概要
この記事では、強化学習に関するインタビューの質問を学習します (RL) これは、エージェントが (試行錯誤を通じて) 環境と対話し、アクションを実行するためのフィードバック (報酬またはペナルティ) を受け取ることによって、環境から学習する一種の機械学習です。 ここでの目標は、Actor-Critic Methods などの手法を使用したフィードバックを使用して、試行錯誤を繰り返しながら、最善の行動を達成し、累積報酬シグナルを最大化することです。 RL エージェントは経験から学び、変化する環境に適応できるという事実を考慮すると、動的で予測不可能な環境に最適です。

最近、特定の環境でエージェントのパフォーマンスを最適化するためにポリシーベースと値ベースの両方の方法を組み合わせた RL アルゴリズムである Actor-Critic メソッドへの関心が高まっています。 この場合、アクターはエージェントがどのように行動するかを制御し、批評家は実行されたアクションがどれだけ優れているかを測定することでポリシーの更新を支援します。 Actor-Critic メソッドは、ロボット工学、ゲーム、自然言語処理など、さまざまな分野で非常に効果的であることが示されています。その結果、多くの企業や研究機関が積極的に Actor-Critic メソッドの使用を研究しています。この分野に詳しい方を求めています。
この記事では、次の面接で成功するための効果的な回答を作成するためのガイドとして使用できる、Actor-Critic メソッドに関する最も重要な XNUMX つの面接質問のリストを書き留めました。
この記事の終わりまでに、次のことを学びます。
- Actor-Critic メソッドとは何ですか? そして、Actor と Critic はどのように最適化されるのでしょうか?
- Actor-Critic Method と Generative Adversarial Network の類似点と相違点は何ですか?
- Actor-Critic Method のいくつかのアプリケーション。
- Entropy Regularization が Actor-Critic Methods の探索と活用のバランスをとるのに役立つ一般的な方法。
- Actor-Critic メソッドは、Q ラーニングやポリシー勾配法とどう違うのですか?
この記事は、の一部として公開されました データサイエンスブログ。
目次
Q1. Actor-Critic Methods とは何ですか? Actor と Critic がどのように最適化されるかを説明します。
これらは、ポリシーベースと値ベースの両方の方法を組み合わせて、特定の環境でエージェントのパフォーマンスを最適化する強化学習アルゴリズムのクラスです。
XNUMX つの関数近似、つまり XNUMX つがあります。 ニューラルネットワーク:
- アクター、政策機能 theta: エージェントの行動を制御する πθ (s) によってパラメーター化されます。
- 評論家、価値関数 w でパラメータ化: q^ w (s,a) は、実行されたアクションがどれだけ優れているかを測定することにより、ポリシーの更新を支援します!

出典:ハグフェイス
最適化プロセス:
ステップ1: 現在の状態 St は、Actor と Critic を介して入力として渡されます。 それに続いて、ポリシーは状態を取得し、アクション At を出力します。
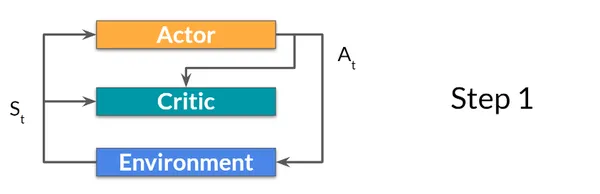
ステップ2: 批評家はその行動を入力として受け取ります。 このアクション (At) は、状態 (St) と共に、Q 値、つまりその状態でアクションを実行する値を計算するためにさらに利用されます。
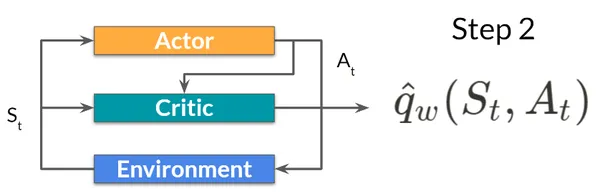
ステップ3: 環境で実行されるアクション (At) は、新しい状態 (S t+1) と報酬 (R t+1) を出力します。
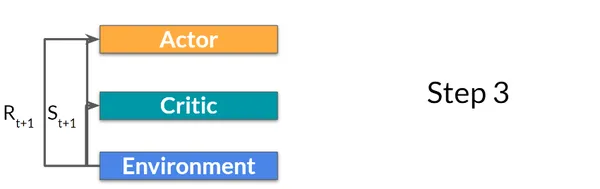
ステップ4: Q 値に基づいて、アクターはそのポリシー パラメータを更新します。

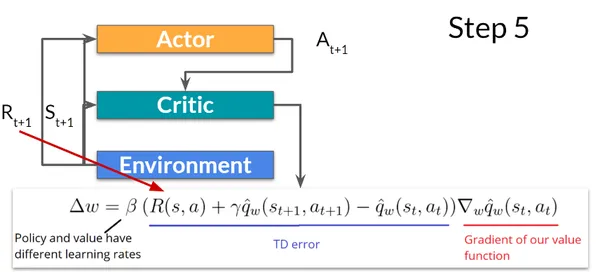
ステップ5: 更新されたポリシー パラメーターを使用して、新しい状態 (St+1) が与えられると、アクターは次のアクション (At+1) を実行します。 さらに、批評家はその値パラメーターも更新します。
Q2. Actor-Critic Method と Generative Adversarial Network の類似点と相違点は何ですか?
