概要
中心に データサイエンス 統計は何世紀にもわたって存在し、今日のデジタル時代においても依然として根本的に不可欠なものです。なぜ?基本的な統計概念がバックボーンであるため、 データ分析、 これにより、毎日生成される膨大なデータを理解できるようになります。それはデータと会話するようなもので、統計は適切な質問をし、データが伝えようとするストーリーを理解するのに役立ちます。
将来の傾向の予測やデータに基づく意思決定から、仮説の検証やパフォーマンスの測定まで、統計はデータに基づいた意思決定の背後にある洞察を強化するツールです。これは生データと実用的な洞察の間の架け橋であり、データ サイエンスに不可欠な部分となっています。
この記事では、データ サイエンスの初心者が知っておくべき基本的な統計概念トップ 15 をまとめました。

目次
1. 統計的サンプリングとデータ収集
いくつかの基本的な統計概念を学びますが、データの海に深く飛び込む前に、データがどこから来てどのように収集されるかを理解することが不可欠です。ここで、母集団、サンプル、さまざまなサンプリング手法が登場します。
ある都市の人々の平均身長を知りたいと想像してください。すべての人を測定するのが現実的であるため、より大きな母集団を代表するより小さなグループ (サンプル) を採取します。秘訣は、このサンプルの選択方法にあります。ランダム、層化、クラスターサンプリングなどの手法により、サンプルが適切に表現されるようになり、バイアスが最小限に抑えられ、結果の信頼性が高まります。
母集団とサンプルを理解することで、自信を持ってサンプルから母集団全体に洞察を拡張し、全員を調査することなく情報に基づいた意思決定を行うことができます。
2. データの種類と測定スケール
データにはさまざまな種類があり、適切な統計ツールと手法を選択するには、扱っているデータの種類を知ることが重要です。
定量的および定性的データ
- 定量的データ: このタイプのデータはすべて数値に関するものです。測定可能であり、数学的な計算に使用できます。定量的なデータは、Web サイトにアクセスするユーザーの数や都市の気温など、「どれだけ」または「何人」かを教えてくれます。単純かつ客観的であり、数値を通じて明確な全体像を提供します。
- 定性的データ: 逆に、定性データは特性と説明を扱います。それは「どのタイプ」か「どのカテゴリー」かです。車の色や本のジャンルなど、品質や属性を記述するデータと考えてください。このデータは主観的なものであり、測定ではなく観察に基づいています。
XNUMXつの尺度
- 公称スケール: これは、特定の順序なしでデータを分類するために使用される最も単純な測定形式です。例には、料理の種類、血液型、国籍などが含まれます。定量的な価値を持たないラベル付けについてです。
- 順序スケール: ここでデータを並べ替えたりランク付けしたりできますが、値間の間隔は定義されていません。満足、どちらでもない、不満などの選択肢がある満足度調査を考えてみましょう。順位はわかりますが、ランキング間の距離はわかりません。
- インターバルスケール: 間隔は注文データをスケールし、エントリ間の差異を定量化します。ただし、実際にはゼロ点はありません。良い例は摂氏での温度です。 10°C と 20°C の差は 20°C と 30°C の差と同じですが、0°C は温度が存在しないことを意味するわけではありません。
