著者による画像
探索的データ分析 (EDA) は、データ分析プロセスの中核フェーズとして機能し、データセットの内部の詳細と特性の徹底的な調査に重点を置きます。
その主な目的は、根底にあるパターンを明らかにし、データセットの構造を把握し、潜在的な異常や変数間の関係を特定することです。
EDA を実行することにより、データ専門家はデータの品質をチェックします。したがって、正確で洞察力に富んだ情報に基づいてさらなる分析が行われるようになり、後続の段階でエラーが発生する可能性が軽減されます。
それでは、次のデータ サイエンス プロジェクトで優れた EDA を実行するための基本的な手順が何であるかを一緒に理解してみましょう。
あなたもすでに次のようなフレーズを聞いたことがあると思います。
ゴミの流入、ゴミの流出
入力データの品質は、データ プロジェクトを成功させるために常に最も重要な要素です。
残念ながら、最初はほとんどのデータが土です。探索的データ分析のプロセスを通じて、ほぼ使用可能なデータセットを完全に使用可能なデータセットに変換できます。
これはデータセットを浄化するための魔法のソリューションではないことを明確にすることが重要です。それにもかかわらず、多くの EDA 戦略は、データセット内で遭遇するいくつかの典型的な問題に対処するのに効果的です。
それでは… Ayodele Oluleye の著書『Exploratory Data Analysis with Python Cookbook』によると、最も基本的な手順を学びましょう。
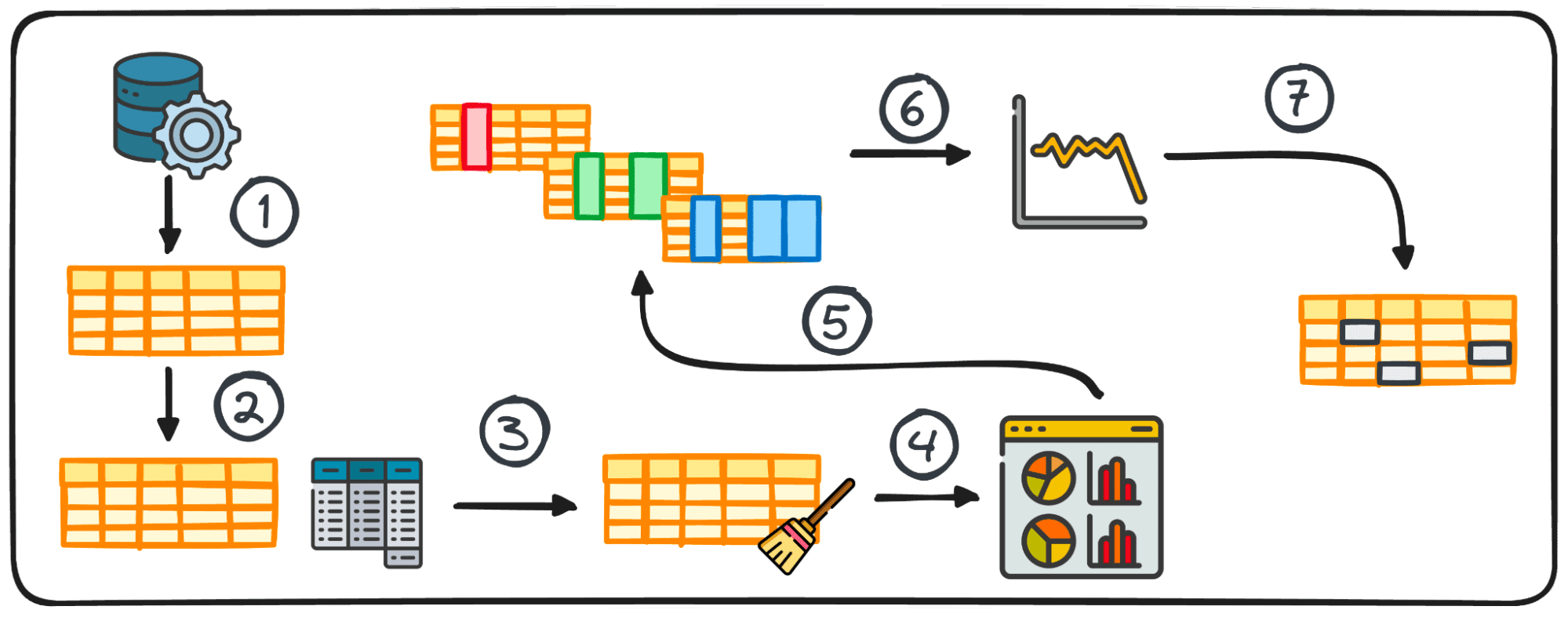
ステップ 1: データ収集
データ プロジェクトの最初のステップは、データ自体を用意することです。この最初のステップでは、その後の分析のためにさまざまなソースからデータが収集されます。
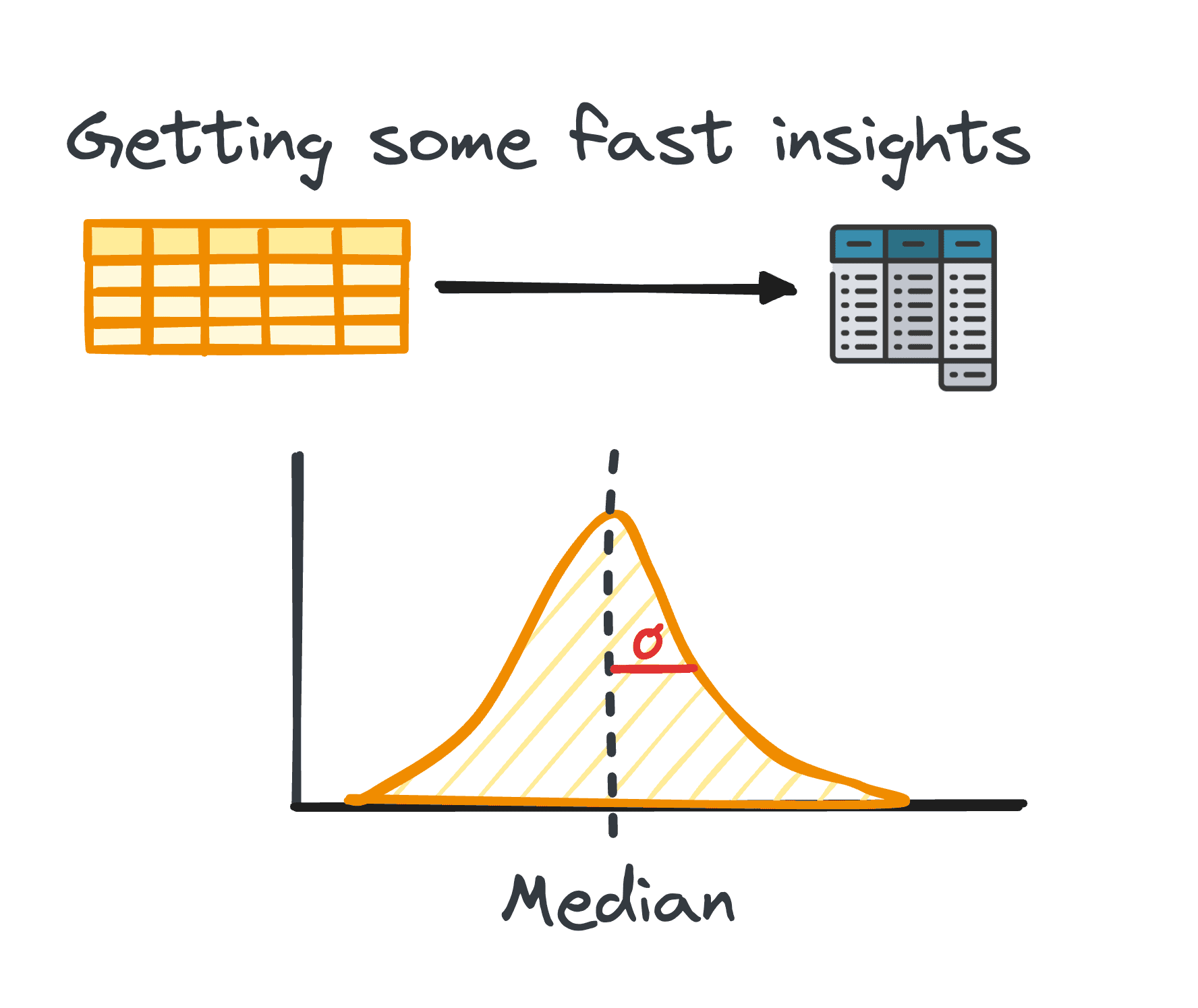
