Einleitung
Data Science ist ein schnell wachsendes Gebiet, das die Art und Weise verändert, wie Unternehmen ihre Daten verstehen und Entscheidungen auf der Grundlage ihrer Daten treffen. Infolgedessen suchen Unternehmen zunehmend nach Data Scientists, die ihnen helfen, ihre Daten zu verstehen und Geschäftsergebnisse zu verbessern. Dies hat zu einer hohen Nachfrage nach Datenwissenschaftlern geführt, und der Wettbewerb um diese Positionen kann hart sein. Um Ihnen bei der Vorbereitung auf ein Data-Science-Interview zu helfen, haben wir eine Liste der 100 wichtigsten Fragen in Data-Science-Interviews zusammengestellt, auf die Sie wahrscheinlich stoßen werden.
Die Fragen, die wir aufgenommen haben, decken ein breites Themenspektrum ab, darunter:
- Python-Interviewfragen
- Interviewfragen zur explorativen Datenanalyse
- Fragen zu Wahrscheinlichkeits- und Statistikinterviews
- Fragen zum maschinellen Lernen im Vorstellungsgespräch
Jede Interviewfrage enthält eine kurze Erläuterung der wichtigsten Konzepte und Fähigkeiten, die getestet werden, sowie Tipps zur Herangehensweise und Beantwortung der Frage. Indem Sie sich mit diesen Fragen vertraut machen und Ihre Antworten üben, sind Sie mit diesen Data-Science-Interviewfragen gut auf Ihr nächstes Vorstellungsgespräch vorbereitet.
Interviewfragen zu Python
Fragen im Vorstellungsgespräch für Anfänger
Q1. Was ist schneller, Python-Liste oder Numpy-Arrays, und warum?
Antwort. NumPy-Arrays sind für numerische Operationen schneller als Python-Listen. NumPy ist eine Bibliothek zum Arbeiten mit Arrays in Python und bietet eine Reihe von Funktionen zum effizienten Ausführen von Operationen an Arrays.
Ein Grund, warum NumPy-Arrays schneller sind als Python-Listen, ist, dass NumPy-Arrays in C implementiert sind, während Python-Listen in Python implementiert sind. Das bedeutet, dass Operationen auf NumPy-Arrays in einer kompilierten Sprache implementiert werden, was sie schneller macht als Operationen auf Python-Listen, die in einer interpretierten Sprache implementiert sind.
Q2. Was ist der Unterschied zwischen einer Python-Liste und einem Tupel?
Antwort. In Python ist eine Liste eine geordnete Sammlung von Objekten, die unterschiedlichen Typs sein können. Listen sind änderbar, was bedeutet, dass Sie den Wert eines Listenelements ändern oder Elemente zu einer Liste hinzufügen oder entfernen können. Listen werden mit eckigen Klammern und einer durch Kommas getrennten Werteliste erstellt.
Ein Tupel ist ebenfalls eine geordnete Sammlung von Objekten, aber es ist unveränderlich, was bedeutet, dass Sie den Wert eines Tupelelements nicht ändern oder Elemente aus einem Tupel hinzufügen oder entfernen können.
Listen werden mit eckigen Klammern ([ '' ]) definiert, während Tupel mit runden Klammern (('', )) definiert werden.
Listen haben mehrere eingebaute Methoden zum Hinzufügen, Entfernen und Bearbeiten von Elementen, während Tupel diese Methoden nicht haben.
Im Allgemeinen sind Tupel schneller als Listen in Python
Q3. Was sind Python-Sets? Erklären Sie einige Eigenschaften von Mengen.
Antwort. In Python ist eine Menge eine ungeordnete Sammlung eindeutiger Objekte. Sätze werden häufig verwendet, um eine Sammlung unterschiedlicher Objekte zu speichern und Zugehörigkeitstests durchzuführen (dh um zu prüfen, ob ein Objekt in dem Satz enthalten ist). Sätze werden mit geschweiften Klammern ({ und }) und einer durch Kommas getrennten Werteliste definiert.
Hier sind einige Schlüsseleigenschaften von Mengen in Python:
- Sätze sind ungeordnet: Sätze haben keine bestimmte Reihenfolge, daher können Sie sie nicht wie Listen oder Tupel indizieren oder aufteilen.
- Sätze sind eindeutig: Sätze erlauben nur eindeutige Objekte. Wenn Sie also versuchen, einem Satz ein doppeltes Objekt hinzuzufügen, wird es nicht hinzugefügt.
- Sätze sind veränderlich: Sie können Elemente mit den Methoden add und remove zu einem Satz hinzufügen oder daraus entfernen.
- Sets werden nicht indiziert: Sets unterstützen keine Indizierung oder Aufteilung, sodass Sie nicht über einen Index auf einzelne Elemente eines Sets zugreifen können.
- Sätze sind nicht hashfähig: Sätze sind veränderlich, können also nicht als Schlüssel in Wörterbüchern oder als Elemente in anderen Sätzen verwendet werden. Wenn Sie ein veränderliches Objekt als Schlüssel oder Element in einer Menge verwenden müssen, können Sie ein Tupel oder eine eingefrorene Menge (eine unveränderliche Version einer Menge) verwenden.
Q4. Was ist der Unterschied zwischen Split und Join?
Antwort. Split und Join sind beides Funktionen von Python-Strings, aber sie sind völlig unterschiedlich, wenn es um die Funktionsweise geht.
Die Split-Funktion wird verwendet, um eine Liste aus Zeichenfolgen basierend auf einem Trennzeichen zu erstellen, z. Platz.
Z.B. a = 'Dies ist eine Zeichenkette'
Li = a.split(' ')
Ausgabe – ['This', 'is', 'a', 'string']
Die join()-Methode ist eine eingebaute Funktion der str-Klasse von Python, die eine Liste von Strings zu einem einzigen String verkettet. Es wird auf einer Trennzeichenfolge aufgerufen und mit einer Liste von zu verbindenden Zeichenfolgen aufgerufen. Die Trennzeichenfolge wird zwischen jeder Zeichenfolge in der Liste eingefügt, wenn die Zeichenfolgen verkettet werden.
Hier ist ein Beispiel für die Verwendung der Methode join():
Eg. „ „.join(li)
Ausgabe – Dies ist eine Zeichenfolge
Hier wird die Liste mit einem Leerzeichen dazwischen verbunden.
Q5. Erklären Sie die logischen Operationen in Python.
Antwort. In Python können die logischen Operationen and, or und not verwendet werden, um boolesche Operationen mit Wahrheitswerten (True und False) durchzuführen.
Der and-Operator gibt True zurück, wenn beide Operanden True sind, andernfalls False.
Der or-Operator gibt True zurück, wenn einer der Operanden True ist, und False, wenn beide Operanden False sind.
Der not-Operator invertiert den booleschen Wert seines Operanden. Wenn der Operand True ist, wird kein False zurückgegeben, und wenn der Operand False ist, wird kein True zurückgegeben.
Q6. Erklären Sie die 5 wichtigsten Funktionen, die für Python-Strings verwendet werden.
Antwort. Hier sind die Top 5 Python-String-Funktionen:
- len(): Diese Funktion gibt die Länge eines Strings zurück.
s = 'Hallo, Welt!'
Linse)
13
- strip(): Diese Funktion entfernt führende und abschließende Leerzeichen aus einem String.
s = 'Hallo, Welt! '
s.streifen()
'Hallo Welt!'
- split(): Diese Funktion teilt einen String basierend auf einem Trennzeichen in eine Liste von Teilstrings auf.
s = 'Hallo, Welt!'
s.split(',')
['Hallo Welt!']
- replace(): Diese Funktion ersetzt alle Vorkommen einer angegebenen Zeichenfolge durch eine andere Zeichenfolge.
s = 'Hallo, Welt!'
s.replace('Welt', 'Universum')
'Hallo, Universum!'
- upper() und lower(): Diese Funktionen wandeln einen String in Groß- bzw. Kleinbuchstaben um.
s = 'Hallo, Welt!'
Abendessen()
'HALLO WELT!'
Langsamer()
'Hallo Welt!'
F7. Was ist die Verwendung des Pass-Schlüsselworts in Python?
Antwort. pass ist eine Null-Anweisung, die nichts bewirkt. Es wird oft als Platzhalter verwendet, wenn eine Anweisung syntaktisch erforderlich ist, aber keine Aktion ausgeführt werden muss. Wenn Sie beispielsweise eine Funktion oder eine Klasse definieren möchten, sich aber noch nicht entschieden haben, was sie tun soll, können Sie pass als Platzhalter verwenden.
Q8. Wozu dient das Continue-Schlüsselwort in Python?
Antwort. Continue wird in einer Schleife verwendet, um die aktuelle Iteration zu überspringen und mit der nächsten fortzufahren. Wenn Continue angetroffen wird, wird die aktuelle Iteration der Schleife beendet und die nächste beginnt.
Intermediate Fragen im Vorstellungsgespräch
Q9. Was sind unveränderliche und veränderliche Datentypen?
Antwort. In Python ist ein unveränderliches Objekt ein Objekt, dessen Zustand nach seiner Erstellung nicht geändert werden kann. Das bedeutet, dass Sie den Wert eines unveränderlichen Objekts nach seiner Erstellung nicht mehr ändern können. Beispiele für unveränderliche Objekte in Python sind Zahlen (z. B. Ganzzahlen, Gleitkommazahlen und komplexe Zahlen), Zeichenfolgen und Tupel.
Andererseits ist ein änderbares Objekt ein Objekt, dessen Zustand geändert werden kann, nachdem es erstellt wurde. Das bedeutet, dass Sie den Wert eines veränderlichen Objekts ändern können, nachdem es erstellt wurde. Beispiele für veränderliche Objekte in Python sind Listen und Wörterbücher.
Es ist wichtig, den Unterschied zwischen unveränderlichen und veränderlichen Objekten in Python zu verstehen, da er sich darauf auswirken kann, wie Sie Daten in Ihrem Code verwenden und bearbeiten. Wenn Sie beispielsweise eine Liste mit Zahlen haben und die Liste in aufsteigender Reihenfolge sortieren möchten, können Sie dazu die integrierte Methode sort() verwenden. Wenn Sie jedoch ein Zahlentupel haben, können Sie die Methode sort() nicht verwenden, da Tupel unveränderlich sind. Stattdessen müssten Sie aus dem ursprünglichen Tupel ein neues sortiertes Tupel erstellen.
Q10. Was ist die Verwendung von Try and Accept-Block in Python?
Antwort. Der Try- und Except-Block in Python werden verwendet, um Ausnahmen zu behandeln. Eine Ausnahme ist ein Fehler, der während der Ausführung eines Programms auftritt.
Der try-Block enthält Code, der möglicherweise eine Ausnahme auslöst. Der Except-Block enthält Code, der ausgeführt wird, wenn während der Ausführung des Try-Blocks eine Ausnahme ausgelöst wird.
Die Verwendung eines Try-Except-Blocks rettet den Code vor dem Auftreten eines Fehlers und kann mit einer gewünschten Nachricht oder Ausgabe im Except-Block ausgeführt werden.
Q11. Was sind 2 veränderliche und 2 unveränderliche Datentypen in Python?
Antwort. 2 veränderliche Datentypen sind –
- Wörterbuch
- Liste
Sie können die Werte in einem Python-Wörterbuch und einer Liste ändern/bearbeiten. Es ist nicht erforderlich, eine neue Liste zu erstellen, was bedeutet, dass sie die Eigenschaft der Veränderlichkeit erfüllt.
2 unveränderliche Datentypen sind:
- Tupel
- Schnur
Sie können eine Zeichenfolge oder einen Wert in einem Tupel nicht bearbeiten, nachdem es erstellt wurde. Sie müssen dem Tupel entweder die Werte zuweisen oder ein neues Tupel erstellen.
Q12. Was sind Python-Funktionen und wie helfen sie bei der Code-Optimierung?
Antwort. In Python ist eine Funktion ein Codeblock, der von anderen Teilen Ihres Programms aufgerufen werden kann. Funktionen sind nützlich, weil sie es Ihnen ermöglichen, Code wiederzuverwenden und Ihren Code in logische Blöcke zu unterteilen, die separat getestet und gewartet werden können.
Um eine Funktion in Python aufzurufen, verwenden Sie einfach den Funktionsnamen, gefolgt von einem Klammerpaar und allen erforderlichen Argumenten. Die Funktion kann einen Wert zurückgeben oder nicht, der von der Verwendung der turn-Anweisung abhängt.
Funktionen können auch bei der Codeoptimierung helfen:
- Wiederverwendung von Code: Mit Funktionen können Sie Code wiederverwenden, indem Sie ihn an einer einzigen Stelle kapseln und mehrmals aus verschiedenen Teilen Ihres Programms aufrufen. Dies kann dazu beitragen, Redundanzen zu reduzieren und Ihren Code prägnanter und einfacher zu warten.
- Verbesserte Lesbarkeit: Durch die Unterteilung Ihres Codes in logische Blöcke können Funktionen Ihren Code lesbarer und leichter verständlich machen. Dies kann es einfacher machen, Fehler zu identifizieren und Änderungen an Ihrem Code vorzunehmen.
- Einfacheres Testen: Mit Funktionen können Sie einzelne Codeblöcke separat testen, was das Auffinden und Beheben von Fehlern erleichtern kann.
- Verbesserte Leistung: Funktionen können auch dazu beitragen, die Leistung Ihres Codes zu verbessern, indem Sie es Ihnen ermöglichen, optimierte Codebibliotheken zu verwenden, oder indem Sie dem Python-Interpreter ermöglichen, den Code effektiver zu optimieren.
Q13. Warum erfreut sich NumPy im Bereich Data Science großer Beliebtheit?
Antwort. NumPy (kurz für Numerical Python) ist eine beliebte Bibliothek für wissenschaftliches Rechnen in Python. Es hat in der Data-Science-Community große Popularität erlangt, da es schnelle und effiziente Tools für die Arbeit mit großen Arrays und Matrizen numerischer Daten bietet.
NumPy bietet schnelle und effiziente Operationen auf Arrays und Matrizen numerischer Daten. Es verwendet optimierten C- und Fortran-Code hinter den Kulissen, um diese Operationen auszuführen, wodurch sie viel schneller sind als entsprechende Operationen, die die integrierten Datenstrukturen von Python verwenden. Es bietet schnelle und effiziente Werkzeuge für die Arbeit mit großen Arrays und Matrizen numerischer Daten.
NumPy bietet eine große Anzahl von Funktionen zur Durchführung mathematischer und statistischer Operationen an Arrays und Matrizen.
Es ermöglicht Ihnen, effizient mit großen Datenmengen zu arbeiten. Es bietet Tools zum Umgang mit großen Datensätzen, die nicht in den Speicher passen würden, z. B. Funktionen zum Lesen und Schreiben von Daten auf die Festplatte und zum Laden von jeweils nur einem Teil eines Datensatzes in den Speicher.
