この記事は、の一部として公開されました データサイエンスブログソン.

概要
これは、交通事故の重大度を XNUMX つのカテゴリに分類する多クラス分類プロジェクトです。 このプロジェクトは実世界のデータに基づいており、データセットも非常に不均衡です。 ターゲット変数には、軽度、重度、致命的な XNUMX 種類の傷害があります。
交通事故は、世界中の不自然な死の主な原因です。 すべての政府は、死亡事故を減らすために路上で車両を運転する際に従うべき規制について、意識を高めるために懸命に取り組んでいます。 そのため、事故の深刻度を予測し、死者数を減らす仕組みが必要です。
この記事では、調査機関が必要な予防措置を講じるために、交通事故の重大度を予測するための機械学習ソリューションを開発したエンドツーエンドのプロジェクトに取り組みます。 それでは、プロジェクトの説明と問題の説明から始めましょう。
機械学習ソリューションを理解する
このデータセットは、修士課程の学生の研究活動のために、エチオピアのアディスアベバ市の警察署から収集されました。 データセットは、2017 年から 20 年の道路交通事故のマニュアル文書から作成されました。 データのエンコード中にすべての機密情報が除外され、最終的に 32 の特徴と 12316 行の事故が含まれています。 次に、さまざまな分類アルゴリズムを使用して分析することにより、事故の主な原因を特定するために前処理されます。 機械学習モデルは評価された後、クラウドベースのプラットフォームに展開され、エンド ユーザーが使用できるようになります。
問題文
ターゲット機能は、多クラス変数である「Accident_severity」です。 タスクは、各データ サイエンス プロセスとタスクを実行することにより、他の 31 の機能に基づいてこの変数を段階的に分類することです。 評価の指標は「F1 スコア」です。
前提条件
これは 中級プロジェクト とともに 不均衡なマルチクラス分類問題. このプロジェクトの前提条件の一部。
- 分類機械学習アルゴリズムの理解が必要です。
- Python プログラミング言語と Pandas、NumPy、Matplotlib、Scikit-Learn などの Python フレームワーク、および streamlit ライブラリの基礎に関する知識が必要です。
データセットの説明
- Time — 事故の時刻 (24 時間形式)
- Day_of_week — 事故が発生した日
- Age_band_of_driver — ドライバーの年齢層
- Sex_of_driver — ドライバーの性別
- Educational_level — ドライバーの最高教育レベル
- Vehical_driver_relation — ドライバーと車両の関係
- Driving_experience — ドライバーの運転経験年数
- Type_of_vehicle — 車両の種類は何ですか
- Owner_of_vehicle — 車両の所有者
- Service_year_of_vehicle — 車両の最後のサービス年
- Defect_of_vehicle — 車両に欠陥があるかどうか?
- Area_accident_occured — 事故現場の場所
- Lanes_or_Medians — 事故現場に車線または中央分離帯はあるか?
- Road_alignment — 土地の地形との道路の線形
- Types_of_junction — 事故現場のジャンクションのタイプ
- Road_surface_type — 道路のサーフェス タイプ
- Road_surface_conditions — 路面の状態は?
- Light_conditions — サイトの照明条件
- Weather_conditions — 事故現場の気象状況
- Type_of_collision — 衝突のタイプは何ですか
- Number_of_vehicles_involved — 事故に巻き込まれた車両の総数
- Number_of_casualties — 事故による死傷者の総数
- Vehicle_movement — 事故が発生する前の車両の動き
- Casualty_class — 事故で亡くなった人
- Sex_of_casualty — 殺された人の性別
- Age_band_of_casualty — 死傷者の年齢グループ
- Casualty_severtiy — 負傷者の重傷の程度
- Work_of_casualty — 犠牲者の仕事は何でしたか
- Fitness_of_casualty — 犠牲者のフィットネス レベル
- Pedestrain_movement — 道路上で歩行者の動きはありましたか?
- cause_of-accident — 事故の原因は?
