2023 年 3 月: この投稿はレビューされ、プロビジョニングされた RAXNUMX クラスターのマルチ AZ デプロイメントの一般提供に合わせて更新されました。
初版発行日は 9 年 2022 月 XNUMX 日です。
Amazonレッドシフト は、標準 SQL を使用して大規模なデータセットを分析できる、フルマネージドのペタバイト規模のクラウド データ ウェアハウスです。 データ ウェアハウスのワークロードは、最高レベルの復元力と可用性を必要とするミッションクリティカルな分析アプリケーションで使用されることが増えています。 Amazon Redshift は、予期せぬ停止に対処し、ダウンタイムを最小限に抑えるための多くの回復機能をサポートするクラウドベースのデータ ウェアハウスです。 Amazon Redshift RA3 インスタンス タイプは、データを Redshift Managed Storage (RMS) に保存します。 Amazon シンプル ストレージ サービス (Amazon S3) デフォルトで可用性と耐久性が高くなります。 Amazon Redshift は、データ ウェアハウスを回復し、障害を自動的に修復し、 移転する アプリケーションを変更することなく、クラスターを異なる AZ に配置できます。 多くの顧客はこれらの機能の恩恵を受けていますが、エンタープライズ データ ウェアハウスの顧客は、アプリケーションへの影響を最小限に抑えながらビジネスの継続性をサポートするために、低い RTO (目標復旧時間) と高い可用性を必要としています。
Amazon Redshift は、3 つのアベイラビリティーゾーンでのデータウェアハウスの同時実行をサポートし、予期しない障害シナリオでも運用を継続できる、プロビジョニングされた RAXNUMX クラスターのマルチ AZ デプロイメントの一般提供を発表しました。 マルチ AZ 展開は、最高レベルの復元力と可用性を必要とするミッションクリティカルな分析アプリケーションを使用する顧客を対象としています。
Redshift マルチ AZ デプロイメントでは、XNUMX つの AZ のコンピューティング リソースを活用して、データ ウェアハウスのワークロード処理を拡張します。 高レベルまたは同時実行性が存在する状況では、Redshift は両方の AZ のリソースを自動的に活用して、読み取りリクエストと書き込みリクエストの両方のワークロードをスケールします。
リリース前のテストでは、Amazon Redshift マルチ AZ のデプロイメントにより、まれに AZ 障害が発生した場合でも、復旧時間が 60 秒以下に短縮されることがわかりました。
シングル AZ 配置とマルチ AZ 配置の比較
Amazon Redshift では、VPC にクラスターを作成するためにクラスター サブネット グループが必要です。 クラスターサブネットグループには、VPC ID に関する情報と VPC 内のサブネットのリストが含まれています。 クラスターを起動すると、Amazon Redshift はデフォルトのクラスターサブネットグループを自動的に作成するか、選択したクラスターサブネットグループを選択して、Amazon Redshift が VPC のいずれかのサブネットでクラスターをプロビジョニングできるようにします。 クラスターサブネットグループを設定して、Amazon Redshift がクラスターのデプロイに使用するさまざまなアベイラビリティーゾーンからサブネットを追加できます。
今日のすべての Amazon Redshift クラスターは、AWS リージョン内の特定のアベイラビリティーゾーンに作成および配置されているため、シングル AZ 配置と呼ばれています。 シングル AZ 配置の場合、Amazon Redshift はリージョン内のアベイラビリティーゾーンの XNUMX つからサブネットを選択し、そこにクラスターを配置します。 デプロイするアベイラビリティーゾーンを選択できます。Amazon Redshift は、提供されたサブネットに基づいて、選択したアベイラビリティーゾーンにクラスターをデプロイします。
一方、マルチ AZ デプロイメントは XNUMX つのアベイラビリティーゾーンで同時にプロビジョニングされます。 マルチ AZ デプロイメントの場合、Amazon Redshift は XNUMX つの異なるアベイラビリティーゾーンから XNUMX つのサブネットを自動的に選択し、各アベイラビリティーゾーンに同じ数のコンピューティングノードをデプロイします。 両方のアベイラビリティーゾーンの計算ノードがワークロード処理に使用されるため、これらすべての計算ノードは単一のエンドポイントを介して利用されます。
次の図に示すように、Amazon Redshift は、シングル AZ デプロイメントの場合は XNUMX つのアベイラビリティーゾーンにクラスターをデプロイし、マルチ AZ デプロイメントの場合は XNUMX つのアベイラビリティーゾーンにクラスターをデプロイします。
 |
 |
マルチ AZ 配置の自動復旧
万一アベイラビリティーゾーンに障害が発生した場合でも、Amazon Redshift マルチ AZ 配置は、他のアベイラビリティーゾーンのリソースを自動的に使用してワークロードを提供し続けます。 マルチ AZ 配置は XNUMX つのエンドポイントを持つ単一のデータ ウェアハウスとしてアクセスされるため、予期しない停止時にビジネスの継続性を維持するためにアプリケーションを変更する必要はありません。 Amazon Redshift のマルチ AZ 配置は、データが失われないように設計されており、障害が発生するまでコミットされたすべてのデータをクエリできます。
下の図に示すように、AZ1 の計算ノードに障害が発生する可能性が低いイベントが発生した場合、マルチ AZ 配置は自動的に回復して AZ2 の計算リソースを使用します。 また、Amazon Redshift は、別のアベイラビリティ ゾーン (AZ3) に同一のコンピューティング ノードを自動的にプロビジョニングし、2 つのアベイラビリティ ゾーン (AZ3 と AZXNUMX) で同時に動作し続けます。
 |
 |
