JavaScript サイトの「落とし穴」の XNUMX つは、DOM の部分的な更新を実行できることです。 ユーザーとして別のページを参照すると、DOM 内のタイトル タグやカノニカル タグなどの一部の要素が更新されない場合がありますが、これは検索エンジンにとっては問題ではない可能性があります。
Google は各ページをステートレスに新規読み込みのように読み込みます。 以前の情報は保存されず、ページ間を移動することもありません。
更新されない正規タグなど、あるページから別のページに移動した後に表示される内容によって、SEO 担当者が問題があると考えてつまずくのを私は見てきました。 しかし、Google がこの状態を目にすることは決してないかもしれません。
開発者は、いわゆる 履歴API。 しかし、繰り返しになりますが、それは問題ではないかもしれません。 多くの場合、開発者にとってそれは奇妙に見えるため、SEO が開発者を困らせているだけです。 ページを更新して、何が表示されるかを確認してください。 さらに良いのは、Google のテスト ツールの XNUMX つで実行して、何が表示されるかを確認することです。
そのテストツールについて話しましょう。
Googleのテストツール
Google には、JavaScript に役立つテスト ツールがいくつかあります。
Google Search ConsoleのURL検査ツール
これがあなたの真実の情報源となるはずです。 URL を検査すると、Google が認識した内容と、そのシステムから実際にレンダリングされた HTML に関する多くの情報が得られます。
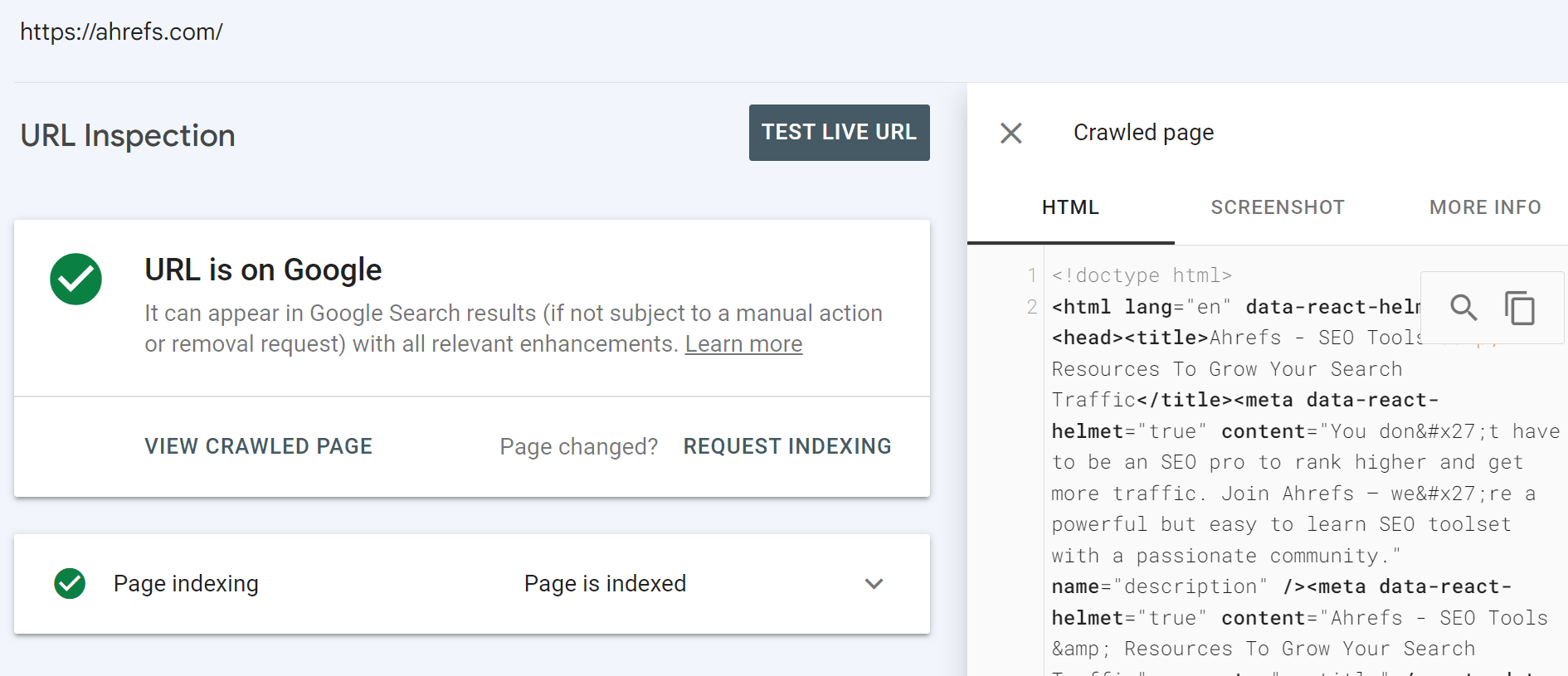
ライブテストを実行するオプションもあります。

メイン レンダラーとライブ テストの間にはいくつかの違いがあります。 レンダラーはキャッシュされたリソースを使用し、かなり忍耐強く動作します。 ライブ テストやその他のテスト ツールはライブ リソースを使用するため、結果を待っているためレンダリングが早期に中断されます。 これについては、後ほどレンダリングのセクションで詳しく説明します。
これらのツールのスクリーンショットには、ピクセルがペイントされたページも表示されますが、Google がページをレンダリングするときに実際にはこれを行いません。
このツールは、コンテンツが DOM で読み込まれているかどうかを確認するのに役立ちます。 これらのツールで表示される HTML は、レンダリングされた DOM です。 テキストのスニペットを検索して、それがデフォルトで読み込まれているかどうかを確認できます。
