多くの企業がオンプレミスのデータストアを AWS クラウドに移行しています。データ移行中の重要な要件は、ソースからターゲットに移動されたすべてのデータを検証することです。このデータ検証は重要なステップであり、正しく行われないとプロジェクト全体の失敗につながる可能性があります。ただし、ソースとターゲット間のデータを比較して移行の精度を判断するカスタム ソリューションの開発には、多くの場合時間がかかります。
この投稿では、構成ベースのツールを使用して、移行後に大規模なデータセットを検証する手順を段階的に説明します。 アマゾンEMR Apache Griffin オープン ソース ライブラリ。 Griffin は、バッチ モードとストリーミング モードの両方をサポートするビッグ データ用のオープン ソース データ品質ソリューションです。
組織がペタバイト規模のデータを扱う今日のデータ主導の状況では、自動化されたデータ検証フレームワークの必要性がますます重要になっています。手動による検証プロセスは時間がかかるだけでなく、特に大量のデータを扱う場合にはエラーが発生しやすくなります。自動化されたデータ検証フレームワークは、大規模なデータセットを効率的に比較し、不一致を特定し、大規模なデータの正確性を確保することで、合理化されたソリューションを提供します。このようなフレームワークを使用すると、組織はデータの整合性に対する信頼を維持しながら貴重な時間とリソースを節約できるため、情報に基づいた意思決定が可能になり、全体的な運用効率が向上します。
このフレームワークの優れた機能は次のとおりです。
- 構成主導のフレームワークを利用します
- シームレスな統合のためのプラグアンドプレイ機能を提供します
- カウント比較を実行して不一致を特定します
- 堅牢なデータ検証手順を実装
- 体系的なチェックを通じてデータ品質を保証します
- 詳細な分析のために、不一致のレコードを含むファイルへのアクセスを提供します
- 洞察と追跡を目的とした包括的なレポートを生成します
ソリューションの概要
このソリューションでは、次のサービスを使用します。
- Amazon シンプル ストレージ サービス (Amazon S3) または Hadoop 分散ファイル システム (HDFS) をソースおよびターゲットとして使用します。
- アマゾンEMR PySpark スクリプトを実行します。 Griffin 上の Python ラッパーを使用して、HDFS または Amazon S3 経由で作成された Hadoop テーブル間のデータを検証します。
- AWSグルー Griffin ジョブの結果を保存する技術テーブルをカタログ化します。
- アマゾンアテナ 出力テーブルをクエリして結果を確認します。
各ソーステーブルとターゲットテーブルのカウントを保存するテーブルを使用し、ソースとターゲット間のレコードの違いを示すファイルも作成します。
次の図は、ソリューションのアーキテクチャを示しています。
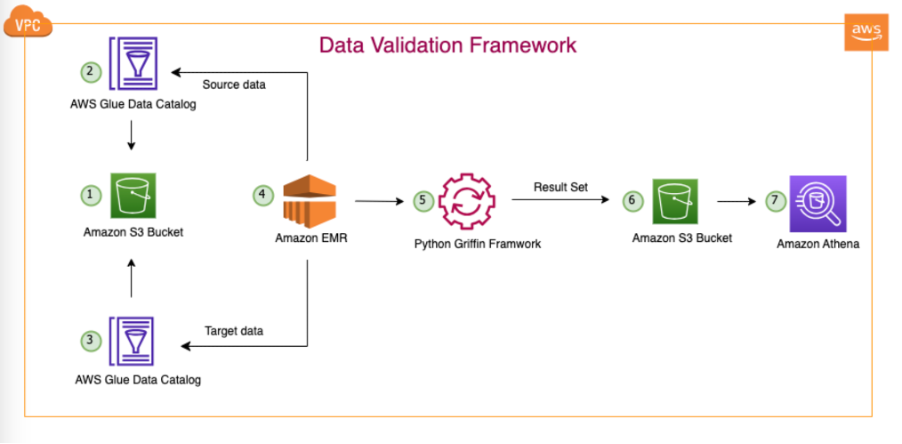
図示のアーキテクチャと典型的なデータレイクの使用例では、データは Amazon S3 に存在するか、次のようなレプリケーション ツールを使用してオンプレミスから Amazon S3 に移行されます。 AWS データ同期 or AWSデータベース移行サービス (AWS DMS)。このソリューションは、Hive Metastore と AWS Glue データ カタログの両方とシームレスに対話できるように設計されていますが、この投稿では例としてデータ カタログを使用します。
このフレームワークは Amazon EMR 内で動作し、定義された頻度に従ってスケジュールされたタスクを毎日自動的に実行します。 Amazon S3 でレポートを生成して公開し、Athena 経由でアクセスできるようにします。このフレームワークの注目すべき機能は、一致しなかった完全なレコードを含むファイルを Amazon S3 に生成することに加えて、カウントの不一致やデータの不一致を検出して、さらなる分析を容易にする機能です。
この例では、オンプレミス データベース内の 3 つのテーブルを使用して、ソースとターゲットの間を検証します。 balance_sheet, covid, survery_financial_report.
