この記事は、の一部として公開されました データサイエンスブログ。
概要
分類問題は、ランダムフォレスト分類器、サポートベクターマシン、ロジスティックリグレッサ(バイナリクラス分類用)などの教師あり学習アルゴリズムを使用して解決されることがよくあります。単一クラスのトレーニング例を使用した特定のタイプのバイナリ分類問題は、ワンクラス分類(OCC)と呼ばれます。 。 1クラス分類は、XNUMXクラスサポートベクターマシン(XNUMX-SVM)、サポートベクターデータ記述(SVDD)などの教師なしまたは半教師あり学習アルゴリズムを使用して解決されます。XNUMXクラス分類の一般的な例のXNUMXつは、アナモリーです。検出(AD)、つまり、異常検出と新規性検出。
XNUMXつのクラスの分類
One Class Classification(OCC)は、トレーニング中に単一クラスのサンプルから学習することにより、特定のクラスのサンプルを区別することを目的としています。 これは、モデルがこれまでに見たことのない異常なケースを特定することを扱う機械学習のサブフィールドである、アナモリー検出(AD)を解決するために最も一般的に使用されるアプローチのXNUMXつです。 OCCは、単項分類、クラスモデリングとも呼ばれます。
サポートベクターマシンの概要
サポートベクターマシン(SVM)は、分類および回帰の問題ステートメントのための最も堅牢な統計アルゴリズムのXNUMXつです。 SVM(別名サポートベクターネットワーク)は、目に見えないデータの一般化がより広いため、分類問題ステートメントで一般的に使用されます。 SVMをより直感的に理解するために、ポジティブな例(緑色のボール)とネガティブな例(青い四角)のデータセットを考えてみましょう。 次の図に示すように、目的は、正の例と負の例を分離する最適な線を描画することですが、線形分類器とは異なり、SVMによって描画される最適な線は、両方のクラスの極値間の距離が最適な線(または中央値)はほぼ等しく、最大です。 学習を通じて溝または最も広い通りを形成するというこのアイデアにより、SVMは見えないデータのテスト中に堅牢になります。 SVMはすでにSK-learnにlibsvmから直接実装されています。 SVCをインポートして、分類の問題に適用できます。 これについての詳細は読むことができます こちら.
最も広い通りを確保するために最大化される関数は2/|w|です。 ここで、wはランダムな重みのベクトルであるため、関数はサポートベクター間のストリートを最大化します。 2 / |w|を最大化する関数1/2*(| w | ^ 2)を最小化することに似ています。 制約のある関数(1/2 *(| w | ^ 2))の極値を見つけるために、つまり、関数がサンプルを誤って分類した場合にペナルティがあり、ラグランジュ乗数が適用されます。 Lagranges乗数を適用すると、複雑な方程式が生成されます。これを導出すると、wrtwは次の関係になります。
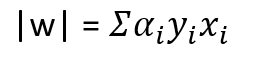
ここで、wは重みのベクトル、alphaはラグランジュ乗数、yは+1または-1のいずれか、つまりサンプルのクラス、xはデータからのサンプルを示します。
中央値または最適な線からの正のサンプルと負のサンプルの両方の極端なサンプル間の側溝または道路を最大化するための関数の数学的導出をよりよく理解するには、リソースを参照してください 【1] & 【2].
画像のソース: ビス.co.in
XNUMXクラスのサポートベクターマシン
1クラスSVMは、特定のクラスのテストサンプルを他のクラスから区別する機能を学習するための教師なし学習手法です。 1-SVMは、ADを含むOCC問題ステートメントにアプローチするための最も便利な方法の1つです。 XNUMX-SVMは、トレーニングデータ内の単一クラスの例の超球を最小化するという基本的な考え方に取り組み、超球外の他のすべてのサンプルを外れ値またはトレーニングデータの分布外と見なします。 次の図は、XNUMX-SVMによって形成された超球を示し、超球に基づいてトレーニング分布データから分類する機能を学習する画像を示しています。
中心cと半径rの超球を計算する数式は次のとおりです。
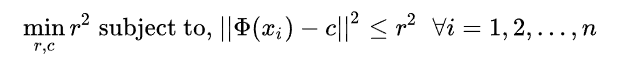
上記の式は、超球の半径を最小化しようとします。 ただし、上記の定式化は外れ値に非常に限定的であるため、ある程度外れ値を許容するためのより柔軟な定式化は、次の式で与えられます。
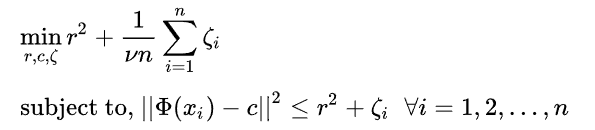
ここで、関数phiはxサンプルの超球変換です。 下の図は、半径r、中心cを最小化することにより、超球の定式化がどのように超球を形成するかを示しています。

1-SVMは、異常値検出と新規性検出の両方の種類の異常検出アプリケーションに使用できます。
画像ソース:One-Class Classification(OCC)に関するウィキペディアのページ。
1サポートベクターマシンの実装
1-SVMの実装は、SK-learnによって非常に簡単になります。 SK-learnはlibsvmから1-SVMを実装します。 SK-learnは、データサンプルからのトレーニングを通じて超球を最小化する数学的モデリングを内部的に実装する「OneClassSVM」と呼ばれるクラスを提供します。 超球を最小化する関数の背後にある数学的推論の詳細については、以下を参照してください。 ページ.
