概要
大規模言語モデルの出現により (LLM)、これらは多くのアプリケーションに浸透し、次のような小型の変圧器モデルに取って代わりました。 ベルト または多くのルールベースのモデル 自然言語処理(NLP) タスク。 LLM は多用途であり、広範な事前トレーニングにより、テキスト分類、要約、感情分析、トピック モデリングなどのタスクを処理できます。ただし、LLM はその広範な機能にもかかわらず、小規模な対応物と比較して精度が劣ることがよくあります。
この制限に対処するための 1 つの効果的な戦略は、事前トレーニングされた LLM を微調整して、特定のタスクで優れた性能を発揮することです。大規模なモデルを微調整すると、最適な結果が得られることがよくあります。特に、Google の Gemini は、他の大規模モデルの中でも特に、ユーザーが独自のトレーニング データを使用してこれらのモデルを微調整する機能を提供しています。このガイドでは、特定の問題に合わせて Gemini モデルを微調整するプロセスと、HuggingFace のリソースを使用してデータセットをキュレーションする方法について説明します。
学習目標
- Google の Gemini モデルのパフォーマンスを理解します。
- Gemini モデルの微調整のためのデータセットの準備について学びます。
- Gemini モデル微調整用のパラメーターを構成します。
- 微調整の進行状況と指標を監視します。
- 新しいデータで Gemini モデルのパフォーマンスをテストします。
- PII マスキング用の Gemini モデル アプリケーションを探索します。

この記事は、の一部として公開されました データサイエンスブログ。
目次
Google、Geminiのチューニングを発表
Gemini には、Pro と Ultra の 1.0 つのバージョンがあります。 Pro バージョンには、Gemini 1.5 Pro と新しい Gemini XNUMX Pro があります。 Google のこれらのモデルは、ChatGPT や Claude などの他の高度なモデルと競合します。 Gemini モデルは、AI Studio UI と無料 API を通じて誰でも簡単にアクセスできます。
最近、Google は Gemini モデル向けの新機能である微調整を発表しました。これは、誰でも自分のニーズに合わせて Gemini モデルを調整できることを意味します。 AI Studio UI または API を使用して Gemini を微調整できます。微調整とは、Gemini が希望どおりに動作できるように、独自のデータを Gemini に与えることです。 Google は、Parameter Efficient Tuning (PET) を使用して、Gemini モデルのいくつかの重要な部分を迅速に調整し、さまざまなタスクに役立てています。
データセットの準備
モデルの微調整を始める前に、必要なライブラリのインストールから始めます。ちなみに、このガイドでは Colab と協力して作業します。
必要なライブラリのインストール
開始するために必要な Python モジュールは次のとおりです。
!pip install -q google-generativeai datasets- グーグルジェネレーティブアイ: これは、Google Gemini モデルにアクセスできるようにする Google チームのライブラリです。同じライブラリを使用して、Gemini モデルを微調整することができます。
- データセット: これは、HuggingFace ハブからさまざまなデータセットをダウンロードするために使用できる HuggingFace のライブラリです。このデータセット ライブラリを使用して PII (個人識別情報) データセットをダウンロードし、それを微調整のために Gemini モデルに渡します。
次のコードを実行すると、Google Generative AI とデータセット ライブラリが Python 環境にダウンロードされ、インストールされます。
OAuthのセットアップ
次のステップでは、このチュートリアル用に OAuth を設定する必要があります。 OAuth は、Gemini の微調整のために Google に送信するデータを安全にするために必要です。 OAuth を取得するには、これに従ってください 。次に、OAuth を作成した後、client_secret.json をダウンロードします。 client_secrent.json の内容を Colab Secrets に CLIENT_SECRET 名で保存し、以下のコードを実行します。
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'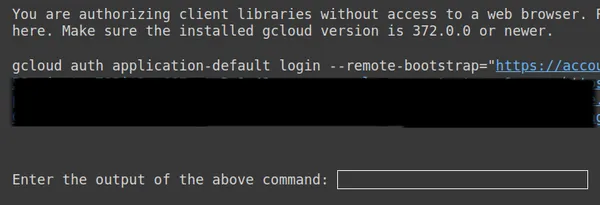