NumPy lässt sich gut in andere Bibliotheken für wissenschaftliches Rechnen in Python integrieren, wie z. B. SciPy (Scientific Python) und Pandas. Dies macht es einfach, NumPy mit anderen Bibliotheken zu verwenden, um komplexere Data-Science-Aufgaben auszuführen.
F14. Erklären Sie das Listenverständnis und das Diktatverständnis.
Antwort. List Comprehension und Diction Comprehension sind beides prägnante Methoden, um neue Listen oder Wörterbücher aus bestehenden Iterables zu erstellen.
List Comprehension ist eine prägnante Möglichkeit, eine Liste zu erstellen. Es besteht aus eckigen Klammern, die einen Ausdruck enthalten, gefolgt von einer for-Klausel, dann null oder mehr for- oder if-Klauseln. Das Ergebnis ist eine neue Liste, die den Ausdruck im Kontext der for- und if-Klauseln auswertet.
Dict Comprehension ist eine prägnante Möglichkeit, ein Wörterbuch zu erstellen. Es besteht aus geschweiften Klammern, die ein Schlüssel-Wert-Paar enthalten, gefolgt von einer for-Klausel, dann null oder mehr for- oder if-Klauseln. Ein Ergebnis ist ein neues Wörterbuch, das das Schlüssel-Wert-Paar im Kontext der for- und if-Klauseln auswertet.
Q15. Was sind globale und lokale Variablen in Python?
Antwort. In Python ist eine Variable, die außerhalb einer Funktion oder Klasse definiert ist, eine globale Variable, während eine Variable, die innerhalb einer Funktion oder Klasse definiert ist, eine lokale Variable ist.
Auf eine globale Variable kann von überall im Programm zugegriffen werden, einschließlich innerhalb von Funktionen und Klassen. Auf eine lokale Variable kann jedoch nur innerhalb der Funktion oder Klasse zugegriffen werden, in der sie definiert ist.
Es ist wichtig zu beachten, dass Sie denselben Namen für eine globale Variable und eine lokale Variable verwenden können, aber die lokale Variable hat innerhalb der Funktion oder Klasse, in der sie definiert ist, Vorrang vor der globalen Variable.
# Dies ist eine globale Variable
x = 10
def func():
# Dies ist eine lokale Variable
x = 5
print(x)my_function
func()
print (x)
Ausgabe – Dies wird 5 und dann 10 drucken
Im obigen Beispiel ist die x-Variable in der Funktion func() eine lokale Variable, daher hat sie Vorrang vor der globalen Variablen x. Wenn also x innerhalb der Funktion ausgegeben wird, wird 5 ausgegeben; Wenn es außerhalb der Funktion gedruckt wird, wird 10 gedruckt.
Q16. Was ist ein geordnetes Wörterbuch?
Antwort. Ein geordnetes Wörterbuch, auch OrderedDict genannt, ist eine Unterklasse der integrierten Python-Wörterbuchklasse, die die Reihenfolge der hinzugefügten Elemente beibehält. In einem normalen Wörterbuch wird die Reihenfolge der Elemente durch die Hash-Werte ihrer Schlüssel bestimmt, die sich im Laufe der Zeit ändern können, wenn das Wörterbuch wächst und sich weiterentwickelt. Ein geordnetes Wörterbuch hingegen verwendet eine doppelt verknüpfte Liste, um sich an die Reihenfolge der Elemente zu erinnern, sodass die Reihenfolge der Elemente unabhängig davon beibehalten wird, wie sich das Wörterbuch ändert.
Q17. Was ist der Unterschied zwischen Return- und Yield-Keywords?
Antwort. Return wird verwendet, um eine Funktion zu verlassen und einen Wert an den Aufrufer zurückzugeben. Wenn eine return-Anweisung auftritt, wird die Funktion sofort beendet, und der Wert des Ausdrucks nach der return-Anweisung wird an den Aufrufer zurückgegeben.
yield hingegen wird verwendet, um eine Generatorfunktion zu definieren. Eine Generatorfunktion ist eine spezielle Art von Funktion, die eine Folge von Werten nacheinander erzeugt, anstatt einen einzelnen Wert zurückzugeben. Wenn auf eine yield-Anweisung gestoßen wird, erzeugt die Generatorfunktion einen Wert und setzt ihre Ausführung aus, wobei sie ihren Status für später speichert
Erweiterte Interviewfragen
Q18. Was sind Lambda-Funktionen in Python und warum sind sie wichtig?
Antwort. In Python ist eine Lambda-Funktion eine kleine anonyme Funktion. Sie können Lambda-Funktionen verwenden, wenn Sie eine Funktion nicht mit dem Schlüsselwort def definieren möchten.
Lambda-Funktionen sind nützlich, wenn Sie eine kleine Funktion für kurze Zeit benötigen. Sie werden oft in Kombination mit Funktionen höherer Ordnung wie map(), filter() und Reduce() verwendet.
Hier ist ein Beispiel für eine Lambda-Funktion in Python:
x = Lambda a : a + 10
x (5)
15
In diesem Beispiel nimmt die Lambda-Funktion ein Argument (a) und fügt ihm 10 hinzu. Die Lambda-Funktion gibt das Ergebnis dieser Operation zurück, wenn sie aufgerufen wird.
Lambda-Funktionen sind wichtig, weil sie es Ihnen ermöglichen, kleine anonyme Funktionen auf prägnante Weise zu erstellen. Sie werden häufig in der funktionalen Programmierung verwendet, einem Programmierparadigma, das den Schwerpunkt auf die Verwendung von Funktionen zur Lösung von Problemen legt.
Q19. Was ist die Verwendung des Schlüsselworts „assert“ in Python?
Antwort. In Python wird die assert-Anweisung verwendet, um eine Bedingung zu testen. Wenn die Bedingung wahr ist, fährt das Programm mit der Ausführung fort. Wenn die Bedingung falsch ist, löst das Programm eine AssertionError-Ausnahme aus.
Die Assert-Anweisung wird häufig verwendet, um die interne Konsistenz eines Programms zu überprüfen. Beispielsweise können Sie eine Assert-Anweisung verwenden, um zu überprüfen, ob eine Liste sortiert ist, bevor Sie eine binäre Suche in der Liste durchführen.
Es ist wichtig zu beachten, dass die assert-Anweisung zu Debugging-Zwecken verwendet wird und nicht dazu gedacht ist, Laufzeitfehler zu behandeln. Im Produktionscode sollten Sie Try- und Except-Blöcke verwenden, um Ausnahmen zu behandeln, die zur Laufzeit ausgelöst werden könnten.
Q20. Was sind Dekorateure in Python?
Antwort. In Python sind Decorators eine Möglichkeit, die Funktionalität einer Funktion, Methode oder Klasse zu ändern oder zu erweitern, ohne ihren Quellcode zu ändern. Decorators werden normalerweise als Funktionen implementiert, die eine andere Funktion als Argument annehmen und eine neue Funktion zurückgeben, die das gewünschte Verhalten aufweist.
Ein Decorator ist eine spezielle Funktion, die mit dem @-Symbol beginnt und unmittelbar vor der Funktion, Methode oder Klasse platziert wird, die sie dekoriert. Das @-Symbol wird verwendet, um anzuzeigen, dass die folgende Funktion ein Dekorierer ist.
Interviewfragen zu EDA und Statistik
Fragen im Vorstellungsgespräch für Anfänger
Q21. Wie führt man eine univariate Analyse für numerische und kategoriale Variablen durch?
Antwort. Die univariate Analyse ist eine statistische Technik zur Analyse und Beschreibung der Merkmale einer einzelnen Variablen. Es ist ein nützliches Werkzeug, um die Verteilung, zentrale Tendenz und Streuung einer Variablen zu verstehen und Muster und Beziehungen innerhalb der Daten zu identifizieren. Hier sind die Schritte zur Durchführung einer univariaten Analyse für numerische und kategoriale Variablen:
Für numerische Variablen:
Berechnen Sie deskriptive Statistiken wie Mittelwert, Median, Modus und Standardabweichung, um die Verteilung der Daten zusammenzufassen.
Visualisieren Sie die Verteilung der Daten mithilfe von Diagrammen wie Histogrammen, Boxplots oder Dichtediagrammen.
Überprüfen Sie die Daten auf Ausreißer und Anomalien.
Überprüfen Sie die Daten mit statistischen Tests oder Visualisierungen wie einem QQ-Plot auf Normalität.
Für kategoriale Variablen.
Berechnen Sie die Häufigkeit oder Anzahl jeder Kategorie in den Daten.
Berechnen Sie den Prozentsatz oder Anteil jeder Kategorie in den Daten.
Visualisieren Sie die Verteilung der Daten mithilfe von Diagrammen wie Balkendiagrammen oder Tortendiagrammen.
Überprüfen Sie die Verteilung der Daten auf Ungleichgewichte oder Anomalien.
Beachten Sie, dass die spezifischen Schritte zum Durchführen einer univariaten Analyse je nach den spezifischen Anforderungen und Zielen der Analyse variieren können. Es ist wichtig, die Analyse sorgfältig zu planen und durchzuführen, um die Daten genau und effektiv zu beschreiben und zu verstehen.
Q22. Welche Möglichkeiten gibt es, Ausreißer in den Daten zu finden?
Antwort. Ausreißer sind Datenpunkte, die sich signifikant von der Mehrheit der Daten unterscheiden. Sie können durch Fehler, Anomalien oder ungewöhnliche Umstände verursacht werden und einen erheblichen Einfluss auf statistische Analysen und Modelle für maschinelles Lernen haben. Daher ist es wichtig, Ausreißer angemessen zu identifizieren und zu handhaben, um genaue und zuverlässige Ergebnisse zu erhalten.
Hier sind einige gängige Methoden, um Ausreißer in den Daten zu finden:
Visuelle Inspektion: Ausreißer können häufig durch visuelle Untersuchung der Daten mithilfe von Diagrammen wie Histogrammen, Streudiagrammen oder Boxplots identifiziert werden.
Zusammengefasste Statistiken: Ausreißer können manchmal identifiziert werden, indem zusammenfassende Statistiken wie Mittelwert, Median oder Interquartilsabstand berechnet und mit den Daten verglichen werden. Wenn sich beispielsweise der Mittelwert erheblich vom Median unterscheidet, könnte dies auf das Vorhandensein von Ausreißern hindeuten.
Z-Wert: Der Z-Score eines Datenpunkts ist ein Maß dafür, wie viele Standardabweichungen er vom Mittelwert entfernt ist. Datenpunkte mit einem Z-Score über einem bestimmten Schwellenwert (z. B. 3 oder 4) können als Ausreißer betrachtet werden.
Es gibt viele andere Methoden zum Erkennen von Ausreißern in den Daten, und die geeignete Methode hängt von den spezifischen Merkmalen und Anforderungen der Daten ab. Es ist wichtig, die am besten geeignete Methode zur Identifizierung von Ausreißern sorgfältig zu bewerten und auszuwählen, um genaue und zuverlässige Ergebnisse zu erhalten.
Q23. Auf welche verschiedenen Arten können Sie die fehlenden Werte im Datensatz imputieren?
Antwort. Es gibt mehrere Möglichkeiten, wie Sie Nullwerte (d. h. fehlende Werte) in einem Datensatz imputieren können:
Zeilen löschen: Eine Möglichkeit besteht darin, Zeilen mit Nullwerten einfach aus dem Datensatz zu löschen. Dies ist eine einfache und schnelle Methode, die jedoch problematisch sein kann, wenn eine große Anzahl von Zeilen ausgelassen wird, da sie die Stichprobengröße erheblich reduzieren und die statistische Aussagekraft der Analyse beeinträchtigen kann.
Spalten löschen: Eine weitere Option besteht darin, Spalten mit Nullwerten aus dem Datensatz zu löschen. Dies kann eine gute Option sein, wenn die Anzahl der Nullwerte im Vergleich zur Anzahl der Nicht-Nullwerte groß ist oder wenn die Spalte für die Analyse nicht relevant ist.
Imputation mit Mittelwert oder Median: Eine gängige Imputationsmethode besteht darin, Nullwerte durch den Mittelwert oder Median der Nicht-Nullwerte in der Spalte zu ersetzen. Dies kann eine gute Option sein, wenn die Daten zufällig fehlen und der Mittelwert oder Median eine angemessene Darstellung der Daten ist.
Imputation mit Modus: Eine weitere Option besteht darin, Nullwerte durch den Modus (dh den häufigsten Wert) der Nicht-Nullwerte in der Spalte zu ersetzen. Dies kann eine gute Option für kategoriale Daten sein, bei denen der Modus eine aussagekräftige Darstellung der Daten ist.
Imputation mit einem Vorhersagemodell: Eine andere Imputationsmethode besteht darin, ein Vorhersagemodell zu verwenden, um die fehlenden Werte basierend auf den anderen verfügbaren Daten zu schätzen. Dies kann eine komplexere und zeitaufwändigere Methode sein, aber sie kann genauer sein, wenn die Daten nicht zufällig fehlen und eine starke Beziehung zwischen den fehlenden Werten und den anderen Daten besteht.
Q24. Was sind Schiefe in Statistiken und ihre Arten?
Antwort. Die Schiefe ist ein Maß für die Symmetrie einer Verteilung. Eine Verteilung ist symmetrisch, wenn sie wie eine Glockenkurve geformt ist, wobei sich die meisten Datenpunkte um den Mittelwert konzentrieren. Eine Verteilung ist verzerrt, wenn sie nicht symmetrisch ist und sich mehr Datenpunkte auf einer Seite des Mittelwerts konzentrieren als auf der anderen.
Es gibt zwei Arten von Schiefe: positive Schiefe und negative Schiefe.
Positive Schiefe: Eine positive Schiefe tritt auf, wenn die Verteilung einen langen Schwanz auf der rechten Seite hat, wobei sich die Mehrheit der Datenpunkte auf der linken Seite des Mittelwerts konzentriert. Eine positive Schiefe zeigt an, dass es einige extreme Werte auf der rechten Seite der Verteilung gibt, die den Mittelwert nach rechts ziehen.
Negative Schiefe: Eine negative Schiefe tritt auf, wenn die Verteilung einen langen Schwanz auf der linken Seite hat, wobei sich die Mehrheit der Datenpunkte auf der rechten Seite des Mittelwerts konzentriert. Eine negative Schiefe zeigt an, dass es einige wenige Extremwerte auf der linken Seite der Verteilung gibt, die den Mittelwert nach links ziehen.
