概要
偽造紙幣は、中小企業でも大企業でも簡単に問題になる可能性があります。 これらの紙幣が本物でない場合に識別できることは非常に重要です。 このプロセスは、日常のビジネス プロフェッショナルや現金を扱う個人にとっては時間がかかる可能性があります。 このため、自動化によってこの目標を達成する必要があります。 AI、機械学習、ディープ ラーニングのおかげです。
その結果、私たちは開発する必要があると考えています 自動機械学習 偽札鑑別プロでなくても真贋を判別できるモデルです。
この記事では、銀行部門で深層学習と画像分類を使用する方法の実世界のプロトタイプを開発した実用的なプロジェクトについて説明します。 目標は、実際の問題シナリオを使用して機械学習のデモを完成させることです。 データの取得とディープ クリーニング/前処理から、トレーニング済みモデルの単純なデプロイに進みます。
モデルのパフォーマンスと、モデルがどれだけ適切に学習されたかを確認するために、いくつかの適切な評価指標を使用します。 これは銀行システムであるため、予測が正確であることを確認したいと考えています。
この記事は、の一部として公開されました データサイエンスブログ。
目次
問題提起
冒頭で説明したように、ほとんどの人にとって、偽の紙幣と本物の紙幣を区別することは困難です。 ほとんどの人はこの分野のスキルを持っておらず、簡単にだまされて、詐欺師による偽物と良い通貨を交換してしまう可能性があります。 私たちは、研究のために専門的に入手できるオリジナルおよび偽のコロンビア紙幣を使用して、この問題を解決するという課題に着手します。

このプロジェクトを完了するための前提条件は、機械学習モデル パイプラインの知識、jupyter ノートブックの基本的な経験、およびディープ ラーニングでそれをさらに進めることに関心があることです。 画像処理が初めての方でも、どのセットもわかりやすいので安心です。
データセットの説明
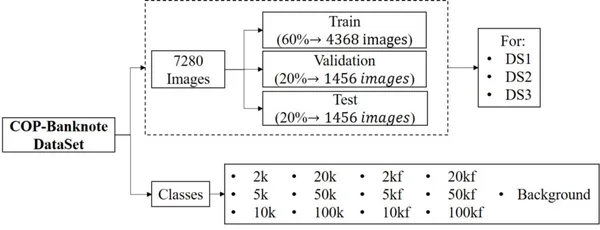
このデータセットは、2020 年に Universidad Militar Nueva Granada によって CC BY 4.0 ライセンスの下で利用できるようになりました。 このデータセットを使用してシステムをリアルタイムでチェックし、紙幣の金種や偽造品を検出できます。 データセットは、サイズと画像数の点で大きなものであり、偽物と本物の両方のクラスのプロがキャプチャした画像で構成されています. 以下のハイライトを見てみましょう。
- このデータセットは、20800 のクラスを含む 13 枚の画像で構成されています。そのうち 6 つは元の紙幣に対応し、別の 6 つは偽造品に対応し、1 つの追加カテゴリは背景に対応します。
- 照明のバリエーション、回転、紙幣の部分的なビューが含まれています。 ds3、ds20800、および ds1 に対応する 2 枚の画像がそれぞれ 3 つのフォルダーに含まれています。
- 各フォルダーには、画像を含むトレーニング、検証、およびテストのサブフォルダーが含まれています。
- すべてのクラスは、画像の数でバランスが取れています。
プロジェクトパイプライン
カバーするすべてのことを把握するために、以下に詳細に開発されたモデルのさまざまなステップの概要を示します。
- 環境のセットアップ
- 依存関係のインポート
- データセットの読み取りとロード
- データ変換
- Data Visualization
- テンソルボーディング
- モデル構築
- 予測の視覚化
- 畳み込みネットワークの微調整
- トレーニングと評価
- 学習した行列の TensorBoard によるレポート
- モデルテスト
- トレーニング済みモデル アーティファクトの保存
- ローカルにデプロイする
- クラウドへのデプロイ (Streamlit Cloud)
注: 実践をフォローアップするために、特にコンピューターにローカル GPU またはグラフィック カードがない場合は、Google Colab を使用してこの作業を再現することをお勧めします。 深層学習での課題はコンピューティング環境ですが、無料で GPU を提供してくれる Google Colab のおかげで、その取り組み方を紹介します。
Step-1: 環境の設定
これ以上苦労することなく、いくつかのコードを書き始めましょう。 Google を使用します アル 開発環境として。 オンラインで簡単に Google Colaboratory を検索したり、https://colab.research.google.com/ にアクセスしたりできます。 jupyter と同じインターフェースを持っているので、Google アカウントさえあればすぐに理解できます。 ホームページは以下のような感じです。

ここで、ランタイムに追加することで使用可能になった無料の GPU を利用してみましょう。 以下に示すように、[ランタイム] タブをクリックし、[ランタイム タイプの変更] を選択します。

「ハードウェア アクセラレータ」の下で、ドロップダウンをクリックし、以下に示すように「GPU」を選択します。
これで GPU が接続されました。 これで、コードを続行できます。
依存関係のインポートを開始する直前に、最後に XNUMX つのことを行う必要があります。 以下の行を使用して、matplotlib でプロットを設定します。 これは、出力またはグラフを整理するのに役立ちます。
#magic function for matplotlib graphs. Graphs will be included in notebook next to the code. %matplotlib inlineStep-2: 依存関係のインポート
#importing dependencies
from __future__ import print_function, division from datetime import datetime
