この投稿では、ビジネス ユーザーが日常のビジネス言語を使用してデータに関する質問と回答を行えるようにする方法について説明します。 アマゾンクイックサイト 自然言語クエリ関数、 アマゾン クイックサイト Q.
QuickSight は、最新の対話型ダッシュボード、自然言語クエリ、ページ分割されたレポート、機械学習 (ML) の洞察、大規模な組み込み分析を提供する統合 BI サービスです。 ML を活用した Q は、自然言語処理 (NLP) を使用して、ビジネス上の質問に迅速に答えます。 Q を使用すると、組織内のすべてのユーザーが自分の言語を使用して質問できるようになります。 Q は、ダッシュボードに使用するものと同じ QuickSight データセットを使用します。 レポート したがって、データは管理され、安全に保護されます。 データは、ダッシュボードやレポートを使用して視覚的に準備されるのと同じように、言語ベースの対話に備えて準備できます。 トピック. トピック ビジネス ユーザーが質問できる主題領域を表す XNUMX つ以上のデータセットのコレクションです。 の作成方法を学ぶには、 トピック、 参照する Amazon QuickSight Q トピックの作成.
QuickSight Q の自動データ準備により、モデルは多くのことを実行します。 トピック セットアップは自動的に行われますが、ビジネスに固有のコンテキストを提供する必要があります。 Q が舞台裏で行う初期セットアップ作業の詳細については、以下を確認してください。 新機能 – Amazon QuickSight Q の自動データ準備の発表.
ビジネス ユーザーは、QuickSight コンソールから、または Web サイトやアプリケーションに埋め込まれた Q にアクセスできます。 Q バーを埋め込む方法については、を参照してください。 登録ユーザー向けの Amazon QuickSight Q 検索バーの埋め込み or 匿名の (未登録) ユーザー。 Q を使用した埋め込みダッシュボードの例については、「 QuickSight デモセントラル.
ビジネス ユーザーとトピックを共有すると、GIF 1 に示すように、ユーザーは自分で質問したり、ピンボードに質問を保存したりできます。

QuickSight 作成者は、GIF 2 に見られるように、Q ビジュアルを分析に直接追加して、ダッシュボードの作成を高速化することもできます。

この投稿では、ダッシュボードまたはレポートでのビジュアル分析の構築に慣れていることを前提として、使いやすい自然言語インターフェイスを構築するために必要な新しいさまざまな戦略を共有します。
この投稿では、次のことについて説明します。
- 狭く焦点を絞ったユースケースから始めることの重要性
- 独自のビジネス言語をシステムに教える理由と方法
- サポートを提供し、フィードバック ループを確立して成功を収める方法
Q をまだ有効にしていない場合は、以下を参照してください。 Amazon QuickSight Q の使用開始 または以下をご覧ください ビデオ.
フォローしてください
次の例では、すぐに使える XNUMX つのサンプル トピックをよく参照します。 Product Sales & Student Enrollment Statistics, 進みながら進めることができます。 準備が整うまでに数分かかるため、この投稿を続ける前に今すぐトピックを作成することをお勧めします。
ユーザーを理解する
ソリューションに入る前に、自然言語クエリ (NLQ) 機能がどのような場合にユースケースに適しているかについて話しましょう。 NLQ は、ビジネス分野の専門家であるビジネス ユーザーが、範囲を絞ったデータ ドメインからのさまざまな質問に柔軟に回答するための迅速な方法です。 NLQ はダッシュボードの必要性を置き換えるものではありません。 代わりに、NLQ は、ダッシュボードまたはレポートのユースケースを拡張するように設計されている場合、ビジネス ユーザーがビジネス アナリストに助けを求めずに、特定の詳細についてカスタマイズされた回答を得るのに役立ちます。
言語は本質的に複雑であるため、ユースケースをよく理解することが重要です。 同じ概念を参照する方法はたくさんあります。 たとえば、大学では「クラス」を「コース」、「プログラム」、「入学」など、さまざまな方法で呼ぶ場合があります。 言語には固有のあいまいさもあり、「トップの学生」とは、ある人にとっては最も高い GPA を意味し、別の人にとっては最も多くの課外授業を行っていることを意味する場合があります。 ユースケースを事前に理解することで、潜在的に曖昧な領域を明らかにし、その知識をトピックに直接組み込むことができます。
例えば、 AWS Analytics のセールスリーダーチームは QuickSight と Q を使用しています 月次ビジネスレビューの一環として、地域の主要な指標を追跡します。 営業リーダーと仕事をしていたとき、私はユーザビリティ セッションを通じて彼らが好む用語やビジネス言語を学びました。 私が観察したことの XNUMX つは、それらがデータ フィールドを参照しているということでした。 Sales Amortized Revenue 「adrr」として。 これらの学習により、同義語を使用してこのコンテキストをトピックに簡単に追加できるようになりました。これについては、以下で詳しく説明します。 営業リーダーの XNUMX 人は、「来月 MBR を書くときにこれは素晴らしいことになるでしょう。 以前は数時間かかっていた作業が、今では数分でできるようになりました。 今では、顧客に成果をもたらすために、より多くの時間を費やすことができます。」 営業リーダーが「adrr」について質問したが、その関連性が Q トピックに含まれていなかった場合、リーダーは誤解されていると感じ、元の、しかし遅い答えを見つける方法に戻ってしまうでしょう。 QuickSight のその他の使用例と成功事例を次のサイトで確認してください。 AWS ビッグデータ ブログ.
小さく始める
このセクションでは、Q を開始する際の一般的な課題と考慮事項をいくつか共有します。
データには重複する単語が含まれる場合があります
注意すべき落とし穴の XNUMX つは、アンケートの書き込み回答や製品の説明など、長い文字列を含むフィールドです。 このタイプのデータでは、読者がナビゲートする際に語彙がさらに複雑になります。 言い換えれば、エンドユーザーが質問するとき、文字列の XNUMX つの単語が他の関連フィールドと重複する可能性が高くなります。たとえば、質問文に製品名が記載されているアンケートの書き込みなどです。 Product 分野。 他の非記述子フィールドにも重複が含まれる場合があります。 字句が重複する XNUMX つ以上のフィールド名、および値間、さらにはフィールドと値の間でも同じフィールド名を持つことができます。 たとえば、次のようなトピックがあるとします。 Product Order Status 値を持つフィールド Open & Closed フォルダーとその下に Customer Complaint Status フィールドにも値が含まれています Open & Closed。 この重複を避けるには、潜在的な曖昧さを避けるために、エンドユーザーにとって自然な代替名を検討してください。 この例では、 Product Order Status 値を変更し、 Customer Complaint Status 〜へ Resolved & Unresolved.