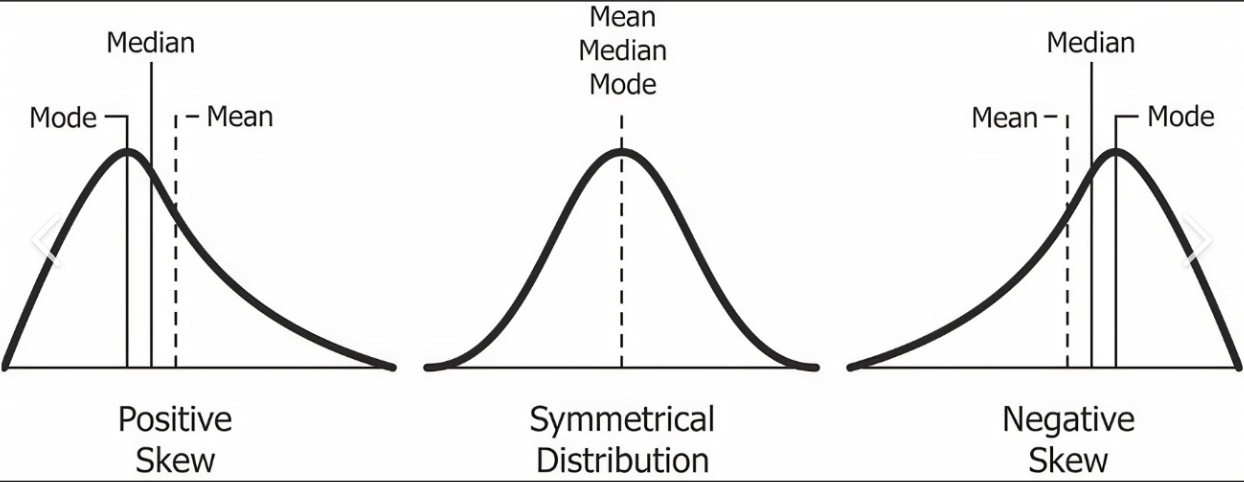
Q25. Was sind die Maße der zentralen Tendenz?
Antwort. In der Statistik sind Maße der zentralen Tendenz Werte, die das Zentrum eines Datensatzes darstellen. Es gibt drei Hauptmaße der zentralen Tendenz: Mittelwert, Median und Modus.
Der Mittelwert ist das arithmetische Mittel eines Datensatzes und wird berechnet, indem alle Werte im Datensatz addiert und durch die Anzahl der Werte dividiert werden. Der Mittelwert reagiert empfindlich auf Ausreißer oder Werte, die deutlich höher oder niedriger als die meisten anderen Werte im Datensatz sind.
Der Median ist der mittlere Wert eines Datensatzes, wenn die Werte in der Reihenfolge vom kleinsten zum größten angeordnet sind. Um den Median zu finden, müssen Sie zuerst die Werte der Reihe nach anordnen und dann den Mittelwert finden. Bei einer ungeraden Anzahl von Werten ist der Median der Mittelwert. Bei einer geraden Anzahl von Werten ist der Median der Mittelwert der beiden mittleren Werte. Der Median ist unempfindlich gegenüber Ausreißern.
Der Modus ist der Wert, der in einem Datensatz am häufigsten vorkommt. Ein Datensatz kann mehrere Modi oder gar keine Modi haben. Der Modus ist unempfindlich gegenüber Ausreißern.
Q26.Können Sie den Unterschied zwischen deskriptiver und inferenzieller Statistik erklären?
Antwort. Deskriptive Statistik wird verwendet, um einen Datensatz zusammenzufassen und zu beschreiben, indem Maße der zentralen Tendenz (Mittelwert, Median, Modus) und Streumaße (Standardabweichung, Varianz, Spannweite) verwendet werden. Inferenzstatistik wird verwendet, um auf der Grundlage einer Stichprobe von Daten und unter Verwendung statistischer Modelle, Hypothesentests und Schätzungen Rückschlüsse auf eine Population zu ziehen.
Q27.Was sind die Schlüsselelemente eines EDA-Berichts und wie tragen sie zum Verständnis eines Datensatzes bei?
Antwort. Zu den Schlüsselelementen eines EDA-Berichts gehören die univariate Analyse, die bivariate Analyse, die Analyse fehlender Daten und die grundlegende Datenvisualisierung. Die univariate Analyse hilft beim Verständnis der Verteilung einzelner Variablen, die bivariate Analyse hilft beim Verständnis der Beziehung zwischen Variablen, die Analyse fehlender Daten hilft beim Verständnis der Datenqualität und die Datenvisualisierung bietet eine visuelle Interpretation der Daten.
Intermediate Fragen im Vorstellungsgespräch
Q28 Was ist der zentrale Grenzwertsatz?
Antwort. Der zentrale Grenzwertsatz ist ein grundlegendes Konzept in der Statistik, das besagt, dass sich die Verteilung des Stichprobenmittelwerts mit zunehmender Stichprobengröße einer Normalverteilung annähert. Dies gilt unabhängig von der zugrunde liegenden Verteilung der Grundgesamtheit, aus der die Stichprobe gezogen wird. Das bedeutet, dass wir selbst dann, wenn die einzelnen Datenpunkte in einer Stichprobe nicht normalverteilt sind, indem wir den Durchschnitt einer ausreichend großen Anzahl von ihnen nehmen, normalverteilungsbasierte Methoden verwenden können, um Rückschlüsse auf die Grundgesamtheit zu ziehen.
Q29. Nennen Sie die zwei Arten von Zielvariablen für die Vorhersagemodellierung.
Antwort. Die zwei Arten von Zielvariablen sind:
Numerische/kontinuierliche Variablen – Variablen, deren Werte innerhalb eines Bereichs liegen, können ein beliebiger Wert in diesem Bereich und dem Zeitpunkt der Vorhersage sein; Werte müssen nicht unbedingt aus demselben Bereich stammen.
Zum Beispiel: Größe der Schüler – 5; 5.1; 6; 6.7; 7; 4.5; 5.11
Hier ist der Wertebereich (4,7)
Und die Größe einiger neuer Schüler kann / kann kein Wert aus diesem Bereich sein.
Kategoriale Variable – Variablen, die einen von einer begrenzten und normalerweise festen Anzahl möglicher Werte annehmen können, wobei jedes Individuum oder jede andere Beobachtungseinheit einer bestimmten Gruppe auf der Grundlage einer qualitativen Eigenschaft zugeordnet wird.
Eine kategoriale Variable, die genau zwei Werte annehmen kann, wird als binäre Variable oder dichotome Variable bezeichnet. Kategoriale Variablen mit mehr als zwei möglichen Werten werden polytome Variablen genannt
Zum Beispiel Prüfungsergebnis: Bestanden, Nicht bestanden (Binäre kategoriale Variable)
Die Blutgruppe einer Person: A, B, O, AB (polytome kategoriale Variable)
Q30. Was ist der Fall, in dem Mittelwert, Median und Modus für den Datensatz gleich sind?
Antwort. Mittelwert, Median und Modus eines Datensatzes sind genau dann gleich, wenn der Datensatz aus einem einzelnen Wert besteht, der mit einer Häufigkeit von 100 % auftritt.
Betrachten Sie beispielsweise den folgenden Datensatz: 3, 3, 3, 3, 3, 3. Der Mittelwert dieses Datensatzes ist 3, der Median ist 3 und der Modus ist 3. Dies liegt daran, dass der Datensatz aus einem einzigen Wert besteht ( 3), die mit einer Häufigkeit von 100 % auftritt.
Wenn der Datensatz andererseits mehrere Werte enthält, sind Mittelwert, Median und Modus im Allgemeinen unterschiedlich. Betrachten Sie beispielsweise den folgenden Datensatz: 1, 2, 3, 4, 5. Der Mittelwert dieses Datensatzes ist 3, der Median ist 3 und der Modus ist 1. Dies liegt daran, dass der Datensatz mehrere Werte enthält und kein Wert vorkommt mit 100% Frequenz.
Es ist wichtig zu beachten, dass Mittelwert, Median und Modus durch Ausreißer oder Extremwerte im Datensatz beeinflusst werden können. Wenn der Datensatz Extremwerte enthält, können sich Mittelwert und Median erheblich vom Modus unterscheiden, selbst wenn der Datensatz aus einem einzelnen Wert besteht, der mit hoher Häufigkeit auftritt.
Q31. Was ist der Unterschied zwischen Varianz und Bias in der Statistik?
Antwort. In der Statistik sind Varianz und Bias zwei Maße für die Qualität oder Genauigkeit eines Modells oder Schätzers.
Varianz: Die Varianz misst die Streuung oder Streuung in einem Datensatz. Er wird als durchschnittliche quadratische Abweichung vom Mittelwert berechnet. Eine hohe Varianz weist darauf hin, dass die Daten verstreut und möglicherweise fehleranfälliger sind, während eine niedrige Varianz darauf hinweist, dass sich die Daten um den Mittelwert konzentrieren und möglicherweise genauer sind.
Bias: Bias bezieht sich auf die Differenz zwischen dem erwarteten Wert eines Schätzers und dem wahren Wert des geschätzten Parameters. Eine hohe Abweichung zeigt an, dass der Schätzer den wahren Wert ständig unter- oder überschätzt, während eine niedrige Abweichung anzeigt, dass der Schätzer genauer ist.
Bei der Bewertung der Qualität eines Modells oder Schätzers ist es wichtig, sowohl die Varianz als auch die Verzerrung zu berücksichtigen. Ein Modell mit geringer Verzerrung und hoher Varianz kann zu Überanpassung neigen, während ein Modell mit hoher Verzerrung und niedriger Varianz zu Unteranpassung neigen kann. Das Finden der richtigen Balance zwischen Bias und Varianz ist ein wichtiger Aspekt bei der Modellauswahl und -optimierung.
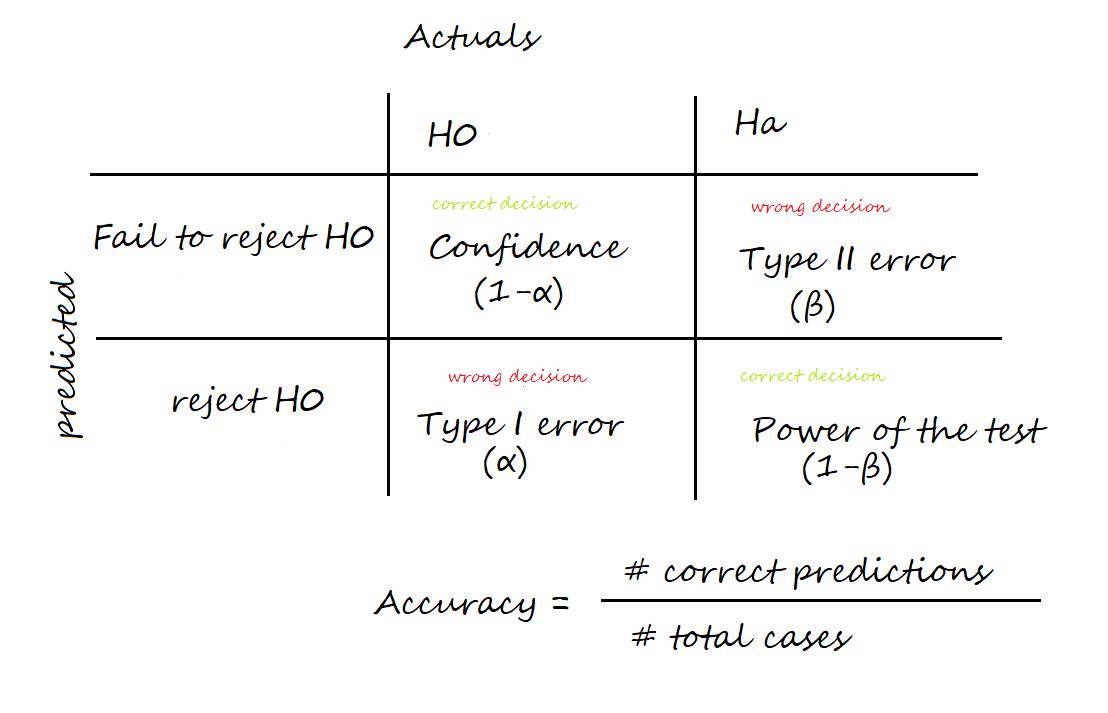
Q32. Was ist der Unterschied zwischen Fehlern vom Typ I und Typ II?
Ans. Zwei Arten von Fehlern können beim Testen von Hypothesen auftreten: Fehler XNUMX. Art und Fehler XNUMX. Art.
Ein Fehler 0.05. Art, auch bekannt als „falsch positiv“, tritt auf, wenn die Nullhypothese wahr ist, aber abgelehnt wird. Diese Art von Fehler wird mit dem griechischen Buchstaben Alpha (α) bezeichnet und normalerweise auf einen Wert von 5 festgelegt. Dies bedeutet, dass eine Wahrscheinlichkeit von XNUMX % besteht, einen Fehler XNUMX. Art oder ein falsches positives Ergebnis zu machen.
Ein Typ-II-Fehler, auch bekannt als „falsch negativ“, tritt auf, wenn die Nullhypothese falsch ist, aber nicht zurückgewiesen wird. Diese Art von Fehler wird mit dem griechischen Buchstaben Beta (β) bezeichnet und oft als 1 – β dargestellt, wobei β die Trennschärfe des Tests ist. Die Teststärke ist die Wahrscheinlichkeit, die Nullhypothese korrekt abzulehnen, wenn sie falsch ist.
Es ist wichtig zu versuchen, die Wahrscheinlichkeit beider Arten von Fehlern beim Testen von Hypothesen zu minimieren.
Q33. Was ist das Konfidenzintervall in der Statistik?
Antwort. Das Konfidenzintervall ist der Bereich, in dem wir erwarten, dass die Ergebnisse liegen, wenn wir das Experiment wiederholen. Es ist der Mittelwert des Ergebnisses plus und minus der erwarteten Variation.
Letzterer wird durch den Standardfehler der Schätzung bestimmt, während die Mitte des Intervalls mit dem Mittelwert der Schätzung zusammenfällt. Das häufigste Konfidenzintervall beträgt 95 %.
Q34.Können Sie das Konzept von Korrelation und Kovarianz erklären?
Antwort. Korrelation ist ein statistisches Maß, das die Stärke und Richtung einer linearen Beziehung zwischen zwei Variablen beschreibt. Eine positive Korrelation zeigt an, dass die beiden Variablen gemeinsam zunehmen oder abnehmen, während eine negative Korrelation anzeigt, dass sich die beiden Variablen in entgegengesetzte Richtungen bewegen. Kovarianz ist ein Maß für die gemeinsame Variabilität zweier Zufallsvariablen. Es wird verwendet, um zu messen, wie zwei Variablen zusammenhängen.
Erweiterte Interviewfragen
Q35. Warum ist das Testen von Hypothesen für einen Datenwissenschaftler nützlich?
Antwort. Hypothesentests sind eine statistische Technik, die in der Datenwissenschaft verwendet wird, um die Gültigkeit einer Behauptung oder Hypothese über eine Population zu bewerten. Es wird verwendet, um festzustellen, ob es genügend Beweise gibt, um eine Behauptung oder Hypothese zu stützen, und um die statistische Signifikanz der Ergebnisse zu bewerten.
Es gibt viele Situationen in der Datenwissenschaft, in denen das Testen von Hypothesen nützlich ist. Beispielsweise kann es verwendet werden, um die Effektivität einer neuen Marketingkampagne zu testen, um festzustellen, ob es einen signifikanten Unterschied zwischen den Mittelwerten zweier Gruppen gibt, um die Beziehung zwischen zwei Variablen zu bewerten oder um die Genauigkeit eines Vorhersagemodells zu bewerten.
