Einleitung
ChatGPT
In der dynamischen Landschaft moderner Unternehmen hat sich die Schnittstelle zwischen maschinellem Lernen und Betrieb (MLOps) zu einer starken Kraft entwickelt, die traditionelle Ansätze zur Umsatzoptimierung umgestaltet. Der Artikel führt Sie in die transformative Rolle ein, die MLOps-Strategien bei der Revolutionierung des Vertriebserfolgs spielen. Während Unternehmen nach höherer Effizienz und verbesserter Kundeninteraktion streben, steht die Integration maschineller Lerntechniken in den Betrieb im Mittelpunkt. Diese Untersuchung stellt innovative Strategien vor, die MLOps nutzen, um nicht nur Vertriebsprozesse zu optimieren, sondern auch beispiellose Erfolge bei der Umwandlung potenzieller Kunden in treue Kunden zu erzielen. Begleiten Sie uns auf einer Reise durch die Feinheiten von MLOps und entdecken Sie, wie seine strategische Anwendung die Landschaft der Vertriebskonvertierung neu gestaltet.
Lernziele
- Bedeutung des Verkaufsoptimierungsmodells
- Bereinigen von Daten, Transformieren von Datensätzen und Vorverarbeiten von Datensätzen
- Aufbau einer durchgängigen Betrugserkennung mit Kedro und Deepcheck
- Bereitstellen des Modells mit Streamlit und Huggingface
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was ist ein Verkaufsoptimierungsmodell?
Ein Verkaufsoptimierungsmodell ist ein End-to-End-Modell für maschinelles Lernen, um den Verkauf von Produkten zu maximieren und die Konversionsrate zu verbessern. Das Modell verwendet mehrere Parameter als Eingaben wie Impression, Altersgruppe, Geschlecht, Klickrate und Kosten pro Klick. Sobald Sie das Modell trainiert haben, prognostiziert es die Anzahl der Personen, die das Produkt kaufen werden, nachdem sie die Anzeige gesehen haben.
Notwendige Voraussetzungen
1) Klonen Sie das Repository
git clone https://github.com/ashishk831/Final-THC.git
cd Final-THC2) Erstellen und aktivieren Sie die virtuelle Umgebung
#create a virtual environment
python3 -m venv SOP
#Activate your virtual environment in your project folder
source SOP/bin/activate
pip install -r requirements.txt4) Installieren Sie Kedro, Kedro-viz, Streamlit und Deepcheck
pip install streamlit
pip install Deepcheck
pip install Kedro
pip install Kedro-vizDaten Beschreibung
Lassen Sie uns eine grundlegende Datenanalyse mithilfe der Python-Implementierung an einem Datensatz von Kaggle durchführen. Um den Datensatz herunterzuladen, klicken Sie auf .
import pandas as pd
import numpy as np
df = pd.read_csv('KAG_conversion_data.csv')
df.head()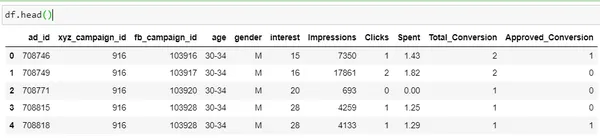
| Kolonne | Beschreibung |
| ad_id | Eine eindeutige ID für jede Anzeige |
| xyz_campaign_id | Eine ID, die jeder Werbekampagne des Unternehmens XYZ zugeordnet ist |
| fb_campaign_id | Eine ID, die damit verknüpft ist, wie Facebook jede Kampagne verfolgt |
| Alter | Alter der Person, der die Anzeige gezeigt wird |
| Geschlecht | Das Geschlecht der Person, die hinzugefügt werden soll, wird angezeigt |
| Interesse | ein Code, der die Kategorie angibt, zu der das Interesse der Person gehört (die Interessen entsprechen den Angaben im öffentlichen Facebook-Profil der Person) |
| Impressionen | die Häufigkeit, mit der die Anzeige angezeigt wurde. |
| Klicks (Clicks) | Anzahl der Klicks auf diese Anzeige. |
| Verbraucht | Betrag, den das Unternehmen xyz an Facebook gezahlt hat, um diese Anzeige anzuzeigen |
| Gesamt Umwandlung |
Gesamt Anzahl der Personen, die sich nach dem Betrachten der Anzeige nach dem Produkt erkundigt haben |
| Genehmigt Umwandlung |
Gesamt Anzahl der Personen, die das Produkt gekauft haben, nachdem sie die Anzeige gesehen haben |
Hier das "Genehmigter Umbau„ist die Zielspalte. Unser
Ziel ist es, ein Modell zu entwerfen, das den Verkauf eines Produkts steigert, sobald es die Leute sehen
die Anzeige.
