
著者による画像
スパース データとは、値がゼロのフィーチャが多数あるデータセットを指します。 さまざまな分野、特に機械学習で問題を引き起こす可能性があります。
不適切な特徴量エンジニアリング手法の結果として、スパース データが発生する可能性があります。 たとえば、多数のダミー変数を作成するワンホット エンコーディングを使用します。
スパース性は、データセット内のゼロと要素の総数の比率を取ることで計算できます。 スパース性に対処すると、機械学習モデルの精度に影響します。
また、スパース性と欠損データを区別する必要があります。 欠損データとは、一部の値が利用できないことを意味します。 スパース データでは、すべての値が存在しますが、ほとんどがゼロです。
また、スパース性は、機械学習に固有の課題を引き起こします。 正確には、オーバーフィッティング、適切なデータの損失、メモリの問題、および時間の問題が発生します。
この記事では、スパース データに関連するこれらの一般的な問題について説明します。 次に、この問題を処理するために使用される手法について説明します。
最後に、さまざまな機械学習モデルをスパース データに適用し、これらのモデルがスパース データに適している理由を説明します。
この記事では、主に scikit-learn ライブラリを使用します。コードと引数を変更したい場合は、公式ドキュメントのリンクも提供します。
それでは、スパース データに関する一般的な問題から始めましょう。
まばらなデータは、データ分析に固有の課題をもたらす可能性があります。 最も一般的な問題には、オーバーフィッティング、適切なデータの損失、メモリの問題、時間の問題などがあることはすでに述べました。
それでは、それぞれについて詳しく見ていきましょう。

著者による画像
オーバーフィット
オーバーフィッティングは、モデルが複雑になりすぎて、基になるパターンではなくデータにノイズが取り込まれ始めると発生します。
まばらなデータでは、多数の機能が存在する場合がありますが、実際に分析に関連するのはそのうちのいくつかだけです。 これにより、重要な機能とそうでない機能の識別が難しくなる可能性があります。
その結果、モデルがデータ内のノイズに過適合し、新しいデータでパフォーマンスが低下する可能性があります。
機械学習を初めて使用する場合、または詳しく知りたい場合は、 オーバーフィッティングに関する scikit-learn ドキュメント.
良いデータを失う
スパース データの最大の問題の XNUMX つは、有用な情報が失われる可能性があることです。
データが非常に限られている場合、そのデータで意味のあるパターンや関係を特定することはより困難になります。 これは、データ セットに固有のノイズとランダム性により、データがまばらな場合に重要な特徴が見えにくくなる可能性があるためです。
さらに、利用できるデータの量が限られているため、データ内の真に価値のあるパターンや関係の一部を見逃す可能性が高くなります。 これは、単に欠落しているのではなく、サンプリングが不足しているためにデータがまばらな場合に特に当てはまります。 このような場合、データ ポイントの欠落に気付かず、貴重な情報を失っていることに気付かない可能性があります。
そのため、あまりにも多くのフィーチャが削除されたり、データが圧縮されすぎたりすると、重要な情報が失われ、モデルの精度が低下する可能性があります。
メモリの問題
データセットのサイズが大きいため、メモリの問題が発生する可能性があります。 まばらなデータは多くの特徴をもたらすことが多く、このデータを格納すると計算コストが高くなる可能性があります。 これにより、一度に処理できるデータの量が制限されたり、大量のコンピューティング リソースが必要になったりする可能性があります。
ここに scikit-learn を使用してデータをスケーリングするためのさまざまな戦略を確認できます。
時間の問題
データセットのサイズが大きいため、時間の問題も発生する可能性があります。 まばらなデータは、特に多数の機能を処理する場合に、より長い処理時間を必要とする場合があります。 これにより、データの処理速度が制限される可能性があり、時間に敏感なアプリケーションでは問題になる可能性があります。

著者による画像
スパース データは、ゼロ以外の値の発生が少ないため、データ分析に課題をもたらします。 ただし、この問題を軽減するために使用できる方法がいくつかあります。
一般的なアプローチの XNUMX つは、データセット内でスパース性を引き起こしている機能を削除することです。
別のオプションは、主成分分析 (PCA) を使用して、重要な情報を保持しながらデータセットの次元を減らすことです。
特徴ハッシュは、特徴を固定長ベクトルにマッピングすることを含む、使用できる別の手法です。
T-Distributed Stochastic Neighbor Embedding (t-SNE) は、高次元データセットを視覚化するために利用できるもう XNUMX つの便利な方法です。
これらの手法に加えて、SVM やロジスティック回帰など、スパース データを処理できる適切な機械学習モデルを選択することが重要です。
これらの戦略を実装することにより、データ分析におけるまばらなデータに関連する課題に効果的に対処できます。
それでは、最初にまばらなデータを削減するために使用される戦術から始めましょう。次に、モデルをさらに深く掘り下げます。
それを除く!
