
編集者による画像
世界がデジタル化に向かって進んでいるため、現在、ほとんどの企業はデータ駆動型になっています。 彼らが収集する膨大な量のデータは、データベースに保存されます。 このデータの管理・分析・加工は、DBMS(Database Management System)によって行われます。 この変化の結果として、データ サイエンスは、無数の雇用機会を持つ最も新しい分野の XNUMX つとして登場しました。 データサイエンティストはデータベースからデータを抽出する必要があり、ここで SQL が活躍します。 この分野をマスターするための最高のデータ サイエンス スキルについて聞いたことがあるはずです。SQL はその XNUMX つです。 さて、問題は次のとおりです。 優れたデータ サイエンティストとして SQL を習得する必要は本当にあるのでしょうか?
答えは NO ですが、SQL は多くのデータベース システムの標準になっているため、SQL の基本的な知識が必要です。 この記事は、知っておく必要があり、データ サイエンスの専門家が推奨する SQL のすべての重要な要素に言及することを目的としています。
SQL は Structured Query Langage の略で、リレーショナル データベースの管理を目的としています。 まず、データ サイエンスにおける SQL の必要性を理解しましょう。 それがユニークで、データ サイエンスで最も人気のあるスキルの XNUMX つである理由は何ですか? その重要性を理解するのに役立ついくつかのポイントを以下に示します。
- 幅広い用途: 約 40 年前のものですが、大部分のリレーショナル データベース システムでクエリに使用され、データを実験するための標準ツールになっています。
- データの理解を簡素化: SQL は、データベースのコンテンツをナビゲートする際に非常に便利です。 特徴を効果的に理解させてくれます。
- 習得が容易: これは、英語に似たシンプルな構文を備えた初心者にとって完璧な出発点であり、わずか数行のコードで貴重な洞察を引き出すことができます。
- 大量のビッグデータの処理を可能にします: SQL を使用すると、膨大な量のデータを整理された方法で管理できるため、データ サイエンス アプリケーションにとって理想的な選択肢となります。
- 他のプログラミング言語およびアプリケーションとの互換性: SQL を Python、C++、R などの言語と統合すると非常に便利です。 また、Power BI や Tableau などのビジネス インテリジェンスおよびデータ視覚化ツールもサポートされているため、開発プロセスが少し簡単になります。
1) 基本的なコマンドの理解
基本的なコマンドの知識は、生涯学習の基礎を築きます。 そうしないと、事実がどのように組み合わされているかを理解せずに、事実を暗記するだけになってしまいます。 最も一般的に使用される SQL コマンドの一部を以下に示します。
- 選択してから: 上記のテーブルからデータの属性を取得します。
- SELECT DISTINCT: 重複する行が削除され、一意のレコードのみが表示されます。
- WHERE: レコードをフィルタリングし、指定された条件を満たすレコードのみを表示します。
- AND、OR、NOT: 条件が True でない場合、クエリを実行しません。 一方、AND と OR は、複数の条件を適用するために使用されます。
- ORDER BY: データを昇順または降順でソートします
- GROUP BY: 同一のデータをグループ化します。
- 持っている: Group By によって集計されたデータは、ここでさらに除外できます。
- 集計関数: COUNT()、MAX()、MIN()、AVG()、SUM() などの集計関数は、指定されたデータに対して操作を実行するために使用されます。
それらを従業員テーブルに適用する例を見てみましょう。
| ID | 名前 | 部門 | 給与($) | 性別 |
| 1 | ジュリア | 20000 | F | |
| 2 | ジャスミン | 15000 | F | |
| 3 | John Redfern | IT | 20000 | M |
| 4 | Mark Hodder | 17000 | M |
ここで、管理部門で働く女性の平均給与を取得したいと考えています。
SELECT Department, AVG(Salary)
FROM Employees
WHERE Gender="F"
GROUP BY Department
HAVING Department = "Admin";
出力:
Admin | 17500.02) ケース
これは、複雑な条件ステートメントを記述するために使用される、SQL の非常に強力で柔軟なステートメントです。 IF.THEN.ELSE ステートメントの機能を提供します。 その構文を見てみましょう。
CASE expression WHEN value_1 THEN result_1 WHEN value_2 THEN result_2 ... WHEN value_n THEN result_n ELSE result END