Amazon Redshift マルチ AZ デプロイメントは、アベイラビリティーゾーン障害の可能性に対する保護のために使用されるだけでなく、ワークロード処理を XNUMX つのアベイラビリティーゾーンに自動的に分散することで、データウェアハウスのパフォーマンスを最大化することもできます。 マルチ AZ デプロイメントでは、常に XNUMX つのアベイラビリティーゾーンのコンピューティングリソースのみを使用して個々のクエリを処理しますが、複数の同時クエリの処理を両方のアベイラビリティーゾーンに自動的に分散して、同時実行性の高いワークロードの全体的なパフォーマンスを向上させることができます。
抽出、変換、ロード (ETL) プロセスとダッシュボードで自動再試行を設定し、プライマリ アベイラビリティ ゾーンで予期せぬ障害が発生した場合に、セカンダリ アベイラビリティ ゾーンのクラスターによってプロセスが再発行され、処理されるようにすることをお勧めします。 接続が切断された場合は、すぐに再試行または再確立できます。 さらに、障害が発生したアベイラビリティーゾーンで実行されていたクエリとロードは中止されます。 障害発生時または障害発生後に発行された新しいクエリでは、マルチ AZ データ ウェアハウスが XNUMX AZ 設定に回復されている間、実行遅延が発生する可能性があります。
ソリューションの概要
この投稿では、Amazon Redshift のマルチ AZ デプロイメントを作成および管理する方法のチュートリアルを提供します AWSマネジメントコンソール。 また、Amazon Redshift Multi-AZ データ ウェアハウスの耐障害性もテストし、Multi-AZ デプロイメントでのクエリを監視します。
コンソールから新しいマルチ AZ 配置を作成する
Amazon Redshift コンソールを通じて、新しいマルチ AZ デプロイメントを簡単に作成できます。 Amazon Redshift は、マルチ AZ デプロイメントの 3 つのアベイラビリティーゾーンのそれぞれに同じ数のノードをデプロイします。 マルチ AZ デプロイメントのすべてのノードは、通常の運用中に読み取りおよび書き込みワークロード処理を実行できます。 マルチ AZ 展開は、プロビジョニングされた RAXNUMX クラスターでのみサポートされます。
次の手順に従って、XNUMX つのアベイラビリティーゾーンに Amazon Redshift プロビジョニングされたクラスターを作成します。
- Amazon Redshift コンソールのナビゲーションペインで、 クラスター.
- 「クラスターの作成」をクリックします。
クラスターの作成に関する一般的な情報については、次を参照してください。 クラスターの作成.
- の RA3 ノード タイプの XNUMX つを選択します。 ノードタイプ ドロップダウンメニュー。 マルチ AZ 配置オプションは、RA3 ノード タイプを選択した場合にのみ使用可能になります。
- マルチ AZ 配置選択 マルチ AZ オプション.
- AZ あたりのノード数で、クラスターに必要なノードの数を入力します。


- 下 データベース構成、選択する 管理者ユーザー名 & 管理者ユーザーのパスワード.
- ターン デフォルトを使用 隣に 追加の構成 デフォルト設定を変更します。
- ネットワークとセキュリティ、次のように指定します。
- 仮想プライベート クラウド (VPC)で、クラスターをデプロイする VPC を選択します。
- VPC セキュリティ グループ、デフォルトのままにするか、選択したセキュリティ グループを追加します。
- クラスタ サブネット グループ、 デフォルトのままにするか、選択したクラスター サブネット グループを追加します。 マルチ AZ 配置の場合、クラスターサブネットグループには、少なくとも XNUMX つ以上の異なるアベイラビリティーゾーンからそれぞれ XNUMX つのサブネットを含める必要があります。
クラスタ サブネット グループの管理に関する一般的な情報については、次を参照してください。 クラスタ サブネット グループ

- データベース構成、用 データベースポート、デフォルト値の 5439 を使用するか、5431 ~ 5455 および 8191 ~ 8215 の範囲から値を選択します。
- データベース構成、で データベースの暗号化 セクション、カスタムを使用する AWSキー管理サービス デフォルトの KMS キー以外の (AWS KMS) キーを選択します。 暗号化設定をカスタマイズする. このオプションは、デフォルトでは選択されていません。
- AWS KMS キーを選択する、既存の KMS キーを選択するか、 AWS KMS キーを作成する 新しい KMS キーを作成します。
KMS を使用してキーを作成する方法の詳細については、次を参照してください。 キーの作成.

- 選択する クラスターを作成する.
クラスターの作成が成功すると、クラスターの詳細ページで詳細を確認できます。
一般的な情報、あなたは見ることができます マルチAZ as 有り.

ソフトウェア設定ページで、下図のように プロパティ タブ、下 ネットワークとセキュリティの設定で、プライマリ アベイラビリティ ゾーンとセカンダリ アベイラビリティ ゾーンの詳細を確認できます。

CLI から新しいマルチ AZ デプロイメントを作成する
次の create-cluster AWS CLI コマンドは、マルチ AZ クラスターを作成する方法を示しています。
シングル AZ 配置をマルチ AZ 配置に変換する
既存のシングル AZ デプロイメントをマルチ AZ デプロイメントに変換するには、Redshift コンソールに移動し、現在シングル AZ セットアップになっている Redshift クラスターを選択し、「アクション」に移動して選択します。 マルチ AZ のアクティブ化。 マルチ AZ への変換を成功させるには、シングル AZ クラスターを暗号化する必要があります。 マルチ AZ への変換中、Redshift はノードの総数を XNUMX 倍にし、各 AZ に均等に分散します。 Redshift では、一貫したクエリ パフォーマンスを維持するためにマルチ AZ に変換する際に、既存のノード数を分割することはできません。
スナップショットから復元されたマルチ AZ 配置を作成するには、次の手順を実行します。
- Amazon Redshift コンソールのナビゲーションペインで、 クラスター.
- クラスターを選択し、クラスターの詳細ページに移動します。
- ソフトウェア設定ページで、下図のように メニュー、選択 マルチ AZ をアクティブ化します。

- 変更の概要を確認し、選択して確認します。 マルチ AZ のアクティブ化.

