
による画像 Freepik
会話型 AI とは、人間の対話を模倣し、人間を会話に参加させることができる仮想エージェントとチャットボットを指します。会話型 AI の使用は急速に生活様式になりつつあり、Alexa に「最寄りのレストランを探す” Siriに「リマインダーを作成してください」 仮想アシスタントやチャットボットは、消費者の質問に答えたり、苦情を解決したり、予約したりするためによく使用されます。
これらの仮想アシスタントの開発には多大な労力が必要です。ただし、主要な課題を理解し、対処することで、開発プロセスを合理化できます。私は、主要な課題とそれに対応する解決策を説明するための参照点として、採用プラットフォーム用の成熟したチャットボットを作成した直接の経験を使用しました。
会話型 AI チャットボットを構築するには、開発者は RASA、Amazon の Lex、Google の Dialogflow などのフレームワークを使用してチャットボットを構築できます。ほとんどの場合、カスタム変更を計画している場合、またはボットがオープンソース フレームワークであるため成熟段階にある場合に RASA を好みます。他のフレームワークも出発点として適しています。
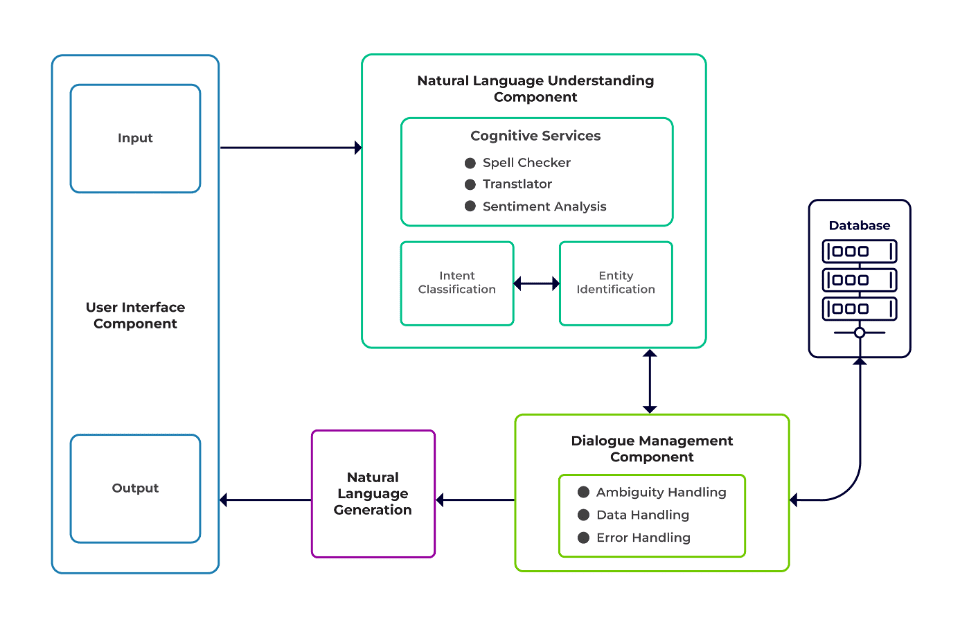
課題は、チャットボットの 3 つの主要なコンポーネントに分類できます。
自然言語理解(NLU) 人間の対話を理解するボットの能力です。インテントの分類、エンティティの抽出、および応答の取得を実行します。
ダイアログマネージャー 現在および以前のユーザー入力のセットに基づいて実行される一連のアクションを担当します。これは、意図とエンティティを入力として (前の会話の一部として) 受け取り、次の応答を識別します。
自然言語生成(NLG) 与えられたデータから書き言葉または話し言葉を生成するプロセスです。これにより応答がフレーム化され、ユーザーに表示されます。
Talentica Software からの画像
データが不十分
開発者が FAQ やその他のサポート システムをチャットボットに置き換えると、かなりの量のトレーニング データが得られます。しかし、ボットを最初から作成する場合は同じことは起こりません。このような場合、開発者はトレーニング データを合成的に生成します。
何をするか?