まばらなデータを扱う場合、XNUMX つのアプローチは、ほとんどゼロの値を含む特徴を削除することです。 これは、各機能のゼロ以外の値のパーセンテージにしきい値を設定することで実行できます。 このしきい値を下回るフィーチャは、データセットから削除できます。
このアプローチは、データセットの次元を減らし、特定の機械学習アルゴリズムのパフォーマンスを向上させるのに役立ちます。
コードの例
この例では、データセットのディメンションと、データセット内のゼロになる値の数を決定するスパース レベルを設定します。
次に、指定されたスパース レベルでランダム データを生成して、メソッドが機能するかどうかを確認します。 このステップでは、スパース性を計算して後で比較します。
次に、コードは削除するゼロの数を設定し、データセットから特定の数のゼロをランダムに削除します。 次に、変更されたデータセットのスパース性を再計算して、メソッドが機能するかどうかを確認します。
最後に、スパース性を再計算して変更を確認します。
これがコードです。
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Set the number of zeros to remove
num_zeros_to_remove = 50000 # Remove a specific number of zeros randomly from the dataset
zero_indices = np.argwhere(data == 0)
zeros_to_remove = np.random.choice( zero_indices.shape[0], num_zeros_to_remove, replace=False
)
data[ zero_indices[zeros_to_remove, 0], zero_indices[zeros_to_remove, 1]
] = np.nan # Calculate the sparsity of the modified dataset num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print( "Sparsity after removing {} zeros:".format(num_zeros_to_remove), sparsity
)
これが出力です。

PCA
PCA は、次元削減の一般的な手法です。 これは、データが最も変化する方向であるデータの主成分を識別します。
これらの主成分は、低次元空間でデータを表すために使用できます。
まばらなデータのコンテキストでは、PCA を使用して、データの変動が最も多い最も重要な特徴を特定できます。
これらの機能のみを選択することで、重要な情報のほとんどを保持しながら、データセットの次元を減らすことができます。
次のコード例で行うように、sci-kit 学習ライブラリを使用して PCA を実装できます。 ここに 詳細については、公式ドキュメントを参照してください。
コードの例
PCA をスパース データに適用するには、Python で scikit-learn ライブラリを使用できます。
このライブラリは、PCA モデルをデータに適合させ、それを低次元空間に変換するために使用できる PCA クラスを提供します。
次のコードの最初のセクションでは、前のセクションで行ったように、特定の次元とスパース性を使用してデータセットを作成します。
10 番目のセクションでは、PCA を適用してデータセットの次元を XNUMX に減らします。その後、スパース性を再計算します。
これがコードです。
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply PCA to the dataset
pca = PCA(n_components=10)
data_pca = pca.fit_transform(data)
# Calculate the sparsity of the reduced dataset
num_zeros = (data_pca == 0).sum()
total_elements = data_pca.shape[0] * data_pca.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after PCA: {sparsity:.4f}")
これが出力です。

機能ハッシュ
スパース データを処理するもう XNUMX つの方法は、特徴ハッシュと呼ばれます。 このアプローチでは、ハッシュ関数を使用して、各フィーチャを値の固定長配列に変換します。
ハッシュ関数は、各入力フィーチャを固定長配列内の一連のインデックスにマップします。 複数の入力フィーチャが同じインデックスにマップされている場合、値は合計されます。 フィーチャ ハッシュは、大規模なフィーチャ ディクショナリを格納できない可能性がある大規模なデータセットに役立ちます。
これについては次のセクションでまとめて説明しますが、さらに深く掘り下げたい場合は、 こちら scikit-learn ライブラリで機能ハッシュの公式ドキュメントを参照できます。
コードの例
ここでも、データセットの作成で同じ方法を使用します。
次に、scikit-learn の FeatureHasher クラスを使用して、特徴ハッシュをデータセットに適用します。
出力特徴の数を n_features パラメータと入力タイプをディクショナリとして 入力方式 パラメータに一致する最初のデバイスのリモートコントロール URL を返します。