以下の AWS CLI コマンドを使用して、単一の AZ Redshift データ ウェアハウスをマルチ AZ に変換できます。
マルチ AZ 展開をシングル AZ 展開に変換する
Redshift は、マルチ AZ デプロイメントからシングル AZ への変換もサポートしています。 このオプションを使用すると、お客様は次のような簡単な手順でさまざまな導入を柔軟に切り替えることができます。
- Amazon Redshift コンソールのナビゲーションペインで、 クラスター.
- クラスターを選択し、クラスターの詳細ページに移動します。
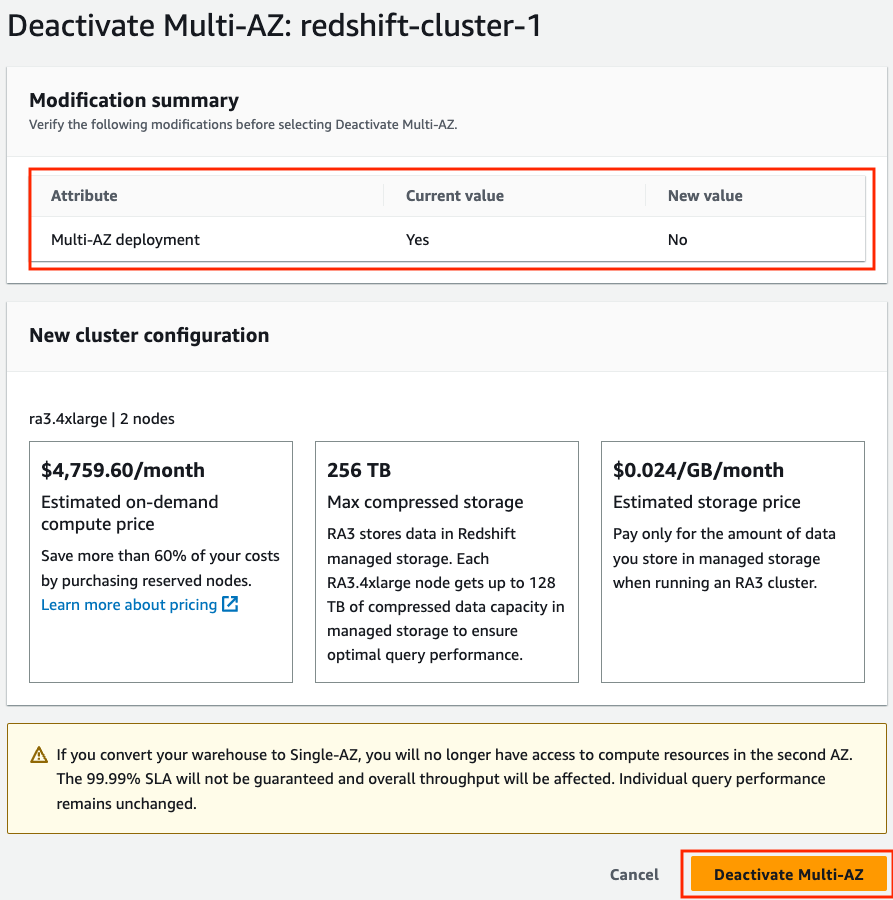
- ソフトウェア設定ページで、下図のように メニュー、選択 マルチ AZ を非アクティブ化します。
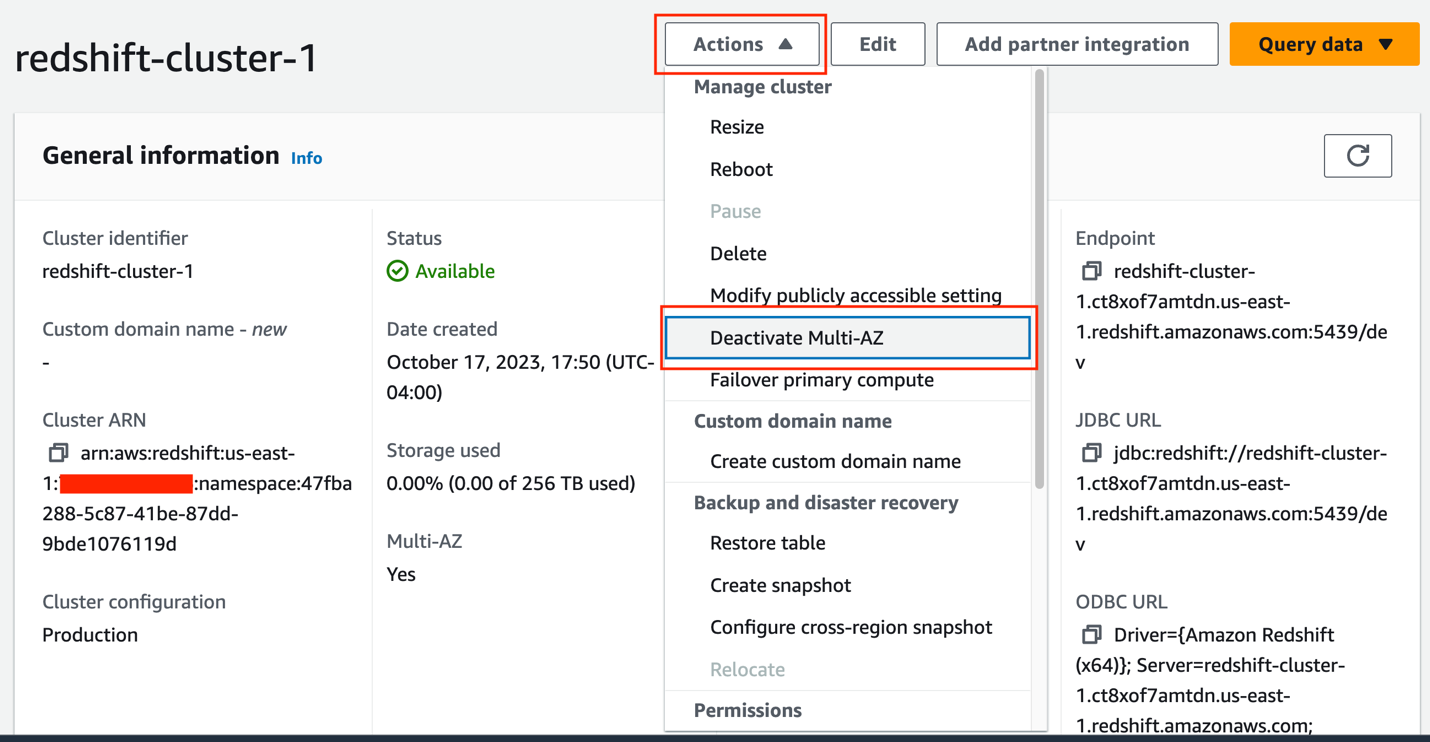
- 変更の概要を確認し、選択して確認します。 マルチ AZ を非アクティブ化する.
