Einleitung
Google Big Query ist ein sicherer, zugänglicher, vollständig verwalteter, nutzungsbasierter, serverloser Multi-Cloud-Data-Warehouse-Plattform-as-a-Service (PaaS)-Dienst, der von bereitgestellt wird Google Cloud Platform Dies hilft dabei, nützliche Erkenntnisse aus Big Data zu generieren, die den Interessenvertretern des Unternehmens bei der effektiven Entscheidungsfindung helfen. Google Big Query bietet eine integrierte maschinelle Lernfunktion und eine SQL-Abfrage-Engine zum Schreiben von SQL, das zum Analysieren großer Datensätze verwendet werden kann. Wir können mit Google Big Query ein sicheres und hochverfügbares Data Warehouse entwickeln.
Udemy ist eine der beliebtesten Online-Lernplattformen. Udemy bietet hochwertige Lerninhalte in Design, Marketing, Entwicklung, Finanz- und Rechnungswesen, IT und Software, Fotografie und Video, Gesundheit und Wellness, Büroproduktivität usw. in verschiedenen Sprachen. Udemy ist eine wichtige Informationsquelle für viele Studenten, Freiberufler und Berufstätige. Udemy ist eine der besten Plattformen, um Python und React zu lernen und sich auf die AWS- und Azure-Zertifizierung vorzubereiten. Die Lernenden könnten jedoch daran interessiert sein, Kurse von Dozenten zu belegen, die besser auf ihre Berufsbezeichnungen abgestimmt sind, Kurse, die von vielen Benutzern besucht werden, und zertifizierte Entwickler wie AWS-zertifiziert, Salesforce-zertifiziert und so weiter. Um dieses Problem anzugehen, werden wir ein Data Warehouse erstellen, um mithilfe von Google Big Query Udemy-Kurstrends und -einblicke zu untersuchen.
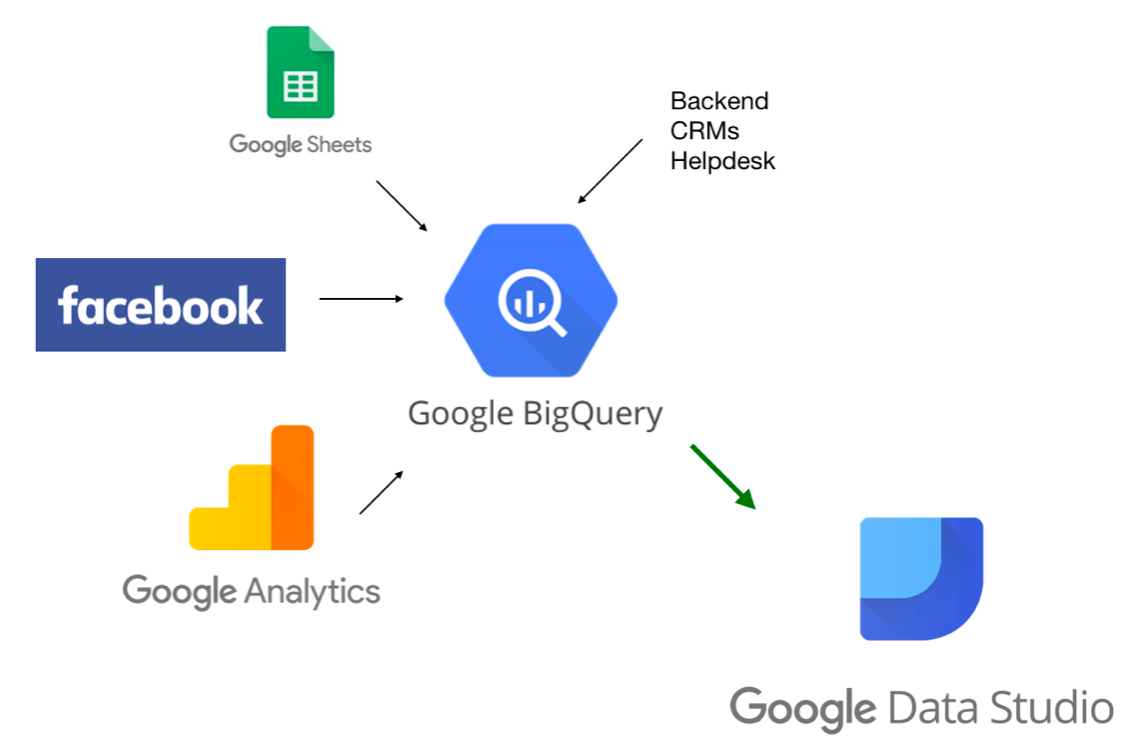
Fast alle großen Cloud-Dienstleister wie Google, Amazon, Microsoft usw. bieten heute Data-Warehouse-Tools an. Cloudbasierte Data-Warehouse-Tools sind hochgradig skalierbar und bieten Notfallwiederherstellung. Verwendung einer Data Warehouse Wir können große Datenmengen speichern und analysieren und mit Hilfe von Datenvisualisierungen und Berichten nützliche Dateneinblicke gewinnen. Gut konzipierte Data Warehouses liefern qualitativ hochwertige Daten und verbessern die Abfrageleistung, indem sie die Art der Daten richtig definieren, Data Mining, künstliche Intelligenz usw. verwenden und dabei helfen, klügere Entscheidungen zu treffen.
In diesem Artikel wird der Ansatz zum Aufbau eines Data Warehouse zum Erkunden von Udemy-Kurstrends und -einblicken mit Google Big Query erörtert, das uns dabei helfen wird, Dinge wie die Klassifizierung von Kursen basierend auf den Berufsbezeichnungen des Dozenten, der durchschnittlichen Bewertung aller Kurse eines Dozenten, usw.