- Accident_severity — 事故の深刻度は? (対象変数)
ここまでで、問題のステートメントとデータの説明を理解しました。 次に、予測分析の問題を解決し、ストリームライト クラウドに機械学習ソリューションを展開するためのエンド ツー エンドのコード実装を見ていきます。
機械学習ソリューションでのデータセットの分析
問題の説明とデータの説明を確認したので、データセットを開発環境にロードし、データの分析を開始して、データの準備とモデリングの段階で重要な洞察を見つけます。
データセットのソース — ここをクリック
Kaggle データセット リンク — ここをクリック
- データセットをインポートする
このプロジェクトでは、Kaggle 環境を使用しました。 このデータセットをローカル環境または任意のクラウドベースの IDE で使用して、段階的なコードに従ってこのプロジェクトの作業を完了することができます。
# pandas import pandas as pd # pandas read_csv 関数を使用してデータセットをロード df = pd.read_csv("/kaggle/input/road-traffic-severity-classification/RTA Dataset.csv") df.head()
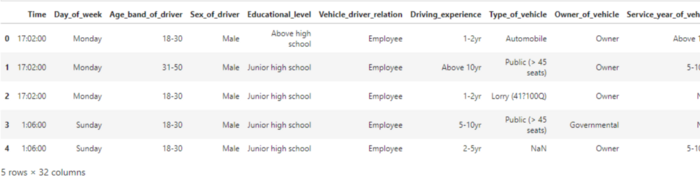
注: データセットが大きいため、上記のコードの出力はスクリーンショットに完全には表示されません。
2. データセットのメタデータ
# データセット情報を表示 df.info()
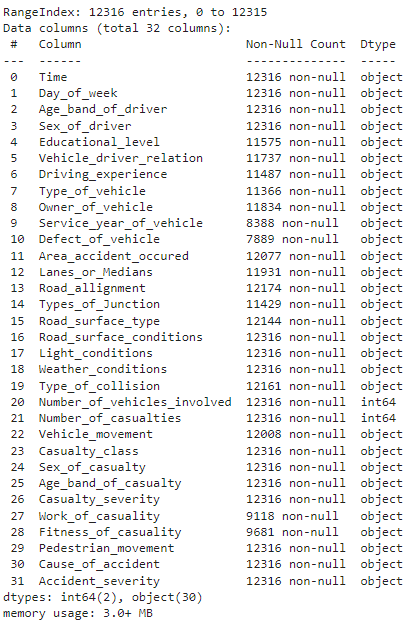
上記のメソッドは、null 以外の値、各列のデータ型、データセットに存在する行と列の数、データセットのメモリ使用量などのメタデータ情報を表示します。
3.各列に存在する欠損値の数を見つけます
# 各列に存在する欠損値の数を見つける df.isnull().sum()
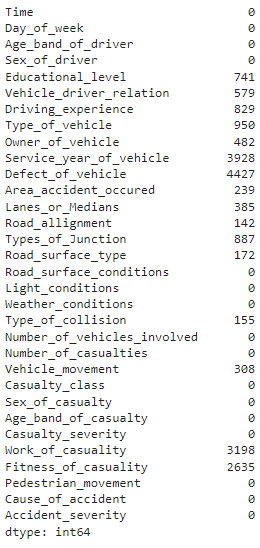
上記のコードの出力
このメソッドは、各列に欠損値がいくつあるかを示します。 「Defect_of_Vehicle」は欠損値の最大数を示しており、4427 インスタンス中 12316 です。
4. ターゲット変数クラスの分布と可視化
# ターゲット変数クラスのカウントとバー プロット print(df['Accident_severity'].value_counts()) df['Accident_severity'].value_counts().plot(kind='bar')

上記のコードの出力
問題ステートメントで前述したように、ターゲット変数クラスは非常に不均衡であり、データ準備段階でこの問題を解決して、正確で一般化された機械学習モデルを開発します。
5. データセットの探索的データ分析
ドライバーの教育水準を知ろう
# 自動車ドライバーの教育レベル df['Educational_level'].value_counts().plot(kind='bar')
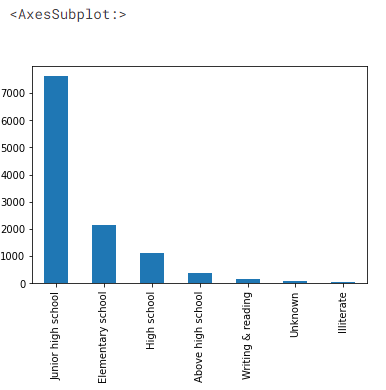
データセットの出力
7000 人以上のドライバーが中学校までの教育を受けており、高校以上の教育を受けているドライバーはごく一部です。
- 「dabl」ライブラリを使用した自動データ視覚化
# dabl ライブラリを使用したデータセットの可視化 pip install dabl
インポートダブル
dabl.plot(df, target_col='Accident_severity')

上記のコードの出力
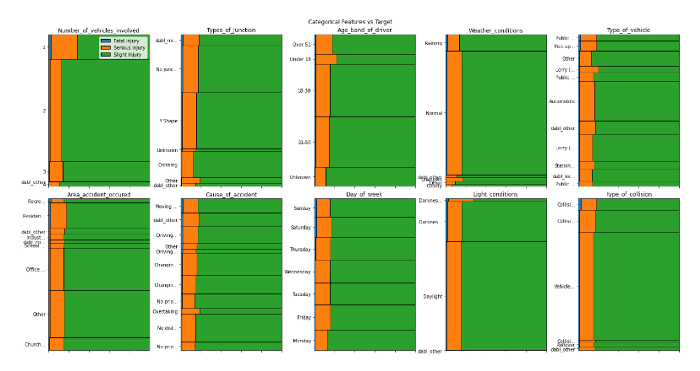
上記のコードの出力
わずか XNUMX 行のコードを使用して、入力フィーチャとターゲット変数の間の関係を視覚化できます。 これまでの分析から、次の洞察を導き出すことができます。
- 死傷者数が多いほど、事故現場で致命傷を負う可能性が高くなります
- 関与する車両が多いほど、重傷を負う可能性が高くなります
- Light_conditions が暗闇であると、重傷を負う可能性が高くなります
- データは非常に不均衡です
- のような機能
area_accident_occured,Cause_of_accident,Day_of_week,type_of_junction致命的な怪我を引き起こす本質的な機能と思われる - Road_surface と道路状況は重大または致命的な事故に影響しないようです
(注: この記事の最後に、このプロジェクトの github リポジトリ リンクを添付しますので、コードに関する詳細情報を確認できます)