Modellentwicklung mit Kedro
Für den End-to-End-Aufbau dieses Projekts verwenden wir das Kedro-Tool. Kedro ist ein Open-Source-Tool zum Aufbau eines produktionsreifen Modells für maschinelles Lernen, das eine Reihe von Vorteilen bietet.
- Bewältigt Komplexität: Es bietet eine Struktur zum Testen von Daten, die nach erfolgreichem Testen in die Produktion übertragen werden können.
- Standardisierung: Es stellt eine Standardvorlage für das Projekt bereit. Damit es für andere leichter verständlich wird.
- Produktionsbereit: Code kann mit explorativem Code einfach in die Produktion übertragen werden, sodass Sie ihn in reproduzierbare, wartbare und modulare Experimente umwandeln können.
Weiterlesen: Exemplarische Vorgehensweise des Kedro Framework
Pipeline-Struktur
Um ein Projekt in Kedro zu erstellen, führen Sie die folgenden Schritte aus.
#create project
kedro new
#create pipeline
kedro pipeline create <pipeline-name>
#Run kedro
kedro run
#Visualizing pipeline
kedro vizMit Kedro entwerfen wir die End-to-End-Modellpipeline, die unten gezeigt wird.
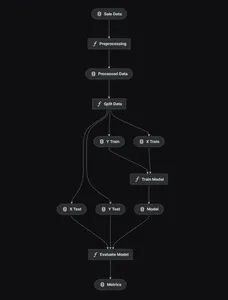
Datenvorverarbeitung
- Suchen Sie nach fehlenden Werten und behandeln Sie diese.
- Erstellen Sie zwei neue Spalten CTR und CPC.
- Spaltenvariable in numerisch umwandeln.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
def preprocessing(data: pd.DataFrame):
data.gender = data.gender.apply(lambda x: 1 if x=="M" else 0)
data['CTR'] = ((data['Clicks']/data['Impressions'])*100)
data['CPC'] = data['Spent']/data['Clicks']
data['CPC'] = data['CPC'].replace(np.nan,0)
encoder=LabelEncoder()
encoder.fit(data["age"])
data["age"]=encoder.transform(data["age"])
#data.Approved_Conversion = data.Approved_Conversion.apply(lambda x: 0 if x==0 else 1)
preprocessed_data = data.copy()
return preprocessed_dataDaten aufteilen
import pandas as pd
from sklearn.model_selection import train_test_split
def split_data(processed_data: pd.DataFrame):
X = processed_data[['ad_id', 'age', 'gender', 'interest', 'Spent',
'Total_Conversion','CTR', 'CPC']]
y = processed_data["Approved_Conversion"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1,
random_state=42)
return X_train, X_test, y_train, y_testOben ist der Datensatz für Modelltrainingszwecke in einen Zugdatensatz und einen Testdatensatz unterteilt.
Modelltraining
from sklearn.ensemble import RandomForestRegressor
def train_model(X_train, y_train):
model = RandomForestRegressor(n_estimators = 50, random_state = 0, max_samples=0.75)
model.fit(X_train, y_train)
return model
Wir werden das Modul „RandomForestRegressor“ verwenden, um das Modell zu trainieren. Allein mit RandomForestRegressor übergeben wir andere Parameter wie n_estimators random_state und max_samples.
Evaluierung
import numpy as np
import logging
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, max_error
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
mse=mean_squared_error(y_test, y_pred)
rmse=np.sqrt(mse)
r2score=r2_score(y_test, y_pred)
me = max_error(y_test, y_pred)
print("MAE Of Model is: ",mae)
print("MSE Of Model is: ",mse)
print("RMSE Of Model is: ",rmse)
print("R2_Score Of Model is: ",r2score)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2score)
return {"r2_score": r2score, "mae": mae, "max_error": me}Sobald das Modell trainiert ist, wird es anhand einer Reihe wichtiger Metriken wie MAE, MSE, RMSE und R2-Score bewertet.
