光学式文字認識 (OCR) ソフトウェアは、PDF、画像、紙のドキュメントなどの編集不可能なドキュメント形式を、編集および検索可能な機械可読形式に変換するのに役立ちます。
OCR アプリケーションは、PDF や画像からテキストをキャプチャし、そのテキストを Word、Excel、またはプレーン テキスト ファイルなどの編集可能な形式に変換するためによく使用されます。 OCR は、ファイルやドキュメントをデジタル化して検索可能にするためにも使用されます。
OCR AI/ML 機能を活用するソフトウェアは、スキャンしたドキュメント/画像からのデータ キャプチャの自動化にも役立ちます。 AI ベースの OCR は、組織のワークフローに適合する便利で編集可能な形式でデータをデジタル化できます。
スキャンと処理 請求書、領収書、貴重なデータの画像などの文書は、従来、エラーや遅延を伴う手動プロセスでした。 OCR ソフトウェア ソリューションは、企業がデータ入力や手動による検証/検証に費やす時間とリソースを節約するのに役立ちます。
ますます多くの組織が自動化しています ドキュメント処理ワークフロー ペーパーレスに移行し、収益を改善するクラウドベースのデジタルソリューションを活用します。
最高のOCRソフトウェアのいくつかを見てみましょう。また、いくつかの無料のOCRソフトウェアもチェックしてください。
Nanonet の AI ベースの OCR ソフトウェアを使用して、手動データ入力を自動化します。 ドキュメントからデータを即座にキャプチャし、データ ワークフローを自動化します。 ターンアラウンドタイムを短縮し、手作業を排除します。

OCRとは何ですか?OCRソフトウェアは何をしますか?
OCR or 光学式文字認識 は、スキャンされたドキュメント、写真、または画像内のテキストを識別および認識するテクノロジーです。 OCRソフトウェアは、このテクノロジーを活用して PDFからデータを抽出する または、スキャンしたドキュメントを機械可読テキストデータに変換して、さらに処理するために編集および保存することができます。 のために OCRに関する詳細な説明 そしてそのユースケースはこれを参照しています ガイド.
OCRは、次のような他のさまざまなユースケースでも使用されます。 PDFからテーブルを抽出する, 画像からテキストを抽出する or PDFからテキストを抽出する または他の編集不可能なフォーマット。
現在、OCR ソフトウェアは、自動データ入力、パターン認識、テキスト読み上げサービス、検索エンジン用のドキュメントのインデックス作成、コグニティブ コンピューティング、テキスト マイニング、主要データ、機械翻訳など、さまざまなアプリケーションに使用されています。 これらのツールは、スキャンしたドキュメントを変換できます。 PDFまたは画像タイプをxmlに、xlsx または csv ファイル。
あなたのビジネスに最適なOCRソフトウェア
市場で入手可能な最高のOCRソフトウェアのいくつかを見てみましょう。
1. ナノネット
Nanonetsは、自動化するAIベースのOCRソフトウェアです。 データ収集 for 請求書のインテリジェントなドキュメント処理、領収書、IDカードなど。 Nanonetsは高度なOCRを使用し、 機械学習画像処理、および非構造化データから関連情報を抽出するためのディープラーニング。 高速、正確、使いやすく、ユーザーはカスタムOCRモデルを最初から作成でき、Zapierとの統合がうまく行われています。 ドキュメントをデジタル化し、データフィールドを抽出し、シンプルで直感的なインターフェースのAPIを介して日常のアプリと統合します。
NanonetsはOCRソフトウェアとしてどのように際立っていますか?
長所:
- 近代的なUI
- 大量のドキュメントを処理します
- 合理的な価格
- 使いやすさ
- ゼロショットまたはゼロトレーニングデータ抽出
- データの認知的キャプチャ –最小限の介入で
- 開発者の社内チームは必要ありません
- アルゴリズム/モデルはトレーニング/再トレーニングできます
- 優れたドキュメントとサポート
- 多くのカスタマイズオプション
- 統合オプションの幅広い選択肢
- 英語以外または複数の言語で動作します
- 複数の会計ソフトウェアとのシームレスな双方向統合
- 開発者向けの優れたOCRAPI
短所:
- テーブルキャプチャUIが改善される可能性があります
Nanonetsの事前トレーニング済みOCRエクストラクタまたは あなた自身のものをつくる カスタムOCRモデル。 あなたもすることができます デモを予約する OCRの詳細については ユースケース!