- 「路面種別」列と対象「事故強度」の対応付け
# road_surface_type と事故重大度フィーチャのバー プロットをプロットします plt.figure(figsize=(6,5)) sns.countplot(x='Road_surface_type', hue='Accident_severity', data=df) plt.xlabel('Rode surafce type') plt.xticks(rotation=60) plt.show
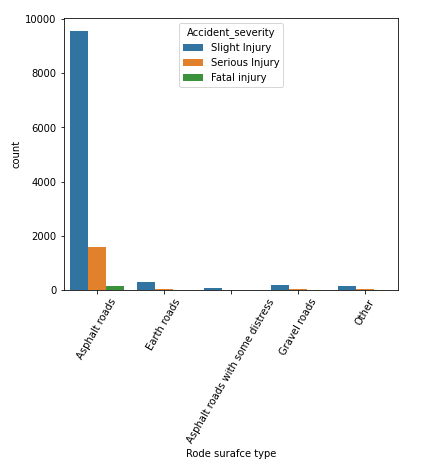
上記のコードの出力
データセットでは、ほとんどの事故が「アスファルト道路」で発生し、次に「土道」が続いていることがわかります。 ここでは、ほとんどの致命的な怪我はアスファルト道路で発生していると言えます。そのため、ターゲット クラスを予測するための重要な変数ではない可能性があります。
ここで、上記の調査結果に基づいて、モデリングと評価の目的で生データを前処理します。
データの準備
「Time」列のデータ型を「datetime」データ型に変更して、データセットの前処理を開始します。 次に、時間帯の特徴を抽出して、モデリング用のデータを準備します。
# オブジェクト型列を datetime データ型列に変換 df['Time'] = pd.to_datetime(df['Time']) # Time 列から 'Hour_of_Day' 機能を抽出 new_df = df.copy() new_df['Hour_of_Day'] = new_df['Time'].dt.hour n_df = new_df.drop('Time', axis=1) n_df.head()
上記のコードの出力
欠測値の処理
この時点までに、前の段階から得られた洞察に基づいて、さらに処理するために選択する機能のサブセットが得られます。 機能のサブセットを選択し、Pandas ライブラリの「fillna()」メソッドを使用して欠損値を処理します。
このコンテキストでは、調査中に欠損値が見つからなかった可能性があると仮定して、値として「不明」を入力することで欠損値を処理します。
# サービス情報が利用できない可能性があるため、NaN が欠落しています。'Unknowns' として入力します。 '].fillna('不明') feature_df['Area_accident_occured'] = feature_df['Area_accident_occured'].fillna('Unknown') feature_df['Driving_experience'] = feature_df['Driving_experience'].fillna('unknown') feature_df ['車両の種類'] = feature_df['車両の種類'].fillna('その他') feature_df['車両ドライバーの関係'] = feature_df['車両ドライバーの関係'].fillna('不明') '].fillna('Unknown') feature_df['Type_of_collision'] = feature_df['Type_of_collision'].fillna('Unknown') # 機能情報 feature_df.info()
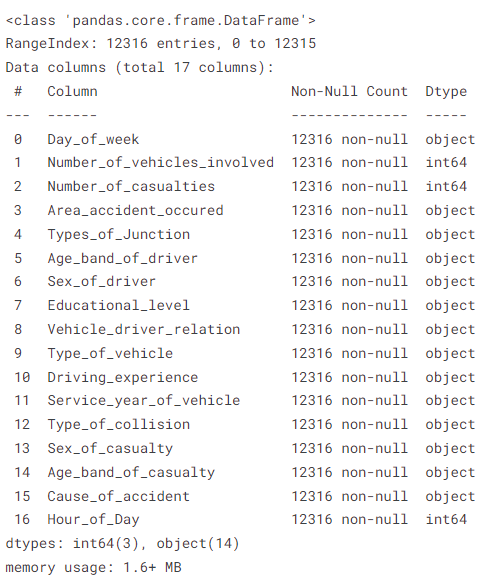
データフレームの出力
ご覧のとおり、以前の未加工のデータセットと比較して、フィーチャ セットの null 値はゼロになりました。 他のデータ前処理ステップに移りましょう。
「get_dummies()」メソッドを使用したワンホット エンコーディング
Pandas の「get_dummies()」を使用して、カテゴリ列を数値特徴に変換できます。 以下のコード スニペットを見てみましょう。
# 12316 つのホット エンコーディング機能を使用してエンコードするカテゴリ機能','Driving_experience','Service_year_of_vehicle','Type_of_collision', 'Sex_of_casualty','Age_band_of_casualty','Cause_of_accident','Hour_of_Day'] # 入力機能 X とターゲット y の設定 X = feature_df[features] # ここで機能は次から選択されます'object' datatype y = n_df['Accident_severity'] # オンホット エンコーディングに pandas get_dummies メソッドを使用します encoded_df = pd.get_dummies(X, drop_first=True) encoded_df.shape ----------- - - - - - - - - - - - - [出力] - - - - - - - - - - - - ------------ (106, XNUMX)
エンコードの結果、エンコードされたデータフレームに 106 列が含まれるようになりました。これをさらに前処理して、モデリング目的で重要な機能のみを保持します。
