トリノ は、対話型分析ワークロード用に設計されたオープンソースの分散 SQL クエリ エンジンです。 AWS では、Trino を実行できます アマゾンEMR、オープン ソース Trino の好みのバージョンを柔軟に実行できます。 アマゾン エラスティック コンピューティング クラウド あなたが管理する (Amazon EC2) インスタンス、または アマゾンアテナ サーバーレスエクスペリエンスのために。 Amazon EMR または Athena で Trino を使用すると、AWS が開発した独自の最適化とともに、最新のオープンソースコミュニティのイノベーションを利用できます。
Amazon EMR 6.8.0 と Athena エンジン バージョン 2 以降、AWS は Trino でのクエリパフォーマンスを向上させるクエリプランとエンジン動作の最適化を開発してきました。この投稿では、Amazon EMR 6.15.0 とオープンソース Trino 426 を比較し、Amazon EMR 2.7 Trino 6.15.0 では TPC-DS クエリが最大 426 倍高速に実行されたことを示します。 オープンソース Trino 426。後で、これらの結果に貢献する AWS が開発したパフォーマンス最適化のいくつかについて説明します。
ベンチマークの設定
テストでは、圧縮された Parquet 形式で Amazon S3 に保存されている 3 TB データセットを使用しました。データベースとテーブルのメタデータは、 AWSグルー データカタログ。このベンチマークは、変更されていない TPC-DS データ スキーマとテーブルの関係を使用します。ファクト テーブルは日付列でパーティション化されており、200 ~ 2100 個のパーティションが含まれています。どのテーブルにもテーブルと列の統計が存在しませんでした。オープンソース Trino の TPC-DS クエリを使用しました。 Githubリポジトリ 変更なしで。ベンチマーククエリは、6.15.0 つの異なる Amazon EMR 426 クラスターで順次実行されました。426 つは Amazon EMR Trino 1 を使用し、もう 5.4 つはオープンソース Trino 20 を使用しました。どちらのクラスターも 5.4 つの rXNUMXxlarge コーディネーターと XNUMX の rXNUMXxlarge ワーカー インスタンスを使用しました。
観察された結果
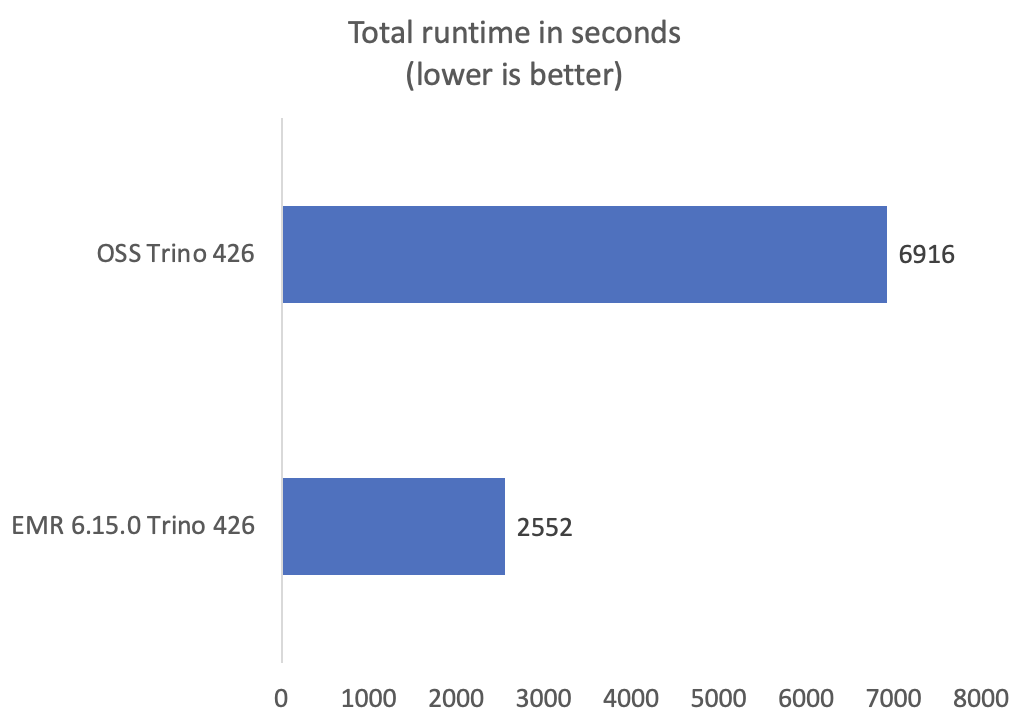
私たちのベンチマークでは、オープンソースの Trino と比較して、Amazon EMR 6.15.0 上の Trino の方が一貫して優れたパフォーマンスを示しています。 Amazon EMR 上の Trino の合計クエリ実行時間は、オープンソースと比較して 2.7 倍高速でした。次のグラフは、ベンチマーク クエリの合計クエリ実行時間 (秒単位) によって測定されたパフォーマンスの向上を示しています。
TPC-DS クエリの多くは、オープンソース Trino と比較して 72 倍以上高速なパフォーマンスの向上を示しました。一部のクエリでは、160 倍向上したクエリ 10 など、さらに優れたパフォーマンスが示されました。次のグラフは、実行時間が最も大きく改善された上位 72 個の TPC-DS クエリを示しています。簡潔に表現し、グラフのパフォーマンス向上の偏りを避けるために、qXNUMX を除外しました。

パフォーマンスの向上
Amazon EMR の Trino によるパフォーマンスの向上を理解したところで、これらの改善に貢献する AWS エンジニアリングによって開発された主要なイノベーションのいくつかをさらに深く掘り下げてみましょう。
より良い結合順序と結合タイプの選択は、特定のテーブルから読み取られるデータの量、ネットワーク経由で中間ステージに転送されるデータの量、構築に必要なメモリの量に影響を与える可能性があるため、クエリのパフォーマンスを向上させるために重要です。結合を容易にするためのハッシュ テーブル。結合順序と結合アルゴリズムの決定は通常、コストベースのオプティマイザーによって実行される機能であり、統計を使用してテーブルとサブクエリの結合方法を決定することでクエリ プランを改善します。
ただし、テーブル統計は入手できない、古い、または大規模なテーブルで収集するにはコストが高すぎることがよくあります。統計が利用できない場合、Amazon EMR と Athena は S3 ファイルのメタデータを使用してクエリプランを最適化します。 S3 ファイルのメタデータは、結合順序または結合タイプを決定する際に、クエリ内の小さなサブクエリとテーブルを推測するために使用されます。たとえば、次のクエリについて考えてみましょう。
構文上の結合順序は次のとおりです。 store_sales ジョイン store_returns ジョイン call_center。 Amazon EMR 結合タイプと順序選択の最適化ルールを使用すると、これらのテーブルに統計情報がない場合でも、最適な結合順序が決定されます。前述のクエリの場合、 call_center S3 ファイルのメタデータを通じておおよそのサイズを推定した後、小さなテーブルとみなされ、EMR の結合最適化ルールによって結合されます。 store_sales call_center まず結合をブロードキャスト結合に変換して、クエリを高速化し、メモリ消費を削減します。結合の並べ替えにより中間結果のサイズが最小限に抑えられるため、全体的なクエリの実行時間がさらに短縮されます。
Amazon EMR 6.10.0 以降では、S3 ファイルのメタデータベースの結合の最適化がデフォルトで有効になっています。 Amazon EMR 6.8.0 または 6.9.0 を使用している場合は、Trino クライアントからセッションプロパティを設定するか、クラスターの作成時に次のプロパティを trino-config 分類に追加することで、これらの最適化を有効にすることができます。参照する アプリケーションの構成 アプリケーションのデフォルト構成をオーバーライドする方法の詳細については、「アプリケーションのデフォルト構成をオーバーライドする方法」を参照してください。
結合タイプ選択の構成:
結合再順序の構成:
まとめ
Amazon EMR 6.8.0 以降では、オープンソース Trino よりも大幅に高速に Trino でクエリを実行できます。このブログ投稿で示されているように、TPC-DS ベンチマークでは、Amazon EMR 2.7 上の Trino を使用した場合、合計クエリ実行時間が 6.15.0 倍向上したことが示されました。この投稿で説明した最適化や他の多くの最適化は、Athena で Trino クエリを実行するときにも利用でき、同様のパフォーマンスの向上が見られます。詳細については、を参照してください。 最新の Amazon Athena エンジンでクエリを 3 倍高速に実行し、コストを最大 70% 削減します.
お客様に代わって革新するという使命のもと、Amazon EMR と Athena は最新バージョンのパフォーマンスと信頼性の強化を頻繁にリリースしています。チェックしてください アマゾンEMR & アマゾンアテナ リリース ページを参照して、新機能と拡張機能について学びます。
著者について
 バルガヴィ・サギ Amazon Athena のソフトウェア開発エンジニアです。彼女は 2020 年に AWS に入社し、エンジンのアップグレード、エンジンの信頼性、エンジンのパフォーマンスなど、Amazon EMR と Athena エンジン V3 のさまざまな分野に取り組んできました。
バルガヴィ・サギ Amazon Athena のソフトウェア開発エンジニアです。彼女は 2020 年に AWS に入社し、エンジンのアップグレード、エンジンの信頼性、エンジンのパフォーマンスなど、Amazon EMR と Athena エンジン V3 のさまざまな分野に取り組んできました。
 スシル・クマール・シヴァシャンカール EMR Trino および Athena Query Engine チームのエンジニアリング マネージャーです。彼は 2014 年からビッグデータ分析分野に注力しています。
スシル・クマール・シヴァシャンカール EMR Trino および Athena Query Engine チームのエンジニアリング マネージャーです。彼は 2014 年からビッグデータ分析分野に注力しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/run-trino-queries-2-7-times-faster-with-amazon-emr-6-15-0/

