クローネ は、世界中のビール醸造所、飲料瓶詰め業者、食品生産者に個別の機械と完全な生産ラインを提供しています。毎日、何百万ものガラス瓶、缶、PET 容器がクローネスのラインを流れています。生産ラインは複雑なシステムであり、ラインを停止させて生産歩留まりを低下させる可能性のあるエラーが多数発生する可能性があります。クローネスは、故障をできるだけ早く(場合によっては故障が発生する前に)検出し、生産ラインのオペレータに信頼性と生産性を高めるよう通知したいと考えています。では、障害を検出するにはどうすればよいでしょうか? Krones は、自社のラインにデータ収集用のセンサーを装備し、ルールに照らして評価できます。 Krones は、ライン メーカーだけでなくライン オペレーターとしても、機械の監視ルールを作成することができます。したがって、飲料瓶詰め業者やその他の事業者は、ラインの誤差の範囲を独自に定義できます。以前、Krones は時系列データベースに基づくシステムを使用していました。主な課題は、このシステムのデバッグが難しく、クエリはマシンの現在の状態を表すが、状態の遷移は表現しないということでした。
この投稿では、Krones が回線を監視するためのストリーミング ソリューションをどのように構築したかを説明します。 アマゾンキネシス & Apache Flink 向け Amazon マネージドサービス。これらのフルマネージド サービスにより、Apache Flink を使用したストリーミング アプリケーションの構築の複雑さが軽減されます。 Apache Flink のマネージド サービスは、永続的なアプリケーションの状態、メトリクス、ログなどを提供する基盤となる Apache Flink コンポーネントを管理します。Kinesis を使用すると、あらゆる規模でストリーミング データをコスト効率よく処理できます。独自の Apache Flink アプリケーションを使い始めたい場合は、以下を確認してください。 GitHubリポジトリ Flink の Java、Python、または SQL API を使用したサンプルの場合。
ソリューションの概要
Krones の回線監視は、 クローネス ショップフロア ガイダンス システム。組織内のサポート、優先順位付け、管理、社内のすべての活動の文書化を提供します。これにより、オペレータがラインのどこにいるかに関係なく、機械が停止した場合や材料が必要な場合にオペレータに通知することができます。実証済みの状態監視ルールはすでに組み込まれていますが、ユーザー インターフェイスを介してユーザー定義することもできます。たとえば、監視されている特定のデータ ポイントがしきい値に違反した場合、ライン上にテキスト メッセージまたはメンテナンス オーダーのトリガーが表示される可能性があります。
状態監視およびルール評価システムは、AWS 分析サービスを使用して AWS 上に構築されています。次の図はアーキテクチャを示しています。
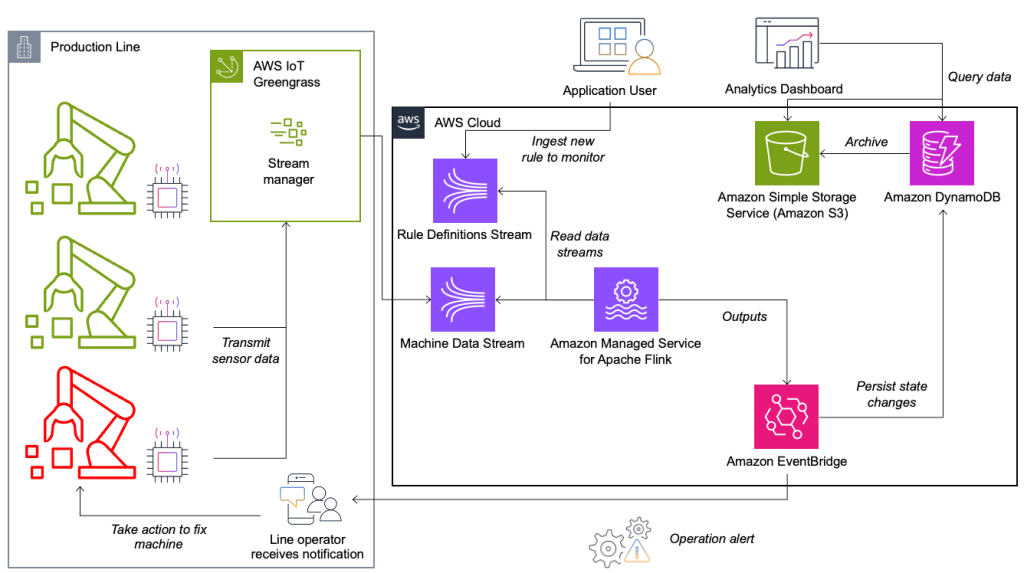
ほぼすべてのデータ ストリーミング アプリケーションは、データ ソース、ストリーム取り込み、ストリーム ストレージ、ストリーム処理、および 1 つ以上の宛先の 5 つのレイヤーで構成されています。次のセクションでは、各レイヤーと、Krones によって構築された回線監視ソリューションがどのように機能するかを詳しく説明します。
情報元
