AmazonOpenSearchサービス 最近、OpenSearch Optimized Instance ファミリ (OR1) を導入しました。これは、内部ベンチマークで既存のメモリ最適化インスタンスと比較して、価格パフォーマンスが最大 30% 向上します。 Amazon シンプル ストレージ サービス (Amazon S3) 11 9 の耐久性を提供します。この新しいインスタンスファミリーにより、OpenSearch Service は OpenSearch イノベーションと AWS テクノロジーを使用して、データのインデックス付けとクラウドへの保存方法を再考します。
現在、OpenSearch Service は大量のデータを取り込みながら豊富なインタラクティブな分析を提供できるため、お客様は運用分析に広く使用しています。これらの利点を提供するために、OpenSearch は、データのインデックス作成とリクエストの処理を行う複数の独立したインスタンスを備えた大規模な分散システムとして設計されています。運用分析データの速度とデータ量が増加すると、ボトルネックが発生する可能性があります。大量のインデックス作成を持続的にサポートし、耐久性を提供するために、OR1 インスタンス ファミリーを構築しました。
この投稿では、再考されたデータ フローが OR1 インスタンスでどのように機能するか、また新しい物理レプリケーション プロトコルを使用して高いインデックス作成スループットと耐久性をどのように提供できるかについて説明します。また、正確性とデータの整合性を維持するために解決したいくつかの課題についても詳しく説明します。
11 9 の耐久性を備えた高スループットの設計
OpenSearch Service は、数万の OpenSearch クラスターを管理します。私たちは、お客様が高スループットと耐久性の目標を達成するために使用する一般的なクラスター構成についての洞察を得ることができました。より高いスループットを実現するために、顧客は多くの場合、レプリカのコピーを削除してレプリケーションの待ち時間を節約することを選択します。ただし、この構成では可用性と耐久性が犠牲になります。他の顧客は高い耐久性を必要とするため、複数のレプリカ コピーを維持する必要があり、運用コストが高くなります。
OpenSearch Optimized Instance ファミリは、データのコピーを Amazon S3 に保存することでコストを抑えながら耐久性を高めます。 OR1 インスタンスを使用すると、インデックス作成のスループットを維持しながら、読み取り可用性を高めるために複数のレプリカ コピーを構成できます。
次の図は、OR1 でのメタデータの更新を伴うインデックス作成フローを示しています。
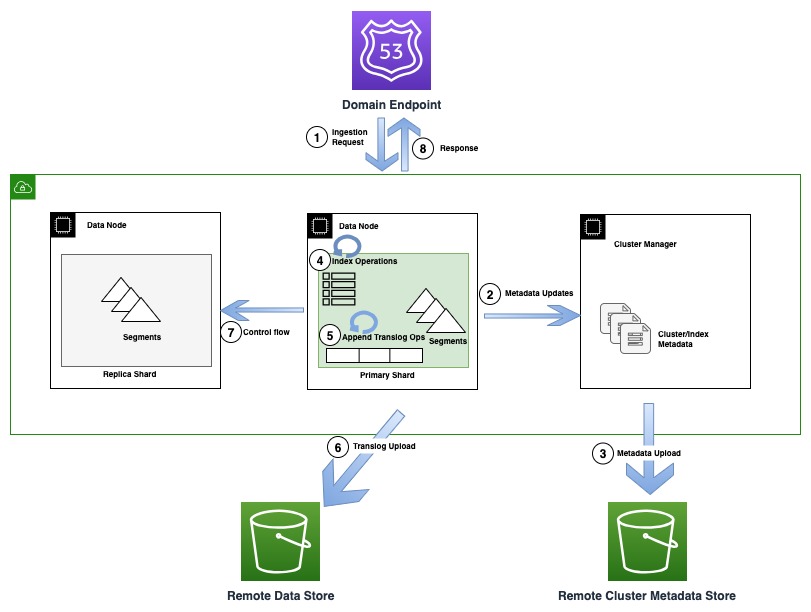
インデックス作成操作中、個々のドキュメントは Lucene にインデックス付けされ、トランスログとも呼ばれる先行書き込みログにも追加されます。クライアントに確認応答を送り返す前に、すべてのトランスログ操作は Amazon S3 によってサポートされるリモート データ ストアに保存されます。レプリカ コピーが構成されている場合、プライマリ コピーは正確性を理由に、すべてのレプリカ コピー上で複数の書き込み (制御フロー) の可能性を検出するためのチェックを実行します。
次の図は、OR1 インスタンスでのセグメントの生成とレプリケーションのフローを示しています。
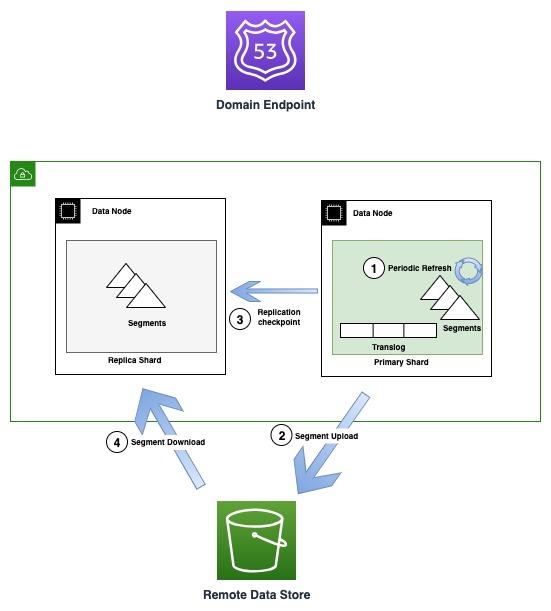