Lernziele
In diesem Artikel lernen wir:
- So bauen Sie ein Data Warehouse mit Google Big Query auf
- So verwenden Sie die Google Big Query-Sandbox
- Erwerben Sie Kenntnisse über das Erstellen von Datasets und Tabellen in Big Query
- Abfragen von Udemy-Daten in der Big Query-SQL-Abfrage-Engine
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Projektbeschreibung
Jetzt erstellen wir die Tabelle innerhalb des Datensatzes in der SQL-Abfrage-Engine der Google Cloud Platform aus den heruntergeladenen Daten. Nach dem Erstellen der Tabelle formatieren wir das Tabellenschema und führen eine Datenbereinigung durch. Wir können importierte Daten abfragen, um nützliche Erkenntnisse zu gewinnen, wie z. B. das Klassifizieren von Kursen basierend auf den Berufsbezeichnungen des Dozenten, das Identifizieren von Kursen mit Höchstbewertungen, das Identifizieren von Dozenten, deren Kurse gute Bewertungen haben usw.
Derzeit haben wir Daten aus nur einer Quelle und importieren Daten im CSV-Format durch Batchaufnahme über die Benutzeroberfläche der Google Cloud Platform. Wir können auch Daten aus mehreren Quellen wie Cloud Storage, Azure Storage Account usw. importieren. Neben dem Importieren von Daten über die Benutzeroberfläche der Google Cloud Platform können Benutzer Daten auch über CLI und REST-APIs importieren, indem sie Datenpipelineoptionen wie Cloud verwenden Dataflow, Cloud Dataproc usw. Google Big Query unterstützt auch Dateiformate wie Parquet, Avro usw. zum Laden und Verarbeiten von Daten. Entwickler können auch Abfragen in der SQL-Abfrage-Engine zum geplanten Zeitpunkt speichern, freigeben und ausführen.

Durch Abfragen von Udemy-Daten können Benutzer bestimmen, welche Kurse sie kaufen sollten, basierend auf Kursdauer, Kursbewertungen, Berufsbezeichnungen von Dozenten, Kursbeliebtheit usw. Benutzer können diese Abfragen speichern und teilen. Benutzer können die Ergebnisse dieser Abfragen auch speichern, um Dashboards mit Power BI, Looker Studio, Tableau usw. zu erstellen. Benutzer können auch mithilfe von Web-Scraping-Techniken weitere Daten aus Udemy extrahieren und in die SQL-Abfrage-Engine von Google Big Query aufnehmen, um die Daten auf dem neuesten Stand zu halten damit Benutzer genauere Ergebnisse erhalten.
Problem Statement
In diesem Artikel verwenden wir den Udemy Courses Data 2023-Datensatz von Kaggle, um ein Data Warehouse für die Untersuchung von Udemy-Kurstrends und -einblicken mit Google Big Query zu entwickeln, das uns dabei helfen wird, Dinge wie die Klassifizierung von Kursen basierend auf den Berufsbezeichnungen des Dozenten zu identifizieren durchschnittliche Bewertung aller Kurse eines Dozenten, Klassifizierung von Kursen basierend auf der Anzahl der Vorlesungen im Kurs, Identifizierung kürzlich veröffentlichter und geänderter Kurse auf Udemy usw.
Wie bereits erwähnt, können wir mithilfe von Web-Scraping-Techniken mehr Daten aus Udemy extrahieren, da auf der Udemy-Plattform ständig neue Kurse und Dozenten hinzukommen. Wir erstellen Tabellen innerhalb des Datasets in der SQL-Abfrage-Engine der Google Cloud Platform, um die von Kaggle heruntergeladenen Kurse und Dozentendaten zu importieren. Nach der Tabellenerstellung führen wir die Datenbereinigung und Formatierung des Tabellenschemas durch.
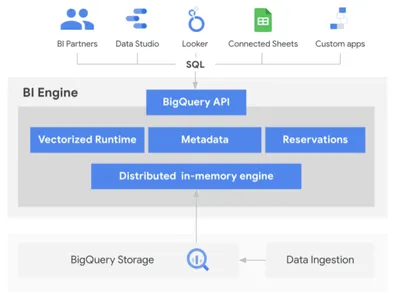
Wir können Abfragen in der SQL-Abfrage-Engine zum geplanten Zeitpunkt speichern, freigeben und ausführen. Abgesehen davon können wir auch die Ergebnisse der Abfrageausführung speichern, damit sie Abfragen verwenden können, um Dashboards mit Power BI, Looker Studio, Tableau usw. zu erstellen. Dieses Projekt zielt darauf ab, ein Data Warehouse mit Udemy-Daten zu entwickeln und abzufragen, welche Benutzer kann kürzlich veröffentlichte und geänderte Kurse auf Udemy identifizieren, Kurse basierend auf Kursdauer und Kursbewertungen klassifizieren, Durchschnittsbewertungen aller Kurse eines Dozenten identifizieren, Kurse basierend auf der Anzahl der Vorlesungen im Kurs klassifizieren usw.
Voraussetzungen:
Nachfolgend finden Sie einige Voraussetzungen, um dieses Projekt durchzuführen:
- Verständnis von Data Warehouse: In diesem Projekt werden wir ein Data Warehouse erstellen, um Udemy-Kurstrends und -einblicke mit Google Big Query zu untersuchen. Daher ist es wichtig zu verstehen, was ein Data Warehouse ist, warum ein Data Warehouse nützlich ist und was das Data Warehouse von verschiedenen Cloud-Anbietern usw. bietet.
- Erfahrung mit Google Cloud Platform: Wir verwenden Google Big Query, einen Data Warehouse-Dienst, der innerhalb der Google Cloud Platform verfügbar ist. Daher ist Erfahrung mit der Google Cloud Platform wichtig, um sich einfach auf der Plattform zurechtzufinden und den Ressourcenerstellungsprozess, Rollen und Zugriffsberechtigungen usw. zu verstehen.
- Erfahrung mit SQL-Abfragen: Wir werden Abfragen in der SQL-Abfrage-Engine schreiben, um nützliche Erkenntnisse zu gewinnen, wie z. B. das Klassifizieren von Kursen basierend auf den Berufsbezeichnungen des Dozenten, das Identifizieren von Kursen mit maximalen Bewertungen, Dozenten, deren Kurse gute Bewertungen haben usw.
