別の日には、別の古典的なアルゴリズムが登場しました。 k-最も近い隣人。 以下のような 単純ベイズ分類器、これは分類問題を解決するためのかなり単純な方法です。 このアルゴリズムは直感的であり、トレーニング時間も非常に短いため、機械学習のキャリアを始めたばかりのときに学習するのに最適です。 そうは言っても、特に大規模なデータセットの場合、予測を行うのは非常に時間がかかります。 多くの特徴を持つデータセットのパフォーマンスも、圧倒的なものではない可能性があります。 次元の呪い.
この記事では、
- 方法 k- 最近傍分類器が機能する
- なぜこのように設計されたのか
- なぜこのような深刻な欠点があるのか、そしてもちろん
- NumPy を使用して Python で実装する方法。
scikit learn-conform の方法で分類子を実装するので、私の記事をチェックすることも価値があります。 独自のカスタム scikit-learn 回帰を構築する. ただし、scikit-learn のオーバーヘッドは非常に小さいため、とにかく従うことができるはずです。
あなたはでコードを見つけることができます 私のGithub.
この分類子の主なアイデアは驚くほどシンプルです。 これは、分類に関する基本的な質問から直接導き出されます。
データ点 x が与えられたとき、x があるクラス c に属する確率は?
数学の言語では、条件付き確率を検索します。 p(c|x)。 ながら 単純ベイズ分類器 いくつかの仮定を使用してこの確率を直接モデル化しようとしますが、この確率を計算する別の直観的な方法、つまり確率の頻度主義的な見方があります。
確率についての素朴な見方
わかりましたが、これは何を意味しますか? 次の簡単な例を考えてみましょう。あなたは XNUMX 面のサイコロを振り、XNUMX の目が出る確率を計算したいとします。 p(ロール番号6)。 これを行う方法? さて、サイコロを転がします n 回を繰り返し、どれくらいの頻度で XNUMX が表示されたかを書き留めます。 XNUMXという数字を見たことがあるなら k 何度も、あなたは XNUMX が出る確率は 周りに k/n。 ここには新しいものや派手なものは何もありませんね?
ここで、たとえば条件付き確率を計算したいと想像してください。
p(6 を出ます | 偶数を出ます)
必要ない ベイズの定理 これを解決するために。 もう一度サイコロを振って、奇数の出目はすべて無視してください。 それが条件付けの機能であり、結果をフィルタリングします。 サイコロを振ったら n 何度も見た m 偶数と k そのうちの XNUMX があった場合、上記の確率は次のとおりです。 周りに k/m k/n.
k最近傍の動機付け
問題に戻りましょう。 計算したい p(c|x) どこ x は特徴を含むベクトルであり、 c あるクラスです。 金型の例のように、
- 多くのデータポイントが必要ですが、
- 特徴のあるものを除外する x &
- これらのデータ ポイントがクラスに属する頻度を確認する c.
相対頻度は確率の推測です p(c|x).
ここに問題がありますか?