- 比率スケール: 最も有益なスケールには、間隔スケールのすべてのプロパティに加えて意味のあるゼロ点が含まれており、大きさを正確に比較できます。例としては、体重、身長、収入などが挙げられます。ここで、あるものが別のものの 2 倍であると言えます。
3。 記述統計
Imagine 記述統計 データの最初の日付として。それは、目の前にあるものを説明する基本、大まかなストロークを知ることです。記述統計には、中心傾向と変動性測定という 2 つの主なタイプがあります。
中心的傾向の尺度: これらはデータの重心のようなものです。これらは、データセットの典型または代表的な単一の値を提供します。
平均: 平均は、すべての値を合計し、値の数で割ることによって計算されます。すべてのレビューに基づいたレストランの総合評価のようなものです。平均の数式は次のとおりです。

中央値: データを最小値から最大値の順に並べたときの中央の値。観測値の数が偶数の場合、それは中央の 2 つの数値の平均です。橋の中点を見つけるために使用されます。
n が偶数の場合、中央値は中央の 2 つの数値の平均になります。
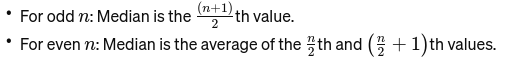
モード: それは、 データセット内で最も頻繁に出現する値。レストランで最も人気のある料理と考えてください。
変動性の尺度: 中心傾向の尺度は私たちを中心に導きますが、変動の尺度は広がりまたは分散を教えてくれます。
測定レンジ: 最高値と最低値の差。スプレッドの基本的な考え方を示します。
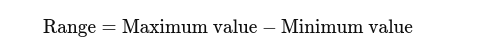
分散: セット内の各数値が平均から、つまりセット内の他のすべての数値からどれだけ離れているかを測定します。サンプルとしては、次のように計算されます。
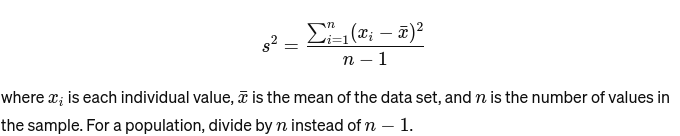
標準偏差: 分散の平方根は、平均からの平均距離の尺度を提供します。それはパン屋のケーキのサイズの一貫性を評価するようなものです。それは次のように表されます。
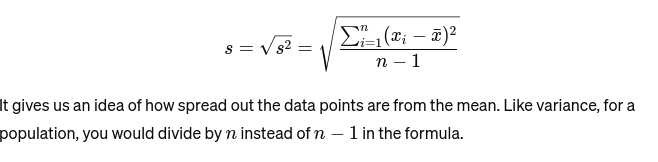
次の基本的な統計概念に進む前に、次のことを説明します。 統計分析の初心者ガイド あなたのため!
4. データの可視化
データの視覚化 データを使ってストーリーを伝える技術と科学です。分析による複雑な結果を具体的で理解しやすいものに変換します。これは、まだ正式な結論を下すことなく、データからパターン、相関関係、洞察を明らかにすることが目標である探索的データ分析にとって非常に重要です。
- チャートとグラフ: 基本から始めて、棒グラフ、折れ線グラフ、円グラフはデータに関する基礎的な洞察を提供します。これらはデータ視覚化の基礎であり、データ ストーリーテラーにとって不可欠です。
以下に棒グラフ (左) と折れ線グラフ (右) の例を示します。
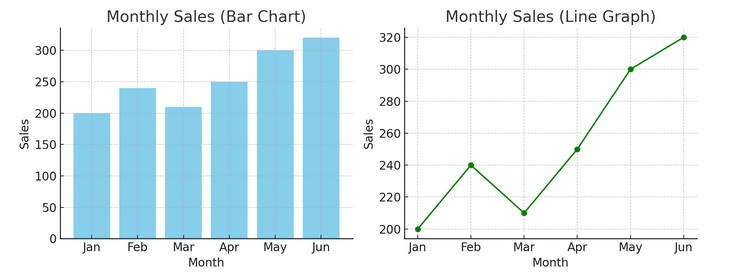
- 高度な視覚化: さらに詳しく調べると、ヒート マップ、散布図、ヒストグラムを使用して、より微妙な分析が可能になります。これらのツールは、傾向、分布、外れ値を特定するのに役立ちます。
以下は散布図とヒストグラムの例です。

ビジュアライゼーションは生データと人間の認知の橋渡しをし、複雑なデータセットを迅速に解釈して理解できるようにします。
5. 確率の基礎
確率 統計言語の文法です。それは出来事が起こる可能性または可能性についてです。確率の概念を理解することは、統計結果を解釈して予測を行うために不可欠です。
