607 8
| SEO | – 13分読み取り – | 2024 年 1 月 2 日 |


Serpstat API には、キーワード調査からバックリンク分析まで、SEO ワークフローの事実上すべての側面を網羅する多くのエンドポイントがあります。 Domain Keywords エンドポイントは、クライアントとその競合他社の生データを抽出するためだけでなく、データ サイエンス技術を使用して洞察を生成するためにも使用できます。以下では、Python を使用してこれを行う方法を示します。
この分析情報は、クラウド コンピューティング データ パイプラインの一部として使用され、Looker、Power BI などの SEO ダッシュボード レポートを強化できます。
APIトークンを取得する
SERPSTAT API をクエリするには、API トークンが必要です。API トークンは、次のようなドキュメント ページに表示されます。 メインAPIページ以下に示すように、

API トークンをコピーしたら、Jupyter iPython ノートブックを起動するときにこれを使用できます。
Jupyter iPython ノートブックを開始する
すべての Python コードは、Jupyter iPython ノートブック環境で実行されます。同様に、必要に応じて、コードは COLAB ノートブックで実行されます。これを起動して実行したら、ライブラリに含まれる関数をインポートします。
インポート要求
パンダをpdとしてインポート
npとしてnumpyをインポートする
jsonをインポートする
プロットナインインポートから*
API 呼び出しを行うには、リクエスト ライブラリが必要です。
Python で Excel と同様にデータ フレームを処理するには、Python を使用し、短縮エイリアスとして「pd」を割り当て、pandas 関数の使用を簡素化します。また、Numpy (略称「np」) を使用して、データ フレーム内のデータを操作します。
API からのデータは多くの場合辞書形式であるため、JSON は結果をデータ フレームにプッシュできるデータ構造に解凍するのに役立ちます。
api_token = 「あなたの API キー」
これは以前に取得したものです (上記を参照)。
api_url_pattern = 'https://api.serpstat.com/v{version}?token={token}'
Serpstat API のさまざまなエンドポイントをクエリできるようにする URL パターンを設定します。現在のバージョンは APIv4 です。アプリケーション プログラミング インターフェイスを数回呼び出すことになるため、これにより、繰り返しコードを入力する手間が省けます。
api_url = api_url_pattern.format(version=4, token=api_token)
API バージョンと API トークンを組み込むための API URL を設定します。
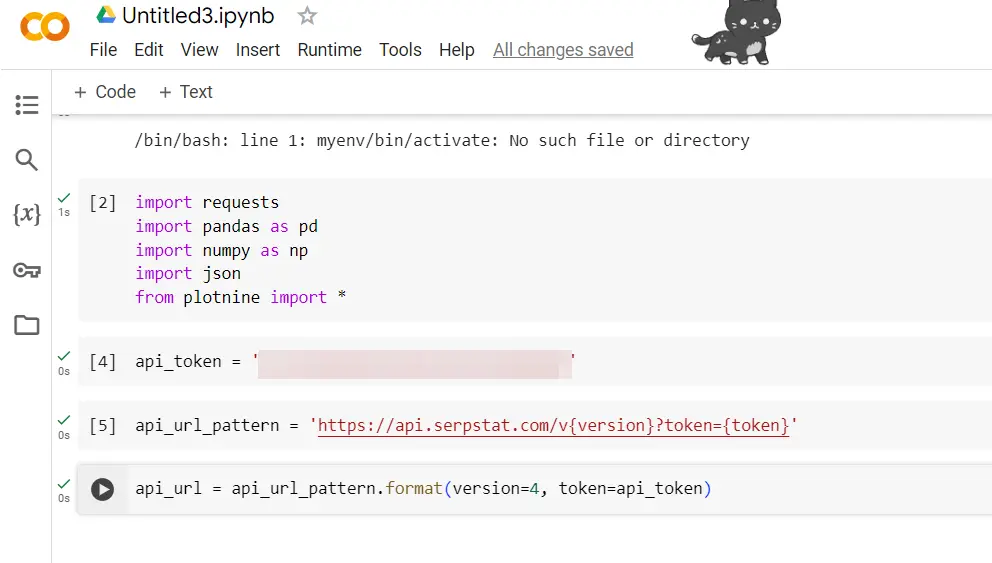
ドメインキーワードの取得
エキサイティングな部分。クエリを実行することで、表示されている任意のドメインのキーワードを抽出できるようになりました。 ドメインキーワード 終点。これにより、特定の検索エンジンでドメインが上位 100 位にランク付けされたすべてのキーワードが表示されます。
まず、API に必要な入力パラメータを設定します。
domain_keyword_params = {
"id": "1",
"method": "SerpstatDomainProcedure.getDomainKeywords",
"params": {
"domain": "deel.com",
"se": "g_uk",
"withSubdomains": False,
"sort": {
"region_queries_count": "desc"
},
"minusKeywords": [
"deel", "deels"
],
"size": "1000",
"filters": {
"right_spelling": False
}
}
}
注意すべき点: Domain Keywords エンドポイントには、メソッドを次のように設定することでアクセスします。 「SerpstatDomainProcedure.getDomainKeywords」
ドメイン名を設定する必要があります "ドメイン" 以下と検索エンジンの下にあります 「グーク」.