Hypothesentests sind ein wichtiges Werkzeug in der Datenwissenschaft, da sie es Datenwissenschaftlern ermöglichen, fundierte Entscheidungen auf der Grundlage von Daten zu treffen, anstatt sich auf Annahmen oder subjektive Meinungen zu verlassen. Es hilft Datenwissenschaftlern, Schlussfolgerungen aus den Daten zu ziehen, die durch statistische Beweise gestützt werden, und ihre Ergebnisse klar und zuverlässig zu kommunizieren. Das Testen von Hypothesen ist daher ein wesentlicher Bestandteil der wissenschaftlichen Methode und ein grundlegender Aspekt der Data-Science-Praxis.
Q36. Wofür wird ein Chi-Quadrat-Unabhängigkeitstest in der Statistik verwendet?
Antwort. Ein Chi-Quadrat-Unabhängigkeitstest ist ein statistischer Test, der verwendet wird, um festzustellen, ob ein signifikanter Zusammenhang zwischen zwei kategorialen Variablen besteht. Es wird verwendet, um die Nullhypothese zu testen, dass die beiden Variablen unabhängig sind, was bedeutet, dass der Wert einer Variablen nicht vom Wert der anderen Variablen abhängt.
Beim Chi-Quadrat-Test auf Unabhängigkeit wird eine Chi-Quadrat-Statistik berechnet und mit einem kritischen Wert verglichen, um die Wahrscheinlichkeit zu bestimmen, dass die beobachtete Beziehung zufällig auftritt. Wenn die Wahrscheinlichkeit unter einer bestimmten Schwelle liegt (z. B. 0.05), wird die Nullhypothese verworfen und es wird gefolgert, dass es einen signifikanten Zusammenhang zwischen den beiden Variablen gibt.
Der Chi-Quadrat-Test der Unabhängigkeit wird in der Datenwissenschaft häufig verwendet, um die Beziehung zwischen zwei kategorialen Variablen zu bewerten, z. B. die Beziehung zwischen Geschlecht und Kaufverhalten oder die Beziehung zwischen Bildungsniveau und Wahlpräferenz. Es ist ein wichtiges Werkzeug, um die Beziehung zwischen verschiedenen Variablen zu verstehen und fundierte Entscheidungen auf der Grundlage der Daten zu treffen.
Q37. Welche Bedeutung hat der p-Wert?
Antwort. Der p-Wert wird verwendet, um die statistische Signifikanz eines Ergebnisses zu bestimmen. Beim Hypothesentest wird der p-Wert verwendet, um die Wahrscheinlichkeit zu bewerten, ein Ergebnis zu erhalten, das mindestens so extrem ist wie das beobachtete, vorausgesetzt, die Nullhypothese ist wahr. Wenn der p-Wert kleiner als das vorgegebene Signifikanzniveau ist (normalerweise als Alpha, α bezeichnet), wird das Ergebnis als statistisch signifikant betrachtet und die Nullhypothese zurückgewiesen.
Die Bedeutung des p-Werts besteht darin, dass er es Forschern ermöglicht, Entscheidungen über die Daten auf der Grundlage eines vorher festgelegten Konfidenzniveaus zu treffen. Durch die Festlegung eines Signifikanzniveaus vor der Durchführung des statistischen Tests können die Forscher feststellen, ob die Ergebnisse wahrscheinlich zufällig aufgetreten sind oder ob die Daten einen echten Effekt aufweisen.
Q38.Welches sind die verschiedenen Arten von Stichprobentechniken, die von Datenanalysten verwendet werden?
Antwort. Es gibt viele verschiedene Arten von Stichprobentechniken, die Datenanalysten verwenden können, aber einige der gebräuchlichsten sind:
Einfache Zufallsstichprobe: Dies ist eine Grundform der Stichprobenziehung, bei der jedes Mitglied der Bevölkerung die gleiche Chance hat, für die Stichprobe ausgewählt zu werden.
Geschichtete Zufallsauswahl: Bei dieser Technik wird die Bevölkerung anhand bestimmter Merkmale in Untergruppen (oder Schichten) unterteilt und dann aus jeder Schicht eine Zufallsstichprobe ausgewählt.
Cluster-Sampling: Bei dieser Technik wird die Population in kleinere Gruppen (oder Cluster) unterteilt und dann eine Zufallsstichprobe von Clustern ausgewählt.
Systematische Stichprobenziehung: Bei dieser Technik wird jedes k-te Mitglied der Bevölkerung ausgewählt, das in die Stichprobe aufgenommen werden soll.
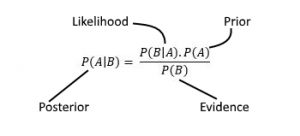
Q39.Was ist der Satz von Bayes und wie wird er in der Datenwissenschaft verwendet?
Antwort. Das Theorem von Bayes ist eine mathematische Formel, die die Wahrscheinlichkeit des Eintretens eines Ereignisses beschreibt, basierend auf vorherigem Wissen über Bedingungen, die mit dem Ereignis zusammenhängen könnten. In der Datenwissenschaft wird der Satz von Bayes häufig in der Bayes'schen Statistik und im maschinellen Lernen für Aufgaben wie Klassifizierung, Vorhersage und Schätzung verwendet.
Q40.Was ist der Unterschied zwischen einem parametrischen und einem nicht-parametrischen Test?
Antwort. Ein parametrischer Test ist ein statistischer Test, der davon ausgeht, dass die Daten einer bestimmten Wahrscheinlichkeitsverteilung folgen, beispielsweise einer Normalverteilung. Ein nichtparametrischer Test macht keine Annahmen über die zugrunde liegende Wahrscheinlichkeitsverteilung der Daten.
Interviewfragen im Zusammenhang mit maschinellem Lernen
Anfänger Interview Fragen
Q41. Was ist der Unterschied zwischen Merkmalsauswahl und Extraktion?
Antwort. Die Merkmalsauswahl ist die Technik, bei der wir die Merkmale filtern, die dem Modell zugeführt werden sollen. Dies ist die Aufgabe, bei der wir die relevantesten Merkmale auswählen. Die Merkmale, die eindeutig keine Bedeutung für die Bestimmung der Vorhersage des Modells haben, werden verworfen.
Die Merkmalsauswahl hingegen ist der Prozess, bei dem die Merkmale aus den Rohdaten extrahiert werden. Dabei werden Rohdaten in eine Reihe von Funktionen umgewandelt, die zum Trainieren eines ML-Modells verwendet werden können.
Beide sind sehr wichtig, da sie beim Filtern der Merkmale für unser ML-Modell helfen, was bei der Bestimmung der Genauigkeit des Modells hilft.
Q42. Was sind die 5 Annahmen für die lineare Regression?
Antwort. Hier sind die 5 Annahmen der linearen Regression:
- Linearität: Es besteht eine lineare Beziehung zwischen den unabhängigen Variablen und der abhängigen Variablen.
- Unabhängigkeit von Fehlern: Die Fehler (Residuen) sind voneinander unabhängig.
- Homoskedastizität: Die Varianz der Fehler ist über alle vorhergesagten Werte konstant.
- Normalität: Die Fehler folgen einer Normalverteilung.
- Unabhängigkeit der Prädiktoren: Die unabhängigen Variablen sind nicht miteinander korreliert.
Q43. Was ist der Unterschied zwischen linearer und nichtlinearer Regression?
Antwort. Lineare Regression ist die Methode, mit der die Beziehung zwischen einer abhängigen und einer oder mehreren unabhängigen Variablen ermittelt wird. Das Modell findet die am besten passende Linie, die eine lineare Funktion (y = mx + c) ist, die dabei hilft, das Modell so anzupassen, dass der Fehler unter Berücksichtigung aller Datenpunkte minimal ist. Die Entscheidungsgrenze einer linearen Regressionsfunktion ist also linear.
Eine nichtlineare Regression wird verwendet, um die Beziehung zwischen einer abhängigen und einer oder mehreren unabhängigen Variablen durch eine nichtlineare Gleichung zu modellieren. Die nichtlinearen Regressionsmodelle sind flexibler und können die komplexere Beziehung zwischen Variablen finden.
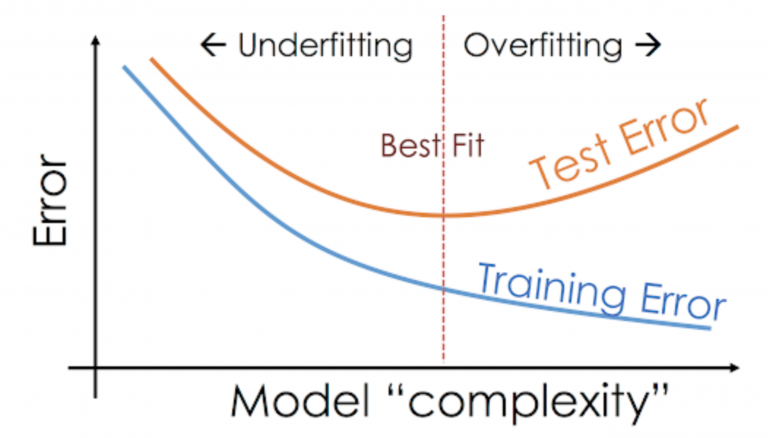
Q44. Wie erkennt man Underfitting in einem Modell?
Antwort. Underfitting tritt auf, wenn ein statistisches Modell oder ein Algorithmus für maschinelles Lernen den zugrunde liegenden Trend der Daten nicht erfassen kann. Dies kann verschiedene Gründe haben, aber eine häufige Ursache ist, dass das Modell zu einfach ist und die Komplexität der Daten nicht erfassen kann
So erkennen Sie Underfitting in einem Modell:
Der Trainingsfehler eines Underfitting-Fehlers wird hoch sein, dh das Modell wird nicht in der Lage sein, aus den Trainingsdaten zu lernen und wird auf den Trainingsdaten schlecht abschneiden.
Der Validierungsfehler eines Underfitting-Modells ist ebenfalls hoch, da es auch bei den neuen Daten schlecht abschneidet.
Q45. Wie erkennen Sie Overfitting in einem Modell?
Antwort. Eine Überanpassung in einem Modell tritt auf, wenn das Modell die gesamten Trainingsdaten lernt, anstatt Signale/Hinweise aus den Daten zu nehmen, und das Modell bei Trainingsdaten sehr gut und bei den Testdaten schlecht abschneidet.
Der Testfehler des Modells ist im Vergleich zum Trainingsfehler hoch. Die Verzerrung eines Overfitting-Modells ist gering, während die Varianz hoch ist.
Q46. Welche Techniken gibt es, um Overfitting zu vermeiden?
Antwort. Einige Techniken, die verwendet werden können, um eine Überanpassung zu vermeiden;
- Aufteilung Zug-Validierung-Test: Eine Möglichkeit, eine Überanpassung zu vermeiden, besteht darin, Ihre Daten in Trainings-, Validierungs- und Testdatensätze aufzuteilen. Das Modell wird auf dem Trainingsset trainiert und dann auf dem Validierungsset evaluiert. Die Hyperparameter werden dann basierend auf der Leistung des Validierungssatzes abgestimmt. Sobald das Modell fertiggestellt ist, wird es auf dem Testset evaluiert.
- Vorzeitiges Stoppen: Eine andere Möglichkeit, eine Überanpassung zu vermeiden, ist das frühzeitige Stoppen. Dazu gehört, das Modell zu trainieren, bis der Validierungsfehler ein Minimum erreicht, und dann den Trainingsprozess zu stoppen.
- Regulierung: Die Regularisierung ist eine Technik, die verwendet werden kann, um eine Überanpassung zu verhindern, indem der Zielfunktion ein Strafterm hinzugefügt wird. Dieser Begriff ermutigt das Modell, kleine Gewichtungen zu haben, was dazu beitragen kann, die Komplexität des Modells zu reduzieren und eine Überanpassung zu verhindern.
- Ensemble-Methoden: Ensemble-Methoden beinhalten das Trainieren mehrerer Modelle und das anschließende Kombinieren ihrer Vorhersagen, um eine endgültige Vorhersage zu treffen. Dies kann dazu beitragen, die Überanpassung zu reduzieren, indem die Vorhersagen der einzelnen Modelle gemittelt werden, was dazu beitragen kann, die Varianz der endgültigen Vorhersage zu verringern.
Q47. Welche Techniken gibt es, um Underfitting zu vermeiden?
Antwort. Einige Techniken zur Vermeidung von Underfitting in einem Modell:
Merkmalsauswahl: Es ist wichtig, das richtige Merkmal auszuwählen, das zum Trainieren eines Modells erforderlich ist, da die Auswahl des falschen Merkmals zu einer Unteranpassung führen kann.
Eine Erhöhung der Anzahl an Features hilft, Underfitting zu vermeiden
Verwenden eines komplexeren maschinellen Lernmodells
Verwenden der Hyperparameter-Abstimmung zur Feinabstimmung der Parameter im Modell
Rauschen: Wenn die Daten mehr Rauschen enthalten, kann das Modell die Komplexität des Datensatzes nicht erkennen.
Q48. Was ist Multikollinearität?
Antwort. Multikollinearität tritt auf, wenn zwei oder mehr Prädiktorvariablen in einem multiplen Regressionsmodell stark korreliert sind. Dies kann zu instabilen und inkonsistenten Koeffizienten führen und die Interpretation der Ergebnisse des Modells erschweren.
Mit anderen Worten, Multikollinearität tritt auf, wenn ein hoher Korrelationsgrad zwischen zwei oder mehr Prädiktorvariablen besteht. Dies kann es schwierig machen, den eindeutigen Beitrag jeder Prädiktorvariablen zur Antwortvariablen zu bestimmen, da die Schätzungen ihrer Koeffizienten durch die anderen korrelierten Variablen beeinflusst werden können.
Q49. Erklären Sie Regressions- und Klassifikationsprobleme.
Antwort. Regression ist eine Methode zur Modellierung der Beziehung zwischen einer oder mehreren unabhängigen Variablen und einer abhängigen Variablen. Das Ziel der Regression besteht darin, zu verstehen, wie die unabhängigen Variablen mit der abhängigen Variablen zusammenhängen, und in der Lage zu sein, auf der Grundlage neuer Werte der unabhängigen Variablen Vorhersagen über den Wert der abhängigen Variablen zu treffen.
Ein Klassifizierungsproblem ist eine Art maschinelles Lernproblem, bei dem das Ziel darin besteht, eine diskrete Bezeichnung für eine bestimmte Eingabe vorherzusagen. Mit anderen Worten, es ist ein Problem, auf der Grundlage eines Trainingsdatensatzes, der Beobachtungen enthält, zu identifizieren, zu welchem Satz von Kategorien eine neue Beobachtung gehört.
Q50. Was ist der Unterschied zwischen K-means und KNN?
Antwort. K-bedeutet und KNN (K-Nearest Neighbors) sind zwei verschiedene maschinelle Lernalgorithmen.