スナップショットから復元されたマルチ AZ データ ウェアハウスの作成
既存のお客様は、既存のシングル AZ 展開からスナップショットを復元することでマルチ AZ 展開を作成することもできます。 以下の必要な手順を参照してください。
- Amazon Redshift コンソールのナビゲーションペインで、 クラスター.
- クラスターを選択し、クラスターの詳細ページに移動します。
- 選択する メンテナンス
- スナップショットを選択し、 スナップショットの復元, プロビジョニングされたクラスターに復元する.
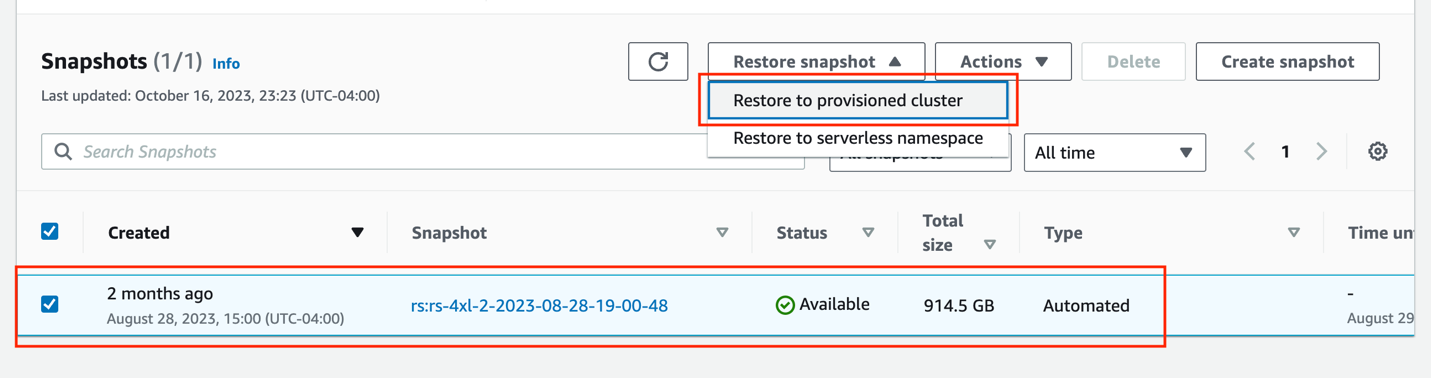
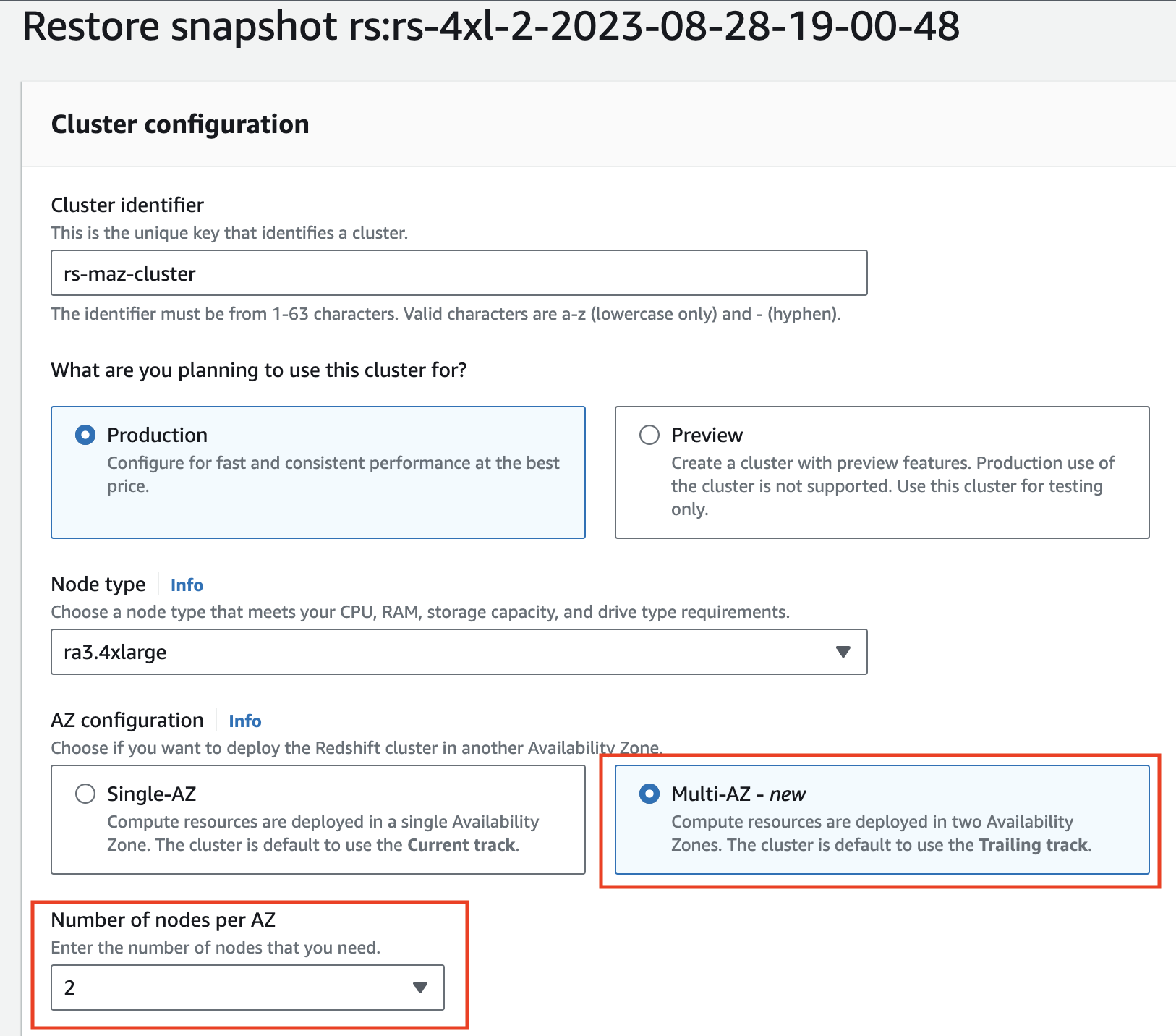
- 確認 クラスタ構成 & クラスタの詳細 スナップショット情報を使用して作成される新しいクラスターの値。