テンプレートベースのデータ ジェネレーターは、トレーニング用に適切な量のユーザー クエリを生成できます。チャットボットの準備が完了すると、プロジェクト所有者はチャットボットを限られた数のユーザーに公開して、トレーニング データを強化し、一定期間にわたってアップグレードすることができます。
適合しないモデルの選択
最良の意図とエンティティの抽出結果を得るには、適切なモデルの選択とトレーニング データが重要です。開発者は通常、特定の言語とドメインでチャットボットをトレーニングします。利用可能な事前トレーニング済みモデルのほとんどはドメイン固有であり、単一言語でトレーニングされていることがよくあります。
人々が多言語を話す場合には、言語が混在する場合もあります。混合言語でクエリを入力する場合があります。たとえば、フランス人が優勢な地域では、人々はフランス語と英語が混合したタイプの英語を使用することがあります。
何をするか?
複数の言語でトレーニングされたモデルを使用すると、問題が軽減される可能性があります。このような場合には、LaBSE (言語に依存しない Bert 文埋め込み) のような事前トレーニングされたモデルが役立ちます。 LaBSE は、文の類似性タスクに関して 109 以上の言語でトレーニングされています。モデルは、別の言語の類似した単語をすでに知っています。私たちのプロジェクトでは、それは非常にうまくいきました。
不適切なエンティティ抽出
チャットボットでは、エンティティがユーザーが検索しているデータの種類を識別する必要があります。これらのエンティティには、時間、場所、人、アイテム、日付などが含まれます。ただし、ボットは自然言語からエンティティを識別できない場合があります。
同じコンテキストだが異なるエンティティ。たとえば、ユーザーが「デリー工科大学の学生の名前」と入力してから「ベンガルールの学生の名前」を入力すると、ボットは場所をエンティティと混同する可能性があります。
エンティティが低い信頼度で誤って予測されるシナリオ。 たとえば、ボットは IIT デリーを信頼性の低い都市として識別することができます。
機械学習モデルによる部分エンティティ抽出。 ユーザーが「IIT デリーの学生」と入力した場合、モデルは「IIT デリー」ではなく「IIT」をエンティティとしてのみ識別できます。
コンテキストのない単一単語の入力は、機械学習モデルを混乱させる可能性があります。 たとえば、「リシケシ」のような単語は、人名と都市の両方の名前を意味することがあります。
何をするか?
トレーニング例をさらに追加することが解決策になる可能性があります。ただし、制限があり、それを超えると追加しても役に立ちません。さらに、それは終わりのないプロセスです。もう 1 つの解決策は、事前に定義された単語を使用して正規表現パターンを定義し、都市、国などの既知の可能な値セットを持つエンティティを抽出することです。
モデルは、エンティティの予測について確信が持てない場合、信頼度が低くなります。開発者はこれをトリガーとして使用し、信頼性の低いエンティティを修正できるカスタム コンポーネントを呼び出すことができます。上の例を考えてみましょう。もし IITデリー 信頼度が低い都市として予測される場合、ユーザーはいつでもデータベース内で都市を検索できます。予測されたエンティティが見つからなかった場合 市町村 テーブルにある場合、モデルは他のテーブルに進み、最終的には 機関 テーブル、エンティティの修正が行われます。
間違った意図の分類
すべてのユーザー メッセージには、何らかの意図が関連付けられています。インテントはボットの次のアクションを導き出すため、ユーザーのクエリをインテントで正しく分類することが重要です。ただし、開発者は、インテント間の混乱を最小限に抑えてインテントを識別する必要があります。そうしないと、混乱によってバグが発生する可能性があります。例えば、 "空いているポジションを見せてください」 対「空いているポジションの候補者を見せてください。」
何をするか?