上記の 2 番目のリンクをコピーし、CMD ローカル システムに貼り付けて実行します。
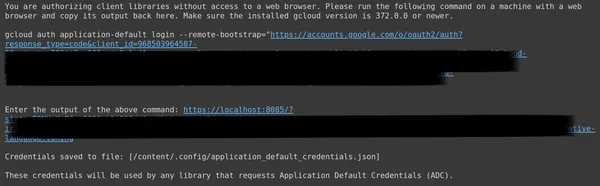
次に、Web ブラウザにリダイレクトされ、OAuth を設定した電子メールでログインします。ログイン後、CMD で URL を取得します。その URL を 3 行目に貼り付けて Enter キーを押します。これで、Google による OAuth の実行が完了しました。
データセットのダウンロードと準備
まず、Gemini モデルに合わせて微調整するために使用するデータセットをダウンロードすることから始めます。このために、データセット ライブラリを使用します。このコードは次のようになります。
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- ここでは、データセット ライブラリからload_dataset関数をインポートすることから始めます。
- このload_dataset()関数に、ダウンロードしたいデータセットを渡します。この例では「ai4privacy/pii-masking-200k」で、200k 行のマスクされた PII データとマスクされていない PII データが含まれています。
- 次に、データセットを印刷します。

データセットには 209261 行のトレーニング データが含まれており、テスト データは含まれていないことがわかります。各行には、masked_text、unmasked_text、privacy_mask、span_labels、bio_labels、tokenized_text などの異なる列が含まれています。サンプルデータは次のとおりです。
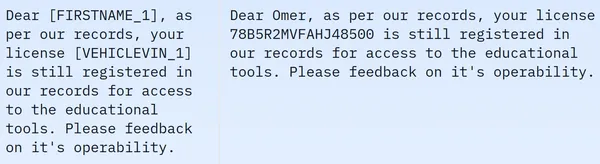
表示された画像では、マスクされた文とマスクされていない文の両方が観察されます。具体的には、マスクされた文では、人物の名前や車の番号などの特定の要素が特定のタグによって隠されています。さらに処理するためにデータを準備するには、データの前処理を行う必要があります。以下は、この前処理ステップのコードです。
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- まず、データセットからデータのトレーニング部分を取得します (ダウンロードしたデータセットにはトレーニング部分のみが含まれています)。次に、これを Pandas Dataframe に変換します。
- ここで Gemini を微調整するには、unmasked_text 列とmasked_text 列だけが必要なので、これら 2 つだけを使用します。
- 次に、データの最初の 2000 行を取得します。最初の 2000 行を使用して Gemini を微調整します。
- 次に、unmasked_text とmasked_text の列名を入力列と出力列に編集します。これは、PII (個人識別情報) を含む入力テキスト データを Gemini モデルに与えると、PII が含まれる出力テキスト データが生成されることが期待されるためです。マスクされています。
Gemini を微調整するためのデータのフォーマット
次のステップは、データをフォーマットすることです。これを行うために、フォーマッタ関数を作成します。
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- ここでは、データの行である x を受け取る関数フォーマッタを定義します。
- 次に、f-strings を使用して変数テキストを定義します。ここでコンテキストを提供し、その後にデータフレームからの入力データを提供します。
- 最後に、書式設定されたテキストを返します。
- 最後の行では、apply() 関数を通じて作成したデータフレームの各行にフォーマッタ関数を適用します。
- axis=1 は、関数がデータフレームの各行に適用されることを示します。
コードを実行すると、入力フィールドを含む各行の書式設定されたテキストを含む「train」という新しい列が作成されます。データフレームの要素の 1 つを観察してみましょう。
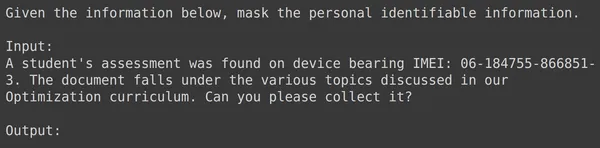
データをトレーニング セットとテスト セットに分割する
text_input にはデータが含まれており、各行には PII をマスクするように指示するデータの先頭にコンテキストが含まれ、その後に入力データが続き、その後にモデルが出力を生成する必要がある単語の出力が続きます。次に、データフレームをトレーニングとテストに分割する必要があります。
