概要
検索拡張世代 (RAG) は、その誕生以来、世界を席巻してきました。 RAG は、大規模言語モデル (LLM) が正確かつ事実に基づいた回答を提供または生成するために必要なものです。 RAG によって LLM の事実性を解決します。ここでは、LLM がこのコンテキストで動作し、事実として正しい応答を生成できるように、ユーザーのクエリと文脈的に類似したコンテキストを LLM に与えることを試みます。これは、データとユーザー クエリをベクトル埋め込みの形式で表し、コサイン類似度を実行することによって行われます。しかし問題は、従来のアプローチはすべて単一の埋め込みでデータを表現しており、これは良い意味で理想的ではない可能性があることです。 検索システム。このガイドでは、従来のバイエンコーダ モデルよりも高い精度で取得を実行する ColBERT について説明します。
学習目標
- RAG での取得が高レベルでどのように機能するかを理解します。
- 検索における単一埋め込みの制限を理解します。
- ColBERT のトークン埋め込みを使用して取得コンテキストを改善します。
- ColBERT の遅いインタラクションによって検索がどのように改善されるかを学びましょう。
- 正確な検索のために ColBERT を使用する方法を理解してください。
この記事は、の一部として公開されました データサイエンスブログ。
目次
RAGとは何ですか?
LLM は、意味があり文法的に正しいテキストを生成できますが、幻覚と呼ばれる問題に悩まされています。 LLM における幻覚 これは、LLM が自信を持って間違った答えを生成する概念です。つまり、LLM は、私たちにそれが真実であると思わせる方法で間違った答えをでっち上げます。これは、LLM の導入以来、大きな問題となってきました。これらの幻覚は、不正確で事実上間違った答えにつながります。そこで、検索拡張生成が導入されました。
RAG では、ドキュメント/ドキュメントのチャンクのリストを取得し、これらのテキスト ドキュメントをベクトル エンベディングと呼ばれる数値表現にエンコードします。単一のベクトル エンベディングはドキュメントの 1 つのチャンクを表し、それらを と呼ばれるデータベースに保存します。 ベクトルストア。これらのチャンクを埋め込みにエンコードするために必要なモデルは、エンコード モデルまたはバイ エンコーダーと呼ばれます。これらのエンコーダは、大規模なデータ コーパスでトレーニングされるため、ドキュメントのチャンクを単一のベクトル埋め込み表現でエンコードするのに十分強力です。
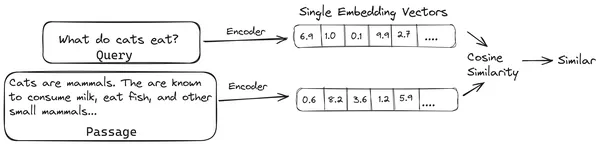
ここで、ユーザーが LLM にクエリを要求すると、このクエリを同じエンコーダに渡して、単一のベクトル埋め込みを生成します。次に、この埋め込みを使用して、文書チャンクの他のさまざまなベクトル埋め込みとの類似性スコアを計算し、文書の最も関連性の高いチャンクを取得します。最も関連性の高いチャンク、または最も関連性の高いチャンクのリストがユーザー クエリとともに LLM に渡されます。次に、LLM はこの追加のコンテキスト情報を受信し、ユーザー クエリから受信したコンテキストに合わせた回答を生成します。これにより、LLM によって生成されたコンテンツが事実であり、必要に応じて追跡できるものであることが保証されます。
従来のバイエンコーダの問題
all-miniLM などの従来の Encoder モデルの問題 OpenAI 埋め込みモデルと他のエンコーダ モデルの違いは、テキスト全体を単一のベクトル埋め込み表現に圧縮することです。これらの単一ベクトル埋め込み表現は、類似したドキュメントを効率的かつ迅速に検索するのに役立つため便利です。ただし、問題はクエリとドキュメントの間のコンテキストにあります。単一のベクトル埋め込みでは、文書チャンクのコンテキスト情報を保存するには不十分な場合があり、そのため情報ボトルネックが発生します。
500 ワードがサイズ 782 の単一ベクトルに圧縮されていると想像してください。このようなチャンクを単一ベクトル埋め込みで表現するだけでは十分ではないため、ほとんどの場合、検索結果が標準以下になります。単一のベクトル表現は、複雑なクエリやドキュメントの場合にも失敗する可能性があります。そのような解決策の XNUMX つは、ドキュメント チャンクまたはクエリを単一の埋め込みベクトルではなく埋め込みベクトルのリストとして表すことです。ここで ColBERT が登場します。
コルバートとは何ですか?