- Vertrautheit mit Udemy und Kaggle: Zu verstehen, was Kaggle ist, wie es zum Herunterladen von Datensätzen nützlich ist, und grundlegende Vertrautheit mit der Online-Lernplattform Udemy werden bei der Entwicklung des Projekts hilfreich sein.
- Verständnis von Google Big Query: Da dieses Projekt Google Big Query zum Erstellen eines Data Warehouse verwendet, wäre es von Vorteil, die allgemeinen Datenoperationen, Konzepte und Techniken von Google Big Query zu verstehen.
Wissen über den Datensatz
In diesem Artikel werden wir verwenden Udemy-Kursdaten 2023 Datensatz von Kagle. Der Datensatz kann unter heruntergeladen werden https://www.kaggle.com/datasets/ankushbisht005/udemy-courses-data-2023. Das Ziel hinter der Verwendung dieses Datensatzes ist es, kürzlich veröffentlichte und geänderte Kurse auf Udemy zu identifizieren, Kurse basierend auf Kursdauer und Kursbewertungen zu klassifizieren, Durchschnittsbewertungen aller Kurse eines Dozenten zu identifizieren, Kurse basierend auf der Anzahl der Vorlesungen im Kurs zu klassifizieren, usw.
Der Udemy-Kursdaten-Datensatz 2023 enthält zwei Dateien namens „courses.csv“ und „instructors.csv“. Die Datei „courses.csv“ enthält Informationen zu den Udemy-Kursen. Die Datei „instructors.csv“ enthält die Informationen zu den Udemy-Dozenten. Die Courses.csv enthält 11 Spalten und 83,105 Zeilen. Die Datei „instructors.csv“ enthält 10 Spalten und 32,234 Zeilen. Die Datei „courses.csv“ enthält die Spalte „instructors_id“, die die ID des Dozenten des Kurses angibt. Die Spalte „instructors_id“ wird verwendet, um die Beziehung zwischen „courses.csv“ und „instructors.csv“ herzustellen.
Das Kurse.csv enthält die eindeutige ID des Kurses, den Kurstitel, die Kursbewertung, die Kursdauer, die Anzahl der Vorlesungen im Udemy-Kurs, die URL des Kurses, das Erstellungsdatum des Kurses, das Datum, an dem der Kurs zuletzt geändert wurde, Anzahl der Bewertungen des Kurses und ID des Kursleiters. Der Ausbilder.csv enthält die eindeutige ID des Kursleiters, den Namen des Kursleiters, den Anzeigenamen des Kursleiters, den Titel des Kursleiters, die Berufsbezeichnung des Kursleiters, die Kursleiterklasse, die URL des Kursleiters, die Initialen von des Kursleiters, 50 x 50-Bild des Kursleiters und 100 x 100-Bild des Kursleiters. Um mehr über den Datensatz zu erfahren, besuchen Sie https://www.kaggle.com/datasets/ankushbisht005/udemy-courses-data-2023.
Herangehensweise an das Projekt
In diesem Projekt werden wir verwenden Udemy-Kursdaten 2023 Datensatz von Kaggle, um ein Data Warehouse zur Untersuchung von Udemy-Kurstrends und Erkenntnissen mithilfe von Google Big Query zu entwickeln, das uns dabei helfen wird, Dinge zu identifizieren, wie z Klassifizieren von Kursen basierend auf den Berufsbezeichnungen des Dozenten, der durchschnittlichen Bewertung aller Kurse eines Dozenten, Klassifizieren von Kursen basierend auf der Anzahl der Vorlesungen im Kurs, Identifizieren kürzlich veröffentlichter und geänderter Kurse auf Udemy usw.
Führen Sie die folgenden Schritte aus, um ein Data Warehouse mit zu erstellen Udemy-Kursdaten 2023 Datensatz von Kaggle:
Schritt 1: Erstellen Sie ein neues Projekt mit Big Query Sandbox
Um mit Google Big Query zu arbeiten, können Entwickler entweder ein Konto auf der Google Cloud Platform erstellen oder die Google Big Query Sandbox verwenden. Ich werde in diesem Artikel Google Big Query Sandbox verwenden, um ein Data Warehouse zu erstellen. Das Projekt wird zum Organisieren aller Google Cloud-Ressourcen in der GCP verwendet. Mit Identity and Access Management können wir festlegen, welcher Benutzer berechtigt ist, auf welche Ressourcen in einem Projekt zuzugreifen.
Besuchen Sie den folgenden Link, um die zu verwenden Google Big Query-Sandbox: https://console.cloud.google.com/bigquery
Befolgen Sie nun die unten beschriebenen Schritte:
1. Klicke auf NEUES PROJEKT und gib dann auf dem nächsten Bildschirm den Projektnamen als Udemy-Projekt und Standort an. Klicken Sie auf ERSTELLEN.
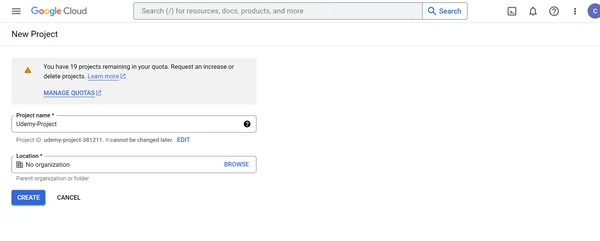
2. Udemy-Projekt wurde erfolgreich erstellt. Wählen Sie das Udemy-Projekt aus, um das Projekt anzuzeigen und Benutzerberechtigungen und Ressourcen innerhalb des Projekts zu verwalten.