フィールドや値に集計名を含めないでください。
不必要なあいまいさをもたらすもう 1 つの一般的な落とし穴は、Q がオンザフライで実行できる基本的な集計に計算フィールドを含めることです。 たとえば、ビジネス ユーザーは、Web サイトの平均クリック率や、無料から有料への月初からのコンバージョンを追跡する場合があります。 ダッシュボードではこれらのタイプの計算が必要ですが、Q ではこれらの計算フィールドは必要ありません。 Q は、図 XNUMX に示すように、単純に「前年比売上高」、「売上高上位顧客」、または「製品の平均割引率」を尋ねるなど、自然言語を使用して指標を集計できます。YoY Sales という名前のフィールドを定義すると、追加の項目が追加されます。トピックに対する潜在的な回答の選択肢をエンド ユーザーに提供し、事前定義された YoY Sales フィールドを使用するか、Q の組み込みの YoY 集計機能を使用するかを選択します。一方、これらの選択肢のどれが最良の結果をもたらす可能性が高いかはすでにわかっているかもしれません。 計算フィールドに複雑なビジネス ロジックが組み込まれている場合でも、それらは含めることに関連しています (また、既存の分析からトピックを作成した場合は、Q によってそれらのロジックが引き継がれます)。
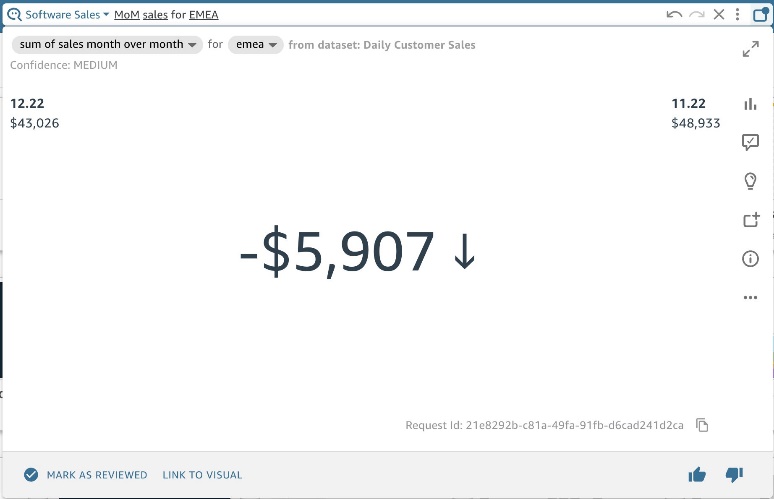
図 1: EMEA の前月比売上高を示す Q ビジュアル
単一のユースケースから始める
この投稿では、実際のビジネス ユーザーが尋ねる明確に定義された一連の質問としてユース ケースを定義することをお勧めします。 Q は、ダッシュボードやレポートでまだ回答されていない質問に回答する機能を提供するため、ダッシュボードまたはデータセットがあるだけでは、必ずしも Q 対応のユースケースがあるとは限りません。 これらの質問は、「顧客のパフォーマンスはどうですか?」など、ビジネス ユーザーが使用する実際の単語やフレーズです。 ここで、「パフォーマンス」という単語はデータ内で「売上償却収益」にマッピングされる可能性がありますが、ビジネス ユーザーは正確なデータ名を使用して質問しない可能性があります。
単一のユースケースと、それを満たす最小限のフィールド数から始めます。 その後、必要に応じてさらに追加していきます。 ユーザーが自信を持てるように、10 フィールドで 100% の成功率から始めるよりも、たとえば 30 フィールドで期待通りの質問への回答成功率が 70% であるトピックを導入する方が良いでしょう。
小規模から始めるのに役立つように、Q を使用すると、既存の分析からワンクリックでトピックを作成できます (図 2)。

図 2: QuickSight 分析からの Q トピックの有効化
Q は、分析の基礎となるメタデータをスキャンし、分析での使用方法に基づいて価値の高い列を自動的に選択します。 また、既存の計算フィールドはすべて新しいトピックに移植されるため、再作成する必要はありません。
語彙コンテキストを追加する
Qさんは英語が上手です。 同じ単語のさまざまなフレーズやさまざまな形式を理解します。 知らないのはあなたのビジネス特有の用語であり、それを教えることができるのはあなただけです。
Q にこのコンテキストを提供するには、同義語、セマンティック タイプ、デフォルトの集計、主な日付、名前付きフィルター、名前付きエンティティの追加など、いくつかの重要な方法があります。 前のセクションで説明したように Q トピックを作成した場合は、数歩進んでいることになりますが、モデルの動作を常に確認することをお勧めします。
同義語を追加する
ダッシュボードでは、作成者は視覚的なタイトル、テキスト ボックス、フィルター名を使用して、ビジネス ユーザーがナビゲートして答えを見つけられるようにします。 NLQ では、言語がインターフェースになります。 NLQ を使用すると、ビジネス ユーザーは自分の言葉で質問できるようになります。 作成者は、同義語を使用して Q のビジネス用語との接続を作成する必要があります。 ビジネス ユーザーは、収益を「総売上高」、「償却収益」、またはビジネスに特有のさまざまな用語で呼ぶ場合があります。 トピック作成ページから、関連する用語を追加できます (図 3)。

図 3: 関連する同義語の追加
ビジネス ユーザーが複数の方法でデータ値を参照する場合、値の同義語を使用して Q に対するそれらの接続を作成できます (図 4)。 たとえば、 Student Enrollment トピックとして、ビジネス ユーザーが時々使用するとします。 First Years マッピングする Freshmen など、分類タイプごとに異なります。 データセットにそのデータが直接存在しない場合は、値の同義語を使用してマッピングを作成できます (図 5)。
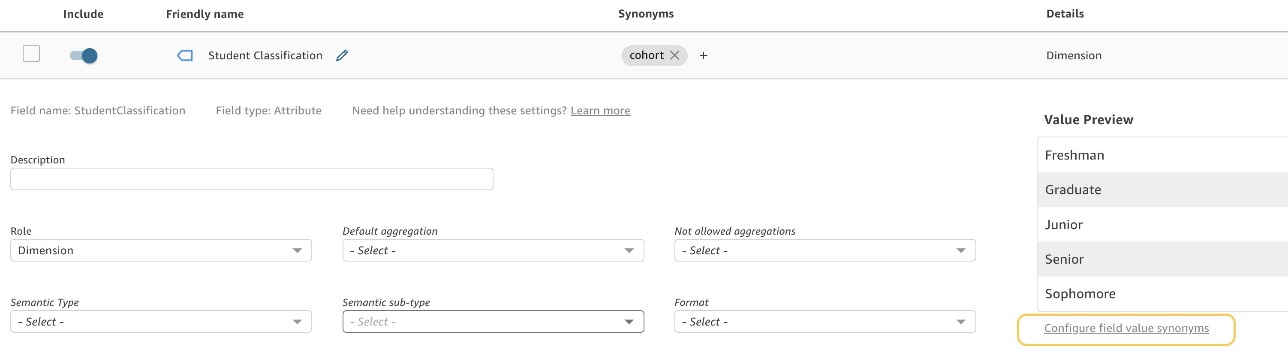
図 4: フィールド値の同義語の構成
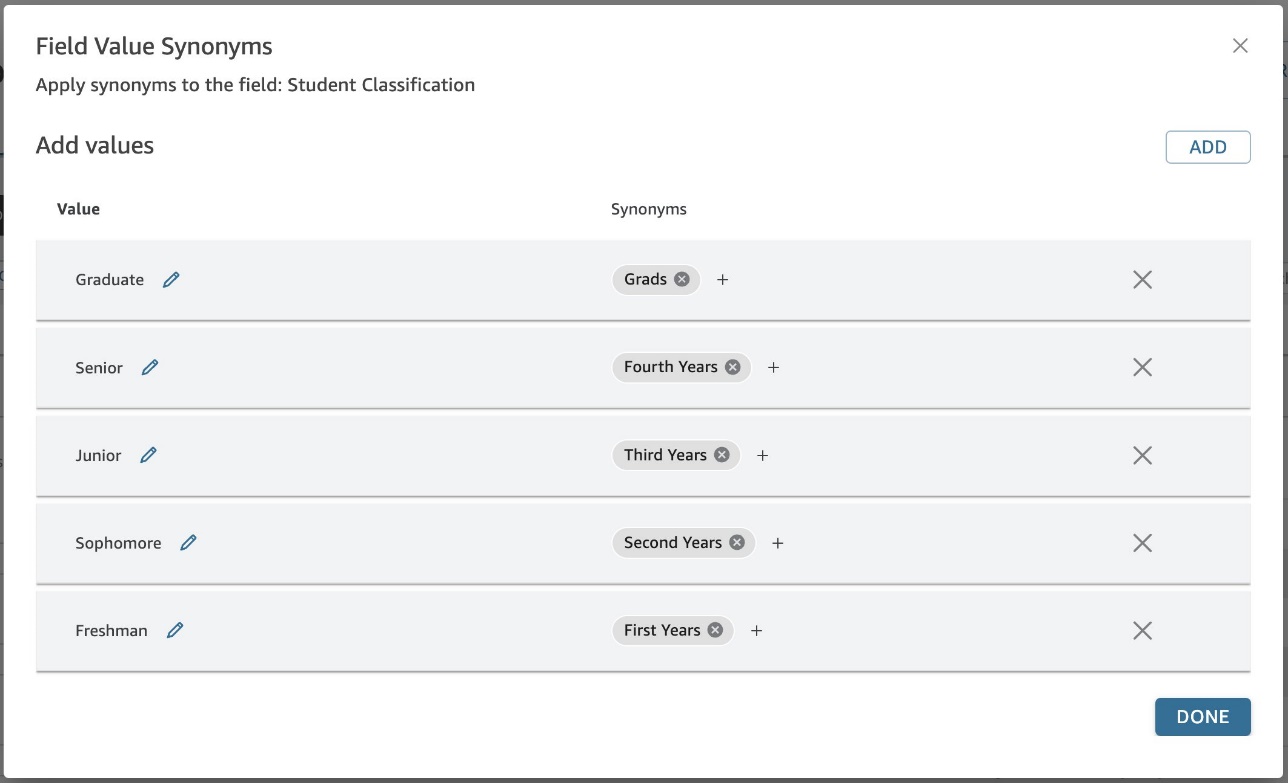
図 5: Student Enrollment トピックの値の同義語の例
セマンティックタイプをチェックする
自動データ準備を使用してトピックを作成すると、Q は検出できる関連するセマンティック タイプを自動的に選択します。 Q はセマンティック タイプを使用して、誰が、どこで、いつ、いくつのような漠然とした質問に答えるためにどの特定のフィールドを使用すればよいかを理解します。 たとえば、学生登録統計の例では、Q はすでに設定されています。 Home of Origin as Location したがって、誰かが「どこ」と尋ねた場合、Q はこのフィールドを使用することがわかります (図 6)。 別の例としては、 Person Student Name & Professor フィールドを使用することで、ビジネス ユーザーが「誰」を尋ねたときにどのフィールドを使用するかを Q が認識できるようになります。
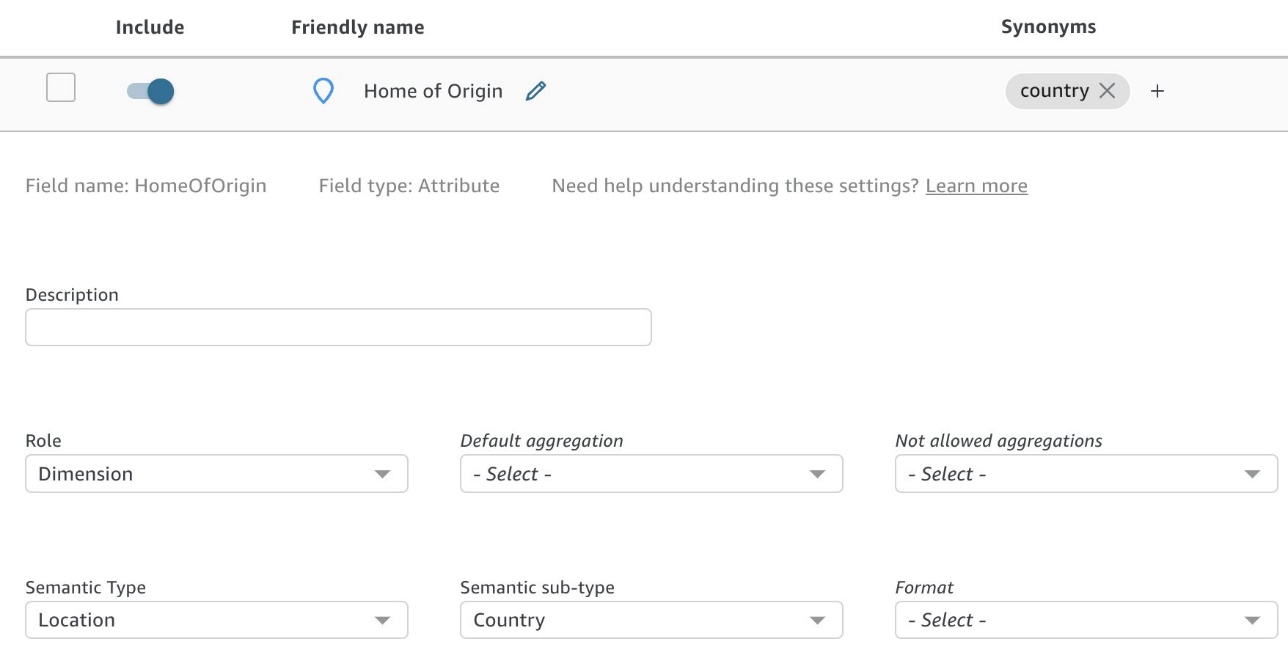
図 6: セマンティック タイプを「場所」に設定
もう XNUMX つの重要なセマンティック タイプは、 Identifier。 これにより、ビジネス ユーザーが「2021 年に生物学に登録したのは何人ですか?」などの質問をしたときに、何を数えるべきかが Q にわかります。 (図7)。 この例では学生IDを設定しています。 Identifier.
