概要
Salesforce は、カリフォルニア州サンフランシスコに本社を置く有名なクラウドベースのソフトウェア会社です。 企業が顧客とのすべてのやり取りをより効果的かつ効率的に管理できるようにする顧客関係管理 (CRM) ソリューションで最もよく知られています。 CRM プラットフォームは高度にカスタマイズ可能であり、ユーザーは販売、マーケティング、顧客サービス、分析、アプリケーション開発を自動化できます。
Salesforce のサービスは、いくつかの広いカテゴリに分類されます。営業部門の自動化のための Sales Cloud、顧客サポートのための Service Cloud、デジタル マーケティング キャンペーンのための Marketing Cloud、オンライン ショッピングのための Commerce Cloud などです。 これらのソリューションは相互接続されており、ビジネスの成長を促進するデータと洞察のシームレスなフローを可能にします。
人工知能は Salesforce Einstein を通じてプラットフォームに統合され、販売、サービス、マーケティングに AI を活用した分析を提供します。 Salesforce はユーザーのトレーニングとスキル向上のための Trailhead プラットフォームも提供し、ユーザーの成功への取り組みを強調しています。
Salesforce における OCR とドキュメントデータ抽出の必要性
デジタル変革の時代において、企業には膨大な量のデータが氾濫しています。 顧客とのやり取り、ビジネス取引、および行政手続きにより、慎重な管理が必要な大量のドキュメントが生成されます。 主要な顧客関係管理 (CRM) プラットフォームである Salesforce は、このデータのハブとして機能し、戦略的なビジネス上の意思決定を推進するための分析を容易にします。 ただし、光学式文字認識 (OCR) および文書データ抽出テクノロジーと組み合わせると、Salesforce の有効性が大幅に向上します。
OCR は、スキャンした紙文書、PDF ファイル、デジタル カメラでキャプチャした画像など、さまざまな種類の文書を編集可能および検索可能なデータに変換するテクノロジーです。 一方、ドキュメント データ抽出は、さまざまな種類のドキュメントから特定の情報を収集し、さらなる処理と分析のために非構造化データを構造化形式に変換するプロセスです。
手動でのデータ入力は労力がかかるだけでなく、エラーが発生しやすく、Salesforce 内のデータの品質が低下する可能性があります。 OCR とドキュメント データ抽出の導入により、この課題は解消されます。 これらのテクノロジーは、データを自動的に取得、分類し、Salesforce に入力することで、データ入力のプロセスを合理化します。 その結果、効率が向上し、人的エラーが削減され、ビジネス インテリジェンスと意思決定に高品質で正確なデータが確実に利用できるようになります。
多数の請求書、契約書、フォームを扱う会社の例を考えてみましょう。 OCR テクノロジーによりこれらの文書をデジタル化して検索や編集が可能になり、文書データ抽出により日付、金額、契約条件、顧客の詳細などの関連情報を抽出できます。 抽出されたデータは Salesforce に自動的に入力されるため、管理作業の負荷が軽減され、データの全体的な精度が向上します。
