概要
データは IT 業界にとって燃料であり、 データサイエンスプロジェクト 今日のオンラインの世界では。 IT 業界は、以下から得られるリアルタイムの洞察に大きく依存しています。 ストリーミングデータ ソース。ストリーミング データの処理と処理は最も困難な作業です。 データ解析。ストリーミング データは、継続的な処理で大量に出力されるデータであり、データは毎秒変化することを意味します。このデータを処理するために使用しているのは コンフルエントなプラットフォーム – 自己管理型のエンタープライズグレードのディストリビューション アパッチカフカ.
Kafka は、アーキテクチャによって処理できる分散型の障害であり、高スループットのデータ ストリームを管理するための一般的な選択肢として機能します。 Kafka からのデータは次の場所に収集されます。 MongoDBの コレクションの形で。この記事では、エンドツーエンドのパイプラインを作成します。このパイプラインでは、パイプラインの API を使用してデータがフェッチされ、トピックの形式で Kafka に収集され、そこから MongoDB に保存されて使用できるようになります。プロジェクト内で作業するか、特徴量エンジニアリングを実行します。
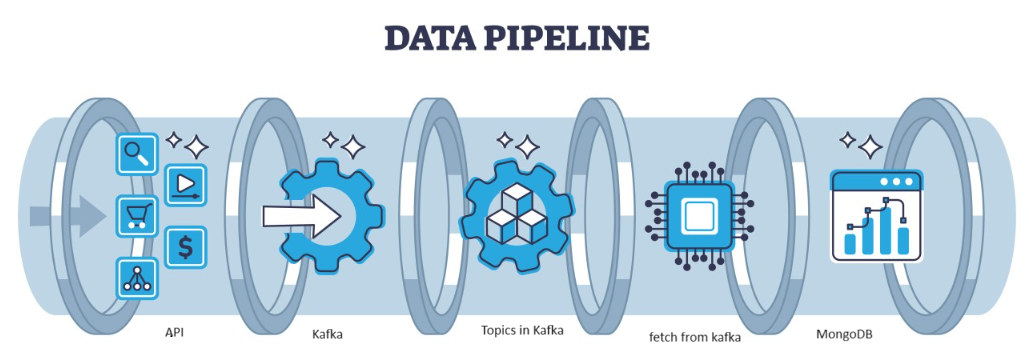
学習目標
- ストリーミング データとは何か、また Kafka を使用してストリーミング データを処理する方法について説明します。
- Confluent プラットフォームを理解する – 自己管理型のエンタープライズ グレードの Apache Kafka ディストリビューション。
- Kafka によって収集されたデータを、非構造化データを格納する NoSQL データベースである MongoDB に格納します。
- データを取得してデータベースに保存するための完全なエンドツーエンドのパイプラインを作成します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
問題を特定する
センサーからのストリーミング データを処理するために、センサー データを含む車両は毎秒生成されますが、データを処理して前処理して使用するのは困難です。 データサイエンスプロジェクト。したがって、この問題に対処するために、データを処理し、データを保存するエンドツーエンドのパイプラインを作成しています。
ストリーミングデータとは何ですか?
ストリーミングデータ さまざまなソースによって継続的に生成されるデータであり、非構造化データです。これは、さまざまなソースからリアルタイムまたはほぼリアルタイムで生成されるデータの継続的なフローを指します。従来のバッチ処理では、データが収集され、このストリーミング データが生成時に処理されます。ストリーミング データには、温度センサーや GPS トラッカーなどの IoT データ、または車両や製造機械からのテレメトリ データなど、機械や産業機器によって生成されるマシン データなどのデータが含まれます。 Apache-Kafka などのストリーミング データ処理プラットフォームがあります。
カフカとは何ですか?
Apache Kafka は、リアルタイム データ パイプラインとストリーミング アプリケーションの構築に使用されるプラットフォームです。 Kafka Streams API は、オンザフライ処理を可能にする強力なライブラリで、ウィンドウ パラメーターの収集と作成、ストリーム内のデータの結合の実行などを可能にします。 Apache Kafka は、効率的なリアルタイムのデータ取り込み、ストリーミング データ パイプライン、システム全体のストレージを組み合わせるストレージ レイヤーとコンピューティング レイヤーで構成されます。
どのようなアプローチになるのでしょうか?