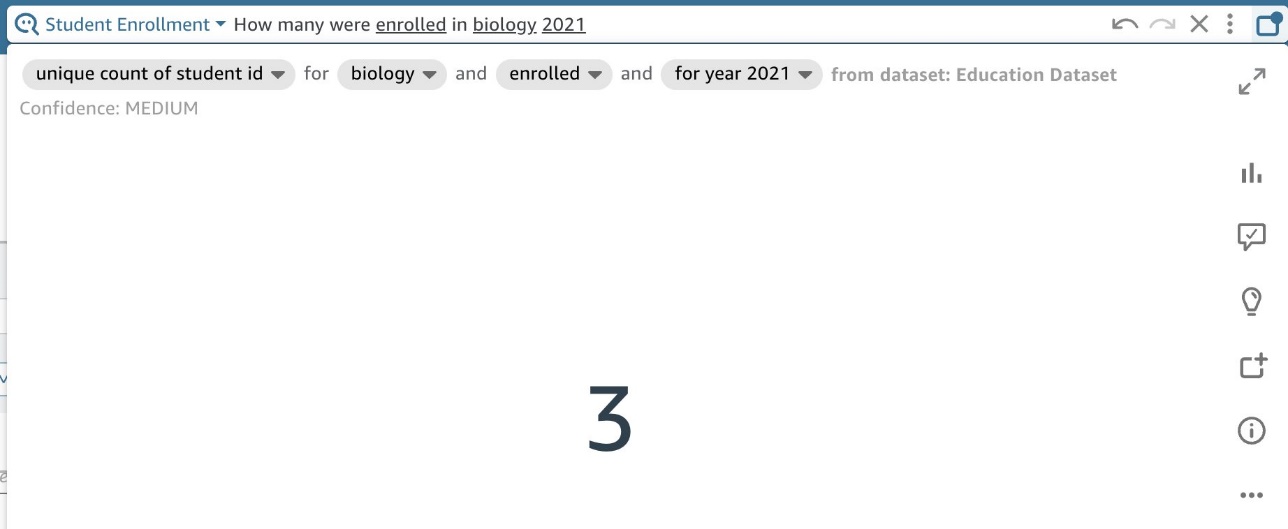
図 7: 「いくつ」の質問を示す Q ビジュアル
以下は、暗黙的な質問フレーズにマップされるセマンティック タイプのリストです。
Location: どこ?PersonorOrganization: 誰?- 個人または組織のフィールドがない場合、Q は識別子を使用します。
Identifier: 幾つか? 数は何ですか?Duration: どのぐらいの間?Date Part: いつ?Age: 何歳?Distance: どこまで?
セマンティック タイプは、「最も高価な」または「最も安い」などの用語をマッピングするなど、他のいくつかの方法でもモデルに役立ちます。 Currency。 関連するセマンティック タイプが常に存在するとは限らないため、それらを空のままにしても問題ありません。
デフォルトの集計を設定する
Q はビジネス ユーザーが要求するメジャー値を常に集計するため、他の値と組み合わせたときに意味を保持するメジャーを使用することが重要です。 この記事の執筆時点では、Q は、通貨値やカウントなどの合計的な基礎となるデータを使用する場合に最適に機能します。 合計ではないメトリクスの例としては、パーセンテージ、パーセンタイル、中央値などがあります。 このタイプの測定値は、相互に加算すると、誤解を招く結果や統計的に不正確な結果を生成する可能性があります。 Q を使用すると、エンドユーザーは基になるデータで最初に計算を実行することなく、平均、パーセンタイル、中央値を生成できます。
デフォルトの集計を設定することで、Q がデータの背後にあるビジネス ロジックを理解できるようにします。 たとえば、 Student Enrollment このトピックでは、すべてのコースの生徒のテストのスコアを取得します。これはパーセンテージであるため、合計ではなく平均する必要があります。 したがって、私たちは、 Average デフォルトとして設定されている Sum 許可されていない集計タイプとして使用されます (図 8)。
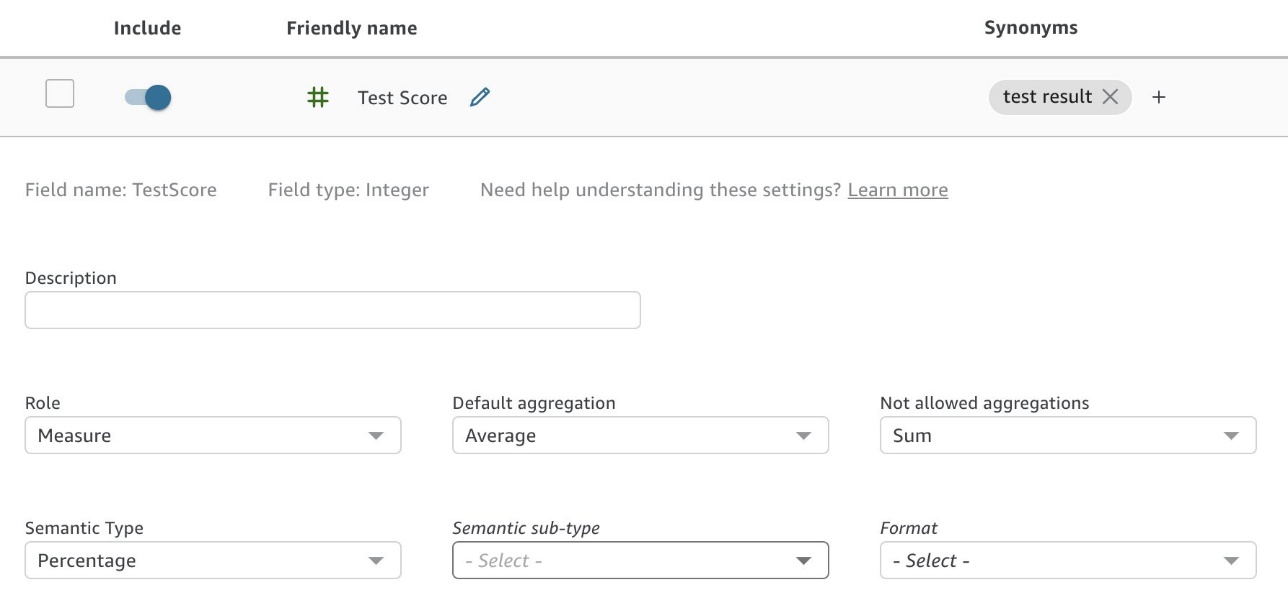