Actor-Critic (AC) メソッドと 生成的敵対的ネットワーク パフォーマンスを向上させるために連携して動作する XNUMX つのモデルをトレーニングする機械学習手法です。 ただし、それらには異なる目的と用途があります。
AC メソッドと GAN の重要な類似点は、相互に作用する XNUMX つのモデルのトレーニングが両方とも含まれていることです。 AC では、アクターと批評家が互いに協力して RL エージェントのポリシーを改善しますが、GAN では、ジェネレーターとディスクリミネーターが協力して、特定の分布から現実的なサンプルを生成します。
Actor-critic メソッドと Generative Adversarial Networks の主な違いは次のとおりです。
- AC メソッドは、ポリシーを改善することにより、RL エージェントの期待報酬を最大化することを目的としています。 対照的に、GANは、生成されたサンプルと実際のサンプルの違いを最小限に抑えることにより、トレーニングデータに似たサンプルを生成することを目指しています.
- AC では、アクターと批評家が協力してポリシーを改善します。一方、GAN では、ジェネレーターとディスクリミネーターがミニマックス ゲームで競合します。ジェネレーターはディスクリミネーターをだます現実的なサンプルを生成しようとし、ディスクリミネーターは本物と偽物を区別しようとします。サンプル。
- トレーニングに関して言えば、AC メソッドは方策勾配や Q 学習などの RL アルゴリズムを使用して、報酬シグナルに基づいてアクターと批評家を更新します。 対照的に、GANは敵対的トレーニングを使用して、生成された(偽の)サンプルと実際のサンプルの間のエラーに基づいてジェネレーターとディスクリミネーターを更新します。
- Actor-Critic メソッドは一連の意思決定タスクに使用されますが、GAN は画像生成、ビデオ合成、およびテキスト生成に使用されます。
Q3. Actor-Critic Methods のいくつかのアプリケーションを挙げてください。
Actor-Critic メソッドの適用例を次に示します。
- ロボティクス制御: Actor-Critic メソッドは、ロボット アームを使用したオブジェクトのピッキングと配置、ポールのバランス調整、ヒューマノイド ロボットの制御など、さまざまな用途で使用されています。
- ゲームプレイ: Actor-Critic メソッドは、Atari ゲーム、囲碁、ポーカーなど、さまざまなゲームで使用されています。
- 自動運転: Actor-Critic 手法は、自動運転に使用されています。
- 自然言語処理: Actor-Criticメソッドが適用されました NLP タスク 機械翻訳、対話生成、要約など。
- ファイナンス: Actor-Critic メソッドは、ポートフォリオ管理、取引、リスク評価などの財務上の意思決定タスクに適用されています。
- 健康管理: Actor-Critic メソッドは、個別化された治療計画、病気の診断、医用画像などのヘルスケア タスクに適用されています。
- レコメンダー システム: Actor-Critic メソッドは、レコメンダー システムで使用されています。たとえば、顧客の好みや購入履歴に基づいて顧客に製品を推奨する方法を学習します。
- 天文学: Actor-Critic メソッドは、巨大なデータセットのパターンの識別や天体イベントの予測など、天文学的なデータ分析に使用されてきました。
- 農業: Actor-Critic メソッドは、収穫量の予測や灌漑のスケジューリングなどの農業操作を最適化しました。
Q4. エントロピーの正則化が Actor-Critic の探索と搾取のバランスをとるのに役立ついくつかの方法を挙げてください。
Entropy Regularization が Actor-Critic での探索と搾取のバランスをとるのに役立つ一般的な方法のいくつかは次のとおりです。
- 探検を促します: エントロピー正則化項は、ポリシーに確率論を追加することで、ポリシーがさらに探索することを奨励します。 そうすることで、ポリシーが局所最適に行き詰まる可能性が低くなり、より優れた可能性のある新しいソリューションを探索する可能性が高くなります。
- 探査と搾取のバランスをとる: エントロピー項は探索を促進するため、ポリシーは最初はさらに探索する可能性がありますが、ポリシーが改善されて最適解に近づくにつれて、エントロピー項は減少し、より決定論的なポリシーと現在の最適解の活用につながります。 このように、エントロピー項は探査と搾取のバランスをとるのに役立ちます。
- 早すぎる収束を防ぎます: エントロピー正則化項は、ポリシーにノイズを追加することによって、ポリシーが最適でないソリューションに時期尚早に収束するのを防ぎます。 これは、ポリシーが状態空間のさまざまな部分を探索し、局所最適に行き詰まらないようにするのに役立ちます。
- 堅牢性の向上: エントロピーの正則化項は探索を促進し、早すぎる収束を防ぐため、結果として、ポリシーが新しい/目に見えない状況にさらされたときにポリシーが失敗する可能性が低くなります。
- 勾配信号を提供: エントロピー正則化項は、ポリシーの更新に使用できる勾配信号、つまりポリシー パラメータに対するエントロピーの勾配を提供します。 そうすることで、ポリシーで探索と利用のバランスをより効果的にとることができます。
Q5. Actor-Critic Method は、Q 学習や方策勾配法などの他の強化学習法とどう違うのですか?
