概要
この記事では、データベースまたはデータ システム内でデータがどのように保存、編成、アクセスされるかを概説する重要なプロセスであるデータ モデリングの概念を紹介します。これには、現実世界のビジネス ニーズを、データベースまたはデータ ウェアハウスで実現できる論理的で構造化された形式に変換することが含まれます。データ モデリングが、組織または特定のドメイン内のデータの関係と相互接続を理解するための概念的なフレームワークをどのように作成するかを検討します。さらに、データの保存、取得、操作を効率的に行うためのデータ構造と関係の設計の重要性についても説明します。

データモデリングの使用例
データ モデリングは、さまざまなシナリオにわたってデータを効果的に管理および利用するための基礎です。ここでは、データ モデリングの典型的な使用例をいくつか示し、それぞれについて詳しく説明します。
データ捕捉(日本未発売)
データ モデリングでは、データの取得には、さまざまなソースからデータを収集または生成する方法を定義することが含まれます。このフェーズには、受信データを保持するために必要なデータ構造を確立し、データを効率的に統合して保存できるようにすることが含まれます。この段階でデータをモデル化することで、組織は収集されたデータが分析ニーズやビジネス プロセスに合わせて構造化されていることを確認できます。これは、必要なデータの種類、データの形式、さらに使用するためにデータがどのように処理されるかを特定するのに役立ちます。
データの読み込み
データを取得したら、データベースなどのターゲット システムにロードする必要があります。 データウェアハウス、またはデータレイク。データ モデリングは、データが挿入されるスキーマまたは構造を定義することにより、ここで重要な役割を果たします。これには、さまざまなソースからのデータをデータベースのテーブルと列にマッピングする方法の指定や、さまざまなデータ エンティティ間の関係の設定が含まれます。適切なデータ モデリングにより、データが最適にロードされ、効率的なストレージ、アクセス、クエリのパフォーマンスが促進されます。
ビジネス計算
データ モデリングは、ビジネス計算のフレームワークを設定するために不可欠です。これらの計算により、保存されたデータから洞察、指標、および主要業績評価指標 (KPI) が生成されます。明確なデータ モデルを確立することで、組織はさまざまなソースからのデータを集約、変換、分析して複雑なビジネス計算を実行する方法を定義できます。これにより、基礎となるデータが意味のある正確な情報の導出をサポートすることが保証されます。 ビジネス・インテリジェンス、意思決定と戦略計画の指針となります。
販売
配布フェーズでは、処理されたデータがエンドユーザーまたは他のシステムで分析、レポート、意思決定に利用できるようになります。この段階でのデータ モデリングは、対象ユーザーがアクセス可能で理解できる方法でデータが構造化およびフォーマットされていることを確認することに重点を置きます。これには、ビジネス インテリジェンス ツールで使用するためのデータの次元スキーマへのモデル化、プログラムによるアクセスのための API の作成、またはデータ共有のためのエクスポート形式の定義が含まれる場合があります。効果的なデータ モデリングにより、データをさまざまなプラットフォーム間で、さまざまな関係者が簡単に配布および利用できるようになり、その有用性と価値が高まります。
これらの各ユースケースは、収集、保管から分析、配布まで、データのライフサイクル全体における重要性を示しています。各段階でデータ構造と関係を慎重に設計することで、組織はデータ アーキテクチャが運用および分析のニーズを効率的かつ効果的にサポートできるようになります。
データ エンジニア/モデラー
データエンジニア データモデラーとデータモデラーは、データの管理と分析において重要な役割を果たし、組織内でデータの力を活用するために独自のスキルと専門知識を提供します。互いの役割と責任を理解することは、堅牢なデータ インフラストラクチャを構築および維持するために相互に連携する方法を明確にするのに役立ちます。
データエンジニア
データ エンジニアは、データの効率的な処理とアクセスを可能にするシステムとアーキテクチャの設計、構築、保守を担当します。彼らの役割には多くの場合、次のことが含まれます。
- データ パイプラインの構築と維持: これらは、さまざまなソースからデータを抽出、変換、ロードするためのインフラストラクチャ (ETL) を作成します。
- データの保存と管理: データを整理してアクセスできる状態に保つために、データベース システム、データ レイク、その他のストレージ ソリューションを設計および実装します。