- 独立イベントと依存イベント:
- 独立したイベント: あるイベントの結果が別のイベントの結果に影響を与えることはありません。コインを投げるのと同じように、あるコインを投げて表が出ても、次のコインを投げる確率は変わりません。
- 依存イベント: あるイベントの結果は別のイベントの結果に影響を与えます。たとえば、デッキからカードを引き、それを置き換えなかった場合、別の特定のカードを引く可能性が変わります。
確率はデータに関する推論を行うための基礎を提供し、統計的有意性と仮説検定を理解するために重要です。
6. 共通確率分布
確率分布 それらは統計生態系における異なる種のようなもので、それぞれがそのニッチな用途に適応しています。
- 正規分布: その形状から釣鐘曲線と呼ばれることが多いこの分布は、平均と標準偏差によって特徴付けられます。現実世界では多くの変数がこのように自然に分布しているため、これは多くの統計テストで一般的な仮定です。
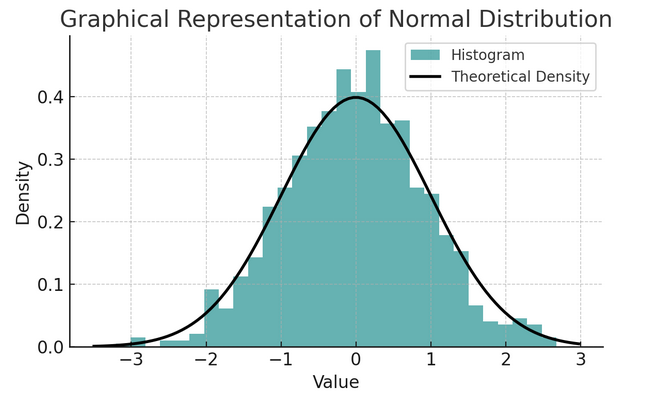
経験則または 68-95-99.7 ルールとして知られる一連のルールは、データが平均の周囲にどのように分散するかを説明する正規分布の特性を要約したものです。
68-95-99.7 ルール (経験則)
このルールは完全な正規分布に適用され、次の概要を示します。
- 視聴者の38%が データの平均値 (μ) の標準偏差 (σ) 1 以内に収まります。
- 視聴者の38%が データの 2 つの標準偏差が平均値の範囲内に収まります。
- 約 視聴者の38%が データの 3 つの標準偏差が平均値の範囲内に収まります。
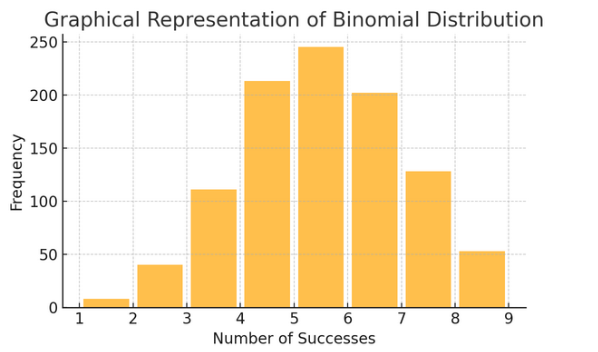
二項分布: この分布は、2 つの結果 (成功または失敗など) が数回繰り返される状況に適用されます。コインを投げたり、真偽テストを受けるなどのイベントをモデル化するのに役立ちます。
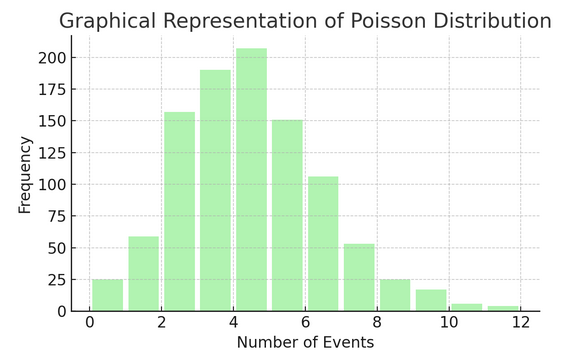
ポアソン分布 特定の間隔または空間で何かが発生した回数を数えます。毎日受信するメールのように、イベントが独立して継続的に発生する状況に最適です。
各分布には独自の一連の式と特性があり、適切なものを選択することは、データの性質と調べようとしている内容によって異なります。これらの分布を理解することで、統計学者やデータ サイエンティストは現実世界の現象をモデル化し、将来の出来事を正確に予測できるようになります。
7 。仮説検証
考える 仮説検定 統計学の探偵仕事として。これは、データに関する特定の理論が真実であるかどうかをテストする方法です。このプロセスは、次の 2 つの相反する仮説から始まります。
- 帰無仮説 (H0): これはデフォルトの仮定であり、そこに影響や違いがあることを示唆しています。ここでは「新しいものではない」と言っているのです。」
- Al「対立仮説 (H1 または Ha): これは現状に挑戦し、効果や違いを提案します。 「何か興味深いことが起こっている」と主張しています。
例: 新しいダイエット プログラムが、ダイエットを行わなかった場合と比較して体重減少につながるかどうかをテストします。
- 帰無仮説 (H0): 新しい食事プログラムは体重減少につながりません(新しい食事プログラムに従う人と従わない人の間で体重減少に差はありません)。