この例では、Google UK で deel.com のキーワードを調べます。検索エンジンの完全なリストが利用可能です こちら これは、Google の世界各地と Bing US をカバーします。
追加のオプションには、マイナス キーワード (除外キーワード) が含まれます。この場合、オーガニック トラフィックがどこから来ているかを理解するために、非ブランド キーワードのみに関心があります。
また、 "サイズ" パラメータを、出力可能な最大行数である 1,000 に設定します。
API に特定のキーワードを含めるように制限できるなど、他にも興味深いパラメータがあります (「キーワード」) またはドメイン内のサイト URL (「URL」).
パラメーターを設定したら、以下のコードを使用してリクエストを行うことができます。
domain_keyword_resp = requests.post(api_url, json=domain_keyword_params)
if domain_keyword_resp.status_code == 200:
domain_keyword_result = domain_keyword_resp.json()
print(domain_keyword_result)
else:
print(domain_keyword_resp.text)
API 呼び出しの結果は次の場所に保存されます。 ドメインキーワード応答。 json 関数を使用して応答を読み取り、データを保存します。 ドメインキーワード結果.
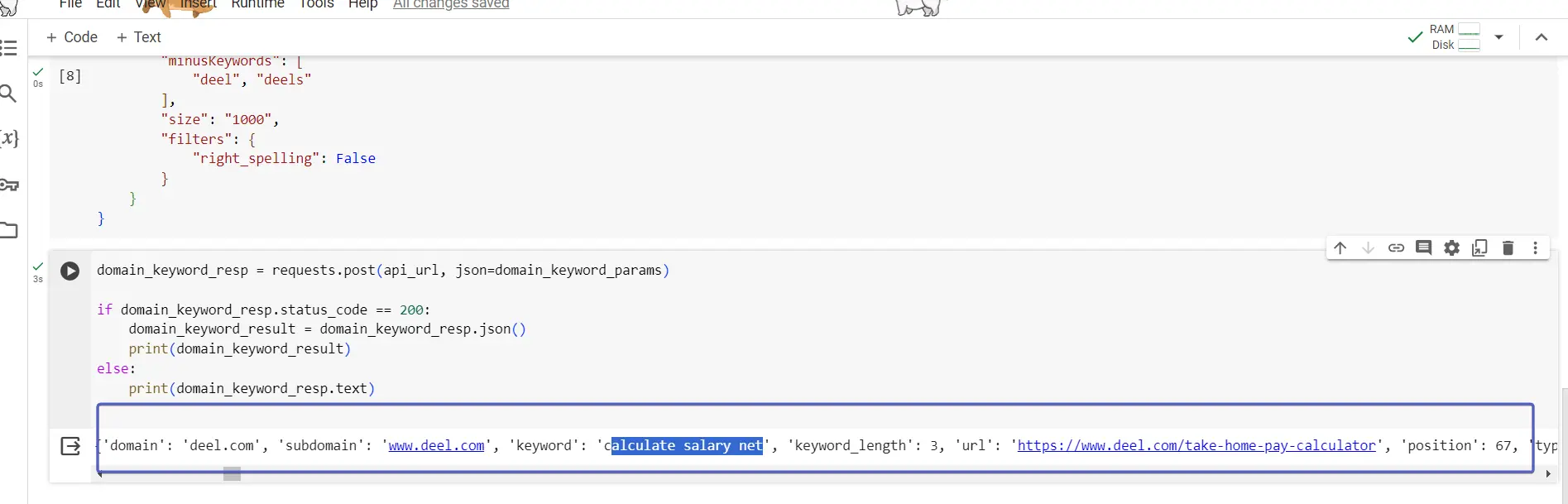
if else 構造は、API 呼び出しが期待どおりに機能しない場合に情報を提供するために使用され、データがない場合や呼び出し時にエラーが発生した場合の API 応答が示されます。
呼び出しを実行すると出力されます ドメインキーワード結果 これは次のようになります:
{'id': '1',
'result':
{'data': [
{'domain': 'deel.com', 'subdomain': 'www.deel.com', 'keyword':
'support for dell', 'keyword_length': 3, 'url': 'https://www.deel.com/',
'position': 73, 'types': ['pic', 'kn_graph_card', 'related_search',
'a_box_some', 'snip_breadcrumbs'], 'found_results': 830000000,
'cost': 0.31, 'concurrency': 3, 'region_queries_count': 33100,