- パフォーマンスの最適化: データ エンジニアは、多くの場合、データ ストレージとクエリの実行を最適化することで、データ プロセスが効率的に実行されるように努めます。
- ステークホルダーとのコラボレーション: ビジネス アナリスト、データ サイエンティスト、その他のユーザーと緊密に連携して、データのニーズを理解し、データに基づいた意思決定を可能にするソリューションを実装します。
- データの品質と整合性の確保: データを監視、検証、クリーンアップするためのシステムとプロセスを実装し、ユーザーが信頼性の高い正確な情報にアクセスできるようにします。
データモデラー
データ モデラーは、次の青写真の設計に重点を置きます。 データ管理システム。彼らの仕事には、ビジネス要件を理解し、それらを効率的なデータの保存、取得、分析をサポートするデータ構造に変換することが含まれます。主な責任には以下が含まれます。
- 概念的、論理的、物理的なデータ モデルの開発: 彼らは、データがどのように関連付けられ、どのようにデータベースに保存されるかを定義するモデルを作成します。
- データ エンティティと関係の定義: データ モデラーは、組織のデータ システムが表現する必要がある主要なエンティティを特定し、これらのエンティティが相互にどのように関連するかを定義します。
- データの一貫性と標準化の確保: データ要素の命名規則と標準を確立して、組織全体の一貫性を確保します。
- データ エンジニアやアーキテクトとのコラボレーション: データ モデラーはデータ エンジニアと緊密に連携して、データ アーキテクチャが設計されたモデルを効果的にサポートしていることを確認します。
- データ ガバナンスと戦略: 多くの場合、データ ガバナンスにおいて役割を果たし、組織内のデータ管理のポリシーと標準の定義に役立ちます。
データ エンジニアとデータ モデラーのスキルとタスクには重複する部分もありますが、2 つの役割は相互に補完し合います。データ エンジニアはデータの保存とアクセスをサポートするインフラストラクチャの構築と維持に重点を置き、データ モデラーはこれらのシステム内のデータの構造と編成を設計します。これらにより、組織のデータ アーキテクチャが堅牢でスケーラブルであり、ビジネス目標と整合していることが保証され、効果的なデータドリブンの意思決定が可能になります。
データモデリングの主要なコンポーネント
データ モデリングは、効率的で拡張性があり、さまざまなアプリケーションの要件を満たすことができるデータベースとデータ システムを設計および実装する上で重要なプロセスです。主要なコンポーネントには、エンティティ、属性、関係、キーが含まれます。これらのコンポーネントを理解することは、一貫性のある機能的なデータ モデルを作成するために不可欠です。
エンティティ
エンティティは、明確に識別できる現実世界のオブジェクトまたは概念を表します。データベースでは、エンティティがテーブルに変換されることがよくあります。エンティティは、保存したい情報を分類するために使用されます。たとえば、顧客関係管理 (CRM) システムでは、典型的なエンティティには、「顧客」、「注文」、および Product.
Attributes
属性はエンティティのプロパティまたは特性です。これらはエンティティに関する詳細を提供し、エンティティをより完全に説明するのに役立ちます。データベース テーブルでは、属性は列を表します。 「顧客」エンティティの場合、属性には「顧客ID」、「名前」、「住所」、「電話番号」などが含まれます。属性は、各エンティティに保存されるデータ型(整数、文字列、日付など)を定義します。実例。
の関係
関係は、システム内のエンティティが互いにどのように接続されているかを記述し、それらの相互作用を表します。関係にはいくつかの種類があります。
- 1対1 (XNUMX:XNUMX): エンティティ A の各インスタンスはエンティティ B の 1 つのインスタンスのみに関連付けられ、その逆も同様です。
- 1 対多 (XNUMX:N): エンティティ A の各インスタンスは、エンティティ B の 0、1 つ、または複数のインスタンスに関連付けることができますが、エンティティ B の各インスタンスは、エンティティ A の 1 つのインスタンスのみに関連付けられます。
- 多対多 (M:N): エンティティ A の各インスタンスは、エンティティ B の 0、1 つ、または複数のインスタンスに関連付けることができ、エンティティ B の各インスタンスは、エンティティ A の 0、1 つ、または複数のインスタンスに関連付けることができます。
リレーションシップは、異なるエンティティに保存されているデータをリンクし、複数のテーブルにわたるデータの取得とレポートを容易にするために重要です。
キーズ
キーは、テーブル内のレコードを一意に識別し、テーブル間の関係を確立するために使用される特定の属性です。キーにはいくつかの種類があります。
