コンテキスト検索とセマンティック検索の台頭により、e コマースや小売企業は消費者にとって検索が簡単になりました。生成 AI を活用した検索エンジンと推奨システムは、自然言語クエリを理解し、より正確な結果を返すことで、製品の検索エクスペリエンスを飛躍的に向上させることができます。これにより全体的なユーザー エクスペリエンスが向上し、顧客が探しているものを正確に見つけられるようになります。
AmazonOpenSearchサービス 今サポートします コサイン類似性 k-NN インデックスのメトリック。 コサイン類似度は、XNUMX つのベクトル間の角度のコサインを測定します。ここで、コサイン角度が小さいほど、ベクトル間の類似度が高いことを示します。 コサイン類似度を使用すると、XNUMX つのベクトル間の向きを測定できるため、特定のセマンティック検索アプリケーションに適しています。
この投稿では、 Amazon Titan マルチモーダル埋め込みモデルで利用可能 アマゾンの岩盤、と Amazon OpenSearch サーバーレス.
マルチモーダル エンベディング モデルは、テキスト、画像、オーディオなどのさまざまなモダリティの共同表現を学習するように設計されています。画像とそれに対応するキャプションを含む大規模なデータセットでトレーニングすることにより、マルチモーダル埋め込みモデルは共有潜在空間に画像とテキストを埋め込む方法を学習します。以下は、概念的にどのように機能するかの概要です。
- 個別のエンコーダ – これらのモデルには、モダリティごとに個別のエンコーダがあります。テキスト用のテキスト エンコーダ(BERT や RoBERTa など)、画像用の画像エンコーダ(画像用の CNN など)、音声用のオーディオ エンコーダ(Wav2Vec などのモデル)です。 。各エンコーダは、それぞれのモダリティの意味論的特徴をキャプチャするエンベディングを生成します。
- モダリティ融合 – ユニモーダル エンコーダーからのエンベディングは、追加のニューラル ネットワーク層を使用して結合されます。目標は、モダリティ間の相互作用と相関関係を学ぶことです。一般的な融合アプローチには、連結、要素ごとの操作、プーリング、およびアテンション メカニズムが含まれます。
- 共有表現空間 – 融合レイヤーは、個々のモダリティを共有表現空間に投影するのに役立ちます。マルチモーダル データセットでトレーニングすることにより、モデルは、同じ基礎となる意味論的コンテンツを表す各モダリティからのエンベディングがより近くにある共通のエンベディング空間を学習します。
- 下流タスク – 生成された結合マルチモーダル エンベディングは、マルチモーダル検索、分類、翻訳などのさまざまな下流タスクに使用できます。このモデルは、モダリティ間の相関関係を使用して、個々のモーダル埋め込みと比較して、これらのタスクのパフォーマンスを向上させます。主な利点は、共同モデリングを通じてテキスト、画像、音声などのモダリティ間の相互作用とセマンティクスを理解できることです。
ソリューションの概要
このソリューションは、テキストまたは画像のクエリに基づいて製品を取得および推奨する、大規模言語モデル (LLM) を利用した検索エンジン プロトタイプを構築するための実装を提供します。を使用する手順を詳しく説明します。 Amazon Titan マルチモーダル埋め込み 画像とテキストをエンコードして埋め込みにし、埋め込みを OpenSearch サービスのインデックスに取り込み、OpenSearch サービスを使用してインデックスをクエリするためのモデル k 最近傍 (k-NN) 機能.