OCR およびドキュメントデータ抽出テクノロジーは、Salesforce の中核である顧客サービスとサポートの強化においても重要な役割を果たします。 顧客関連の文書やコミュニケーションを迅速に処理することで、応答時間を短縮し、顧客サービスの品質を向上させることができます。 物理的な文書、電子メール、またはデジタル フォームからの情報を顧客サービス担当者が迅速に利用できるようになり、よりパーソナライズされたタイムリーなサポートを提供できるようになります。
これらのテクノロジーは、効率と精度に加えて、手動プロセスでは到底太刀打ちできないレベルの拡張性ももたらします。 ビジネスが成長し、データ量が増加するにつれて、OCR およびドキュメント データ抽出テクノロジはそれに応じて拡張でき、一貫したデータ品質とプロセス効率を確保できます。
コンプライアンスは、OCR とドキュメント データ抽出が大きな利点を提供するもう XNUMX つの分野です。 多くの業界は、特定のデータを特定の形式で保持することを要求する規制の対象となります。 このデータの抽出と分類を自動化することで、企業は規制要件を確実に遵守し、監査や調査に必要なデータにすぐにアクセスできるようになります。
結論として、OCR とドキュメント データ抽出を Salesforce と統合すると、強力な相乗効果が得られます。 これらのテクノロジーは、データ品質の向上、プロセス効率の向上、顧客サービスの強化、拡張性の実現、規制遵守の促進により、CRM ツールとしての Salesforce の能力を強化します。 企業がデジタル環境への対応を続けるにつれ、これらのテクノロジーをデータ管理戦略に組み込むことは、競争上の優位性となるだけでなく、ますます必要不可欠なものとなるでしょう。
Salesforce を使用した OCR ワークフローの例
請求書の処理: 企業はさまざまなサプライヤーから無数の請求書を受け取ります。 Nanonets OCR を使用すると、これらの請求書をデジタル化でき、サプライヤー名、請求書番号、日付、明細項目の詳細、合計金額などの関連情報を抽出できます。 この抽出されたデータは、Salesforce Billing または FinancialForce システムに自動的に入力できます。 OCR ソリューションにより、注文書と請求書の自動照合が可能になり、財務チームが買掛金をより効率的に管理できるようになります。
受注管理: 企業は多くの場合、物理的またはデジタルの販売注文を処理します。 Nanonets OCR を使用すると、顧客名、注文番号、製品の詳細、数量などの重要なデータをこれらの文書から抽出できます。 データは Salesforce の Sales Cloud にインポートされ、受注および関連する商談レコードを自動的に作成または更新できます。 これにより、販売プロセスが合理化され、注文データの正確性が保証されます。

顧客のオンボーディング: 顧客のオンボーディング プロセス中に、企業は身分証明、住所証明、財務書類などのさまざまな文書を収集します。 Nanonets OCR を使用すると、これらの文書から顧客の名前、住所、生年月日などの重要なデータを抽出できます。このデータを使用して、Salesforce の Service Cloud に新しい顧客のレコードを入力し、オンボーディング プロセスを迅速化し、正確な顧客データを確保できます。今後のやりとり。