図 8: パーセンテージ データ フィールドの「合計」を「許可されていない集計」として設定する
エンドユーザーが正しいカウントを取得できるようにするには、各次元フィールドのデフォルトの集計タイプを次のようにする必要があるかどうかを検討してください。 Distinct Count or Count それに応じて設定します。 たとえば、「提供しているコースの数」を尋ねたい場合は、次のように設定します。 Courses 〜へ Distinct Count 基礎となるデータには、登録した各学生を追跡するための同じコースの複数のレコードが含まれているためです。
カウントがある場合、6,000 を超えるコースが得られます。これは、 Courses データセット内のすべての生徒をカバーするフィールドです (図 9)。
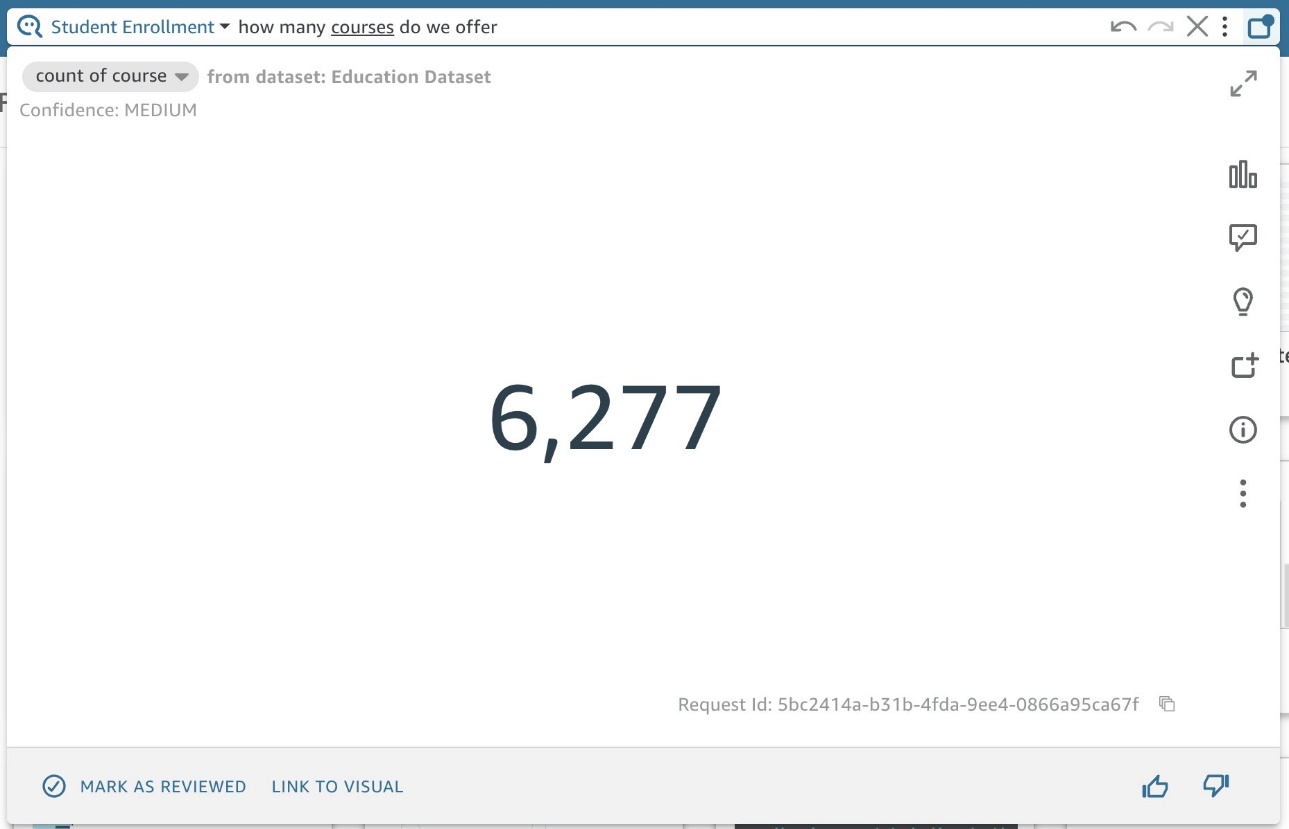
図 9: コースの数を示す Q ビジュアル
デフォルトの集計を次のように設定すると、 Distinct Count、一意のコース名の数を取得します。これは、エンドユーザーが期待するものである可能性が高くなります (図 10)。
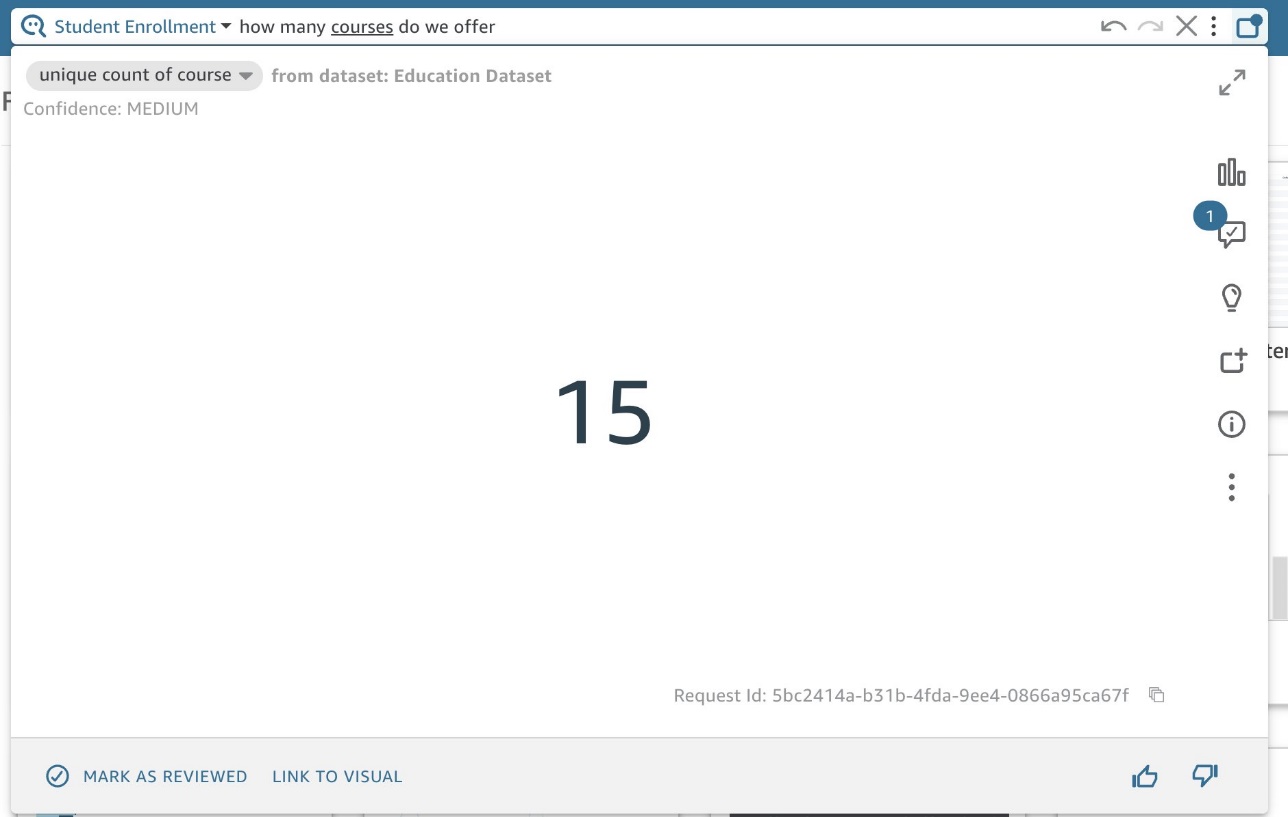
図 10: コースの一意の数を示す Q ビジュアル
主要な日付フィールドを確認する
Q は、「いつ」や「前年」などの時間関連の質問に回答するための主要な日付フィールドを自動的に選択します。 データに複数の日付フィールドが含まれている場合は、Q のデフォルトの選択とは異なる日付を選択することができます。 エンドユーザーは、追加の日付フィールドに明示的に名前を付けることで、追加の日付フィールドについて問い合わせることもできます (図 12)。 必要に応じていつでも別の日付を指定できます。 主要な日付を確認または変更するには、トピック ページに移動し、 且つ セクションを選択して、 データセット タブ。 データセットを展開して、次の値を確認します。 デフォルトの日付 (図11)。
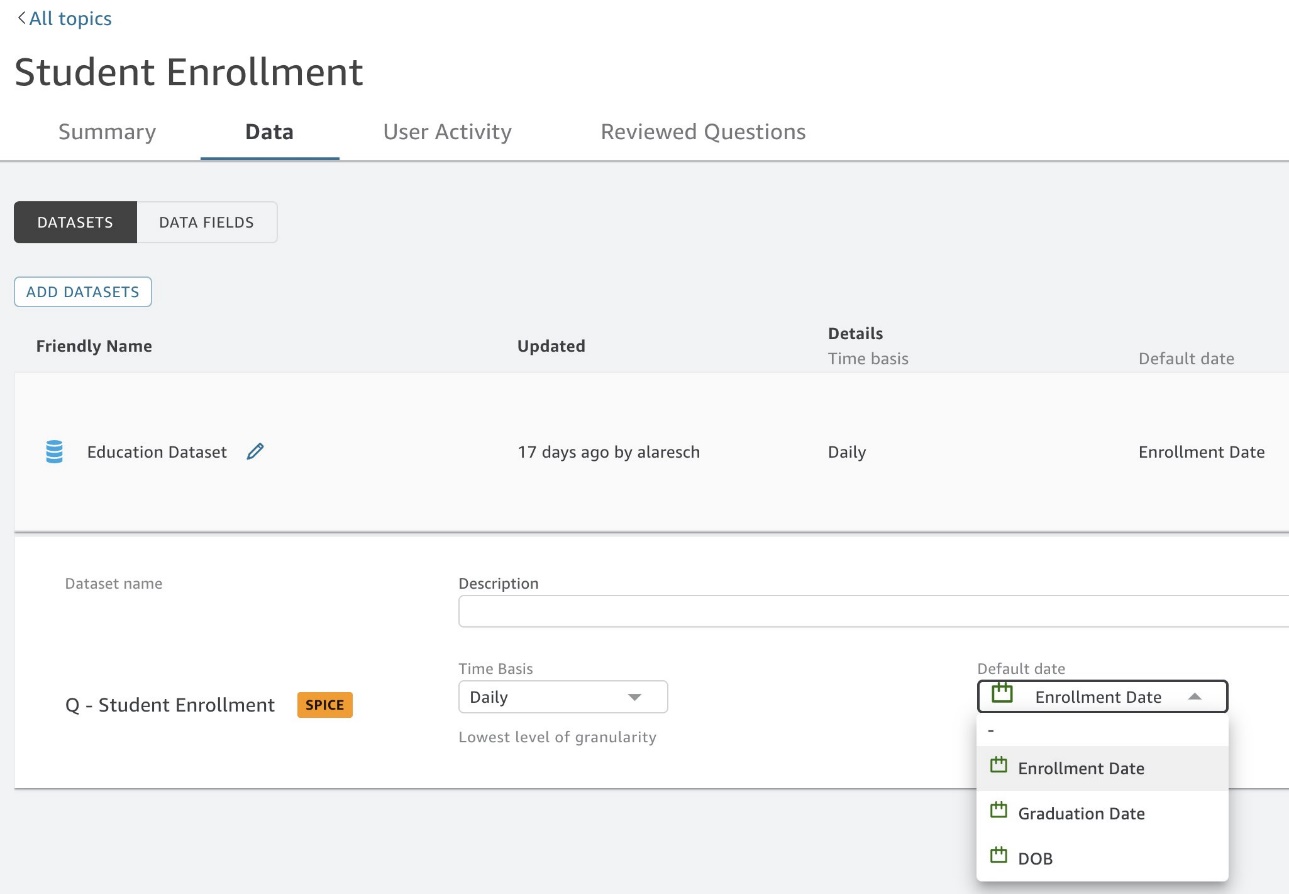
図 11: デフォルトの日付の確認
必要に応じて日付を変更できます。