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import time
import os
import copy plt.ion() # interactive modeStep-3: データセットの読み込み
データセットへのリンクは、この記事の最後、またはこの記事に付属するパブリック GitHub リポジトリにあります。 データセットをダウンロードしたら、簡単に使用できるように Google ドライブにアップロードできます。 既にそこにあるので、右側の列からドライバーをロードしてセルを実行するだけです。
from google.colab import drive
drive.mount('/content/drive')#Dataset from drive DATA_FILE = "/content/drive/MyDrive/MLProjects/dataset/COP"
train_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Train/"
val_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Validation/"注: 上記のスニペットでは、パスを独自の Google ドライブ ファイル パスに置き換える必要があります。
Step-4: データ変換
#changing the format and structure of the data.
data_transforms = { 'Train': transforms.Compose([ transforms.Resize((224, 224)),# resizing the image dimention transforms.RandomHorizontalFlip(),# generating different possible image position transforms.ToTensor(), # tensors are like the data type for deep learning images transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # normalizes the tensor image for each channel regards mean and SD ]), 'Validation': transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'Test': transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]),
} data_dir = DATA_FILE
data_types = ['Train', 'Validation', 'Test'] # grouping into the various sets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in data_types}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in data_types}
dataset_sizes = {x: len(image_datasets[x]) for x in data_types}
class_names = image_datasets['Train'].classes #checking for available processor device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")Step-5: データ可視化
データの視覚化の助けを借りて、データがどのように見えるか、画像から何を扱っているかを確認できます。
# Reasigning images for visualization
image_size = 300
batch_size = 128
# converting to Tensors for visualization purpose
train_dataset = ImageFolder(data_dir+'/Train', transform=ToTensor())
val_dataset = ImageFolder(data_dir+'/Validation', transform=ToTensor())img, label = val_dataset[13]
print(img.shape, label)
img上記のコードは、インデックス 13 の val_datasets の XNUMX つのテンソル バージョンを示しています。
def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # Get a batch of training data
inputs, classes = next(iter(dataloaders['Train'])) # Make a grid from batch
out = torchvision.utils.make_grid(inputs) imshow(out, title=[class_names[x] for x in classes])
# attempting to show the image classes and directories
print("List of Directories:", os.listdir(data_dir))
classes = os.listdir(data_dir + "/Train")
print("List of classes:", classes)ディレクトリのリスト: ['Validation', 'Test', 'Train'] クラスのリスト: ['2k', '20k', '50kf', '20kf', '5kf', 'Background', '5k', '50k'、'10k'、'10kf'、'100k'、'2kf'、'100kf']