通常、同じ特徴を持つデータ ポイントはそれほど多くありません。 多くの場合、XNUMX つだけ、場合によっては XNUMX つだけです。 たとえば、人の身長 (cm 単位) と体重 (kg 単位) という XNUMX つの特徴を持つデータセットを想像してください。 ラベルは、 男性 or 女性。 したがって、 x=(x?, x?) どこ x? は高さであり、 x? は重量であり、 c 男性と女性の値を取ることができます。 いくつかのダミーデータを見てみましょう。
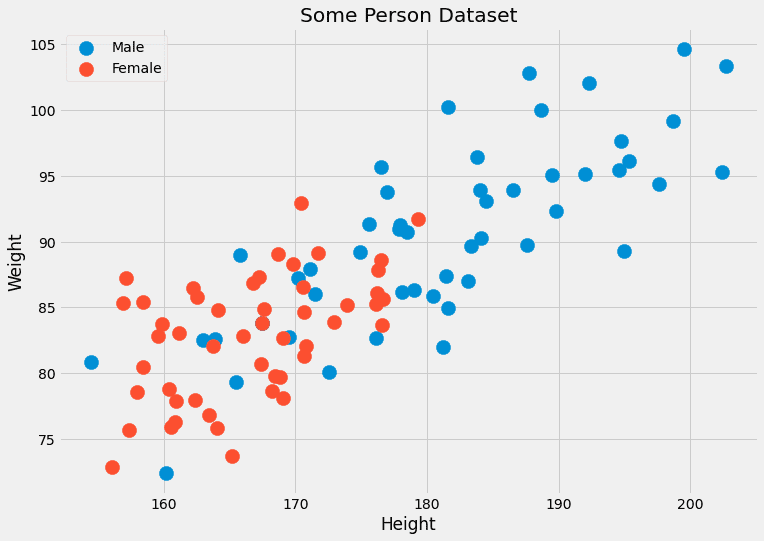
著者による画像。
これら XNUMX つの特徴は連続しているため、データ ポイントが XNUMX つ、ましてや数百ある可能性は無視できます。
別の問題: (190.1, 85.2) など、これまでに見たことのない特徴を持つデータ ポイントの性別を予測したい場合はどうなるでしょうか? それが実際の予測のすべてです。 このような単純なアプローチが機能しないのはこのためです。 なんと k-最近傍アルゴリズムは代わりに次のことを行います。
確率を近似しようとします p(c|x) を持つデータ ポイントではありません。 正確に 機能 x, ただし、次のような特徴を持つデータ ポイントを使用します。 x.
ある意味、それほど厳密ではありません。 身長=182.4、体重=92.6の人がたくさんいるのを待って性別を確認するのではなく、 k-最も近い隣人は人々を考慮することを可能にします 閉じる こういった特徴を持つことに。 の k アルゴリズムで考慮される人の数は、 ハイパーパラメータ.
これらは、私たち、またはグリッド検索などのハイパーパラメーター最適化アルゴリズムが選択する必要があるパラメーターです。 これらは学習アルゴリズムによって直接最適化されるわけではありません。
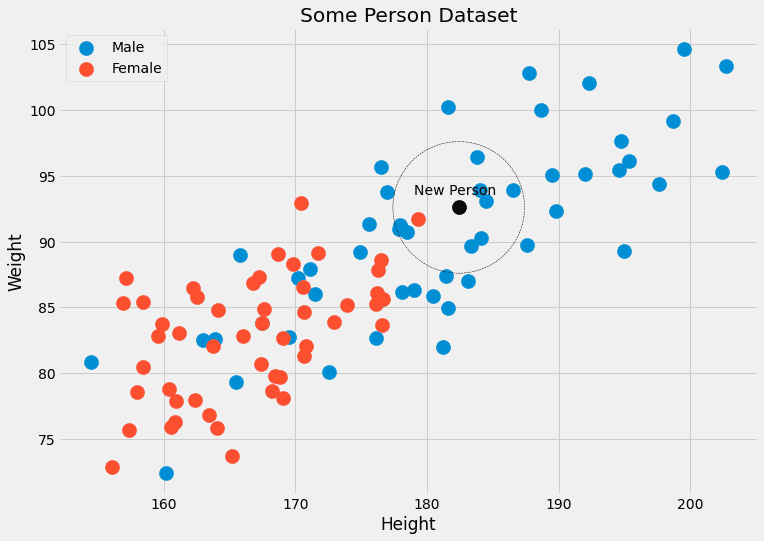
著者による画像。
アルゴリズム
アルゴリズムを説明するために必要なものはすべて揃っています。
トレーニング:
- 整理します トレーニングデータを何らかの方法で保存します。 予測時間中、この順序により、 k 任意のデータ ポイントに最も近いポイント x.
- それはもうそれだけです! 😉
予測:
- 新しいデータポイントの場合 x、 を見つける k 最も近い隣人 組織化されたトレーニングデータの中で。
- 集計 これらのラベル k 隣人。
- ラベル/確率を出力します。
埋めなければならない空白がたくさんあるため、今のところこれを実装することはできません。
- 組織化とはどういう意味ですか?
- 近接性をどのように測定するのでしょうか?
- 集計方法は?