データは、Siemens S7 や OPC/UA などのいくつかのプロトコルを読み取るエッジ デバイス上で実行されるサービスによって収集されます。生データは前処理されて統合された JSON 構造を作成するため、後からルール エンジンで処理しやすくなります。 JSON に変換されたサンプル ペイロードは次のようになります。
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}ストリームの取り込み
AWS IoT Greengrass は、オープンソースのモノのインターネット (IoT) エッジ ランタイムおよびクラウド サービスです。これにより、ローカルでデータを操作し、デバイス データを集約およびフィルタリングできるようになります。 AWS IoT Greengrass は、エッジにデプロイできる事前構築済みコンポーネントを提供します。生産ライン ソリューションでは、データを処理して AWS の宛先に転送できるストリーム マネージャー コンポーネントを使用します。 AWS IoT 分析, Amazon シンプル ストレージ サービス (Amazon S3)、Kinesis。ストリームマネージャーはレコードをバッファリングして集約し、それを Kinesis データストリームに送信します。
ストリームストレージ
ストリーム ストレージの役割は、フォールト トレラントな方法でメッセージをバッファリングし、1 つ以上のコンシューマー アプリケーションで使用できるようにすることです。 AWS でこれを実現するには、最も一般的なテクノロジーは Kinesis と ApacheKafkaのAmazonマネージドストリーミング (アマゾンMSK)。生産ラインからのセンサーデータを保存するために、Krones は Kinesis を選択しました。 Kinesis は、あらゆる規模で低遅延で動作するサーバーレス ストリーミング データ サービスです。 Kinesis データストリーム内のシャードは、一意に識別されるデータレコードのシーケンスであり、ストリームは 2 つ以上のシャードで構成されます。各シャードには、1 MB/秒の読み取り容量と 1,000 MB/秒の書き込み容量があります (最大 XNUMX レコード/秒)。これらの制限に達しないようにするには、データをシャード間でできるだけ均等に分散する必要があります。 Kinesis に送信されるすべてのレコードにはパーティション キーがあり、データをシャードにグループ化するために使用されます。したがって、負荷を均等に分散するには、多数のパーティション キーを用意する必要があります。 AWS IoT Greengrass で実行されているストリーム マネージャーは、ランダムなパーティション キーの割り当てをサポートしています。これは、すべてのレコードがランダムなシャードに配置され、負荷が均等に分散されることを意味します。ランダムなパーティションキー割り当ての欠点は、レコードが Kinesis に順番に保存されないことです。これを解決する方法については、次のセクションでウォーターマークについて説明します。
透かし
A 透かし データ ストリーム内のイベント時間の進行状況を追跡および測定するために使用されるメカニズムです。イベント時間は、イベントがソースで作成されたときのタイムスタンプです。ウォーターマークは、ストリーム処理アプリケーションのタイムリーな進行状況を示すため、それより前のタイムスタンプまたは同じタイムスタンプを持つすべてのイベントが処理済みとみなされます。この情報は、Flink がイベント時間を進め、ウィンドウ評価などの関連する計算をトリガーするために不可欠です。イベント時間とウォーターマークの間の許容ラグを構成して、ウィンドウが完了したとみなしてウォーターマークを進める前に、遅いデータを待つ時間を決定できます。