K-Means ist ein Clustering-Algorithmus, der verwendet wird, um eine Gruppe von Datenpunkten in K Cluster zu unterteilen, wobei jeder Datenpunkt zu dem Cluster mit dem nächsten Mittelwert gehört. Es handelt sich um einen iterativen Algorithmus, der einem Cluster Datenpunkte zuweist und dann den Clusterschwerpunkt (Mittelwert) basierend auf den ihm zugewiesenen Datenpunkten aktualisiert.
Andererseits ist KNN ein Klassifizierungsalgorithmus, der verwendet wird, um Datenpunkte basierend auf ihrer Ähnlichkeit mit anderen Datenpunkten zu klassifizieren. Es funktioniert, indem es die K Datenpunkte im Trainingssatz findet, die dem zu klassifizierenden Datenpunkt am ähnlichsten sind, und dann den Datenpunkt der Klasse zuweist, die unter diesen K Datenpunkten am häufigsten vorkommt.
Zusammenfassend wird also K-Means für das Clustering und KNN für die Klassifizierung verwendet.
Q51. Was ist der Unterschied zwischen Sigmoid und Softmax?
Antwort. Wenn Ihre Ausgabe in der Sigmoid-Funktion binär (0,1) ist, verwenden Sie die Sigmoid-Funktion für die Ausgabeschicht. Die Sigmoidfunktion erscheint in der Ausgabeschicht der Deep-Learning-Modelle und wird zur Vorhersage wahrscheinlichkeitsbasierter Ausgaben verwendet.
Die Softmax-Funktion ist eine andere Art von Aktivierungsfunktion, die in neuronalen Netzwerken verwendet wird, um die Wahrscheinlichkeitsverteilung aus einem Vektor reeller Zahlen zu berechnen.
Diese Funktion wird hauptsächlich in Mehrklassenmodellen verwendet, wo sie Wahrscheinlichkeiten jeder Klasse zurückgibt, wobei die Zielklasse die höchste Wahrscheinlichkeit hat.
Der Hauptunterschied zwischen der Sigmoid- und der Softmax-Aktivierungsfunktion besteht darin, dass erstere für die binäre Klassifizierung, letztere für die multivariate Klassifizierung verwendet wird
Q52. Können wir die logistische Regression für die Mehrklassenklassifizierung verwenden?
Antwort. Ja, die logistische Regression kann für die Mehrklassenklassifizierung verwendet werden.
Die logistische Regression ist ein Klassifizierungsalgorithmus, der verwendet wird, um die Wahrscheinlichkeit vorherzusagen, dass ein Datenpunkt zu einer bestimmten Klasse gehört. Es ist ein binärer Klassifizierungsalgorithmus, was bedeutet, dass er nur zwei Klassen verarbeiten kann. Es gibt jedoch Möglichkeiten, die logistische Regression auf eine Mehrklassenklassifizierung auszudehnen.
Eine Möglichkeit, dies zu tun, besteht darin, die One-vs-all (OvA)- oder One-vs-Rest (OvR)-Strategie zu verwenden, bei der Sie K logistische Regressionsklassifikatoren trainieren, einen für jede Klasse, und der Klasse, die hat, einen Datenpunkt zuweisen die höchste vorhergesagte Wahrscheinlichkeit. Dies wird als OvA bezeichnet, wenn Sie für jede Klasse einen Klassifikator trainieren und die andere Klasse der „Rest“ der Klassen ist. Dies wird als OvR bezeichnet, wenn Sie einen Klassifikator für jede Klasse trainieren und die andere Klasse „alle“ Klassen sind.
Eine andere Möglichkeit, dies zu tun, ist die Verwendung der multinomialen logistischen Regression, die eine Verallgemeinerung der logistischen Regression für den Fall ist, in dem Sie mehr als zwei Klassen haben. Bei der multinomialen logistischen Regression trainieren Sie einen logistischen Regressionsklassifikator für jedes Klassenpaar und verwenden die vorhergesagten Wahrscheinlichkeiten, um der Klasse mit der höchsten Wahrscheinlichkeit einen Datenpunkt zuzuweisen.
Zusammenfassend lässt sich also sagen, dass die logistische Regression für die Mehrklassenklassifizierung unter Verwendung von OvA/OvR oder multinomialer logistischer Regression verwendet werden kann.
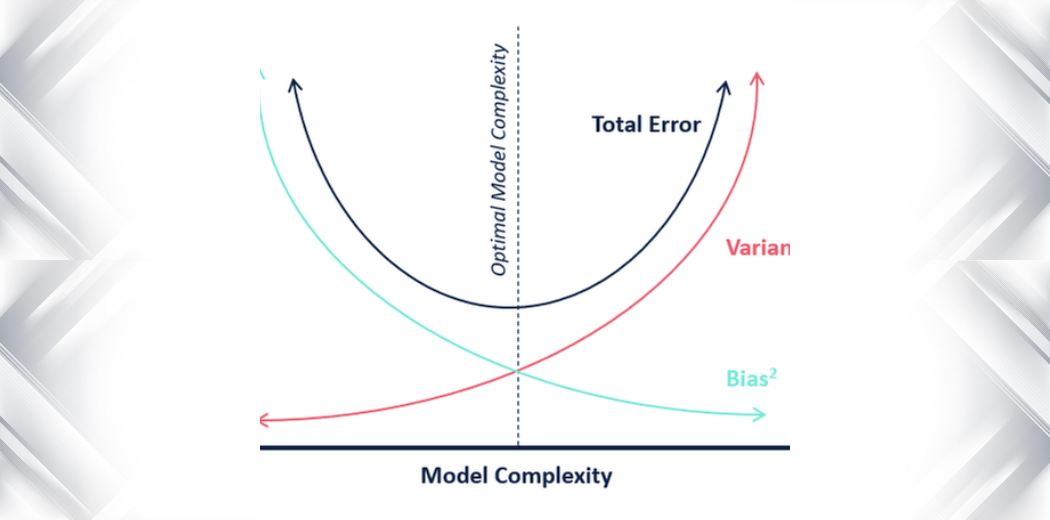
Q53. Können Sie den Bias-Varianz-Tradeoff im Kontext des überwachten maschinellen Lernens erklären?
Antwort. Beim überwachten maschinellen Lernen besteht das Ziel darin, ein Modell zu erstellen, das genaue Vorhersagen auf unsichtbaren Daten treffen kann. Es gibt jedoch einen Kompromiss zwischen der Fähigkeit des Modells, die Trainingsdaten gut anzupassen (geringe Verzerrung) und seiner Fähigkeit, auf neue Daten zu verallgemeinern (geringe Varianz).
Ein Modell mit hoher Verzerrung tendiert dazu, die Daten zu wenig anzupassen, was bedeutet, dass es nicht flexibel genug ist, um die Muster in den Daten zu erfassen. Andererseits neigt ein Modell mit hoher Varianz dazu, die Daten zu überanpassen, was bedeutet, dass es zu empfindlich auf Rauschen und zufällige Schwankungen in den Trainingsdaten reagiert.
Der Bias-Varianz-Kompromiss bezieht sich auf den Kompromiss zwischen diesen beiden Arten von Fehlern. Ein Modell mit geringer systematischer Abweichung und hoher Varianz passt die Daten wahrscheinlich zu stark an, während ein Modell mit hoher systematischer Abweichung und niedriger Varianz wahrscheinlich zu schwach an die Daten angepasst ist.
Um den Kompromiss zwischen Verzerrung und Varianz auszugleichen, müssen wir ein Modell mit dem richtigen Komplexitätsgrad für das vorliegende Problem finden. Wenn das Modell zu einfach ist, weist es eine hohe Verzerrung und geringe Varianz auf, ist jedoch nicht in der Lage, die zugrunde liegenden Muster in den Daten zu erfassen. Wenn das Modell zu komplex ist, weist es eine geringe Verzerrung und eine hohe Varianz auf, reagiert jedoch empfindlich auf das Rauschen in den Daten und lässt sich nicht gut auf neue Daten verallgemeinern.
Q54. Wie entscheiden Sie, ob ein Modell unter hoher Verzerrung oder hoher Varianz leidet?
Antwort. Es gibt mehrere Möglichkeiten, um festzustellen, ob ein Modell unter hoher Verzerrung oder hoher Varianz leidet. Einige gängige Methoden sind:
Teilen Sie die Daten in einen Trainingssatz und einen Testsatz auf und überprüfen Sie die Leistung des Modells auf beiden Sätzen. Wenn das Modell auf dem Trainingsdatensatz gut, aber auf dem Testdatensatz schlecht abschneidet, leidet es wahrscheinlich unter einer hohen Varianz (Overfitting). Wenn das Modell in beiden Sätzen schlecht abschneidet, leidet es wahrscheinlich unter einer hohen Verzerrung (Underfitting).
Verwenden Sie die Kreuzvalidierung, um die Leistung des Modells abzuschätzen. Wenn das Modell eine hohe Varianz aufweist, variiert die Leistung je nach den für Training und Test verwendeten Daten erheblich. Wenn das Modell eine hohe Verzerrung aufweist, ist die Leistung über verschiedene Datenaufteilungen hinweg konstant niedrig.
Zeichnen Sie die Lernkurve, die die Leistung des Modells auf der Trainingsmenge und der Testmenge als Funktion der Anzahl der Trainingsbeispiele zeigt. Ein Modell mit hoher Verzerrung hat einen hohen Trainingsfehler und einen hohen Testfehler, während ein Modell mit hoher Varianz einen niedrigen Trainingsfehler und einen hohen Testfehler hat.
Q55. Welche Techniken gibt es, um Verzerrungen und Varianzen in einem Modell auszugleichen?
Antwort. Es gibt mehrere Techniken, die verwendet werden können, um die Verzerrung und Varianz in einem Modell auszugleichen, einschließlich:
Erhöhen der Modellkomplexität durch Hinzufügen weiterer Parameter oder Merkmale: Dies kann dem Modell helfen, komplexere Muster in den Daten zu erfassen und Verzerrungen zu reduzieren, aber es kann auch die Varianz erhöhen, wenn das Modell zu komplex wird.
Reduzieren der Modellkomplexität durch Entfernen von Parametern oder Merkmalen: Dies kann dem Modell helfen, eine Überanpassung zu vermeiden und die Varianz zu reduzieren, aber es kann auch die Verzerrung erhöhen, wenn das Modell zu einfach wird.
Verwendung von Regularisierungstechniken: Diese Techniken schränken die Modellkomplexität ein, indem sie große Gewichtungen bestrafen, was dem Modell helfen kann, eine Überanpassung zu vermeiden und die Varianz zu reduzieren. Einige Beispiele für Regularisierungstechniken sind L1-Regularisierung, L2-Regularisierung und Elastic-Net-Regularisierung.
Aufteilen der Daten in ein Trainingsset und ein Testset: Dies ermöglicht es uns, die Verallgemeinerungsfähigkeit des Modells zu bewerten und die Modellkomplexität abzustimmen, um ein gutes Gleichgewicht zwischen Verzerrung und Varianz zu erreichen.
Verwenden von Kreuzvalidierung: Dies ist eine Technik zum Bewerten der Leistung des Modells bei verschiedenen Aufteilungen der Daten und Mittelwertbildung der Ergebnisse, um eine genauere Schätzung zu erhalten
der Verallgemeinerungsfähigkeit des Modells.
Q56. Wie wählt man die geeignete Bewertungsmetrik für ein Klassifikationsproblem aus und wie interpretiert man die Ergebnisse der Bewertung?
Antwort. Es gibt viele Bewertungsmetriken, die Sie für ein Klassifizierungsproblem verwenden können, und die geeignete Metrik hängt von den spezifischen Merkmalen des Problems und den Zielen der Bewertung ab. Einige gängige Bewertungsmetriken für die Klassifizierung sind:
Genauigkeit: Dies ist die häufigste Bewertungsmetrik für die Klassifizierung. Es misst den Prozentsatz der korrekten Vorhersagen des Modells.
Präzision: Diese Metrik misst den Anteil wahrer positiver Vorhersagen an allen positiven Vorhersagen des Modells.
Erinnern: Diese Metrik misst den Anteil wahrer positiver Vorhersagen an allen tatsächlich positiven Fällen in der Testreihe.
F1 Punktzahl: Dies ist das harmonische Mittel aus Präzision und Recall. Es ist eine gute Metrik, die Sie verwenden können, wenn Sie Präzision und Erinnerung ausbalancieren möchten.
AUC-ROC: Diese Metrik misst die Fähigkeit des Modells, zwischen positiven und negativen Klassen zu unterscheiden. Es wird häufig für unausgeglichene Klassifizierungsprobleme verwendet.
Um die Ergebnisse der Evaluation zu interpretieren, sollten Sie die spezifischen Merkmale des Problems und die Ziele der Evaluation berücksichtigen. Wenn Sie beispielsweise versuchen, betrügerische Transaktionen zu identifizieren, sind Sie möglicherweise eher daran interessiert, die Genauigkeit zu maximieren, da Sie die Anzahl der Fehlalarme minimieren möchten. Wenn Sie andererseits versuchen, eine Krankheit zu diagnostizieren, sind Sie möglicherweise eher daran interessiert, die Erinnerung zu maximieren, da Sie die Anzahl der verpassten Diagnosen minimieren möchten.
Q57. Was ist der Unterschied zwischen K-means und hierarchischem Clustering und wann sollte man was verwenden?
Antwort. K-Means und hierarchisches Clustering sind zwei unterschiedliche Methoden zum Clustering von Daten. Beide Methoden können in verschiedenen Situationen nützlich sein.
K-Means ist ein zentroidbasierter Algorithmus oder ein entfernungsbasierter Algorithmus, bei dem wir die Entfernungen berechnen, um einen Punkt einem Cluster zuzuweisen. K-Means ist sehr schnell und effizient in Bezug auf die Rechenzeit, kann jedoch das globale Optimum nicht finden, da es zufällige Initialisierungen für die Zentroid-Seeds verwendet.
Hierarchisches Clustering hingegen ist ein dichtebasierter Algorithmus, bei dem wir die Anzahl der Cluster nicht vorher angeben müssen. Es baut eine Hierarchie von Clustern auf, indem es ein baumartiges Diagramm erstellt, das als Dendrogramm bezeichnet wird. Es gibt zwei Haupttypen von hierarchischem Clustering: agglomerativ und divisiv. Agglomeratives Clustering beginnt mit einzelnen Punkten als separate Cluster und führt sie zu größeren Clustern zusammen, während divisives Clustering mit allen Punkten in einem Cluster beginnt und sie in kleinere Cluster unterteilt. Hierarchisches Clustering ist ein langsamer Algorithmus und erfordert viele Rechenressourcen, ist aber genauer als K-means.
Wann sollte man also K-Means und wann hierarchisches Clustering verwenden? Es hängt wirklich von der Größe und Struktur Ihrer Daten sowie von den verfügbaren Ressourcen ab. Wenn Sie über ein großes Dataset verfügen und es schnell clustern möchten, ist K-means möglicherweise eine gute Wahl. Wenn Sie über ein kleines Dataset verfügen oder genauere Cluster wünschen, ist hierarchisches Clustering möglicherweise die bessere Wahl.