- マルチ AZ オプションを選択し、新しいクラスターのプロパティを更新してから、 スナップショットからクラスターを復元する ページの下部にあります。
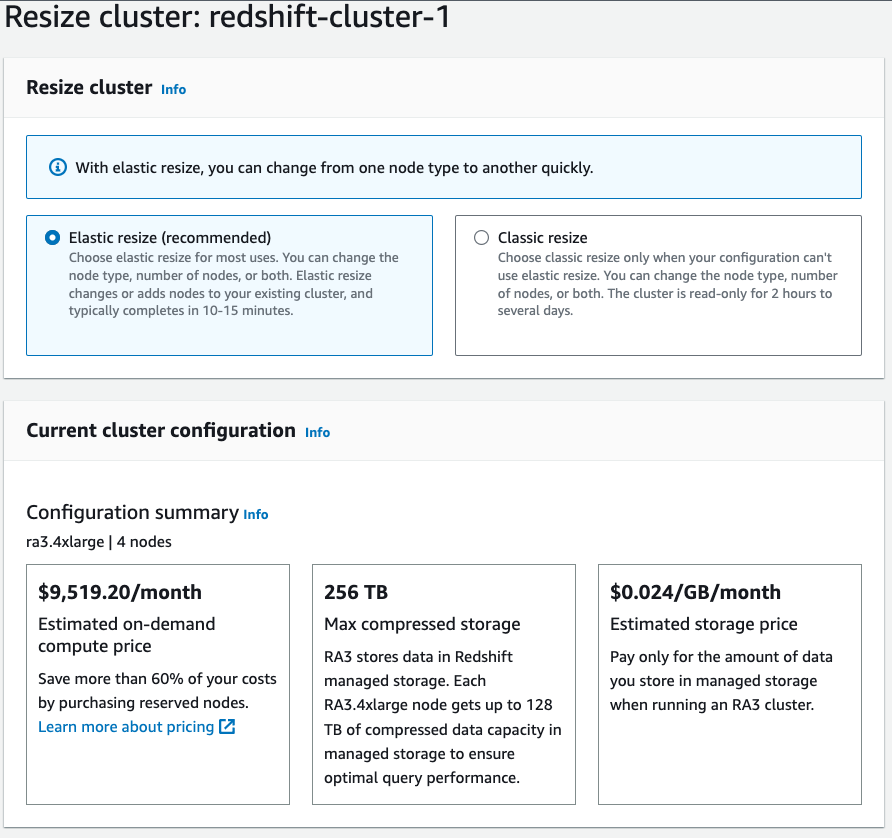
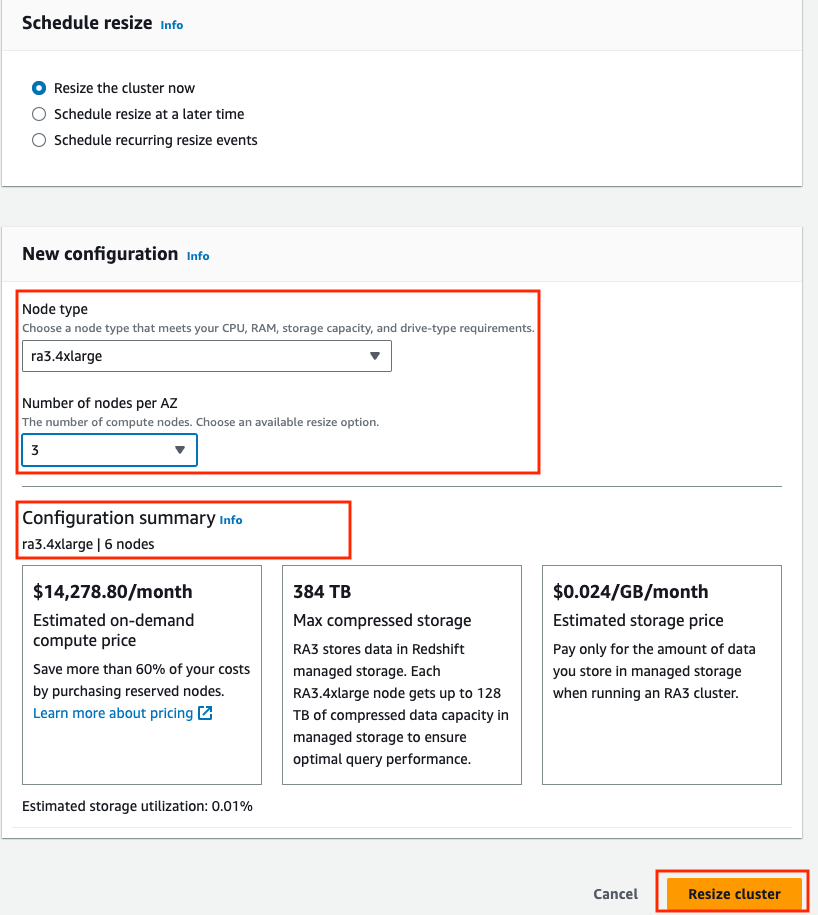
マルチ AZ データ ウェアハウスのサイズ変更
Redshift Multi-AZ 機能は、スケーリングのニーズに基づいてクラスター構成を変更するための、Multi-AZ Redshift クラスター デプロイメントのサイズ変更もサポートしています。 必要に応じてノードの数とタイプの両方を変更できます。
- Amazon Redshift コンソールのナビゲーションペインで、 クラスター.