これは、Kafka confluent との間でデータを JSON 形式で公開および処理する方法を知るのに役立つ機械学習パイプラインです。 Kafka データ処理には、コンシューマとプロデューサの 2 つの部分があります。さまざまなプロデューサーからのストリーミング データを格納し、それを Confluent に格納した後、データの逆シリアル化が行われ、そのデータがデータベースに格納されます。
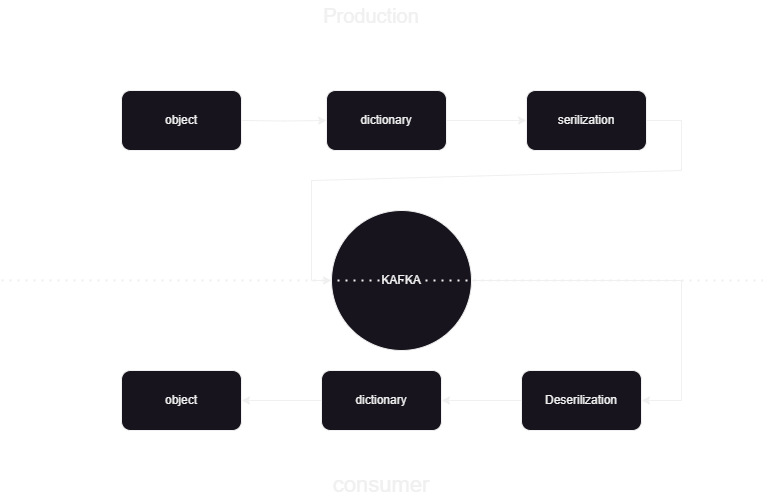
システムアーキテクチャの概要
Confluent Kafka を使用してストリーミング データを処理しています。Kafka は 2 つの部分に分かれています。
- Kafka プロデューサー: Kafka プロデューサーは、データを作成して Kafka トピックに送信する責任を負います。
- Kafka Consumer: Kafka Consumer は、Kafka トピックからデータを読み取り、処理します。
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
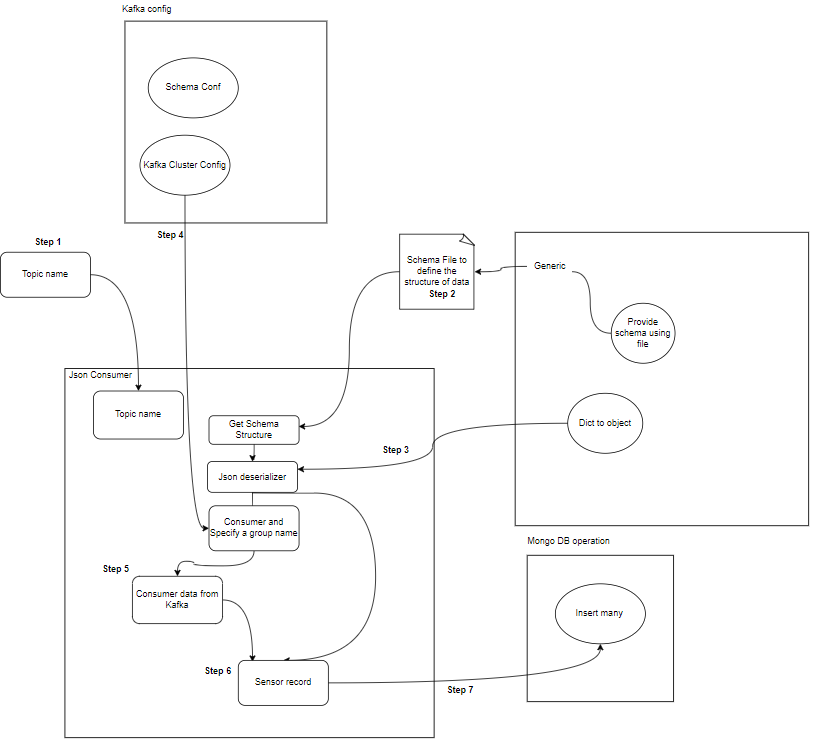
コンポーネントとは何ですか?