Q58. Wie können Sie mit unausgeglichenen Klassen in einem logistischen Regressionsmodell umgehen?
Antwort. Es gibt mehrere Möglichkeiten, unausgeglichene Klassen in einem logistischen Regressionsmodell zu handhaben. Einige Ansätze umfassen:
Unterabtastung der Mehrheitsklasse: Dies beinhaltet die zufällige Auswahl einer Teilmenge der Mehrheitsklassenstichproben zur Verwendung beim Trainieren des Modells. Dies kann helfen, die Klassenverteilung auszugleichen, aber es kann auch wertvolle Informationen verschenken.
Oversampling der Minderheitsklasse: Dies beinhaltet das Generieren synthetischer Stichproben der Minderheitsklasse, um sie dem Trainingssatz hinzuzufügen. Eine beliebte Methode zur Generierung synthetischer Samples heißt SMOTE (Synthetic Minority Oversampling Technique).
Anpassen der Klassengewichte: Viele maschinelle Lernalgorithmen ermöglichen es Ihnen, die Gewichtung jeder Klasse anzupassen. In der logistischen Regression können Sie dies tun, indem Sie den Parameter class_weight auf „balanced“ setzen. Dadurch werden die Klassen automatisch umgekehrt proportional zu ihrer Häufigkeit gewichtet, sodass das Modell der Minderheitsklasse mehr Aufmerksamkeit schenkt.
Verwenden einer anderen Bewertungsmetrik: Bei unausgewogenen Klassifizierungsaufgaben ist es oft informativer, Bewertungsmetriken zu verwenden, die empfindlich auf Klassenungleichgewichte reagieren, wie z. B. Genauigkeit, Erinnerung und die F1-Punktzahl.
Verwenden eines anderen Algorithmus: Einige Algorithmen wie Entscheidungsbäume und Random Forests sind robuster gegenüber unausgeglichenen Klassen und können bei unausgeglichenen Datensätzen eine bessere Leistung erbringen.
Q59. Wann sollte PCA nicht zur Dimensionsreduktion verwendet werden?
Antwort. Es gibt mehrere Situationen, in denen Sie die Hauptkomponentenanalyse (PCA) möglicherweise nicht zur Dimensionsreduktion verwenden möchten:
Wenn die Daten nicht linear trennbar sind: PCA ist eine lineare Technik, daher ist es möglicherweise nicht effektiv, die Dimensionalität von Daten zu reduzieren, die nicht linear trennbar sind.
Wenn die Daten kategoriale Merkmale aufweisen: PCA wurde entwickelt, um mit kontinuierlichen numerischen Daten zu arbeiten und ist möglicherweise nicht effektiv, um die Dimensionalität von Daten mit kategorischen Merkmalen zu reduzieren.
Wenn die Daten eine große Anzahl fehlender Werte aufweisen: PCA reagiert empfindlich auf fehlende Werte und funktioniert möglicherweise nicht gut mit Datensätzen, die eine große Anzahl fehlender Werte aufweisen.
Wenn die Daten stark unausgeglichen sind: PCA reagiert empfindlich auf Klassenungleichgewichte und liefert möglicherweise keine guten Ergebnisse bei stark unausgeglichenen Datensätzen.
Wenn das Ziel darin besteht, die Beziehungen zwischen den ursprünglichen Merkmalen beizubehalten: PCA ist eine Technik, die nach Mustern in den Daten sucht und neue Merkmale erstellt, die Kombinationen der ursprünglichen Merkmale sind. Daher ist es möglicherweise nicht die beste Wahl, wenn das Ziel darin besteht, die Beziehungen zwischen den ursprünglichen Features beizubehalten.
Q60. Was ist Gradientenabstieg?
Antwort. Gradientenabstieg ist ein Optimierungsalgorithmus, der beim maschinellen Lernen verwendet wird, um die Werte von Parametern (Koeffizienten und Bias) eines Modells zu finden, die die Kostenfunktion minimieren. Es handelt sich um einen iterativen Optimierungsalgorithmus erster Ordnung, der dem negativen Gradienten der Kostenfunktion folgt, um gegen das globale Minimum zu konvergieren.
Beim Gradientenabstieg werden die Parameter des Modells mit zufälligen Werten initialisiert, und der Algorithmus aktualisiert iterativ die Parameter in der entgegengesetzten Richtung des Gradienten der Kostenfunktion in Bezug auf die Parameter. Die Größe der Aktualisierung wird durch die Lernrate bestimmt, die ein Hyperparameter ist, der steuert, wie schnell der Algorithmus zum globalen Minimum konvergiert.
Wenn der Algorithmus die Parameter aktualisiert, sinkt die Kostenfunktion und die Leistung des Modells verbessert sich
Q61. Was ist der Unterschied zwischen MinMaxScaler und StandardScaler?
Antwort. Sowohl der MinMaxScaler als auch der StandardScaler sind Werkzeuge, die verwendet werden, um die Merkmale eines Datensatzes so umzuwandeln, dass sie besser durch maschinelle Lernalgorithmen modelliert werden können. Sie arbeiten jedoch auf unterschiedliche Weise.
MinMaxScaler skaliert die Merkmale eines Datensatzes, indem er sie in einen bestimmten Bereich transformiert, normalerweise zwischen 0 und 1. Dazu subtrahiert er den Mindestwert jedes Merkmals von allen Werten in diesem Merkmal und dividiert dann das Ergebnis durch den Bereich (d. h , die Differenz zwischen Minimal- und Maximalwert). Diese Transformation ist durch die folgende Gleichung gegeben:
x_skaliert = (x – x_min) / (x_max – x_min)
StandardScaler standardisiert die Merkmale eines Datensatzes, indem er sie so umwandelt, dass sie einen Mittelwert von null und eine Einheitsvarianz aufweisen. Dazu wird der Mittelwert jedes Merkmals von allen Werten in diesem Merkmal subtrahiert und das Ergebnis dann durch die Standardabweichung dividiert. Diese Transformation ist durch die folgende Gleichung gegeben:
x_scaled = (x – Mittelwert(x)) / std(x)
Im Allgemeinen eignet sich StandardScaler besser für Datensätze, bei denen die Verteilung der Merkmale ungefähr normal oder gaußsch ist. MinMaxScaler eignet sich besser für Datensätze, bei denen die Verteilung verzerrt ist oder Ausreißer vorhanden sind. Es ist jedoch immer eine gute Idee, die Daten zu visualisieren und die Verteilung der Merkmale zu verstehen, bevor Sie sich für eine Skalierungsmethode entscheiden.
Q62. Was ist der Unterschied zwischen überwachtem und unüberwachtem Lernen?
Antwort.Beim überwachten Lernen enthält das Trainingsset, das Sie dem Algorithmus zuführen, das gewünschte
Lösungen, Etiketten genannt
Bsp. = Spamfilter (Klassifizierungsproblem)
k-Nächste Nachbarn
- Lineare Regression
- Logistische Regression
- Support Vector Machines (SVMs)
- Entscheidungsbäume und Random Forests
- Neuronale Netze
Beim unüberwachten Lernen sind die Trainingsdaten unbeschriftet.
Nehmen wir an, das System versucht ohne Lehrer zu lernen.
Clustering
—K-Mittel
– DBSCAN
—Hierarchische Clusteranalyse (HCA)
- Anomalieerkennung und Neuheitserkennung
– Ein-Klassen-SVM
– Isolationswald
- Visualisierung und Dimensionsreduktion
—Hauptkomponentenanalyse (PCA)
– Kernel-PCA
– Lokal lineare Einbettung (LLE)
—t-Verteilte stochastische Nachbareinbettung (t-SNE)
Q63. Was sind einige gängige Methoden für die Hyperparameter-Abstimmung?
Antwort. Es gibt mehrere gängige Methoden für die Hyperparameter-Abstimmung:
Grid-Suche: Hierbei wird ein Wertesatz für jeden Hyperparameter angegeben, und das Modell wird anhand einer Kombination aller möglichen Hyperparameterwerte trainiert und bewertet. Dies kann rechenintensiv sein, da die Anzahl der Kombinationen exponentiell mit der Anzahl der Hyperparameter wächst.
Zufallssuche: Dies beinhaltet das Abtasten zufälliger Kombinationen von Hyperparametern und das Trainieren und Bewerten des Modells für jede Kombination. Dies ist weniger rechenintensiv als die Rastersuche, kann jedoch weniger effektiv sein, um den optimalen Satz von Hyperparametern zu finden.
Q64. Wie legen Sie die Größe Ihrer Validierungs- und Testsets fest?
Antwort. Die Größe des Datensatzes: Je größer der Datensatz, desto größer können im Allgemeinen die Validierungs- und Testdatensätze sein. Dies liegt daran, dass mit mehr Daten gearbeitet werden kann, sodass die Validierungs- und Testsätze repräsentativer für den Gesamtdatensatz sein können.
Die Komplexität des Modells: Wenn das Modell sehr einfach ist, sind möglicherweise nicht so viele Daten zum Validieren und Testen erforderlich. Wenn das Modell andererseits sehr komplex ist, sind möglicherweise mehr Daten erforderlich, um sicherzustellen, dass es robust ist und sich gut auf unsichtbare Daten verallgemeinern lässt.
Das Maß an Unsicherheit: Wenn erwartet wird, dass das Modell bei der Aufgabe sehr gut abschneidet, können die Validierungs- und Testsätze kleiner sein. Wenn die Leistung des Modells jedoch unsicher oder die Aufgabe sehr herausfordernd ist, kann es hilfreich sein, größere Validierungs- und Testsätze zu haben, um eine genauere Bewertung der Leistung des Modells zu erhalten.
Die verfügbaren Ressourcen: Die Größe der Validierungs- und Testsätze kann auch durch die verfügbaren Rechenressourcen begrenzt sein. Es ist möglicherweise nicht praktikabel, sehr große Validierungs- und Testsätze zu verwenden, wenn das Trainieren und Evaluieren des Modells lange dauert.
Q65. Wie bewerten Sie die Leistung eines Modells für ein Klassifikationsproblem mit mehreren Klassen?
Antwort. Ein Ansatz zur Bewertung eines Mehrklassen-Klassifizierungsmodells besteht darin, eine separate Bewertungsmetrik für jede Klasse zu berechnen und dann einen Makro- oder Mikrodurchschnitt zu berechnen. Beim Makrodurchschnitt werden alle Klassen gleich gewichtet, während beim Mikrodurchschnitt die Klassen mit mehr Beobachtungen stärker gewichtet werden. Darüber hinaus können auch einige häufig verwendete Metriken für Mehrklassen-Klassifizierungsprobleme wie Konfusionsmatrix, Präzision, Erinnerung, F1-Score, Genauigkeit und ROC-AUC verwendet werden.
Q66. Was ist der Unterschied zwischen statistischem Lernen und maschinellem Lernen mit ihren Beispielen?
Antwort. Statistisches Lernen und maschinelles Lernen sind beides Methoden, die verwendet werden, um Vorhersagen oder Entscheidungen auf der Grundlage von Daten zu treffen. Es gibt jedoch einige wesentliche Unterschiede zwischen den beiden Ansätzen:
Statistisches Lernen konzentriert sich darauf, Vorhersagen oder Entscheidungen auf der Grundlage eines statistischen Modells der Daten zu treffen. Ziel ist es, die Beziehungen zwischen den Variablen in den Daten zu verstehen und auf der Grundlage dieser Beziehungen Vorhersagen zu treffen. Maschinelles Lernen hingegen konzentriert sich darauf, Vorhersagen oder Entscheidungen auf der Grundlage von Mustern in den Daten zu treffen, ohne unbedingt zu versuchen, die Beziehungen zwischen den Variablen zu verstehen.
Statistische Lernmethoden beruhen oft auf starken Annahmen über die Datenverteilung, wie etwa Normalität oder Unabhängigkeit von Fehlern. Methoden des maschinellen Lernens sind dagegen oft robuster gegenüber Verstößen gegen diese Annahmen.
Statistische Lernmethoden sind im Allgemeinen besser interpretierbar, da das statistische Modell verwendet werden kann, um die Beziehungen zwischen den Variablen in den Daten zu verstehen. Methoden des maschinellen Lernens hingegen sind oft weniger interpretierbar, da sie eher auf Mustern in den Daten als auf expliziten Zusammenhängen zwischen Variablen beruhen.
Beispielsweise ist die lineare Regression ein statistisches Lernverfahren, das eine lineare Beziehung zwischen Prädiktor- und Zielvariablen annimmt und die Koeffizienten des linearen Modells unter Verwendung eines Optimierungsalgorithmus schätzt. Random Forests ist eine maschinelle Lernmethode, die ein Ensemble von Entscheidungsbäumen aufbaut und Vorhersagen basierend auf dem Durchschnitt der Vorhersagen der einzelnen Bäume trifft.
Q67. Inwiefern sind normalisierte Daten für die Erstellung von Modellen in der Datenwissenschaft von Vorteil?
Antwort. Verbesserte Modellleistung: Das Normalisieren der Daten kann die Leistung einiger Modelle für maschinelles Lernen verbessern, insbesondere solcher, die empfindlich auf die Größe der Eingabedaten reagieren. Beispielsweise kann die Normalisierung der Daten die Leistung von Algorithmen wie K-nächsten Nachbarn und neuronalen Netzen verbessern.
Einfacher Feature-Vergleich: Das Normalisieren der Daten kann es einfacher machen, die Wichtigkeit verschiedener Merkmale zu vergleichen. Ohne Normalisierung können Features mit großen Maßstäben das Modell dominieren, wodurch es schwierig wird, die relative Wichtigkeit anderer Features zu bestimmen.
Reduzierter Einfluss von Ausreißern: Das Normalisieren der Daten kann die Auswirkung von Ausreißern auf das Modell verringern, da sie zusammen mit den restlichen Daten herunterskaliert werden. Dies kann die Robustheit des Modells verbessern und verhindern, dass es durch Extremwerte beeinflusst wird.
Verbesserte Interpretierbarkeit: Das Normalisieren der Daten kann die Interpretation der Ergebnisse des Modells erleichtern, da die Koeffizienten und Merkmalswichtigkeiten alle auf derselben Skala liegen.
Es ist wichtig zu beachten, dass eine Normalisierung nicht immer für alle Modelle notwendig oder vorteilhaft ist. Es ist notwendig, die spezifischen Eigenschaften und Anforderungen der Daten und des Modells sorgfältig zu bewerten, um festzustellen, ob eine Normalisierung angemessen ist.
Intermediate Fragen im Vorstellungsgespräch
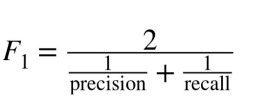
Q68. Warum wird im f1-Score der harmonische Mittelwert berechnet und nicht der Mittelwert?