# carrying out more visualization
import matplotlib.pyplot as plt def show_example(img, label): print('Label: ', train_dataset.classes[label], "("+str(label)+")") plt.imshow(img.permute(1, 2, 0)) import random
random_value = random.randint(1, 2000)# getting random images
show_example(*train_dataset[2000])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
Step-6: テンソルボーディング
TensorBoard は、さまざまなパラメーターがどのように変化したかを後で視覚化できるように、機械学習トレーニングを実行するための優れた方法です。 これは、機械学習ワークフロー中に測定値の変化を視覚化して提供するためのツールです。 これは、パラメーター ロギングの一種と見なすことができます。 ここでは、損失、精度、さらには最後の実行の外れ値を追跡するために使用します。
コード入力:
#tensorboard logging
#to track various metrics such as accuracy and log loss on training or validation set
from torch.utils.tensorboard import SummaryWriter TB_DIR = f'runs/exp_{datetime.now().strftime("%Y%m%d-%H%M%S")}' tb_train_writer = SummaryWriter(f'{TB_DIR}/Train')
tb_val_writer = SummaryWriter(f'{TB_DIR}/Validation') %load_ext tensorboardStep-7: モデル構築
ここで肉とチーズが出会います。 またはまだではありません。 後で呼び出すことができる、必要なすべてのパラメーターと設定を使用してヘルパー関数を作成しましょう。
コード入力:
# helper function
def train_model(model, criterion, optimizer, scheduler, num_epochs=4): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['Train', 'Validation']: if phase == 'Train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'Train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == 'Train': loss.backward() optimizer.step() # statistics running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) if phase == 'Train': scheduler.step() epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects.double() / dataset_sizes[phase] if phase == 'Train': tb_writer = tb_train_writer else: tb_writer = tb_val_writer tb_writer.add_scalar(f'Loss', epoch_loss, epoch) tb_writer.add_scalar(f'Accuracy', epoch_acc, epoch) print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'Validation' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) tb_train_writer.close() tb_val_writer.close() # load best model weights model.load_state_dict(best_model_wts) return modelStep-8: 予測の視覚化
予測を行うためのヘルパー関数をもう XNUMX つ作成します。 コードのより単純なバージョンでは、このフェーズをスキップして、得られた精度を使用することができます。
コード入力:
def visualize_model(model, dataset, num_images=6): was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() with torch.no_grad(): for i, (inputs, labels) in enumerate(dataloaders[dataset]): inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) _, preds = torch.max(outputs, 1) for j in range(inputs.size()[0]): images_so_far += 1 ax = plt.subplot(num_images//2, 2, images_so_far) ax.axis('off') ax.set_title('predicted: {}'.format(class_names[preds[j]])) imshow(inputs.cpu().data[j]) if images_so_far == num_images: model.train(mode=was_training) return model.train(mode=was_training)Step-9: Convnet の微調整