'region_queries_count_wide': 0, 'geo_names': [], 'traff': 0,
'difficulty': 44.02206115387234, 'dynamic': None},
{'domain': 'deel.com', 'subdomain': 'www.deel.com',
'keyword': 'hr and go',
'keyword_length': 3, 'url': 'https://www.deel.com/',
'position': 67, 'types': ['related_search', 'snip_breadcrumbs'],
'found_results': 6120000000, 'cost': 0.18, 'concurrency': 4,
'region_queries_count': 12100, 'region_queries_count_wide': 0,
'geo_names': [], 'traff': 0, 'difficulty': 15.465889053157944,
'dynamic': 3},
API を操作するときは、データ構造を出力して、データを使用可能な形式に解析する方法を知ることが重要です。これは、必要なデータが結果データ キーの下に含まれる、複数のキーを持つ辞書を生成するわけではありません。データの値は辞書のリストにあり、各辞書はキーワードを表します。
データを抽出するために以下のコードを作成しました。 ドメインキーワード結果 に押し込みます ドメインキーワード_df データフレーム:
Domain_keyword_df = pd.DataFrame(domain_keyword_result[‘結果’][‘データ’])
データフレームを表示してみましょう。
表示(ドメイン_キーワード_df)
次のようになります:
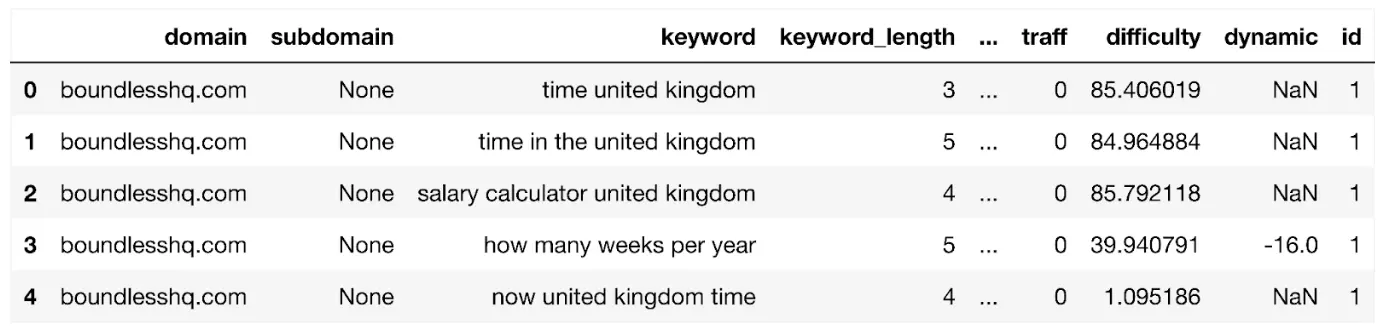
データフレームには、ドメインのすべてのキーワードが最大 1,000 行まで表示されます。次のような列フィールドが含まれます。
- リージョンクエリ数: 対象地域内の検索ボリューム
- URL: キーワードのランク URL
- 位置:SERPランク
- : SERPの特徴
- 並行性: 取引および/または商業的意図のレベルを示す可能性がある有料検索広告の量。
大規模なサイトで作業しているため、さらに多くの機能が必要な場合は、次のようにすることができます。
2.for ループの一部としてこれらのサイト URL に対して上記のコードを使用し、複数のドメイン キーワード呼び出しを実行します。この場合、URL を入力パラメータとして指定します。 「URL」.
