AWS を活用したデータレイクは、比類のない可用性によってサポートされています。 Amazon シンプル ストレージ サービス (Amazon S3) は、さまざまなデータと分析アプローチを組み合わせるために必要なスケール、俊敏性、柔軟性を処理できます。データ レイクのサイズが増大し、使用方法が成熟するにつれて、データとビジネス イベントの整合性を維持するために多大な労力が費やされる可能性があります。ファイルがトランザクション的に一貫した方法で更新されるようにするために、次のようなオープンソースのトランザクション テーブル形式を使用する顧客が増えています。 アパッチ氷山, アパッチ・フディ, Linux Foundation デルタレイク これは、高圧縮率でデータを保存し、アプリケーションやフレームワークとネイティブにインターフェイスし、Amazon S3 上に構築されたデータレイクでの増分データ処理を簡素化するのに役立ちます。これらの形式により、ACID (アトミック性、整合性、分離性、耐久性) トランザクション、アップサート、削除、および以前はデータ ウェアハウスでのみ利用可能であったタイム トラベルやスナップショットなどの高度な機能が可能になります。各ストレージ形式は、この機能をわずかに異なる方法で実装します。比較については、を参照してください。 AWS のトランザクション データ レイクにオープン テーブル形式を選択する.
2023年には、 AWS が一般提供を発表 Apache Iceberg、Apache Hudi、および Linux Foundation Delta Lake の場合 Apache Spark 用 Amazon Athenaこれにより、別個のコネクタまたは関連する依存関係をインストールしてバージョンを管理する必要がなくなり、これらのフレームワークの使用に必要な構成手順が簡素化されます。
この投稿では、Spark SQL を使用する方法を説明します。 アマゾンアテナ ノートブックを作成し、Iceberg、Hudi、Delta Lake テーブル形式で動作します。 Athena の Spark SQL を使用した、データベースとテーブルの作成、テーブルへのデータの挿入、データのクエリ、Amazon S3 でのテーブルのスナップショットの確認などの一般的な操作を示します。
前提条件
次の前提条件を完了します。