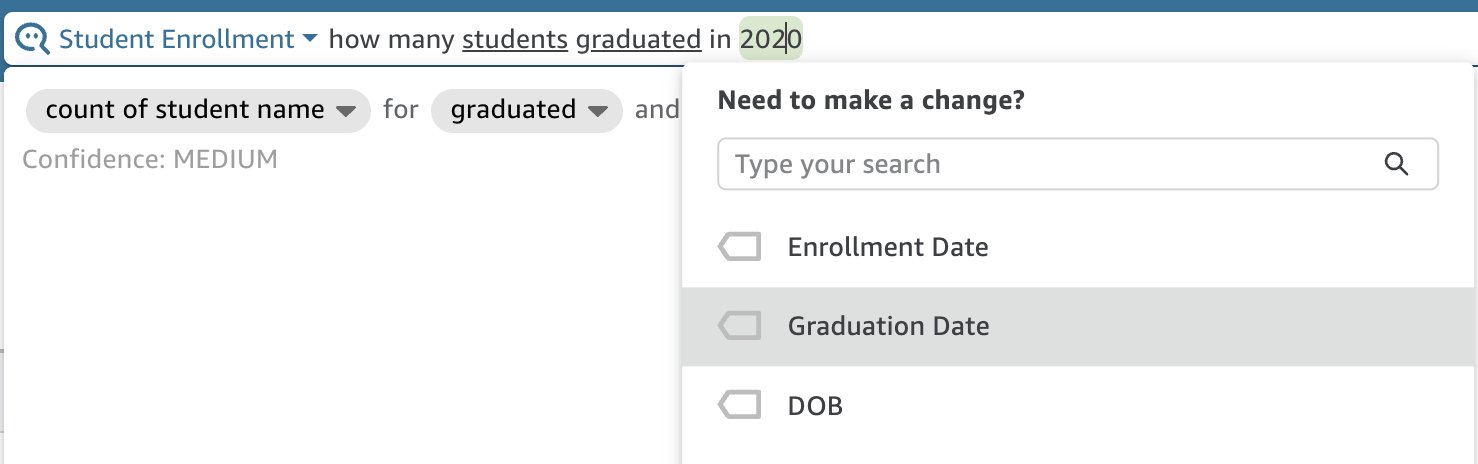
図 12: デフォルト以外の日付について尋ねる
名前付きフィルターを追加する
ダッシュボードでは、ユーザーが関心のある領域に集中できるようにするためにフィルターが重要です。 Q では、ユーザーは Q トピックに含まれるフィールド値を自動的にフィルターするように要求できるため、従来のフィルターは必要ありません。 たとえば、「Acme Inc. のリピーターに対する先週の売上はいくらでしたか?」と尋ねることができます。 ダッシュボードでフィルター (日付、顧客名、リピート顧客と新規顧客) を構築する代わりに、Q はその場でフィルター処理を実行して、即座に答えを提供します。
Q、a filter ビジネス ユーザーが Q に返された結果をフィルターするように指示するために使用する特定の単語またはフレーズです。 たとえば、学生のテストのスコアはあるが、ユーザーが不合格のテストのスコアについて質問できる方法が必要だとします。 テストスコアが 70% 未満であると定義される「不合格」のフィルターを設定できます (図 13)。
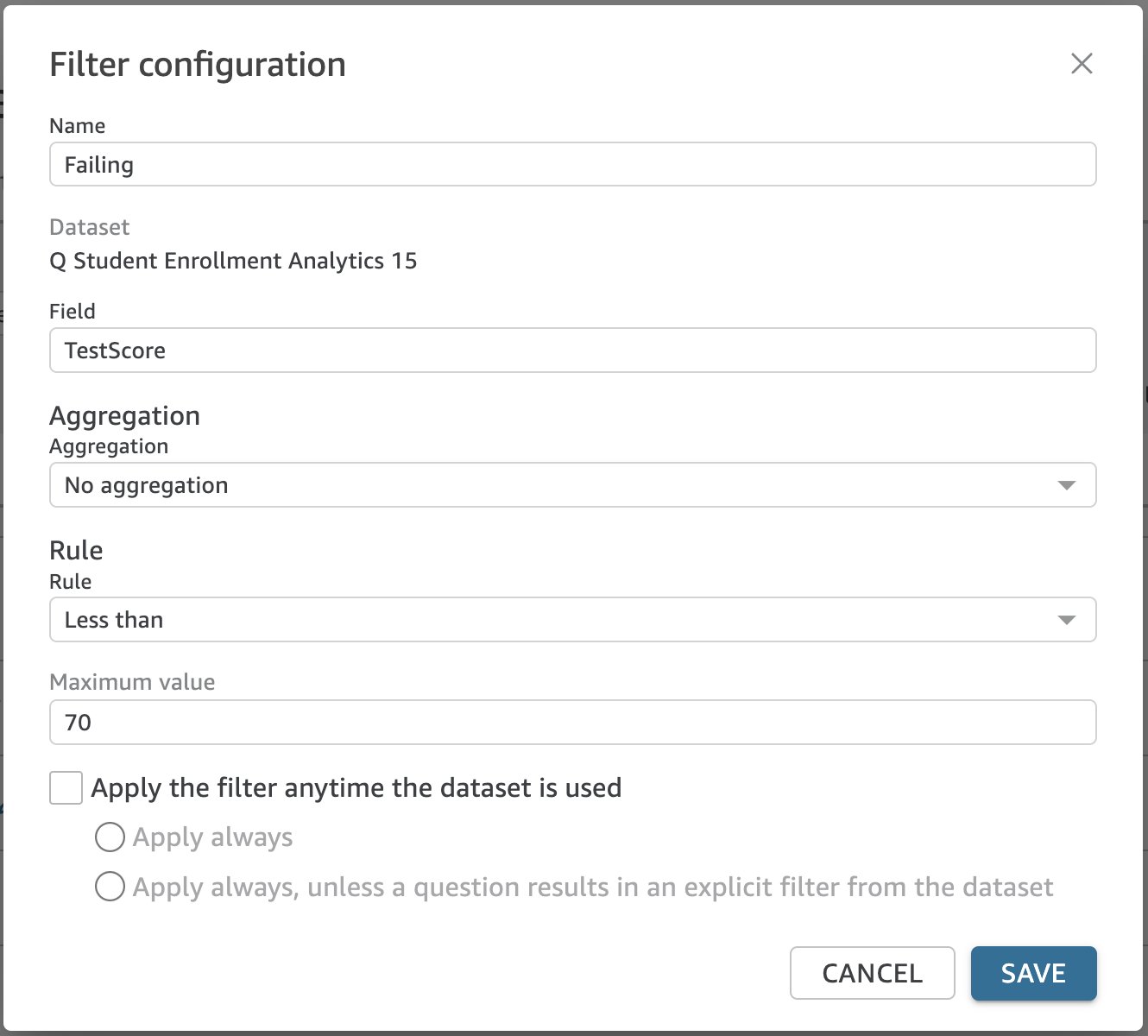
図 13: メジャーを使用したフィルター構成例
さらに、おそらく次のフィールドがあります Student Classification、含まれ Freshmen, Sophomore, Junior, Senior, Graduateそして、ユーザーに「学部生」と「卒業生」について質問させたいとします (図 14)。 関連する値を含むフィルターを作成できます。
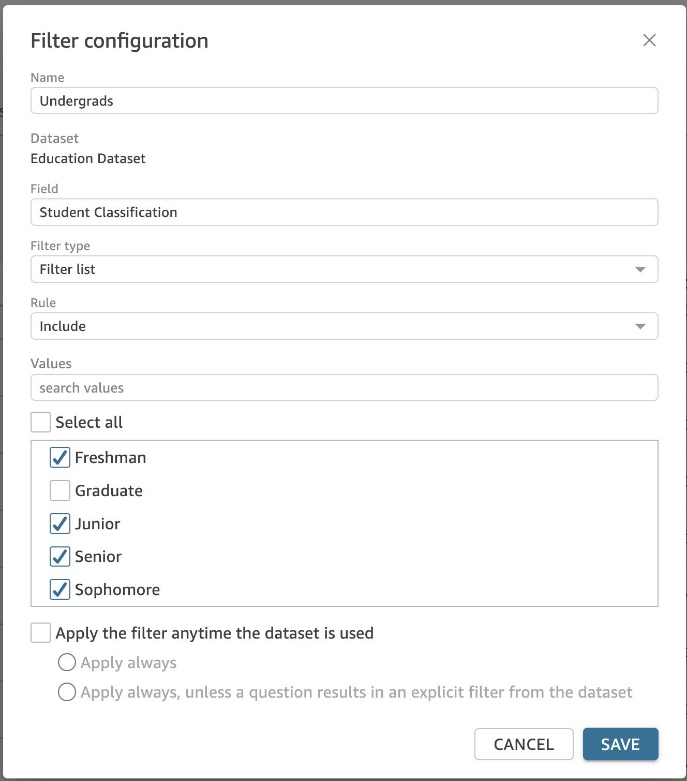
図 14: ディメンションを使用したフィルター構成例
名前付きエンティティを追加する
名前付きエンティティは、ユーザーが特定の単語または語句を要求したときに Q にフィールドのセットをテーブル ビジュアルとして返すようにする方法です。 誰かが「6,169 月の小売売上高」を知りたいと思ったときに、追加のコンテキストなしで $15 という KPI を取得した場合、この数字に含まれるすべてのデータを理解するのは困難です (図 XNUMX)。