次に、FeatureHasher オブジェクトの transform メソッドを使用して、入力データをハッシュ配列に変換します。
最後に、結果のデータセットのスパース性を計算します。
これがコードです。
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply feature hashing to the dataset
hasher = FeatureHasher(n_features=10, input_type="dict")
data_dict = [ dict(("feature" + str(i), val) for i, val in enumerate(row)) for row in data
]
data_hashed = hasher.transform(data_dict).toarray() # Calculate the sparsity of the reduced dataset
num_zeros = (data_hashed == 0).sum()
total_elements = data_hashed.shape[0] * data_hashed.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after feature hashing: {sparsity:.4f}")
これが出力です。
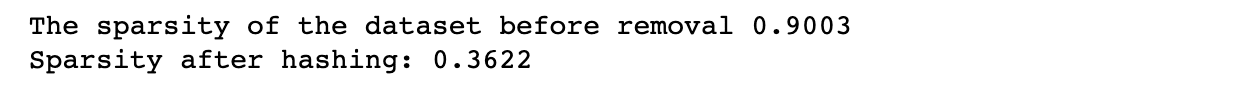
t-SNEの埋め込み
t-SNE (t-Distributed Stochastic Neighbor Embedding) は、高次元データを視覚化するために使用される非線形次元削減手法です。 グローバル構造を維持しながらデータの次元を削減し、機械学習で高次元データを視覚化およびクラスタリングするための一般的なツールになりました。
t-SNE は、データの構造を維持しながらデータの次元を効果的に削減できるため、スパース データの操作に特に役立ちます。 t-SNE アルゴリズムは、高次元空間と低次元空間のデータ ポイント間のペアごとの距離を計算することによって機能します。 次に、高次元空間と低次元空間でこれらの距離の差を最小化します。
スパース データで t-SNE を使用するには、最初にデータを密行列に変換する必要があります。 これは、PCA や機能ハッシュなどのさまざまな手法を使用して実行できます。 データが変換されると、t-SNE を high-x にして、データの低次元埋め込みを取得できます。
また、t-SNEが気になる方は、 こちら 詳しくは、scikit-learn の公式ドキュメントをご覧ください。
コードの例
次のコードは、前の例で行ったように、最初にデータセットの次元とスパース レベルを設定し、指定されたスパース レベルでランダム データを生成し、t-SNE を適用する前にデータセットのスパース性を計算します。
次に、3 つのコンポーネントを持つデータセットに t-SNE を適用し、結果の t-SNE 埋め込みのスパース性を計算します。 最後に、t-SNE 埋め込みのスパース性を出力します。
これがコードです。
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply t-SNE to the dataset
tsne = TSNE(n_components=3)
data_tsne = tsne.fit_transform(data) # Calculate the sparsity of the t-SNE embedding
num_zeros = (data_tsne == 0).sum()
total_elements = data_tsne.shape[0] * data_tsne.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after t-SNE: {sparsity:.4f}")
これが出力です。

まばらなデータを扱う際の課題に対処したので、まばらなデータでうまく機能するように特別に設計された機械学習モデルを探索できます。
これらのモデルは、従来のモデルでは正確な予測を達成することが困難になる可能性がある、多くのゼロや限られた情報を含む多数の特徴など、スパース データの固有の特性を処理できます。
スパース データ用に明示的に設計されたモデルを使用することで、予測の精度と信頼性を高めることができます。
次に、スパース データに適したモデルについて説明しましょう。
SVC (サポート ベクター分類子)
線形カーネルを使用した SVC (サポート ベクター分類子) は、サポート ベクターと呼ばれるトレーニング ポイントのサブセットを使用して予測を行うため、スパース データで適切に機能します。 これは、高次元のスパース データを効率的に処理できることを意味します。
回帰にもサポート ベクターを使用できます。
を説明しました ベクターマシンのサポートはこちら 分類と回帰の両方のサポート ベクター アルゴリズムについて詳しく知りたい場合は、
ロジスティック回帰
ロジスティック回帰では正則化項を使用してモデルの複雑さを制御し、疎なデータセットでの過剰適合を防ぐことができるため、これは疎なデータでもうまく機能します。
ロジスティック回帰やその他の分類アルゴリズムについて詳しく知りたい場合は、こちらをご覧ください 機械学習アルゴリズムの概要: 分類.
