Einleitung
„Weniger ist mehr“, wie der Architekt Ludwig Mies van der Rohe berühmt sagte, und das ist es, was Zusammenfassung bedeutet. Zusammenfassungen sind ein entscheidendes Werkzeug, um umfangreiche Textinhalte in prägnante, relevante Häppchen zu zerlegen, die dem schnellen Informationskonsum von heute gerecht werden. In Textanwendungen erleichtert die Zusammenfassung das Auffinden von Informationen und unterstützt die Entscheidungsfindung. Die Integration generativer KI, wie z. B. OpenAI GPT-3-basierter Modelle, hat diesen Prozess revolutioniert, indem nicht nur Schlüsselelemente aus Texten extrahiert und kohärente Zusammenfassungen generiert werden, die das Wesentliche der Quelle bewahren. Interessanterweise reichen die Fähigkeiten der generativen KI über die Text- bis hin zur Videozusammenfassung hinaus. Dabei werden zentrale Szenen, Dialoge und Konzepte aus Videos extrahiert und gekürzte Darstellungen des Inhalts erstellt. Sie können eine Videozusammenfassung auf viele verschiedene Arten erreichen, einschließlich der Erstellung eines kurzen Zusammenfassungsvideos, der Durchführung einer Videoinhaltsanalyse und der Hervorhebung wichtiger Abschnitte des Videos oder der Erstellung einer Textzusammenfassung des Videos mithilfe der Videotranskription
Die Open AI Whisper API nutzt die automatische Spracherkennungstechnologie, um gesprochene Sprache in geschriebenen Text umzuwandeln und so die Genauigkeit und Effizienz der Textzusammenfassung zu erhöhen. Andererseits stellt die Hugging Face Chat API modernste Sprachmodelle wie GPT-3 bereit.
Lernziele
In diesem Artikel erfahren wir mehr über:
- Wir lernen Techniken zur Videozusammenfassung kennen
- Verstehen Sie die Anwendungen der Videozusammenfassung
- Entdecken Sie die Modellarchitektur von Open AI Whisper
- Erfahren Sie, wie Sie die Videotextzusammenfassung mithilfe der Open AI Whisper- und Hugging Chat-API implementieren
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Video-Zusammenfassungstechniken
Videoanalyse
Dabei geht es darum, aussagekräftige Informationen aus einem Video zu extrahieren. Verwenden tiefe Lernen um Objekte und Aktionen in einem Video zu verfolgen und zu identifizieren und die Szenen zu identifizieren. Einige der beliebtesten Techniken zur Videozusammenfassung sind:
Keyframe-Extraktion und Aufnahmegrenzenerkennung
Dieser Vorgang umfasst die Konvertierung des Videos in eine begrenzte Anzahl von Standbildern. Video Skim ist ein anderer Begriff für dieses kürzere Video mit Keyshots.
Videoaufnahmen sind ununterbrochene Serien von Einzelbildern. Die Aufnahmegrenzenerkennung erkennt Übergänge zwischen Aufnahmen, wie Schnitte, Überblendungen oder Überblendungen, und wählt Einzelbilder aus jeder Aufnahme aus, um eine Zusammenfassung zu erstellen. Im Folgenden sind die wichtigsten Schritte aufgeführt, um aus einem längeren Video eine fortlaufende kurze Videozusammenfassung zu extrahieren:
- Frame-Extraktion – Der Schnappschuss des Videos wird aus dem Video extrahiert. Für ein 1-fps-Video können wir 30 Bild pro Sekunde verwenden.
- Gesichts- und Emotionserkennung – Anschließend können wir Gesichter aus Videos extrahieren und die Emotionen der Gesichter bewerten, um Emotionsbewertungen zu ermitteln. Gesichtserkennung mittels SSD (Single Shot Multibox Detector).
- Rahmenranking und -auswahl – Wählen Sie Frames aus, die einen hohen Emotionswert haben, und ordnen Sie sie dann ein.
- Endgültige Extraktion – Wir extrahieren Untertitel zusammen mit Zeitstempeln aus dem Video. Anschließend extrahieren wir die Sätze, die den oben ausgewählten extrahierten Frames entsprechen, zusammen mit ihren Start- und Endzeiten im Video. Schließlich führen wir die diesen Intervallen entsprechenden Videoteile zusammen, um das endgültige zusammenfassende Video zu generieren.
Aktionserkennung und zeitliche Unterabtastung
Dabei versuchen wir, im Video ausgeführte menschliche Handlungen zu identifizieren. Dies ist eine weit verbreitete Anwendung der Videoanalyse. Wir zerlegen das Video in kleine Teilsequenzen statt in Einzelbilder und versuchen, die im Segment ausgeführte Aktion mithilfe von Klassifizierungs- und Mustererkennungstechniken wie HMC (Hidden Markov Chain Analysis) abzuschätzen.