前提条件
開始する前に、次の前提条件があることを確認してください。
ソリューションを展開する
簡単に開始できるように、ソリューションを自動的に構成してデプロイする CloudFormation テンプレートを作成しました。次の手順を実行します。
- AWS アカウントに S3 バケットを作成します。
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(AWS アカウント ID と AWS リージョンを入力します)。 - 以下を解凍してください file ローカル システムに。
- ファイルをローカル システムに解凍した後、次のように変更します。 アカウントで作成したもの (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) 次のファイルにあります。bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- ローカル フォルダー内のすべてのフォルダーとファイルを S3 バケットにアップロードします。
- 以下を実行します CloudFormationテンプレート あなたのアカウントに。
CloudFormation テンプレートは、というデータベースを作成します。 griffin_datavalidation_blog と呼ばれる AWS Glue クローラー griffin_data_validation_blog .zip ファイルのデータ フォルダーの上にあります。
- 選択する Next.
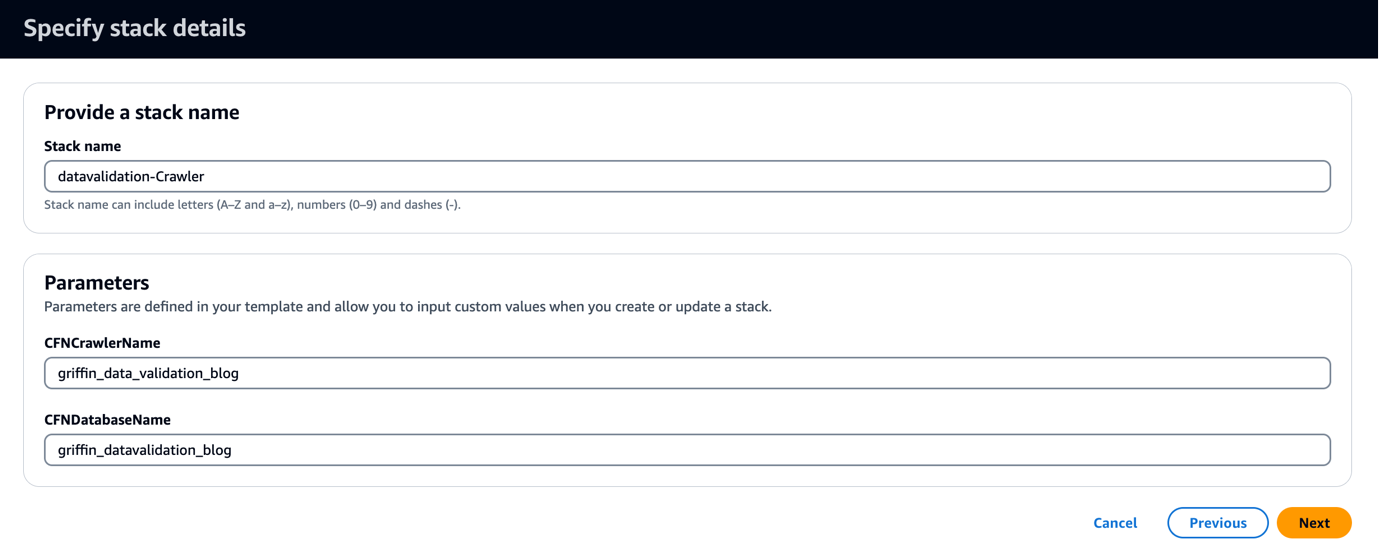
- 選択する Next 再び。
- ソフトウェア設定ページで、下図のように レビュー AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます.