Experiment-Tracker
Um die Modellleistung zu verfolgen und das beste Modell auszuwählen, verwenden wir den Experiment-Tracker. Die Funktionalität des Experiment-Trackers besteht darin, alle Informationen über das Experiment zu speichern, wenn die Anwendung ausgeführt wird. Um den Experiment-Tracker in Kedro zu aktivieren, können wir die Datei „catalog.xml“ aktualisieren. Der Parameter versioned muss auf True gesetzt sein. Unten ist das Beispiel
model:
type: pickle.PickleDataSet
filepath: data/06_models/model.pkl
backend: pickle
versioned: TrueDies hilft bei der Verfolgung des Modellergebnisses und beim Speichern der Modellversion. Hier verwenden wir den Experiment-Tracker im Evaluierungsschritt, um die Modellleistung während der Entwicklungsphase zu verfolgen.
Wenn das Modell ausgeführt wird, generiert es verschiedene Bewertungsmetriken wie MAE, MSE, RMSE und R2-Score für verschiedene Zeitstempel, wie im Bild gezeigt. Auf der Grundlage der oben genannten Bewertungsmetriken kann das beste Modell ausgewählt werden.
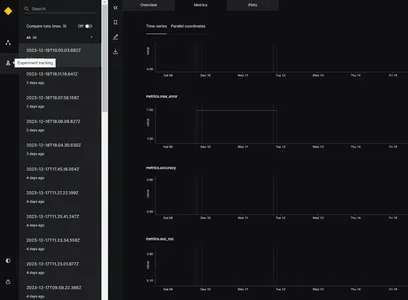
Deepcheck: Für die Daten- und Modellüberwachung
Wenn das Modell in der Produktion eingesetzt wird, besteht die Möglichkeit, dass sich die Datenqualität im Laufe der Zeit ändert und sich dadurch auch die Modellleistung ändern kann. Um dieses Problem zu beheben, müssen wir die Daten in der Produktionsumgebung überwachen. Hierzu verwenden wir das Open-Source-Tool Deepcheck. Deepcheck verfügt über integrierte Bibliotheken wie Label-Drift und Feature-Drift, die problemlos in Modellcode integriert werden können.
- FeatureDrift: – Eine Drift bedeutet eine Änderung der Datenverteilung im Laufe der Zeit, aufgrund derer sich die Modellleistung verschlechtert. FeaturDift bedeutet, dass in einem einzelnen Feature des Datensatzes eine Änderung aufgetreten ist.
- Labeldrift: – Labeldrift tritt auf, wenn sich die Grundwahrheitsbezeichnungen für einen Datensatz im Laufe der Zeit ändern. Dies ist hauptsächlich auf Änderungen der Kennzeichnungskriterien zurückzuführen.
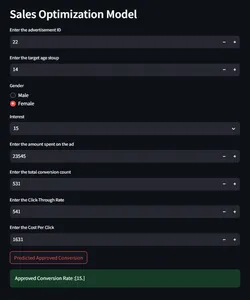
Integration von Modellvorhersage und -überwachung mit Streamlit
Jetzt erstellen wir eine Benutzeroberfläche für die Interaktion mit dem Modell, um anhand der angegebenen Eingabeparameter Vorhersagen zu treffen und die Conversion-Rate zu überprüfen.