事前トレーニング済みのモデルをロードし、最終的な完全に接続されたレイヤーをリセットします。 この実践は転移学習として知られています。 パラメーターに関して行った設定に依存する代わりに、既にトレーニングされたモデルから知識を借りることも決定しました。 これは、ResNet18 として知られる残留ネットワークです。
残差ネットワーク: 深層学習は多くの種類の人工ニューラル ネットワークで構成されており、残差ニューラル ネットワークはその XNUMX つです。
コード入力:
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to number of classes.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, len(class_names)) model_ft = model_ft.to(device) criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)Step-10: トレーニングと評価
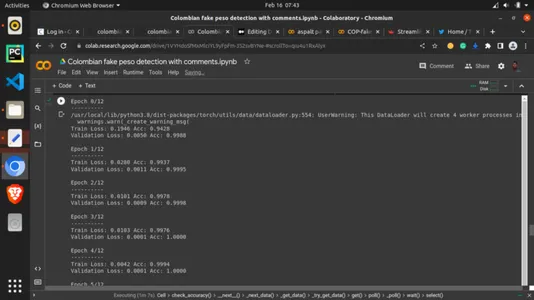
最後に、チーズが肉と出会います。 ここで、以前のヘルパー関数を呼び出し、トレーニング パラメーターを割り当てます。 エポックを 13 に設定します。エポックは、すべてのトレーニング データの反復回数として、トレーニング データが一度に見られるラウンドです。 これは、トレーニング セットがアルゴリズムで使用するビューの数と見なすことができます。 これは間違いなく重要です。 見た目は多ければ多いほどよいのですが、モデルが見過ぎてしまうのは避けたいところです。 13 エポックとは、ここでは 13 回実行することを意味しますが、他の高い値と低い値を試してみることができます。
コード入力:
# setting the number of epochs and other key parametersp model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=13)OUTPUT:
Step-11: 学習したメトリクスの TensorBoard を表示する
コード入力:
# calling the tensorboard %tensorboard --logdir='./runs'Step-12: トレーニング済みモデルの保存
最後に、この記事の torch.save メソッドと PyTorch .pt 拡張子を使用してモデルを保存します。 しばらく待ってから、左側の列で保存されたモードを確認し、それを右クリックしてダウンロードを選択します。 モードがコンピュータにダウンロードされます。 これをアーティファクトと呼びます。 このアーティファクトを次のセクションで使用します。
コード入力:
torch.save(model_ft, 'model100.pt')
Step-13: 保存したモデルをローカルにデプロイする
これが楽しい道です。 GUI を使用して予測を行い、モデルをリアルタイムで表示しようとします。 ここでは、Streamlit フレームワーク用の Python スクリプトを作成します。 コードの詳細は、この記事に付随する GitHub リポジトリにあります。 Streamlit は、機械学習フレームワークをローカルまたはクラウドにデプロイするために設計された軽量のフレームワークです。 最初にローカル バージョンが表示され、次にクラウド バージョンが表示されます。 ファイルを作成し、任意のコード エディターで python .py 拡張子を付けて保存し、以下のコードを記述します。
コード入力:
# importing dependencies
import io
from PIL import Image
import streamlit as st
import torch
from torchvision import transforms
import base64 # setting background
def add_bg_from_local(image_file): with open(image_file, "rb") as image_file: encoded_string = base64.b64encode(image_file.read()) st.markdown( f""" <style> .stApp {{ background-image: url(data:images/{"jpg"};base64,{encoded_string.decode()}); background-size: cover }} </style> """, unsafe_allow_html=True )
add_bg_from_local('images/bg2.jpg') # importing model
MODEL_PATH = 'model/model100.pt'
# importing class names
LABELS_PATH = 'model/model_classes.txt' # image picker