このツールには、ブロックされている可能性のあるリソースや、デバッグに役立つコンソール エラー メッセージも表示されます。
ウェブサイトの Google Search Console プロパティにアクセスできない場合でも、ウェブサイトでライブ テストを実行できます。 Google Search Console にアクセスできるプロパティ上の独自のウェブサイトにリダイレクトを追加すると、その URL を検査でき、検査ツールがリダイレクトを追跡し、他のドメイン上のページのライブ テスト結果を表示します。
以下のスクリーンショットでは、自分のサイトから Google のホームページへのリダイレクトを追加しました。 このライブ テストはリダイレクトに従い、Google のホームページが表示されます。 できればよかったのですが、実際には Google の Google Search Console アカウントにアクセスできません。
リッチリザルトテストツール
リッチリザルトテストツール Googlebot がモバイルまたはデスクトップで表示するのと同じように、レンダリングされたページを確認できます。
モバイルフレンドリーなテストツール
あなたはまだ使用することができます モバイルフレンドリーなテストツール 今のところ、Googleは2023年XNUMX月に閉鎖すると発表した。
これには、Google の他のテスト ツールと同じ癖があります。
Ahrefs
Ahrefs は、 Web をクロールするときに Web ページをレンダリングします, そのため、他のツールでは取得できない JavaScript サイトからのデータが得られます。 私たちは 200 日に最大 XNUMX 億ページをレンダリングしますが、それはクロールするページのほんの一部です。
これにより、JavaScript リダイレクトをチェックできるようになります。 JavaScript で挿入されたリンクを表示することもできます。リンク レポートでは JS タグを使用して表示されます。

ページのドロップダウン メニューで サイトエクスプローラー、ページの履歴を表示し、他のクロールと比較できる検査オプションもあります。 JavaScript を有効にしてレンダリングされたページには、JS マーカーがあります。

JavaScript を有効にすると、 サイト監査 クロールして監査でより多くのデータをロック解除します。
JavaScript レンダリングを有効にしている場合は、すべてのページに生の HTML とレンダリングされた HTML が提供されます。 ページエクスプローラーでページの横にある「虫眼鏡」オプションを使用し、メニューの「ソースを表示」に移動します。 また、以前のクロールと比較したり、サイト上のすべてのページにわたって生の HTML またはレンダリングされた HTML 内を検索したりすることもできます。