の値に加えて、 k、これらはすべて私たちが選択できるものであり、異なる決定によって異なるアルゴリズムが与えられます。 簡単にして、次のような質問に答えてみましょう。
- 整理 = トレーニング データセットをそのまま保存するだけ
- 近接度 = ユークリッド距離
- 集計 = 平均化
これには例が必要です。 もう一度人物データで写真を確認してみましょう。
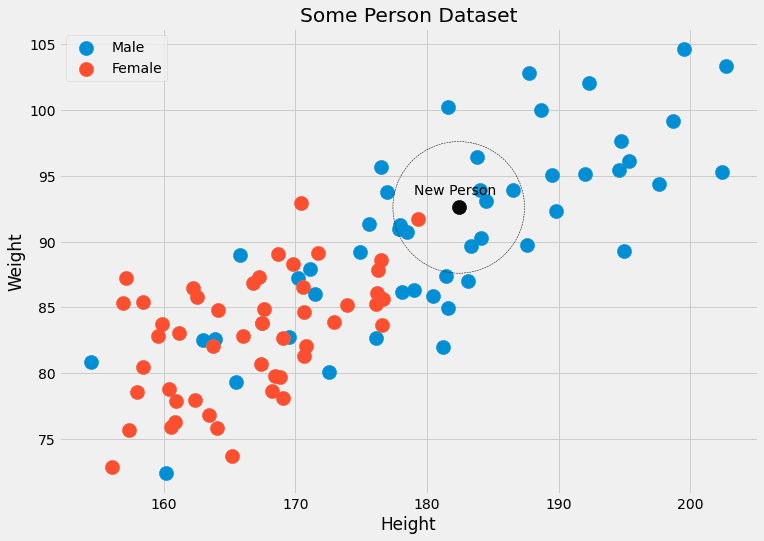
私たちはそれを見ることができます k= 黒のデータ ポイントに最も近い 5 つのデータ ポイントには、4 つの男性ラベルと 4 つの女性ラベルがあります。 したがって、黒い点に属する人は、実際には 5/80=1% が男性、5/20=XNUMX% が女性であると出力できます。 出力として単一のクラスを選択する場合は、male を返します。 問題ない!
それでは、実装してみましょう。
最も難しいのは、ある点に最も近い点を見つけることです。
クイック入門書
Python でこれを行う方法の小さな例を見てみましょう。 から始めます
import numpy as np features = np.array([[1, 2], [3, 4], [1, 3], [0, 2]])
labels = np.array([0, 0, 1, 1]) new_point = np.array([1, 4])
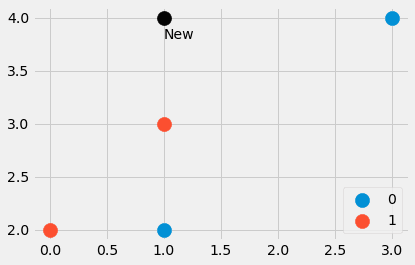
著者による画像。
0 つのデータ ポイントと別のポイントで構成される小さなデータセットを作成しました。 最も近いポイントはどれですか? そして、新しいポイントには 1 または XNUMX のラベルを付ける必要がありますか? 調べてみましょう。 入力する
distances = ((features - new_point)**2).sum(axis=1)4 つの値 distances=[4, 1, 5, XNUMX] が得られます。 二乗 からのユークリッド距離 new_point 他のすべてのポイントに features 。 甘い! ポイント XNUMX が最も近く、次にポイント XNUMX と XNUMX が続くことがわかります。 XNUMX 番目のポイントは最も遠いです。
配列 [4, 4, 1, 5] から最も近い点を抽出するにはどうすればよいでしょうか? あ distances.argsort() 助けます。 結果は [2, 0, 1, 3] で、インデックス 2 のデータ ポイントが最も小さく (出力ポイント番号 0)、次にインデックス 1 のポイント、次にインデックス 3 のポイント、そして最後にインデックスのポイントであることがわかります。 XNUMXが一番大きいです。
注意してください argsort 最初の4を入れてください distances 4 番目の前 XNUMX. 並べ替えアルゴリズムによっては、これが逆の場合もありますが、この紹介記事ではこれらの詳細には触れません。
たとえば、XNUMX つの最も近い近傍が必要な場合、次のようにしてそれらを取得するにはどうすればよいでしょうか。
distances.argsort()[:3]そしてラベルはこれらの最も近い点に対応します。