Amazon S3 からサンプルノートブックをダウンロードしてインポートする
手順を進めるには、この投稿で説明したノートブックを次の場所からダウンロードしてください。
ノートブックをダウンロードした後、次の手順に従ってノートブックを Athena Spark 環境にインポートします。 ノートブックをインポートするには のセクション ノートブック ファイルの管理.
特定の「Open Table Format」セクションに移動します
Iceberg テーブル形式に興味がある場合は、次の場所に移動してください。 Apache Iceberg テーブルの操作 のセクションから無料でダウンロードできます。
Hudi テーブル形式に興味がある場合は、次の場所に移動してください。 Apache Hudi テーブルの操作 のセクションから無料でダウンロードできます。
Delta Lake テーブル形式に興味がある場合は、次の場所に移動してください。 Linux 基盤の Delta Lake テーブルの操作 のセクションから無料でダウンロードできます。
Apache Iceberg テーブルの操作
Athena で Spark ノートブックを使用する場合、PySpark を使用せずに SQL クエリを直接実行できます。これを行うには、セル マジックを使用します。セル マジックは、セルの動作を変更するノートブック セル内の特別なヘッダーです。 SQL の場合、次を追加できます。 %%sql マジックは、セルの内容全体を Athena 上で実行される SQL ステートメントとして解釈します。
このセクションでは、Apache Spark for Athena で SQL を使用して Apache Iceberg テーブルを作成、分析、管理する方法を示します。
ノートブックセッションをセットアップする
Athena で Apache Iceberg を使用するには、セッションの作成または編集中に、 アパッチ氷山 オプションを展開して、 Apache Spark のプロパティ セクション。次のスクリーンショットに示すように、プロパティが事前に設定されます。
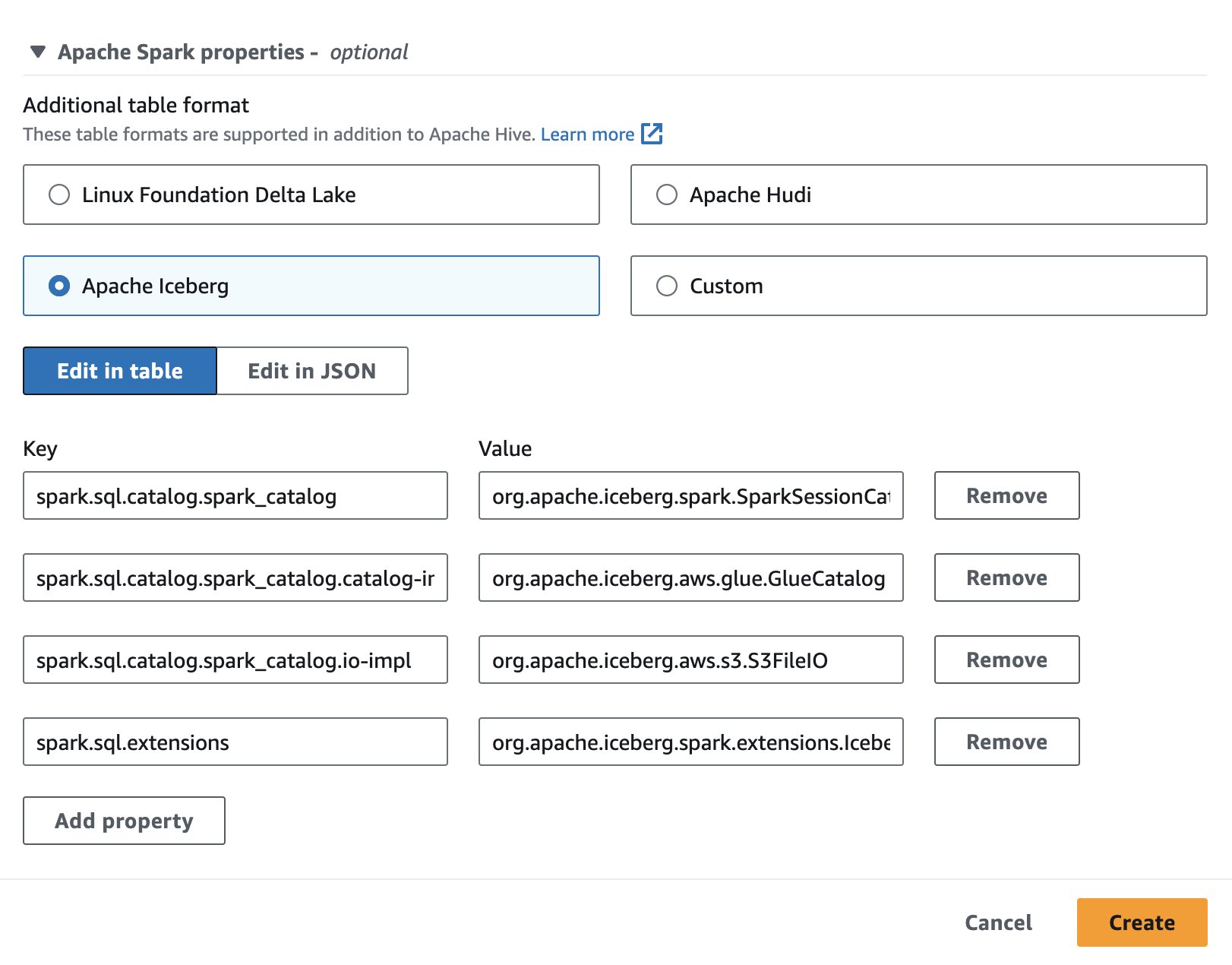
手順については、を参照してください。 セッションの詳細の編集 or 自分だけのノートを作成する.