JavaScript を使用せずにクロールを実行し、JavaScript を使用して別のクロールを実行する場合、クロール比較機能を使用してバージョン間の違いを確認できます。
Ahrefs ' SEOツールバー は JavaScript もサポートしており、HTML とレンダリングされたバージョンのタグを比較できます。
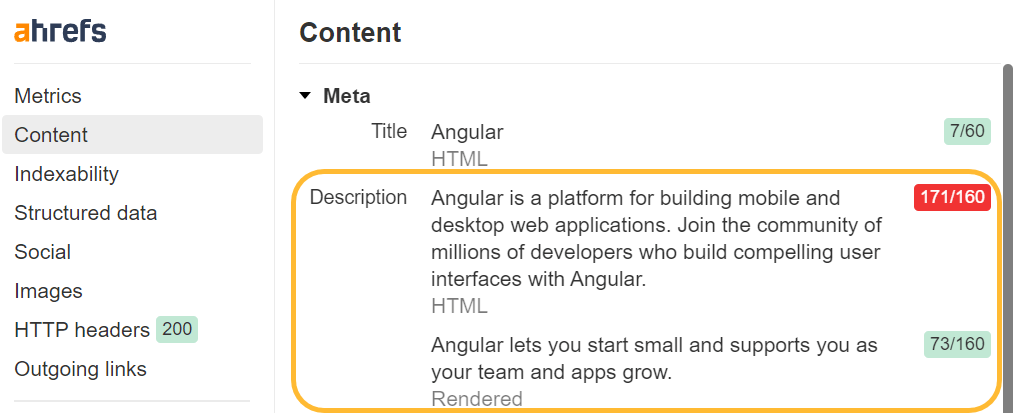
ソースの表示と検査
ブラウザ ウィンドウで右クリックすると、ページのソース コードを表示したり、ページを検査したりするためのオプションがいくつか表示されます。 ソースの表示では、GET リクエストと同じものが表示されます。 これはページの生の HTML です。

Inspect では、変更が加えられた後に処理された DOM が表示され、Googlebot が認識するコンテンツに近くなります。 これは、JavaScript が実行されて変更が加えられた後のページです。
JavaScript を使用する場合は、主にビュー ソースの検査を使用する必要があります。
場合によってはソースの表示を確認する必要があります
Google は一部の問題について生の HTML とレンダリングされた HTML の両方を調査するため、場合によってはソースの表示を確認する必要がある場合があります。 たとえば、Google のツールではページが noindex としてマークされていると表示されているにもかかわらず、レンダリングされた HTML に noindex タグが表示されない場合、生の HTML にそのタグが存在し、上書きされた可能性があります。
noindex、nofollow、canonical タグなどについては、問題が引き継がれる可能性があるため、生の HTML を確認する必要がある場合があります。 Google はメタ ロボット タグに関して最も制限的なステートメントを採用し、複数の正規タグが表示された場合は正規タグを無視することに注意してください。
JavaScriptをオフにして閲覧しないでください
この推奨方法を何度も見ました。 Google は JavaScript をレンダリングするため、JavaScript を使用しない場合に表示されるものは、Google が表示するものとはまったく異なります。 これはただの愚かなことです。
Googleキャッシュを使用しないでください
Google のキャッシュは、Googlebot が何を認識しているかを確認する信頼できる方法ではありません。 通常、キャッシュ内に表示されるのは、生の HTML スナップショットです。 次に、ブラウザは HTML 内で参照される JavaScript を起動します。 これは、Google がページをレンダリングしたときに見たものではありません。
