多腕バンディット (MAB) は、複数の選択肢が提示されたときに複雑なアルゴリズムを使用してリソースを動的に割り当てる機械学習フレームワークです。 つまり、データ アナリスト、医学研究者、マーケティング スペシャリストによって最も一般的に使用されている A/B テストの高度な形式です。
多腕バンディットの概念を深く掘り下げる前に、強化学習と、探索と搾取のジレンマについて説明する必要があります。 次に、さまざまなバンディット ソリューションと実用的なアプリケーションに焦点を当てることができます。
教師あり学習と教師なし学習と並んで、強化学習は基本的な XNUMX つのパラダイムの XNUMX つです。 機械学習. 前述の最初の XNUMX つのアーキタイプとは異なり、強化学習は、エージェントが環境と相互作用するたびに、エージェントに対する報酬と罰に焦点を当てています。
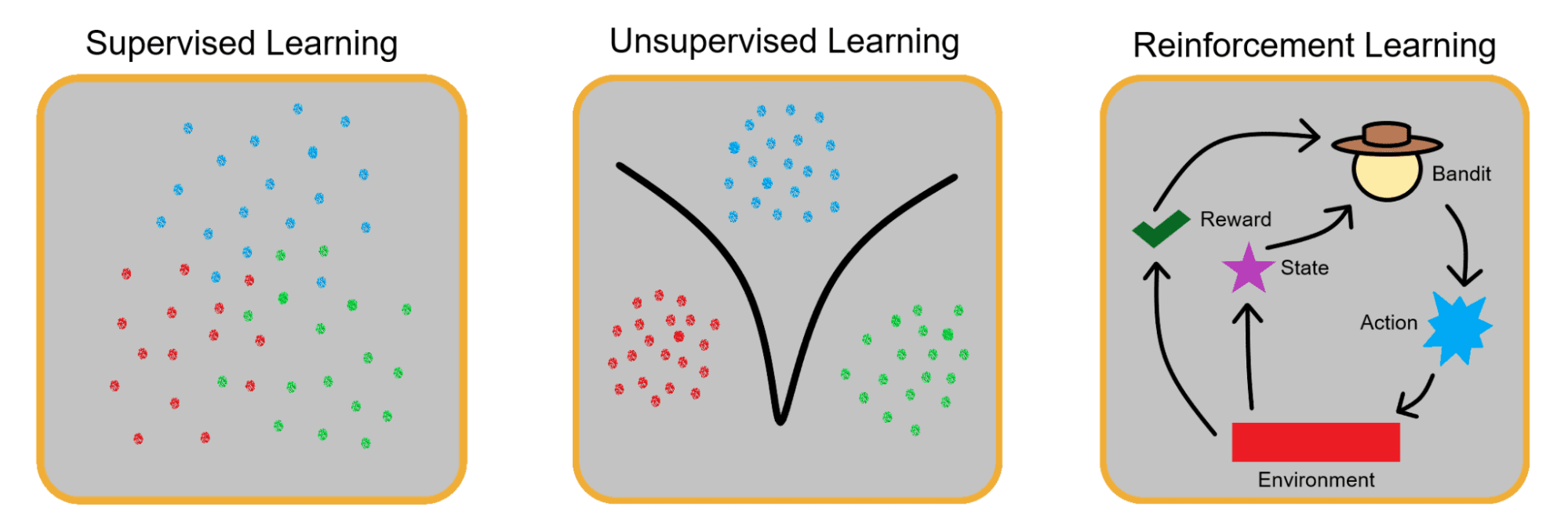
強化学習の実際の例は、日常的に利用できます。 たとえば、子犬がコンピューターのケーブルをかじると、子犬を叱ったり、その行動に対する不満を表明したりすることがあります。 そうすることで、家の周りのケーブルを破壊することは良いことではないことを犬に教えることができます. これが負の強化です。
同様に、あなたの犬が学んだトリックを実行するとき、あなたはそれに御馳走を与えます. この場合、正の強化を使用してその行動を奨励しています。
多腕バンディットも同じように学習します。
このほとんど哲学的なジレンマは、私たちの生活のあらゆる面に存在します。 仕事帰りに数え切れないほど訪れた場所でコーヒーを飲むべきですか、それとも通りの向かいにオープンしたばかりの新しいコーヒーショップを試してみるべきですか?