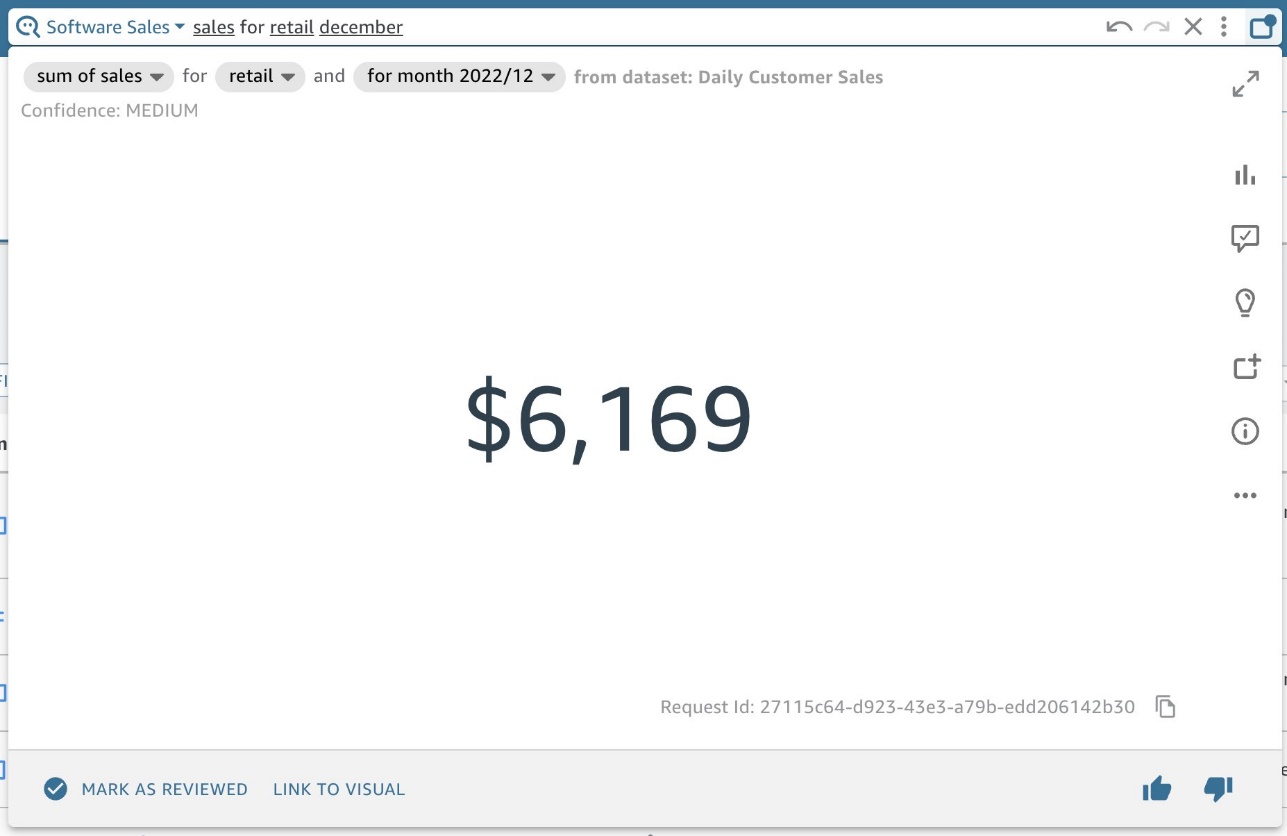
図 15: 「XNUMX 月の小売売上高」を示す AQ ビジュアル
KPI を他の関連ディメンションとともにテーブル ビューで表示することで、データに追加のコンテキストが含まれ、意味を理解しやすくなります (図 16)。
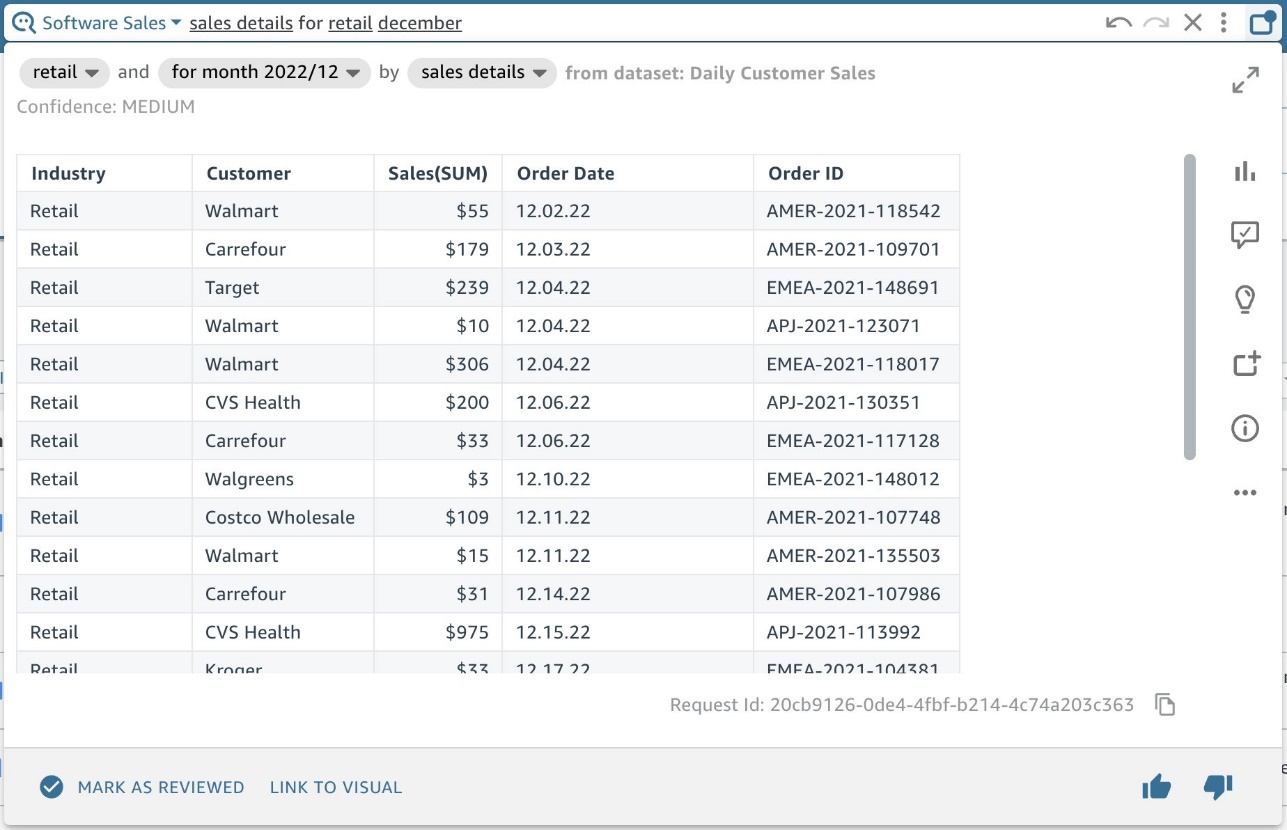
図 16: 「XNUMX 月の小売の売上詳細」を示す AQ ビジュアル
これらのテーブル ビューを構築すると、各データを明示的に要求しなくても、ビジネス ユーザーが見たい情報を予測して喜んで驚かせることができます。 最も優れた点は、ビジネス ユーザーが言語を使用してテーブルを簡単にフィルタリングして、独自のデータに関する質問に答えることができることです。 たとえば、 Student Enrollment トピックを作成しました Student information 名前、専攻、電子メール、コースごとのテストのスコアなどの重要な学生の詳細を含む名前付きエンティティ。
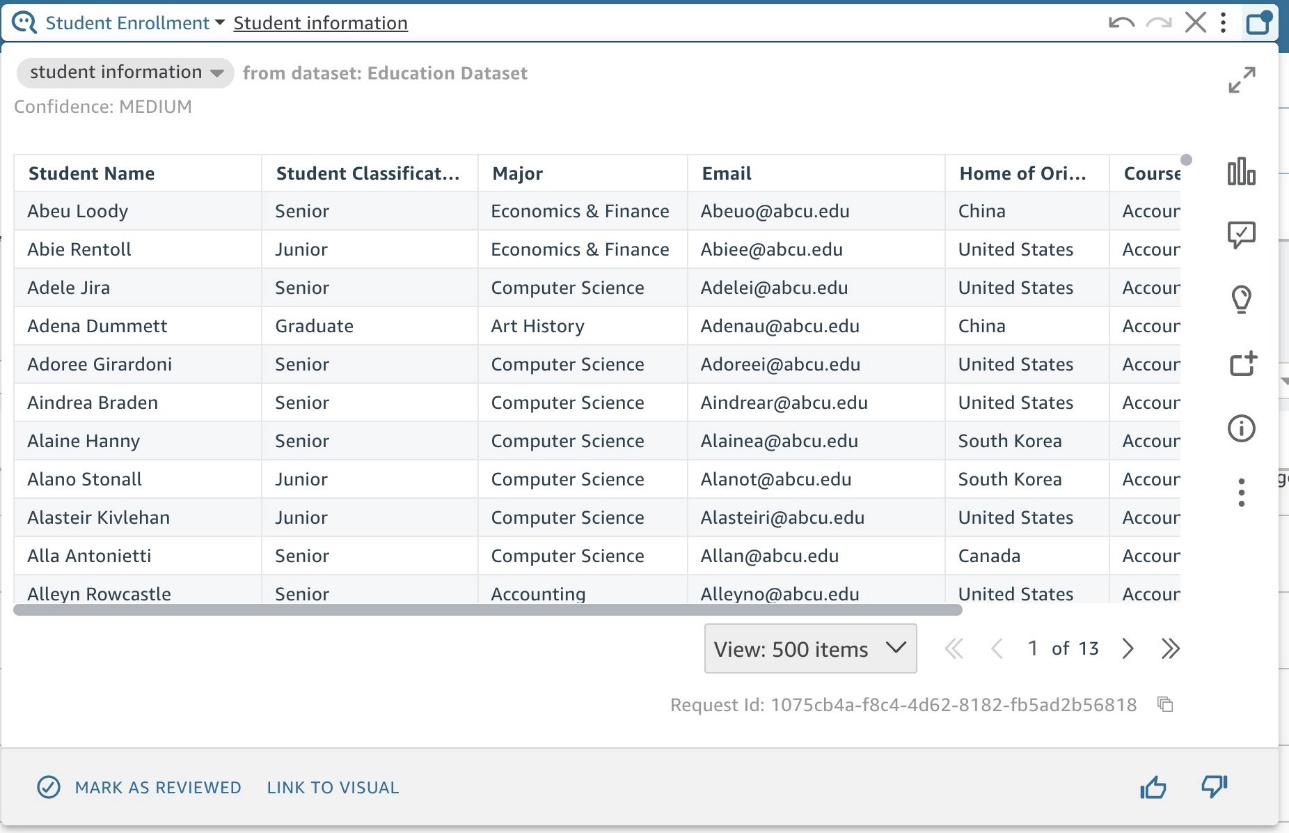
図 17: 名前付きエンティティの例
大学管理者が生物学で不合格になっている学生に連絡を取りたい場合は、「生物学専攻で不合格になっている学生の情報」を尋ねるだけで済みます。 18 つのステップで、電子メールとテストのスコアがすでに含まれているフィルタリングされたリストを取得して、連絡を取ることができます (図 XNUMX)。
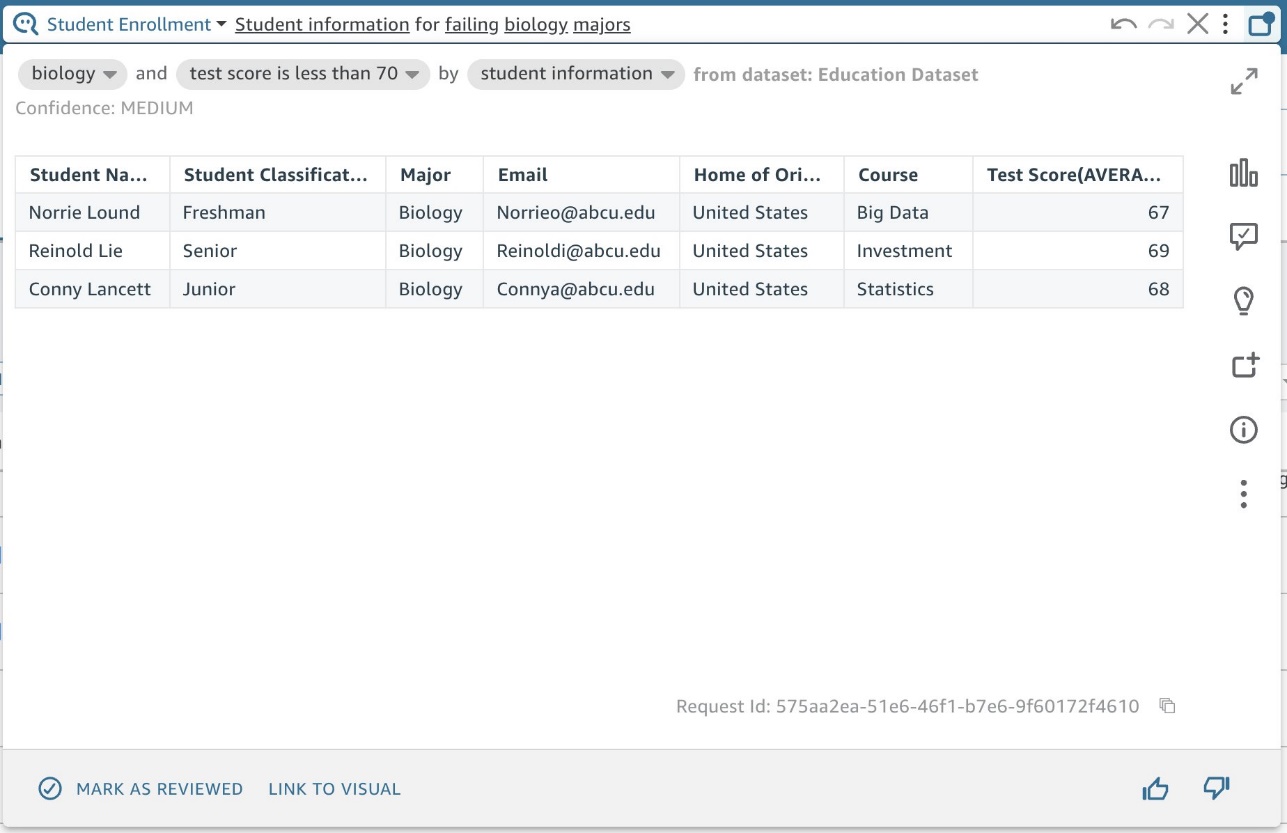
図 18: 名前付きエンティティのフィルタリング
大学の管理者が、無料の個別指導を提供するテキストを送信するために学生の電話番号も確認したい場合は、「電話番号のある生物学専攻の不合格者の学生情報」を Q に尋ねるだけで済みます。 今、 Mobile が最初の列として追加されます (図 19)。
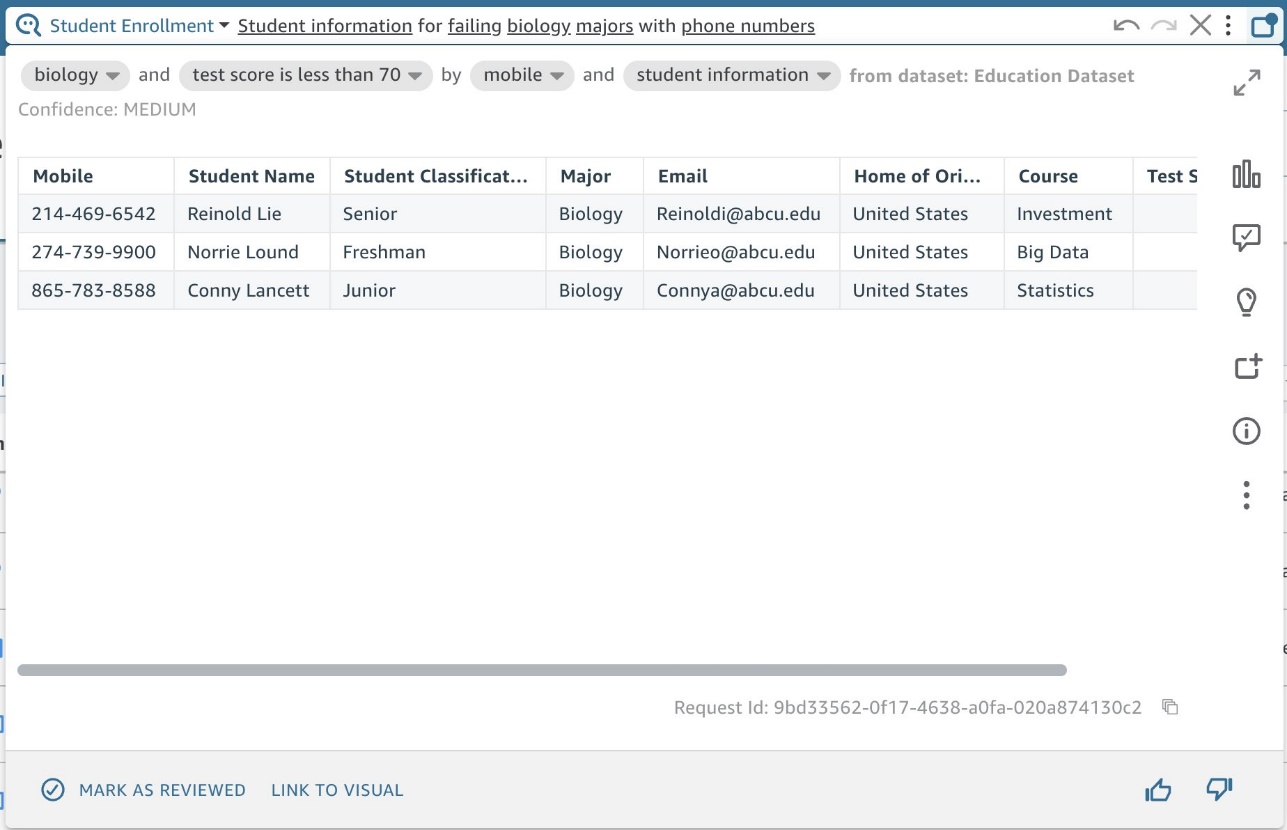
図 19: 名前付きエンティティへの列の追加