labels[distances.argsort()[:3]][1, 0, 0] が得られます。1 は (1, 4) に最も近い点のラベルであり、XNUMX は次に近い XNUMX つの点に属するラベルです。
必要なのはこれだけです。実際の取引に移りましょう。
最終的なコード
コードについてはよく知っているはずです。 唯一の新しい機能は、 np.bincount ラベルの出現をカウントします。 実装したことに注意してください predict_proba 最初にメソッドを使用して確率を計算します。 方法 predict このメソッドを呼び出して、最も高い確率でインデックス (=class) を返します。 argmax関数。 クラスは0からのクラスを待っています C-1、ここで C クラス数です。
免責事項: このコードは最適化されておらず、教育目的のみを目的としています。
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted class KNNClassifier(BaseEstimator, ClassifierMixin): def __init__(self, k=3): self.k = k def fit(self, X, y): X, y = check_X_y(X, y) self.X_ = np.copy(X) self.y_ = np.copy(y) self.n_classes_ = self.y_.max() + 1 return self def predict_proba(self, X): check_is_fitted(self) X = check_array(X) res = [] for x in X: distances = ((self.X_ - x)**2).sum(axis=1) smallest_distances = distances.argsort()[:self.k] closest_labels = self.y_[smallest_distances] count_labels = np.bincount( closest_labels, minlength=self.n_classes_ ) res.append(count_labels / count_labels.sum()) return np.array(res) def predict(self, X): check_is_fitted(self) X = check_array(X) res = self.predict_proba(X) return res.argmax(axis=1)以上です! 小さなテストを実行して、それが scikit-learn と一致するかどうかを確認できます。 k- 最近傍分類子。
コードのテスト
テスト用に別の小さなデータセットを作成しましょう。
from sklearn.datasets import make_blobs
import numpy as np X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)
X = np.vstack([X, np.array([[2, 4], [-1, 4], [1, 6]])])
y = np.append(y, [2, 1, 0])それは次のようになります。