このセクションで使用されているコードは、次の場所にあります。 SparkSQL_iceberg.ipynb ファイルを参照してください。
データベースと Iceberg テーブルを作成する
まず、AWS Glue データカタログにデータベースを作成します。次の SQL を使用すると、次のようなデータベースを作成できます。 icebergdb:
次にデータベース内で icebergdbという名前の Iceberg テーブルを作成します。 noaa_iceberg データをロードする Amazon S3 内の場所を指します。次のステートメントを実行し、場所を置き換えます s3://<your-S3-bucket>/<prefix>/ S3 バケットとプレフィックスを使用して:
テーブルにデータを挿入する
を設定するには、 noaa_iceberg Iceberg テーブル、Parquet テーブルからデータを挿入します sparkblogdb.noaa_pq これは前提条件の一部として作成されました。これを行うには、 INSERT INTO Spark でのステートメント:
また、 SELECTとしてのテーブルの作成 USING Iceberg 句を使用して、1 ステップで Iceberg テーブルを作成し、ソース テーブルからデータを挿入します。
Iceberg テーブルにクエリを実行する
データが Iceberg テーブルに挿入されたので、分析を開始できます。 Spark SQL を実行して、年ごとに記録された最低気温を見つけてみましょう。 'SEATTLE TACOMA AIRPORT, WA US' 場所:
次の出力が得られます。

Iceberg テーブルのデータを更新する
テーブル内のデータを更新する方法を見てみましょう。駅名を更新したい 'SEATTLE TACOMA AIRPORT, WA US' 〜へ 'Sea-Tac'。 Spark SQL を使用すると、 UPDATE Iceberg テーブルに対するステートメント:
次に、前の SELECT クエリを実行して、その場所で記録された最低温度を見つけることができます。 'Sea-Tac' 場所:
次の出力が得られます。

コンパクトなデータファイル
Iceberg のようなオープン テーブル フォーマットは、ファイル ストレージ内にデルタ変更を作成し、マニフェスト ファイルを通じて行のバージョンを追跡することによって機能します。データファイルが増えるとマニフェストファイルに保存されるメタデータも多くなり、データファイルが小さいと不要な量のメタデータが発生することが多く、その結果クエリの効率が低下し、Amazon S3 アクセスコストが高くなります。アイスバーグのランニング rewrite_data_files Spark for Athena のプロシージャは、多くの小さなデルタ変更ファイルを、読み取りに最適化された小さな Parquet ファイルのセットに結合して、データ ファイルを圧縮します。ファイルを圧縮すると、クエリ時の読み取り操作が高速化されます。テーブルで圧縮を実行するには、次の Spark SQL を実行します。