- 対立仮説 (H1): 新しいダイエットプログラムは体重減少につながります(それに従う人と従わない人の体重減少の差)。
仮説検証では、証拠 (当社のデータ) に基づいて、これら 2 つのうちのいずれかを選択します。
タイプ I および II のエラーと重大度レベル:
- タイプ I エラー: これは、帰無仮説を誤って棄却した場合に発生します。無実の人を有罪にするのです。
- タイプ II エラー: これは、偽の帰無仮説を棄却できなかった場合に発生します。罪を犯した人を釈放してくれるのです。
- 有意水準(α):これは 帰無仮説を棄却するのに十分な証拠がどれだけあるかを判断するためのしきい値。多くの場合、5% (0.05) に設定され、タイプ I エラーのリスクが 5% であることを示します。
8. 信頼区間
信頼区間 有効な母集団パラメーター (平均や割合など) が特定の信頼水準 (通常 95%) に収まると予想される値の範囲を指定します。これは、スポーツ チームの最終スコアを誤差の範囲内で予測するようなものです。私たちは、「実際のスコアはこの範囲内にあると 95% 確信しています」と言っているのです。
信頼区間を構築して解釈することは、推定の精度を理解するのに役立ちます。間隔が広いほど推定の精度は低くなり、その逆も同様です。
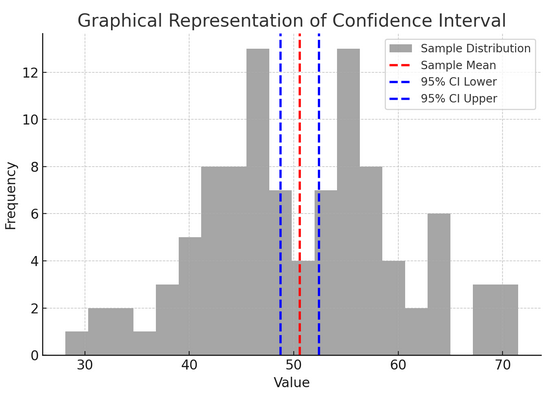
上の図は、標本分布と標本平均の周囲の 95% 信頼区間を使用して、統計における信頼区間 (CI) の概念を示しています。
図の重要なコンポーネントの内訳は次のとおりです。
- サンプル分布 (グレー ヒストグラム): これは、平均 100、標準偏差 50 の正規分布からランダムに生成された 10 個のデータ ポイントの分布を表します。ヒストグラムは、データ ポイントが平均の周囲にどのように広がっているかを視覚的に示します。
- サンプル平均 (赤い破線): この線はサンプル データの平均 (平均) 値を示します。これは、信頼区間を構築する際の点推定値として機能します。この場合、すべてのサンプル値の平均を表します。
- 95% 信頼区間 (青い破線): これらの 95 本の線は、サンプル平均値の周囲の 1.96% 信頼区間の下限と上限を示しています。区間は、平均の標準誤差 (SEM) と、必要な信頼レベル (95% の信頼度の場合は 95) に対応する Z スコアを使用して計算されます。信頼区間は、母平均がこの範囲内にあることを XNUMX% の信頼できることを示しています。
9. 相関関係と因果関係
相関関係と因果関係 よく混同されますが、次のような違いがあります。
- 相関: 1 つの変数間の関係または関連性を示します。一方が変化すると、もう一方も変化する傾向があります。相関は、-1 から 1 までの範囲の相関係数によって測定されます。1 または -0 に近い値は強い関係を示し、XNUMX は関係がないことを示します。
- 原因: これは、ある変数の変化が別の変数の変化を直接引き起こすことを意味します。これは相関よりも堅牢なアサーションであり、厳密なテストが必要です。
2 つの変数に相関があるからといって、一方がもう一方の原因になるとは限りません。これは、「相関関係」と「因果関係」を混同しない典型的なケースです。
10.単純な線形回帰
簡単な拡張で 線形回帰 は、観測データに線形方程式を当てはめることによって 2 つの変数間の関係をモデル化する方法です。 1 つの変数は説明変数 (独立) とみなされ、もう 1 つは従属変数と見なされます。