これをさらに複雑にするために、Web サイトには クロスオリジンリソース共有(CORS) 必要なリソースを別のドメインからロードできないようにポリシーが設定されている。
キャッシュは webcache.googleusercontent.com でホストされています。 そのドメインが実際のドメインからリソースを要求しようとすると、CORS ポリシーは「いいえ、私のファイルにはアクセスできません」と表示します。 その後、ファイルは読み込まれず、ページはキャッシュ内で壊れているように見えます。
キャッシュ システムは、Web サイトがダウンしたときにコンテンツを表示するために作成されました。 デバッグ ツールとしては特に役に立ちません。
検索エンジンの初期の頃は、ダウンロードされた HTML 応答でほとんどのページのコンテンツを確認できました。 JavaScript の台頭のおかげで、検索エンジンはユーザーが見たようにコンテンツを表示できるように、ブラウザーと同じように多くのページをレンダリングする必要があります。
Google でレンダリング プロセスを処理するシステムは、Web レンダリング サービス (WRS) と呼ばれます。 Google は、このプロセスがどのように機能するかを説明する単純な図を提供しています。
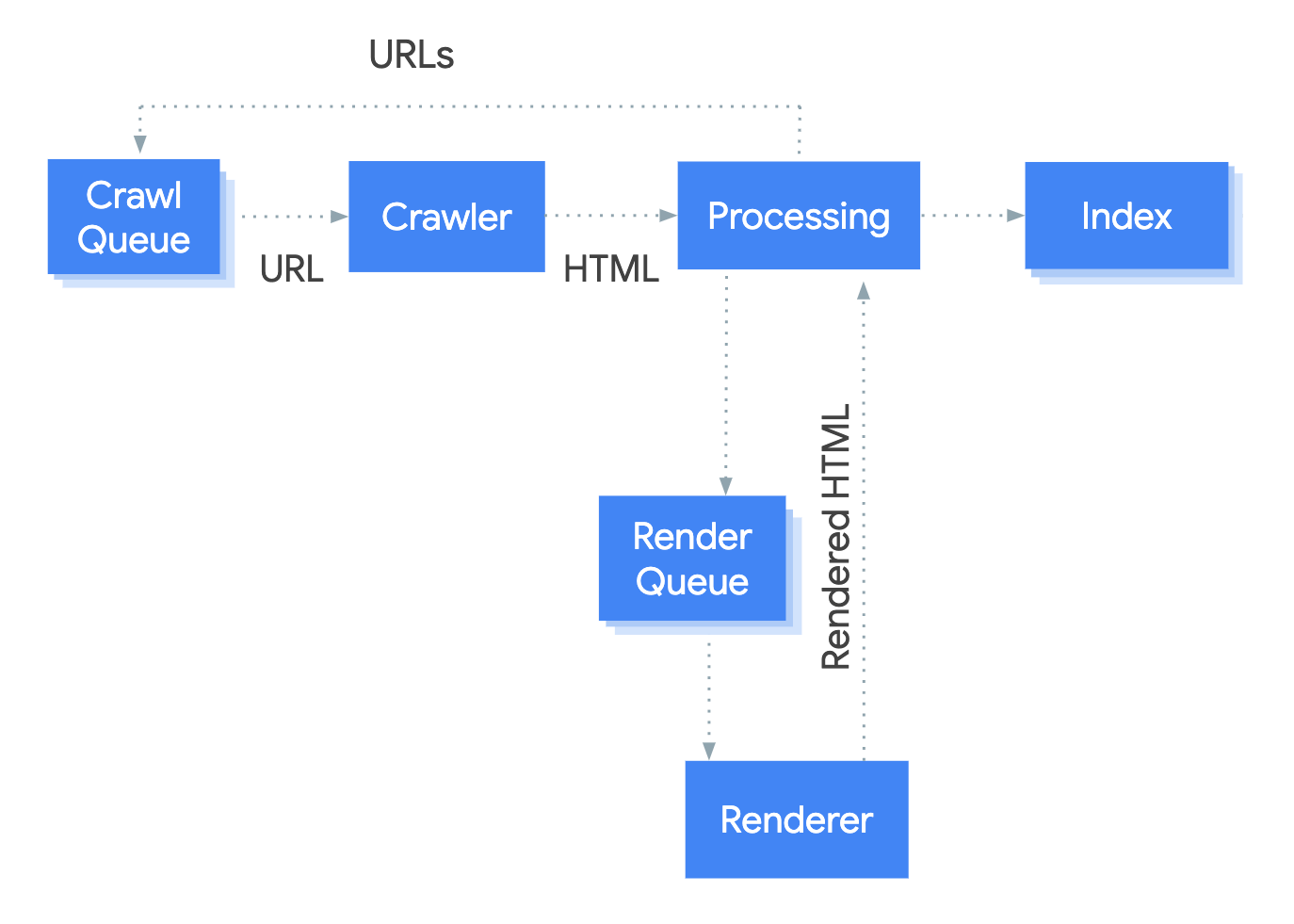
URL でプロセスを開始するとします。
1.クローラー
クローラーはサーバーに GET リクエストを送信します。 サーバーはヘッダーとファイルの内容で応答し、ファイルは保存されます。 通常、ヘッダーとコンテンツは同じリクエスト内に含まれます。
Google はモバイル ユーザー エージェントであるため、リクエストはモバイル ユーザー エージェントから送信される可能性があります。 モバイルファーストインデックス作成 現在は、デスクトップ ユーザー エージェントを使用してクロールします。
リクエストのほとんどはマウンテン ビュー (カリフォルニア州、米国) からのものですが、 ロケール対応ページのクロール 米国外 先ほど述べたように、サイトが特定の国の訪問者をさまざまな方法でブロックしたり扱ったりしている場合、問題が発生する可能性があります。
また、Google は上の画像ではクロール プロセスの出力を「HTML」と表現していますが、実際には、HTML、JavaScript ファイル、CSS ファイルなど、ページの構築に必要なリソースをクロールして保存していることに注意することも重要です。 HTML ファイルには 15 MB の最大サイズ制限もあります。