- トピック: トピックは、プロデューサーによって公開される論理的なチャネルまたはカテゴリです。各トピックは 1 つ以上のパーティションに分割され、フォールト トレランスのために各トピックが複数のブローカー間で複製されます。プロデューサは特定のトピックに関するデータを公開し、コンシューマはデータを使用するためにトピックをサブスクライブします。
- プロデューサー: Apache Kafka プロデューサーは、イベントを Kafka クラスターに発行 (書き込み) するクライアント アプリケーションです。データをトピックに送信するアプリケーションは、Kafka プロデューサーとして知られています。このセクションでは、Kafka プロデューサーの概要を説明します。
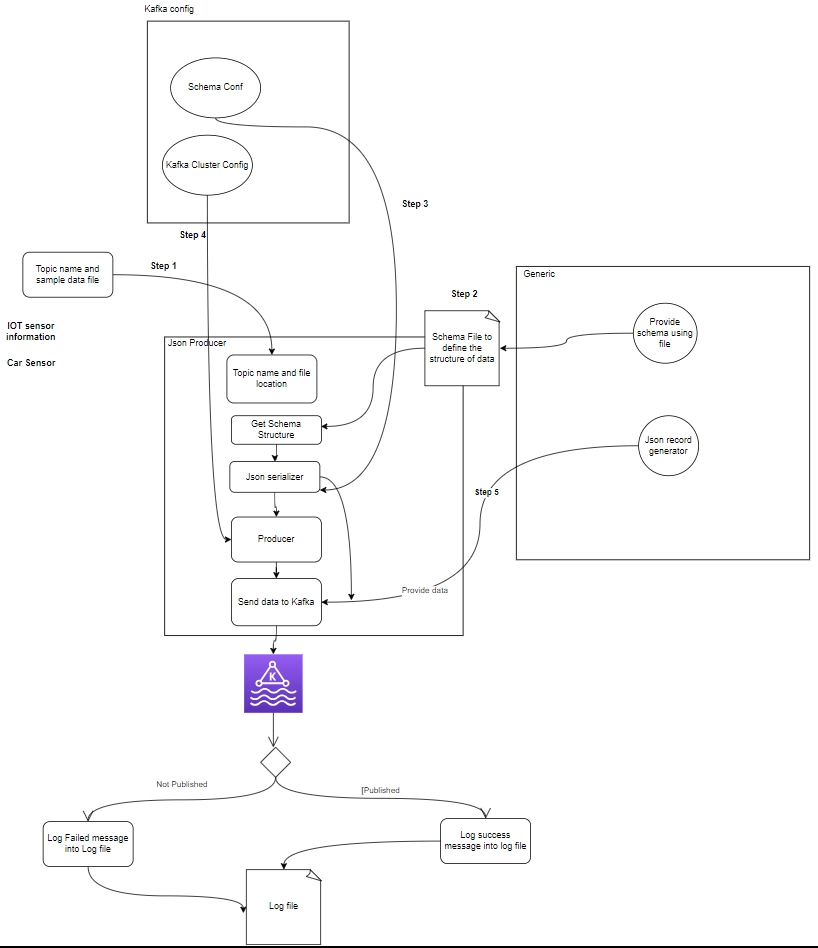
- 消費者: Kafka コンシューマーは、Kafka トピックからデータを読み取り、処理する責任があります。コンシューマは、Kafka からのデータを使用し、それに反応する必要があるアプリケーションの一部になることができます。彼らは、Kafka ブローカーからの 1 つ以上のトピックとデータをサブスクライブします。コンシューマはコンシューマ グループに編成できます。各コンシューマ グループには 1 つ以上のコンシューマがあり、トピックの各トピックはグループ内の 1 人のコンシューマのみによって消費されます。これにより、データ消費の並列処理と負荷分散が可能になります。
プロジェクトの構造とは何ですか?
これは、プロジェクト内でフォルダーとファイルがどのように分割されるかを示すプロジェクトのフローチャートです。
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- カフカプロデューサー: プロデューサは、センサー データを (たとえば、sample_data/ の CSV ファイルから) 生成し、それを Kafka トピックに公開する主要な部分です。データの生成または公開中に発生する可能性のあるエラー状態。
- Kafka ブローカー: Kafka ブローカーは、Kafka クラスター全体でデータを保存および複製し、データのパーティショニングを処理し、フォールト トレランスと高可用性を確保します。
- Kafka コンシューマ: コンシューマは、Kafka トピックからデータを読み取り、それを処理 (変換、集計など) して、MongoDB に保存します。また、データ処理中に発生する可能性のあるエラー状態も監視します。
- MongoDB: MongoDB は、Kafka コンシューマから受信したセンサー データを保存します。データ取得のためのクエリを提供し、レプリケーションとフォールト トレランス メカニズムを通じてデータの耐久性を保証します。
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
データ保存の前提条件
合流カフカ
- アカウントの作成: Kafka を理解するには、Confluent が必要です。 Apache Kafka® は大好きですが、それを管理することはできません。クラウドネイティブで完全なフルマネージド サービスは Kafka を超えており、優秀な人材がビジネスに価値を提供することに集中できます。
- トピックの作成:
- ホーム ページとサイドバーに移動します
- 「環境」に移動し、「デフォルト」をクリックします。
- トピックスへ行く

- 新しいトピックを選択し、トピックの名前を付けます

MongoDBの
サインアップを作成して MongoDB Atlas にサインインし、後で使用できるように MongoDB Atlas の接続リンクを保存します。
プロジェクト設定のステップバイステップ ガイド
- Python のインストール: Python がマシンにインストールされていることを確認します。ダウンロードしてインストールできます Python 公式サイトから。
- Conda バージョン: ターミナルで conda バージョンを確認します。
- 仮想環境の作成: venv を使用して仮想環境を作成します。
conda create -p venv python==3.10 -y- 仮想環境のアクティブ化: 仮想環境をアクティブ化します。
conda activate venv/- 必要なパッケージをインストールします。 pip を使用して、requirements.txt ファイルにリストされている必要な依存関係をインストールします。
pip install -r requirements.txt- ローカル システムでいくつかの環境変数を設定する必要があります。これは Confluent クラウドのクラスター環境変数です。
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
.env ファイルの資格情報を更新し、以下のコマンドを実行して、Docker でアプリケーションを実行します。.