rewrite_data_files にはオプションがあります をクリックして並べ替え戦略を指定します。これは、データの再編成と圧縮に役立ちます。
テーブルのスナップショットをリストする
Iceberg テーブルに対する書き込み、更新、削除、アップサート、圧縮の各操作により、テーブルの新しいスナップショットが作成されますが、スナップショットの分離とタイム トラベルのために古いデータとメタデータは保持されます。 Iceberg テーブルのスナップショットを一覧表示するには、次の Spark SQL ステートメントを実行します。
古いスナップショットを期限切れにする
不要になったデータ ファイルを削除し、テーブル メタデータのサイズを小さく保つために、スナップショットを定期的に期限切れにすることをお勧めします。期限切れになっていないスナップショットにまだ必要なファイルは削除されません。 Spark for Athena で、次の SQL を実行してテーブルのスナップショットを期限切れにします icebergdb.noaa_iceberg 特定のタイムスタンプより古いもの:
タイムスタンプ値は、次の形式の文字列として指定されることに注意してください。 yyyy-MM-dd HH:mm:ss.fff。出力には、削除されたデータ ファイルとメタデータ ファイルの数が表示されます。
テーブルとデータベースを削除します
次の Spark SQL を実行して、この演習から Amazon S3 内の Iceberg テーブルと関連データをクリーンアップできます。
次の Spark SQL を実行して、データベース Icebergdb を削除します。
Spark for Athena を使用して Iceberg テーブルで実行できるすべての操作の詳細については、「」を参照してください。 スパーククエリ & スパーク手順 Iceberg のドキュメントに記載されています。
Apache Hudi テーブルの操作
次に、Spark for Athena で SQL を使用して Apache Hudi テーブルを作成、分析、管理する方法を示します。
ノートブックセッションをセットアップする
Athena で Apache Hudi を使用するには、セッションの作成または編集中に、 アパッチ・フディ オプションを展開して、 Apache Spark のプロパティ のセクションから無料でダウンロードできます。
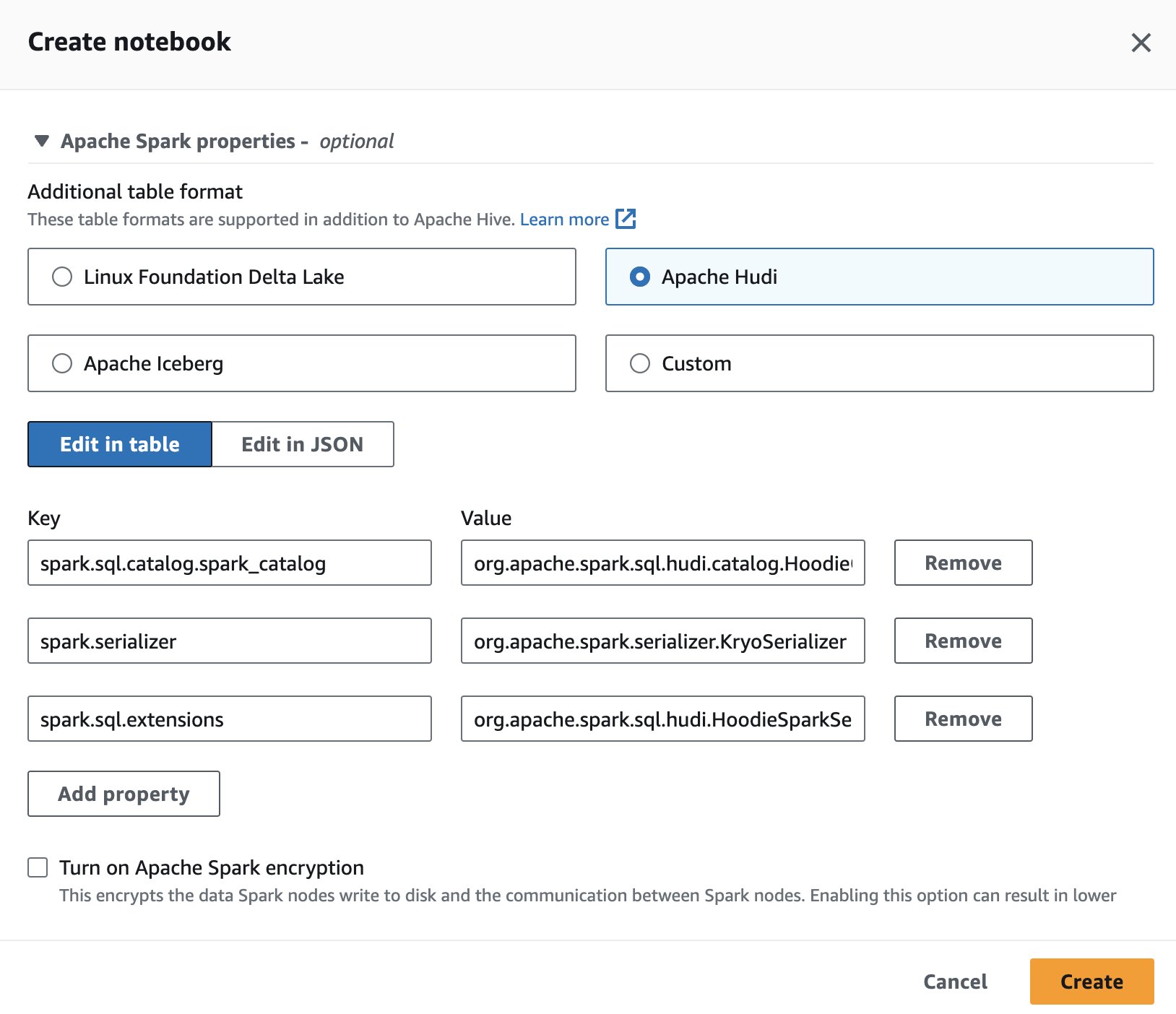
手順については、を参照してください。 セッションの詳細の編集 or 自分だけのノートを作成する.