以下の例では、1から10までのランダムな正の整数を使用してXNUMXクラスSVMをトレーニングします。さらに、モデルはランダムな正と負の整数のセットでテストされ、モデルは正と負のクラスまたはサンプルの間で整数を正常に分類します。 。
注:1クラスSVMモデルは、正の整数をクラス+1として扱い、負の整数を-XNUMXとして扱います。 トレーニングデータセット内のサンプルは、One-ClassSVMによって常にポジティブサンプルと見なされます。
>>> sklearn.svm から OneClassSVM をインポート >>> X = [[1],[2],[3],[4],[5],[6],[7],[8],[9] ,[10]] >>> y = [[-1],[1],[-2],[2],[-3]] >>> one_svm = OneClassSVM(ガンマ='auto', nu=0.01 ).fit(X) >>> # ガンマを使用して、学習する超球を形成するためのカーネル関数を設定する >>> # サンプルを微分し、ハイパーパラメータ nu を調整して比率を近似する >>> 外れ値の数 >>> one_svm.predict(y) [-1 1 -1 1 -1] >>> # estimator predict メソッドを使用して、クラス 1、-1 間のデータ ポイントを分類します >>> # トレーニング データに基づいて >>> one_svm. score_samples(y) array([1.24920628e-02, 8.32434204e-01, 8.38893433e-05, 8.32667829e-01, 7.64624773e-08]) >>> # score_samples メソッドを使用して推定器のスコアリング関数にアクセスし、 >>> # 汚染パラメーターは、分類のしきい値を設定するために使用されます >>> one_svm.decision_function(y) array([-8.19890222e-01, 5.19198778e-05, -8.32298395e-01, 2.85544227e-04, - 8.32382208e-01]) >>> # decision_function は n 負の値は >>> # サンプルが異常値またはトレーニング分布から外れていることを表します
ワンクラス分類の応用
ワンクラス分類は、アナモリー検出(AD)で非常に一般的に使用されます。 ADは、機械学習アルゴリズムが一般化するのが難しい分野のXNUMXつです。 ADの例のいくつかは次のとおりです。
1.外れ値の検出:トレーニングデータから外れ値を検出することは、機械学習モデルをトレーニングする前にデータをクリーンアップして、実世界でのモデルの展開後の堅牢なパフォーマンスを確保するための重要なステップです。
2.音響信号のAD:ADの主な用途のXNUMXつは、機械の部品によって生成された音響信号を使用して、産業機械の異常を検出することです。
3.ノベルティ検出および他の多く。
まとめ
1-SVMを理解すると、外れ値の検出や新規性の検出などの異常検出に関連する問題ステートメントを理解するのに役立ちます。 新規性の検出と外れ値の検出には、それぞれ他の半教師あり学習アルゴリズムと教師なし学習アルゴリズムがあります。 SK-learnを使用して実装できる一般的なアルゴリズムには、Isolation Forest、Local Outlier Factor、RobustCovarianceなどがあります。
これらの手法の違いを理解するには、sklearnのドキュメントからXNUMXクラスの分類問題への取り組みまで、他の手法の実装を参照してください。
これらのモデルのパフォーマンスを比較するには、画像を参照してください こちら.
サポートベクターマシンの背後にある数学的推論を理解することは、ワンクラスSVMの概念をよりよく理解するのに役立ちます。 SVMに関するAnalyticsVidyaの記事/ガイドを参照してください こちら。 「VAEとSVDD/1-SVMを使用した音響信号の異常検出」に関する次の記事をお楽しみに。 それまでの間、Analytics Vidyaの記事から、サポートベクターマシン、1-SVM、およびSVDDのアイデアを検討してください。 また、AnalyticsVidyaの記事「初心者向けオートエンコーダの概要」からVAEとそのアーキテクチャを調べてください。 こちら.
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。