2。 処理
画像には「処理」という用語によって難読化されているシステムがたくさんあります。 このうち JavaScript に関連するものをいくつか取り上げます。
リソースとリンク
Google は、ユーザーのようにページからページに移動することはありません。 「処理」の一部は、ページを構築するために必要な他のページやファイルへのリンクがないかページを確認することです。 これらのリンクは抽出され、クロール キューに追加されます。これは、Google がクロールの優先順位付けとスケジュール設定に使用するものです。

Google は、ページの構築に必要なリソース リンク (CSS、JS など) を次のようなものから取得します。 <link> タグ。
私が前に述べたように、 内部リンク JavaScript で追加されたものは、レンダリング後まで取得されません。 これは比較的早く完了するはずで、ほとんどの場合、心配する必要はありません。 ニュース サイトなどは、一秒を争う例外かもしれません。
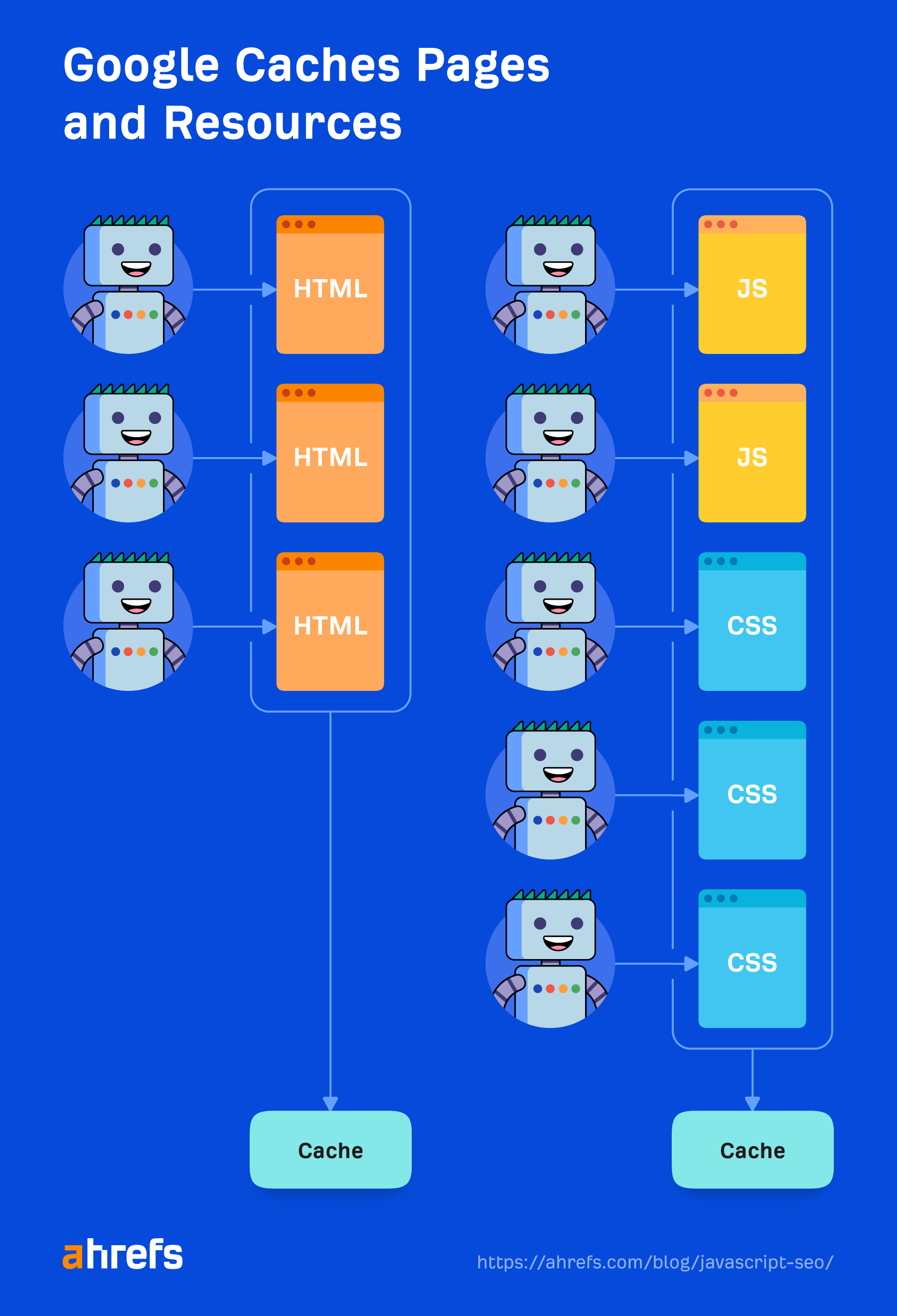
キャッシング
HTML ページ、JavaScript ファイル、CSS ファイルなど、Google がダウンロードするすべてのファイルは積極的にキャッシュされます。 Google はキャッシュのタイミングを無視し、必要に応じて新しいコピーを取得します。 これについて、そしてそれがなぜ重要なのかについては、「レンダラー」セクションでもう少し詳しく説明します。
重複の削除
重複したコンテンツは、レンダリングに送信される前に、ダウンロードされた HTML から削除または優先順位が下げられる場合があります。 これについては、上記の「重複コンテンツ」セクションですでに説明しました。
最も制限的なディレクティブ
前に述べたように、Google は最も制限の厳しいものを選択します。 文 HTML とページのレンダリングされたバージョンの間。 JavaScript がステートメントを変更し、それが HTML のステートメントと矛盾する場合、Google は最も制限の厳しい方に従うだけです。 noindex はインデックスをオーバーライドし、HTML 内の noindex はレンダリングを完全にスキップします。
3. レンダーキュー
JavaScript と XNUMX 段階インデックス作成 (HTML の後にページをレンダリングする) を使用する多くの SEO の最大の懸念の XNUMX つは、ページが数日、場合によっては数週間レンダリングされない可能性があることです。 Googleがこれを調べたところ、 ページがレンダラーに送信されるまでの時間の中央値は XNUMX 秒でした、90 パーセンタイルは分でした。 したがって、HTML を取得してからページをレンダリングするまでの時間は、ほとんどの場合、気にする必要はありません。