データ特徴の作成
洞察を得るために、生データの要約を支援するいくつかの機能を作成したいと考えています。ベスト プラクティスに従って、データフレームのコピーを作成し、それを新しいデータフレームに保存します。 dk_enhanced_df.
dk_enhanced_df = ドメインキーワード_df.copy()
という新しい列を設定します。 'カウント' 後で説明するように、文字通り物を数えることができるようになります。
dk_enhanced_df[‘カウント’] = 1
また、SERP ページ カテゴリを示す「serp」というカスタマイズされた列も作成したいと考えています。これは、SERP ごとのサイトの位置の分布を確認し、ダッシュボード レポートにプッシュするのに役立ちます。
<code data-code="dk_enhanced_df['serp'] = np.where(dk_enhanced_df['position'] dk_enhanced_df[「セルプ」] = np。どこ(dk_enhanced_df['位置'] < 11, '1', 「どこにもない」) dk_enhanced_df[「セルプ」] = np。どこ(dk_enhanced_df['位置']。間(11, 20), '2'、dk_enhanced_df[「セルプ」]) dk_enhanced_df[「セルプ」] = np。どこ(dk_enhanced_df['位置']。間(21, 30), '3'、dk_enhanced_df[「セルプ」]) dk_enhanced_df[「セルプ」] = np。どこ(dk_enhanced_df['位置']。間(31, 99), 「4+」、dk_enhanced_df[「セルプ」])