定期的に、新しいセグメント ファイルが作成されると、OR1 はそれらのセグメントを Amazon S3 にコピーします。転送が完了すると、プライマリはすべてのレプリカ コピーに新しいチェックポイントを発行し、新しいセグメントがダウンロード可能になったことを通知します。その後、レプリカ コピーによって新しいセグメントがダウンロードされ、検索可能になります。このモデルは、Amazon S3 を使用して発生するデータフローと、ノード間トランスポート通信で発生する制御フロー (チェックポイント発行と用語検証) を分離します。
次の図は、OR1 インスタンスのリカバリ フローを示しています。
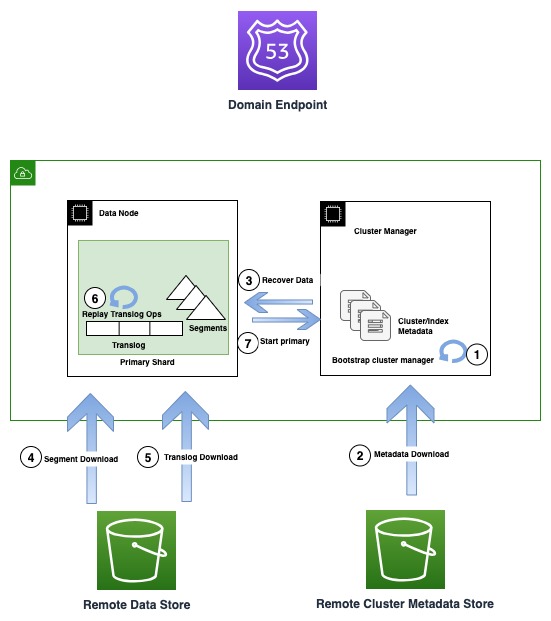
OR1 インスタンスは、データだけでなく、インデックス マッピング、テンプレート、設定などのクラスター メタデータも Amazon S3 に保持します。これにより、非専用のクラスター マネージャー セットアップでよくある障害モードであるクラスター マネージャーのクォーラム損失が発生した場合に、OpenSearch が最後に確認されたメタデータを確実に回復できるようになります。
インフラストラクチャに障害が発生した場合、OpenSearch ドメインは 3 つ以上のノードを失う可能性があります。このようなイベントが発生した場合、新しいインスタンス ファミリーは、最後に確認された操作までのクラスター メタデータとインデックス データの両方のリカバリを保証します。新しい交換ノードがクラスターに参加すると、内部クラスター回復メカニズムが新しいノードのセットをブートストラップし、リモート クラスター メタデータ ストアから最新のクラスター メタデータを回復します。クラスターのメタデータが回復されると、回復メカニズムが開始され、欠落しているセグメント データと Amazon SXNUMX からのトランスログがハイドレートされます。次に、最後に確認された操作までの、コミットされていないすべてのトランスログ操作が再実行され、失われたコピーが復元されます。
新しいデザインでは、検索の動作方法は変更されません。クエリは、インデックス内の各シャードのプライマリ シャードまたはレプリカ シャードによって通常どおり処理されます。データのレプリケーションには Amazon S10 が使用されているため、すべてのコピーが特定の時点まで一貫性を保つまでに、より長い遅延 (3 秒の範囲) が発生する場合があります。
このアーキテクチャの主な利点は、リーダーとライターの分離など、将来のイノベーションのための基礎的な構成要素として機能し、コンピューティング層とストレージ層の分離に役立つことです。
レプリケーション戦略を再定義することでインデックス作成のスループットがどのように向上するか
OpenSearch は、論理 (ドキュメント) 複製と物理 (セグメント) 複製という 1 つの複製戦略をサポートしています。論理レプリケーションの場合、データはすべてのコピー上で個別にインデックス付けされるため、クラスター上で冗長な計算が行われます。 ORXNUMX インスタンスは新しい 物理レプリケーション このモデルでは、データはプライマリ コピーでのみインデックス付けされ、追加のコピーはプライマリからデータをコピーすることによって作成されます。レプリカ コピーの数が多い場合、プライマリ コピーをホストするノードは、セグメントをすべてのコピーに複製するために大量のネットワーク帯域幅を必要とします。新しい OR1 インスタンスは、セグメントを Amazon S3 に永続的に永続化することでこの問題を解決します。 リモートストレージ オプション。また、プライマリでボトルネックを発生させずにレプリカをスケーリングするのにも役立ちます。