2. ABBYY フレキシカプチャー
FlexiCaptureは、安定したスケーラブルなドキュメントイメージングおよびデータ抽出ソフトウェアであり、あらゆる構造、言語、またはコンテンツのドキュメントを、使用可能でアクセス可能なビジネス対応データに自動的に変換します。
長所:
- 画像を非常によく認識します
- ハードコピーの結果をシステムに簡単に保存できます
- ERPシステムとうまく統合
- ドキュメントからのデータ抽出を(ある程度まで)自動化します
短所:
- 初期設定は困難で複雑になる可能性があります
- 請求書の自動処理 設定されていません
- 既製のテンプレートはありません
- カスタマイズが難しい
- 利用可能なリソースがありません
- RPAソリューションとの統合が改善される可能性があります
- 低解像度の画像/ドキュメントでの低精度
- 特定のセクションでエラーが発生した場合でも、バッチ検証は保留されます
- スキップする必要があるアイテムについても、広告申込情報のエラーメッセージがポップアップ表示されます
- オンプレミスバージョンではRESTfulAPIは使用できません
- ではない Mac OCR ソフトウェア
3. ABBYY ファインリーダー
ABBYYファインリーダー PDFはOCRです PDFファイル編集をサポートするソフトウェア。 このプログラムでは、画像ドキュメントを編集可能な電子形式に変換できます。
長所:
- 手動修正用のキーボード対応のOCRエディター
- 非常にクリアなインターフェース
- 複数の形式へのエクスポート
- 独自のドキュメント比較機能
短所:
- 高速検索のための全文索引付けが不足している
- 学習曲線が必要
- 価格設定は法外なものになる可能性があります
- ドキュメントの変更履歴を表示できない
- 複数のファイルをXNUMXつにマージすることはできません
- 後処理が必要な場合があります
- UIは最初は圧倒される可能性があります
- 大きなファイルの処理が遅い
のOCRソフトウェアが必要 画像からテキストへの抽出 or PDFデータ抽出? 変換しようとしています PDFからExcelへまたは PDFからテキストへ? 動作中のナノネットをチェックしてください!
4. Kofax オムニページ
Omnipageは強力です PDF OCR 大量の企業OCRタスクの自動化を処理できるソフトウェア。 このツールは、テーブル抽出、ラインアイテムマッチング、およびスマート抽出を専門としています。
長所:
- 画像を強調するための強力なツールセットがあります
- 高精度
短所:
- UIは直感的ではありません
- APオートメーションの構成は簡単ではありません
- API統合を改善できます
- Kofax の代替
5. IBM データキャップ
Datacapは、ビジネスドキュメントのキャプチャ、認識、分類を合理化して、ビジネスドキュメントから重要な情報を抽出します。 Datacapには、強力なOCRエンジン、複数の機能、およびカスタマイズ可能なルールがあります。 スキャナー、モバイルデバイス、多機能周辺機器、ファックスなど、複数のチャネルで機能します。
長所:
- データキャプチャで複雑なアプリケーションを構成します
- スキャンメカニズム
- 使いやすさ
短所:
- オンラインサポートはほとんどありません
- UIはより直感的になる可能性があります
- セットアップが面倒な場合があります
- 遅く
- カスタマイズされたフローの作成は簡単ではありません
- バッチコミットには時間がかかります
使い始める 自動化のためのナノネット。 さまざまなOCRモデルを試してみるか デモをリクエストする 。 詳細 Nanonetsのユースケースを製品にどのように適用できるか。
6. GoogleドキュメントAI
Google Cloud AIスイートのソリューションのXNUMXつ、 AIを文書化する (資料)です。 文書処理 機械学習を使用してデータを自動的に分類、抽出、強化し、ドキュメント内の洞察を引き出すコンソール。
長所:
- セットアップが簡単
- 他のGoogleサービスと非常によく統合します
- 情報の保存
- 速度
短所:
- AIモジュールには適切なドキュメントがありません
- 既存のモジュールとライブラリのカスタマイズは難しい
- Pythonやその他のコーディング言語には適していません
- 古いAPIドキュメント
- 高価な
- ハイブリッドクラウドの展開には適していません
- カスタムAIアルゴリズムを必要とするユースケースには適していません
AWS テキストラクト 機械学習とOCRを使用して、スキャンしたドキュメントからテキストやその他のデータを自動的に抽出します。 また、フォームやテーブルからデータを識別、理解、抽出するためにも使用されます。 詳細については、こちらをご覧ください AWSTextractの詳細な内訳.