Krones は世界中にシステムを展開しており、接続損失やその他のネットワーク制約による遅れ到着に対処する必要がありました。彼らはまず、遅延到着を監視し、デフォルトの Flink 遅延処理をこのメトリクスで確認された最大値に設定しました。エッジ デバイスからの時刻同期に問題が発生したため、より洗練された透かしの方法が必要になりました。彼らはすべての送信者に対してグローバル ウォーターマークを構築し、最も低い値をウォーターマークとして使用しました。タイムスタンプは、すべての受信イベントの HashMap に保存されます。ウォーターマークが定期的に発行される場合、この HashMap の最小値が使用されます。データの欠落によるウォーターマークの停止を避けるために、彼らは idleTimeOut パラメータを使用すると、特定のしきい値より古いタイムスタンプが無視されます。これによりレイテンシーは増加しますが、強力なデータ一貫性が得られます。
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
ストリーム処理
データがセンサーから収集され、Kinesis に取り込まれた後、ルールエンジンによって評価される必要があります。このシステムのルールは、単一のメトリクス (温度など) またはメトリクスの集合の状態を表します。メトリクスを解釈するには、複数のデータ ポイントが使用されます。これはステートフルな計算です。このセクションでは、Apache Flink のキー付き状態とブロードキャスト状態、およびそれらが Krones ルール エンジンの構築にどのように使用されるかについて詳しく説明します。
制御ストリームとブロードキャスト状態パターン
Apache Flink では、 状態 時間や操作全体にわたって情報を永続的に保存および管理するシステムの機能を指し、ステートフル計算のサポートによるストリーミング データの処理を可能にします。
ブロードキャスト状態パターン オペレーターのすべての並列インスタンスに状態を分散できます。したがって、すべての演算子は同じ状態を持ち、この同じ状態を使用してデータを処理できます。この読み取り専用データは、制御ストリームを使用して取り込むことができます。制御ストリームは通常のデータ ストリームですが、通常はデータ レートがはるかに低くなります。このパターンを使用すると、すべてのオペレーターの状態を動的に更新できるため、ユーザーは再デプロイせずにアプリケーションの状態と動作を変更できます。より正確には、状態の配布は制御ストリームを使用して行われます。新しいレコードを制御ストリームに追加すると、すべてのオペレーターがこの更新を受け取り、新しいメッセージの処理に新しい状態を使用します。
これにより、Krones アプリケーションのユーザーは、再起動せずに新しいルールを Flink アプリケーションに取り込むことができます。これにより、ダウンタイムが回避され、変更がリアルタイムで発生するため、優れたユーザー エクスペリエンスが得られます。ルールは、プロセスの逸脱を検出するためのシナリオをカバーします。場合によっては、マシン データは一見したように解釈するのが簡単ではありません。温度センサーが高い値を送信している場合、これはエラーを示している可能性がありますが、進行中のメンテナンス手順の影響である可能性もあります。メトリクスをコンテキストに配置し、一部の値をフィルターすることが重要です。これは、と呼ばれる概念によって実現されます。 グループ化.