セグメントが Amazon S3 にアップロードされると、プライマリはチェックポイント リクエストを送信し、すべてのレプリカに新しいセグメントをダウンロードするように通知します。次に、レプリカ コピーは増分セグメントをダウンロードする必要があります。このプロセスにより、レプリカ上のコンピューティング リソースが解放されます。このプロセスを使用しない場合は、データの冗長インデックス作成と、データを複製するためにプライマリで発生するネットワーク オーバーヘッドに必要なリソースが解放されるため、クラスターはより多くのスループットを生み出すことができます。過負荷またはネットワーク パスの遅さにより、レプリカが新しく作成されたセグメントを処理できない場合、古い結果が返されるのを防ぐために、ある時点を超えるレプリカは失敗としてマークされます。
耐久性が高いのは良いアイデアだが、うまくやるのが難しい理由
コミットされたセグメントはすべて、作成されるたびに Amazon S3 に永続的に保持されますが、高い耐久性を実現するための重要な課題の 3 つは、クライアントへのリクエストを確認応答する前に、コミットされていないすべてのオペレーションを Amazon SXNUMX の先行書き込みログに同期的に書き込むことです。スループット。新しいセマンティクスにより、個々のリクエストに対して追加のネットワーク遅延が発生しますが、スループットに影響がないことを確認する方法は、指定された間隔まで単一スレッドでリクエストをバッチ処理して排出し、同時に他のスレッドがインデックスを作成し続けるようにすることです。リクエスト。その結果、大量のペイロードを最適にバッチ処理することで、より多くの同時クライアント接続でスループットを向上させることができます。
耐久性の高いシステムを設計する際のその他の課題には、データの整合性と正確性を常に強化することが含まれます。ネットワーク分割などの一部のイベントはまれですが、システムの正確性が損なわれる可能性があるため、システムはこれらの障害モードに対処する準備ができている必要があります。したがって、新しいセグメント レプリケーション プロトコルに切り替える際に、各レプリカで複数のライターを検出するなど、他のプロトコルの変更もいくつか導入しました。このプロトコルは、クラスター マネージャー クォーラムに基づいて、新しく昇格された別のプライマリが新しい書き込みを同時に受け付けている間、分離されたライターが書き込みリクエストを確認できないことを保証します。
新しいインスタンスファミリーは、データの回復中にプライマリシャードの損失を自動的に検出し、Amazon S3 からデータを再ハイドレートしてクラスターを正常な状態に戻す前に、ネットワークの到達可能性について広範なチェックを実行します。
データの整合性を確保するため、すべてのファイルは広範囲にわたってチェックサムを取得し、データを読み取れなくなる可能性のあるネットワークまたはファイル システムの破損を検出して防止できることを確認します。さらに、メタデータを含むすべてのファイルは不変になるように設計されており、破損に対する安全性が向上し、偶発的な変更を防ぐためにバージョン管理されています。
データの流れを再考する
OR1 インスタンスは、インフラストラクチャ障害時に失われたシャードの回復を実行するために、Amazon S3 から直接コピーをハイドレートします。 Amazon S3 を使用することで、プライマリ ノードのネットワーク帯域幅、ディスク スループット、コンピューティングを解放できるため、プライマリ ノードの調整を最小限に抑えてプロセス全体を調整することで、よりシームレスなインプレース スケーリングと Blue/Green デプロイメント エクスペリエンスを提供できます。
OpenSearch Service は、と呼ばれる自動データ バックアップを提供します。 スナップショット つまり、データを誤って変更した場合に、前の特定の時点の状態に戻ることができます。ただし、新しい OpenSearch インスタンス ファミリーでは、データがすでに Amazon S3 に永続的に保存されていると説明しました。では、Amazon S3 にデータがすでに存在している場合、スナップショットはどのように機能するのでしょうか?
