
2022年六月
By ジェームズ・ナートン、 フリーランスのライター
洗練された機能を有効にする方法 人工知能 (AI) ツールのプライバシーを尊重し、データ資産の知的財産を保護しますか? ベルリンを拠点とするスタートアップ企業は、フェデレーテッド ラーニングが答えを提供すると信じています。

連合学習は信念に基づいています
「機密データはローカルに保管し、
データ管理者の管理下にある」
と同等の結果を提供します。
自分のサーバーにすべてのデータがある場合は、」
Apheris の法務責任者、Lucie Arntz 氏は次のように述べています。
(写真:アフェリス提供)
2021 年 XNUMX 月に開催された IP とフロンティア テクノロジーに関する WIPO カンバセーションの第 XNUMX 回セッションでの開会のスピーチで データ: 世界経済を変革する燃料)、WIPO事務局長のDaren Tang氏は、データはデジタル化を推進する「燃料」であると説明しました。 機械学習のアルゴリズムには、学習するために大量のデータが必要ですが、燃料の流れが中断された場合、つまり、プライバシー、セキュリティ、または理由でデータを共有できない場合はどうなりますか? 知的財産 (IP)保護?
この問題に対する XNUMX つの解決策は、フェデレーテッド ラーニングとして知られています。この場合、データはデータ所有者の制御から離れることはありません。 むしろ、機械学習アルゴリズムは、データが共有されることなくローカルでトレーニングされます。 簡単な例では、病院からの患者記録などの機密データを、病院がデータを開示することなく、製薬会社による新薬の開発に使用できます。 より高度なケースでは、複数のソースからのデータを使用して同じアルゴリズムをトレーニングし、量と多様性の両方でメリットをもたらすことができます。
フェデレーテッド ラーニングでは、信頼できるサード パーティがアルゴリズムとデータの所有者を結び付ける必要があります。 2019 年に立ち上げられたベルリンを拠点とするスタートアップの Apheris は、そのような企業の 20 つです。 Apheris には、安全なデータ共有のための安全なプラットフォームを提供する約 XNUMX 人の開発者、プライバシー専門家、およびデータ サイエンティストのチームがあります。 その法務責任者であるルーシー・アーンツは最近、 WIPOマガジン 会社のビジネスモデル、データ保護、セキュリティについて。
連合学習の利点
Arntz 氏は 2020 年夏に Apheris に入社しました。これは科学者ではない最初の従業員であり、適切な法的基盤を確保し、顧客の権利を保護し、契約を監督する責任を負っています。 フェデレーテッド ラーニングは、「機密データはローカルに保管し、データ コントローラーの管理下に置くのが最善」であり、「すべてのデータを自分のサーバーに置いているのと同じくらい良い」結果をもたらすという信念に基づいていると彼女は言います。 .
これまでのところ、AI 技術が進歩しており、患者の機密データや機密データに関する基本的な懸念がある医療分野で、そのメリットが最も顕著に現れています。 しかし、Arntz 氏は、フェデレーテッド ラーニングは、個人を特定できる情報 (PII) に関してデータの機密性が高くない場合でもメリットがあると指摘しています。 たとえば、Apheris は現在、化学製品メーカーのプロジェクトに取り組んでいます。このプロジェクトには、商業的に機密性の高い秘密の製品データと顧客データが含まれます。 連合学習は、特定のデータが知的財産権によって保護されている場合にも適用できます。
「データの一元化は時代遅れになりつつあります」と Arntz 氏は言い、多くの企業が共有に関する懸念のために活用されていない大量の貴重なデータを所有していると付け加えました。あなたにとってではないので、誰かと提携しなければ、そのデータにはまったく価値がありません。」
場合によっては、フェデレーテッド ラーニングを通じて他のソースからのデータと組み合わせた場合にのみ、データの価値が明らかになることがあります。 たとえば、米国の患者の医療データをアフリカやアジアの医療データで補完することで、より多様な臨床試験データセットを作成できます。 「必要に応じてスケールアップでき、そこが魔法のようです」と Arntz 氏は言います。