このセクションで使用されるコードは、 SparkSQL_hudi.ipynb ファイルを参照してください。
データベースとHudiテーブルを作成する
まず、というデータベースを作成します。 hudidb これは AWS Glue データ カタログに保存され、その後 Hudi テーブルが作成されます。
データをロードする Amazon S3 内の場所を指す Hudi テーブルを作成します。表は次のものであることに注意してください。 コピーオンライト タイプ。それは次のように定義されます type= 'cow' テーブル DDL 内。 station と date を複数の主キーとして定義し、preCombinedField を年として定義しました。また、テーブルは年ごとにパーティション化されます。次のステートメントを実行し、場所を置き換えます s3://<your-S3-bucket>/<prefix>/ S3 バケットとプレフィックスを使用して:
テーブルにデータを挿入する
Iceberg と同様に、 INSERT INTO からデータを読み取ってテーブルにデータを設定するステートメント sparkblogdb.noaa_pq 前回の投稿で作成したテーブル:
Hudi テーブルをクエリする
テーブルが作成されたので、クエリを実行して、その場所で記録された最高温度を見つけてみましょう。 'SEATTLE TACOMA AIRPORT, WA US' 場所:
Hudi テーブルのデータを更新する
駅名を変えましょう 'SEATTLE TACOMA AIRPORT, WA US' 〜へ 'Sea–Tac'。 Spark for Athena で UPDATE ステートメントを実行すると、 update の記録 noaa_hudi テーブル:
前の SELECT クエリを実行して、記録された最高温度を見つけます。 'Sea-Tac' 場所:
タイムトラベルクエリを実行する
Athena 上の SQL でタイムトラベル クエリを使用して、過去のデータ スナップショットを分析できます。例えば:
このクエリは、過去の特定の時点でのシアトル空港の気温データをチェックします。タイムスタンプ句を使用すると、現在のデータを変更せずに戻ることができます。タイムスタンプ値は、次の形式の文字列として指定されることに注意してください。 yyyy-MM-dd HH:mm:ss.fff.
クラスタリングによるクエリ速度の最適化
クエリのパフォーマンスを向上させるには、次のことを実行できます。 クラスタリング Spark for Athena で SQL を使用する Hudi テーブル:
コンパクトなテーブル
コンパクションは、Hudi が特に Merge On Read (MOR) テーブルで使用するテーブル サービスで、行ベースのログ ファイルから対応する列ベースのベース ファイルに更新を定期的にマージして、新しいバージョンのベース ファイルを生成します。圧縮はコピー オン ライト (COW) テーブルには適用されず、MOR テーブルにのみ適用されます。 Spark for Athena で次のクエリを実行して、MOR テーブルで圧縮を実行できます。
テーブルとデータベースを削除します
次の Spark SQL を実行して、作成した Hudi テーブルと関連データを Amazon S3 の場所から削除します。
次の Spark SQL を実行してデータベースを削除します hudidb:
Spark for Athena を使用して Hudi テーブルで実行できるすべての操作については、「」を参照してください。 SQL DDL & 手順 Hudi のドキュメントに記載されています。
Linux 基盤の Delta Lake テーブルの操作
次に、Spark for Athena で SQL を使用して Delta Lake テーブルを作成、分析、管理する方法を示します。
ノートブックセッションをセットアップする
Spark for Athena で Delta Lake を使用するには、セッションの作成または編集中に、 Linux Foundation デルタレイク 展開することにより Apache Spark のプロパティ のセクションから無料でダウンロードできます。

手順については、を参照してください。 セッションの詳細の編集 or 自分だけのノートを作成する.