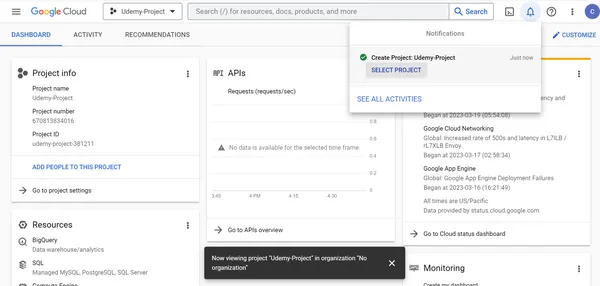
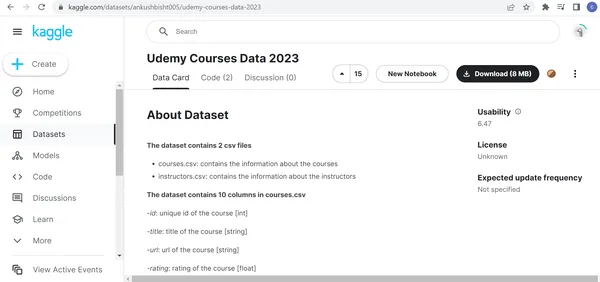
Schritt 2: Laden Sie das Dataset von Kaggle herunter und speichern Sie es auf dem lokalen Computer
Besuchen Sie https://www.kaggle.com/datasets/ankushbisht005/udemy-courses-data-2023 und klicken Sie auf Herunterladen. Nach dem Entpacken der heruntergeladenen ZIP-Datei finden Sie zwei CSV-Dateien mit den Namen „courses.csv“ und „instructors.csv“. Die Datei „courses.csv“ enthält Informationen zu den Udemy-Kursen. Die Datei „instructors.csv“ enthält die Informationen zu den Udemy-Dozenten. Die Courses.csv enthält 11 Spalten und 83,105 Zeilen. Die Datei „instructors.csv“ enthält 10 Spalten und 32,234 Zeilen. Die Spalte „instructors_id“ wird verwendet, um die Beziehung zwischen „courses.csv“ und „instructors.csv“ herzustellen.
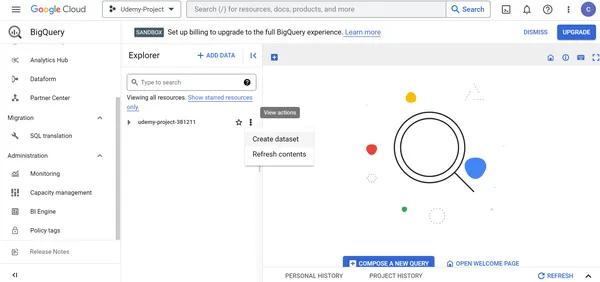
Schritt 3: Erstellen eines Datensatzes innerhalb der Google Big Query-Ressource
Führen Sie die unten beschriebenen Schritte aus, um einen Datensatz in Google Big Query zu erstellen:
1. Wählen Sie den Namen des Projekts -> Big Query in der Ressourcenkarte -> Klicken Sie auf Datensatz erstellen.
2. Geben Sie Udemy_dataset als Datensatz-ID an, wählen Sie Region als Standorttyp, wählen Sie Asia-south1 (Mumbai) als Region und aktivieren Sie den Tabellenablauf.
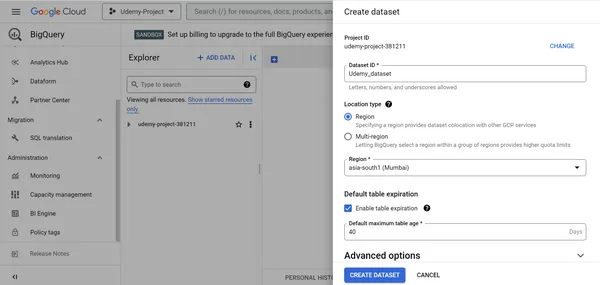
3. Klicken Sie auf DATENSATZ ERSTELLEN
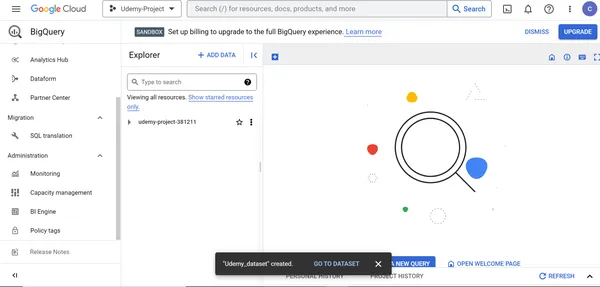
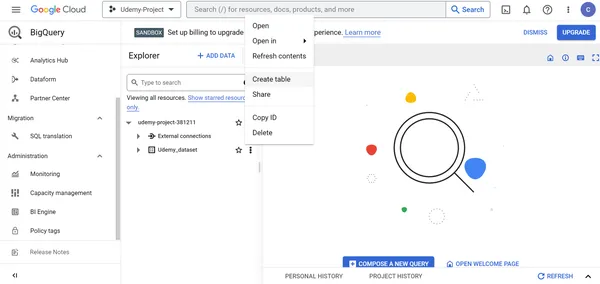
Schritt 4: Erstellen Sie Tabellen im Datensatz innerhalb der Google Big Query-Ressource
Führen Sie die unten beschriebenen Schritte aus, um Tabellen im Dataset in Google Big Query zu erstellen:
1. Wählen Sie Udemy_dataset-Datensatz -> Tabelle erstellen
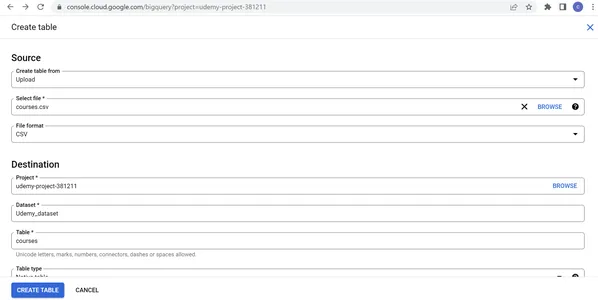
2. Wählen Sie „Tabelle aus Upload erstellen“, wählen Sie die von Kaggle heruntergeladene Datei „courses.csv“, wählen Sie das Dateiformat „CSV“, geben Sie Kurse als Tabellennamen an, „Native Tabelle“ als Tabellentyp, wählen Sie „Automatisch zum Erkennen im Schema“ und „Partitionieren und Clustern“. Einstellungen nach unseren Anforderungen. Geben Sie in den erweiterten Optionen 1 in den Kopfzeilen ein, um sie zu überspringen, und wählen Sie die Verschlüsselung, die den Anforderungen entspricht. Klicken Sie auf TABELLE ERSTELLEN.