SERP は上記のコードを使用してコード化されています。 numpy.where この関数は、よりよく知られた Excel の if ステートメントの Python バージョンに似ています。
タイプ列に注目すると、その値には、キーワードの検索エンジンに表示されるユニバーサル検索結果タイプのリストが含まれています。
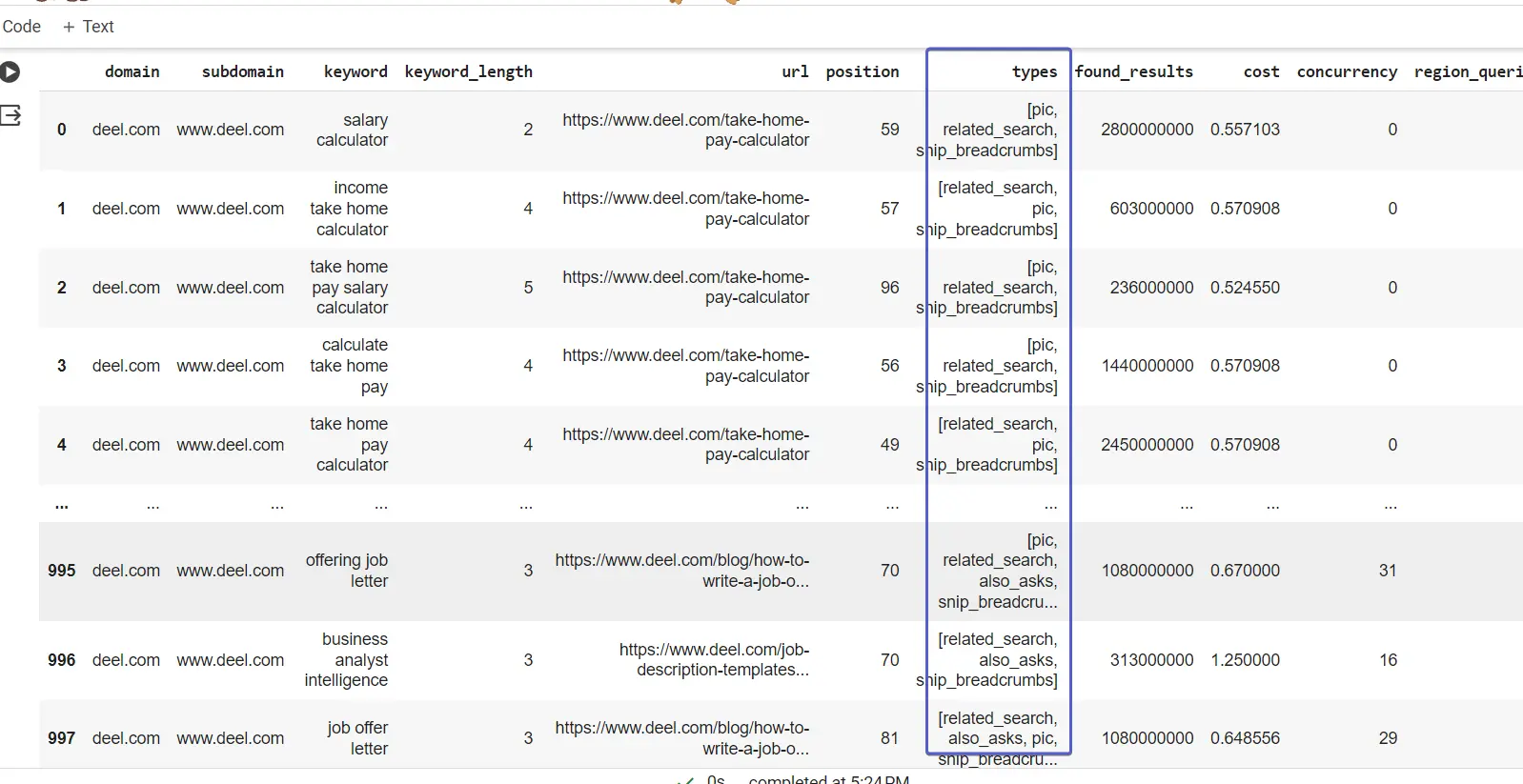
これを解凍し、次のコマンドを使用して分析を容易にします。 ワンホットエンコーディング (OHE) テクニック。 OE は、すべての結果タイプの値の列を作成し、キーワードの結果が存在する場所に 1 を配置します。
types_dummies = pd.get_dummies(dk_enhanced_df[‘types’].apply(pd.Series).stack())。
合計(レベル=0)
ワンホット エンコードされた結果タイプの列を dk_enhanced_df データフレーム
dk_enhanced_df = pd.concat([dk_enhanced_df.drop(columns=[‘types’]), tables_dummies], axis=1)
ディスプレイ(dk_enhanced_df)

OHE とその他の機能強化のおかげで、分析と洞察の生成が容易になる列を含む拡張されたデータフレームが得られました。
自信を持って SEO の旅を始めましょう!