- 選択する スタックを作成.
また、ご購読はいつでも停止することが可能です スタック出力を表示する AWSマネジメントコンソール または、次の AWS CLI コマンドを使用します。
- AWS Glue クローラーを実行し、データ カタログに 6 つのテーブルが作成されたことを確認します。
- 以下を実行します CloudFormationテンプレート あなたのアカウントに。
このテンプレートは、Griffin 関連の JAR およびアーティファクトをコピーするブートストラップ スクリプトを使用して EMR クラスターを作成します。また、次の 3 つの EMR ステップも実行されます。
- Griffin フレームワークによって生成された検証マトリックスを確認するには、2 つの Athena テーブルと 2 つの Athena ビューを作成します。
- 3 つのテーブルすべてに対してカウント検証を実行して、ソース テーブルとターゲット テーブルを比較します。
- 3 つのテーブルすべてに対してレコード レベルと列レベルの検証を実行して、ソース テーブルとターゲット テーブルを比較します。
- サブネットID、サブネット ID を入力します。
- 選択する Next.
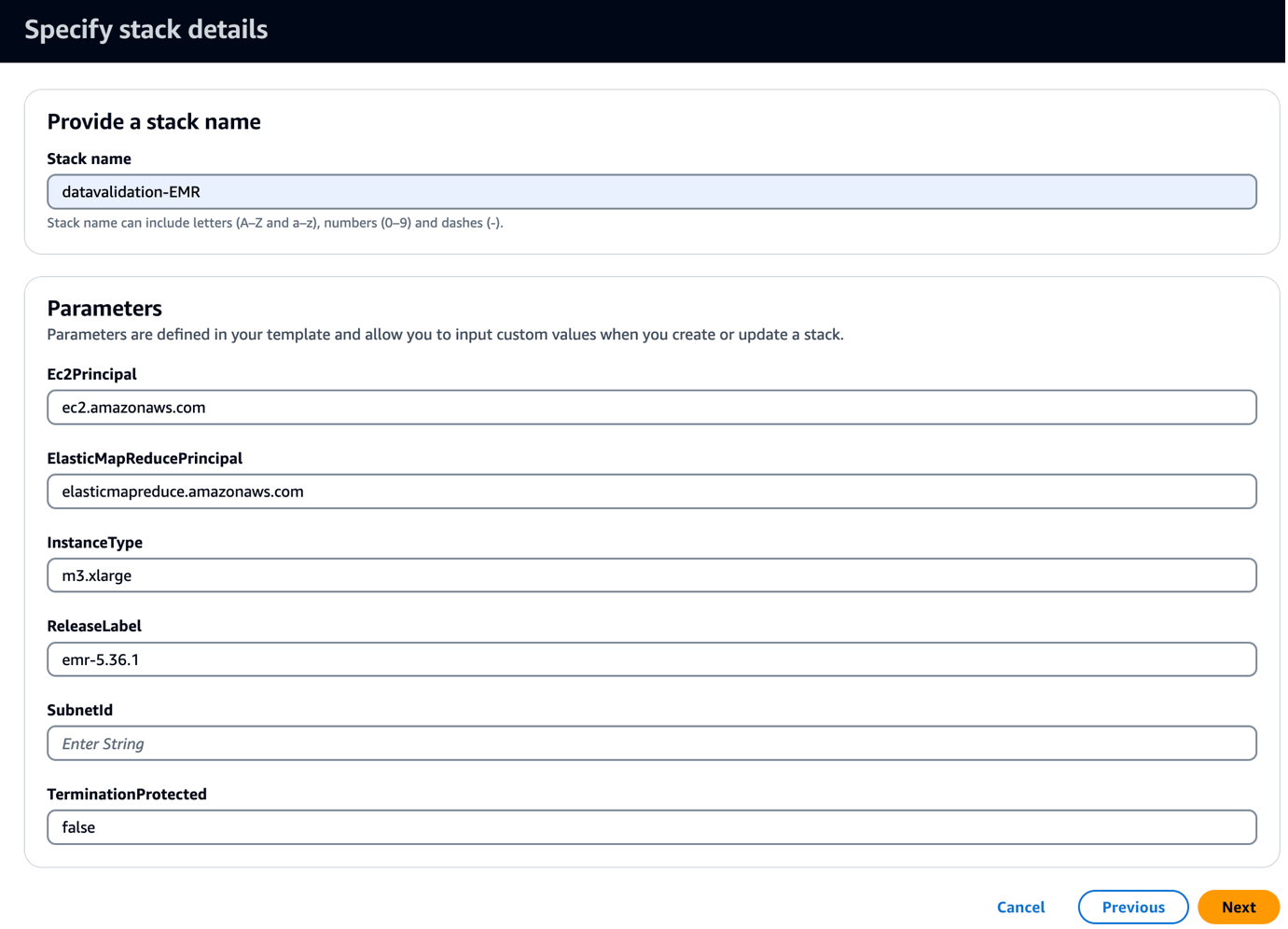
- 選択する Next 再び。
- ソフトウェア設定ページで、下図のように レビュー AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます.
- 選択する スタックを作成.
スタック出力は、コンソール上で表示するか、次の AWS CLI コマンドを使用して表示できます。
デプロイが完了するまでに約 5 分かかります。スタックが完了すると、次のようなメッセージが表示されます。 EMRCluster リソースが起動され、アカウントで利用可能になります。
EMR クラスターが起動されると、クラスター起動後の一環として次の手順が実行されます。