3. Wählen Sie nun erneut den Datensatz Udemy_dataset aus
-> Tabelle erstellen. Wählen Sie aus, ob Sie eine Tabelle aus dem Upload erstellen möchten, wählen Sie die von Kaggle heruntergeladene Datei „instructors.csv“ aus, wählen Sie das Dateiformat „CSV“ aus, geben Sie „Dozenten“ als Tabellennamen an, „Native Tabelle“ als Tabellentyp, „Automatisch zum Erkennen im Schema“ sowie „Partitions- und Clustereinstellungen“. nach unseren Anforderungen. Geben Sie in den erweiterten Optionen 1 in den Kopfzeilen ein, um sie zu überspringen, und wählen Sie die Verschlüsselung, die den Anforderungen entspricht. Klicken Sie auf TABELLE ERSTELLEN.
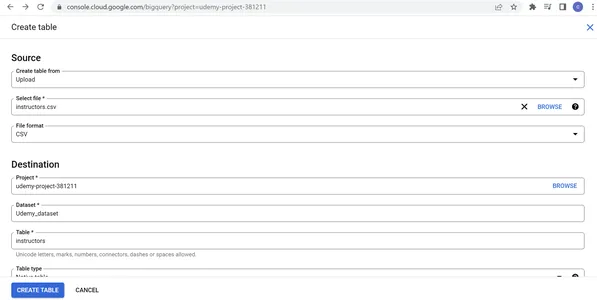
Schritt 5: Überprüfen des Tabellenschemas und Vorschau der Daten
Wechseln Sie zur Tabelle „courses“ und überprüfen Sie den Feldnamen, den Typ und den Modus in der Tabelle Schema Tab. Zeigen Sie die Zeilenzugriffsrichtlinien der Kurstabelle an und bearbeiten Sie bei Bedarf das Tabellenschema. Sehen Sie sich die Tabelleninformationen in der an DETAILS Registerkarte und bearbeiten Sie die Details im Falle von Korrekturen. Wir können die Daten auch in der Vorschau anzeigen, kopieren, aktualisieren und teilen. Wechseln Sie auf ähnliche Weise zur Lehrertabelle und überprüfen Sie den Feldnamen, den Typ und den Modus in der Schema Tab. Zeigen Sie die Zeilenzugriffsrichtlinien der Dozententabelle an und bearbeiten Sie bei Bedarf das Tabellenschema.
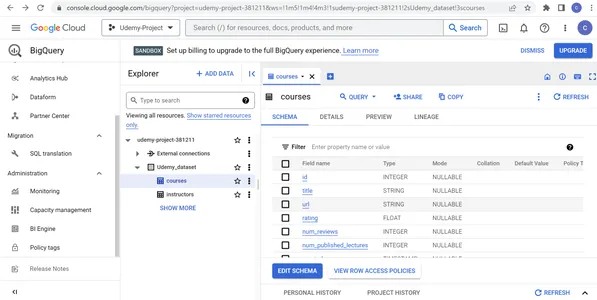
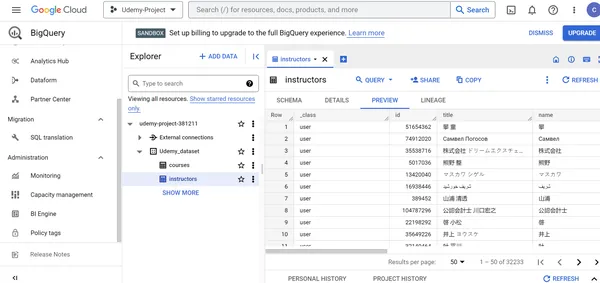
Schritt 6: Erkunden von Udemy-Kurstrends und -erkenntnissen durch Abfragen der Daten
Um 5000 Datensätze aus dem zu sehen Kurse Tabelle, führen Sie die folgende Abfrage in der SQL-Abfrage-Engine aus:
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` LIMIT 5000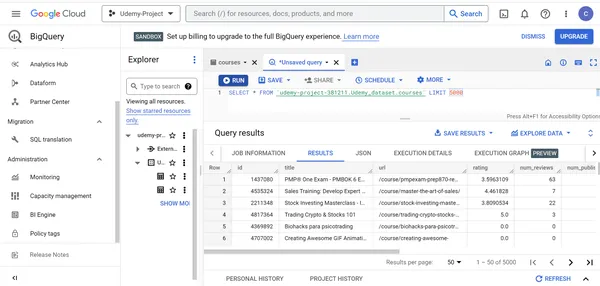
Um 5000 Datensätze aus dem zu sehen Ausbilder Tabelle, führen Sie die folgende Abfrage in der SQL-Abfrage-Engine aus:
SELECT * FROM `udemy-project-381211.Udemy_dataset.instructors` LIMIT 5000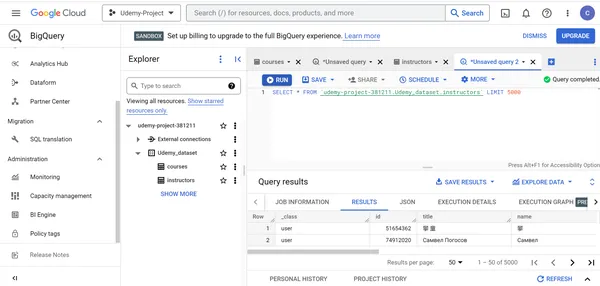
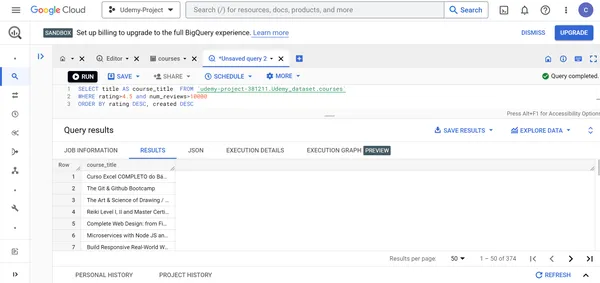
A. Finden Sie die Titel aller Kurse, deren Bewertungen größer als 4.5 sind und mehr als 10000 Personen die Bewertung für diese Kurse abgegeben haben. Zeigen Sie diese Kurse in absteigender Reihenfolge der Kursbewertungen und des Erstellungsdatums an.