ColBERT (Contextual Late Interactions BERT) は、マルチベクトル埋め込み表現でテキストを表現するバイエンコーダーです。クエリまたはドキュメント/小さなドキュメントのチャンクを受け取り、トークン レベルでベクトル埋め込みを作成します。つまり、各トークンは独自のベクトル埋め込みを取得し、クエリ/ドキュメントはトークンレベルのベクトル埋め込みのリストにエンコードされます。トークンレベルの埋め込みは、事前にトレーニングされたものから生成されます。 ベルト モデルなので BERT という名前が付けられています。
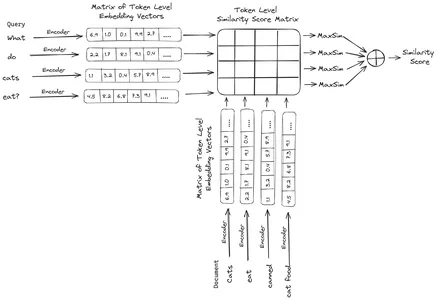
これらはベクトル データベースに保存されます。ここで、クエリが入力されると、そのクエリに対してトークン レベルの埋め込みのリストが作成され、ユーザー クエリと各ドキュメントの間で行列の乗算が実行され、類似性スコアを含む行列が得られます。全体的な類似性は、各クエリ トークンのドキュメント トークン全体の最大類似性の合計を取得することによって得られます。この計算式は以下の図で見ることができます。
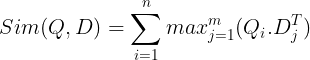
ここで、上記の方程式では、クエリ トークン行列 (N トークン レベルのベクトル埋め込みを含む) とドキュメント トークン行列の転置 (M トークン レベルのベクトル埋め込みを含む) の間でドット積を計算し、最大の類似度を取得することがわかります。各クエリ トークンのドキュメント トークンを調べます。次に、これらすべての最大類似度の合計を取得し、それによってドキュメントとクエリ間の最終的な類似度スコアが得られます。これにより効果的かつ正確な検索が行われる理由は、ここではトークンレベルの対話が行われており、クエリとドキュメントの間でよりコンテキストを理解する余地が与えられているためです。
ColBERT という名前の理由
埋め込みベクトルのリストをその前に計算し、モデル推論中にこの MaxSim (最大類似度) 操作のみを実行するため、これを後期インタラクション ステップと呼びます。また、トークン レベルのインタラクションを通じてより多くのコンテキスト情報を取得しているため、コンテキスト ステップと呼ばれます。遅いやりとり。したがって、Contextual Late Interactions という名前が付けられました。 ベルト またはコルバート。これらの計算は並行して実行できるため、効率的に計算できます。最後に、2 つの懸念はスペースです。つまり、このトークン レベルのベクトル埋め込みのリストを保存するには多くのスペースが必要です。この問題は ColBERTvXNUMX で解決され、埋め込みは残差圧縮と呼ばれる技術によって圧縮され、使用されるスペースが最適化されます。
実践的な ColBERT と例
このセクションでは、ColBERT を実際に操作し、通常の埋め込みモデルに対して ColBERT がどのように動作するかを確認します。
ステップ 1: ライブラリをダウンロードする
まず、次のライブラリをダウンロードします。
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- ラガトゥイユ: このライブラリを使用すると、ColBERT などの最先端 (SOTA) 取得メソッドを使いやすい方法で操作できるようになります。データセットに対してインデックスを作成したり、データセットに対してクエリを実行したり、データに対して ColBERT モデルをトレーニングしたりするためのオプションが提供されます。
- ラングチェーン: このライブラリを使用すると、オープンソースの埋め込みモデルを操作できるため、他の埋め込みモデルが ColBERT と比較してどの程度うまく機能するかをテストできます。
- langchain_openai: をインストールします ラングチェーン OpenAI の依存関係。 OpenAI Embedding モデルと連携して、ColBERT に対するパフォーマンスをチェックすることもします。
- クロマDB: このライブラリを使用すると、環境内にベクター ストアを作成できるため、データ上に作成したエンベディングを保存し、後でクエリと保存されたエンベディングの間でセマンティック検索を実行できます。
- エイノプス: このライブラリは、テンソル行列の乗算を効率的に行うために必要です。
- 文変換器 と ティックトークン オープンソースの埋め込みモデルが適切に動作するには、ライブラリが必要です。
ステップ 2: 事前トレーニングされたモデルをダウンロードする
次のステップでは、事前トレーニングされた ColBERT モデルをダウンロードします。このためのコードは次のようになります