「LabelEncoder()」メソッドを使用したターゲット エンコーディング
# sklearn.preprocessing から sklearn.preprocessing から labelencoder をインポートする import LabelEncoder # labelencoder オブジェクトを作成する lb = LabelEncoder() lb.fit(y) y_encoded = lb.transform(y) print("Encoded labels:",lb.classes_) y_en = pd.Series(y_encoded) -----------------------------------[出力]------ ---------------------------- エンコードされたラベル: [「致命傷」「重傷」「軽傷」]
現在、「encoded_df」をエンコードされたデータフレーム オブジェクトとして、「y_en」をエンコードされたターゲット列として使用して、「Kbest」機能をさらに選択し、不均衡なデータセットを処理します。
「Chi2」統計を使用した機能選択
# カテゴリ出力に chi2 を使用する機能選択方法、sklearn.feature_selection からのカテゴリ入力 import SelectKBest, chi2 fs = SelectKBest(chi2, k=50) X_new = fs.fit_transform(encoded_df, y_en) # 選択された機能を取得 cols = fs.get_feature_names_out () # 選択した機能をデータフレームに変換 fs_df = pd.DataFrame(X_new, columns=cols)
エンコードされたデータ フレームから 50 個のフィーチャから上位 106 個のフィーチャを選択し、「fs_df」と呼ばれる新しいデータフレーム オブジェクトに格納します。 対象の特徴がカテゴリ変数の場合は "Chi2" 統計量が使用され、対象の特徴が連続変数の場合は "ピアソン係数" が使用されます。 次に、データセットをアップサンプリングして、カテゴリ機能のバランスを取りましょう。
「SMOTENC」手法を使用した不均衡データ処理
scikit-learn ライブラリには、という拡張ライブラリがあります。 「アンバランス学習」 不均衡なデータを処理するためのさまざまな方法があります。 (公式文書 — ここをクリック).
少数派クラスのサンプルをアップサンプリングするには、 「ノミナルおよび連続の合成マイノリティ オーバーサンプリング手法」 (SMOTENC) プロジェクトのテクニック。 この方法は、データセットを正確にアップサンプリングするために、カテゴリおよび連続機能用に設計されています。
# imblearn.over_sampling から imblearn ライブラリから SMOTENC オブジェクトをインポートする import SMOTENC # SMOTENC のカテゴリ特徴 カテゴリ特徴の手法 n_cat_index = np.array(range(3,50)) # SMOTENC クラスで smote オブジェクトを作成する smote = SMOTENC(categorical_features=n_cat_index , random_state=42, n_jobs=True) X_n, y_n = smote.fit_resample(fs_df,y_en) # 新しいアップサンプリングされたデータセットの形状を出力します X_n.shape, y_n.shape -------------- - - - - - - - - - - -[出力] - - - - - - - - - - - - - -------- ((31245, 50), (31245,)) # 対象クラスの分布を表示 print(y_n.value_counts()) ---------------- - - - - - - - - - -[出力] - - - - - - - - - - - - - - ------ 2 10415 1 10415 0 10415 dtype: int64
ご覧のとおり、合計でアップサンプリングされた新しいデータセットがあります。 31245 サンプル。 ターゲットクラスにはそれぞれ 10415 サンプルであり、データセットはモデリング タスク用にバランスが取れています。