KNeighboursClassifier
このアルゴリズムは、データ ポイント間の距離を計算し、高次元データを処理できるため、まばらなデータでうまく機能します。
KNNなどをご覧いただけます 機械学習アルゴリズムはこちら データサイエンスのために知っておくべきこと。
MLP分類子
MLPClassifier は、最適化に勾配降下法を使用するため、入力データが標準化されている場合、まばらなデータでうまく機能します。
ここに ChatGPT の助けを借りて、MLP Classifier の実装と、他の多くのアルゴリズムを確認できます。
デシジョンツリー分類子
特徴の数が少ない場合、まばらなデータでうまく機能します。 決定木を知らない方のために説明しました 決定木とランダムフォレストはこちら、スパース データのモデルを分析するための最終的なモデルになります。
RandomForestClassifier
RandomForestClassifier は、特徴の数が少ない場合、まばらなデータでうまく機能します。

著者による画像
ここで、これらのモデルが生成されたデータに対してどのように機能するかを示します。 ただし、別のアルゴリズムを追加して、これらのアルゴリズムがこのアルゴリズムよりも優れているかどうかを確認します (通常、スパース データには適していません)。
コードの例
このセクションでは、多くの空またはゼロの値を持つデータセットであるスパース データセットで複数の機械学習モデルをテストします。
データセットのスパース性を計算し、F1 スコアを使用してモデルを評価します。
次に、各モデルの F1 スコアを含むデータ フレームを作成して、パフォーマンスを比較します。 また、評価プロセス中に表示される可能性のある警告を除外します。
import numpy as np
from scipy.sparse import random
import numpy as np
from scipy.sparse import random
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.exceptions import ConvergenceWarning
import warnings # Generate a sparse dataset
X = random(1000, 20, density=0.1, format="csr", random_state=42)
y = np.random.randint(2, size=1000) # Calculate the sparsity of the dataset
sparsity = 1.0 - X.nnz / float(X.shape[0] * X.shape[1])
print("Sparsity:", sparsity) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
) # Train and evaluate multiple classifiers
classifiers = [ SVC(kernel="linear"), LogisticRegression(), KMeans( n_clusters=2, init="k-means++", max_iter=100, random_state=42, algorithm="full", ), KNeighborsClassifier(n_neighbors=5), MLPClassifier( hidden_layer_sizes=(100, 50), max_iter=1000, alpha=0.01, solver="sgd", verbose=0, random_state=21, tol=0.000000001, ), DecisionTreeClassifier(), RandomForestClassifier(),
] # Create an empty DataFrame with column names
df = pd.DataFrame(columns=["Classifier", "F1 Score"]) # Filter out the specific warning
warnings.filterwarnings( "ignore", category=ConvergenceWarning
) # Filter warning that mlp classifier will possibly print out. for clf in classifiers: clf.fit(X_train, y_train) y_pred = clf.predict(X_test) f1 = f1_score(y_test, y_pred) df = pd.concat( [ df, pd.DataFrame( {"Classifier": [type(clf).__name__], "F1 Score": [f1]} ), ], ignore_index=True, )
df = df.sort_values(by="F1 Score", ascending=True)
df
これが出力です。
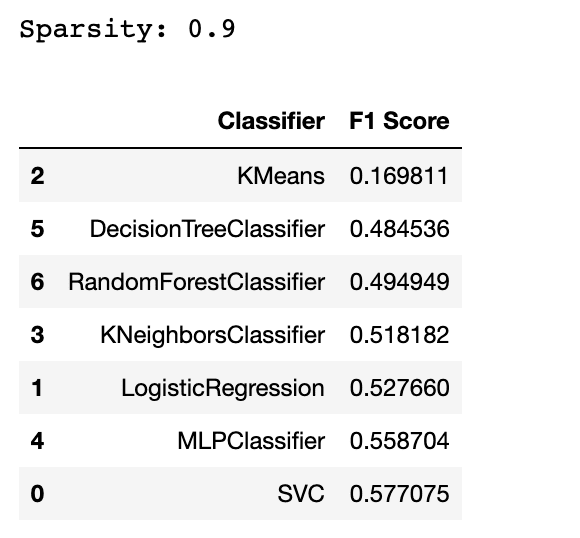
ここまでで、スパース データにはあまり適していないアルゴリズムを見つけたかもしれません。 はい、答えは KMeans です。 しかし、なぜ?
KMeans は通常、疎なデータにはあまり適していません。これは、高次元の疎なデータでは問題になる可能性がある距離測定に基づいているためです。
試すことさえできないアルゴリズムもいくつかあります。 たとえば、このリストに GaussianNB 分類子を含めようとすると、エラーが発生します。 これは、GaussianNB 分類器が疎データではなく密データを想定していることを示唆しています。 これは、GaussianNB 分類器が、入力データがガウス分布に従っており、まばらなデータには適していないと想定しているためです。
結論として、過適合、適切なデータの損失、メモリ、時間の問題などのさまざまな問題により、スパース データの処理が困難になる可能性があります。
ただし、機能の削除、PCA の使用、機能ハッシュなど、スパース機能を操作する方法はいくつかあります。
さらに、SVM、ロジスティック回帰、投げ縄、デシジョン ツリー、ランダム フォレスト、MLP、k 最近傍などの特定の機械学習モデルは、まばらなデータの処理に適しています。
これらのモデルは、高次元のスパース データを効率的に処理するように設計されているため、スパース データの問題に最適です。 これらの方法とモデルを使用すると、モデルの精度が向上し、時間とリソースを節約できます。
ネイト・ロシディ データサイエンティストであり、製品戦略に携わっています。 彼はまた、分析を教える非常勤教授であり、 ストラタスクラッチ、データサイエンティストがトップ企業からの実際の面接の質問で面接の準備をするのを支援するプラットフォーム。 彼とつながる Twitter:StrataScratch or LinkedIn.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/04/best-machine-learning-model-sparse-data.html?utm_source=rss&utm_medium=rss&utm_campaign=best-machine-learning-model-for-sparse-data