Q ラーニングは価値ベースのアプローチであり、ポリシー勾配法はポリシーベースです。
Q ラーニングでは、エージェントは状態とアクションの各ペアの値を推定することを学習し、次にそれらの推定値を使用して最適なアクションを選択します。
ポリシー勾配法では、エージェントは状態をアクションにマッピングするポリシーを学習し、パフォーマンス メジャーの勾配を使用してポリシー パラメーターを更新します。
対照的に、アクター クリティカル メソッドは、値ベースの関数とポリシー ベースの関数を使用して、特定の状態で実行するアクションを決定するハイブリッド メソッドです。 正確に言うと、値関数は特定の状態からの期待リターンを推定し、ポリシー関数はその状態で実行するアクションを決定します。
強化学習におけるインタビューの質問と継続学習のヒント
以下は、面接で優れた成績を収め、RL の理解を深めるのに役立つヒントです。
- 基本を見直します。 複雑なトピックに飛び込む前に、しっかりとした基礎を身につけることが重要です。
- OpenAI gym や Stable-Baselines3 などの RL ライブラリに慣れ、標準アルゴリズムを実装して遊んで、物事を把握してください。
- 現在の研究を最新の状態に保ちます。 これについては、Twitter/LinkedIn で OpenAI、Hugging Face、DeepMind などの著名な技術巨人をフォローするだけです。 また、研究論文を読んだり、会議に参加したり、コンテストやハッカソンに参加したり、関連するブログやフォーラムをフォローしたりすることで、最新情報を入手できます。
- 面接対策はChatGPTで!
まとめ
この記事では、データ サイエンスのインタビューで尋ねられる可能性がある Actor-Critic メソッドに関する XNUMX つのインタビューの質問を調べました。 これらの面接の質問を使用して、さまざまな概念を理解し、効果的な回答を作成し、面接官に提示することができます。
要約すると、この記事の要点は次のとおりです。
- 強化学習 (RL) は、エージェントが (試行錯誤を通じて) 環境と対話し、アクションを実行するためのフィードバック (報酬またはペナルティ) を受け取ることによって、環境から学習する一種の機械学習です。
- AC では、アクターと批評家が協力して RL エージェントのポリシーを改善しますが、GAN では、ジェネレーターとディスクリミネーターが協力して、特定の分布から現実的なサンプルを生成します。
- AC メソッドと GAN の主な違いの XNUMX つは、アクターと批評家が協力してポリシーを改善するのに対し、GAN ではジェネレーターとディスクリミネーターがミニマックス ゲームで競合し、ジェネレーターがディスクリミネーターを欺く現実的なサンプルを生成しようとすることです。弁別器は、本物のサンプルと偽のサンプルを区別しようとします。
- Actor-Critic Methods には、ロボット制御、ゲームプレイ、金融、NLP、農業、ヘルスケアなど、幅広い用途があります。
- エントロピーの正則化は、探索と搾取のバランスをとるのに役立ちます。 また、堅牢性が向上し、時期尚早の収束が防止されます。
- Actor-Critic メソッドは、価値ベースのアプローチとポリシー ベースのアプローチを組み合わせたものですが、Q ラーニングは価値ベースのアプローチであり、ポリシー勾配法はポリシー ベースのアプローチです。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/04/top-interview-questions-on-actor-critic-methods/