Einzel- und multimodale Ansätze
In diesem Artikel haben wir einen einzelmodalen Ansatz verwendet, bei dem wir den Ton des Videos verwenden, um eine Zusammenfassung des Videos mithilfe einer Textzusammenfassung zu erstellen. Hier verwenden wir a
Ein einzelner Aspekt des Videos, nämlich Audio, wird in Text umgewandelt und dann anhand dieses Textes eine Zusammenfassung erstellt.
Im multimodalen Ansatz kombinieren wir Informationen aus vielen Modalitäten wie Audio, Bild und Text und liefern ein ganzheitliches Wissen über den Videoinhalt für eine genauere Zusammenfassung.
Anwendungen der Videozusammenfassung
Bevor wir uns mit der Implementierung unserer Videozusammenfassung befassen, sollten wir zunächst die Anwendungen der Videozusammenfassung kennen. Nachfolgend finden Sie einige der aufgeführten Beispiele für Videozusammenfassungen in verschiedenen Bereichen und Bereichen:
- Sicherheit und Überwachung: Durch die Videozusammenfassung können wir große Mengen an Überwachungsvideos analysieren, um wichtige Ereignisse hervorzuheben, ohne das Video manuell überprüfen zu müssen
- Schul-und Berufsbildung: Man kann Schlüsselnotizen und Schulungsvideos liefern, sodass die Schüler die Videoinhalte noch einmal durcharbeiten können, ohne das gesamte Video durchgehen zu müssen.
- Durchsuchen von Inhalten: YouTube verwendet dies, um wichtige Teile des Videos hervorzuheben, die für die Benutzersuche relevant sind, damit Benutzer anhand ihrer Suchanforderungen entscheiden können, ob sie dieses bestimmte Video ansehen möchten oder nicht.
- Katastrophenmanagement: Bei Notfällen und Krisen können durch die Videozusammenfassung Maßnahmen auf der Grundlage der in der Videozusammenfassung hervorgehobenen Situationen ergriffen werden.
Öffnen Sie die Übersicht über das AI Whisper-Modell
Das Whisper-Modell von Open AI ist eine automatische Spracherkennung (ASR). Es wird zum Transkribieren von Sprachaudio in Text verwendet.
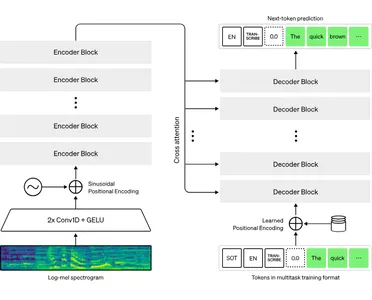
Es basiert auf der Transformer-Architektur, die Encoder- und Decoderblöcke mit einem Aufmerksamkeitsmechanismus stapelt, der Informationen zwischen ihnen weitergibt. Dabei wird die Audioaufnahme in 30-sekündige Abschnitte aufgeteilt und jeder einzelne einzeln verarbeitet. Bei jeder 30-Sekunden-Aufnahme kodiert der Encoder die Audiodaten und speichert die Position jedes angegebenen Wortes. Der Decoder verwendet diese kodierten Informationen, um zu bestimmen, was gesagt wurde.
Der Decoder erwartet von all diesen Informationen Token, bei denen es sich im Grunde um jedes ausgesprochene Wort handelt. Anschließend wird dieser Vorgang für das folgende Wort wiederholt, wobei dieselben Informationen verwendet werden, um das nächste Wort zu identifizieren, das mehr Sinn ergibt.

Codierungsbeispiel für die Videotextzusammenfassung

1 – Bibliotheken installieren und laden
!pip install yt-dlp openai-whisper hugchat
import yt_dlp
import whisper
from hugchat import hugchat
#Function for saving audio from input video id of youtube
def download(video_id: str) -> str: video_url = f'https://www.youtube.com/watch?v={video_id}' ydl_opts = { 'format': 'm4a/bestaudio/best', 'paths': {'home': 'audio/'}, 'outtmpl': {'default': '%(id)s.%(ext)s'}, 'postprocessors': [{ 'key': 'FFmpegExtractAudio', 'preferredcodec': 'm4a', }] } with yt_dlp.YoutubeDL(ydl_opts) as ydl: error_code = ydl.download([video_url]) if error_code != 0: raise Exception('Failed to download video') return f'audio/{video_id}.m4a' #Call function with video id
file_path = download('A_JQK_k4Kyc&t=99s')
3 – Transkribieren Sie Audio mit Whisper in Text
# Load whisper model
whisper_model = whisper.load_model("tiny") # Transcribe audio function
def transcribe(file_path: str) -> str: # `fp16` defaults to `True`, which tells the model to attempt to run on GPU. transcription = whisper_model.transcribe(file_path, fp16=False) return transcription['text'] #Call the transcriber function with file path of audio transcript = transcribe('/content/audio/A_JQK_k4Kyc.m4a')
print(transcript)4 – Fassen Sie transkribierten Text mit Hugging Chat zusammen
Hinweis: Um die Hugging-Chat-API nutzen zu können, müssen wir uns bei Hugging Face anmelden oder registrieren Plattform. Danach müssen wir anstelle von „Benutzername“ und „Passwort“ unsere Anmeldeinformationen für das Umarmungsgesicht eingeben.