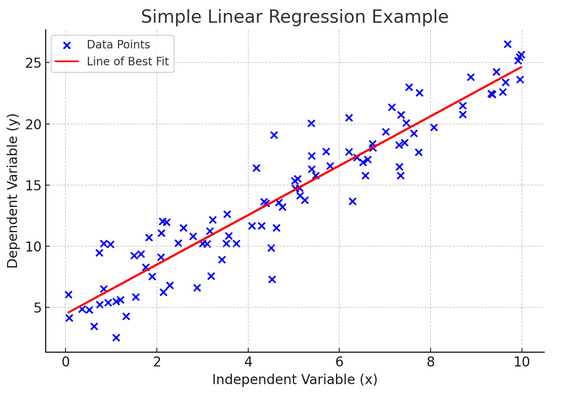
単純な線形回帰は、独立変数の変化が従属変数にどのような影響を与えるかを理解するのに役立ちます。これは予測のための強力なツールであり、他の多くの複雑な統計モデルの基礎となります。 2 つの変数間の関係を分析することで、それらがどのように相互作用するかについて情報に基づいた予測を行うことができます。
単純線形回帰では、独立変数 (説明変数) と従属変数の間に線形関係があると仮定します。これら 2 つの変数間の関係が線形でない場合、単純な線形回帰の仮定に違反する可能性があり、不正確な予測や解釈が生じる可能性があります。したがって、単純な線形回帰を適用する前に、データ内の線形関係を検証することが不可欠です。
11.重回帰
多重線形回帰は、単純な線形回帰の拡張として考えてください。それでも、輝く鎧を着た 1 人の騎士 (予測者) で結果を予測しようとするのではなく、チーム全体が必要になります。これは、1 対 1 のバスケットボール ゲームから、各プレーヤー (予測者) が独自のスキルをもたらすチーム全体の取り組みにアップグレードするようなものです。目的は、複数の変数が一緒になって単一の結果にどのような影響を与えるかを確認することです。
ただし、チームが大きくなると、多重共線性として知られる関係管理の課題が生じます。これは、予測子が互いに近づきすぎて、同様の情報を共有する場合に発生します。 2 人のバスケットボール選手が常に同じシュートを打とうとしていると想像してください。彼らはお互いの邪魔になる可能性があります。回帰により、各予測子の固有の寄与を確認することが難しくなり、どの変数が重要であるかについての理解が歪む可能性があります。
12.ロジスティック回帰
線形回帰は連続的な結果 (気温や価格など) を予測しますが、 ロジスティック回帰 結果が明確な場合 (はい/いいえ、勝ち/負けなど) に使用されます。さまざまな要因に基づいてチームが勝つか負けるかを予測しようとしていると想像してみてください。ロジスティック回帰が頼りになる戦略です。
線形方程式を変換して、その出力が 0 と 1 の間に収まり、特定のカテゴリに属する確率を表します。これは、連続スコアを明確な「あれか」のビューに変換する魔法のレンズを持っているようなもので、カテゴリ的な結果を予測できるようになります。
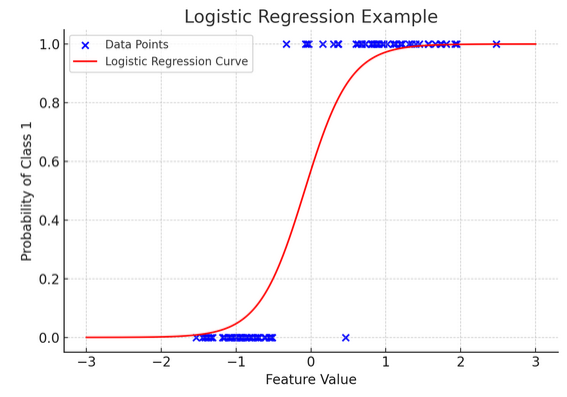
このグラフ表示は、合成バイナリ分類データセットに適用されるロジスティック回帰の例を示しています。青い点はデータ ポイントを表し、x 軸に沿った位置は特徴値を示し、y 軸はカテゴリ (0 または 1) を示します。赤い曲線は、さまざまな特徴値に対するクラス 1 (たとえば、「勝ち」) に属する確率のロジスティック回帰モデルの予測を表します。ご覧のとおり、曲線はクラス 0 の確率からクラス 1 まで滑らかに移行しており、基礎となる連続特徴に基づいてカテゴリカルな結果を予測するモデルの能力を示しています。
ロジスティック回帰の式は次のように与えられます。

この式では、ロジスティック関数を使用して、線形方程式の出力を 0 と 1 の間の確率に変換します。この変換により、出力を独立変数 xx の値に基づいた特定のカテゴリに属する確率として解釈できます。
13. ANOVA とカイ二乗検定