2. 概要統計
データ分析では、表形式のデータを処理することが非常に一般的です。このようなデータの分析中に、多くの場合、データのパターンと分布についての迅速な洞察を得ることが必要になります。
これらの最初の洞察は、さらなる調査と詳細な分析のベースとして機能し、概要統計として知られています。
これらは、平均、中央値、最頻値、分散、標準偏差、範囲、パーセンタイル、四分位などのメトリクスを通じてカプセル化された、データセットの分布とパターンの簡潔な概要を提供します。
著者による画像
3. EDA 用のデータの準備
通常、調査を開始する前に、さらなる分析のためにデータを準備する必要があります。データの準備には、分析のニーズに合わせて Python の pandas ライブラリを使用してデータを変換、集計、またはクリーニングすることが含まれます。
この手順はデータの構造に合わせて調整されており、グループ化、追加、結合、並べ替え、分類、重複の処理などが含まれます。
Python では、pandas ライブラリのさまざまなモジュールを通じてこのタスクの実行が容易になります。
表形式データの準備プロセスは、普遍的な方法に準拠しているわけではありません。代わりに、データの行、列、データ型、データに含まれる値など、データの特定の特性によって形成されます。
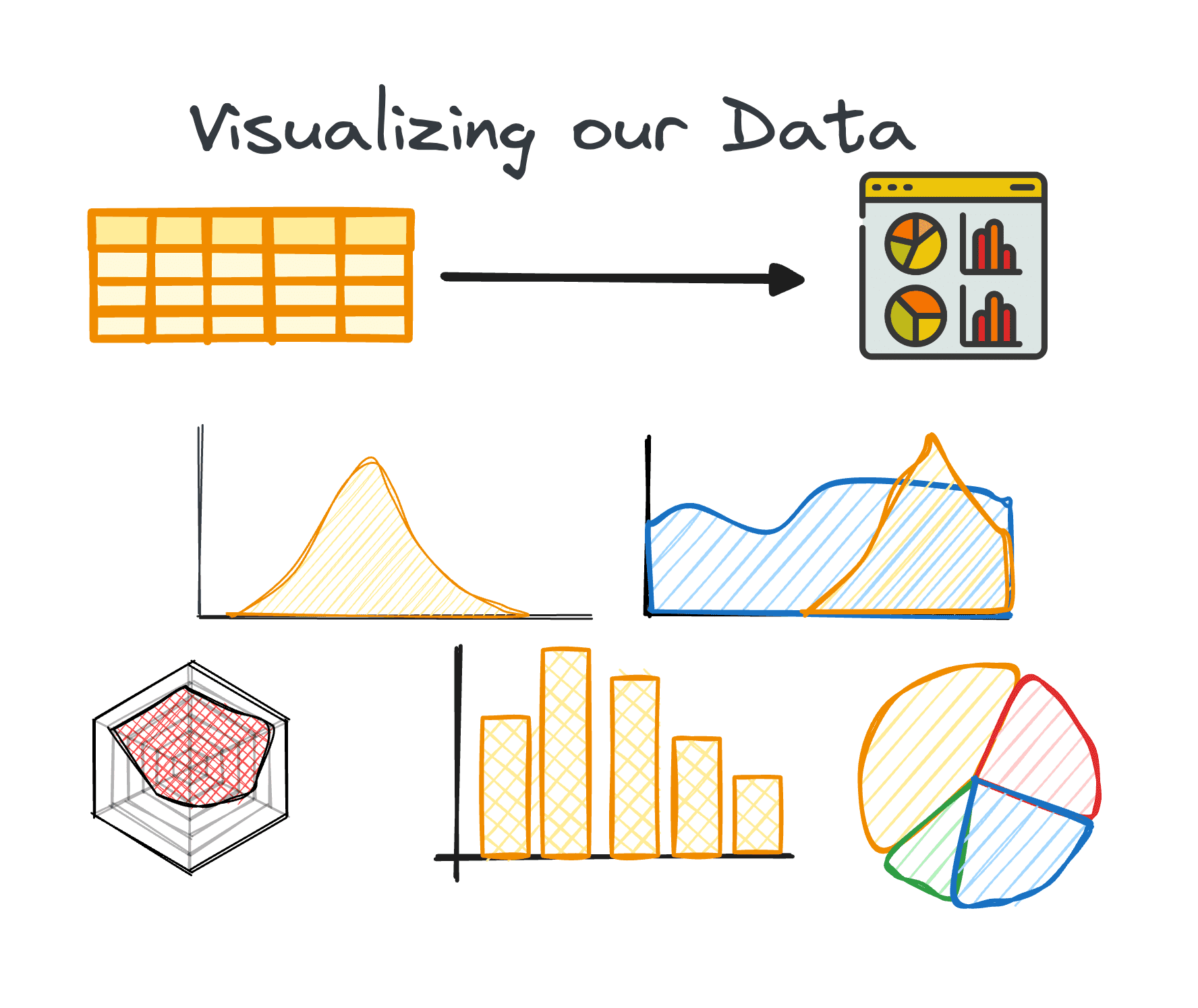
4. データの視覚化
視覚化は EDA の中核コンポーネントであり、データセット内の複雑な関係と傾向を簡単に理解できるようにします。
適切なチャートを使用すると、大きなデータセット内の傾向を特定し、隠れたパターンや外れ値を見つけることができます。 Python は、Matplotlib や Seaborn など、データ視覚化のためのさまざまなライブラリを提供します。
著者による画像
5. 変数分析の実行:
変数分析は、一変量、二変量、または多変量のいずれかになります。それらのそれぞれは、データセットの変数間の分布と相関関係についての洞察を提供します。手法は分析される変数の数に応じて異なります。
一変量
単変量解析の主な焦点は、データセット内の各変数を独自に調べることにあります。この分析中に、中央値、最頻値、最大値、範囲、外れ値などの洞察を明らかにできます。
このタイプの分析は、カテゴリ変数と数値変数の両方に適用できます。
二変量
二変量分析は、選択した 2 つの変数間の洞察を明らかにすることを目的としており、これら 2 つの変数間の分布と関係を理解することに重点を置いています。
2 つの変数を同時に分析するため、このタイプの分析は複雑になる可能性があります。これには、数値対数値、数値対カテゴリカル、およびカテゴリカル対カテゴリカルの 3 つの異なる変数ペアを含めることができます。
多変量
大規模なデータセットでよくある課題は、複数の変数の同時分析です。単変量および二変量分析手法は貴重な洞察を提供しますが、これは通常、複数の変数 (通常は 5 つ以上) を含むデータセットを分析するには十分ではありません。
通常、次元の呪いと呼ばれる、高次元データの管理に関するこの問題については、十分に文書化されています。変数の数が多いと、より多くの洞察を抽出できるため有利です。同時に、複数の変数を同時に分析または視覚化するために利用できる手法の数が限られているため、この利点が不利になる可能性があります。
6. 時系列データの分析
このステップでは、一定の時間間隔で収集されたデータ ポイントの検査に焦点を当てます。時系列データは、時間の経過とともに変化するデータに適用されます。これは基本的に、データセットが一定の時間間隔で記録されたデータ ポイントのグループで構成されていることを意味します。
時系列データを分析すると、通常、時間の経過とともに繰り返され、一時的な季節性を示すパターンや傾向を明らかにできます。時系列データの主な構成要素には、傾向、季節変動、周期的変動、不規則な変動やノイズが含まれます。