- ブートストラップアクション – このフレームワークの Griffin JAR ファイルとディレクトリをインストールします。また、次のステップで使用するサンプル データ ファイルもダウンロードします。
- Athena_Table_Creation – 結果レポートを読み取るためのテーブルを Athena に作成します。
- カウント_検証 – Data Catalog テーブルのソース データとターゲット データのデータ数を比較するジョブを実行し、結果を S3 バケットに保存し、Athena テーブル経由で読み取られます。
- 正確さ – ジョブを実行して、Data Catalog テーブルのソース データとターゲット データの間でデータ行を比較し、その結果を S3 バケットに保存します。この結果は、Athena テーブルを介して読み取られます。
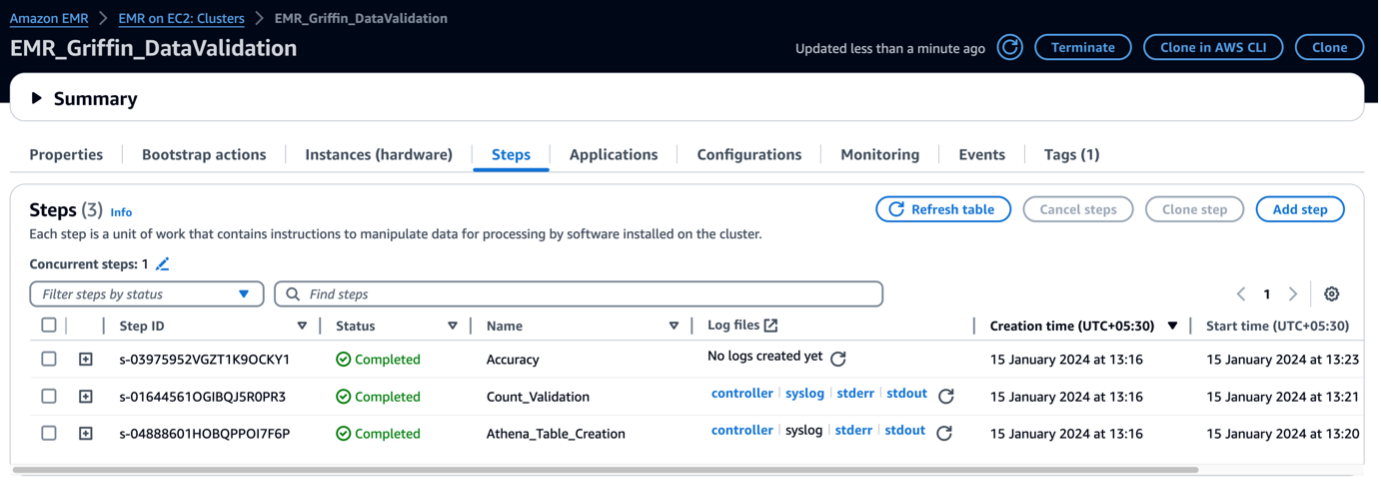
EMR ステップが完了すると、テーブルの比較が完了し、Athena で自動的に表示できるようになります。検証のために手動介入は必要ありません。
Python Griffin でデータを検証する
EMR クラスターの準備が整い、すべてのジョブが完了すると、カウントの検証とデータの検証が完了したことになります。結果は Amazon S3 に保存されており、その上に Athena テーブルがすでに作成されています。次のスクリーンショットに示すように、Athena テーブルにクエリを実行して結果を表示できます。
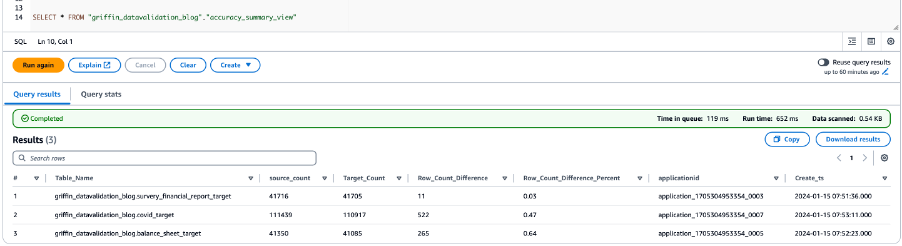
次のスクリーンショットは、すべてのテーブルのカウント結果を示しています。
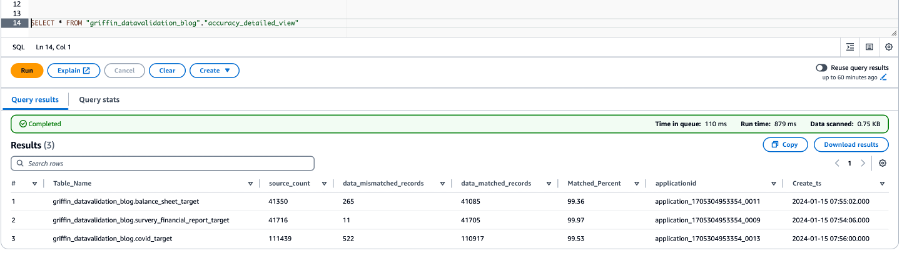
次のスクリーンショットは、すべてのテーブルのデータ精度の結果を示しています。
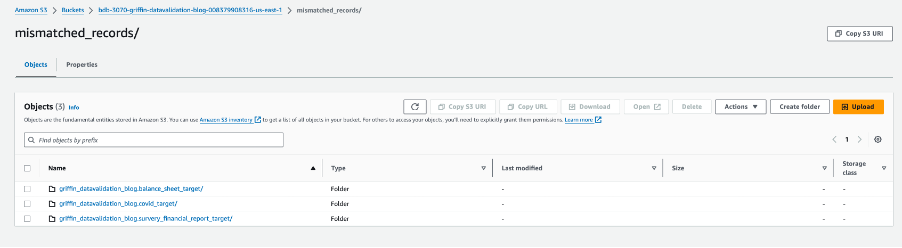
次のスクリーンショットは、レコードが一致しないテーブルごとに作成されたファイルを示しています。ジョブから直接テーブルごとに個別のフォルダーが生成されます。