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- まず、データに text_input 列と出力列が含まれるようにデータをフィルター処理します。これらは、Gemini をトレーニングするために Google Fine-Tune ライブラリによって期待される列です
- Gemini は text_input を取得し、出力の書き方を学習します。
- データを、元のデータの 1900 行を含む df_train に分割します。
- そして約 100 行の元のデータを含む df_test
- Gemini を df_train でトレーニングし、df_test から 3 ~ 4 つの例を取得してテストし、生成された出力を確認します。
したがって、コードを実行するとデータがフィルタリングされ、トレーニングとテストに分割されます。最後に、データの前処理部分が完了しました。
ジェミニ モデルの微調整
Gemini モデルを微調整するには、以下の手順に従ってください。
チューニングパラメータの設定
このセクションでは、Gemini モデルを調整するプロセスを説明します。このために、次のコードを使用します。
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- google.generativeai ライブラリをインポートする: このライブラリは、Google の Generative AI サービスと対話するための API を提供します。
- 基本モデル名を指定します。これは、微調整されたモデルの開始点として使用する事前トレーニングされたモデルの名前です。現時点では、調整可能なモデルは models/gemini-1.0-pro-001 のみであり、これを変数 bm_name に保存します。
- 微調整されたモデルの名前を入力してください: これは、微調整されたモデルに付けたい名前です。ここでは「pii-model」という名前を付けます。
- 調整されたモデル操作オブジェクトの作成: このオブジェクトは、微調整されたモデルを作成する操作を表します。次の引数を受け取ります。
- source_model: 基本モデルの名前
- training_data: 作成したばかりの微調整モデルのトレーニング データ (df_train)
- id: 微調整されたモデルの ID/名前
- epoch_count: トレーニング エポックの数。この例では、2 エポックを使用します。
- batch_size: トレーニングのバッチ サイズ。この例では、値 4 を使用します。
- learning_rate: トレーニングの学習率。ここでは値 0.001 を指定しています。
- パラメータの指定が完了しました。このコードを実行すると、微調整されたモデル オブジェクトが作成されます。ここで、Gemini LLM をトレーニングするプロセスを開始する必要があります。このために、次のコードを使用します。
パラメータの設定が完了しました。このコードを実行すると、調整されたモデル オブジェクトが作成されます。ここで、Gemini LLM をトレーニングするプロセスを開始する必要があります。このために、次のコードを使用します。
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)調整されたモデルの作成
ここでは、genai ライブラリの .get_tuned_model() 関数を使用し、定義したモデルの名前を渡して、トレーニング プロセスを開始します。次に、以下の画像に示すように、モデルを印刷します。
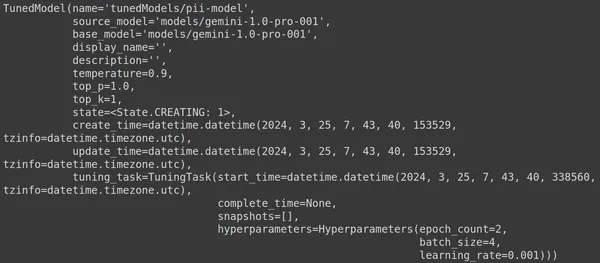
モデルのタイプは TunedModel です。ここでは、定義したモデルのさまざまなパラメーターを観察できます。彼らです:
- name: この変数には、調整されたモデルに指定した名前が含まれます
- source_model: これは微調整しているソース モデルです。この例では、models/gemini-1.0-pro です。
- base_model: これも微調整中の基本モデルです。この例では、models/Gemini-1.0-pro です。基本モデルは、以前に微調整されたモデルであっても構いません。ここでは両方とも同じです
- display_name: 調整されたモデルの表示名
- description: モデルの説明とモデルの内容が含まれます。
- 温度: 値が大きいほど、大規模言語モデルから生成される回答はより創造的になります。ここではデフォルトで 0.9 に設定されています