from hugchat.login import Login # login
sign = Login("username", "password")
cookies = sign.login()
sign.saveCookiesToDir("/content") # load cookies from usercookies
cookies = sign.loadCookiesFromDir("/content") # This will detect if the JSON file exists, return cookies if it does and raise an Exception if it's not. # Create a ChatBot
chatbot = hugchat.ChatBot(cookies=cookies.get_dict()) # or cookie_path="usercookies/<email>.json"
print(chatbot.chat("Hi!")) #Summarise Transcript
print(chatbot.chat('''Summarize the following :-'''+transcript))Zusammenfassung
Zusammenfassend lässt sich sagen, dass das Konzept der Zusammenfassung eine transformative Kraft im Informationsmanagement ist. Es handelt sich um ein leistungsstarkes Tool, das umfangreiche Inhalte in prägnante, aussagekräftige Formen umwandelt, die auf den schnelllebigen Konsum der heutigen Welt zugeschnitten sind.
Durch die Integration generativer KI-Modelle wie GPT-3 von OpenAI hat die Zusammenfassung ihre traditionellen Grenzen überschritten und sich zu einem Prozess entwickelt, der nicht nur kohärente und kontextgenaue Zusammenfassungen extrahiert, sondern diese auch generiert.
Die Reise in die Videozusammenfassung zeigt ihre Relevanz für verschiedene Sektoren. Die Implementierung, wie Audioextraktion, Transkription mit Whisper und Zusammenfassung mit Hugging Face Chat nahtlos integriert werden können, um Videotextzusammenfassungen zu erstellen.
Key Take Away
1. Generative KI: Die Zusammenfassung von Videos kann mithilfe generativer KI-Technologien wie LLMs und ASR erreicht werden.
2. Anwendungen in bestimmten Bereichen: Die Zusammenfassung von Videos ist tatsächlich in vielen wichtigen Bereichen von Vorteil, in denen man große Mengen an Videos analysieren muss, um wichtige Informationen zu gewinnen.
3. Grundlegende Implementierung: In diesem Artikel haben wir die grundlegende Code-Implementierung der Videozusammenfassung basierend auf der Audiodimension untersucht.
4. Modellarchitektur: Wir haben auch etwas über die grundlegende Architektur des Open AI Whisper-Modells und seinen Prozessablauf gelernt.
Häufig gestellte Fragen
A. Das Limit für Whisper-API-Aufrufe beträgt 50 pro Minute. Es gibt keine Begrenzung der Audiolänge, aber Dateien bis zu 25 MB können nur geteilt werden. Man kann die Dateigröße von Audio reduzieren, indem man die Bitrate des Audios verringert.
A. Die folgenden Dateiformate: m4a, mp3, webm, mp4, mpga, wav, mpeg
A. Einige der wichtigsten Alternativen für die automatische Spracherkennung sind: Twilio Voice, Deepgram, Azure Speech-to-Text, Google Cloud Speech-to-Text.
A. Einer der Gründe ist die Schwierigkeit, unterschiedliche Akzente derselben Sprache zu verstehen, und die Notwendigkeit spezieller Schulungsanwendungen in speziellen Bereichen.
A. Auf dem Gebiet der Spracherkennung wird derzeit fortgeschrittene Forschung betrieben, etwa die Dekodierung eingebildeter Sprache aus EEG-Signalen mithilfe neuronaler Architektur. Dies ermöglicht den Menschen
Menschen mit Sprachbehinderungen können ihre Sprachgedanken mit Hilfe von Geräten der Außenwelt mitteilen. Ein solch interessantes Papier hier.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- ChartPrime. Verbessern Sie Ihr Handelsspiel mit ChartPrime. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/09/video-summarization-using-openai-whisper-and-hugging-chat-api/