メトリクスのグループ化
データとメトリクスをグループ化することで、受信データの関連性を定義し、正確な結果を生成できます。次の図の例を見てみましょう。
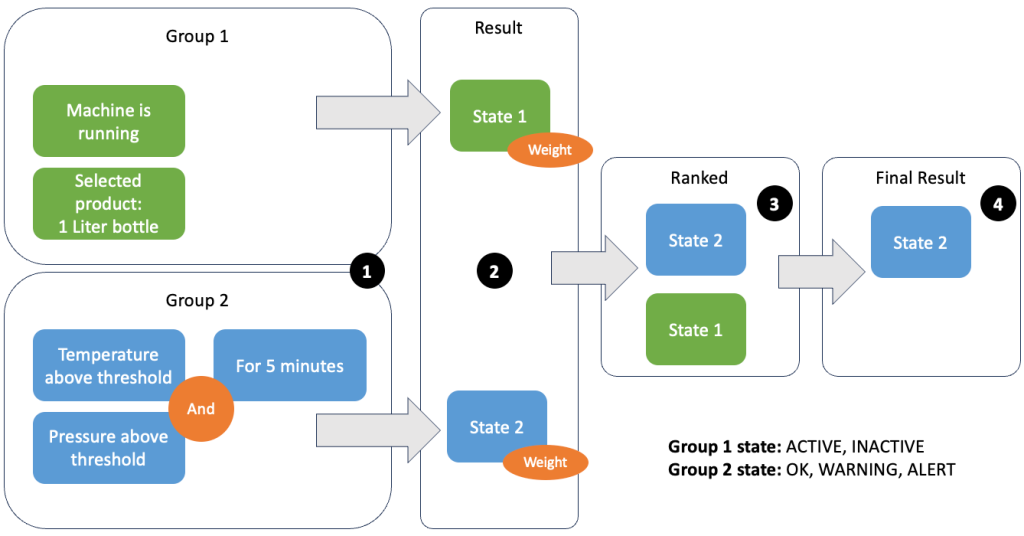
ステップ 1 では、1 つの条件グループを定義します。グループ 2 は、マシンの状態とどの製品がラインを通過しているかを収集します。グループ 1 は、温度センサーと圧力センサーの値を使用します。条件グループは、受け取る値に応じて異なる状態を持つことができます。この例では、グループ XNUMX がマシンが稼働しているというデータを受信し、XNUMX リットルのボトルが製品として選択されています。これにより、このグループに状態が与えられます ACTIVE。グループ 2 には、温度と圧力のメトリクスがあります。両方のメトリクスが 5 分以上にわたってしきい値を超えています。この結果、グループ 2 は次の状態になります。 WARNING 州。これは、グループ 1 はすべてが正常であると報告し、グループ 2 はそうではないことを意味します。ステップ 2 では、グループに重みが追加されます。グループが矛盾する情報を報告する可能性があるため、状況によってはこれが必要になります。このシナリオでは、グループ 1 がレポートします。 ACTIVE そしてグループ2のレポート WARNINGしたがって、回線の状態がシステムにとって明確ではありません。重みを追加した後、ステップ 3 に示すように、状態をランク付けできます。最後に、ステップ 4 に示すように、最高ランクの状態が勝利の状態として選択されます。
ルールが評価され、最終的なマシン状態が定義された後、結果はさらに処理されます。実行されるアクションはルール設定によって異なります。これは、ライン オペレーターに資材を補充したり、メンテナンスを行ったり、ダッシュボード上の単なる視覚的な更新を通知したりすることができます。メトリクスとルールを評価し、結果に基づいてアクションを実行するシステムのこの部分は、「 ルールエンジン.