紛らわしいクエリを区別するには 2 つの方法があります。まず、開発者はサブインテントを導入できます。次に、モデルは識別されたエンティティに基づいてクエリを処理できます。
ドメイン固有のチャットボットは、何が可能で何が不可能かを明確に識別するクローズド システムである必要があります。開発者は、ドメイン固有のチャットボットを計画しながら、段階的に開発を行う必要があります。各フェーズで、チャットボットのサポートされていない機能を (サポートされていないインテントを介して) 特定できます。
また、チャットボットが「範囲外」のインテントで処理できないものを特定することもできます。ただし、サポートされていない意図や範囲外の意図に関してボットが混乱する場合もあります。このようなシナリオでは、インテントの信頼度がしきい値を下回った場合に、モデルがフォールバック インテントを使用して正常に動作し、混乱のケースを処理できるフォールバック メカニズムを導入する必要があります。
ボットはユーザーのメッセージの意図を識別したら、応答を返信する必要があります。ボットは、定義されたルールとストーリーの特定のセットに基づいて応答を決定します。たとえば、ルールは非常に単純なものにすることができます。 "おはようございます" ユーザーが挨拶するとき "こんにちは"。 ただし、ほとんどの場合、チャットボットとの会話にはフォローアップのやり取りが含まれており、チャットボットの応答は会話の全体的なコンテキストによって異なります。
何をするか?
これに対処するために、チャットボットにはストーリーと呼ばれる実際の会話の例が供給されます。ただし、ユーザーが常に意図したとおりに操作するとは限りません。成熟したチャットボットは、そのような逸脱をすべて適切に処理する必要があります。デザイナーや開発者は、ストーリーを書くときに幸せな道だけに焦点を当てるだけでなく、不幸な道にも取り組むことで、これを保証できます。
チャットボットに対するユーザーの関与は、チャットボットの応答に大きく依存します。応答がロボット的すぎたり、ありきたりすぎると、ユーザーは興味を失う可能性があります。たとえば、ユーザーは、応答が正しい場合でも、入力が間違っている場合に「間違ったクエリを入力しました」などの応答を好まない場合があります。ここでの答えはアシスタントの性格と一致しません。
何をするか?
チャットボットはアシスタントとして機能し、特定のペルソナと声のトーンを備えている必要があります。彼らは歓迎的かつ謙虚であるべきであり、開発者はそれに応じて会話や発話を設計する必要があります。応答はロボット的または機械的に聞こえるべきではありません。たとえば、ボットは次のように言うことができます。申し訳ありませんが、詳細はないようです。クエリを再入力していただけますか?」 間違った入力に対処するため。
ChatGPT や Bard などの LLM (Large Language Model) ベースのチャットボットは、革新的なイノベーションであり、会話型 AI の機能を向上させました。彼らは、人間らしい自由な会話をするのが得意なだけでなく、テキストの要約や段落作成など、これまでは特定のモデルでしか実現できなかったさまざまなタスクを実行することもできます。
従来のチャットボット システムの課題の 1 つは、各文を意図に分類し、それに応じて応答を決定することです。このアプローチは現実的ではありません。 「ごめんなさい、連絡できませんでした」のような返答は、多くの場合イライラさせられます。意図のないチャットボット システムが今後の前進であり、LLM はこれを実現できます。
LLM は、特定のドメイン固有のエンティティ認識を除いて、一般的な名前付きエンティティ認識において最先端の結果を簡単に達成できます。チャットボット フレームワークで LLM を使用する混合アプローチにより、より成熟した堅牢なチャットボット システムを実現できます。
会話型 AI の最新の進歩と継続的な研究により、チャットボットは日々改良されています。 「ムンバイ行きの飛行機を予約し、ダダール行きのタクシーを手配する」など、複数の目的を持つ複雑なタスクを処理する分野が大きな注目を集めています。
まもなく、ユーザーの特性に基づいてパーソナライズされた会話が行われ、ユーザーの関心を維持できるようになるでしょう。たとえば、ユーザーが不満を抱いているとボットが判断すると、会話を実際のエージェントにリダイレクトします。さらに、チャットボット データが増え続ける中、ChatGPT などの深層学習技術により、ナレッジ ベースを使用してクエリに対する応答を自動的に生成できます。
スーマン・サウラフ ソフトウェア製品開発会社 Talentica Software のデータ サイエンティストです。彼は NIT Agartala の卒業生であり、NLP、会話型 AI、生成型 AI を使用した革新的な AI ソリューションの設計と実装に 8 年以上の経験があります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them