あなたはすることを選択した場合 探る、あなたの毎日のコーヒーは不快な経験になるかもしれません. ただし、先に進むと エクスプロイト すでに知っていることを知っていて、なじみのある場所を訪れていると、今まで味わったことのない最高のコーヒーを逃す可能性があります。
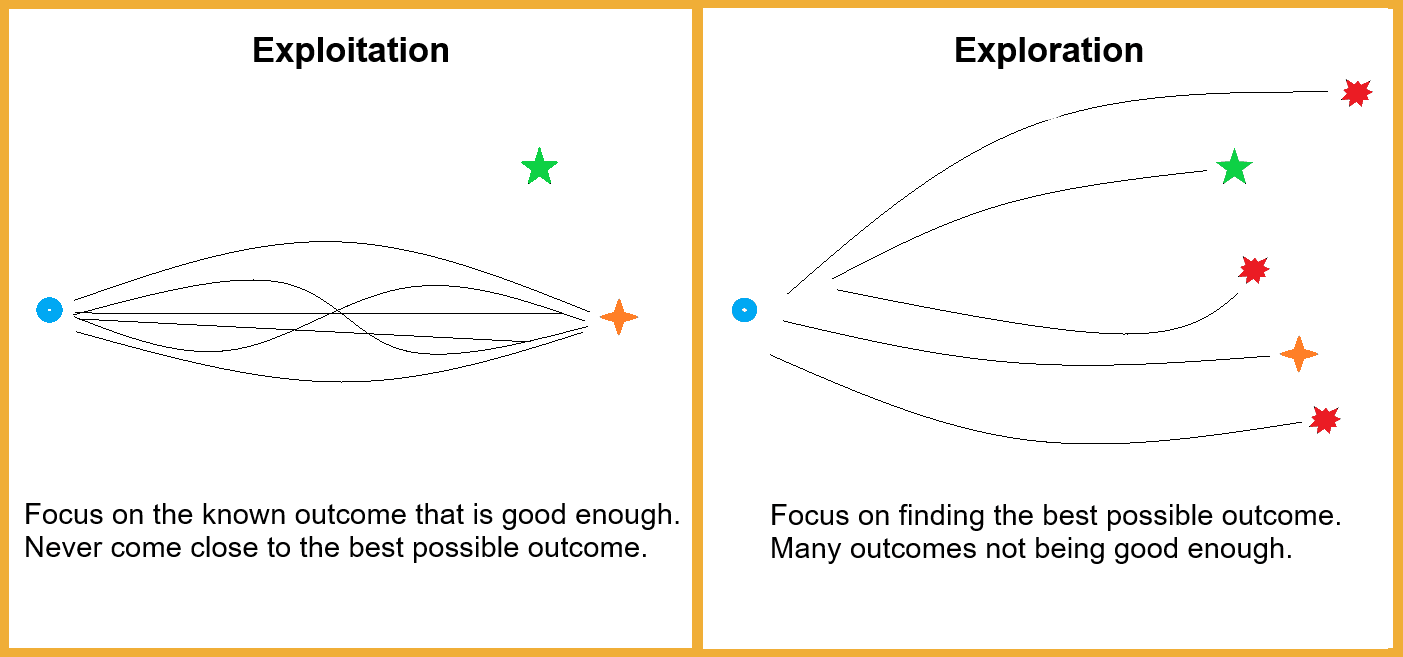
多腕バンディットは、さまざまな作業分野でこれらの問題に取り組み、データ アナリストが正しい行動方針を決定するのに役立ちます。
片腕のバンディットは、スロット マシンの別名です。 ニックネームの背後にある意味を説明する必要はありません。
多腕バンディット問題は、悪名高い片腕バンディットにちなんで名付けられました。 ただし、その認識は、盗賊や強盗に基づくものではなく、スロット マシンを使用した場合に長期的に当選結果が得られる所定の確率に基づくものでした。
これがどのように機能するかをよりよく理解するために、別の実際の例を使用してみましょう。 今回は、野菜をどこで買うかを決めています。 XNUMX つの選択肢があります。 スーパーマーケット、地元の食料品店、近くのファーマーズ マーケット。 価格設定や食品がオーガニックであるかどうかなど、考慮すべき要素はそれぞれ異なりますが、この例では食品の品質のみに焦点を当てます.
それぞれの場所で食料品を XNUMX 回購入し、ファーマーズ マーケットの野菜に最も満足していたとします。 ある時点で、あなたはその市場からのみ野菜を購入するという意識的な決定を下すでしょう.

まれに、市場が閉まっているときに、店やスーパーマーケットをもう一度試してみることを余儀なくされ、その結果があなたの考えを変えるかもしれません. 最高のバンディット エージェントは、同じことを行い、報酬の少ないオプションを時々再試行し、既に持っているデータを強化するようにプログラムされています。
バンディットはリアルタイムで学習し、それに応じてパラメーターを調整します。 A/B テストと比較して、多腕バンディットでは、短時間のテストだけで選択を行うのではなく、長期間にわたって高度な情報を収集できます。
多腕バンディット エージェントを作成する方法は無限にあります。 純粋探索エージェントは完全にランダムです。 彼らは探索に集中し、収集したデータを一切悪用しません。
名前が示すように、純粋な搾取エージェントは、搾取するすべてのデータをすでに持っているため、常に可能な限り最良のソリューションを選択します。 本質的に逆説的であるため、これは理論上のみ可能であり、ランダムエージェントと同様に悪い.