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- まず、RAGatouille ライブラリから RAGPretrainedModel クラスをインポートします。
- 次に、.from_pretrained() を呼び出し、モデル名、つまり「colbert-ir/colbertv2.0」を指定します。
上記のコードを実行すると、ColBERT RAG モデルがインスタンス化されます。次に、Wikipedia ページをダウンロードして、そこから検索を実行してみましょう。この場合、コードは次のようになります。
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille には、文字列を受け取り、対応する Wikipedia ページを取得する get_wikipedia_page という便利な関数が付属しています。ここでは、Elon Musk に関する Wikipedia コンテンツをダウンロードし、変数ドキュメントに保存します。文書内に存在する単語数と文書の最初の数行を出力してみましょう。
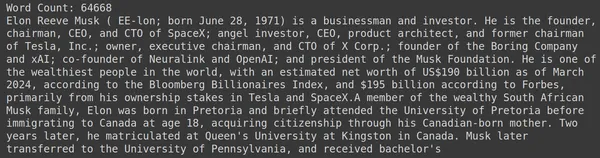
ここでは、画像の出力を確認できます。イーロン・マスクの Wikipedia ページには合計 64,668 語があることがわかります。
ステップ 3: インデックス作成
次に、このドキュメントにインデックスを作成します。
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)ここでは、RAG の .index() を呼び出してドキュメントのインデックスを作成します。これに対して、以下を渡します。
- コレクション: これはインデックスを作成するドキュメントのリストです。ここにはドキュメントが 1 つだけあるため、1 つのドキュメントのリストになります。
- document_id: 各ドキュメントには一意のドキュメント ID が必要です。このドキュメントはイーロン・マスクに関するものなので、ここでは elon_musk という名前を渡します。
- ドキュメントメタデータ: 各ドキュメントにはメタデータがあります。これも辞書のリストであり、各辞書には特定のドキュメントのキーと値のペアのメタデータが含まれています。
- インデックス名: 作成しているインデックスの名前。 Elon2 と名付けましょう。
- 最大ドキュメントサイズ: これはチャンク サイズと同様です。各ドキュメントのチャンクの大きさを指定します。ここでは、値 256 を指定しています。値を指定しない場合、256 がデフォルトのチャンク サイズとして使用されます。
- 分割ドキュメント: これはブール値で、True は指定されたチャンク サイズに従ってドキュメントを分割することを示し、False はドキュメント全体を単一のチャンクとして保存することを示します。
上記のコードを実行すると、ドキュメントがチャンクあたり 256 のサイズでチャンク化され、ColBERT モデルを通じて埋め込まれます。これにより、各チャンクのトークンレベルのベクトル埋め込みのリストが生成され、最終的にインデックスに格納されます。このステップの実行には少し時間がかかりますが、GPU がある場合は高速化できます。最後に、インデックスを保存するディレクトリを作成します。ここでのディレクトリは「.ragatouille/colbert/indexes/Elon2」になります。
ステップ 4: 一般的なクエリ
では、検索を開始します。このためのコードは次のようになります
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- ここでは、まず RAG オブジェクトの .search() メソッドを呼び出します。
- これには、クエリ名、k (取得するドキュメントの数)、および検索するインデックス名を含む変数を与えます。
- ここでは、「イーロン・マスクが見つけた企業は何ですか?」というクエリを提供します。取得された結果は、content、score、rank、document_id、passage_id、document_metadata などのキーを含む辞書形式のリストになります。
- したがって、以下のコードを使用して、取得したドキュメントをきちんとした方法で印刷します。
- ここでは辞書のリストを確認し、ドキュメントの内容を印刷します。
コードを実行すると、次の結果が生成されます。
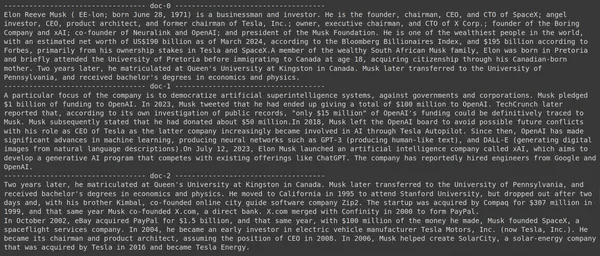
写真では、最初と最後の文書がイーロン・マスクによって設立されたさまざまな企業を完全にカバーしていることがわかります。 ColBERT は、クエリに答えるために必要な関連チャンクを正しく取得できました。