SELECT title AS course_title FROM `udemy-project-381211.Udemy_dataset.courses` WHERE rating>4.5 and num_reviews>10000
ORDER BY rating DESC, created DESC
B. Einzelheiten zu den 10 neu erstellten Udemy-Kursen finden.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` ORDER BY created DESC
LIMIT 10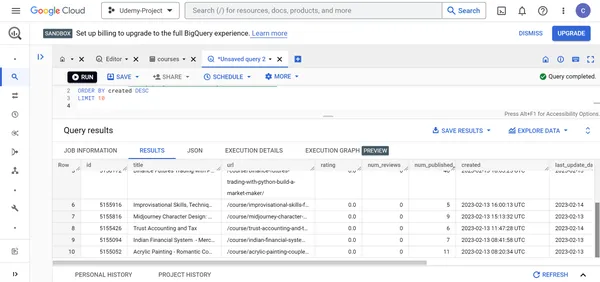
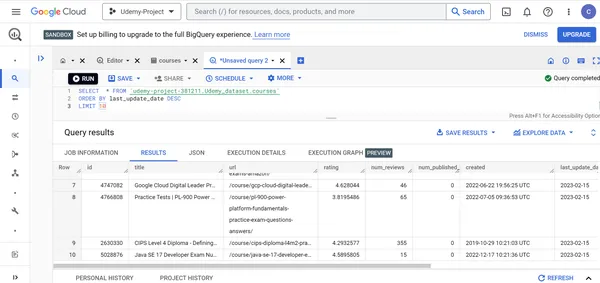
C. Finden Sie die Details der 10 kürzlich geänderten Udemy-Kurse.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` ORDER BY last_update_date DESC
LIMIT 10
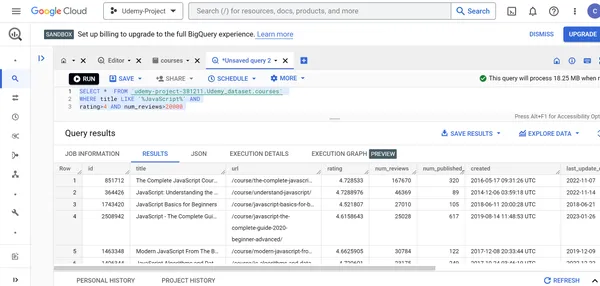
D. Suchen Sie die Details der JavaScript-Kurse, deren Bewertungen größer als 4 sind und von denen mehr als 20000 Personen die Bewertung für diese Kurse abgegeben haben.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%JavaScript%' AND
rating>4 AND num_reviews>20000
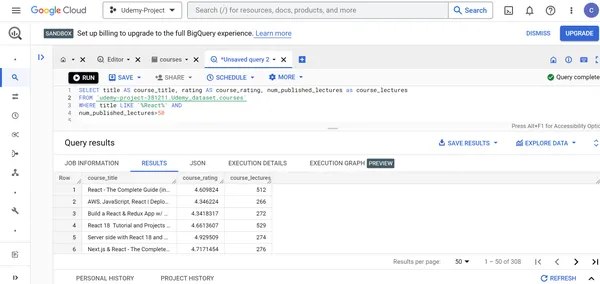
E. Anzeige des Titels, der Bewertung und der Anzahl der Vorlesungen der Udemy React-Kurse mit mehr als 50 Vorlesungen.
SELECT title AS course_title, rating AS course_rating, num_published_lectures as course_lectures FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%React%' AND
num_published_lectures>50
F. Ermitteln Sie die Anzahl der Kurse und den Namen des Kursleiters, die von den Kursleitern mit Kursbewertungen entwickelt wurden, die größer sind als die durchschnittlichen Bewertungen der Kurse.
SELECT COUNT(courses.id), instructors.name
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.instructors_id IN (SELECT instructors_id FROM `Udemy_dataset.courses` WHERE rating >(SELECT AVG(rating) FROM `Udemy_dataset.courses`))
GROUP BY instructors.name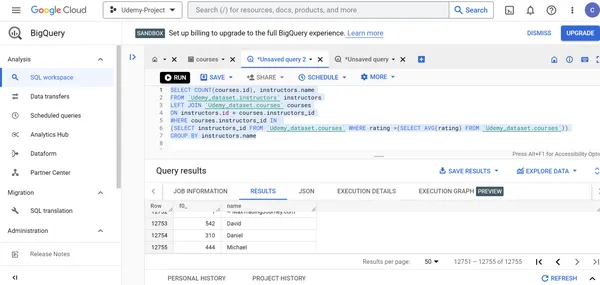
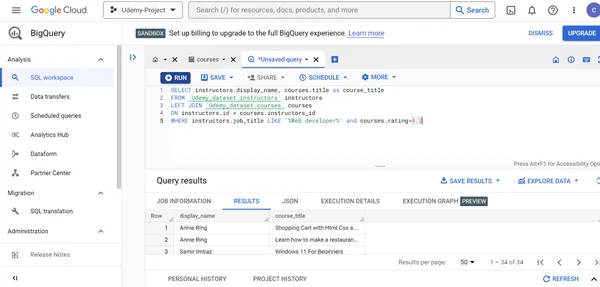
G. Zeigen Sie den Namen und Titel des Kursleiters der Udemy-Kurse an, die von Personen erstellt wurden, deren Berufsbezeichnung Webentwickler ist
und deren Platzbewertungen größer als 4.2 sind.