長所:
- 従量課金制
- 使いやすさ
短所:
- 訓練できません
- さまざまな精度
- 手書き文書用ではありません
したい PDFからデータをスクレイピング 文書、 PDFテーブルをExcelに変換する or テーブル抽出を自動化する? Nanonetsをチェックしてください PDFスクレーパー or PDFパーサー PDFデータをスクレイプするまたは PDFを解析する 大規模に!
8. ドパーサー
Docparser はクラウドベースです 文書処理 ビジネスの価値の低いタスクやワークフローを自動化できる OCR ソフトウェア。
長所:
- 簡単なセットアップ
- ザピアの統合
短所:
- Webhookが失敗することがあります
- 解析ルールを理解するには、ある程度のトレーニングが必要です
- テンプレートが足りない
- ゾーンOCR アプローチ–不明なテンプレートを処理できません
- UIはもっと良いかもしれません
- ページの読み込みが遅い
- ドキュメントはもっと良いかもしれません
9.アドビ アクロバットDC
アドビは、OCR機能が組み込まれた包括的なPDFエディターを提供しています。
長所:
- 安定性/互換性。
- 使いやすさ
短所:
- 高価な
- 排他的なOCRソフトウェアではありません
- システムに重い
- ハードディスク上で多くのスペースを占有します
- SharepointやDropboxなどのサービスとの統合が難しい
- AdobeCreativeCloudライセンスが必要です。
10. クリッパ
Klippaは、組織内の紙のドキュメントをデジタル化するための自動化されたドキュメント管理、処理、分類、およびデータ抽出ソリューションを提供します。
長所:
- 迅速なセットアップ
- 素晴らしいサポート
- 開発者向けの優れたAPI
- 明確で簡潔なAPIドキュメント
- 会計プログラムとうまくリンクします
- 競争力のある価格
- インテグレーション
短所:
- OCR認識が向上する可能性があります
- 限られたテンプレートのカスタマイズ
- 限定的なホワイトラベルのカスタマイズ
- 一括調整はサポートされていません
- VATが正しく表示されないことがよくあります
- アプリが頻繁にクラッシュする
- OCRモデルをトレーニングできません
- オプションがたくさんあるので、選択プロセスは簡単ではありません
ナノネット OCR API 多くの興味深いものがあります ユースケース t帽子はあなたの業績を最適化し、コストを節約し、成長を後押しすることができます。 詳細 Nanonetsのユースケースを製品にどのように適用できるか。
その他の注目すべき言及は次のとおりです。 ベリーフィ, リードアイリス, 侵害する, ロッサム & ハイパトス。 先行作品もチェックしてね ナノネットの代替品.