- top_p: テキスト生成時のトークン選択の最高確率を定義します。 top_p が大きいほど、より多くのトークンが選択されます。つまり、トークンはより大きなデータ サンプルから選択されます。
- top_k: 各ステップで次の可能性が最も高い k 個のトークンからサンプリングするように指示します。ここで、top_k は 1 です。これは、最も可能性の高い次のトークンが選択されることを意味します。つまり、最も高い確率のトークンが常に選択されます。
- state: 状態は作成中です。モデルが現在微調整中であることを意味します。
- create_time: モデルが作成された時刻
- update_time: モデルが最後に調整された時刻です。
- Tuning_task: 温度、エポック、バッチ サイズなど、調整用に定義したパラメータが含まれます。
トレーニングプロセスの開始
次のコードを通じて、調整されたモデルの状態とメタデータを取得することもできます。
print(operation.metadata)
ここでは、予測可能な合計ステップ数、つまり 950 が表示されます。この例では 1900 行のトレーニング データがあるためです。各ステップでは 4 つのバッチ、つまり 4 行を取り込むため、1900 つの完全なエポックには 4/475、つまり 2 ステップがあります。トレーニングに 2 エポックを設定しました。これは、475*950 = XNUMX ステップを意味します。
トレーニングの進捗状況のモニタリング
以下のコードは、トレーニングの完了率とトレーニング プロセス全体の完了にかかる時間を示すステータス バーを作成します。
import time
for status in operation.wait_bar():
time.sleep(30)
上記のコードは進行状況バーを作成します。完了すると、調整プロセスが終了したことを意味します。
トレーニングパフォーマンスの可視化
操作オブジェクトにはトレーニングのスナップショットも含まれています。エポックごとの平均損失などの評価メトリクスが含まれること。これは次のコードで視覚化できます。
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- ここでは、operation.result() から最終的に調整されたモデルを取得します。
- モデルをトレーニングするとき、モデルは頻繁な間隔でスナップショットを取得します。これらのスナップショットには、mean_loss などのデータが含まれています。したがって、model.tuning_task.snapshots を呼び出して、調整されたモデルのスナップショットを抽出します。
- スナップショットを pd.DataFrame に渡し、スナップショット変数に保存することで、これらのスナップショットからデータフレームを作成します。
- 最後に、抽出したスナップショット データから折れ線プロットを作成します。
コードを実行すると、次のようなグラフが表示されます。
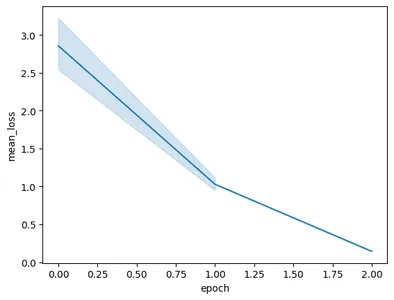
この画像では、わずか 3 エポックのトレーニングで損失が 0.5 から 2 未満に減少したことがわかります。最後に、Gemini モデルのトレーニングが完了しました。
微調整された Gemini モデルのテスト
このセクションでは、テスト データでモデルをテストします。次に、調整されたモデルを操作するために、次のコードを操作します。
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')上記のコードは、個人を特定できる情報データを使用してトレーニングしたばかりの調整されたモデルを読み込みます。ここで、保存しておいたテスト データからのいくつかの例を使用してこのモデルをテストします。このために、ランダムな text_input とそれに対応するテスト セットからの出力を出力しましょう。
print(df_test['text_input'][1900])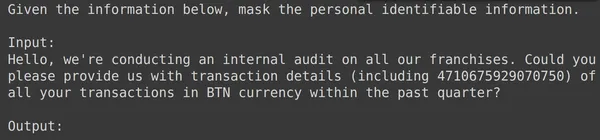
df_test['output'][1900]
上では、ランダムな text_input とテスト セットから取得した出力を確認できます。次に、この text_input をモデルに渡し、生成された出力を観察します。
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
モデルが指定された text_input の個人を特定できる情報をマスクすることに成功し、モデルによって生成された出力がテスト セットからの出力と正確に一致していることがわかります。ここで、さらにいくつかの例を使ってこれを試してみましょう。