このソリューションには、次のコンポーネントが含まれています。
- Amazon Titan マルチモーダル埋め込みモデル – この基礎モデル (FM) は、この投稿で使用されている製品画像の埋め込みを生成します。 Amazon Titan マルチモーダル エンベディングを使用すると、コンテンツのエンベディングを生成し、ベクトル データベースに保存できます。エンドユーザーがテキストと画像の任意の組み合わせを検索クエリとして送信すると、モデルは検索クエリのエンベディングを生成し、保存されているエンベディングと照合して、関連する検索結果と推奨結果をエンドユーザーに提供します。モデルをさらにカスタマイズして、独自のコンテンツの理解を強化し、微調整用の画像とテキストのペアを使用して、より有意義な結果を提供することができます。デフォルトでは、モデルは 1,024 次元のベクトル (埋め込み) を生成し、Amazon Bedrock 経由でアクセスします。速度とパフォーマンスを最適化するために、より小さいディメンションを生成することもできます。
- Amazon OpenSearch サーバーレス – これは、OpenSearch Service のオンデマンドのサーバーレス構成です。 Amazon Titan マルチモーダル エンベディング モデルによって生成されたエンベディングを保存するためのベクトル データベースとして Amazon OpenSearch Serverless を使用します。 Amazon OpenSearch サーバーレス コレクションで作成されたインデックスは、検索拡張生成 (RAG) ソリューションのベクトル ストアとして機能します。
- Amazon SageMakerスタジオ – 機械学習 (ML) のための統合開発環境 (IDE) です。 ML 実践者は、データの準備から ML モデルの構築、トレーニング、デプロイに至るまで、すべての ML 開発ステップを実行できます。
ソリューション設計は、データのインデックス作成とコンテキスト検索の 2 つの部分で構成されます。データのインデックス作成中に、製品画像を処理してこれらの画像の埋め込みを生成し、ベクトル データ ストアにデータを取り込みます。これらのステップは、ユーザー対話ステップの前に完了します。
コンテキスト検索フェーズでは、ユーザーからの検索クエリ (テキストまたは画像) が埋め込みに変換され、ベクトル データベース上で類似性検索が実行され、類似性検索に基づいて類似した製品画像が検索されます。次に、類似した上位の結果を表示します。この投稿のコードはすべて次の場所にあります。 GitHubレポ.
次の図は、ソリューションのアーキテクチャを示しています。
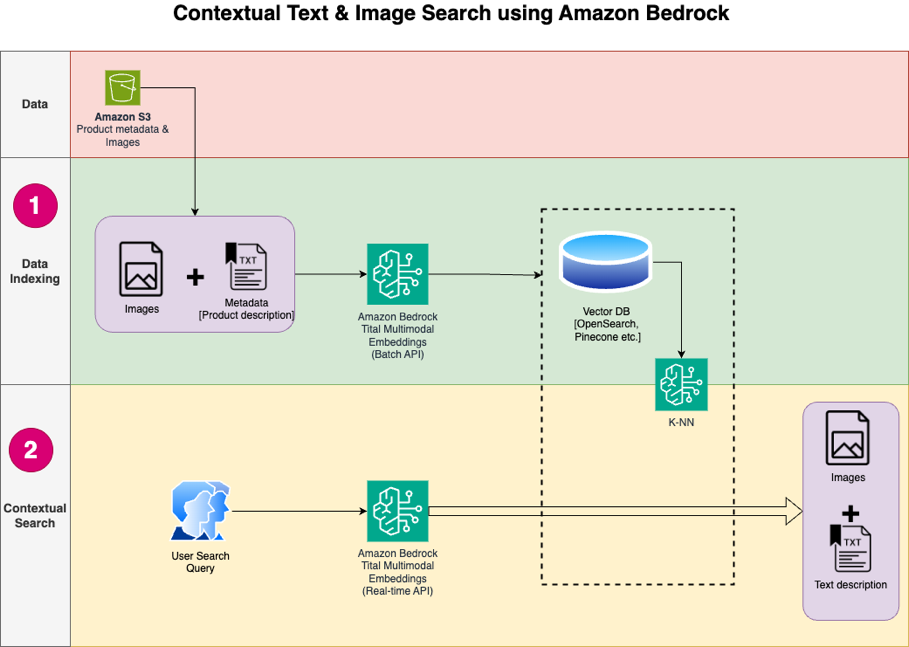
ソリューション ワークフローの手順は次のとおりです。
- 製品説明のテキストと画像を一般からダウンロードする Amazon シンプル ストレージ サービス (Amazon S3)バケット。
- データセットを確認して準備します。
- Amazon Titan マルチモーダル埋め込みモデル (amazon.titan-embed-image-v1) を使用して、製品画像の埋め込みを生成します。膨大な数の画像と説明がある場合は、オプションで Amazon Bedrock のバッチ推論.