したがって、完全にランダムでもなく、実際に展開することも不可能でもない、最も人気のある XNUMX つの MAB エージェントの説明に焦点を当てます。
イプシロン貪欲
イプシロン貪欲な多腕盗賊は、式に探索値 (イプシロン) を追加することで、探索と搾取のバランスを取ります。 イプシロンが 0.3 の場合、エージェントは 30% の確率でランダムな可能性を探索し、残りの 70% の確率で最良の平均結果を利用することに集中します。
減衰パラメーターも含まれており、時間の経過とともにイプシロンが減少します。 エージェントを構築するとき、一定の時間またはアクションが実行された後、方程式からイプシロンを削除することを決定する場合があります。 これにより、エージェントはすでに収集したデータの活用のみに集中し、方程式からランダム テストを削除します。
信頼限界の上限
これらの多腕バンディットは、貪欲なイプシロン エージェントと非常によく似ています。 ただし、この XNUMX つの主な違いは、上限信頼限界バンディットを作成するときに含まれる追加のパラメーターです。
バンディットが時々最も調査されていない可能性に集中するように強制する変数が方程式に含まれています。 たとえば、オプション A、B、C、および D があり、オプション D が XNUMX 回しか選択されておらず、残りが数百回選択されている場合、盗賊は意図的に D を選択して結果を調べます。
本質的に、信頼度上限のエージェントはリソースの一部を犠牲にして、可能な限り最良の結果を決して探らないという、非常にありそうもない巨大な間違いを回避します。
トンプソン サンプリング (ベイジアン)
このエージェントは、上記で調べた XNUMX つとはまったく異なる方法で構築されています。 リストの中で群を抜いて最も高度なバンディット ソリューションであるため、それがどのように機能するかを十分に詳細に説明するには、エッセイの長さの記事が必要です。 ただし、代わりに複雑でない分析を選択することもできます。
トンプソンの盗賊は、過去に選択された頻度に基づいて、特定の選択を多かれ少なかれ信頼することができます. たとえば、エージェントが平均報酬率 0.71 で XNUMX 回選択したオプション A があります。 オプション A と同じ平均報酬ラジオで合計 XNUMX 回選択されたオプション B もあります。
この場合、トンプソン サンプリング エージェントはオプション A を選択する頻度が高くなります。 これは、パスを選択する頻度が高いほど、平均報酬が低くなる傾向があるためです。 エージェントは、オプション A の方が信頼性が高く、オプション B がより頻繁に選択された場合、平均結果が低くなると想定します。
おそらく、ここで言及できる最も一般的な例は Google Analytics. 公式ドキュメントの一部として、多腕バンディットを使用してさまざまな検索結果の実行可能性を調査し、さまざまな訪問者に表示する頻度を説明しました。
2018年には、 Netflixがプレゼンテーションを行いました Data Council で、どのタイトルをより頻繁に視聴者に表示するかを決定するために多腕バンディットをどのように適用したかについて話しています。 マーケティング担当者は、このデモンストレーションを非常に興味深いと感じるかもしれません。マルチアーム バンディット ソリューションに影響を与えた視聴者がタイトルを再生したり一時停止したりする頻度など、さまざまな要因がどのように説明されているかを説明しているからです。
おそらく、人類にとって多腕バンディットの最も重要な用途は、医療に関連しています。 今日まで、医療専門家はさまざまな MAB ビルドを使用して、患者に最適な治療法を決定しています。 バンディットはまた、臨床試験や新しい治療法の探索においてさまざまなアプリケーションを目にしています。
多腕バンディットは、マーケティング、金融、さらには健康など、複数の分野で成功裏に適用されています。 ただし、強化学習自体と同様に、環境の変化によって厳しく制限されます。 状況が変化する傾向がある場合、MABS は毎回「学習」をやり直さなければならず、有用性の低いツールになります。
アレックス・ポポビッチ 技術と財務のチーム リーダーとして XNUMX 年の経験を持つエンジニアリング マネージャー兼ライターです。 彼は現在、自身のコンサルタント会社の運営に時間を費やしていると同時に、データ サイエンス、AI、ハイ ファンタジーなど、彼が愛するようになったトピックを探求しています。 hello@writeralex.com で Alex に連絡できます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/01/introduction-multiarmed-bandit-problems.html?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-multi-armed-bandit-problems