- 主キー: 列または列のセットは、各テーブル レコードを一意に識別します。テーブル内で 2 つのレコードが同じ主キー値を持つことはできません。
- 外部キー: 別のテーブルの主キーを参照する、あるテーブル内の列または列のセット。外部キーは、テーブル間の関係を確立し、強制するために使用されます。
- 複合キー: テーブル内の各レコードを一意に識別するために使用できる、テーブル内の 2 つ以上の列の組み合わせ。
- 候補キー: テーブル内の主キーとして認められる任意の列または列のセット。
これらの主要なコンポーネントを理解し、正しく実装することは、効果的なデータの保存、取得、および管理システムを作成するための基礎となります。適切なデータ モデリングにより、パフォーマンスとスケーラビリティを実現するために適切に編成および最適化されたデータベースが実現され、開発者とエンド ユーザーの両方のニーズがサポートされます。
データモデルのフェーズ
データ モデリングは通常、概念データ モデル、論理データ モデル、物理データ モデルの 3 つの主要なフェーズで展開されます。各フェーズは特定の目的を果たし、前のフェーズに基づいて抽象的なアイデアを具体的なデータベース設計に徐々に変換します。これらのフェーズを理解することは、データ システムを作成または管理する人にとって非常に重要です。
概念データ モデル
概念的データ モデルは、最も抽象的なレベルのデータ モデリングです。このフェーズでは、データの保存方法の詳細には触れず、上位レベルのエンティティとエンティティ間の関係を定義することに重点を置きます。主な目標は、ビジネス ドメインに関連する主要なデータ オブジェクトとその相互作用の概要を、技術者以外の関係者でも理解できる方法で説明することです。このモデルは、最初の計画とコミュニケーションによく使用され、ビジネス要件と技術的な実装の橋渡しをします。
主な特徴は次のとおりです。
- 重要なエンティティとその関係の特定。
- 高レベルであり、ビジネス用語が頻繁に使用されます。
- データベース管理システム (DBMS) やテクノロジーから独立しています。
論理データ モデル
論理データ モデルは、概念モデルにさらに詳細を追加し、データ要素の構造を指定し、データ要素間の関係を設定します。これには、エンティティの定義、各エンティティの属性、主キー、外部キーが含まれます。ただし、実装に使用されるテクノロジからは依然として独立しています。論理モデルは概念モデルよりも詳細かつ構造化されており、データを管理するルールと制約が導入され始めます。
主な特徴は次のとおりです。
- エンティティ、関係、属性の詳細な定義。
- 関係を確立するには、主キーと外部キーを含める必要があります。
- 正規化プロセスは、データの整合性を確保し、冗長性を削減するために適用されます。
- 依然として特定の DBMS テクノロジーから独立しています。
物理データモデル
物理データ モデルは最も詳細なフェーズであり、特定のデータベース管理システム内でのデータ モデルの実装が含まれます。このモデルは、論理データ モデルを、データベースに実装できる詳細なスキーマに変換します。これには、テーブル、列、データ型、制約、インデックス、トリガー、その他のデータベース固有の機能など、実装に必要な詳細がすべて含まれています。
主な特徴は次のとおりです。
- 特定の DBMS に固有であり、データベース固有の最適化が含まれます。
- テーブル、列、データ型、制約の詳細な仕様。
- 物理ストレージのオプション、インデックス作成戦略、パフォーマンスの最適化を考慮します。
これらのフェーズを移行することで、ビジネス要件に合わせて、特定の技術環境内でのパフォーマンスを最適化したデータ システムの綿密な計画と設計が可能になります。概念モデルは全体の構造がビジネス目標と一致していることを保証し、論理モデルは概念計画と物理実装の間のギャップを埋め、物理モデルはデータベースが実際の使用に合わせて最適化されていることを保証します。
学校データセットの例
エンティティ: 生徒、教師、クラス。
概念データ モデル
この概念的なデータ モデルは、学生、教師、クラスという 3 つの主要なエンティティを特徴とする、学校の記録を管理するためのデータベース システムの概要を示しています。このモデルでは、生徒を複数の教師およびクラスに関連付けることができ、教師は複数の生徒を指導し、さまざまなクラスを主導することができます。各クラスには多数の生徒が収容されますが、指導は 1 人の教師によって行われます。この設計は、技術的利害関係者と非技術的利害関係者の両方がエンティティ間の関係を理解しやすくすることを目的としており、システム構造の明確かつ直観的な概要を提供します。概念モデルから始めると、より詳細な要素を段階的に統合できるようになり、洗練されたデータベース モデルを開発するための強固な基盤が築かれます。