- 埋め込みを Amazon OpenSearch サーバーレス 検索エンジンとして。
- 最後に、自然言語でユーザークエリを取得し、Amazon Titan マルチモーダル埋め込みモデルを使用して埋め込みに変換し、k-NN 検索を実行して関連する検索結果を取得します。
ソリューションを開発するための IDE として SageMaker Studio (図には示されていません) を使用します。
これらの手順については、次のセクションで詳しく説明します。スクリーンショットと出力の詳細も含まれます。
前提条件
この投稿で提供されるソリューションを実装するには、次のものが必要です。
- An AWSアカウント FM、Amazon Bedrock、 アマゾンセージメーカー、OpenSearch サービス。
- Amazon Bedrock で有効になっている Amazon Titan マルチモーダル埋め込みモデル。有効になっていることを確認できます モデルアクセス Amazon Bedrock コンソールのページ。 Amazon Titan マルチモーダル埋め込みが有効になっている場合、アクセスステータスは次のように表示されます。 アクセスが許可されました、次のスクリーンショットに示すように。

モデルが利用できない場合は、選択してモデルへのアクセスを有効にします。 モデルへのアクセスを管理する選択する Amazon Titan マルチモーダル埋め込み G1、および選択 モデルへのアクセスをリクエストする。モデルはすぐに使用できるようになります。

ソリューションをセットアップする
前提条件の手順が完了すると、ソリューションをセットアップする準備が整います。
- AWS アカウントで、SageMaker コンソールを開いて、 Studio ナビゲーションペインに表示されます。
- ドメインとユーザー プロファイルを選択し、 オープンスタジオ.
ドメインとユーザー プロファイル名は異なる場合があります。

- 選択する システム端末 下 ユーティリティとファイル.
- 次のコマンドを実行して、 GitHubレポ SageMaker Studio インスタンスに:
- に移動します
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2eフォルダにコピーします。 - Video Cloud Studioで
titan_mm_embed_search_blog.ipynbノート。
ソリューションを実行する
ファイルをオープンする titan_mm_embed_search_blog.ipynb データ サイエンス Python 3 カーネルを使用します。で ラン メニュー、選択 すべてのセルを実行 このノートブックのコードを実行します。