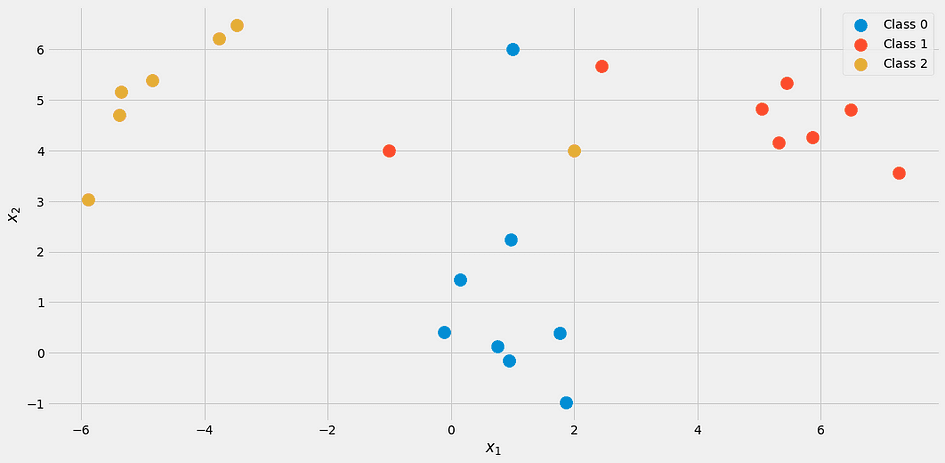
著者による画像。
分類器を使用して k = 3
my_knn = KNNClassifier(k=3)
my_knn.fit(X, y) my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])我々は得る
array([[1. , 0. , 0. ], [0.33333333, 0.33333333, 0.33333333], [0. , 0.66666667, 0.33333333]])次のように出力を読み取ります。 最初のポイントは 100% がクラス 1 に属し、33 番目のポイントは各クラスに均等に 67% 存在し、2 番目のポイントは約 33% がクラス 3、XNUMX% がクラス XNUMX です。
具体的なラベルが必要な場合は、試してみてください
my_knn.predict([[0, 1], [0, 5], [3, 4]])[0, 0, 1] を出力します。 同点の場合、実装したモデルは下位クラスを出力するため、点 (0, 5) はクラス 0 に属するものとして分類されることに注意してください。
画像を確認してみると分かります。 しかし、scikit-learn の助けを借りて安心しましょう。
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y) my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])結果:
array([[1. , 0. , 0. ], [0.33333333, 0.33333333, 0.33333333], [0. , 0.66666667, 0.33333333]])ふう! すべてが良さそうです。 美しいという理由だけで、アルゴリズムの決定境界を確認してみましょう。
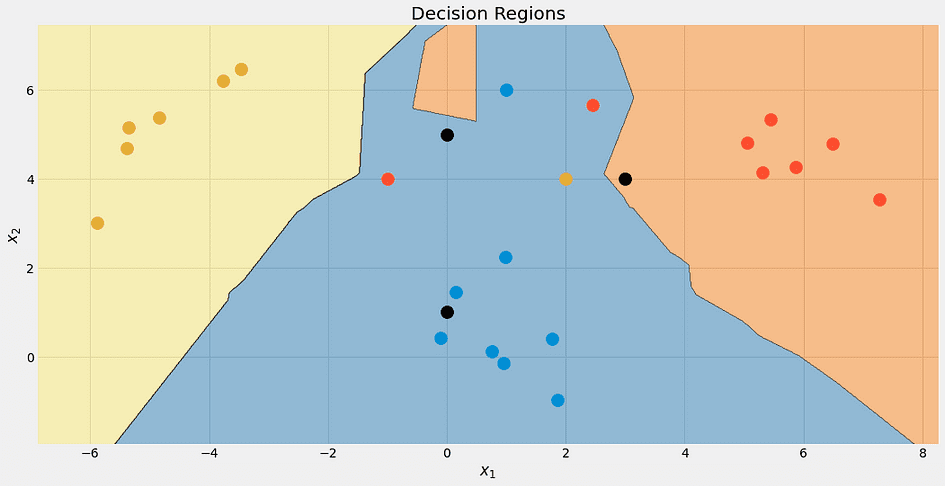
著者による画像。
繰り返しますが、上部の黒い点は 100% 青ではありません。 33% は青、赤、黄ですが、アルゴリズムは最も低いクラスである青を決定的に決定します。
のさまざまな値の決定境界を確認することもできます。 k.
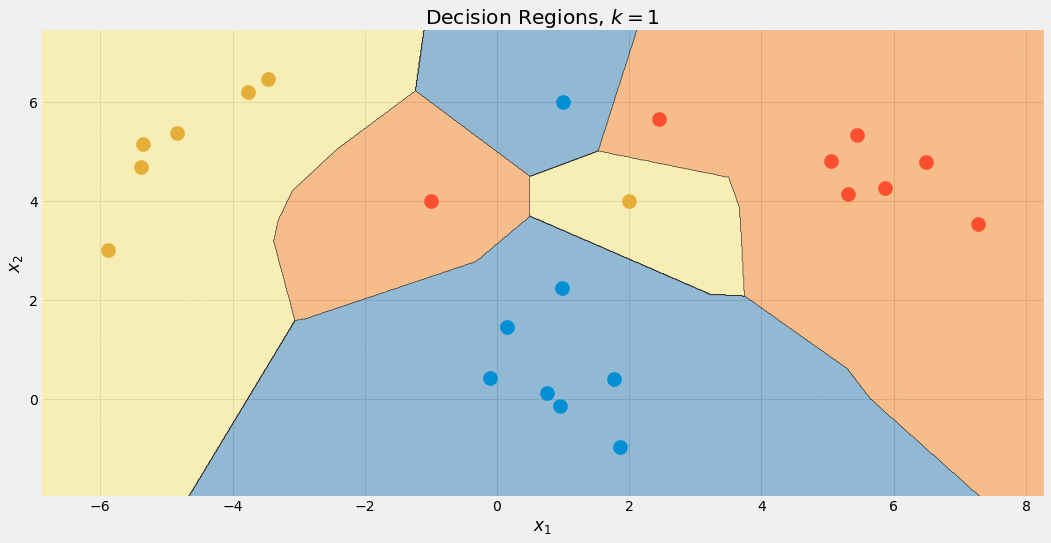
著者による画像。
このクラスの優遇措置により、最終的には青い領域が大きくなることに注意してください。 についてもそれが分かります k=1 境界がめちゃくちゃです: モデルは 過適合。 極限の向こう側では、 k はデータセットのサイズと同じくらい大きく、すべてのポイントが集計ステップに使用されます。 したがって、各データ ポイントは同じ予測、つまり多数派クラスを取得します。 モデルは アンダーフィッティング この場合。 スイート スポットはその中間にあり、ハイパーパラメータ最適化手法を使用して見つけることができます。
最後に進む前に、このアルゴリズムにどのような問題があるかを見てみましょう。
問題は次のとおりです。
- 最近傍を見つけるには、特に単純な実装では非常に時間がかかります。 新しいデータ ポイントのクラスを予測したい場合は、データセット内の他のすべてのポイントと比較してチェックする必要がありますが、これには時間がかかります。 高度なデータ構造を使用してデータを整理するより良い方法がありますが、問題は依然として残ります。