しかし彼女は、フェデレーテッド ラーニングの可能性が実現されるまでにはおそらく XNUMX 年はかかるだろうと付け加えています。 その理由の XNUMX つは、データの収集とフォーマットの標準化をさらに進める必要があることです。 コンピューティング能力の向上により、より大量のデータの処理が可能になりますが、最適な結果を得るには、データを適切に構造化して安全なデータ コラボレーションを可能にする必要があります。 ここでも、医療セクターが先導していますが、他のセクターが追いついています。 Arntz 氏が指摘する XNUMX つは自動車業界で、部分的および完全自動運転車の開発は、ドライバー、車両、高速道路当局、法執行機関、保険会社など、さまざまなソースからの多種多様なデータの分析に依存しています。 「自動車業界は、その標準化を実現することに非常に重点を置いています」と彼女は言います。 「そのデータで協力できることに大きな関心が寄せられており、大手メーカーを集めて標準化する取り組みが行われています。 公共部門と民間部門の両方の相互作用が関与するため、特に興味深い分野です。」 自動車部門では、解決策は自発的で業界主導のものになる可能性が高いですが、開発には時間がかかります。
コンピューティング能力の向上により、より大量のデータの処理が可能になりますが、最適な結果を得るには、データを適切に構造化して安全なデータ コラボレーションを可能にする必要があります。
匿名化の難問
AI ツールの開発における大きな課題の XNUMX つは、匿名化のレベルです。 個人が自分の個人データ (病歴、家族歴、財務情報、その他の個人情報など) を保護することに関心を持つのは当然ですが、Arntz 氏は次のように述べています。 匿名化は機械学習の未来ではありません。」 たとえば、効果的な医薬品の開発と試験では、年齢、民族性、アレルギー、投薬などの要因を考慮する必要があります。 自動運転車には、移動先、運転する車両の種類、移動速度に関する情報が必要です。 Arntz 氏は、フェデレーテッド ラーニングがバランスを提供し、「プライバシーとイノベーションの両方を持つことは対立ではない」ことを示すのに役立つと考えています。
このような課題を克服するには、技術的および法的な解決策を組み合わせる必要があります。テクノロジーは、厳格で徹底的にテストされたプロセスを通じてデータのセキュリティを確保できます。一方、法律は、誰がデータを管理し、誰が結果を受け取ることができるか、およびどのレベルの詳細を規定するかを規定する契約を可能にします。彼らは受け取ります。
集中学習と連合学習の比較

「データの一元化は時代遅れになりつつあります」と Arntz 氏は言います。 「他の誰かにとっては非常に重要であるが、あなたにとっては重要ではないデータがたくさんあるかもしれません。そのため、誰かと提携しなければ、そのデータにはまったく価値がありません。」
データを実際にどのように保護するかは、依然として難しい問題です。 著作権 法と 独特の EU のデータベース権などのツールはある程度の保護を提供する可能性がありますが、境界は明確ではなく、ほとんどの組織はデータを安全に保つことを好む可能性が高く、契約上の規定と保護の下に依存しています。 企業秘密 または機密情報法。 しかし、Arntz 氏は、データが保護されているかどうか、およびどのように保護されているかという問題は必ずしも問題ではないと述べています。 連合学習では、データが正式に保護されているかどうかは問題ではありません。 私たちは安全側で過ちを犯しています。」
より差し迫った問題は、「広範な同意」であると彼女は信じています。 GDPR は、科学研究者がデータが収集されるすべての目的を常に特定できるとは限らないことを認識しています。 したがって、他の分野での計画についてそれほど具体的にする必要はないかもしれませんが、それでも、データ主体が将来の研究使用についてインフォームド コンセントを与えることができるように、オプションを提供する必要があります。 「「研究目的」とは何かについて、より明確なガイダンスが必要です。 現時点では、大学や研究者にとって不確実性があり、それがイノベーションを制限しています」と彼女は言います。
公正な規制に光を当てる