このノートブックは次の手順を実行します。
- このソリューションに必要なパッケージとライブラリをインストールします。
- 公開されているものをロードする Amazon Berkeley オブジェクト データセット パンダ データ フレーム内のメタデータ。
このデータセットは、多言語メタデータを含む 147,702 件の製品リストと 398,212 件の固有のカタログ画像のコレクションです。この投稿では、米国英語の商品画像と商品名のみを使用します。約1,600の製品を使用しています。

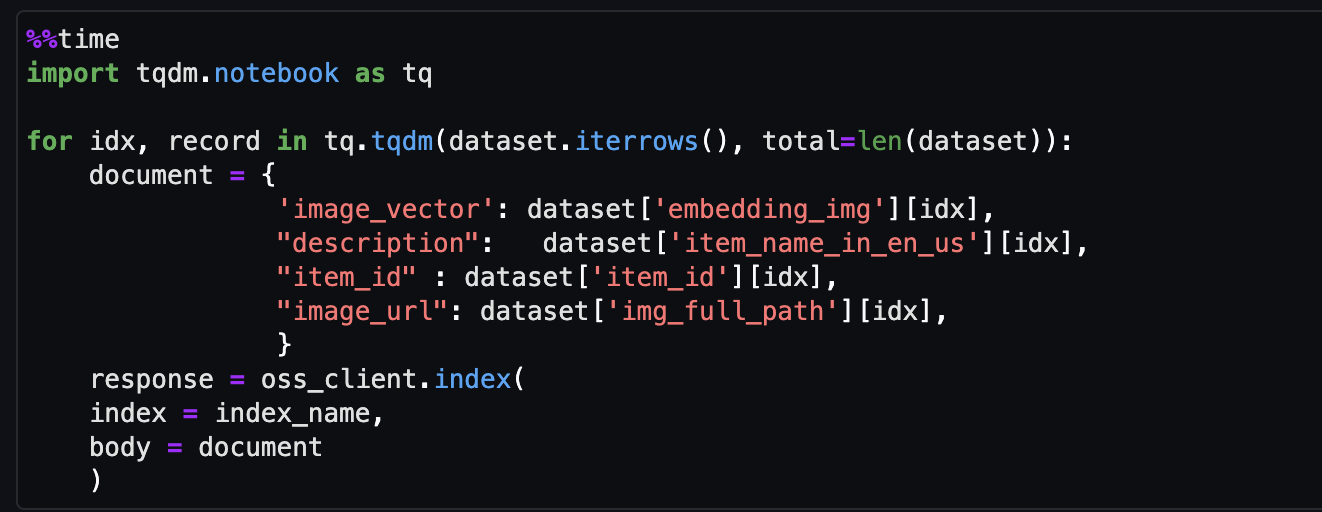
- Amazon Titan マルチモーダル埋め込みモデルを使用してアイテム画像の埋め込みを生成します。
get_titan_multomodal_embedding()関数。抽象化のために、このノートブックで使用されるすべての重要な関数をutils.pyファイルにソフトウェアを指定する必要があります。

次に、Amazon OpenSearch サーバーレス ベクター ストア (コレクションとインデックス) を作成して設定します。
- 新しいベクトル検索コレクションとインデックスを作成する前に、まず、暗号化セキュリティ ポリシー、ネットワーク セキュリティ ポリシー、およびデータ アクセス ポリシーという 3 つの関連する OpenSearch サービス ポリシーを作成する必要があります。

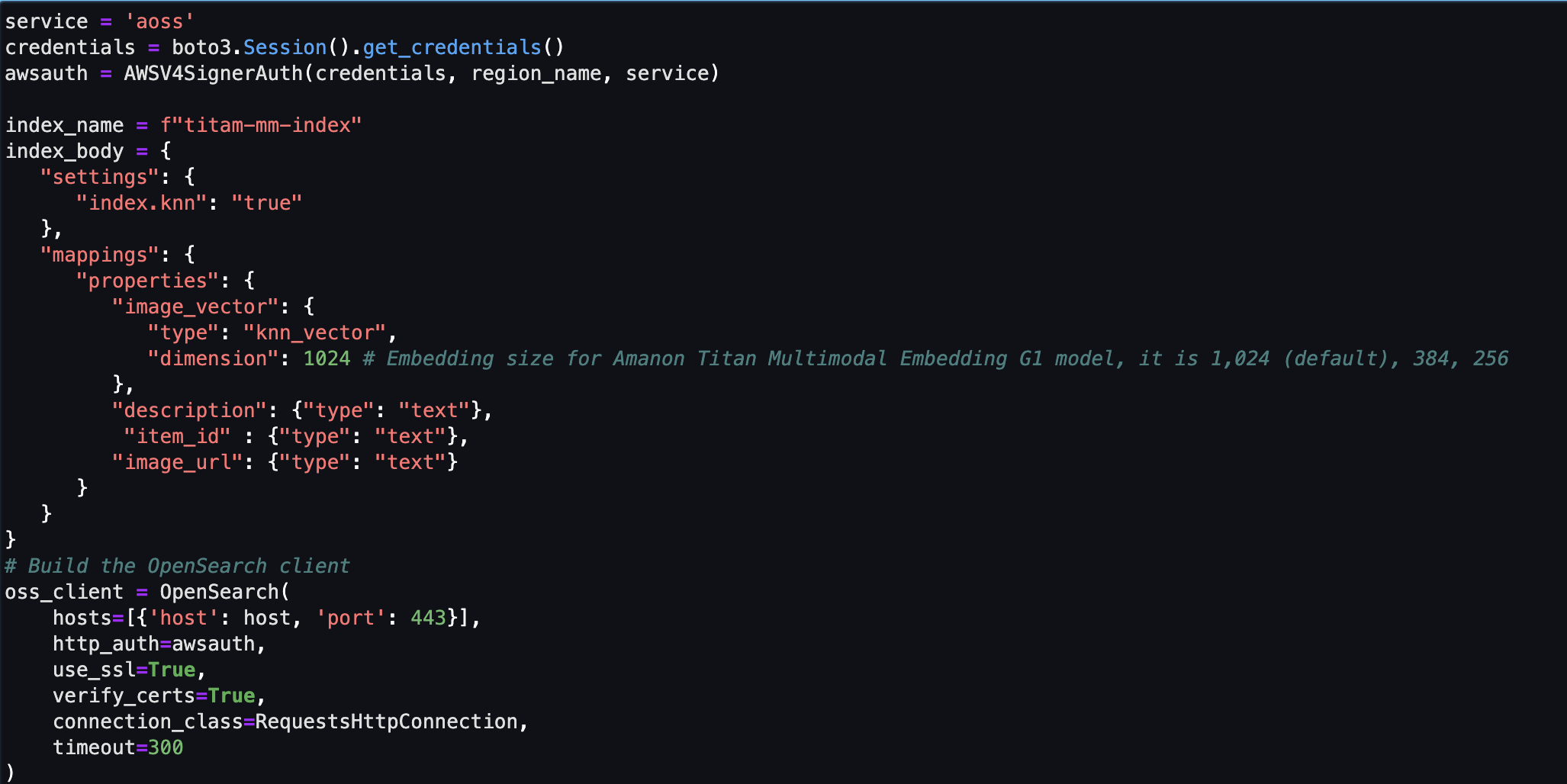
- 最後に、ベクトル インデックスに埋め込まれた画像を取り込みます。
リアルタイムのマルチモーダル検索を実行できるようになりました。
コンテキスト検索を実行する
このセクションでは、テキストまたは画像のクエリに基づいたコンテキスト検索の結果を示します。
まずは文字入力による画像検索を行ってみましょう。次の例では、「ドリンクウェア グラス」というテキスト入力を使用し、それを検索エンジンに送信して、類似のアイテムを検索します。
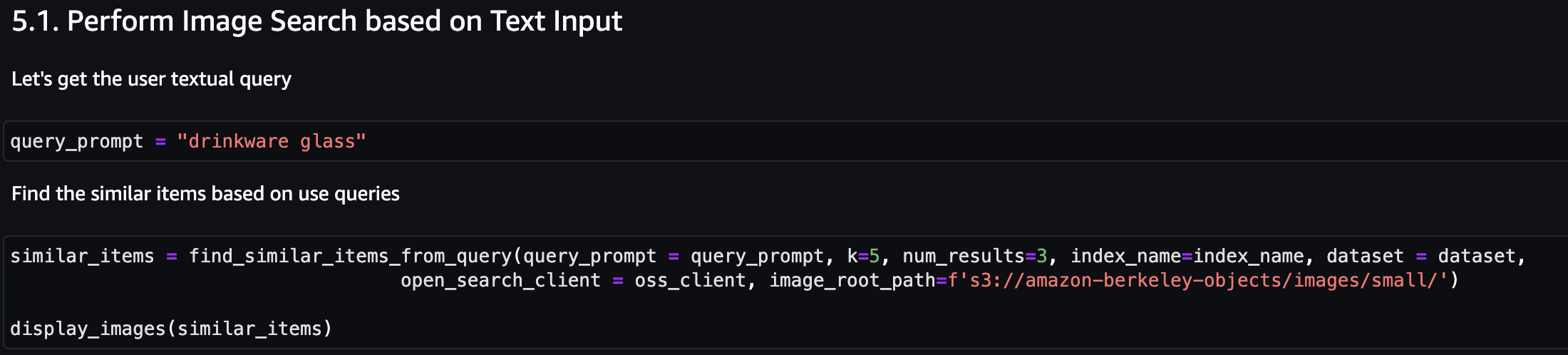
次のスクリーンショットは結果を示しています。

それでは、簡単なイメージに基づいて結果を見てみましょう。入力画像はベクトル埋め込みに変換され、類似性検索に基づいてモデルは結果を返します。
任意の画像を使用できますが、次の例では、アイテム ID に基づいてデータセットからランダムな画像を使用します (例: item_id = “B07JCDQWM6”)、この画像を検索エンジンに送信して、類似のアイテムを検索します。

次のスクリーンショットは結果を示しています。