Antwort.Der F1-Score ist eine Metrik, die Präzision und Erinnerung kombiniert. Präzision ist die Anzahl richtig positiver Ergebnisse dividiert durch die Gesamtzahl positiver Ergebnisse, die vom Klassifikator vorhergesagt wurden, und Recall ist die Anzahl richtig positiver Ergebnisse dividiert durch die Gesamtzahl positiver Ergebnisse in der Grundwahrheit. Zur Berechnung des F1-Scores wird das harmonische Mittel aus Precision und Recall verwendet, da es unausgewogenere Klassenanteile besser verzeiht als das arithmetische Mittel.
Wenn die harmonischen Mittel nicht verwendet würden, wäre der F1-Score höher, da er auf dem arithmetischen Mittel von Präzision und Erinnerung basieren würde, wodurch die hohe Präzision stärker und die niedrige Erinnerung weniger Gewicht erhalten würde. Die Verwendung des harmonischen Mittels im F1-Score hilft, die Präzision und den Abruf auszugleichen, und gibt eine genauere Gesamtbewertung der Leistung des Klassifikators.
Q69. Welche Möglichkeiten gibt es, Features auszuwählen?
Antwort. Hier sind einige Möglichkeiten, die Funktionen auszuwählen:
- Filtermethoden: Diese Methoden verwenden statistische Bewertungen, um die relevantesten Merkmale auszuwählen.
z.B.
- Korrelationskoeffizient: Wählt Merkmale aus, die stark mit der Zielvariablen korrelieren.
- Chi-Quadrat-Test: Wählt Merkmale aus, die von der Zielvariablen unabhängig sind.
- Wrapper-Methoden: Diese Methoden verwenden einen Lernalgorithmus, um die besten Merkmale auszuwählen.
z.B.
- Vorwärtsauswahl: Beginnt mit einem leeren Satz von Features und fügt jeweils ein Feature hinzu, bis die Leistung des Modells optimal ist.
- Rückwärtsauswahl: Beginnt mit dem vollständigen Funktionssatz und entfernt jeweils eine Funktion, bis die Leistung des Modells optimal ist.
- Eingebettete Methoden: Diese Methoden lernen, welche Merkmale am wichtigsten sind, während das Modell trainiert wird.
z.B.
- Lasso-Regression: Regularisiert das Modell durch Hinzufügen eines Strafterms zur Verlustfunktion, der die Koeffizienten der weniger wichtigen Merkmale auf null schrumpft.
- Ridge Regression: Regularisiert das Modell, indem der Verlustfunktion ein Strafterm hinzugefügt wird, der die Koeffizienten aller Merkmale gegen Null schrumpft, sie aber nicht auf Null setzt.
Feature-Bedeutung: Wir können auch den Merkmalswichtigkeitsparameter verwenden, der uns die wichtigsten vom Modell berücksichtigten Merkmale angibt
Q70. Was ist der Unterschied zwischen Bagging-Boosting-Unterschied?
Antwort. Sowohl Bagging als auch Boosting sind Ensemble-Lerntechniken, die zur Verbesserung der Leistung des Modells beitragen.
Bagging ist die Technik, bei der verschiedene Modelle auf dem uns vorliegenden Datensatz trainiert werden und dann der Durchschnitt der Vorhersagen dieser Modelle berücksichtigt wird. Die Intuition dahinter, die Vorhersagen aller Modelle zu nehmen und dann die Ergebnisse zu mitteln, führt zu vielfältigeren und verallgemeinerten Vorhersagen, die genauer sein können.
Boosting ist die Technik, bei der verschiedene Modelle trainiert werden, aber sie werden nacheinander trainiert. Jedes nachfolgende Modell korrigiert den Fehler des vorherigen Modells. Dies macht das Modell stark, was zu den geringsten Fehlern führt.
Q71. Was ist der Unterschied zwischen stochastischem Gradienten-Boosting und XGboost?
Antwort. XGBoost ist eine Implementierung von Gradient Boosting, die speziell auf Effizienz, Flexibilität und Portabilität ausgelegt ist. Stochastic XGBoost ist eine Variante von XGBoost, die einen stärker randomisierten Ansatz zum Erstellen von Entscheidungsbäumen verwendet, wodurch das resultierende Modell robuster gegenüber Überanpassung werden kann.
Sowohl XGBoost als auch stochastisches XGBoost sind beliebte Optionen zum Erstellen von Modellen für maschinelles Lernen und können für eine Vielzahl von Aufgaben verwendet werden, einschließlich Klassifizierung, Regression und Rangfolge. Der Hauptunterschied zwischen den beiden besteht darin, dass XGBoost einen deterministischen Baumkonstruktionsalgorithmus verwendet, während stochastischer XGBoost einen randomisierten Baumkonstruktionsalgorithmus verwendet.
Q72. Was ist der Unterschied zwischen Catboost und XGboost?
Antwort. Unterschied zwischen Catboost und XGboost:
Catboost verarbeitet kategoriale Funktionen besser als XGboost. In Catboost müssen die kategorialen Features nicht One-Hot-kodiert werden, was viel Zeit und Speicher spart. XGboost hingegen kann auch kategoriale Funktionen verarbeiten, aber sie mussten zuerst One-Hot-codiert werden.
XGboost erfordert eine manuelle Verarbeitung der Daten, während Catboost dies nicht tut. Sie unterscheiden sich in der Art und Weise, wie sie Entscheidungsbäume erstellen und Vorhersagen treffen.
Catboost ist schneller als XGboost und baut im Gegensatz zu XGboost symmetrische (ausgeglichene) Bäume auf.
Q73. Was ist der Unterschied zwischen linearen und nichtlinearen Klassifikatoren?
Antwort. Der Unterschied zwischen den linearen und nichtlinearen Klassifizierern ist die Art der Entscheidungsgrenze.
In einem linearen Klassifikator ist die Entscheidungsgrenze eine lineare Funktion der Eingabe. Mit anderen Worten, die Grenze ist eine gerade Linie, eine Ebene oder eine Hyperebene.
Bsp.: Lineare Regression, Logistische Regression, LDA
Ein nichtlinearer Klassifikator ist einer, bei dem die Entscheidungsgrenze keine lineare Funktion der Eingabe ist. Das bedeutet, dass der Klassifikator nicht durch eine lineare Funktion der Eingabemerkmale dargestellt werden kann. Nichtlineare Klassifikatoren können komplexere Beziehungen zwischen den Eingabemerkmalen und der Beschriftung erfassen, sie können jedoch auch anfälliger für eine Überanpassung sein, insbesondere wenn sie viele Parameter aufweisen.
Bsp.: KNN, Entscheidungsbaum, Random Forest
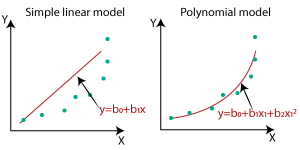
Q74. Was sind parametrische und nichtparametrische Modelle?
Antwort. Ein parametrisches Modell ist ein Modell, das durch eine feste Anzahl von Parametern beschrieben wird. Diese Parameter werden aus den Daten unter Verwendung eines Maximum-Likelihood-Schätzverfahrens oder eines anderen Verfahrens geschätzt und sie werden verwendet, um Vorhersagen über die Antwortvariable zu treffen.
Nichtparametrische Modelle hingegen sind Modelle, die keine Annahmen über die Form des Zusammenhangs zwischen abhängiger und unabhängiger Variable treffen. Sie sind im Allgemeinen flexibler als parametrische Modelle und können an eine größere Bandbreite von Datenformen angepasst werden, aber sie haben auch weniger interpretierbare Parameter und können schwieriger zu interpretieren sein.
Q75. Wie können wir Kreuzvalidierung verwenden, um Overfitting zu überwinden?
Antwort. Die Kreuzvalidierungstechnik kann verwendet werden, um zu identifizieren, ob das Modell unter- oder überangepasst ist, aber es kann nicht verwendet werden, um eines der Probleme zu überwinden. Wir können die Leistung des Modells nur mit zwei verschiedenen Datensätzen vergleichen und feststellen, ob die Daten über- oder unterangepasst oder verallgemeinert sind.
Q76. Wie kann man eine numerische Variable in eine kategoriale Variable umwandeln und wann kann es nützlich sein?
Antwort. Es gibt mehrere Möglichkeiten, eine numerische Variable in eine kategoriale Variable umzuwandeln. Eine gängige Methode ist die Verwendung von Klassierungen, bei denen die numerische Variable in eine Reihe von Klassen oder Intervallen unterteilt und jede Klasse als separate Kategorie behandelt wird.
Eine andere Möglichkeit, eine numerische Variable in eine kategoriale Variable umzuwandeln, ist die Verwendung einer Technik namens „Diskretisierung“, bei der der Bereich der numerischen Variablen in eine Reihe von Intervallen unterteilt und jedes Intervall als separate Kategorie behandelt wird. Dies kann nützlich sein, wenn Sie eine detailliertere Darstellung der Daten erstellen möchten.
Das Konvertieren einer numerischen Variablen in eine kategoriale Variable kann nützlich sein, wenn die numerische Variable eine begrenzte Anzahl von Werten annimmt und Sie diese Werte in Kategorien gruppieren möchten. Es kann auch nützlich sein, wenn Sie die zugrunde liegenden Muster oder Trends in den Daten hervorheben möchten, anstatt nur die nackten Zahlen.
Q77. Was sind verallgemeinerte lineare Modelle?
Antwort. Verallgemeinerte lineare Modelle (GLMs) sind eine Familie von Modellen, die es uns ermöglichen, die Beziehung zwischen einer Antwortvariablen und einer oder mehreren Prädiktorvariablen zu spezifizieren, während sie im Vergleich zu herkömmlichen linearen Modellen mehr Flexibilität in der Form dieser Beziehung ermöglichen. In einem herkömmlichen linearen Modell wird angenommen, dass die Antwortvariable normalverteilt ist, und die Beziehung zwischen der Antwortvariablen und den Prädiktorvariablen wird als linear angenommen. GLMs lockern diese Annahmen, indem sie die Verteilung der Antwortvariablen gemäß einer Vielzahl unterschiedlicher Verteilungen ermöglichen und nichtlineare Beziehungen zwischen den Antwort- und Prädiktorvariablen ermöglichen. Einige gängige Beispiele für GLMs sind die logistische Regression (für binäre Klassifizierungsaufgaben), die Poisson-Regression (für Zähldaten) und die exponentielle Regression (für die Modellierung von Time-to-Event-Daten).
Q78. Was ist der Unterschied zwischen Ridge- und Lasso-Regression? Wie unterscheiden sie sich hinsichtlich ihres Ansatzes zur Modellauswahl und Regularisierung?
Antwort. Ridge-Regression und Lasso-Regression sind beide Techniken, die verwendet werden, um eine Überanpassung in linearen Modellen zu verhindern, indem der Zielfunktion ein Regularisierungsterm hinzugefügt wird. Sie unterscheiden sich darin, wie sie den Regularisierungsbegriff definieren.
Bei der Ridge-Regression wird der Regularisierungsterm als die Summe der quadrierten Koeffizienten definiert (auch L2-Penalty genannt). Dies führt zu einer glatten Optimierungsoberfläche, die dem Modell helfen kann, besser auf unsichtbare Daten zu generalisieren. Die Ridge-Regression hat den Effekt, dass die Koeffizienten gegen Null getrieben werden, aber sie setzt keine Koeffizienten genau auf Null. Das bedeutet, dass alle Features im Modell erhalten bleiben, aber ihre Auswirkung auf die Ausgabe reduziert wird.
Andererseits definiert die Lasso-Regression den Regularisierungsterm als die Summe der Absolutwerte der Koeffizienten (auch als L1-Penalty bezeichnet). Dies hat den Effekt, dass einige Koeffizienten genau auf Null gesetzt werden, wodurch effektiv eine Teilmenge der Merkmale ausgewählt wird, die in dem Modell verwendet werden sollen. Dies kann für die Merkmalsauswahl nützlich sein, da es dem Modell ermöglicht, automatisch die wichtigsten Merkmale auszuwählen. Die Optimierungsoberfläche für die Lasso-Regression ist jedoch nicht glatt, was das Trainieren des Modells erschweren kann.
Zusammenfassend lässt sich sagen, dass die Ridge-Regression die Koeffizienten aller Merkmale gegen Null schrumpft, während die Lasso-Regression einige Koeffizienten genau auf Null setzt. Beide Techniken können nützlich sein, um eine Überanpassung zu verhindern, unterscheiden sich jedoch darin, wie sie die Modellauswahl und -regularisierung handhaben.
Q79.Wie wirkt sich die Schrittweite (oder Lernrate) eines Optimierungsalgorithmus auf die Konvergenz des Optimierungsprozesses in der logistischen Regression aus?
Antwort. Die Schrittweite oder Lernrate bestimmt die Größe der Schritte, die der Optimierungsalgorithmus unternimmt, wenn er sich dem Minimum der Zielfunktion nähert. Bei der logistischen Regression ist die Zielfunktion die negative logarithmische Wahrscheinlichkeit des Modells, die wir minimieren möchten, um die optimalen Koeffizienten zu finden.
Wenn die Schrittweite zu groß ist, kann der Optimierungsalgorithmus über das Minimum hinausschießen und um dieses herum oszillieren, möglicherweise sogar divergieren statt konvergieren. Wenn andererseits die Schrittgröße zu klein ist, wird der Optimierungsalgorithmus sehr langsam fortschreiten und kann lange Zeit brauchen, um zu konvergieren.
Daher ist es wichtig, eine geeignete Schrittgröße zu wählen, um die Konvergenz des Optimierungsprozesses sicherzustellen. Im Allgemeinen kann eine größere Schrittweite zu einer schnelleren Konvergenz führen, erhöht jedoch auch das Risiko, das Minimum zu überschreiten. Eine kleinere Schrittgröße ist sicherer, aber auch langsamer.
Es gibt mehrere Ansätze zum Auswählen einer geeigneten Schrittgröße. Ein üblicher Ansatz besteht darin, für alle Iterationen eine feste Schrittgröße zu verwenden. Ein anderer Ansatz besteht darin, eine abnehmende Schrittgröße zu verwenden, die groß beginnt und mit der Zeit abnimmt. Dies kann dem Optimierungsalgorithmus helfen, am Anfang schneller voranzukommen und dann die Koeffizienten fein abzustimmen, wenn er sich dem Minimum nähert.
Q80. Was ist Overfitting in Entscheidungsbäumen und wie kann es gemildert werden?
Antwort. Eine Überanpassung in Entscheidungsbäumen tritt auf, wenn das Modell zu komplex ist und zu viele Verzweigungen hat, was zu einer schlechten Verallgemeinerung auf neue, unsichtbare Daten führt. Dies liegt daran, dass das Modell die Muster in den Trainingsdaten zu gut „gelernt“ hat und diese Muster nicht auf neue, unsichtbare Daten verallgemeinern kann.
Es gibt mehrere Möglichkeiten, die Überanpassung in Entscheidungsbäumen zu mindern:
Beschneidung: Dies beinhaltet das Entfernen von Zweigen aus dem Baum, die den Vorhersagen des Modells keinen signifikanten Wert hinzufügen. Das Beschneiden kann dazu beitragen, die Komplexität des Modells zu reduzieren und seine Generalisierungsfähigkeit zu verbessern.
