著者による画像
モデルを操作するときは、アルゴリズムが異なれば、データを取り込む際の学習パターンも異なることに留意する必要があります。 これは直観的な学習の一種で、モデルが特定のデータセット内のパターンを学習できるようにするもので、モデルのトレーニングと呼ばれます。
次にモデルは、モデルがこれまでに見たことのないデータセットであるテスト データセットでテストされます。 モデルがトレーニング データセットとテスト データセットの両方で正確な出力を生成できる最適なパフォーマンス レベルを達成したいと考えています。
検証セットについても聞いたことがあるかもしれません。 これは、データセットをトレーニング データセットとテスト データセットの XNUMX つに分割する方法です。 データの最初の分割はモデルのトレーニングに使用され、データの XNUMX 番目の分割はモデルのテストに使用されます。
ただし、検証セット方式には欠点もあります。
モデルはトレーニング データセット内のすべてのパターンを学習していますが、テスト データセット内の関連情報を見逃している可能性があります。 これにより、モデル全体のパフォーマンスを向上させることができる重要な情報がモデルから失われてしまいました。
もう XNUMX つの欠点は、トレーニング データセットで、モデルが学習するデータ内の外れ値やエラーに直面する可能性があることです。 これはモデルのナレッジ ベースの一部となり、第 XNUMX フェーズでのテスト時に適用されます。
では、これを改善するにはどうすればよいでしょうか? リサンプリング。
リサンプリングは、トレーニング データセットからサンプルを繰り返し抽出する方法です。 これらのサンプルは、特定のモデルを再適合するために使用され、適合されたモデルに関する詳細情報を取得します。 目的は、サンプルに関するより多くの情報を収集し、精度を向上させ、不確実性を推定することです。
たとえば、線形回帰の近似を調べていて、ばらつきを調べたい場合です。 トレーニング データからのさまざまなサンプルを繰り返し使用し、各サンプルに線形回帰を近似します。 これにより、さまざまなサンプルに基づいて結果がどのように異なるかを調べたり、新しい情報を取得したりできます。
リサンプリングの大きな利点は、モデルが最適なパフォーマンスを達成するまで、同じ母集団から小さなサンプルを繰り返し抽出できることです。 同じデータセットをリサイクルでき、新しいデータを探す必要がないため、時間とお金を大幅に節約できます。
アンダーサンプリングとオーバーサンプリング
非常に不均衡なデータセットを使用している場合、リサンプリングはそれを解決するために使用できる手法です。
- アンダーサンプリングとは、バランスを高めるために大部分のクラスからサンプルを削除することです。
- オーバーサンプリングとは、収集されたデータが不十分であるために、少数派のクラスからランダムなサンプルを複製することです。
ただし、これらには欠点もあります。 アンダーサンプリングでサンプルを削除すると、情報が失われる可能性があります。 少数派クラスからのランダムなサンプルを複製すると、過剰適合が発生する可能性があります。
データ サイエンスでは、次の XNUMX つのリサンプリング手法が頻繁に使用されます。
- ブートストラップ法
- 交差検証
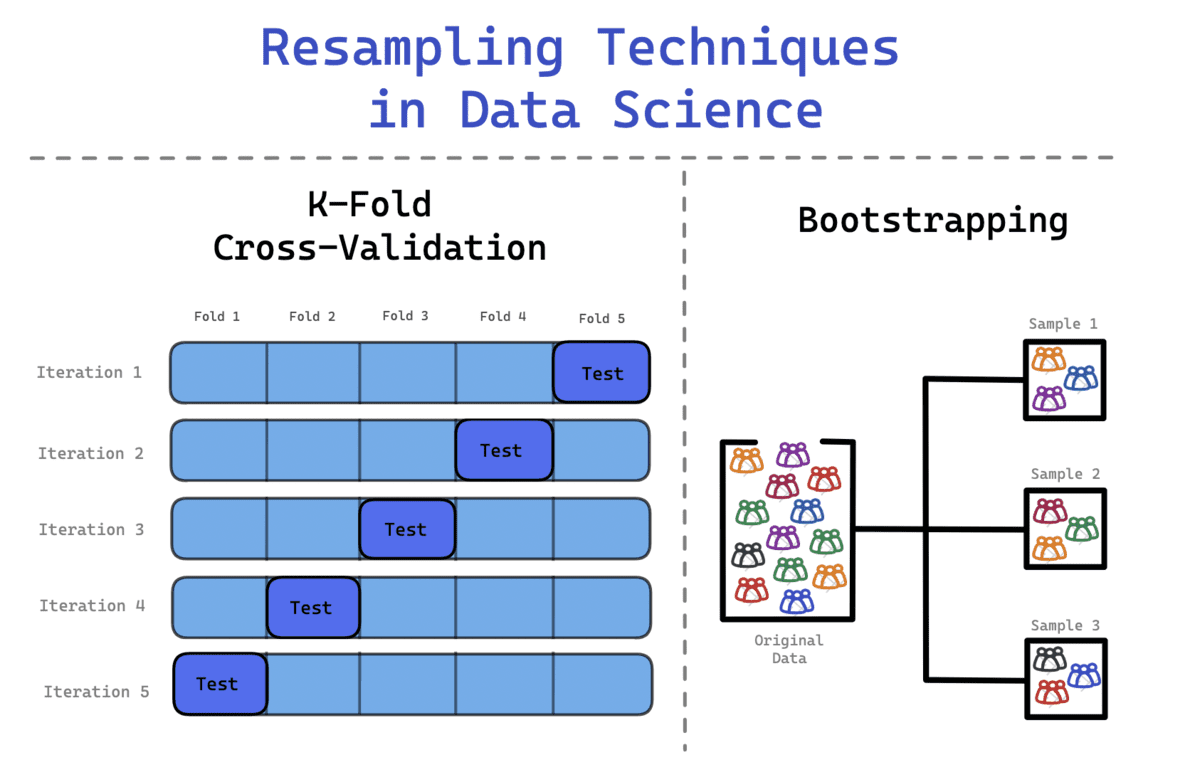
ブートストラップ法
典型的な正規分布に従っていないデータセットに遭遇することがあります。 したがって、ブートストラップ法を適用して、データセットの隠された情報と分布を調べることができます。
ブートストラップ法を使用する場合、描画されたサンプルが置き換えられ、サンプルに含まれていないデータがモデルのテストに使用されます。 これは、データ サイエンティストや機械学習エンジニアが不確実性を定量化するのに役立つ柔軟な統計手法です。