7 日間のトライアルにサインアップして、API を使用した高度な SEO 分析の世界に飛び込んでください。約束はなく、ただ純粋に探求するだけです。
ドメインキーワードデータの調査
まず、ドメイン キーワード データの統計的特性を調べることから始めます。 describe() 関数:
dk_enhanced_df.describe()
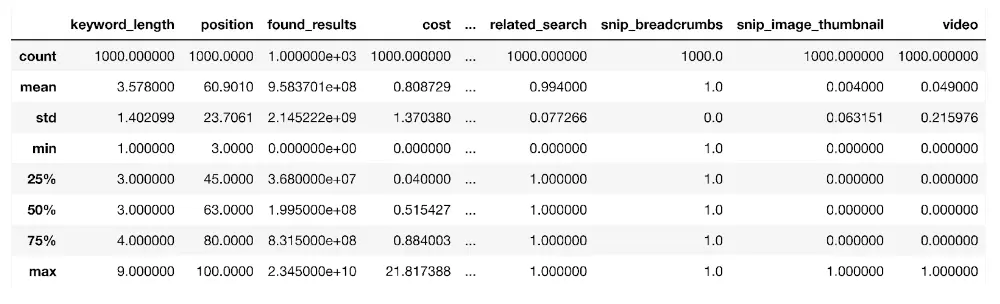
この関数は、データフレーム内のすべての数値列を取得して、平均 (平均)、平均からの分散率を測定する標準偏差 (std)、データ ポイントの数 (カウント)、および上に示したように、25 番目 (25%) などのパーセンタイル。
この関数は概要として便利ですが、ビジネスの観点から見ると、データを集計するのに役立つことがよくあります。たとえば、次の組み合わせを使用します。 グループバイ & adj 以下のコードを使用して、SERP 1 などにあるキーワードの数をカウントできます。
serp_agg = dk_enhanced_df.groupby('serp').agg({'count': 'sum'}).reset_index()
groupby 関数は (Excel のピボット テーブルと同じように) 列ごとにデータフレームをグループ化し、他の列を集計します。この使用例では、以下に示すように、SERP ごとにグループ化して、各 SERP に含まれるキーワードの数を数えています。
ディスプレイ(serp_agg)
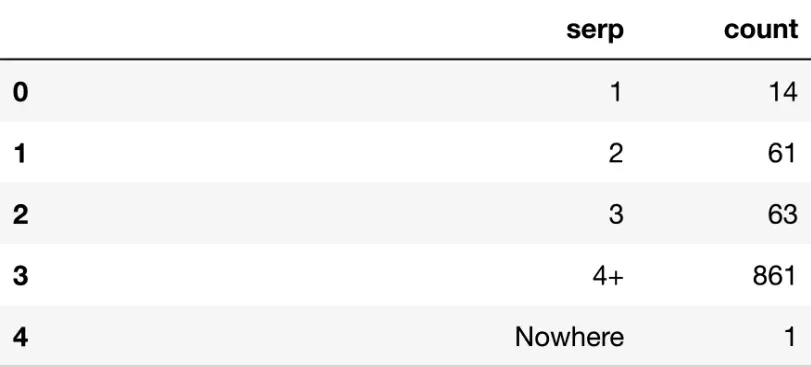
SERP 3+ のカウント値 861 が示すように、ほとんどのキーワードは 4 ページ以降にあります。
SEO の専門家ではない視聴者向けにデータを視覚化したい場合は、plotnine の ggplot 関数を使用できます。
serp_dist_plt = (ggplot(serp_agg,
aes(x = 'serp', y = 'count')) +
geom_bar(stat = 'identity', alpha = 0.8, fill = 'blue') +
labs(y = 'SERP', x = '') +
theme_classic() +
theme(legend_position = 'none')
)