クリーンアップ
今後の料金発生を回避するには、このソリューションで使用されているリソースを削除してください。これを行うには、ノートブックのクリーンアップ セクションを実行します。

まとめ
この投稿では、Amazon Bedrock で Amazon Titan マルチモーダル埋め込みモデルを使用して強力なコンテキスト検索アプリケーションを構築するチュートリアルを紹介しました。特に、商品リスト検索アプリケーションの例をデモしました。エンベディング モデルにより、画像やテキスト データから情報を効率的かつ正確に検出できるようになり、それによって関連アイテムを検索する際のユーザー エクスペリエンスが向上する様子がわかりました。
Amazon Titan マルチモーダル埋め込みは、より正確でコンテキストに関連したマルチモーダル検索、推奨、パーソナライゼーションのエクスペリエンスをエンドユーザーに提供するのに役立ちます。たとえば、何億もの画像を保有するストックフォト会社は、このモデルを使用して検索機能を強化できるため、ユーザーはフレーズ、画像、または画像とテキストの組み合わせを使用して画像を検索できます。
Amazon Bedrock の Amazon Titan マルチモーダル埋め込みモデルが、米国東部 (バージニア北部) と米国西部 (オレゴン) の AWS リージョンで利用できるようになりました。詳細については、を参照してください。 Amazon Titan Image Generator、マルチモーダル埋め込み、テキストモデルが Amazon Bedrock で利用可能になりました Amazon タイタンの商品ページ、 そしてその Amazon Bedrock ユーザーガイド。 Amazon Bedrock で Amazon Titan マルチモーダル埋め込みを開始するには、次のサイトにアクセスしてください。 Amazon Bedrock コンソール.
Amazon Titan マルチモーダル埋め込みモデルを使用して構築を開始します。 アマゾンの岩盤 。
著者について
 サンディープ・シン アマゾン ウェブ サービスのシニア ジェネレーティブ AI データ サイエンティストで、ジェネレーティブ AI による企業のイノベーションを支援しています。専門は生成 AI、人工知能、機械学習、システム設計です。彼は、さまざまな業界の複雑なビジネス問題を解決し、効率と拡張性を最適化する、最先端の AI/ML を活用したソリューションの開発に情熱を注いでいます。