- クラスターを選択し、クラスターの詳細ページに移動します。
- ソフトウェア設定ページで、下図のように メニュー、選択
- 選択すると別の画面が表示され、クラスターのサイズ変更画面が表示されます。そこでノードのタイプと数を選択し、 クラスターのサイズを変更する.
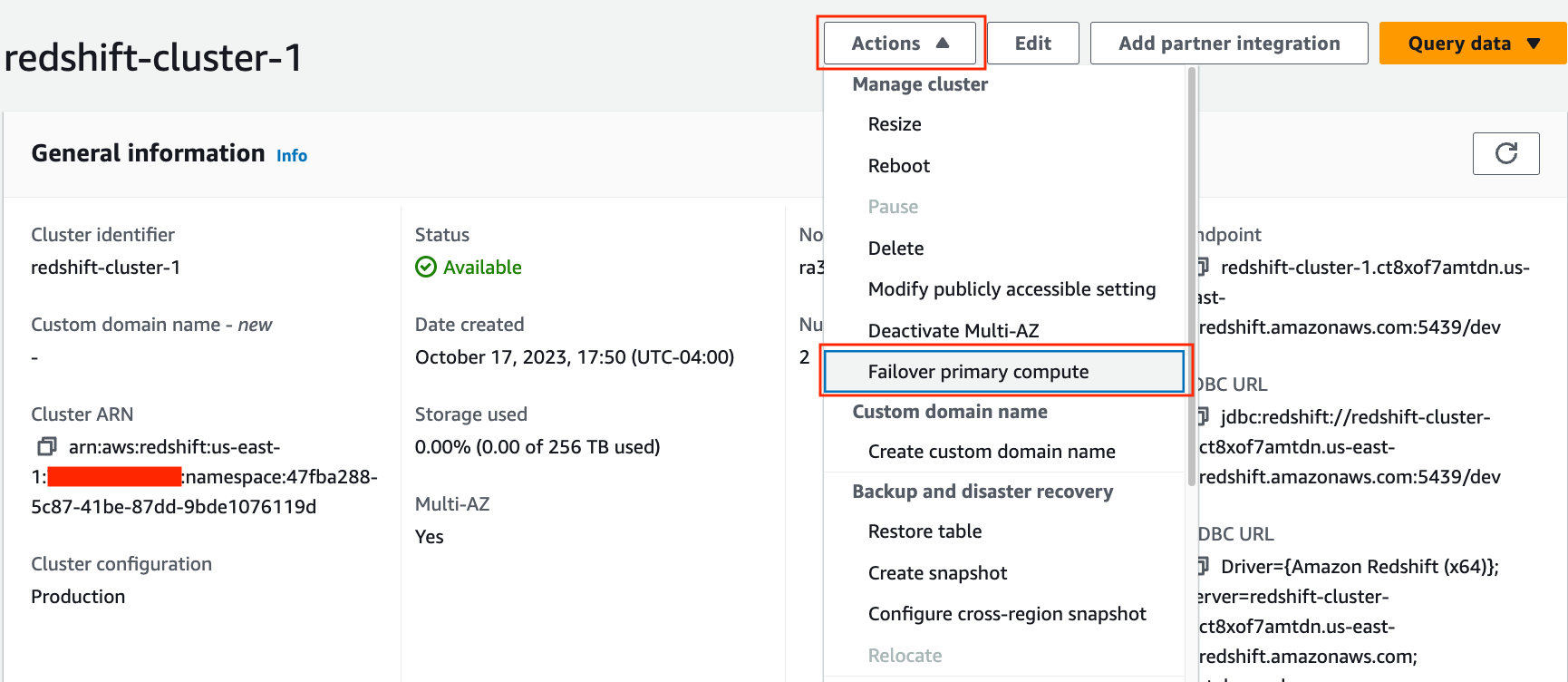
マルチ AZ 展開のフェイルオーバー
自動回復プロセスに加えて、フェールオーバー プライマリ コンピューティング オプションを使用して、データ ウェアハウスに対してこのプロセスを手動でトリガーすることもできます。 このアプローチは、それぞれの環境のニーズに応じて運用保守やその他の計画された運用手順を管理するために使用できます。 クラスターが正常に回復すると、マルチ AZ 展開が利用可能になります。 Multi-AZ デプロイメントでは、別のアベイラビリティーゾーンが利用可能になるとすぐに、そのアベイラビリティーゾーンに新しいコンピューティングノードが自動的にプロビジョニングされます。
Redshift Multi-AZ デプロイメントのフェイルオーバーを手動でトリガーしてみましょう。
- Amazon Redshiftコンソールで、 クラスター ナビゲーションペインに表示されます。
- クラスタの詳細ページに移動します
- 、選択する フェイルオーバープライマリコンピューティング.
- プロンプトが表示されたら、を選択します。 確認します.