ただし、Google はすべてのページをレンダリングするわけではありません。 前に述べたように、robots メタ タグまたは noindex タグを含むヘッダーを持つページはレンダラに送信されません。 とにかくインデックスを作成できないページをレンダリングするためにリソースを無駄にすることはありません。
このプロセスでは品質チェックも行われます。 HTML を確認するか、他の信号やパターンからページの品質がインデックスに登録するには十分ではないと合理的に判断できる場合は、それをレンダラーに送信する必要はありません。
ニュースサイトにも癖があります。 Google は、まず HTML コンテンツに基づいてページのインデックスを作成し、後で戻ってこれらのページをレンダリングできるように、ニュース サイトのページを迅速にインデックスしたいと考えています。
4.レンダラー
レンダラーは、Google がページをレンダリングしてユーザーに何が表示されるかを確認する場所です。 ここで、JavaScript と JavaScript によって加えられた変更が処理されます。 DOM.
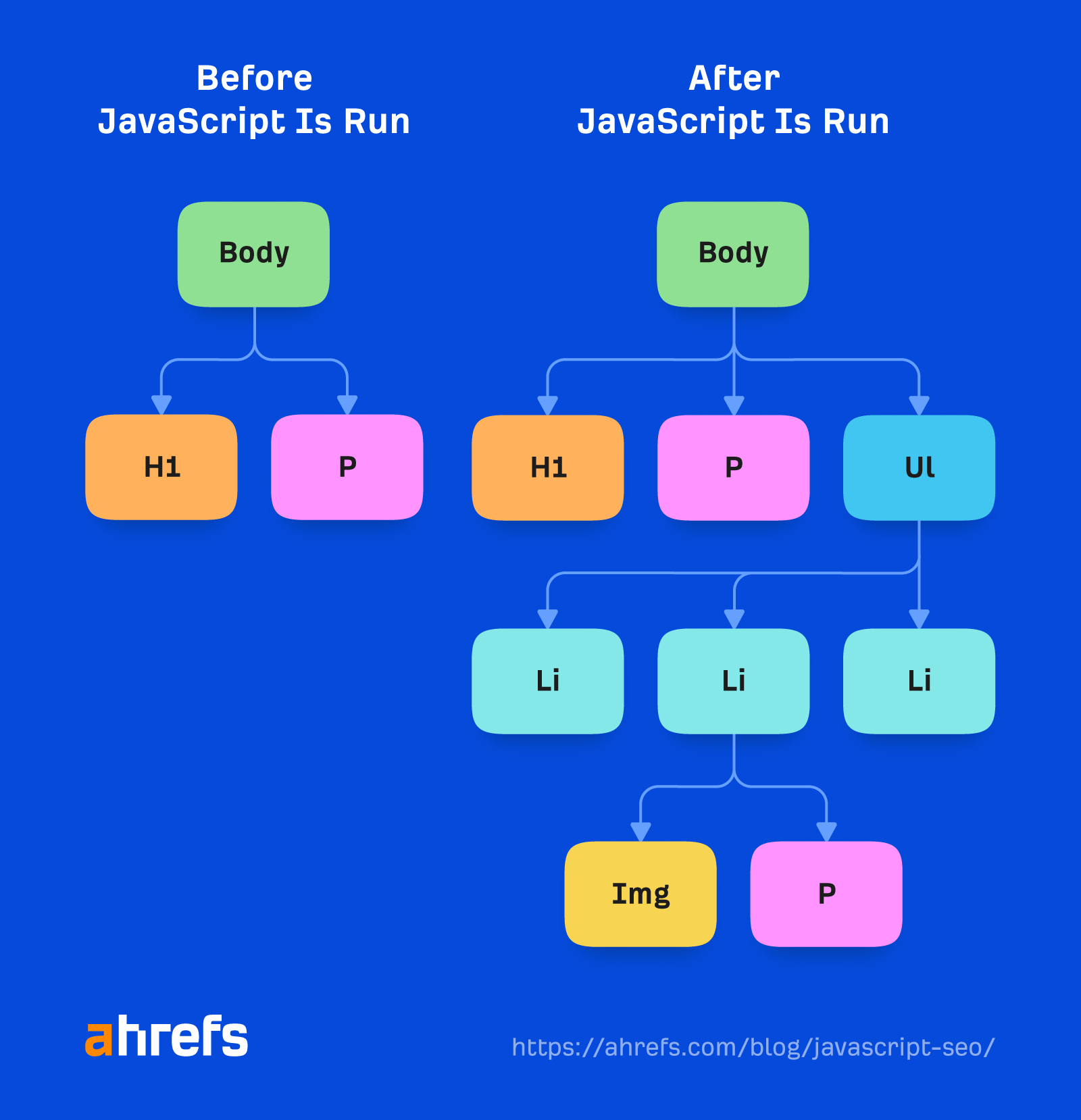
このため、Google は現在「エバーグリーン」となっているヘッドレス Chrome ブラウザを使用しています。つまり、最新の Chrome バージョンを使用し、最新の機能をサポートする必要があります。 数年前、Google は Chrome 41 を使用してレンダリングを行っていましたが、その時点では多くの機能がサポートされていませんでした。
Googleには他にもあります WRSの情報これには、アクセス許可の拒否、ステートレス化、ライト DOM とシャドウ DOM のフラット化などが含まれており、読む価値があります。
Web スケールでのレンダリングは、世界の XNUMX 番目の不思議かもしれません。 これは重大な取り組みであり、膨大な量のリソースが必要です。 その規模のため、Google はレンダリング プロセスを高速化するために多くのショートカットを講じています。
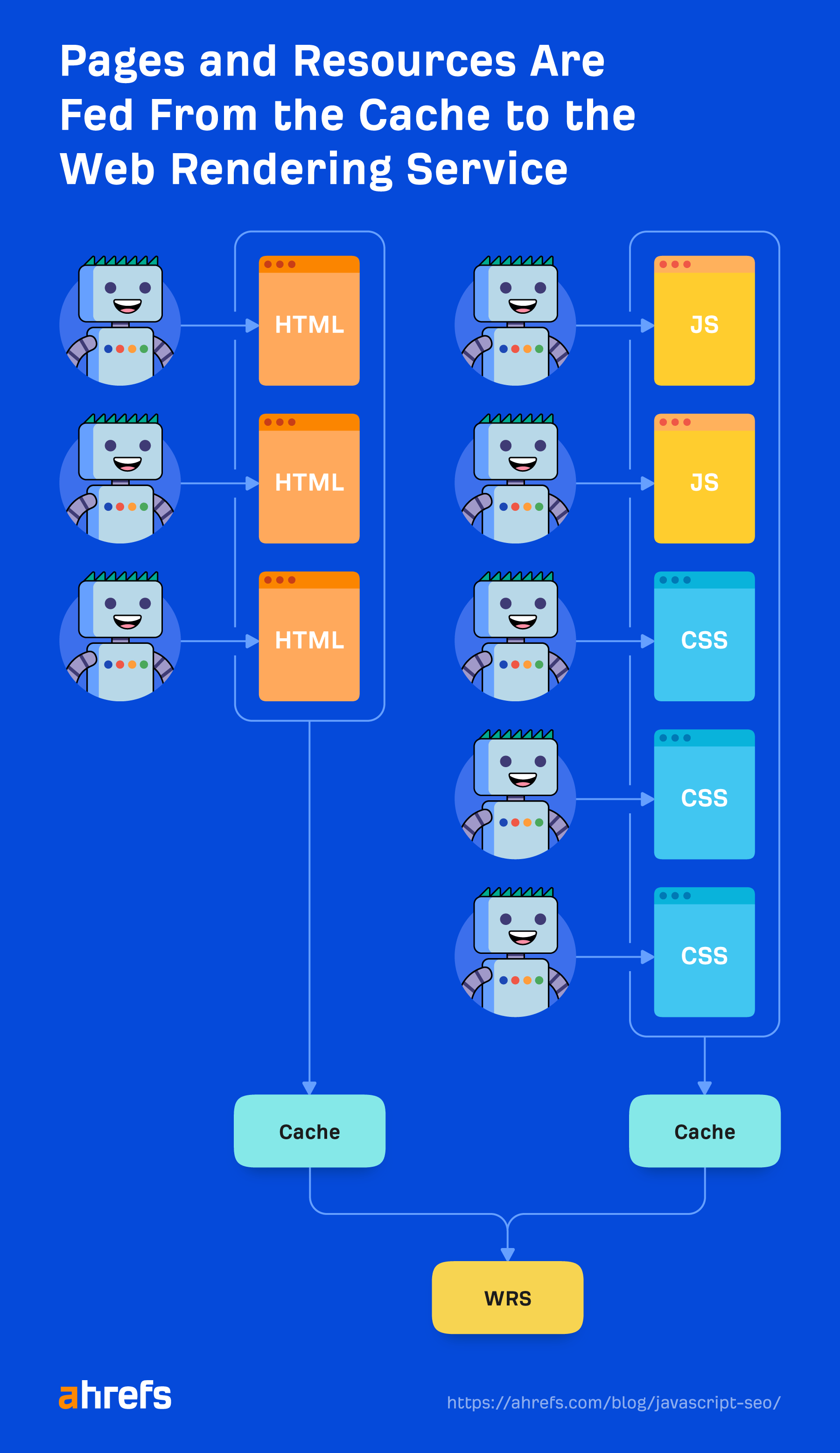
キャッシュされたリソース