すべてのテーブル フォルダーには、ジョブが実行される日ごとのディレクトリが含まれています。
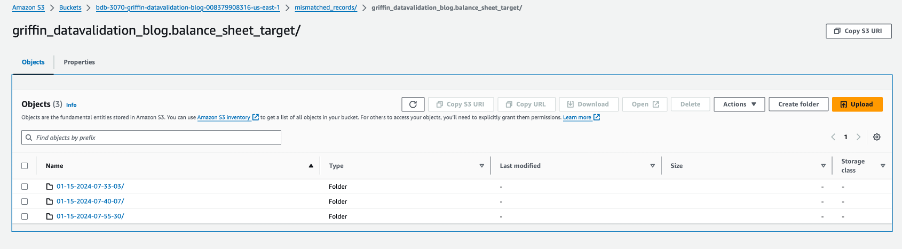
その特定の日付内に、という名前のファイルが __missRecords 一致しないレコードが含まれています。

次のスクリーンショットは、 __missRecords ファイルにソフトウェアを指定する必要があります。

クリーンアップ
追加料金が発生しないようにするには、ソリューションの終了後に次の手順を実行してリソースをクリーンアップします。
- AWS Glue データベースを削除する
griffin_datavalidation_blogそしてデータベースを削除しますgriffin_datavalidation_blogカスケード。 - 作成したプレフィックスとオブジェクトをバケットから削除します
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - CloudFormation スタックを削除すると、追加のリソースが削除されます。
まとめ
この投稿では、Python Griffin を使用して移行後のデータ検証プロセスを高速化する方法を説明しました。 Python Griffin は、コードを書かずにカウントと行および列レベルの検証を計算し、不一致のレコードを特定するのに役立ちます。
データ品質の使用例の詳細については、以下を参照してください。 AWS Glue データカタログから AWS Glue データ品質を開始する & AWS Glue データ品質.
著者について
 ディパル・マハジャン アマゾン ウェブ サービスの主任コンサルタントとして、安全性、拡張性、信頼性、コスト効率の高いクラウド アプリケーションの開発に関して世界中のクライアントに専門的な指導を提供しています。金融、通信、小売、ヘルスケアなどのさまざまなセクターにわたるソフトウェア開発、アーキテクチャ、分析における豊富な経験を持つ彼は、自身の役割に貴重な洞察をもたらします。プロの枠を超えて、ディパルは新しい目的地を探索することを楽しんでおり、希望リストにある 14 か国のうち 30 か国をすでに訪問しています。