ステップ 5: 具体的なクエリ
では、さらに一歩進んで、具体的な質問をしてみましょう。
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])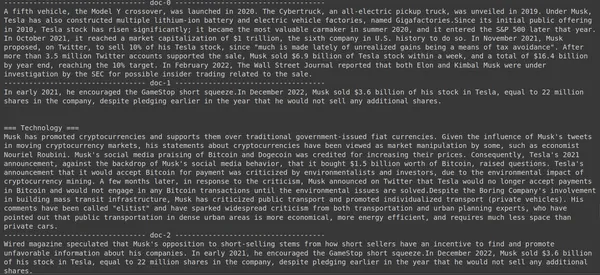
上記のコードでは、2022 年 1 月に販売された Tesla Elon 株の数について非常に具体的な質問をしています。出力はここで確認できます。 doc-3.6 には、質問に対する回答が含まれています。イーロンはXNUMX億ドル相当のテスラ株を売却した。ここでも、ColBERT は、指定されたクエリに関連するチャンクを正常に取得できました。
ステップ 6: 他のモデルをテストする
ここで、オープンソースとクローズドの両方の他の埋め込みモデルで同じ質問を試してみましょう。
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- まず、Transformers ライブラリから AutoModel クラスを通じてモデルをダウンロードします。
- 次に、model_name と model_kwargs をそれぞれの変数に保存します。
- LangChain でこのモデルを操作するために、HuggingFaceEmbeddings を ラングチェーン そしてモデル名とmodel_kwargsを指定します。
このコードを実行すると、Jina 埋め込みモデルがダウンロードおよびロードされ、操作できるようになります。
ステップ 7: 埋め込みを作成する
ここで、ドキュメントの分割を開始し、そこから埋め込みを作成して Chroma ベクター ストアに保存する必要があります。このために、次のコードを使用します。
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- まず、LangChain ライブラリから Chroma と RecursiveCharacterTextSplitter をインポートします。
- 次に、RecursiveCharacterTextSplitter の .from_tiktoken_encoder を呼び出し、それに chunk_size と chunk_overlap を渡すことで、text_splitter をインスタンス化します。
- ここでは、ColBERT に提供したのと同じ chunk_size を使用します。
- 次に、この text_splitter の .split_text() メソッドを呼び出し、イーロン・マスクに関する Wikipedia 情報を含むドキュメントをそれに与えます。次に、指定されたチャンク サイズに基づいてドキュメントを分割し、最後にドキュメント チャンクのリストが変数 splits に保存されます。
- 最後に、Chroma クラスの .from_texts() 関数を呼び出して、ベクター ストアを作成します。この関数に、分割、埋め込みモデル、および collection_name を与えます。
- 次に、ベクター ストア オブジェクトの .as_retriever() 関数を呼び出して、そこからレトリーバーを作成します。 k 値には 3 を与えます
このコードを実行すると、ドキュメントが取得され、チャンクごとにサイズ 256 の小さなドキュメントに分割され、これらの小さなチャンクが Jina 埋め込みモデルに埋め込まれ、これらの埋め込みベクトルがクロマ ベクトル ストアに保存されます。
ステップ 8: レトリバーの作成
最後に、それからレトリーバーを作成します。次に、ベクトル検索を実行して結果を確認します。
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)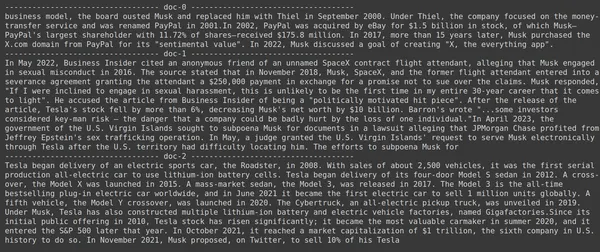
- 取得オブジェクトの .get_relevent_documents() 関数を呼び出し、同じクエリを与えます。
- 次に、取得した上位 3 つのドキュメントをきちんと印刷します。
- この図では、Jina Embedder は人気のある埋め込みモデルであるにもかかわらず、クエリの検索が不十分であることがわかります。正しいドキュメント チャンクを取得できませんでした。
各チャンクを単一のベクトル埋め込みとして表す埋め込みモデルである Jina と、各チャンクをトークンレベルの埋め込みベクトルのリストとして表す ColBERT モデルの違いを明確に見つけることができます。この場合、ColBERT のパフォーマンスが明らかに優れています。
ステップ 9: OpenAI の埋め込みモデルをテストする
次に、OpenAI 埋め込みモデルのようなクローズドソース埋め込みモデルを使用してみましょう。