print(df_test['text_input'][1969])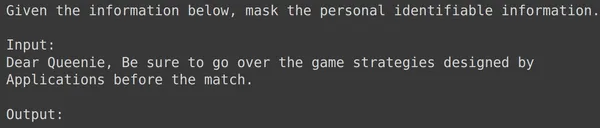
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])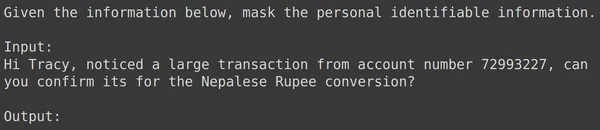
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])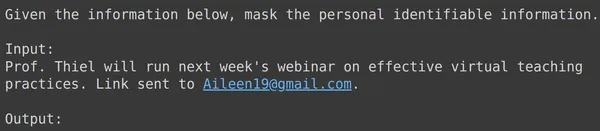
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
上記のすべての例で、微調整されたモデルのパフォーマンスが良好であることがわかります。モデルは、指定されたトレーニング データから学習し、マスキングを正しく適用して機密の個人情報を隠すことができました。したがって、微調整用のデータセットを作成する方法と、データセット上でジェミニ モデルを微調整する方法を最初から最後まで見てきました。そして、微調整されたモデルにとって非常に有望であると思われる結果が得られました。
まとめ
結論として、このガイドでは、個人を特定できる情報 (PII) をマスクするために Google の主力モデルである Gemini モデルを微調整するための包括的なチュートリアルを提供しました。私たちは、Gemini モデルの微調整機能に関する Google のブログ投稿を調査することから始め、タスク固有の精度を達成するためにこれらのモデルを微調整する必要性を強調しました。データセットの準備、Gemini モデルの微調整、パフォーマンスのテストなど、ガイドで概説されている実践的な手順を通じて、ユーザーは PII マスキング タスクに大規模な言語モデルの力を活用できます。
このガイドの重要なポイントは次のとおりです。
- Gemini モデルは微調整用の強力なライブラリを提供しており、ユーザーはパラメーター効率的なチューニング (PET) を通じて、PII マスキングを含む特定のタスクに合わせてモデルを調整できます。
- データセットの準備は重要なステップであり、必要なモジュールのインストール、データ セキュリティのための OAuth の開始、トレーニング用のデータのフォーマットが含まれます。
- 微調整プロセスには、準備されたデータセットで Gemini モデルをトレーニングするための、ベース モデル、エポック数、バッチ サイズ、学習率などのパラメーターの提供が含まれます。
- ステータスの更新やエポックごとの平均損失などの指標の視覚化により、トレーニングの進行状況の監視が容易になります。
- 別のテスト データセットで微調整されたモデルをテストすると、データの整合性を維持しながら PII を正確にマスキングするパフォーマンスを検証できます。
- 提供された例は、機密性の高い個人情報をうまくマスキングする際の微調整された Gemini モデルの有効性を示しており、現実世界のアプリケーションで有望な結果が得られることを示しています。
よくある質問
A. Parameter Efficient Tuning (PET) は、モデルの少数のパラメーター セットのみを微調整する微調整手法の 1 つです。これは、Gemini モデルの重要なレイヤーを迅速に微調整するために Google によって採用されています。モデルをユーザーのデータに効率的に適応させ、特定のタスクのパフォーマンスを向上させます。
A. Gemini モデルのチューニングには、基本モデル名、エポック数、バッチ サイズ、学習率などのパラメーターを指定することが含まれます。これらのパラメーターはトレーニング プロセスに影響を与え、最終的にはモデルのパフォーマンスに影響を与えます。
A. ユーザーは、ステータスの更新、エポックあたりの平均損失などのメトリクスの視覚化、トレーニング プロセスのスナップショットの観察を通じて、微調整された Gemini モデルのトレーニングの進行状況を監視できます。
A. Gemini モデルを微調整する前に、ユーザーは google-generativeai やデータセットなどの必要なライブラリをインストールする必要があります。さらに、データ セキュリティのために OAuth を開始し、トレーニング用にデータセットをフォーマットすることも重要な手順です。
A. 微調整された Gemini モデルは、データの匿名化、NLP アプリケーションでのプライバシー保護、GDPR などのデータ保護規制への準拠など、PII マスキングが必要なさまざまなドメインに適用できます。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