契約管理: 企業は多くの場合、ベンダー契約、リース契約、顧客契約など、複数の種類の契約を扱います。 Nanonets OCR を使用すると、契約期間、更新日、条項、関係者などの重要なデータをこれらの契約から抽出できます。 この情報は Salesforce の契約管理システムに入力できるため、企業は契約上の義務を追跡し、更新通知を自動化できるため、契約違反や契約失効のリスクを軽減できます。
保険請求の処理: 保険業界では、請求処理には、事故報告書、医療文書、領収書などのさまざまな種類の文書の確認が含まれます。 Nanonets OCR は、請求番号、保険証券番号、請求金額、請求の性質などの関連データを抽出できます。 このデータを Salesforce の保険請求管理システムに入力することで、請求処理時間を短縮し、精度を向上させ、顧客満足度を高めることができます。
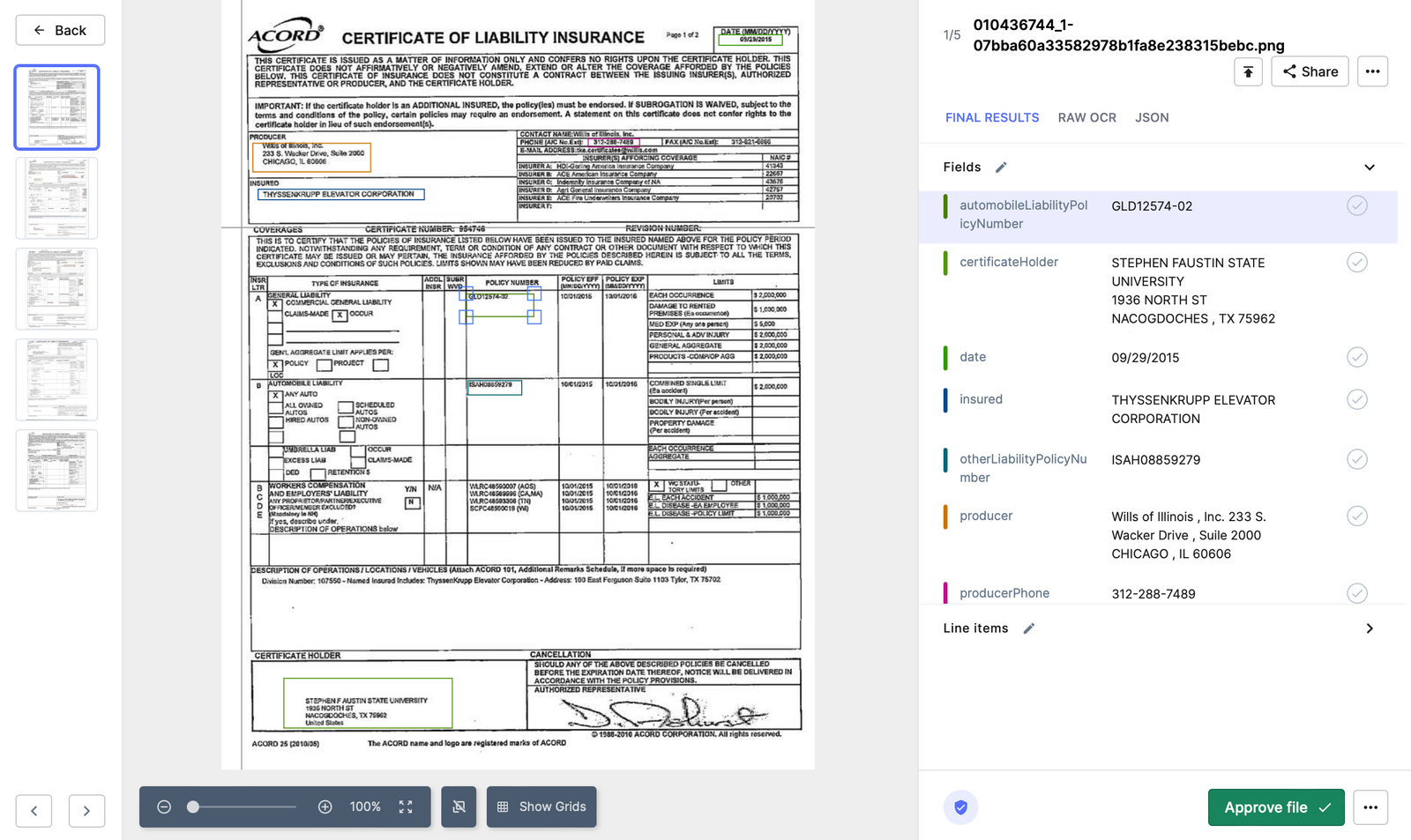
Nanonets を使用して Salesforce で OCR とドキュメント抽出を設定する方法
以下の手順に従って、Nanonets を使用して Salesforce の OCR とドキュメント抽出を設定できます。

- ドキュメントの種類に基づいて事前トレーニングされたモデルを選択し、数分以内に独自のドキュメント抽出ツールを作成します。

- モデルを作成したら、左側のナビゲーション ペインの [ワークフロー] セクションに移動します。

- ワークフロー画面で、エクスポートタブに移動し、「Salesforceにエクスポート」をクリックします。

- 「Salesforce にサインイン」をクリックします。

- Salesforce の認証情報を入力します。
- Nanonets Salesforce カードに戻り、Nanonets フィールドを Salesforce の対応する列にマップします。
例: Nanonets で取得された Invoice_number は、Salesforce の「請求書 ID」の下に入力される必要があります。 これら XNUMX つのエンティティをリンクするには、Nanonets エクスポート モーダルでマッピングする必要があります。 - エクスポート トリガーを選択します。
– ファイルは処理後すぐにエクスポートできます。または
– ファイルは承認済みとマークされている場合にのみエクスポートできます - 「完了」をクリックすれば準備完了です。
統合を追加すると、Nanonets はエクスポート設定に基づいて受信ファイルから抽出されたデータを Salesforce に送信します。
OCR 用の Nanonets と Salesforce 用の自動データ抽出
デジタル データが増大する時代に突入するにつれ、企業はこのデータを効果的に管理、解釈し、CRM システムに統合するという課題に直面しています。 Salesforce は、主要な CRM プラットフォームとして、この情報の効率的な処理を容易にします。 しかし、光学式文字認識 (OCR) や自動データ抽出などの高度なテクノロジーと統合すると、その能力を大幅に高めることができます。 Nanonets は、この目的を果たし、企業のデータ管理方法に革命をもたらす強力なツールの XNUMX つです。