SELECT instructors.display_name, courses.title as course_title
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE instructors.job_title LIKE '%Web developer%' and courses.rating>4.2
H. Anzeige des Kurstitels, des Kursleiternamens, der Bewertungen und der Kursdauer der Udemy-Kurse, wenn die Kursdauer mehr als 40 Minuten, 40 Stunden oder 40 Fragen beträgt.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating, courses.duration
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE CASE WHEN courses.duration LIKE '%.%' THEN CAST(LEFT(courses.duration, STRPOS(courses.duration,'.')-1) AS FLOAT64)>40 WHEN courses.duration LIKE '%total%' THEN CAST(LEFT(courses.duration, STRPOS(courses.duration,'t')-1) AS FLOAT64)>40 WHEN courses.duration LIKE '%ques%' THEN CAST(LEFT(courses.duration, STRPOS(courses.duration,'q')-1) AS FLOAT64)>40
END
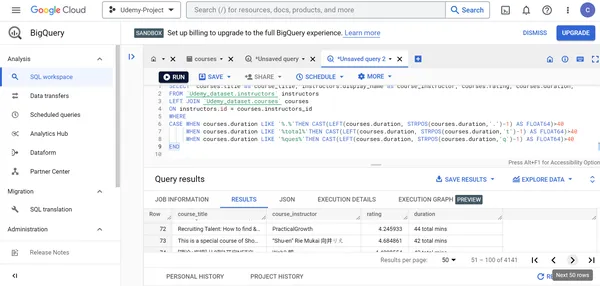
I. Anzeige des Kursleiternamens und -titels der von zertifizierten Entwicklern erstellten Udemy-Kurse.
SELECT courses.title as course_title, instructors.display_name as course_instructor
FROM `Udemy_dataset.instructors` instructors LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE instructors.job_title LIKE '%certified%'
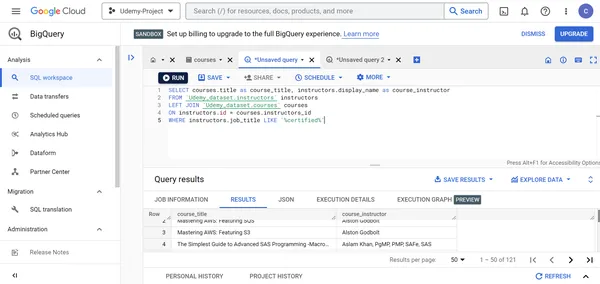
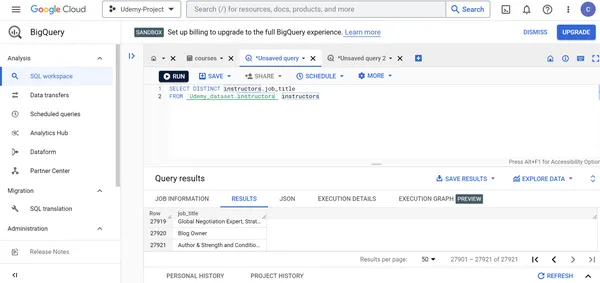
J. Finden Sie alle unterschiedlichen Berufsbezeichnungen von Udemy-Kursleitern.
SELECT DISTINCT instructors.job_title
FROM `Udemy_dataset.instructors` instructors
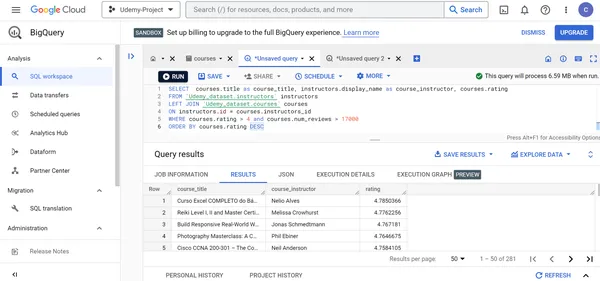
K. Finden Sie den Titel, die Bewertungen und den Dozenten aller Kurse, deren Bewertungen größer als 4 sind und von denen mehr als 17000 Personen die Bewertung für diese Kurse abgegeben haben. Zeigen Sie diese Kurse in absteigender Reihenfolge der Kursbewertungen an.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.rating > 4 and courses.num_reviews > 17000
ORDER BY courses.rating DESC
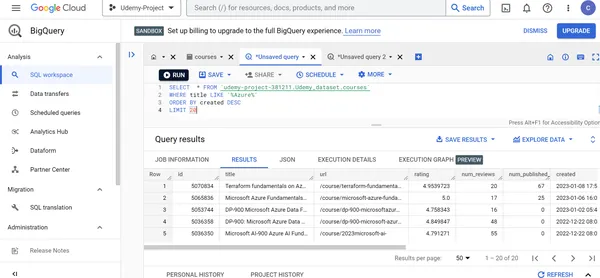
L. Hier finden Sie die Details der 20 neu erstellten Azure Udemy-Kurse.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%Azure%'
ORDER BY created DESC
LIMIT 20
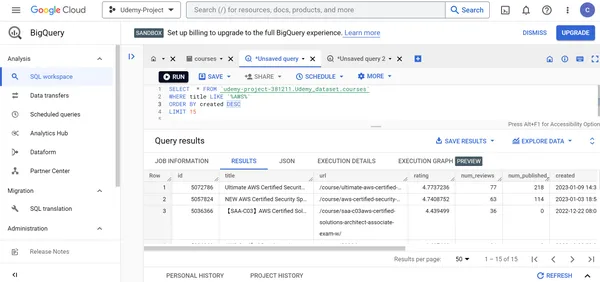
M. Finden Sie die Details der 15 neu erstellten AWS Udemy-Kurse.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%AWS%'
ORDER BY created DESC
LIMIT 15
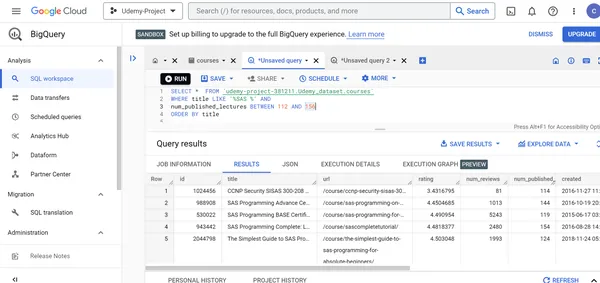
N. Zeigt alle Details der Udemy SAS-Kurse mit Kursvorträgen zwischen 112 und 156 in aufsteigender Reihenfolge des Kurstitels an.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%SAS %' AND
num_published_lectures BETWEEN 112 AND 156
ORDER BY title
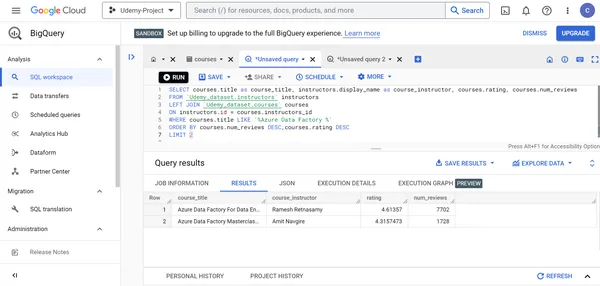
O. Zeigen Sie den Namen, den Titel, die Bewertungen und die Kursbewertungen des Kursleiters der beiden besten Udemy Azure Data Factory-Kurse basierend auf den Kursbewertungen und der Anzahl der Kursbewertungen an.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating, courses.num_reviews
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.title LIKE '%Azure Data Factory %'
