AmazonOpenSearchサービス は、AWS クラウドで OpenSearch とレガシー Elasticsearch クラスターを大規模に保護、デプロイ、運用することを容易にするマネージド サービスです。 Amazon OpenSearch Service は、クラスターのすべてのリソースをプロビジョニングして起動し、障害が発生したノードを自動的に検出して置き換えることで、自己管理インフラストラクチャのオーバーヘッドを削減します。 このサービスでは、OpenSearch の最新バージョン、Elasticsearch の 19 バージョン (1.5 から 7.10 バージョン) のサポート、およびOpenSearch ダッシュボードと Kibana (1.5 から 7.10 バージョン)。
最新のサービス ソフトウェア リリースでは、ノードに障害が発生した場合にシャードが再分散されるときに、障害が発生したノードで以前にホストされていたシャードによって残りのノードが過負荷になることをサービスが許可しないように、シャード割り当てロジックを負荷対応に更新しました。 これは、マルチ AZ ドメインが一貫した予測可能なクラスターパフォーマンスを提供するために特に重要です。
一般的なシャード割り当てロジックの背景について詳しく知りたい場合は、次を参照してください。 Elasticsearch シャード割り当てのわかりやすい説明.
課題
Amazon OpenSearch Service ドメインは、構成されたアベイラビリティーゾーン全体でノード数が均等に分散され、シャードの総数が使用可能なすべてのノードで均等に分散され、XNUMX つのインデックスのシャードがいずれかのノードに集中していない場合、「バランスがとれている」と言われます。ノード。 また、OpenSearch には「ゾーン認識」と呼ばれるプロパティがあり、有効にすると、プライマリ シャードとそれに対応するレプリカが異なるアベイラビリティ ゾーンに割り当てられます。 データのコピーが複数ある場合、複数のアベイラビリティ ゾーンを使用すると、フォールト トレランスと可用性が向上します。 ドメインがスケールアウトまたはスケールインされた場合、またはノードに障害が発生した場合、OpenSearch は、ゾーン認識に基づく割り当てルールに従いながら、利用可能なノード間でシャードを自動的に再分配します。
シャード バランシング プロセスにより、シャードがアベイラビリティー ゾーン全体に均等に分散されるようになりますが、場合によっては、XNUMX つのゾーンで予期しない障害が発生した場合、シャードは残りのノードに再割り当てされます。 これにより、生き残ったノードが圧倒され、クラスターの安定性に影響を与える可能性があります。
たとえば、XNUMX ノード クラスター内の XNUMX つのノードがダウンした場合、OpenSearch は、次の図に示すように、割り当てられていないシャードを再配布します。 ここで、「P」はプライマリ シャード コピーを表し、「R」はレプリカ シャード コピーを表します。

ドメインのこの動作は、障害時と復旧時の XNUMX つの部分で説明できます。
故障時
複数のアベイラビリティーゾーンにデプロイされたドメインは、ライフサイクル中に複数のタイプの障害に遭遇する可能性があります。
ゾーンの完全な失敗
クラスターは、さまざまな理由により、単一のアベイラビリティーゾーンを失う可能性があり、そのゾーン内のすべてのノードも失う可能性があります。 現在、サービスは失われたノードを残りの正常なアベイラビリティーゾーンに配置しようとします。 サービスは、割り当てルールに従いながら、失われたシャードを残りのノードで再作成しようとします。 これにより、意図しない結果が生じる可能性があります。
- 影響を受けたゾーンのシャードが正常なゾーンに再割り当てされると、追加の CPU サイクルとネットワーク帯域幅を消費するため、レイテンシが増加する可能性があるシャード リカバリがトリガーされます。
- n-AZ、n-copy セットアップ (n>1) の場合、残りの n-1 アベイラビリティーゾーンに n 番目のシャードコピーが割り当てられます。ノード間の不均衡なトラフィック。 これらのノードは過負荷になり、さらなる障害につながる可能性があります。
部分的なゾーン障害