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})ここでのコードは、先ほど書いたコードと非常によく似ています。
- 唯一の違いは、環境変数を設定するために OpenAI API キーを渡すことです。
- 次に、LangChain からインポートして OpenAI Embedding モデルのインスタンスを作成します。
- また、コレクション名を作成するときに、OpenAI Embedding モデルからの埋め込みが別のコレクションに保存されるように、別のコレクション名を付けます。
このコードを実行すると、ドキュメントが再度取得され、サイズ 256 の小さなドキュメントに分割され、OpenAI 埋め込みモデルを使用して単一のベクトル埋め込み表現に埋め込まれ、最終的にこれらの埋め込みが Chroma Vector Store に保存されます。次に、他の質問に関連するドキュメントを取得してみましょう。
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)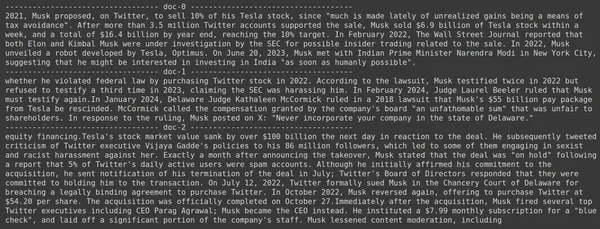
- 期待した答えが、取得したチャンク内に見つからないことがわかります。
- チャンクワンには2022年のテスラ株に関する情報が含まれていますが、イーロンの売却については触れられていません。
- 残りの 2 つの文書チャンクにも同様のことが見られ、そこに含まれる情報はテスラとその株式に関するものですが、これは私たちが期待する情報ではありません。
- 上記で取得したチャンクは、LLM が提供したクエリに答えるためのコンテキストを提供しません。
ここでも、単一ベクトルの埋め込み表現と複数ベクトルの埋め込み表現の間に明確な違いが見られます。マルチエンベディング表現は複雑なクエリを明確にキャプチャし、より正確な検索を実現します。
まとめ
結論として、ColBERT は、テキストをトークン レベルでマルチベクトル埋め込みとして表現することにより、従来のバイエンコーダー モデルに比べて検索パフォーマンスが大幅に向上していることを示しています。このアプローチにより、クエリとドキュメントの間の文脈をより微妙に理解できるようになり、より正確な検索結果が得られ、LLM でよく見られる幻覚の問題が軽減されます。
主要な取り組み
- RAG は、事実に基づく回答を生成するためのコンテキスト情報を提供することで、LLM の幻覚の問題に対処します。
- 従来のバイエンコーダは、テキスト全体を単一のベクトル埋め込みに圧縮するため、情報のボトルネックに悩まされ、その結果、検索精度が標準以下になってしまいます。
- ColBERT は、トークンレベルの埋め込み表現を備えているため、クエリとドキュメント間のコンテキストの理解を促進し、検索パフォーマンスの向上につながります。
- ColBERT の後半の対話ステップとトークンレベルの対話を組み合わせることで、文脈上のニュアンスを考慮することで検索の精度が向上します。
- ColBERTv2 は、検索効率を維持しながら、残留圧縮を通じてストレージ スペースを最適化します。
- 実際の実験では、Jina や OpenAI Embedding などの従来のオープンソース埋め込みモデルと比較して、ColBERT の検索パフォーマンスの優位性が実証されています。
よくある質問
A. 従来のバイエンコーダはテキスト全体を単一のベクトル埋め込みに圧縮するため、コンテキスト情報が失われる可能性があります。これにより、特に複雑なクエリやドキュメントの検索タスクにおける有効性が制限されます。
A. ColBERT (Contextual Late Interactions BERT) は、トークンレベルのベクトル埋め込みを使用してテキストを表現するバイエンコーダー モデルです。これにより、クエリとドキュメントの間の文脈をより微妙に理解できるようになり、検索の精度が向上します。
A. ColBERT は、クエリとドキュメントのトークンレベルの埋め込みを生成し、行列の乗算を実行して類似性スコアを計算し、トークン間の最大類似性に基づいて最も関連性の高い情報を選択します。これにより、文脈を理解しながら効果的な検索が可能になります。
A. ColBERTv2 は、残差圧縮方式を通じてスペースを最適化し、取得精度を維持しながら、トークンレベルの埋め込みに必要なストレージ要件を削減します。
A. RAGatouille のようなライブラリを使用すると、ColBERT を簡単に操作できます。ドキュメントとクエリにインデックスを付けることで、効率的な検索タスクを実行し、コンテキストに合わせた正確な回答を生成できます。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