ORDER BY courses.num_reviews DESC, courses.rating DESC LIMIT 2
P. Zeigen Sie den Namen, den Titel, die Bewertungen und die Kursbewertungen des Kursleiters des besten Udemy Salesforce-Kurses basierend auf den Kursbewertungen und der Anzahl der Kursbewertungen an.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating, courses.num_reviews
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.title LIKE '%Salesforce %'
ORDER BY courses.num_reviews DESC, courses.rating DESC LIMIT 1
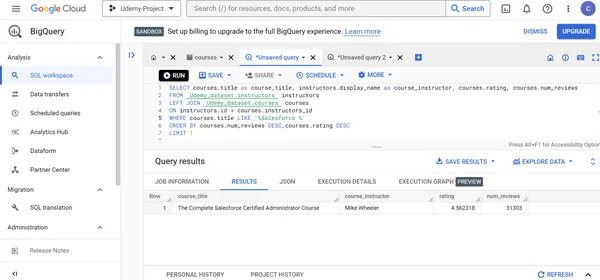
Wichtige Trends und Erkenntnisse, die beim Erkunden der Udemy-Kursdaten entdeckt wurden
Aus dem oben Gesagten wissen wir, wie man ein Data Warehouse zum Erkunden von Udemy-Kurstrends und -erkenntnissen erstellt Große Google-Abfrage. Im Folgenden sind einige wichtige Trends und Erkenntnisse aufgeführt, die beim Erkunden der Udemy-Kursdaten entdeckt wurden:
1. Die beliebtesten JavaScript-Kurse haben eine durchschnittliche Bewertung von mehr als 4.6.
2. Nur 34 Udemy-Kurse werden von Dozenten erstellt, deren Berufsbezeichnung Webentwickler ist und deren Kursbewertungen über 4.2 liegen.
3. Fast 150 Udemy-Kurse werden von AWS-, Azure-, GCP- oder Salesforce-zertifizierten Entwicklern erstellt.
4. Ramesh Retnasamy erstellt den beliebtesten Azure Data Factory-Kurs auf Udemy.
5. Kürzlich erstellte Azure- und AWS-Kurse sind auf Udemy sehr beliebt.
6. Udemy-Nutzer schreiben sich bevorzugt in SAS-Kurse mit etwa 100-150 Vorlesungen mit guten Bewertungen ein.
Zusammenfassung
In diesem Artikel haben wir gesehen, wie man mit Google Big Query ein Data Warehouse erstellt, um Udemy-Kurstrends und -einblicke zu untersuchen. Ein Data Warehouse speichert und analysiert eine große Datenmenge und erzeugt mithilfe von Datenvisualisierungen und Berichten nützliche Dateneinblicke. Wir haben gesehen, wie man eine Tabelle erstellt, indem man Daten aus Kaggle in Google Big Query importiert. Wir wissen auch, wie man Beziehungen zwischen Tabellen herstellt, um Daten besser zu verstehen. Wir haben uns angesehen, wie die Daten mithilfe von Abfragen analysiert werden können, um aussagekräftige Erkenntnisse aus den Daten zu gewinnen. Nachfolgend finden Sie die wichtigsten Erkenntnisse aus dem obigen Artikel:
- Wir haben gesehen, wie wir Tabellen in Google Big Query erstellen können.
- Wir haben verstanden, wie Daten in der SQL-Abfrage-Engine von Big Query abgefragt werden.
- Wir haben auch Einzelheiten zu den Udemy-Kursen ermittelt, die von Personen erstellt wurden, deren Berufsbezeichnung Webentwickler ist und deren Kursbewertungen über 4.2 liegen.
- Wir haben auch gesehen, wie viele Kurse auf Udemy von zertifizierten Entwicklern erstellt werden.
- Die Trends haben wir anhand der neu erstellten Azure- und AWS-Kurse auf Udemy herausgefunden.
- Abgesehen davon haben wir auch andere Kurstrends auf Udemy gesehen, indem wir Udemy-Daten in der SQL-Abfrage-Engine untersucht haben.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/04/exploring-udemy-courses-trends-and-insights-with-google-big-query/