7. 外れ値と欠損値の処理
外れ値や欠損値に適切に対処しないと、分析結果が歪む可能性があります。このため、それらに対処するために常に 1 つのフェーズを考慮する必要があります。
これらのデータ ポイントを特定、削除、または置換することは、データセット分析の整合性を維持するために重要です。したがって、データ分析を開始する前にそれらに対処することが非常に重要です。
- 外れ値は、残りのデータ ポイントからの大幅な逸脱を示すデータ ポイントです。これらは通常、異常に高い値または低い値を示します。
- 欠損値とは、特定の変数または観測値に対応するデータ ポイントが存在しないことです。
欠損値と外れ値に対処するための重要な最初のステップは、それらがデータセットに存在する理由を理解することです。この理解は、多くの場合、問題に対処するための最適な方法の選択に役立ちます。考慮すべき追加の要素は、データの特性と実行される特定の分析です。
EDA は、データセットの明瞭性を高めるだけでなく、多数の変数を含むデータセットを管理するための戦略を提供することで、データ専門家が次元の呪縛を回避できるようにします。
これらの綿密な手順を通じて、Python を使用した EDA は、データから有意義な洞察を抽出するために必要なツールをアナリストに提供し、その後のすべてのデータ分析作業のための強固な基盤を築きます。
ジョセップ・フェレール バルセロナ出身の分析エンジニアです。 彼は物理工学を卒業し、現在は人間の移動に適用されるデータ サイエンス分野で働いています。 彼は、データ サイエンスとテクノロジーに焦点を当てた非常勤のコンテンツ クリエイターです。 あなたは彼に連絡することができます LinkedIn, Twitter or M.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis