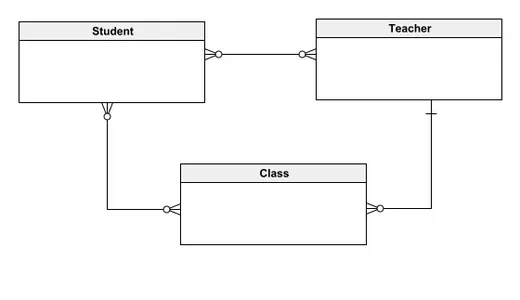
論理データ モデル
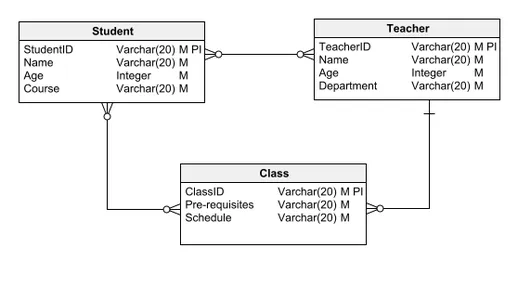
論理データ モデルは、明瞭さと詳細のバランスが高く評価されており、エンティティ、関係、属性、主キー、外部キーが組み込まれています。データベース内でのデータの論理的な進行を細心の注意を払って概説し、データの構成や使用されるデータ型などの詳細を明確にします。論理データ モデルは、実際のデータベース構築を開始するためのソフトウェア開発に十分な基礎を提供します。
前に説明した概念データ モデルからさらに進んで、典型的な論理データ モデルを調べてみましょう。概念的な前モデルとは異なり、このモデルには属性と主キーが強化されています。たとえば、Student エンティティは、名前や年齢などの他の重要な属性とともに、主キーおよび一意の識別子としての StudentID によって区別されます。
このアプローチは、教師やクラスなどの他のエンティティ全体に一貫して適用され、概念モデルで確立された関係を維持しながら、属性やキー識別子を含む詳細なスキーマでモデルを強化します。
物理データモデル
物理データ モデルは、抽象化レベルの中で最も詳細であり、PostgreSQL、Oracle、MySQL など、選択したデータベース管理システムに合わせた詳細が組み込まれています。このモデルでは、エンティティはテーブルに変換され、属性は列になり、実際のデータベースの構造を反映します。各列には特定のデータ型が割り当てられます。たとえば、整数の場合は INT、可変文字列の場合は VARCHAR、日付の場合は DATE です。
物理データ モデルはその詳細な性質を考慮して、使用されているデータベース プラットフォームに固有の技術を詳しく掘り下げます。これらの包括的な側面は、高レベルの概要の範囲を超えています。これには、ストレージの割り当て、インデックス付け戦略、制約の実装などの考慮事項が含まれます。これらはデータベースのパフォーマンスと整合性にとって重要ですが、通常は事前の議論としては細かすぎます。

データモデリングのフェーズ
- ビジネス要件を理解する: 関係者と詳細な話し合いを行って、データベースのビジネス目的を理解します。主な考慮事項には、ビジネス ドメイン、データ ストレージのニーズ、データベースが解決しようとしている問題の特定が含まれます。データベース設計をパフォーマンス、コスト、セキュリティに関するビジネス目標に合わせることに重点を置きます。
- チームコラボレーション: 他のチーム (UX/UI デザイナーや開発者など) と緊密に連携して、データベースがより広範なソリューションをサポートしていることを確認します。データの形式とタイプをアプリケーションの要件に合わせて調整し、協調的な設計とコミュニケーションのスキルを重視します。
- 業界標準を活用: ゼロから始めることを避けるために、既存のモデルと標準を調査してください。業界のベスト プラクティスを活用して時間とリソースを節約し、既存のモデルとデータベースを区別する独自の取り組みをデータベースの側面に集中させます。
- データベース モデリングを開始します。 ビジネス ニーズ、チームの意見、業界標準をしっかりと理解した上で、概念モデリングから始めて論理モデルに移行し、物理モデルで最終的に仕上げます。この構造化されたアプローチにより、必要なエンティティ、属性、関係を包括的に理解できるようになり、ビジネス目標に合わせたスムーズなデータベース実装が促進されます。
データ モデリング ツールは、組織のデータ構造を設計、維持、進化させるために不可欠です。これらのツールは、データベースの設計と管理のライフサイクル全体をサポートするさまざまな機能を提供します。データ モデリング ツールに求められる主な機能は次のとおりです。
- データモデルを構築する: 概念的、論理的、物理的なデータ モデルの作成を容易にし、エンティティ、属性、関係を明確に定義できるようにします。このコア機能は、データベース アーキテクチャの初期および継続的な設計をサポートします。
- コラボレーションと中央リポジトリ: チームメンバーがデータモデルの設計と変更に協力できるようにします。中央リポジトリにより、すべての関係者が最新バージョンにアクセスできるようになり、開発の一貫性と効率が促進されます。
- リバースエンジニアリング: SQL スクリプトをインポートする機能、または既存のデータベースに接続してデータ モデルを生成する機能を提供します。これは、レガシー システムを理解して文書化する場合、または既存のデータベースを統合する場合に特に役立ちます。