- プロジェクトのルート ディレクトリに .env ファイルを作成します (利用できない場合)。以下の内容を貼り付けて資格情報を更新します。
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- プロデューサー ファイルとコンシューマー ファイルを実行します。
python producer_main.py
python consumer_main.pyコードを実装するにはどうすればよいですか?
- ソース/: このディレクトリは、すべてのソース コード ファイルのメイン フォルダーです。このディレクトリ内には、次のサブディレクトリがあります。
Consumer/: このディレクトリには、Kafka トピックからデータを読み取り、それを処理する Kafka_consumer のコードが含まれています。
プロデューサー/: このディレクトリには、センサー データの生成と Kafka トピックへの送信を担当する Kafka_Producer のコードが含まれています。 - README.md: この Markdown ファイルには、プロジェクトの目的の概要、手順、使用ガイドライン、その他の情報を含む、プロジェクトのドキュメントと手順が含まれています。
- 要件.txt: このファイルには、プロジェクトに必要な Python ライブラリがリストされています。各依存関係はそのバージョン番号とともにリストされます。 pip などのツールは、このファイルを使用して、必要な依存関係を自動的にインストールできます。
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: リンクを通じて MongoDB Altas に接続するために、Python スクリプトを作成しています
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
MongoDb Altas からコピーした URL を入力してください
出力:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
このファイルが実行されてから、 Pythonプロデューサー_メイン.py これは以下のファイルを呼び出します:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
出力:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
このファイルが実行されてから、 Python Consumer_main.py これは以下のファイルを呼び出します:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()出力:

コンシューマーとプロデューサーの両方を実行すると、システムは kafka 上で実行され、情報/データがより速く収集されます。

出力:
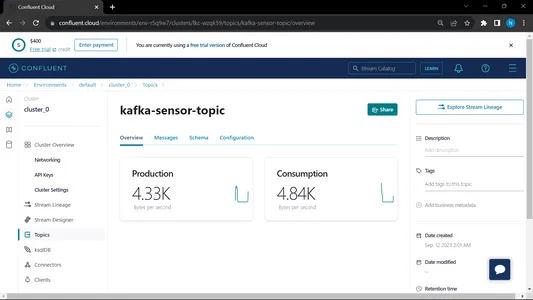
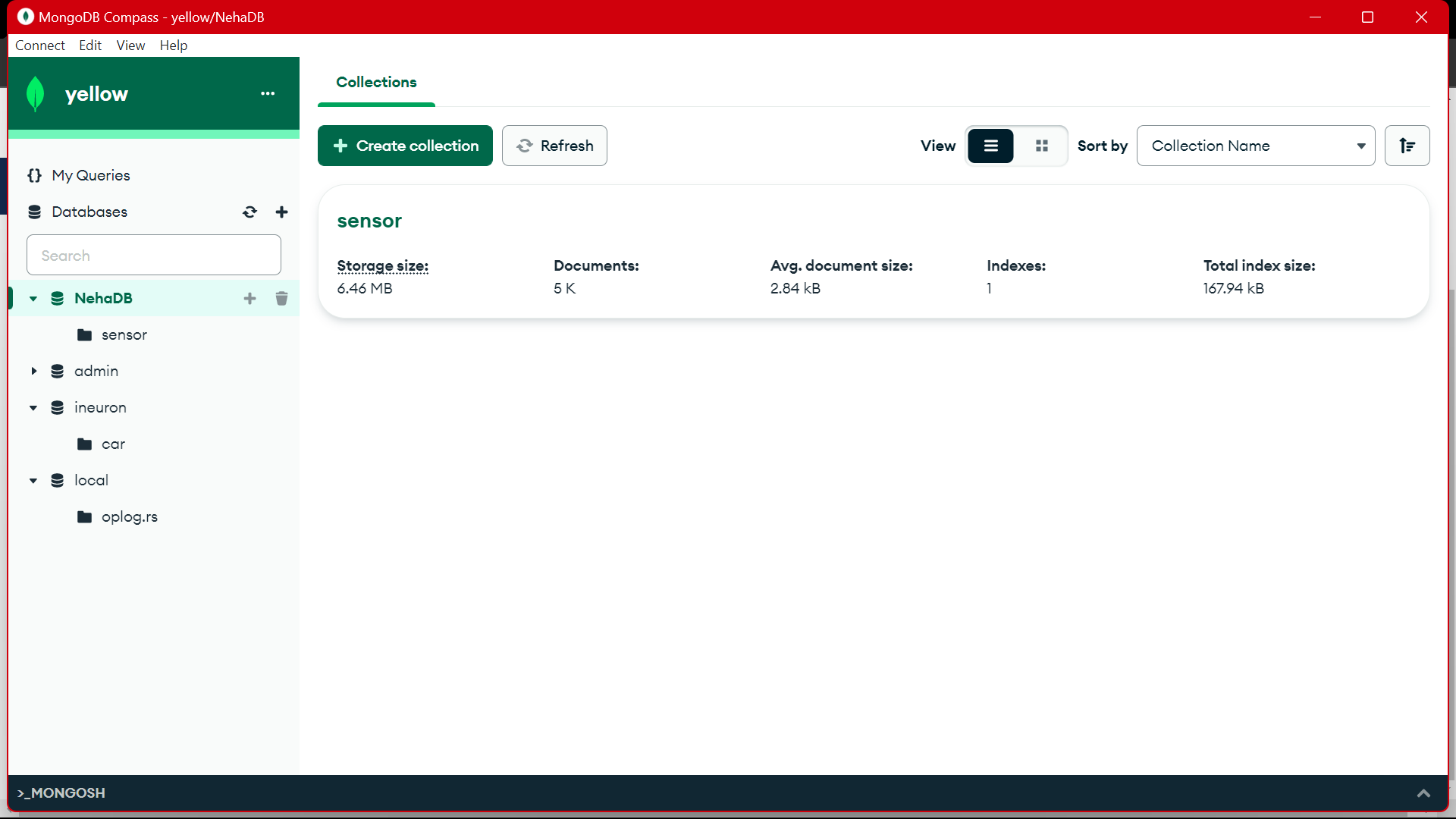
MongoDB からこのデータを使用して EDA で前処理し、特徴量エンジニアリングとデータ分析作業がこのデータに対して行われます。
[埋め込まれたコンテンツ]
まとめ
この記事では、センサーから Kafka へのストリーミング データを JSON 形式で保存および処理し、そのデータを MongoDB に保存する方法を理解します。ストリーミング データは、継続的な処理で大量に出力されるデータであり、データは毎秒変化することを意味します。エンドツーエンドのパイプラインを作成しました。このパイプラインでは、パイプライン内の API を使用してデータがフェッチされ、トピックの形式で Kafka に収集され、そこから MongoDB に保存されます。プロジェクトで使用したり、特徴エンジニアリング。
主要な取り組み
- ストリーミング データとは何か、また Kafka を使用してストリーミング データを処理する方法について説明します。
- Confluent プラットフォーム – 自己管理型のエンタープライズ グレードの Apache Kafka ディストリビューションについて理解します。
- Kafka によって収集されたデータを、非構造化データを格納する NoSQL データベースである MongoDB に格納します。
- データを取得してデータベースに保存するための完全なエンドツーエンドのパイプラインを作成します。
- プロジェクトの各コンポーネントの機能を理解して、それを Docker 上に実装し、いつでも使用できるようにクラウド上に実装します。
リソース
よくある質問
A. MongoDB はデータを非構造化データに保存します。ストリーミング データは、メモリ使用量を考慮した非構造化形式のデータであり、データベースとして MongoDB を使用しています。
A. 目的は、Kafka トピックに取り込まれたデータを、さらに分析、レポート、またはアプリケーションの使用のために消費、処理、MongoDB に保存できるリアルタイム データ処理パイプラインを作成することです。
A. ユース ケースには、リアルタイム分析、IoT データ処理、ログ集約、ソーシャル メディア モニタリング、レコメンデーション システムが含まれます。これらのシステムでは、さらなる分析やアプリケーションの使用のためにストリーミング データを処理および保存する必要があります。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