新しいインスタンス ファミリーでは、スナップショットがチェックポイントとして機能し、ある時点で存在する既存のセグメント データを参照します。これにより、追加のデータを再アップロードする必要がなくなるため、スナップショットがより軽量かつ高速になります。代わりに、その時点でのセグメントのビューをキャプチャするメタデータ ファイルをアップロードします。これを私たちはメタデータ ファイルと呼びます。 浅いスナップショット。浅いスナップショットの利点は、スナップショットの作成、削除、クローン作成など、すべての操作に及びます。独立したコピーのスナップショットを作成するオプションもまだあります。 手動スナップショット その他の管理業務のため。
まとめ
OpenSearch は、オープンソースのコミュニティ主導のソフトウェアです。レプリケーション モデル、リモートバックアップ ストレージ、リモート クラスターのメタデータなどの基本的な変更のほとんどはオープン ソースに提供されています。実際、私たちはオープンソースファーストの開発モデルに従っています。
スループットと信頼性を向上させる取り組みは、学習と改善を続ける終わりのないサイクルです。新しい OpenSearch に最適化されたインスタンスは、基礎的な構成要素として機能し、将来のイノベーションへの道を切り開きます。私たちは、信頼性とパフォーマンスの向上に向けた取り組みを継続し、新規および既存のソリューション ビルダーが OpenSearch Service を使用してどのようなものを作成できるかを見ることに興奮しています。これにより、新しい OpenSearch インスタンス ファミリー、この製品がどのようにして高い耐久性と優れたスループットを実現するのか、そしてそれがビジネスのニーズに基づいてクラスターを構成するのにどのように役立つのかについて、より深い理解が得られることを願っています。
OpenSearch に貢献することに興奮している場合は、 GitHubの問題 あなたの考えをお聞かせください。また、OpenSearch Service で高いスループットと耐久性を実現した成功事例についてもぜひお聞かせください。他にご質問がある場合は、コメントを残してください。
著者について
 ブフタワル・カーン Amazon OpenSearch Service に取り組むプリンシパルエンジニアです。 彼は分散型自律システムの構築に興味を持っています。 彼は OpenSearch のメンテナーであり、積極的な貢献者でもあります。
ブフタワル・カーン Amazon OpenSearch Service に取り組むプリンシパルエンジニアです。 彼は分散型自律システムの構築に興味を持っています。 彼は OpenSearch のメンテナーであり、積極的な貢献者でもあります。
 ガウラフ・バフナ アマゾン ウェブ サービスで OpenSearch に取り組むシニア ソフトウェア エンジニアです。 彼は分散システムの問題を解決することに興味を持っています。 彼は OpenSearch のメンテナーであり、積極的な貢献者でもあります。
ガウラフ・バフナ アマゾン ウェブ サービスで OpenSearch に取り組むシニア ソフトウェア エンジニアです。 彼は分散システムの問題を解決することに興味を持っています。 彼は OpenSearch のメンテナーであり、積極的な貢献者でもあります。
 サチン・ケール AWS のシニア ソフトウェア開発エンジニアで、OpenSearch に取り組んでいます。
サチン・ケール AWS のシニア ソフトウェア開発エンジニアで、OpenSearch に取り組んでいます。
 ロヒン・バルガヴァ は、AmazonOpenSearchServiceチームのシニアプロダクトマネージャーです。 AWSでの彼の情熱は、お客様がAWSサービスの正しい組み合わせを見つけて、ビジネス目標を達成できるよう支援することです。
ロヒン・バルガヴァ は、AmazonOpenSearchServiceチームのシニアプロダクトマネージャーです。 AWSでの彼の情熱は、お客様がAWSサービスの正しい組み合わせを見つけて、ビジネス目標を達成できるよう支援することです。
 ランジス・ラマチャンドラ は、Amazon OpenSearch Service に取り組むシニアエンジニアリングマネージャーです。 彼は、拡張性の高い分散システム、高性能で回復力のあるシステムに情熱を注いでいます。
ランジス・ラマチャンドラ は、Amazon OpenSearch Service に取り組むシニアエンジニアリングマネージャーです。 彼は、拡張性の高い分散システム、高性能で回復力のあるシステムに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