ビジネス ユーザーがこのデータ グループを参照するあらゆる方法を把握するために、同義語を使用してエンティティを参照することもできます。 この例では、大学管理者が使用する一般的な用語に基づいて、「学生の連絡先情報」と「学術の詳細」を追加することもできます。
データ フィールドのパターンを探すだけでなく、ビジネス ユーザーが何を気にしているのかを自問してください。 たとえば、人事スペシャリストのデータがあり、彼らが求人情報、候補者、採用担当者を気にかけていることがわかっているとします。 各著者はグループについて少しずつ異なる考え方をするかもしれませんが、それが実行すべきビジネス業務に根ざしている限り、グループ化は価値を提供します。 これら XNUMX つのグループを念頭に置いて、すべてのデータをこれらのバケットの XNUMX つに分類できます。 このユースケースでは、 Candidate バケットはかなり大きく、約 20 フィールドがあります。 リストをスキャンすると、拒否された候補者と承認された候補者の情報が追跡されていることがわかります。そのため、指標を XNUMX つのグループに分割し始めます。 Successful Candidates & Rejected Candidates。 今では次のような情報が Offer Letter Date, Accept Date, Final Salary すべてにあります Successful Candidate グループ、および R に関する関連分野ejected Candidates 明確にグループ化されています。
エンティティの作成方法についての戦略に興味がある場合は、カードの並べ替えテクニックを確認してください。
Product Sales サンプル トピックでは、データをスキャンした後、次のことから始めます。 Sales, Product, Customer 分析する情報を XNUMX つの主要なグループに分類します。 自分のデータで演習を試してみて、質問があればお気軽に質問してください。 QuickSightコミュニティ。 名前付きエンティティの作成方法については、「」を参照してください。 名前付きエンティティをトピック データセットに追加する.