Arntz 氏は、GDPR は「非常に批判されているが、非常に愛されている」法律の一例であると考えています。GDPR はデータ保護の健全な基盤を提供しますが、技術の変化に応じて更新する必要があります。 「何よりも、明確にする必要があります。何かを行うことができないというガイダンスがあったとしても、少なくとも明確な線を引くことは良いことです。」
彼女はまた、GDPR は、地域 (この場合は EU) が公正な規制を促進するために「光を当てる」ことができる方法の一例であると主張しています。途中で妥協しなければならないとしても。 彼女は、最近採択されたような新しい EU のイニシアチブについて楽観的です。 データガバナンス法 そして提案された AI法、さらに明確になります。 将来的にはそれを適応させ、達成しようとしていることを再検討する必要があります。」
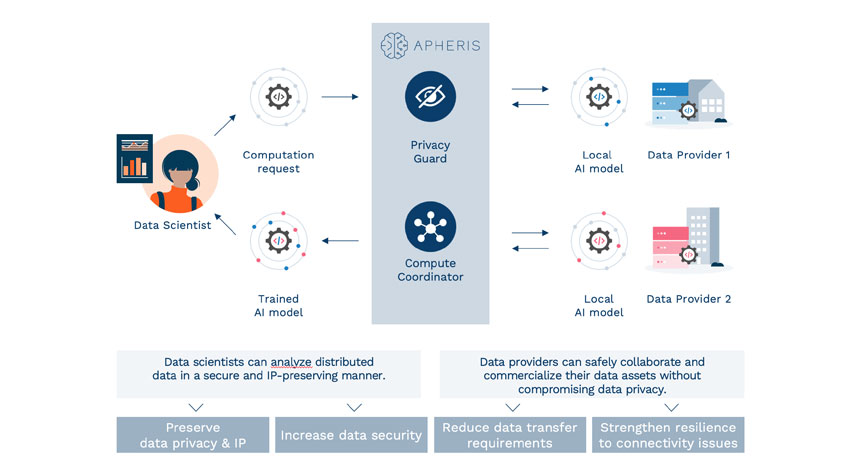
Apheris を使用すると、企業は機密情報を非公開に保ちながら、複数の関係者のデータを安全に分析できます。
ただし、プロセスは包括的かつ学際的でなければならないと彼女は警告します。ビジネス、法律、政策、技術の専門家が同じ部屋にいないか、同じ言語を話しているとは限らないことがあまりにも多く、スタートアップや中小企業の声が常に聞かれるとは限りません。 「政府は大企業とよく話をしますが、新興企業と話をしないと、革新的な技術について耳にすることはありません」と Arntz 氏は説明します。
技術はますます洗練されており、AI やデータ分析から派生した新しい製品やサービスに利用できる資金は豊富にあるため、会話は重要であると彼女は言います。 COVID-19 パンデミックへの取り組みから気候変動の影響の評価まで、データの重要性は明らかです。 Arntz 氏は次のように述べています。
一般的なデータ保護規則 (GDPR): 2016 GDPR は、EU データ保護指令に取って代わり、欧州経済領域におけるデータ主体の個人データの処理を規制しています。 これは、カリフォルニア州消費者プライバシー法 (2018 年) など、他の多くの国や地域で採用されています。
データガバナンス法: この法律は、6 年 2022 月 XNUMX 日に欧州議会で採択されました。欧州議会は、「イノベーションを刺激し、スタートアップや企業がビッグデータを使用するのを支援する」動きとして歓迎しています。 この規則は、データのコストと市場参入の障壁を下げることで、ビジネスに利益をもたらします。 消費者は、例えば、よりスマートなエネルギー消費とより少ない排出量にアクセスできるようになることで利益を得るでしょう。 また、ルールは、データ保護法に確実に準拠することで、データの共有をより簡単かつ安全にすることで、信頼を構築するように設計されています。 また、公共部門のデータの特定のカテゴリの再利用を促進し、データ仲介者への信頼を高め、データ利他主義 (社会の利益のためにデータを共有すること) を促進します。 この法律は、企業、個人、および公共部門がデータを共有しやすくするための「プロセスと構造」を作成します。 法律になる前に、理事会のすべての EU 加盟国によって採択される必要があります。
EU データ法: The Act、通称 データへの公正なアクセスと使用に関する調和規則に関する規則案、2022 年 XNUMX 月に欧州委員会によって採択され、欧州のデータ戦略の重要な柱となっています。 誰がデータから価値を生み出すことができるか、また、その価値を生み出す条件を明確にします。
人工知能法: EU 向けに調和のとれた規則を定める AI 規則の提案は、欧州委員会の AI パッケージ 2021年XNUMX月公開。「AIの水平規制を制定する」初の試みであり、![]() そして、ヨーロッパを人間中心の信頼できる AI のグローバル ハブに変えるように設計されています。
そして、ヨーロッパを人間中心の信頼できる AI のグローバル ハブに変えるように設計されています。
- コインスマート。 ヨーロッパで最高のビットコインと暗号通貨取引所。ここをクリック
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.wipo.int/wipo_magazine/en/2022/02/article_0001.html