サンディープ・シン アマゾン ウェブ サービスのシニア ジェネレーティブ AI データ サイエンティストで、ジェネレーティブ AI による企業のイノベーションを支援しています。専門は生成 AI、人工知能、機械学習、システム設計です。彼は、さまざまな業界の複雑なビジネス問題を解決し、効率と拡張性を最適化する、最先端の AI/ML を活用したソリューションの開発に情熱を注いでいます。
 マニカヌジャ テクノロジーリード – ジェネレーティブ AI スペシャリストであり、『Applied Machine Learning and High Performance Computing on AWS』の著者であり、女性製造教育財団理事会のメンバーでもあります。彼女は、コンピューター ビジョン、自然言語処理、生成 AI などのさまざまな分野で機械学習プロジェクトを主導しています。彼女は、AWS re:Invent、Women in Manufacturing West、YouTube ウェビナー、GHC 23 などの社内および社外のカンファレンスで講演しています。自由時間には、ビーチに沿って長距離ランニングをするのが好きです。
マニカヌジャ テクノロジーリード – ジェネレーティブ AI スペシャリストであり、『Applied Machine Learning and High Performance Computing on AWS』の著者であり、女性製造教育財団理事会のメンバーでもあります。彼女は、コンピューター ビジョン、自然言語処理、生成 AI などのさまざまな分野で機械学習プロジェクトを主導しています。彼女は、AWS re:Invent、Women in Manufacturing West、YouTube ウェビナー、GHC 23 などの社内および社外のカンファレンスで講演しています。自由時間には、ビーチに沿って長距離ランニングをするのが好きです。
 ルピンダー・グレワル AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。彼は現在、Amazon SageMaker でのモデルと MLOps の提供に重点を置いています。この役職に就く前は、モデルの構築とホスティングを行う機械学習エンジニアとして働いていました。仕事以外では、テニスや山道でのサイクリングを楽しんでいます。
ルピンダー・グレワル AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。彼は現在、Amazon SageMaker でのモデルと MLOps の提供に重点を置いています。この役職に就く前は、モデルの構築とホスティングを行う機械学習エンジニアとして働いていました。仕事以外では、テニスや山道でのサイクリングを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