NLQ の導入を促進する
トピックを洗練し、一部の読者でテストし、より多くの読者が利用できるようにしたら、採用を促進する XNUMX つの戦略に従うことが重要です。
まず、ビジネス ユーザーにサポートを提供します。 サポートは、短いチュートリアル ビデオやニュースレターのお知らせのように見えるかもしれません。 アクティブなユーザーが質問や機能強化を投稿できる、Slack や Teams チャットなどのオープン チャネルを維持することを検討してください。
ここ Amazon では、Prime チームには、PrimeQ と呼ばれる組み込み Q アプリケーションの専任のプロダクト マネージャー (PM) がいます。 PM は定期的にデモとトレーニング セッションを主催し、Prime チームはそこで質問をし、どのような種類の回答が得られるかについてアイデアを得ることができます。 また、PM は毎月のニュースレターを送信して、新しいデータやトピックの利用可能性、サンプル質問、FAQ、Q から価値を得る Prime チーム メンバーからの引用をお知らせします。また、PM にはアクティブな Slack チャネルもあり、あらゆる質問が寄せられます。 PM または Prime チームのデータ エンジニアが 24 時間以内に回答します。
プロのヒント: ビジネス ユーザーが、行き詰まった場合に誰に連絡できるかを確認してください。 「著者に連絡する」というブラックボックスを避けて、読者が自分の質問に既知の人が答えてくれると確信できるようにします。 組み込みアプリケーションの場合は、サポートを受ける簡単な方法を構築してください。
次に、健全なフィードバック ループを維持します。 製品で使用状況データを直接確認し、読者との 1 対 1 セッションをスケジュールします。 使用状況データを使用して導入を追跡し、答えられない質問をしている読者を特定します (図 20)。 成功している読者と苦労している読者の両方に参加して、エクスペリエンスを反復して改善し続ける方法を学びましょう。 ビジネス ユーザーと話すことは、言語の暗黙のあいまいさを明らかにするために特に重要です。
ここ Amazon での別の例では、最初にサービスを開始した後、 Revenue Insights AWS Analytics セールスチーム、QuickSight ソリューションアーキテクト (SA)、そして私自身が毎日使用状況タブをチェックして、答えられない質問を追跡し、セールスチームのメンバーに直接連絡して、質問を調整する方法や、彼らの質問が機能するように変更を加えました。 たとえば、最初はフィールドをオフにしていました。 Market Segment そして、営業リーダーからセグメント別の売上についての質問があることに気づきました。 私たちはフィールドをオンにして、これらの質問が今後機能することを彼に伝えました。 SA と私は他の関係者と Slack チャネルを持っているため、非同期で簡単にトラブルシューティングを行うことができます。 このトピックが公開されてから数か月が経過したため、毎週「使用状況」タブをチェックしています。
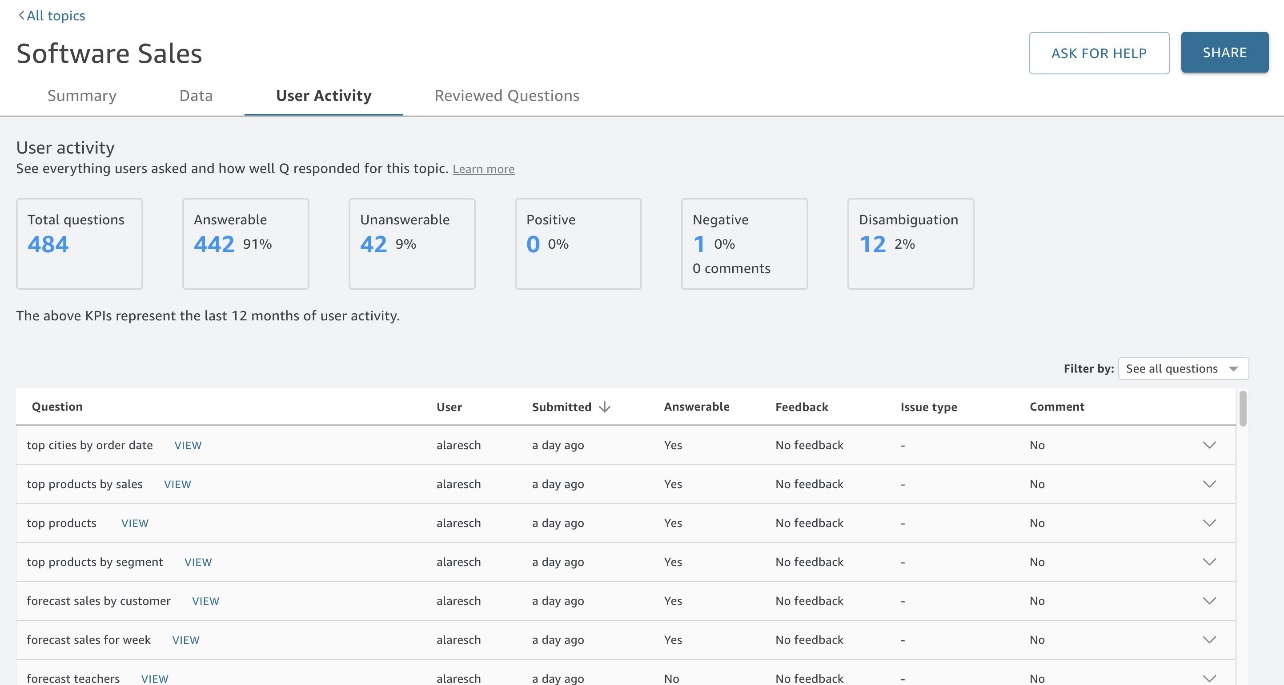
図 20: Q の [ユーザー アクティビティ] タブ
まとめ
この投稿では、言語が本質的にどのように複雑であるか、そして独自のビジネス言語についてシステムに教えるために Q を提供する必要があるコンテキストについて説明しました。 Q の自動データ準備を使用して開始できますが、ビジネス ユーザーの言語に固有のコンテキストを追加する必要があります。 投稿の冒頭で述べたように、次の点を考慮してください。
- 狭く焦点を絞ったユースケースから始める
- 独自のビジネス言語をシステムに教え込む
- サポートを提供し、フィードバック ループを確立することで成功を収める
この投稿に従って、ビジネス ユーザーが QuickSight で自然言語を使用してデータの質問に回答できるようにします。
Q を始める準備はできましたか? 私たちを見てください クイックチュートリアル QuickSight Q を有効にする場合。
チームと共有するチュートリアル ビデオが必要ですか? 以下を確認してください。
Q がデータ変更の背後にある「なぜ」にどのように答え、将来の業績を予測できるかを確認するには、以下を参照してください。 Amazon QuickSight Q で使用できる新しい分析の質問: 「なぜ」と「予測」.
著者について
 エイミー・ラレッシュ 彼女は、Amazon QuickSight Q の製品マネージャーです。彼女は分析に情熱を持っており、すべての QuickSight Q 読者に最高のエクスペリエンスを提供することに重点を置いています。 @AmazonQuickSight YouTube チャンネルで彼女のビデオをチェックして、ベスト プラクティスと QuickSight Q の新機能を確認してください。
エイミー・ラレッシュ 彼女は、Amazon QuickSight Q の製品マネージャーです。彼女は分析に情熱を持っており、すべての QuickSight Q 読者に最高のエクスペリエンスを提供することに重点を置いています。 @AmazonQuickSight YouTube チャンネルで彼女のビデオをチェックして、ベスト プラクティスと QuickSight Q の新機能を確認してください。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/best-practices-for-enabling-business-users-to-answer-questions-about-data-using-natural-language-in-amazon-quicksight/