ディパル・マハジャン アマゾン ウェブ サービスの主任コンサルタントとして、安全性、拡張性、信頼性、コスト効率の高いクラウド アプリケーションの開発に関して世界中のクライアントに専門的な指導を提供しています。金融、通信、小売、ヘルスケアなどのさまざまなセクターにわたるソフトウェア開発、アーキテクチャ、分析における豊富な経験を持つ彼は、自身の役割に貴重な洞察をもたらします。プロの枠を超えて、ディパルは新しい目的地を探索することを楽しんでおり、希望リストにある 14 か国のうち 30 か国をすでに訪問しています。
 Akhil は、AWS プロフェッショナル サービスの主任コンサルタントです。彼は、顧客によるスケーラブルなデータ分析ソリューションの設計と構築、およびデータ パイプラインとデータ ウェアハウスの AWS への移行を支援します。余暇には、旅行、ゲーム、映画鑑賞が大好きです。
Akhil は、AWS プロフェッショナル サービスの主任コンサルタントです。彼は、顧客によるスケーラブルなデータ分析ソリューションの設計と構築、およびデータ パイプラインとデータ ウェアハウスの AWS への移行を支援します。余暇には、旅行、ゲーム、映画鑑賞が大好きです。
 ラメシュ・ラグパシー AWS の WWCO ProServe のシニア データ アーキテクトです。 彼は AWS のお客様と協力して、AWS クラウド上のデータ ウェアハウスとデータ レイクの設計、デプロイ、移行を行っています。 仕事をしていないとき、Ramesh は旅行、家族との時間を過ごし、ヨガを楽しんでいます。
ラメシュ・ラグパシー AWS の WWCO ProServe のシニア データ アーキテクトです。 彼は AWS のお客様と協力して、AWS クラウド上のデータ ウェアハウスとデータ レイクの設計、デプロイ、移行を行っています。 仕事をしていないとき、Ramesh は旅行、家族との時間を過ごし、ヨガを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