これは、いくつかの重要なOCRソフトウェアの機能とパラメーター全体で上記のすべてのOCRソフトウェアを簡単に比較したものです。
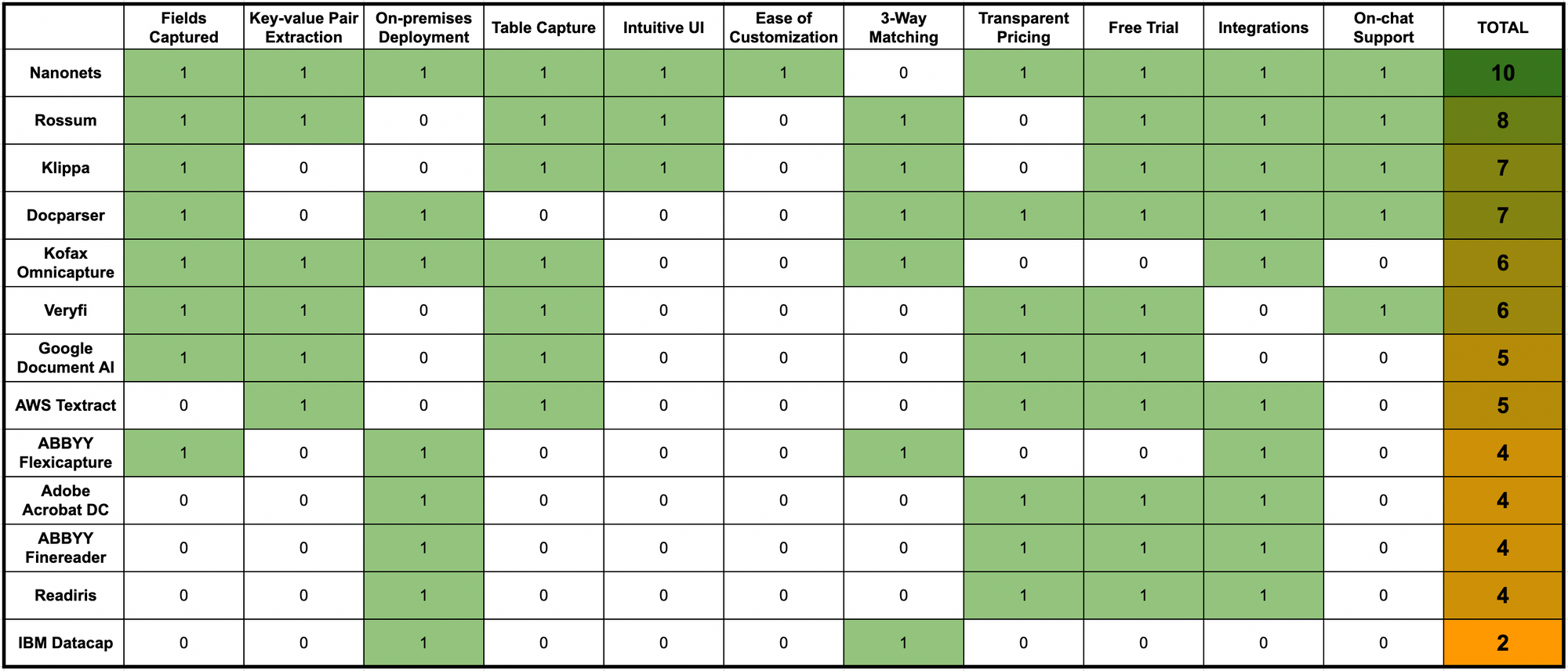
NanonetsはOCRソフトウェアとしてどのように際立っていますか?
NanonetsOCRソフトウェアは セットアップが簡単で柔軟、約 1 日かかります。 の インテリジェント自動化プラットフォーム ハンドル 非構造化データ それほど困難なく、AIも処理します 一般的なデータの制約 簡単に。 からの情報 欠陥や傷のある文書 非常に簡単に抽出されます。 処理します 複数ページの請求書 識別します 複数行のアイテム 簡単に; ほとんどのレガシーおよび最新のOCRツールが失敗するもの。 ナノネット 列ヘッダーをカスタマイズします 複雑な請求書をより効率的に処理できるようにします。 NanonetsのAIは、 高精度 最小限の手直しや修正を必要とするドキュメントを処理している間。
Nanonetを使用する利点は、精度、経験、拡張性の向上だけではありません。 Nanonetのユニークな利点を強調する8つの理由は次のとおりです。
- カスタムデータのトレーニングと操作 –そこにあるほとんどのOCRソフトウェアは、処理できるデータのタイプに非常に厳格です。 ナノネットはそのような制限に縛られません。 Nanonetsは、独自のデータを使用して、ビジネスの特定のニーズを満たすのに最適なモデルをトレーニングします。
- 使いやすく柔軟性 –特定のビジネスニーズに合わせてナノネットを適応させるのは簡単で簡単です。 カスタムOCRモデルの作成と再トレーニングから、新しいフィールドの追加と統合の処理まで、Nanonetsはすべてを処理できます。
- 継続的に学習および再トレーニング – 企業は、動的に変化する要件やニーズに直面することがよくあります。 潜在的な障害を克服するには、 Nanonets OCR ソフトウェア 新しいデータを使用してモデルを簡単に再トレーニングできます。 これにより、OCR モデルが予期せぬ変化に適応できるようになります。
- カスタマイズ、カスタマイズ、カスタマイズ – Nanonetは、テキスト/データのフィールドを好きなだけキャプチャして、任意の方法で表示できます。 キャプチャされたデータは、カスタム検証ルールを使用して、テーブルやラインアイテム、またはその他の任意の形式で表示できます。 Nanonetsはドキュメントのテンプレートに拘束されないことを常に忘れないでください!