- フォワードエンジニアリング: データ モデルから SQL スクリプトまたはコードを生成できます。この機能により、データベース構造の変更の実装が効率化され、物理データベースが最新のモデルを確実に反映するようになります。
- さまざまなデータベース タイプのサポート: MySQL、PostgreSQL、Oracle、SQL Server などの複数のデータベース管理システム (DBMS) との互換性を提供します。この柔軟性により、このツールはさまざまなプロジェクトや技術環境にわたって使用できます。
- バージョン管理: バージョン管理システムを組み込むか、バージョン管理システムと統合して、長期にわたるデータ モデルの変更を追跡します。この機能は、データベース構造の反復を管理し、必要に応じて以前のバージョンへのロールバックを容易にするために非常に重要です。
- さまざまな形式での図のエクスポート: ユーザーがデータ モデルや図をさまざまな形式 (PDF、PNG、XML など) でエクスポートできるため、共有や文書化が容易になります。これにより、技術者以外の関係者もデータ アーキテクチャを確認して理解できるようになります。
これらの機能を備えたデータ モデリング ツールを選択すると、組織内でのデータ管理作業の効率、精度、コラボレーションが大幅に向上し、データベースが適切に設計され、最新の状態に保たれ、ビジネス ニーズに適合することが保証されます。
ER / Studio

包括的なモデリング機能とコラボレーション機能を提供し、さまざまなデータベース プラットフォームをサポートします。
IBM InfoSphere データアーキテクト

他の IBM 製品との統合と同期をサポートする、データ モデルの設計と管理のための堅牢な環境を提供します。
Oracle SQL Developerデータ・モデラー

フォワード エンジニアリングとリバース エンジニアリング、バージョン管理、およびマルチデータベースのサポートをサポートする無料のツール。
Oracle SQL Developerデータモデラーリンク
パワーデザイナー (SAP)

データ、情報、エンタープライズ アーキテクチャのサポートを含む広範なモデリング機能を提供します。
Navicatデータモデラー
ユーザーフレンドリーなインターフェイスと幅広いデータベースのサポートで知られており、フォワード エンジニアリングとリバース エンジニアリングが可能です。
これらのツールは、データ モデリング プロセスを合理化し、チームのコラボレーションを強化し、さまざまなデータベース システム間での互換性を確保します。
また、お読みください。 データモデリングに関する面接の質問
まとめ
この記事では、データ モデリングの重要な実践を詳しく掘り下げ、データベースやデータ システム内のデータの整理、保存、アクセスにおけるデータ モデリングの重要な役割を強調しました。プロセスを概念モデル、論理モデル、物理モデルに分類することで、データ モデリングがどのようにビジネス ニーズを構造化データ フレームワークに変換し、効率的なデータ処理と洞察力に富んだ分析を促進するかを説明しました。
主なポイントとしては、ビジネス要件を理解することの重要性、さまざまな関係者が関与するデータベース設計の協調的な性質、開発プロセスを合理化するためのデータ モデリング ツールの戦略的使用などが挙げられます。データ モデリングにより、データ構造が現在のニーズに合わせて最適化され、将来の成長に備えたスケーラビリティが確保されます。
データ モデリングは効果的なデータ管理の中心にあり、組織がデータを活用して戦略的な意思決定と運用効率を向上できるようにします。
よくある質問
答え。データ モデリングは、システムのデータを視覚的に表現し、データがどのように保存、編成、アクセスされるかを概説します。これは、ビジネス要件を構造化データベース形式に変換し、データを効率的に使用できるようにするために非常に重要です。
答え。主な使用例には、データの取得、読み込み、ビジネス計算、配布が含まれており、データが効果的に収集、保存され、ビジネス上の洞察に活用されるようにします。
答え。データ エンジニアはデータ インフラストラクチャを構築および維持し、データ モデラーはビジネス目標とデータの整合性をサポートするデータの構造と組織を設計します。
答え。このプロセスは、ビジネス要件の理解からチームとのコラボレーション、業界標準の活用、概念的、論理、物理的な段階を経たデータベースのモデリングへと移行します。
答え。これらのツールは、データ モデルの設計、コラボレーション、進化を促進し、さまざまなデータベース タイプをサポートし、効率的なデータベース管理のためのリバース エンジニアリングおよびフォワード エンジニアリングを可能にします。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