Google はキャッシュ リソースに大きく依存しています。 ページはキャッシュされます。 ファイルはキャッシュされます。 ほぼすべてがレンダラーに送信される前にキャッシュされます。 ページが読み込まれるたびに各リソースをダウンロードすることはありません。それは、Web サイトと Web サイト所有者にとってコストがかかるからです。 代わりに、これらのキャッシュされたリソースを使用して効率を高めます。
XHR リクエストは例外で、レンダラーはリアルタイムで実行します。
XNUMX秒のタイムアウトはありません
SEO に関するよくある誤解は、Google がページを読み込むのに XNUMX 秒しかかからないというものです。 サイトを高速化するのは常に良いことですが、この通説は、上記で説明した Google のファイルのキャッシュ方法に関してはあまり意味がありません。 新しいリソースを要求するのではなく、システムにキャッシュされているすべてのものを含むページをすでに読み込んでいます。
XNUMX 秒しか待っていない場合、多くのコンテンツが失われることになります。
この迷信は、リソースがキャッシュではなくライブで取得され、妥当な時間内にユーザーに結果を返す必要がある URL 検査ツールなどのテスト ツールから来ていると考えられます。 また、ページがクロールの優先順位を付けられていないことが原因である可能性もあります。そのため、ユーザーはページのレンダリングとインデックス作成に長い時間がかかると思われます。
レンダラーには固定のタイムアウトはありません。 後で何かが追加されるかどうかを確認するために、高速タイマーで実行されます。 また、ブラウザ内のイベント ループを調べて、すべてのアクションがいつ実行されたかを確認します。 非常に忍耐強く、特定の時間制限を気にする必要はありません。
忍耐強いですが、何かが行き詰まったり、誰かがそのページでビットコインをマイニングしようとしたりした場合に備えて、安全策も講じています。 はい、それは事です。 ビットコインのマイニングにも安全策を追加する必要がありました。 研究を発表 それについて。
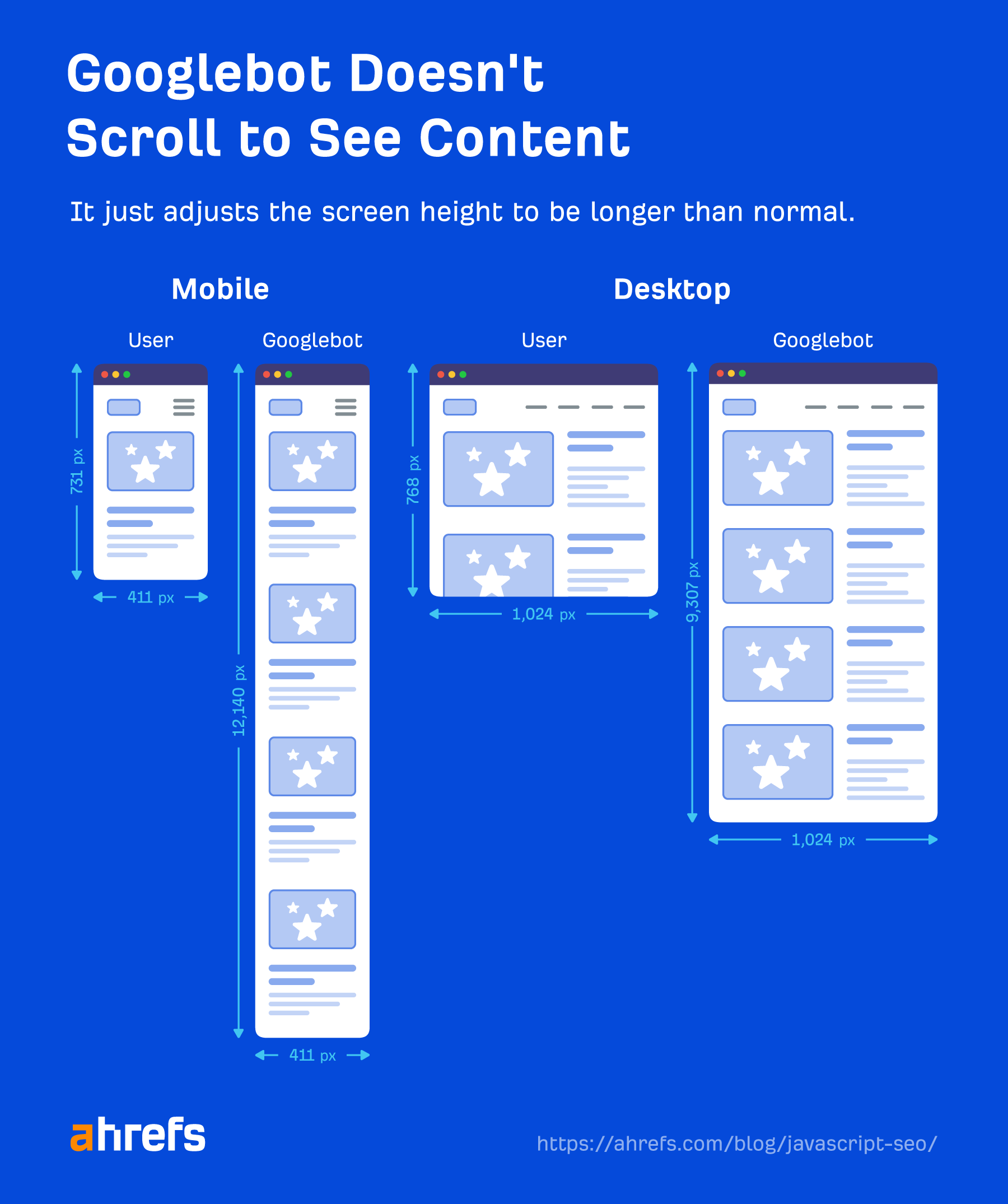
Googlebot が見ているもの
Googlebot はウェブページに対してアクションを起こしません。 クリックしたりスクロールしたりすることはありませんが、回避策がないわけではありません。 必要なアクションを行わずにコンテンツが DOM に読み込まれている限り、Google はそれを認識します。 クリックするまで DOM に読み込まれない場合、コンテンツは見つかりません。
Google には、コンテンツを表示するための賢い回避策があるため、コンテンツを表示するためにスクロールする必要もありません。 モバイルの場合、画面サイズ 411×731 ピクセルのページが読み込まれます。 長さを 12,140 ピクセルに変更します.