import streamlit as st
import pandas as pd
import joblib
import numpy as np
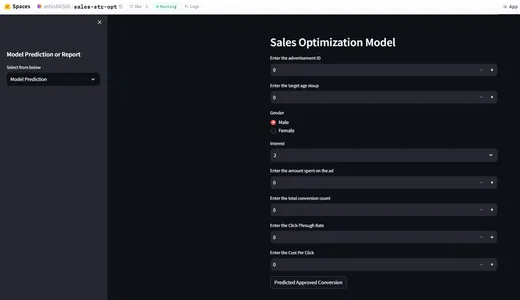
st.sidebar.header("Model Prediction or Report")
selected_report = st.sidebar.selectbox("Select from below", ["Model Prediction",
"Data Integrity","Feature Drift", "Label Drift"])
if selected_report=="Model Prediction":
st.header("Sales Optimization Model")
#def predict(ad_id, age, gender, interest, Impressions, Clicks, Spent,
#Total_Conversion, CTR, CPC):
def predict(ad_id, age, gender, interest, Spent, Total_Conversion, CTR, CPC):
if gender == 'Male':
gender = 0
else:
gender = 1
ad_id = int(ad_id)
age = int(age)
gender = int(gender)
interest = int(interest)
#Impressions = int(Impressions)
#Clicks = int(Clicks)
Spent = float(Spent)
Total_Conversion = int(Total_Conversion)
CTR = float(CTR*0.000001)
CPC = float(CPC)
input=np.array([[ad_id, age, gender, interest, Spent,
Total_Conversion, CTR, CPC]]).astype(np.float64)
model = joblib.load('model/model.pkl')
# Make prediction
prediction = model.predict(input)
prediction= np.round(prediction)
# Return the predicted value for Approved_Conversion
return prediction
ad_id = st.number_input('Enter the advertisement ID',min_value = 0)
age = st.number_input('Enter the target age stoup',min_value = 0)
gender = st.radio("Gender",('Male','Female'))
interest = st.selectbox('Interest', [2, 7, 10, 15, 16, 18, 19, 20, 21, 22, 23,
24, 25,
26, 27, 28, 29, 30, 31, 32, 36, 63, 64, 65, 66, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114])
#Impressions = st.number_input('Enter the number of impressions',min_value = 0)
#Clicks = st.number_input('Enter the number of clicks',min_value = 0)
Spent = st.number_input('Enter the amount spent on the ad',min_value = 0)
Total_Conversion = st.number_input('Enter the total conversion count',
min_value = 0)
CTR = st.number_input('Enter the Click-Through Rate',min_value = 0)
CPC = st.number_input('Enter the Cost Per Click',min_value = 0)
if st.button("Predicted Approved Conversion"):
output = predict(ad_id, age, gender, interest, Spent, Total_Conversion,
CTR, CPC)
st.success("Approved Conversion Rate :{}".format(output))
else:
st.header("Sales Model Monitoring Report")
report_file_name = "report/"+ selected_report.replace(" ", "") + ".html"
HtmlFile = open(report_file_name, 'r', encoding='utf-8')
source_code = HtmlFile.read()
st.components.v1.html(source_code, width=1200, height=1500, scrolling=True)
Bereitstellung mit HuggingFace
Nachdem wir nun ein End-to-End-Verkaufsoptimierungsmodell erstellt haben, werden wir das Modell mit HuggingFace bereitstellen. In Huggingface müssen wir die Datei README.md für die Modellbereitstellung konfigurieren. Huggingface kümmert sich um CI/CD. Bei jeder Änderung in der Datei werden die Änderungen nachverfolgt und die App erneut bereitgestellt. Nachfolgend finden Sie die Konfiguration der Datei readme.md.
title: {{Sale-str-opt}}
emoji: {{Sale-str-opt}}
colorFrom: {{colorFrom}}
colorTo: {{colorTo}}
sdk: {{sdk}}
sdk_version: {{sdkVersion}}
app_file: app.py
pinned: falseHuggingFace-App-Demo
Klicken Sie für die Cloud-Version .
Zusammenfassung
- Apps für maschinelles Lernen können die Testkonversionsrate in unbekannten Märkten ermitteln und Unternehmen dabei helfen, die Produktnachfrage zu ermitteln.
- Mithilfe des Verkaufsoptimierungsmodells können Unternehmen ihre richtige Zielgruppe ansprechen.
- Diese Anwendung trägt dazu bei, den Geschäftsumsatz zu steigern.
- Die Überwachung von Daten in Echtzeit kann auch dabei helfen, Modelländerungen und Änderungen im Benutzerverhalten zu verfolgen.
Häufig gestellte Fragen
A. Der Zweck des Verkaufsoptimierungsmodells besteht darin, die Anzahl der Kunden vorherzusagen, die das Produkt kaufen werden, nachdem sie die Anzeige gesehen haben.
A. Die Überwachung der Daten hilft bei der Verfolgung des Datensatzes und des Modellverhaltens.
A. Ja, die Nutzung von Huggingface ist mit der Grundfunktion 2 vCPU und 16 GB RAM kostenlos.
A. Es gibt keine strengen Regeln für die Auswahl von Berichten in der Modellüberwachungsphase. Deepcheck verfügt über viele integrierte Bibliotheken wie Modelldrift und Verteilungsdrift.
A. Streamlit hilft bei der lokalen Bereitstellung und hilft bei der Behebung von Fehlern während der Entwicklungsphase.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/01/mlops-strategies-for-sales-conversion-success/