ggプロット データフレームと美学 (aes) という 2 つの主な引数を取ります。 aes は、グラフにマップされるデータフレームの部分を指定します。チャートの種類や軸のラベルなどを決定するために、コードに追加のレイヤーが追加されます。この例では、棒グラフである geom_bar を使用しています。
コードはチャートオブジェクトに保存されます serp_dist_plt これを実行すると、次のグラフが表示されます。
serp_dist_plt
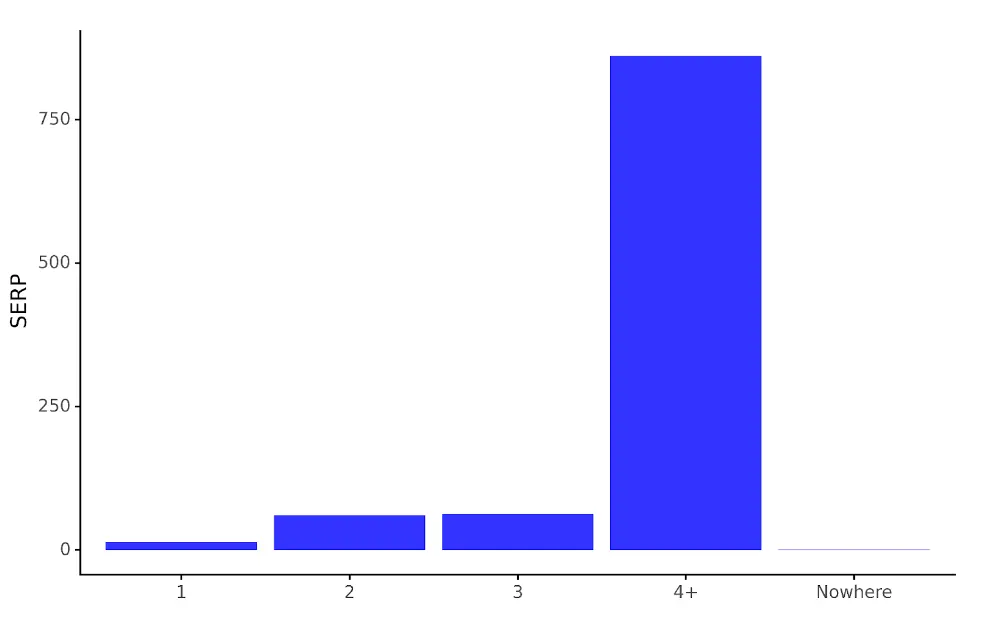
生成されたチャートは、 serp_agg データフレームを使用すると、SERP 間のキーワードの位置の数を比較するのがはるかに簡単になります。
ドメインキーワードからの競合他社の洞察
これは素晴らしいことですが、単一の Web サイト ドメインの数値は、同じ検索スペースで競合する他のサイトと比較した場合ほど洞察力に欠けます。上記の例では、deel.com の SERP 14 には 1 個のキーワードがあります。それで良いでしょうか?悪い?平均?どうやって知ることができるのでしょうか?
競合するドメイン データによりコンテキストと意味が追加され、API クレジットを消費するのに適した使用例となります。上記のコードを適応させると、複数のドメインのデータを取得して、より意味のあるものを取得できます。
たとえば、同じスペースで運営されている競合サイトで同じ API エンドポイントを使用すると、各ドメインの SERP ごとのキーワード数を示す表が得られます。
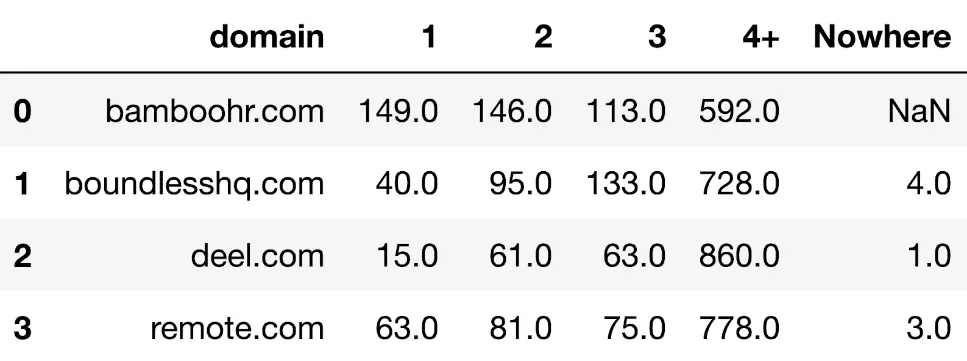
より視覚化された形式では、次のようになります。
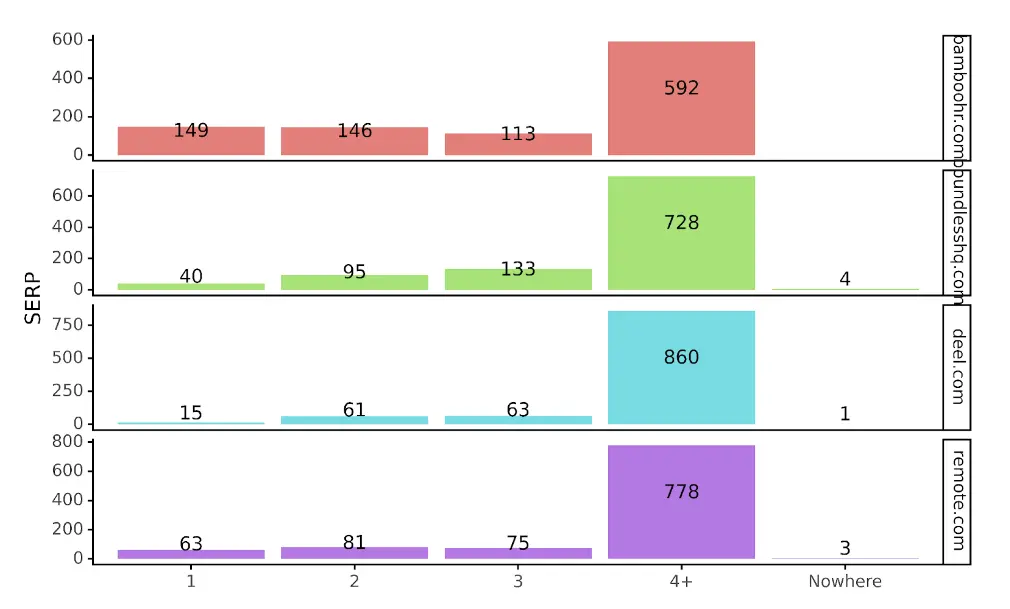
追加のコンテキストにより、deel は他の競合他社と比較して SERP 1 でパフォーマンスが劣っている可能性があることがわかります。また、Bamboo HR がリードしており、次に、remote.com が続いていることもわかります。実際、SERP 1 よりも SERP 2 の方が多いサイトは Bamboo だけです。
API を使用すると、データから傾向を抽出できるだけでなく、どの SERP キーワードが Bamboo の可視性を高めているかを確認するための実際のデータも得られます。 Python では次のようになります。