基本的に、画面サイズが411×12140ピクセルの非常に長い電話になります。 デスクトップの場合も同様で、1024×768 ピクセルから 1024×9307 ピクセルになります。 これらの数値については最近のテストを見たことがありません。ページの長さに応じて変化する可能性があります。
もう XNUMX つの興味深いショートカットは、Google がレンダリング プロセス中にピクセルをペイントしないことです。 ページの読み込みを完了するには時間と追加のリソースが必要ですが、ピクセルがペイントされた最終状態を実際に確認する必要はありません。 さらに、グラフィックス カードは、ゲーム、仮想通貨マイニング、AI の間で高価です。
Google は構造とレイアウトを知るだけでよく、実際にピクセルを描画することなくそれを取得します。 として マーティン それはこう言います:
Google 検索では、ピクセルを誰かに見せたくないので、ピクセルはあまり気にしません。 情報と意味情報を処理したいので、中間状態にあるものが必要です。 実際にピクセルをペイントする必要はありません。
ビジュアルがあると、何が切り取られたのかをもう少しわかりやすく説明できるかもしれません。 Chrome Dev Tools では、「パフォーマンス」タブでテストを実行すると、負荷グラフが表示されます。 ここでの緑色の塗りつぶし部分は塗装段階を表します。 Googlebot の場合、そのようなことは決して起こらないため、リソースが節約されます。

グレー =ダウンロード
青 = HTML
イエロー = JavaScript
パープル = レイアウト
グリーン = 絵を描く
5. クロールキュー
Google には、クロールの予算について少し説明したリソースがあります。 ただし、各サイトには独自のクロール バジェットがあり、各リクエストには優先順位を付ける必要があることを知っておく必要があります。 Google はまた、あなたのページとインターネット上の他のすべてのページのクロールのバランスをとる必要があります。
一般に、新しいサイトや動的ページが多数あるサイトは、クロールが遅くなる可能性があります。 一部のページは他のページよりも更新頻度が低くなり、一部のリソースはリクエストされる頻度も低くなります。
JavaScript のレンダリングには多くのオプションがあります。 Google にはしっかりしたグラフがありますので、それをお見せします。 SSR、静的レンダリング、およびプリレンダリングのセットアップは、検索エンジンにとってはどのようなものでも問題ありません。 Gatsby、Next、Nuxt などはどれも素晴らしいです。

最も問題となるのは、すべてのレンダリングがブラウザ内で行われる完全なクライアント側レンダリングです。 Google はおそらくクライアント側レンダリングに問題ありませんが、他のレンダリング オプションをサポートするには別のレンダリング オプションを選択するのが最善です。 検索エンジン.
ビングにもあります JavaScript レンダリングのサポートが、規模は不明。 私が見た限りでは、Yandex と Baidu のサポートは限られており、他の多くの検索エンジンは JavaScript をほとんどまたはまったくサポートしていません。 弊社独自の検索エンジン、 うんはサポートされており、200 日あたり最大 XNUMX 億ページをレンダリングします。 ただし、クロールするすべてのページをレンダリングするわけではありません。
のオプションもあります 動的レンダリング、これは特定のユーザー エージェントに対してレンダリングされます。 これは回避策であり、正直に言うと、私はこれを推奨したことはありませんでしたが、現在 Google も推奨していることを嬉しく思います。
状況によっては、検索エンジンやソーシャル メディア ボットなどの特定のボットのレンダリングに使用することもできます。 ソーシャル メディア ボットは JavaScript を実行しないため、次のようなことが起こります。 OGタグ コンテンツを提供する前にコンテンツをレンダリングしない限り、表示されません。
実際には、設定がより複雑になり、SEO にとってトラブルシューティングが困難になります。 それは間違いなく クローキング、たとえGoogleがそうではなく、それは問題ないと言っているにもかかわらずです。
Note
古いものを使用していた場合 AJAX クロール スキーム ハッシュバング (#!) を使用すると、これは非推奨となり、サポートされなくなったことを知ってください。
最終的な考え
SEO にとって JavaScript は恐れるものではありません。 この記事が、その操作方法をよりよく理解するのに役立つことを願っています。
恐れずに開発者に連絡し、協力して質問してください。 これらは、検索エンジン向けの JavaScript サイトの改善を支援する最大の味方となるでしょう。
ご質問がありますか? お知らせ下さい Twitterで.
参考文献
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://ahrefs.com/blog/javascript-seo/