ステートメントを順番に実行し、条件が True になるとすぐに値を返します。 どの条件も満たされない場合は ELSE ブロックが実行され、存在しない場合は NULL が返されます。
学生データベースがあり、成績に基づいて学生を採点したいとします。次の SQL ステートメントを使用できます。
SELECT student_name, marks, CASE WHEN marks >= 85 THEN 'A' WHEN marks >= 75 AND marks 85 THEN 'B+' WHEN marks >= 65 AND marks 75 THEN 'B' WHEN marks >= 55 AND marks 65 THEN 'C' WHEN marks >= 45 AND marks 55 THEN 'D' ELSE 'F' END AS grading
FROM Students;
3) サブクエリ
サブクエリはさまざまなテーブルを操作する必要があり、XNUMX つのクエリの結果を再度使用してメイン クエリのデータをさらに制限する場合があるため、データ サイエンティストとして、サブクエリの知識は不可欠です。 これは、ネストされたクエリまたは内部クエリとも呼ばれます。 サブクエリは括弧で囲む必要があり、メイン クエリの前に実行されます。 複数の行を返す場合、それは複数行のサブクエリと呼ばれ、複数行の演算子を使用する必要があります。
保険会社が新しい保険を導入し、年齢が 80 歳を超えた人々の保険を解約するとします。これは、次のサブクエリを使用して行うことができます。
DELETE
FROM INSURANCE_CUSTOMERS
WHERE AGE IN (SELECT AGE FROM INSURANCE_CUSTOMERS WHERE AGE > 80 );
内部サブクエリは、80 歳以上のすべての顧客を選択し、このグループに対して削除操作を実行します。
4)参加する
SQL 結合は、複数のテーブルの行をそれらの間の論理関係に基づいて結合するために使用されます。 4 種類の SQL 結合を以下に示します。
- 内部結合: 内部結合は、指定された条件を満たす両方のテーブルの行のみを表示します。 これは、セット用語で交差点と呼ぶことができます。

SELECT Student.Name
FROM Student
INNER JOIN Sports ON Student.ID = Sports.ID;
スポーツに登録した学生を返します。 注: スポーツ ID は、学生の登録 ID と同じです。
- 左結合: LEFT テーブルのすべてのレコードを返し、右側のテーブルの一致するレコードのみが表示されます。
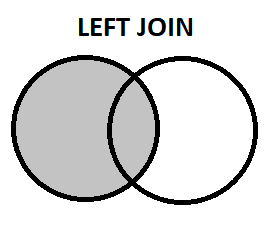
SELECT Student.Name
FROM Student
LEFT JOIN Sports ON Student.ID = Sports.ID;
- 右参加: 左結合とは正反対です。
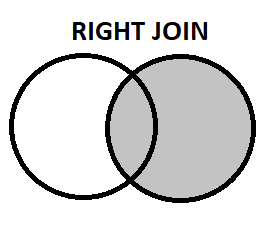
SELECT Student.Name
FROM Student
RIGHT JOIN Sports ON Student.ID = Sports.ID;
- 完全結合: 両方のテーブルのすべての行が含まれており、対応する一致するエントリがない場合は NULL 値が表示されます。
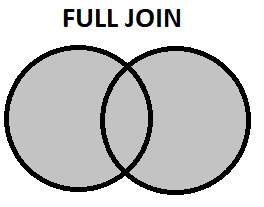
SELECT Student.Name
FROM Student
FULL JOIN Sports ON Student.ID = Sports.ID;
5) ストアド プロシージャ
ストアド プロシージャを使用すると、複数の SQL ステートメントをデータベースに格納して後で使用できます。 これにより、再利用が可能になり、呼び出し時にパラメーター値を受け入れることもできます。 パフォーマンスが向上し、変更が容易になります。
CREATE PROCEDURE SelectStudents @Major nvarchar(30), @Grade char(1) AS
SELECT *
FROM Students
WHERE Major = @Major AND Grade = @Grade GO; EXEC SelectStudents @Major = 'Data Science', @Grade = 'A';
この手順により、成績に基づいてさまざまな専攻の学生を抽出できます。 たとえば、データ サイエンスを専攻し、成績が A の学生をすべて抽出しようとしています。 CREATE PROCEDURE は関数宣言と同様であり、実行のために EXEC を使用して呼び出す必要があることに注意してください。
6) 文字列のフォーマット