プロセスには以下が含まれます
- データセットからサンプル観測値を繰り返し抽出する
- これらのサンプルを置き換えて、元のデータセットが同じサイズのままであることを確認します。
- 観測値は複数回表示されることも、まったく表示されないこともあります。
バギングというアンサンブル手法について聞いたことがあるかもしれません。 これは Bootstrap Aggregation の略で、ブートストラップと集約を組み合わせて XNUMX つのアンサンブル モデルを形成します。 元のトレーニング データの複数のセットを作成し、それを集計して最終的な予測を結論付けます。 各モデルは前のモデルのエラーを学習します。
ブートストラップの利点は、前述のトレーニングとテストの分割方法と比較して分散が低いことです。
交差検証
データセットをランダムに繰り返し分割すると、サンプルがトレーニング セットまたはテスト セットのいずれかに含まれる可能性があります。 残念ながら、これはモデルに正確な予測を行う上で不均衡な影響を与える可能性があります。
これを回避するには、K-Fold Cross Validation を使用してデータをより効果的に分割します。 このプロセスでは、データが k 個の等しいセットに分割され、XNUMX つのセットがテスト セットとして定義され、残りのセットがモデルのトレーニングに使用されます。 このプロセスは、各セットがテスト セットとして機能し、すべてのセットがトレーニング フェーズを通過するまで続きます。
プロセスには以下が含まれます。
- データは k 分割に分割されます。 たとえば、データセットは 10 分割、つまり 10 個の等しいセットに分割されます。
- 最初の反復中に、モデルは (k-1) でトレーニングされ、残りの 10 つのセットでテストされます。 たとえば、モデルは (1-9 = 1) でトレーニングされ、残りの XNUMX セットでテストされます。
- このプロセスは、すべての折り目がテスト段階の残り 1 セットとして機能するまで繰り返されます。
これにより、各サンプルのバランスの取れた表現が可能になり、すべてのデータがモデルの学習の改善とモデルのパフォーマンスのテストに確実に使用されるようになります。
この記事では、リサンプリングとは何か、また 3 つの異なる方法 (トレーニングとテストの分割、ブートストラップ、相互検証) でデータセットをサンプリングする方法を理解しました。
これらすべてのメソッドの全体的な目的は、モデルが効果的な方法でできるだけ多くの情報を取り込めるようにすることです。 モデルが正常に学習されたことを確認する唯一の方法は、データセット内のさまざまなデータ ポイントでモデルをトレーニングすることです。
リサンプリングは、予測モデリング段階の重要な要素です。 正確な出力、高性能モデル、効果的なワークフローを保証します。
ニシャ・アリア データサイエンティスト兼フリーランステクニカルライターです。 彼女は特に、データサイエンスのキャリアに関するアドバイスやチュートリアル、およびデータサイエンスに関する理論に基づく知識の提供に関心を持っています。 彼女はまた、人工知能が人間の寿命の長寿に役立つ/できるさまざまな方法を探求したいと考えています。 他の人を導くのを助けながら、彼女の技術知識とライティングスキルを広げることを求めている熱心な学習者。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/02/role-resampling-techniques-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-role-of-resampling-techniques-in-data-science