部分的なゾーン障害が発生した場合、またはドメインがアベイラビリティ ゾーン内の一部のノードのみを失った場合、Amazon OpenSearch Service は障害が発生したノードをできるだけ早く交換しようとします。 ただし、ノードの置換に時間がかかりすぎる場合、OpenSearch はそのゾーンの未割り当てのシャードをアベイラビリティーゾーン内の残りのノードに割り当てようとします。 サービスが影響を受けるアベイラビリティーゾーンのノードを置き換えることができない場合、サービスはそれらを他の構成済みアベイラビリティーゾーンに割り当てることができ、ゾーン全体およびゾーン内の両方でシャードの分散をさらに歪める可能性があります。 これもまた、意図しない結果をもたらします。
- ドメイン上のノードに、追加のシャードに対応するための十分なストレージ容量がない場合、ドメインは書き込みがブロックされ、インデックス作成操作に影響を与える可能性があります。
- シャードの分散が偏っているため、ドメインではノード間でトラフィックの偏りが発生する可能性があり、読み取りおよび書き込み操作の待機時間またはタイムアウトがさらに増加する可能性があります。
回復
現在、ドメインの必要なノード数を維持するために、Amazon OpenSearch Service は、上記の障害セクションで説明したシナリオと同様に、残りの正常なアベイラビリティーゾーンでデータノードを起動します。 このようなインシデントの後、すべてのアベイラビリティーゾーンで適切なノード分散を確保するために、AWS による手動の介入が必要でした。
何が変わったのか
全体的な障害処理を改善し、ドメインの健全性とパフォーマンスに対する障害の影響を最小限に抑えるために、Amazon OpenSearch Service は次の変更を行っています。
- 強制ゾーン認識: OpenSearch には、強制認識と呼ばれる既存のシャード バランシング構成があり、シャードを割り当てる必要があるアベイラビリティー ゾーンを設定するために使用されます。 たとえば、ゾーンと呼ばれる認識属性があり、ノードを構成する場合
zone1&zone2、強制認識を使用して、使用可能なゾーンが XNUMX つしかない場合に OpenSearch がレプリカを割り当てないようにすることができます。
この構成例では、XNUMX つのノードを node.attr.zone に設定 zone1 XNUMX つのシャードと XNUMX つのレプリカでインデックスを作成すると、OpenSearch はインデックスを作成し、XNUMX つのプライマリ シャードを割り当てますが、レプリカは割り当てません。 レプリカは、ノードに一度だけ割り当てられます node.attr.zone に設定 zone2 ご利用いただけます。
Amazon OpenSearch Service は、マルチ AZ ドメインで強制認識設定を使用して、シャードがゾーン認識のルールに従ってのみ割り当てられるようにします。 これにより、正常なアベイラビリティーゾーンのノードの負荷が突然増加するのを防ぐことができます。
- 負荷を考慮したシャード割り当て: Amazon OpenSearch Service は、プロビジョニングされた容量、実際の容量、合計シャード コピーなどの要因を考慮して、ノードあたりの予想平均シャードに基づいて、より多くのシャードでノードが過負荷になっているかどうかを計算します。 いずれかのノードがこの制限を超えるシャード数を割り当てた場合、シャードの割り当てが妨げられます。
Note 割り当てられていない 主要な 過負荷のノードでもコピーは引き続き許可され、差し迫ったデータ損失からクラスターを防ぎます。
同様に、(上記の「復旧」セクションで説明したように) 手動復旧の問題に対処するために、Amazon OpenSearch Service は内部スケーリング コンポーネントにも変更を加えています。 新しい変更が適用されると、Amazon OpenSearch Service は、前述の障害シナリオを通過した場合でも、残りのアベイラビリティーゾーンでノードを起動しません。
現在および新しい動作の視覚化
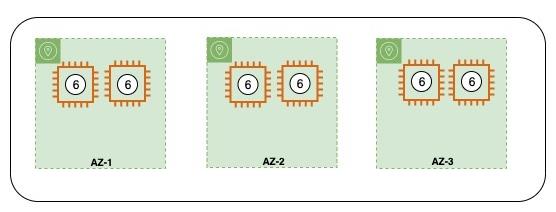
たとえば、Amazon OpenSearch Service ドメインは、3-AZ、6 つのデータノード、12 のプライマリ シャード、および 24 のレプリカ シャードで構成されています。 ドメインは、AZ-1、AZ-2、および AZ-3 にわたってプロビジョニングされ、各ゾーンに XNUMX つのノードがあります。
現在のシャード割り当て:
シャードの総数: 12 プライマリ + 24 レプリカ = 36 シャード
アベイラビリティーゾーンの数: 3
ゾーンごとのシャード数 (ゾーン認識は true): 36/3 = 12
アベイラビリティーゾーンあたりのノード数: 2
ノードあたりのシャード数: 12/2 = 6
次の図は、ドメインの設定を視覚的に表したものです。 円は、ノードに割り当てられたシャードの数を示します。 Amazon OpenSearch Service は、ノードごとに XNUMX つのシャードを割り当てます。
AZ-3 の XNUMX つのノードで障害が発生する部分的なゾーン障害の間、障害が発生したノードは残りのゾーンに割り当てられ、ゾーン内のシャードは使用可能なノードに基づいて再配布されます。 上記の変更後、クラスターは、ノードの障害後に新しいノードを作成したり、シャードを再配布したりしません。
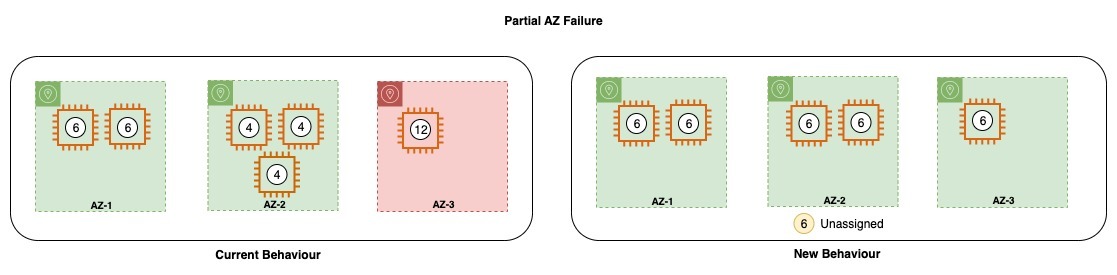
上の図では、AZ-3 で XNUMX つのノードが失われると、Amazon OpenSearch Service は同じゾーンで代替容量を起動しようとします。 ただし、一部の停止により、ゾーンが損なわれ、代替の起動に失敗する可能性があります。 このような場合、サービスは別の正常なゾーンで不足容量を起動しようとします。これにより、アベイラビリティー ゾーン間でゾーンの不均衡が生じる可能性があります。 影響を受けたゾーンのシャードは、同じゾーン内の生き残ったノードに詰め込まれます。 ただし、新しい動作では、サービスは同じゾーンで容量を起動しようとしますが、不均衡を避けるために他のゾーンで不足容量を起動することは避けます。 シャード アロケーターは、生き残ったノードが過負荷にならないようにすることもできます。

同様に、AZ-3 のすべてのノードが失われた場合、または AZ-3 が機能しなくなった場合、Amazon OpenSearch Service は残りのアベイラビリティーゾーンで失われたノードを起動し、ノード上のシャードを再配布します。 ただし、新しい変更後、Amazon OpenSearch Service は残りのゾーンにノードを割り当てないか、失われたシャードを残りのゾーンに再割り当てしようとします。 Amazon OpenSearch Service は、復旧が行われ、復旧後にドメインが元の構成に戻るまで待機します。
アベイラビリティーゾーンの損失に耐えるのに十分な容量がドメインにプロビジョニングされていない場合、ドメインのスループットが低下する可能性があります。 そのため、ドメインのサイジング中はベスト プラクティスに従うことを強くお勧めします。つまり、単一のアベイラビリティ ゾーン障害の損失に耐えるために十分なリソースをプロビジョニングすることを意味します。

現在、ドメインが復旧すると、アベイラビリティー ゾーン間で容量のバランスをとるためにサービスに手動で介入する必要があり、これにはシャードの移動も含まれます。 ただし、新しい動作では、容量が影響を受けたゾーンに戻り、シャードも回復されたノードに自動的に割り当てられるため、回復プロセス中に介入は必要ありません。 これにより、残りのリソースに競合する優先順位がなくなります。
あなたが期待することができますどのような
Amazon OpenSearch Service ドメインを最新のサービス ソフトウェア リリースに更新すると、 ベスト プラクティスで構成された アベイラビリティーゾーンで XNUMX つまたは多数のデータノードが失われた後でも、より予測可能なパフォーマンスが得られます。 ノードでのシャードの割り当て超過のケースが減少します。 単一ゾーンの障害に耐えられるように十分な容量をプロビジョニングすることをお勧めします
過負荷のノードにレプリカ シャードを割り当てないため、このような予期しない障害が発生したときにドメインが黄色に変わることがあります。 ただし、これは、適切に構成されたドメインでデータが失われるという意味ではありません。 停止中も、すべてのプライマリが割り当てられていることを確認します。 自動復旧が行われ、ドメイン内のノードのバランスを取り、障害が復旧したときにレプリカが確実に割り当てられるようにします。
Amazon OpenSearch Service ドメインのサービス ソフトウェアを更新して、これらの新しい変更をドメインに適用します。 サービス ソフトウェアの更新プロセスの詳細については、 Amazon OpenSearch サービスのドキュメント.