このセクションで使用されるコードは、 SparkSQL_delta.ipynb ファイルを参照してください。
データベースと Delta Lake テーブルを作成する
このセクションでは、AWS Glue データ カタログにデータベースを作成します。次の SQL を使用して、というデータベースを作成できます。 deltalakedb:
次にデータベース内で deltalakedbという名前の Delta Lake テーブルを作成します。 noaa_delta データをロードする Amazon S3 内の場所を指します。次のステートメントを実行し、場所を置き換えます s3://<your-S3-bucket>/<prefix>/ S3 バケットとプレフィックスを使用して:
テーブルにデータを挿入する
私たちは使用します INSERT INTO からデータを読み取ってテーブルにデータを設定するステートメント sparkblogdb.noaa_pq 前回の投稿で作成したテーブル:
CREATE TABLE AS SELECT を使用して Delta Lake テーブルを作成し、1 つのクエリでソース テーブルからデータを挿入することもできます。
Delta Lake テーブルをクエリする
データが Delta Lake テーブルに挿入されたので、分析を開始できます。 Spark SQL を実行して、最低記録温度を見つけてみましょう。 'SEATTLE TACOMA AIRPORT, WA US' 場所:
デルタレイクテーブルのデータを更新する
駅名を変えましょう 'SEATTLE TACOMA AIRPORT, WA US' 〜へ 'Sea–Tac'。実行できます UPDATE Spark for Athena のレコードを更新するためのステートメント noaa_delta テーブル:
前の SELECT クエリを実行して、その場所で記録された最低温度を見つけることができます。 'Sea-Tac' 場所を指定すると、結果は前と同じになるはずです。
コンパクトなデータファイル
Spark for Athena では、Delta Lake テーブルで OPTIMIZE を実行できます。これにより、小さなファイルが大きなファイルに圧縮されるため、小さなファイルのオーバーヘッドによってクエリに負担がかかりません。圧縮操作を実行するには、次のクエリを実行します。
参照する 最適化 OPTIMIZE の実行中に使用できるさまざまなオプションについては、Delta Lake のドキュメントを参照してください。
Delta Lake テーブルによって参照されなくなったファイルを削除する
Spark for Athena を使用してテーブルに対して VACCUM コマンドを実行することで、Delta Lake テーブルで参照されなくなった、保持しきい値より古い Amazon S3 に保存されているファイルを削除できます。
参照する デルタテーブルによって参照されなくなったファイルを削除します VACUUM で使用できるオプションについては、Delta Lake のドキュメントを参照してください。
テーブルとデータベースを削除します
次の Spark SQL を実行して、作成した Delta Lake テーブルを削除します。
次の Spark SQL を実行してデータベースを削除します deltalakedb:
Delta Lake テーブルとデータベースで DROP TABLE DDL を実行すると、これらのオブジェクトのメタデータが削除されますが、Amazon S3 内のデータ ファイルは自動的に削除されません。ノートブックのセルで次の Python コードを実行して、S3 の場所からデータを削除できます。
Spark for Athena を使用して Delta Lake テーブルで実行できる SQL ステートメントの詳細については、「 クイックスタート Delta Lake のドキュメントに記載されています。
まとめ
この投稿では、Athena ノートブックで Spark SQL を使用してデータベースとテーブルを作成し、データの挿入とクエリを実行し、Hudi、Delta Lake、Iceberg テーブルで更新、圧縮、タイムトラベルなどの一般的な操作を実行する方法を説明しました。オープン テーブル フォーマットは、ACID トランザクション、アップサート、削除をデータ レイクに追加し、生のオブジェクト ストレージの制限を克服します。 Spark on Athena の組み込み統合により、個別のコネクタをインストールする必要がなくなるため、Amazon S3 で信頼性の高いデータレイクを構築するためのこれらの一般的なフレームワークを使用する際の設定手順と管理オーバーヘッドが削減されます。データ レイク ワークロードにオープン テーブル形式を選択する方法の詳細については、次を参照してください。 AWS のトランザクション データ レイクにオープン テーブル形式を選択する.
著者について
![]() パティック・シャー Amazon Athena のシニア分析アーキテクトです。 彼は 2015 年に AWS に入社し、それ以来ビッグデータ分析分野に注力し、AWS 分析サービスを使用して顧客がスケーラブルで堅牢なソリューションを構築できるよう支援しています。
パティック・シャー Amazon Athena のシニア分析アーキテクトです。 彼は 2015 年に AWS に入社し、それ以来ビッグデータ分析分野に注力し、AWS 分析サービスを使用して顧客がスケーラブルで堅牢なソリューションを構築できるよう支援しています。
![]() ラジ・デヴナス は、Amazon Athena の AWS のプロダクト マネージャーです。 彼は、顧客に愛される製品を構築し、顧客がデータから価値を抽出できるよう支援することに情熱を注いでいます。 彼の経歴は、金融、小売、スマート ビルディング、ホーム オートメーション、データ通信システムなどの複数の最終市場向けのソリューションの提供にあります。
ラジ・デヴナス は、Amazon Athena の AWS のプロダクト マネージャーです。 彼は、顧客に愛される製品を構築し、顧客がデータから価値を抽出できるよう支援することに情熱を注いでいます。 彼の経歴は、金融、小売、スマート ビルディング、ホーム オートメーション、データ通信システムなどの複数の最終市場向けのソリューションの提供にあります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/