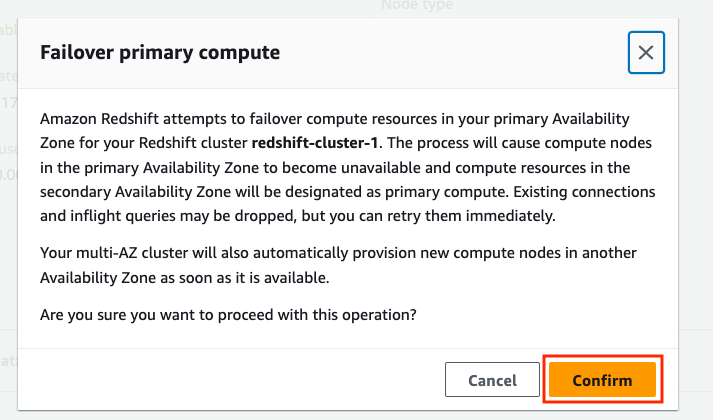
クラスタが戻った後 Available ステータスで、プライマリおよびセカンダリ アベイラビリティ ゾーンが変更されたことを確認できます。
次のスクリーンショットは、失敗を挿入する前の状態を示しています。
次のスクリーンショットは、失敗を注入した後の状態を示しています。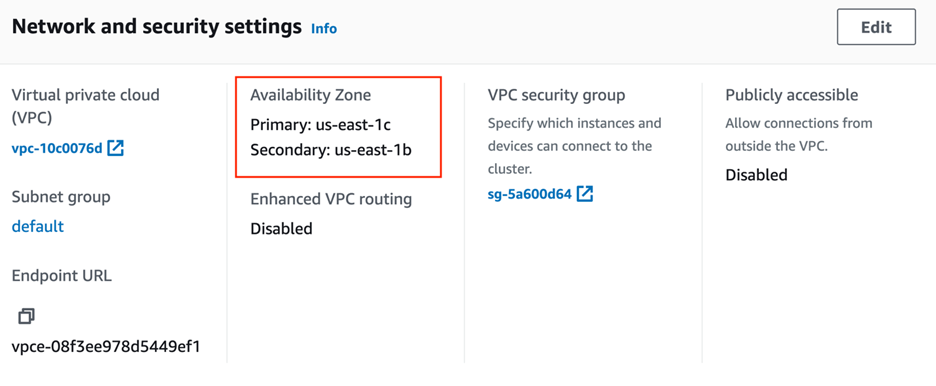
スナップショットからテーブルを復元する
マルチ AZ クラスターのスナップショットから単一のテーブルを復元できます。 スナップショットから XNUMX つのテーブルを復元する場合は、ソース スナップショット、データベース、スキーマ、テーブル名、およびターゲット データベース、スキーマ、復元されたテーブルの新しいテーブル名を指定します。
スナップショットからテーブルを復元するには:
- Amazon Redshift コンソールのナビゲーションペインで、 クラスター.
- クラスターを選択し、クラスターの詳細ページに移動します。
- ソフトウェア設定ページで、下図のように メニュー、選択 テーブルを復元します。
- 使用するスナップショット、ソース テーブル、ターゲット テーブルに関する情報を入力し、[テーブルの復元] を選択します。

Multi-AZ データ ウェアハウスのパブリック接続を有効にする
- ナビゲーション メニューから、[クラスター] を選択します。
- 変更するマルチ AZ クラスターを選択します。
- 「アクション」を選択します。
- [パブリックにアクセスできるようにする] を選択します。
- Elastic IP アドレスを選択します。選択しない場合は、アドレスがランダムに割り当てられます。
- [変更を保存]を選択します。


マルチ AZ 配置のクエリを監視する
マルチ AZ 配置では、両方のアベイラビリティーゾーンに配置されているコンピューティングリソースを使用し、特定のアベイラビリティーゾーンのリソースが利用できない場合でも操作を継続できます。 すべてのコンピューティング リソースが常に使用されるため、読み取り操作と書き込み操作の両方で XNUMX つのアベイラビリティー ゾーンにまたがる完全な操作が可能になります。
クエリを実行できます SYS_views セクションに pg_catalog マルチ AZ クエリの実行を監視するためのスキーマ。 の SYS_views プライマリ クラスタとセカンダリ クラスタからのクエリ実行アクティビティと統計をカバーします。
以下は、 SYS_view リスト:
Amazon Redshift コンソールからマルチ AZ 配置で実行されるクエリをモニタリングするには、次の手順に従います。
- Amazon Redshift コンソールで、マルチ AZ 配置のデータベースに接続し、 クエリを実行する クエリ エディターを使用します。
- マルチ AZ Redshift 配置でサンプル クエリを実行します。
- マルチ AZ デプロイメントの場合、クエリとそれが実行されている (プライマリまたはセカンダリ アベイラビリティ ゾーンで実行されている) アベイラビリティ ゾーンを、
compute_type列のSYS_QUERY_HISTORYテーブル。 計算タイプ列の有効な値は次のとおりです。- 主要な – マルチ AZ 配置のプライマリ アベイラビリティ ゾーンで実行する場合。
- 二次 – マルチ AZ 配置のセカンダリ アベイラビリティ ゾーンで実行する場合。
以下は、 compute_type クエリを監視する列:
コンソールからクエリ履歴にアクセスして、クエリの診断を分析することもできます。
- ソフトウェア設定ページで、下図のように クエリの監視 タブを選択 データベースに接続します。

- 接続、選択する 新しい接続を作成する
- 認証、選択する 一時的な資格情報
- データベース名、データベース名を入力します (たとえば、
dev). - データベースユーザーで、データベースのユーザー名を入力します (たとえば、
awsuser). - 選択する お問合せ.

接続したら、 クエリの監視上 クエリ履歴タブでは、次のスクリーンショットに示すように、すべてのクエリと負荷を表示できます。

メトリック フィルターでさまざまなフィルターを使用できます。 追加のフィルタリング オプション に基づいてクエリ履歴を表示するセクション 時間間隔, ユーザー, データベースまたは SQLコマンド.