機械学習モデリング
それでは、ランダム フォレスト機械学習アルゴリズムを使用して分類機械学習モデルを開発しましょう。 Scikit-Learn ライブラリのさまざまなクラスをインポートして ML モデルを開発し、次のステップで評価します。
# sklearn.model_selection から必要なライブラリをインポートします import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import conflict_matrix, classification_report, f1_score # トレーニングとテスト分割、およびターゲット機能を予測するためのベースライン モデルの構築 X_trn, X_tst, y_trn, y_tst = train_test_split( X_n, y_n, test_size=0.2, random_state=42) # ランダム フォレスト ベースラインを使用したモデリング rf = RandomForestClassifier(n_estimators=800, max_depth=20, random_state=42) rf.fit(X_trn, y_trn) # テスト データの予測 predics = rf .predict(X_tst) # トレーニング スコア rf.score(X_trn, y_trn) ---------------------------------- -[出力]---------------------------------- 0.9416306609057449
ここで、n_estimators = 800 および max_depth = 20 のランダム フォレスト モデルを開発しました。このモデルをテスト データで評価して、結果を検証し、新しい入力データに基づいて予測を行います。
テスト データセットの分類レポートを印刷してみましょう。
# テスト データセットの分類レポート classif_re = classification_report(y_tst,predics) print(classif_re) -------------------------------- ---[出力]------------------------------------------------- 精度リコール f1-スコア サポート 0 0.94 0.96 0.95 2085 1 0.84 0.83 0.84 2100 2 0.86 0.87 0.86 2064精度0.88.6249 0.88マクロAVG 0.88 0.88 6249 0.88 - - - - - - - - - - - - - - - - - [出力] - - - - - - - --------------------- 0.88
モデルは、トレーニング データセットの 88% と比較して、テスト データの 94% の精度をアーカイブすることがわかります。 私たちのモデルはテスト データセットでうまく機能しているように見えます。モデルをストリームライト クラウドにデプロイして、エンド ユーザーがアクセスできるようにするのは良いことです。
Streamlit を使用したデータセットの展開
データを分析し、テスト データセットで f88_score の 1% の機械学習モデルを構築したので、ML パイプラインに進み、streamlit ライブラリを使用して Web インターフェイスを開発します。 Streamlit を使用して機械学習を利用した Web アプリケーションを作成するのは非常に簡単です。フロントエンド テクノロジの知識は必要ありません。 さらに、Streamlit はカスタム サブドメイン名を使用した無料のクラウド展開を提供するため、ML を利用したアプリケーションを展開するための好ましいオプションになります。
モデル オブジェクトの保存と入力フィーチャの選択から始めましょう。 Web アプリケーションから機械学習モデルを推測する Web アプリケーションを構築するための 10 の機能を選択しました。 これとは別に、順序エンコーダ オブジェクトも保存して、カテゴリ入力をそれぞれのエンコーディングに変換します。