Nanonets は、機械学習ベースの OCR およびデータ抽出ソリューションであり、企業がさまざまなドキュメントの非構造化データを構造化された実用的な情報に変換できるようにします。 請求書、契約書、注文書、フォームなどの無数の種類のドキュメントをシームレスに操作し、重要なデータを抽出して分析と処理の準備を整えます。
プロセスの最初のステップでは、文書をスキャンしてデジタル化します。 Nanonets OCR は、高度なアルゴリズムを採用して、形式やスキャンの品質に関係なく、文書内のテキストを正確に認識します。 これは、スキャンした紙文書、PDF ファイル、さらには画像のデータを、編集可能で検索可能な形式に簡単に変換できることを意味します。
次に、Nanonets の自動データ抽出機能が機能します。 デジタル化された文書から、名前、日付、数字、その他の関連する詳細などの特定のデータ ポイントを識別して抽出できます。 このソリューションの時間の経過とともに学習および改善できる機能により、データ抽出の高精度が保証され、手動データ入力に伴う人的エラーの可能性が低減されます。
Nanonets の利点は、Salesforce とのシームレスな統合にあります。 Nanonets によって抽出されたデータは、Salesforce の適切なフィールドに自動的に入力できます。 たとえば、請求書データを Salesforce Billing システムに送信したり、販売注文の詳細で販売注文と商談を更新したり、オンボーディング ドキュメントからの顧客データを Service Cloud に入力したりできます。
基本的に、Nanonets は、さまざまなドキュメントの非構造化データを Salesforce の構造化環境に接続するブリッジとして機能します。 これにより、手動データ入力にかかる時間とリソースが大幅に節約されるだけでなく、Salesforce システム内のデータの信頼性も確保されます。 その結果、企業は高品質で正確なデータを活用して、戦略的意思決定を推進し、顧客サービスを強化し、全体的な業務効率を向上させることができます。
さらに、Nanonets の拡張性は、ビジネスの拡大に伴って増大するデータを処理できることを意味し、データ品質とプロセス効率の一貫性を確保します。 コンプライアンスは、ナノネットが大きな利点を提供するもう XNUMX つの分野です。 規制要件に合わせて保持する必要があるデータの抽出と分類を支援し、企業がコンプライアンスを維持し、監査や調査に備えるのに役立ちます。
結論として、Nanonets は OCR とデータ抽出のための強力な自動ソリューションを提供しており、Salesforce と統合すると CRM プラットフォームの有効性を大幅に高めることができます。 これにより、企業はデータを活用し、顧客エンゲージメント、業務効率、ビジネスの成長を促進する戦略的資産に変えることができます。 デジタル時代がさらに進むにつれて、データを最大限に活用しようとしている企業にとって、Nanonets のようなソリューションは不可欠なものとなるでしょう。 Nanonets と Salesforce の相乗効果は、データ管理の未来、つまりデータの抽出と解釈がシームレスで正確で本質的にインテリジェントになる未来を垣間見ることができます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/salesforce-ocr-and-pdf-data-extraction/