- 後処理はほとんど必要ありません –ほとんどのOCRソフトウェアは単にデータを取得してダンプしますが、Nanonetsは関連するデータのみを抽出し、それらをインテリジェントに構造化されたフィールドに自動的に分類して、表示と理解を容易にします。 これにより、改訂と検証に費やされる多くの時間がなくなります。
- 一般的なデータの制約を簡単に処理します – Nanonetsは、ディープラーニングとオブジェクト検出の手法を活用して、他のOCRソフトウェアの中でもテキストの認識と抽出に大きな影響を与える一般的なデータの制約を克服します。 Nanonets AIは、手書きのテキスト、低解像度の画像、新しいフォントまたは筆記体のフォントとさまざまなサイズの画像、影のあるテキスト、傾斜したテキスト、ランダムな非構造化テキスト、画像ノイズ、ぼやけた画像などを認識して処理できます。 従来のOCRソフトウェアは、このような制約の下で実行する機能を備えていません。 それらは、実際のシナリオでは標準ではない非常に高いレベルの忠実度のデータを必要とします。
- 英語以外または複数の言語で動作します – Nanonets はカスタム データを使用したトレーニングに重点を置いているため、単一のモデルを構築する独自の位置にあります。 文書からテキストを抽出する 任意の言語または同時に複数の言語で。
- 開発者の社内チームは必要ありません –ビジネス要件に合わせてNanonets APIをパーソナライズするために、開発者の採用や人材の獲得について心配する必要はありません。 Nanonetsは、手間のかからない統合のために構築されました。 NanonetsをほとんどのCRM、ERP、 コンテンツサービス またはRPAソフトウェア。
無料のOCRソフトウェアはありますか?
上記のプロの最先端のOCRソリューションとは別に、ある程度の仕事をする無料のOCRソフトウェアがあります。 これらの無料ソリューションは、オープンソースのOCRエンジン(Tesseractなど)で実行され、写真、PDF、TIFF、またはスキャンされたドキュメントを編集可能なデジタルテキスト形式に変換するのに役立ちます。 手の込んだビジネスドキュメントを大規模に処理できない場合もありますが、単純なドキュメントから簡単なフォーマットでテキストを抽出するには十分です。
これらの無料のOCRソリューションは、Webベースのアプリケーション、さまざまなプラットフォームにインストールする必要のあるスタンドアロンソフトウェア、または本格的なドキュメント編集サービスの副次的な機能として提供されます。 無料のOCRソフトウェアは、手書きのドキュメント、複数列のテーブル、長い行項目、または低品質の画像/スキャンを定期的に処理できないことに注意してください。
ここにいくつかの無料があります 光学式文字認識 検討のためのツール:
2023 年 2021 月の更新: この投稿は、XNUMX 年 XNUMX 月に最初に公開されたものであり、その後、最新の調査結果とリソースで更新されています。
これがスライドです 調査結果をこの記事にまとめます。 これは 代替バージョン この記事の。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/ocr-software-best-ocr-software/