- 問題 1 に続く: 通常、より高速で強力なコンピューターでモデルをトレーニングし、その後、そのモデルを弱いコンピューターにデプロイできます。 たとえば、ディープラーニングについて考えてみましょう。 しかし、のために k-最近隣、トレーニング時間は簡単ですが、予測時間中に重い作業が行われますが、これは私たちが望んでいることではありません。
- 最も近い隣人がまったく近くにいない場合はどうなりますか? それでは、それらは何の意味もありません。 これは特徴の数が少ないデータセットではすでに発生する可能性がありますが、特徴がさらに多くなると、この問題が発生する可能性が大幅に増加します。 これは人々が次元の呪いと呼ぶものでもあります。 素晴らしい視覚化は次の場所にあります。 キャシー・コジルコフのこの投稿.
特に問題 2 のせいで、 k- 最近傍分類子があまりにも頻繁に使用される。 これは知っておくべき素晴らしいアルゴリズムであり、小さなデータセットにも使用できますが、それは悪いことではありません。 しかし、数千の特徴を持つ数百万のデータ ポイントがある場合、事態は困難になります。
この記事では、 k-最近傍分類器が機能する理由と、その設計が理にかなっている理由。 データポイントの確率を推定しようとします x クラスに所属している c 可能な限り最も近いデータポイントを使用して、 x。 これは非常に自然なアプローチであるため、このアルゴリズムは通常、機械学習コースの最初に教えられます。
構築するのは非常に簡単であることに注意してください。 k-最も近い隣人 リグレッサー、 それも。 クラスの出現を数える代わりに、最も近いクラスのラベルを平均して予測を取得します。 これは自分で実装することもできますが、ほんの小さな変更です。
次に、scikit-learn API を模倣して、それを簡単な方法で実装しました。 これは、この推定器を scikit-learn のパイプラインやグリッド検索でも使用できることを意味します。 ハイパーパラメータもあるので、これは大きな利点です。 k グリッド検索、ランダム検索、またはベイジアン最適化を使用して最適化できます。
ただし、このアルゴリズムにはいくつかの重大な問題があります。 これは大規模なデータセットには適しておらず、予測を行うために弱いマシンにデプロイすることはできません。 次元の呪いの影響を受けやすいことと合わせて、これは理論的には優れたアルゴリズムですが、小規模なデータ セットにのみ使用できます。
ロバート・キューブラー博士 METRO.digital のデータ サイエンティストであり、Towards Data Science の著者です。
元の。 許可を得て転載。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/06/theory-practice-building-knearest-neighbors-classifier.html?utm_source=rss&utm_medium=rss&utm_campaign=from-theory-to-practice-building-a-k-nearest-neighbors-classifier