ANOVA(分散分析) & カイ二乗検定 統計の世界の探偵のようなもので、さまざまな謎を解決するのに役立ちます。私t を使用すると、複数のグループの平均を比較して、少なくとも 1 つが統計的に異なるかどうかを確認できます。これは、クッキーのいくつかのバッチのサンプルを試食して、どのバッチの味が大きく異なるかどうかを判断することだと考えてください。
一方、カイ二乗検定はカテゴリデータに使用されます。これは、2 つのカテゴリ変数間に有意な関連があるかどうかを理解するのに役立ちます。たとえば、好きな音楽のジャンルと年齢層の間に関係はあるのでしょうか?カイ二乗検定は、このような質問に答えるのに役立ちます。
14. 中心極限定理とデータサイエンスにおけるその重要性
中心極限定理 (CLT) これは、ほとんど魔法のように感じられる基本的な統計原理です。これは、母集団から十分なサンプルを採取し、その平均値を計算すると、母集団の元の分布に関係なく、それらの平均値が正規分布 (釣鐘曲線) を形成することを示しています。これは、正確な分布がわからない場合でも、母集団について推論できるため、非常に強力です。
データ サイエンスでは、CLT が多くの技術を支えており、データが最初は基準を満たしていない場合でも、正規分布データ用に設計されたツールを使用できるようになります。それは、統計手法の汎用アダプターを見つけて、多くの強力なツールをより多くの状況に適用できるようにするようなものです。
15. バイアスと分散のトレードオフ
In 予測モデリング & 機械学習 偏りと分散のトレードオフ これは、モデルを狂わせる可能性がある 2 つの主なタイプのエラー間の緊張関係を強調する重要な概念です。バイアスとは、根本的な傾向をうまく捉えていない、過度に単純化されたモデルからの誤差を指します。曲がりくねった道路に直線を当てはめようとしているところを想像してみてください。的を外してしまうでしょう。逆に、複雑すぎるモデルの分散は、あたかも実際のパターンであるかのようにデータ内のノイズをキャプチャします。たとえば、すべてのねじれを追跡し、でこぼこした道を曲がって、それが進むべき道であると考えるようなものです。
重要なのは、これら 2 つのバランスをとって全体の誤差を最小限に抑え、モデルが適切なスイート スポットを見つけることです。正確なパターンをキャプチャするには十分複雑ですが、ランダム ノイズは無視できるほど単純です。それはギターをチューニングするようなものです。きつすぎたり緩すぎたりすると正しく聞こえません。 バイアスと分散のトレードオフ これら 2 つの間の完璧なバランスを見つけることが重要です。バイアスと分散のトレードオフは、結果を正確に予測する際に最大限のパフォーマンスを発揮するように統計モデルを調整する上での本質です。
まとめ
統計的サンプリングからバイアスと分散のトレードオフに至るまで、これらの原則は単なる学術的な概念ではなく、洞察力に富んだデータ分析に不可欠なツールです。意欲的なデータ サイエンティストに膨大なデータを実用的な洞察に変えるスキルを提供し、デジタル時代におけるデータ主導の意思決定とイノベーションのバックボーンとしての統計を強調します。
統計に関する基本的な概念を見逃していませんか?以下のコメント欄でお知らせください。
私たちの探検 エンドツーエンドの統計ガイド データ サイエンスに関するトピックについて知るための情報です。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