bamboo_serp_1s = mdk_enhanced_df.loc[mdk_enhanced_df[‘ドメイン’] == ‘bamboohr.com’].copy()
上記は、ドメインの API データを組み合わせたデータフレームと、bamboohr.com というドメインのフィルターを取得します。
ディスプレイ(bamboo_serp_1s)

これは、コンテンツ計画の目的で Excel にエクスポートできます。
その他のドメインのキーワードに関する洞察
これまでのコードは、Domain Keywords API からデータを抽出することに重点を置き、わずか 1 列で単一ドメインおよび複数ドメインに関する洞察を生成できることを示しました。
ドメイン キーワード エンドポイント内で他の列を調査し、競合ドメインを比較することで、さらに多くの洞察が得られるでしょうか。それは、SERPSTAT API から利用できる他のエンドポイントの使用を開始する前です。
たとえば、どの結果タイプが最も多く表示されますか? Google の傾向を理解するのに役立つ特定の結果タイプが時間の経過とともに増加していますか?結果タイプ列を解凍する上記のコードは、開始に役立つはずです。
ゲスト投稿の著者の意見は、Serpstat の編集スタッフおよび専門家の意見と一致しない場合があります。
エラーが見つかりましたか? それを選択して Ctrl + Enter を押して教えてください
他の SEO ツールを発見する
バックリンクチェッカー
バックリンクのチェック あらゆるサイトに。 バックリンクプロファイルの力を強化する
SEO用API
ビッグデータを検索し、結果を取得する SEO API
おすすめの投稿
ニュースを追う時間がありませんか? 心配ない! 私たちの編集者は、あなたの仕事に確実に役立つ記事を選択します。 居心地の良いコミュニティに参加してください 🙂
ボタンをクリックすることにより、あなたは私たちに同意します プライバシーポリシー。
本気ですか?
ありがとうございます。新しいメール設定を保存しました。
バグを報告
読み込み中、しばらくお待ちください...
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://serpstat.com/blog/competitor-keywords-api-with-python