プレビュー モードで Amazon Redshift マルチ AZ を使用する場合、いくつかの制限があります。 こちら 制限のために。
顧客フィードバック
 |
ヤンセンファーマシューティカルズはジョンソン・エンド・ジョンソンの子会社であり、患者と医療業界の変化するニーズに焦点を当てた医薬品の研究と製造を行っています。
– Shyam Mohapatra 氏、情報技術担当ディレクター – Janssen Pharmaceutical Companies of Johnson & Johnson |
 |
ストライプ は、インターネットの経済インフラを構築するテクノロジー企業です。 Stripe の製品は、オンラインおよび対面小売店、サブスクリプション ビジネス、ソフトウェア プラットフォームとマーケットプレイス、およびその間のすべての支払いを強化します。
「何百万もの企業が、Stripe のソフトウェアと API を使用して、オンラインでの支払いの受け入れ、送金、ビジネスの管理を行っています。 Amazon Redshift などの主要なデータ ウェアハウスを介した Stripe データへのアクセスは、お客様からの最も多いリクエストです。 当社のお客様は、複雑なデータ パイプラインを構築したり、データを移動したりコピーしたりすることなく、可用性が高く、安全で、高速で統合された大規模な分析を必要としていました。 Amazon Redshift 用の Stripe Data Pipeline を使用すると、お客様が数回クリックするだけで直接的で信頼性の高いデータ パイプラインをセットアップできるようになります。 Stripe Data Pipeline を使用すると、お客様は完全な最新の Stripe データを Amazon Redshift データ ウェアハウスと自動的に共有し、ビジネス分析とレポートを次のレベルに引き上げることができます。に設立された地域オフィスに加えて、さらにローカルカスタマーサポートを提供できるようになります。」 – ブライアン・ブルナー Stripe のエンジニアリング担当シニアマネージャー |
まとめ
この投稿では、XNUMX つのアベイラビリティーゾーンで Amazon Redshift マルチ AZ デプロイメントを構成し、アベイラビリティーゾーンに予期せぬ障害が発生した際にワークロードのフォールトトレランスをテストする方法を説明しました。 Amazon Redshift マルチ AZ デプロイメントは、両方のアベイラビリティーゾーンのコンピューティングノードが読み取りおよび書き込み操作に使用されるため、データウェアハウスの全体的なパフォーマンスの向上にも役立ちます。 Amazon Redshift Multi-AZ データ ウェアハウスは、最高レベルの可用性と復元力を必要とするミッションクリティカルな分析アプリケーションで顧客の要求を満たすのに役立ちます。 詳細については、を参照してください。 マルチ AZ 配置の構成.
著者について
 ランジャン・バーマン AWS の分析スペシャリスト ソリューション アーキテクトです。 彼は Amazon Redshift を専門とし、顧客がスケーラブルな分析ソリューションを構築するのを支援しています。 彼は、さまざまなデータベースおよびデータ ウェアハウジング テクノロジで 16 年以上の経験があります。 彼は、クラウド ソリューションを使用して顧客の問題を自動化し、解決することに情熱を注いでいます。
ランジャン・バーマン AWS の分析スペシャリスト ソリューション アーキテクトです。 彼は Amazon Redshift を専門とし、顧客がスケーラブルな分析ソリューションを構築するのを支援しています。 彼は、さまざまなデータベースおよびデータ ウェアハウジング テクノロジで 16 年以上の経験があります。 彼は、クラウド ソリューションを使用して顧客の問題を自動化し、解決することに情熱を注いでいます。
 サウラヴ・ダス Amazon Redshift 製品管理チームの一員です。 彼は、リレーショナル データベース テクノロジとデータ保護に 16 年以上携わってきました。 彼は、高可用性と災害復旧を中心とした顧客の課題を解決することに深い関心を持っています。
サウラヴ・ダス Amazon Redshift 製品管理チームの一員です。 彼は、リレーショナル データベース テクノロジとデータ保護に 16 年以上携わってきました。 彼は、高可用性と災害復旧を中心とした顧客の課題を解決することに深い関心を持っています。
 アヌシャチャラ は、Amazon Redshift を専門とするシニア アナリティクス スペシャリスト ソリューション アーキテクトです。 彼女は、多くの顧客がクラウドおよびオンプレミスで大規模なデータ ウェアハウス ソリューションを構築するのを支援してきました。 彼女はデータ分析とデータ サイエンスに情熱を注いでいます。
アヌシャチャラ は、Amazon Redshift を専門とするシニア アナリティクス スペシャリスト ソリューション アーキテクトです。 彼女は、多くの顧客がクラウドおよびオンプレミスで大規模なデータ ウェアハウス ソリューションを構築するのを支援してきました。 彼女はデータ分析とデータ サイエンスに情熱を注いでいます。
 ニタ・シャー ニューヨークを拠点とするAWSのアナリティクススペシャリストソリューションアーキテクトです。 彼女は20年以上にわたってデータウェアハウスソリューションを構築しており、AmazonRedshiftを専門としています。 彼女は、顧客がエンタープライズ規模の適切に設計された分析および意思決定支援プラットフォームを設計および構築するのを支援することに焦点を当てています。
ニタ・シャー ニューヨークを拠点とするAWSのアナリティクススペシャリストソリューションアーキテクトです。 彼女は20年以上にわたってデータウェアハウスソリューションを構築しており、AmazonRedshiftを専門としています。 彼女は、顧客がエンタープライズ規模の適切に設計された分析および意思決定支援プラットフォームを設計および構築するのを支援することに焦点を当てています。
 スレシュ・パトナム AWS のプリンシパル BDM – GTM AI/ML リーダーです。 彼は顧客と協力して IT 戦略を構築し、データと AI/ML を使用してクラウドを介したデジタル トランスフォーメーションをより利用しやすくしています。 余暇には、Suresh はテニスをしたり、家族と過ごす時間を楽しんでいます。
スレシュ・パトナム AWS のプリンシパル BDM – GTM AI/ML リーダーです。 彼は顧客と協力して IT 戦略を構築し、データと AI/ML を使用してクラウドを介したデジタル トランスフォーメーションをより利用しやすくしています。 余暇には、Suresh はテニスをしたり、家族と過ごす時間を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/enable-multi-az-deployments-for-your-amazon-redshift-data-warehouse/