全体的な生産性を向上させ、質の高い意思決定を行うには、生データをクリーンアップする必要があることは誰もが知っています。 このコンテキストでは文字列の書式設定が大きな役割を果たし、文字列を操作して無関係なものを削除する必要があります。 SQL には、文字列を変換して操作するためのさまざまな文字列関数が用意されています。 それらの中で最も一般的に使用される5つは次のとおりです。
- 連結: XNUMX つ以上の文字列を一緒に追加するために使用されます。
SELECT CONCAT(Name, ' has a major of ', Major)
FROM Students
WHERE student_Id = 37;
- サブストリング: 文字列の一部を返し、パラメータで返される部分文字列の開始位置と長さを取ります。
SELECT student_name,admission_date, SUBSTR(admission_date, 4, 2) AS day
FROM Students
日付列は、admission_date から抽出されたものとは別に表示されます。
- トリム: トリミングの主な仕事は、文字列の先頭、文字列の末尾、または指定されている場合はその両方から文字を削除することです。 先頭、末尾、またはその両方を指定し、次に削除する文字を指定し、その後に削除する文字列を指定する必要があります。
SELECT age, TRIM(trailing ' years' FROM age)
FROM Students
「26歳」が「26」に変わります。
- インサート: 指定された文字列内の指定された位置に文字列を挿入できます。 書き込みたい新しい部分文字列の位置と長さを指定する必要があります。 この新しい文字列は以前のテキストを上書きすることに注意してください。
SELECT INSERT("OldWebsite.com", 1, 9, "NewWebsite");
NewWebsite.comに更新されます。
- COALESCE: これを使用して、null 値を、データ サイエンスでしばしば必要とされるユーザー定義の値に置き換えることができます。
SELECT COALESCE (NULL, NULL, 10, 'John’')
これは10を返します。
7) ウィンドウ機能
ウィンドウ関数は集計関数に似ていますが、計算後に行が単一の行に折りたたまれることはありません。 代わりに、行は個別の ID を保持します。 これらは、次の XNUMX つの主要なカテゴリに分類されます。
- 集計関数: AVG()、COUNT()、MAX()、MIN()、SUM()などの数値列からの集計値が表示されます。
SELECT name, AVG(salary) over (PARTITION BY department) FROM Employees;
Employees テーブルからのさまざまな部門の平均給与が表示されます。
- 値関数: 各パーティションには、値ウィンドウ関数を使用していくつかの値が割り当てられます。 最も一般的に使用される値関数には、LAG()、LEAD()、FIRST_VALUE()、LAST_VALUR()、および NTH_VALUE() があります。
SELECT bank_branch, month, income, LAG(income,1) OVER ( PARTITION BY bank_branch ORDER BY month ) income_next_month
FROM Bank;
当月の銀行のさまざまな支店の収入を前月と比較します。
- ランキング機能: これらは、事前定義された順序に基づいて行にランキングを割り当てるのに役立ちます。
SELECT product_name, price, RANK () OVER ( ORDER BY list DESC ) price_hightolow
FROM Products;
製品は、RANK() を使用して価格に基づいてランク付けされます。
この記事をお読みいただき、データ サイエンティストとしてどれだけの SQL を知る必要があるかを包括的に理解していただければ幸いです。 これらの概念をさらに深く掘り下げたい場合は、次のリソースを参考にしてください。
W3Schools
カンワル・メーリーン は、データ サイエンスと医療における AI の応用に強い関心を持つ意欲的なソフトウェア開発者です。 Kanwal は、APAC 地域の Google Generation Scholar 2022 に選ばれました。 Kanwal は、流行のトピックに関する記事を書いて技術知識を共有することを好み、技術業界における女性の割合を改善することに情熱を注いでいます。
- コインスマート。 ヨーロッパで最高のビットコインと暗号通貨取引所。ここをクリック
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2022/11/7-sql-concepts-needed-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=7-sql-concepts-you-should-know-for-data-science