def load_image(): uploaded_file = st.file_uploader(label='Pick a banknote to test') if uploaded_file is not None: image_data = uploaded_file.getvalue() st.image(image_data) return Image.open(io.BytesIO(image_data)) else: return None def load_model(model_path): model = torch.load(model_path, map_location='cpu') model.eval() return model def load_labels(labels_file): with open(labels_file, "r") as f: categories = [s.strip() for s in f.readlines()] return categories def predict(model, categories, image): preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(image) input_batch = input_tensor.unsqueeze(0) with torch.no_grad(): output = model(input_batch) probabilities = torch.nn.functional.softmax(output[0], dim=0) all_prob, all_catid = torch.topk(probabilities, len(categories)) for i in range(all_prob.size(0)): st.write(categories[all_catid[i]], all_prob[i].item()) def main(): st.title('Colombian Pesu banknote Detection') model = load_model(MODEL_PATH) categories = load_labels(LABELS_PATH) image = load_image() result = st.button('Predict image') if result: st.write('Checking...') predict(model, categories, image) if __name__ == '__main__': main()注: モデルと一緒にインポートされたクラス ファイルも作成する必要があります。 これを行うには、「model_classes.txt」という名前のテキスト ファイルを作成します。 これを保存してから、python スクリプトと同じディレクトリにある「model」という名前のフォルダーにモデルをダウンロードします。 また、クラス名はトレーニング方法に従っている必要があることに注意する必要があります。 これは、上記のクラスとディレクトリを印刷した場所から見つけることができます。 以下に示すように、モデルはテキスト ファイルを XNUMX 行ずつ読み取るため、すべてのクラスが XNUMX 行になるようにします。
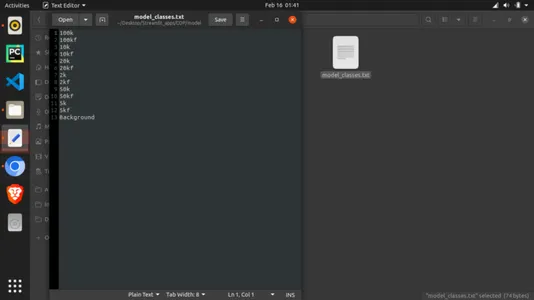
Python スクリプトを実行するには、パッケージがまだインストールされていない場合はインストールする必要があります。 リポジトリで見つけることができる依存関係は次のとおりです。
- 流線型
- トーチ
- トーチビジョン
依存関係をインストールした後、スクリプトがあるディレクトリのターミナルで実行します。
streamlit run filename.pyうまくいけば、これによりアプリが次のように表示されるはずです。

Step-14: クラウドへのデプロイ
近くにいない人と機械学習アプリを共有したいと思うかもしれません。 これは、クラウド インフラストラクチャを介して実行できます。 リポジトリを Streamlit Cloud に接続するには、作業ディレクトリを GitHub などのオンライン コード管理プラットフォームに移動する必要があります。 Git を使用してディレクトリをプッシュし、 https://streamlit.io/cloud 以下のようなホーム画面で:
サインアップして、「Get Started」をクリックします。 サインアップする必要があります。 それは完全に無料です! サインアップしたら、アプリがある GitHub リポジトリを選択して選択します。 デプロイを選択して、アプリが焼き上がるまで待ってください! これで、共有用のリンクをコピーできます。
まとめ
Streamlit コミュニティ クラウドを使用して、美しく強力な機械学習製品をトレーニング、保存、およびクラウドにデプロイすることができました。 また、100 番目のエポックで 3% の精度が得られました。
主要な取り組み
- 偽造紙幣は、銀行部門にとって簡単に問題になる可能性があります。 これらの紙幣を識別できるようにすることは、ディープ ラーニングを使用して達成できたタスクです。
- 私たちは、専門家でなくてもこれらの紙幣の真正性を検出するために使用できる自動機械学習偽紙幣検出モデルを開発しました。
- 100% の精度で、損失と精度を含むいくつかの適切な評価指標を使用しました。
- ディープ ラーニングを使用して、モデルをローカルとクラウドの両方にデプロイしました。
参考文献
Pachon Suescun、Cesar; バレステロス、ドラ・マリア。 Renza、Diego (2020)、「オリジナルおよび偽造のコロンビア ペソ紙幣」、Mendeley Data、V1、doi: 10.17632/tj8kvrbfz6.1
リンク
パブリック GitHub リポジトリ: https://github.com/inuwamobarak/Deep-learning-in-Banking
データセット: https://data.mendeley.com/datasets/tj8kvrbfz6/1
ストリームリット: https://streamlit.io/
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/02/deep-learning-in-banking-colombian-peso-banknote-detection/