ルールエンジンのスケーリング
ユーザーが独自のルールを作成できるようにすることで、ルール エンジンは評価する必要がある多数のルールを持つことができ、一部のルールは他のルールと同じセンサー データを使用する可能性があります。 Flink は、水平方向に非常にうまく拡張できる分散システムです。データ ストリームを複数のタスクに分散するには、 keyBy() 方法。これにより、データ ストリームを論理的に分割し、データの一部を別のタスク マネージャーに送信できます。これは多くの場合、負荷が均等に分散されるように、任意のキーを選択することによって行われます。この場合、クローネスは次のことを追加しました。 ruleId データポイントに追加し、それをキーとして使用しました。それ以外の場合、必要なデータ ポイントは別のタスクによって処理されます。キー付きデータ ストリームは、通常の変数と同様に、すべてのルールで使用できます。
目的地
ルールの状態が変更されると、情報は Kinesis ストリームに送信され、 アマゾンイベントブリッジ 消費者へ。消費者の 1 人がイベントから生産ラインに送信される通知を作成し、担当者に行動するよう警告します。ルールの状態の変化を分析できるようにするために、別のサービスがデータを Amazon DynamoDB 高速アクセスのためのテーブルと、さらなるレポート作成のために長期履歴を Amazon S3 にオフロードするための TTL が用意されています。
まとめ
この投稿では、Krones が AWS 上にリアルタイムの生産ライン監視システムを構築した方法を紹介しました。 Apache のマネージド サービス Flink により、Krones チームはインフラストラクチャではなくアプリケーション開発に重点を置くことで、迅速に開始できるようになりました。 Flink のリアルタイム機能により、Krones はマシンのダウンタイムを 10% 削減し、効率を最大 5% 向上させることができました。
独自のストリーミング アプリケーションを構築したい場合は、次のサイトで利用可能なサンプルを確認してください。 GitHubリポジトリ。カスタム コネクタを使用して Flink アプリケーションを拡張する場合は、次を参照してください。 Apache Flink を使用したコネクタの構築を容易にする: 非同期シンクの導入。 Async Sink は、Apache Flink バージョン 1.15.1 以降で使用できます。
著者について
 フロリアン・メア AWS のシニア ソリューション アーキテクトおよびデータ ストリーミングの専門家です。彼は、AWS クラウド サービスを使用してビジネス上の課題を解決することで、ヨーロッパの顧客の成功と革新を支援する技術者です。ソリューション アーキテクトとして働くことに加えて、Florian は情熱的な登山家でもあり、ヨーロッパ各地の最も高い山のいくつかに登っています。
フロリアン・メア AWS のシニア ソリューション アーキテクトおよびデータ ストリーミングの専門家です。彼は、AWS クラウド サービスを使用してビジネス上の課題を解決することで、ヨーロッパの顧客の成功と革新を支援する技術者です。ソリューション アーキテクトとして働くことに加えて、Florian は情熱的な登山家でもあり、ヨーロッパ各地の最も高い山のいくつかに登っています。
 エミール・ディートル Krones のシニア テック リードで、Apache Flink とマイクロサービスを主要分野とするデータ エンジニアリングを専門としています。彼の仕事には、ミッションクリティカルなソフトウェアの開発と保守が含まれることがよくあります。仕事以外では、家族と充実した時間を過ごすことをとても大切にしています。
エミール・ディートル Krones のシニア テック リードで、Apache Flink とマイクロサービスを主要分野とするデータ エンジニアリングを専門としています。彼の仕事には、ミッションクリティカルなソフトウェアの開発と保守が含まれることがよくあります。仕事以外では、家族と充実した時間を過ごすことをとても大切にしています。
 サイモン・パイヤー スイスに拠点を置く AWS のソリューションアーキテクトです。彼は実務家であり、AWS クラウド サービスを使用してテクノロジーと人々を結び付けることに情熱を持っています。彼が特に注力しているのは、データ ストリーミングと自動化です。仕事のほかに、サイモンは家族、アウトドア、山でのハイキングを楽しんでいます。
サイモン・パイヤー スイスに拠点を置く AWS のソリューションアーキテクトです。彼は実務家であり、AWS クラウド サービスを使用してテクノロジーと人々を結び付けることに情熱を持っています。彼が特に注力しているのは、データ ストリーミングと自動化です。仕事のほかに、サイモンは家族、アウトドア、山でのハイキングを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