# データフレームから 7 つのカテゴリ機能を選択 import joblib from sklearn.preprocessing import OrdinalEncoder new_fea_df = feature_df[['Type_of_collision','Age_band_of_driver','Sex_of_driver', 'Educational_level','Service_year_of_vehicle','Day_of_week','Area_accident_occured']] oencoder2 = OrdinalEncoder() encoded_df3 = pd.DataFrame(oencoder2.fit_transform(new_fea_df)) encoded_df3.columns = new_fea_df.columns # 推論パイプライン用に序数エンコーダー オブジェクトを保存します joblib.dump(oencoder, "ordinal_encoder2.joblib")
ここで、XNUMX つのカテゴリ特徴と XNUMX つの数値特徴を組み合わせて、推論用の最終モデルをトレーニングします。
# モデル推論のためにトレーニングされる最終的なデータフレーム s_final_df = pd.concat([feature_df[['Number_of_vehicles_involved','Number_of_casualties','Hour_of_Day']],encoded_df3], axis=1) # トレーニングとテストの分割とベースライン モデルの構築ターゲット機能を予測 X_trn2, X_tst2, y_trn2, y_tst2 = train_test_split(s_final_df, y_en, test_size=0.2, random_state=42) # ランダム フォレスト ベースラインを使用したモデリング rf = RandomForestClassifier(n_estimators=700, max_depth=20, random_state=42) rf.fit (X_trn2, y_trn2) # モデルオブジェクトを保存 joblib.dump(rf, "rta_model_deploy3.joblib", compress=9)
以下の XNUMX つのファイルをプロジェクト リポジトリに読み込みます。
- Requirements.txt
- app.py
- ordinal_encoder2.joblib
- rta_model_deploy3.joblib
すべての依存関係を requirements.txt にロードします
pandas numpy streamlit scikit-learn joblib shap matplotlib ipython Pillow
app.py ファイルを作成し、フォームベースのユーザー インターフェイスを使用して推論パイプラインを記述し、エンド ユーザーからの入力を取得して交通事故の重大度を予測します。
# すべてのアプリの依存関係をインポートする import pandas as pd import numpy as np import sklearn import streamlit as st import joblib import shhap import matplotlib from IPython import get_ipython from PIL import Image # エンコーダーとモデル オブジェクトを読み込む model = joblib.load("rta_model_deploy3. joblib") encoding = joblib.load("ordinal_encoder2.joblib") st.set_option('deprecation.showPyplotGlobalUse', False) # 1:重傷、2:軽傷、0:致命傷 st.set_page_config(page_title="事故重大度予測アプリ", page_icon="🚧", layout="wide") #ドロップダウンメニューのオプションリスト作成 options_day = ['Sunday', "Monday", "Tuesday", "Wednesday", "Thursday", "Friday" , "Saturday"] options_age = ['18-30', '31-50', 'Over 51', 'Unknown', 'Under 18'] # 関係する車両の数: 1 から 7 の範囲 # 犠牲者の数: 1 から 8 の範囲 # 0 日の時間: 23 から 2 の範囲 options_types_collision = ['Vehicle with vehicle collision','Collision with roadside objects', 'Collision with歩行者','Roll over','動物との衝突', '不明','路上駐車車両との衝突','車両からの落下', 