まとめ
この投稿では、Amazon OpenSearch Service が最近、ゾーンの停止時にノードとシャードをアベイラビリティーゾーン全体に分散するロジックをどのように改善したかを説明しました。
この変更は、サービスがノードまたはゾーンの障害時に、より一貫した予測可能なパフォーマンスを保証するのに役立ちます。 ドメインでは、書き込みと読み取りの処理中にレイテンシーの増加や書き込みブロックが発生することはありません。これは、ノード上のシャードの過剰割り当てが原因で以前に表面化していたものです。
著者について
 ブフタワル・カーン は、Amazon OpenSearch Service に取り組んでいるシニア ソフトウェア エンジニアです。 分散型および自律型システムに関心があります。 彼は OpenSearch に積極的に貢献しています。
ブフタワル・カーン は、Amazon OpenSearch Service に取り組んでいるシニア ソフトウェア エンジニアです。 分散型および自律型システムに関心があります。 彼は OpenSearch に積極的に貢献しています。
 アンシュ・アガルワル アマゾン ウェブ サービスで AWS OpenSearch に取り組んでいるシニア ソフトウェア エンジニアです。 彼女は、スケーラブルで信頼性の高いシステムの構築に関連する問題を解決することに情熱を注いでいます。
アンシュ・アガルワル アマゾン ウェブ サービスで AWS OpenSearch に取り組んでいるシニア ソフトウェア エンジニアです。 彼女は、スケーラブルで信頼性の高いシステムの構築に関連する問題を解決することに情熱を注いでいます。
 ショーリヤ・ドゥッタ・ビスワス アマゾン ウェブ サービスで AWS OpenSearch に取り組んでいるソフトウェア エンジニアです。 彼は、回復力の高い分散システムの構築に情熱を注いでいます。
ショーリヤ・ドゥッタ・ビスワス アマゾン ウェブ サービスで AWS OpenSearch に取り組んでいるソフトウェア エンジニアです。 彼は、回復力の高い分散システムの構築に情熱を注いでいます。
 ナハタ・リシャブ アマゾン ウェブ サービスで OpenSearch に取り組んでいるソフトウェア エンジニアです。 彼は、分散システムの問題を解決することに興味を持っています。 彼は OpenSearch に積極的に貢献しています。
ナハタ・リシャブ アマゾン ウェブ サービスで OpenSearch に取り組んでいるソフトウェア エンジニアです。 彼は、分散システムの問題を解決することに興味を持っています。 彼は OpenSearch に積極的に貢献しています。
 ランジス・ラマチャンドラ アマゾンウェブサービスでアマゾンオープンサーチサービスに取り組んでいるエンジニアリングマネージャーです。
ランジス・ラマチャンドラ アマゾンウェブサービスでアマゾンオープンサーチサービスに取り組んでいるエンジニアリングマネージャーです。
 ジョン・ハンドラー AWS 検索テクノロジー (Amazon CloudSearch および Amazon OpenSearch Service) を専門とするシニア プリンシパル ソリューション アーキテクトです。 パロアルトに拠点を置く彼は、幅広い顧客が検索とログ分析のワークロードを適切にデプロイして適切に機能させるのを支援しています。
ジョン・ハンドラー AWS 検索テクノロジー (Amazon CloudSearch および Amazon OpenSearch Service) を専門とするシニア プリンシパル ソリューション アーキテクトです。 パロアルトに拠点を置く彼は、幅広い顧客が検索とログ分析のワークロードを適切にデプロイして適切に機能させるのを支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/