'その他','電車あり'] options_sex = ['男性','女性','不明'] options_education_level = ['中学校','小学校','高等学校','不明','高校以上','読み書き能力','文盲'] options_services_year = ['不明','5 -10yrs','5yr以上','10-1yrs','2-1yr','XNUMXyr未満'] options_acc_area = ['その他', 'オフィスエリア', '住宅エリア', '教会エリア', '工業地域', '学校地域', 'レクリエーション地域', '農村地域外', '病院地域', '市場地域', '農村地域', '不明', '農村地域オフィス地域', 'レクリエーション地域' ] # features list features = ['Number_of_vehicles_involved','Number_of_casualties','Hour_of_Day','Type_of_collision','Age_band_of_driver','Sex_of_driver', 'Educational_level','Service_year_of_vehicle','Day_of_week','Area_accident_occured']
一度、ユーザーから取得するすべての入力を定義すると、「main()」関数を定義して、フロント エンドでレンダリングされる UI を開発できます。
# HTML 構文 st.markdown(" を使用して Web アプリにタイトルを付けます
事故重大度予測アプリ 🚧
", unsafe_allow_html=True) # フォーム ベースのアプローチでユーザーからの入力を取得する main() 関数を定義します。 No_vehicles = st.slider("関与した車両数:",1,7, value=0, format="%d") No_casualties = st.slider("死傷者数:",1,8, value=0, format="%d") Hour = st.slider("時刻:", 0, 23, value=0, format="%d") collision = st.selectbox("衝突の種類:",options =options_types_collision) Age_band = st.selectbox("ドライバーの年齢層?:", options=options_age) Sex = st.selectbox("ドライバーの性別:", options=options_sex) Education = st.selectbox("ドライバーの教育: ",options=options_education_level) service_vehicle = st.selectbox("車両のサービス年度:", options=options_services_year) Day_week = st.selectbox("曜日:", options=options_day) Accident_area = st.selectbox("地域事故の:", options=options_acc_area) submit = st.form_submit_button("Predict") # enc オーディナル エンコーダーを使用して送信し、送信するかどうかを予測します: num_arr = [No_vehicles,No_casualties,Hour] pred_arr = np.array(num_arr + encoded_arr).reshape(2,-1) # すべての入力フィーチャからターゲットを予測します predict = model.predict(pred_arr) if predict == 1: st.write(f"重症度予測は致命傷です⚠") elif predict == 0: st.write(f"重症度予測は重傷です") else: st.write(f"重症度予測は軽傷です" ) st.subheader("予測を理解するための説明可能な AI (XAI)") # shap ライブラリを使用した説明可能な AI shap.initjs() shap_values = shap.TreeExplainer(model).shap_values(pred_arr) st.write(f"For 予測}") shap.force_plot(shap.TreeExplainer(model).expected_value[1], shap_values[0], pred_arr, feature_names=features, matplotlib=True,show=False).savefig("pred_force_plot.jpg", bbox_inches='tight') img = Image.open("pred_force_plot.jpg") # フロントエンドで shap プロットをレンダリングして予測を説明する st.image(img, caption='Shap を使用したモデルの説明') st.write("開発者: Avi kumar Talaviya") st.markdown("""連絡先: [Twitter](https://twitter.com/avikumart_) | [Linkedin](https://www.linkedin.com/in/avi-kumar-talaviya-0/) | [Kaggle](https://www.kaggle.com/avikumart) """)
最後に、フロント エンドにプロジェクトの説明と問題の説明を書き留めて、取り組んできたプロジェクトを明確に紹介します。
a,b,c = st.columns([0.2,0.6,0.2]) with b: st.image("vllkyt19n98psusds8.jpg", use_column_width=True) # プロジェクトとコード ファイルに関する説明 st.subheader("🧾Description :") st.text("""このデータセットは、修士の研究活動のためにアディスアベバ市の警察署から収集されたものです。このデータセットは、2017 年から 20 年の道路交通事故のマニュアル文書から作成されました。データのエンコード中に情報が除外され、最終的に 32 の特徴と 12316 の事故事例が含まれています。その後、前処理され、さまざまな機械学習分類アルゴリズムを使用して分析することにより、事故の主な原因を特定します。""") st.markdown ("データセットのソース: [ここをクリック](https://www.narcis.nl/dataset/RecordID/oai%3Aeasy.dans.knaw.nl%3Aeasy-dataset%3A191591)") st.subheader("🧭 Problem Statement:") st.text("""ターゲット フィーチャは、マルチクラス変数である Accident_severity です。タスクは、この変数を他の 31 変数に基づいて分類することです。 毎日のタスクを実行することで、段階的に機能します。 評価の指標は f1-score """) st.markdown("プロジェクトの GitHub リポジトリ リンクを見つけてください: [ここをクリック](https://github.com/avikumart/Road-Traffic-Severity-Classification-Project )") # メイン関数を実行 if __name__ == '__main__': main()
それでおしまい! プロジェクト ファイルを github リポジトリにプッシュし、streamlit アカウントにサインインするだけで、ワンクリックで Streamlit アプリを起動できます。
streamlit でアプリをデプロイする方法の詳細については、Analytics Vidhya で公開された以前の記事をご覧ください — ここをクリック
プロジェクトリポジトリにアクセスできます こちら
デプロイされた Web アプリケーションを表示できます こちら
まとめ
結論として、エンド ツー エンドのデータ サイエンスと機械学習プロジェクトは、データ分析と予測を使用して交通事故死の防止を支援する可能性を提示することに成功しました。 提供されたデータを徹底的に分析し、機械学習モデルをトレーニングして潜在的な事故の深刻度を予測することにより、調査機関は最もリスクの高い状況に向けてその取り組みとリソースを優先することができます。 このプロジェクトは、複雑な問題に対処するためにデータ駆動型のアプローチを使用することの価値と、これらのイニシアチブへの継続的な投資の重要性を強調しています。 この記事の重要なポイントを見てみましょう。
- 予測分析を実行するには、問題とその基礎となるデータを完全に理解する必要があります。
- インサイトを見つけ、データセットを前処理して機械学習モデルを開発するための探索的データ分析。
- ワンクリックで機械学習パイプラインを開発し、ストリームリット クラウドにデプロイ
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/01/machine-learning-solution-predicting-road-accident-severity/