Begrenzung der Baumtiefe: Indem Sie die Tiefe des Baums einschränken, können Sie verhindern, dass der Baum zu komplex wird und die Trainingsdaten zu stark anpasst.
Verwendung von Ensembles: Ensemble-Methoden wie Random Forests und Gradient Boosting können dazu beitragen, die Überanpassung zu reduzieren, indem die Vorhersagen mehrerer Entscheidungsbäume aggregiert werden.
Kreuzvalidierung verwenden: Indem Sie die Leistung des Modells bei mehreren Train-Test-Splits bewerten, können Sie die Generalisierungsleistung des Modells besser einschätzen und das Risiko einer Überanpassung verringern.
Q81. Warum wird SVM als Large-Margin-Klassifikator bezeichnet?
Antwort. SVM oder Support Vector Machine wird als Klassifikator mit großem Spielraum bezeichnet, weil er versucht, eine Hyperebene mit dem größtmöglichen Spielraum oder Abstand zwischen den positiven und negativen Klassen im Merkmalsraum zu finden. Der Rand ist der Abstand zwischen der Hyperebene und den nächsten Datenpunkten und wird verwendet, um die Entscheidungsgrenze des Modells zu definieren.
Durch die Maximierung des Spielraums kann der SVM-Klassifikator besser auf neue, unsichtbare Daten verallgemeinern und ist weniger anfällig für Überanpassung. Je größer die Spanne, desto geringer die Unsicherheit um die Entscheidungsgrenze und desto zuverlässiger ist das Modell in seinen Vorhersagen.
Daher ist es das Ziel des SVM-Algorithmus, eine Hyperebene mit dem größtmöglichen Rand zu finden, weshalb er als Klassifikator mit großem Rand bezeichnet wird.
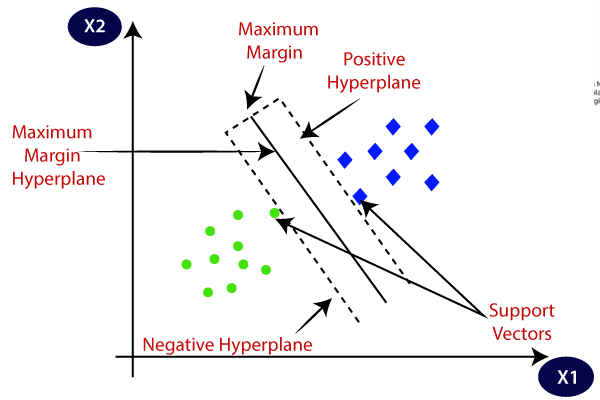
Q82. Was ist Scharnierverlust?
Antwort. Scharnierverlust ist eine Verlustfunktion, die in Support Vector Machines (SVMs) und anderen linearen Klassifizierungsmodellen verwendet wird. Es ist definiert als der Verlust, der entsteht, wenn eine Vorhersage falsch ist.
Der Scharnierverlust für ein einzelnes Beispiel ist definiert als:
Verlust = max(0, 1 – y * f(x))
Dabei ist y das wahre Label (entweder -1 oder 1) und f(x) die vorhergesagte Ausgabe des Modells. Die vorhergesagte Ausgabe ist das Skalarprodukt zwischen den Eingabe-Features und den Modellgewichtungen plus einem Bias-Term.
Der Gelenkverlust wird in SVMs verwendet, da es sich um eine konvexe Funktion handelt, die Vorhersagen bestraft, die nicht zuverlässig und korrekt sind. Der Scharnierverlust ist gleich null, wenn die vorhergesagte Bezeichnung korrekt ist, und er nimmt zu, wenn das Vertrauen in die falsche Bezeichnung zunimmt. Dies ermutigt das Modell, sich auf seine Vorhersagen zu verlassen, aber auch vorsichtig zu sein und keine Vorhersagen zu treffen, die zu weit von der wahren Bezeichnung entfernt sind.
Erweiterte Interviewfragen
Q83. Was passiert, wenn wir die Anzahl der Nachbarn in KNN erhöhen?
Antwort. Wenn Sie die Anzahl der Nachbarn auf einen sehr großen Wert in KNN erhöhen, wird der Klassifikator immer konservativer und die Entscheidungsgrenze wird immer glatter. Dies kann helfen, eine Überanpassung zu reduzieren, aber es kann auch dazu führen, dass der Klassifikator weniger empfindlich auf subtile Muster in den Trainingsdaten reagiert. Ein größerer Wert von k führt zu einem weniger komplexen Modell, das weniger anfällig für Überanpassung, aber anfälliger für Unteranpassung ist.
Um eine Überanpassung oder Unteranpassung zu vermeiden, ist es daher wichtig, einen geeigneten Wert von k zu wählen, der ein Gleichgewicht zwischen Komplexität und Einfachheit findet. Es ist normalerweise besser, verschiedene Werte für die Anzahl der Nachbarn auszuprobieren und zu sehen, welcher für einen bestimmten Datensatz am besten funktioniert.
Q84. Was passiert im Entscheidungsbaum, wenn die maximale Tiefe erhöht wird?
Antwort. Das Erhöhen der maximalen Tiefe eines Entscheidungsbaums erhöht die Komplexität des Modells und macht es anfälliger für Überanpassung. Wenn Sie die maximale Tiefe eines Entscheidungsbaums erhöhen, kann der Baum komplexere und differenziertere Entscheidungen treffen, was die Fähigkeit des Modells verbessern kann, die Trainingsdaten gut anzupassen. Wenn der Baum jedoch zu tief ist, kann er zu empfindlich auf die spezifischen Muster in den Trainingsdaten reagieren und sich nicht gut auf unsichtbare Daten verallgemeinern.
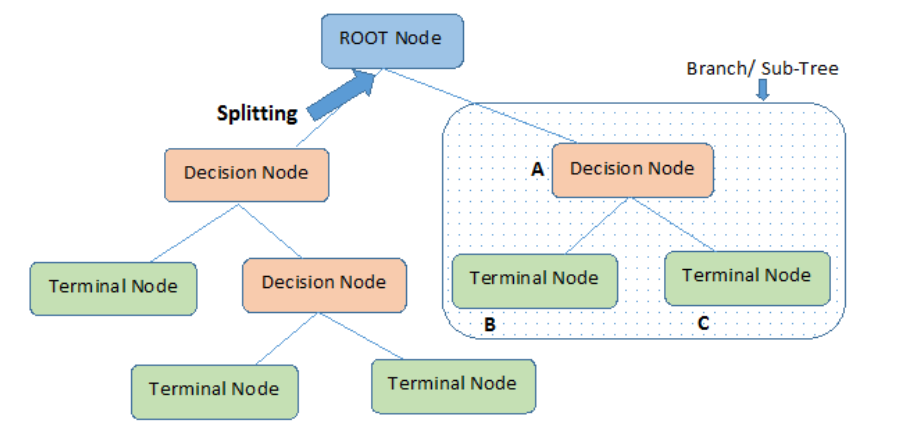
Q85. Was ist der Unterschied zwischen zusätzlichen Bäumen und zufälligen Wäldern?
Antwort. Der Hauptunterschied zwischen den beiden Algorithmen besteht darin, wie die Entscheidungsbäume aufgebaut sind.
In einer Zufälliger Waldwerden die Entscheidungsbäume unter Verwendung von Bootstrap-Stichproben der Trainingsdaten und einer zufälligen Teilmenge der Merkmale konstruiert. Dies führt dazu, dass jeder Baum mit einem etwas anderen Satz von Daten und Merkmalen trainiert wird, was zu einer größeren Baumvielfalt und einer geringeren Varianz führt.
In einem Extra Trees-Klassifikator werden die Entscheidungsbäume auf ähnliche Weise konstruiert, aber anstatt eine zufällige Teilmenge der Merkmale bei jeder Teilung auszuwählen, wählt der Algorithmus die beste Teilung aus einer zufälligen Teilmenge der Merkmale aus. Dies führt zu einer größeren Anzahl zufälliger Aufteilungen und einem höheren Grad an Zufälligkeit, was zu einer geringeren Verzerrung und einer höheren Varianz führt.
Q86. Wann sollte One-Hot-Encoding und Label-Encoding verwendet werden?
Antwort. One-Hot-Codierung und Label-Codierung sind zwei verschiedene Techniken, die verwendet werden können, um kategoriale Variablen als numerische Werte zu codieren. Sie werden häufig in maschinellen Lernmodellen als Vorverarbeitungsschritt verwendet, bevor das Modell an die Daten angepasst wird.
One-Hot-Codierung wird normalerweise verwendet, wenn Sie kategoriale Variablen haben, die keine ordinale Beziehung haben, dh die Kategorien haben keine natürliche Reihenfolge oder Rangordnung. One-Hot-Codierung erstellt neue binäre Spalten für jede Kategorie, wobei ein Wert von 1 das Vorhandensein der Kategorie angibt und ein Wert von 0 das Fehlen der Kategorie angibt. Dies kann nützlich sein, wenn Sie die Eindeutigkeit jeder Kategorie bewahren und verhindern möchten, dass das Modell ordinale Beziehungen zwischen den Kategorien annimmt.
Andererseits wird die Beschriftungskodierung normalerweise verwendet, wenn Sie kategoriale Variablen haben, die eine ordinale Beziehung haben, dh die Kategorien haben eine natürliche Reihenfolge oder Rangordnung. Die Label-Codierung weist jeder Kategorie einen eindeutigen ganzzahligen Wert zu, und die ganzzahligen Werte werden normalerweise durch die natürliche Reihenfolge der Kategorien bestimmt. Dies kann nützlich sein, wenn Sie die ordinalen Beziehungen zwischen den Kategorien beibehalten und dem Modell erlauben möchten, diese Informationen zu verwenden.
Im Allgemeinen ist es am besten, One-Hot-Codierung für nominale Daten (dh Daten, die keine inhärente Ordnung haben) und Label-Codierung für ordinale Daten (dh Daten, die eine inhärente Ordnung haben) zu verwenden. Die Wahl zwischen One-Hot-Codierung und Label-Codierung kann jedoch auch von den spezifischen Anforderungen Ihres Modells und den Eigenschaften Ihres Datensatzes abhängen.
Q87. Was ist das Problem bei der Verwendung der Etikettencodierung für nominale Daten?
Antwort. Die Beschriftungscodierung ist eine Methode zum Codieren kategorialer Variablen als numerische Werte, was in bestimmten Situationen von Vorteil sein kann. Es gibt jedoch einige potenzielle Probleme, die Sie beachten sollten, wenn Sie die Label-Codierung für nominale Daten verwenden.
Ein Problem bei der Bezeichnungskodierung besteht darin, dass sie eine ordinale Beziehung zwischen Kategorien erzeugen kann, wo keine existiert
Wenn Sie eine kategoriale Variable mit drei Kategorien haben: „Rot“, „Grün“ und „Blau“, und Sie eine Beschriftungscodierung anwenden, um diese Kategorien den numerischen Werten 0, 1 und 2 zuzuordnen, kann das Modell davon ausgehen, dass die Kategorie „ grün“ liegt irgendwie „zwischen“ den Kategorien „rot“ und „blau“. Dies kann ein Problem sein, wenn Ihr Modell von der Annahme abhängt, dass die Kategorien voneinander unabhängig sind.
Ein weiteres Problem bei der Beschriftungscodierung besteht darin, dass sie zu unerwarteten Ergebnissen führen kann, wenn Sie einen unausgeglichenen Datensatz haben. Wenn beispielsweise eine Kategorie viel häufiger vorkommt als die anderen, wird ihr ein viel niedrigerer numerischer Wert zugewiesen, was dazu führen könnte, dass das Modell ihr weniger Bedeutung beimisst, als sie verdient.
Q88. Wann kann One-Hot-Codierung ein Problem sein?
Antwort. Die One-Hot-Codierung kann in bestimmten Situationen ein Problem darstellen, da sie eine große Anzahl neuer Spalten im Datensatz erstellen kann, was die Arbeit mit den Daten erschweren und möglicherweise zu einer Überanpassung führen kann.
One-Hot-Codierung erstellt eine neue binäre Spalte für jede Kategorie in einer kategorialen Variablen. Wenn Sie eine kategoriale Variable mit vielen Kategorien haben, kann dies zu einer sehr großen Anzahl neuer Spalten führen.
Ein weiteres Problem bei der One-Hot-Codierung besteht darin, dass sie zu einer Überanpassung führen kann, insbesondere wenn Sie einen kleinen Datensatz und eine große Anzahl von Kategorien haben. Wenn Sie viele neue Spalten für jede Kategorie erstellen, erhöhen Sie effektiv die Anzahl der Features im Dataset. Dies kann zu einer Überanpassung führen, da das Modell zwar die Trainingsdaten speichern kann, sich aber nicht gut auf neue Daten verallgemeinern lässt.
Schließlich kann die One-Hot-Codierung auch ein Problem darstellen, wenn Sie dem Datensatz in Zukunft neue Kategorien hinzufügen müssen. Wenn Sie die vorhandenen Kategorien bereits One-Hot-codiert haben, müssen Sie darauf achten, dass die neuen Kategorien auf eine Weise hinzugefügt werden, die keine Verwirrung stiftet oder zu unerwarteten Ergebnissen führt.
Q89. Was kann eine geeignete Codierungstechnik sein, wenn Sie Hunderte von kategorialen Werten in einer Spalte haben?
Antwort. Einige Techniken können verwendet werden, wenn wir Hunderte von Spalten in einer kategorialen Variablen haben.
Häufigkeitscodierung: Dabei wird jede Kategorie durch die Häufigkeit dieser Kategorie im Datensatz ersetzt. Dies kann gut funktionieren, wenn die Kategorien basierend auf ihrer Häufigkeit eine natürliche ordinale Beziehung haben.
Zielcodierung: Dabei wird jede Kategorie durch den Mittelwert der Zielvariablen für diese Kategorie ersetzt. Dies kann effektiv sein, wenn die Kategorien einen klaren Bezug zur Zielvariablen haben.
Q90. Was sind die Quellen der Zufälligkeit im Random Forest?
Antwort. Random Forests sind eine Ensemble-Lernmethode, bei der mehrere Entscheidungsbäume auf verschiedenen Teilmengen der Daten trainiert und die Vorhersagen der einzelnen Bäume gemittelt werden, um eine endgültige Vorhersage zu treffen. Beim Training einer zufälligen Gesamtstruktur gibt es mehrere Zufälligkeitsquellen:
Bootstrap-Stichproben: Beim Training jedes Entscheidungsbaums erstellt der Algorithmus eine Bootstrap-Stichprobe der Daten, indem er Stichproben mit Ersetzung aus dem ursprünglichen Trainingssatz zieht. Dies bedeutet, dass einige Datenpunkte mehrfach in die Stichprobe aufgenommen werden, während andere überhaupt nicht enthalten sind. Dies erzeugt Variationen zwischen den Trainingssätzen verschiedener Bäume.
Zufällige Merkmalsauswahl: Beim Training jedes Entscheidungsbaums wählt der Algorithmus eine zufällige Teilmenge der Merkmale aus, die bei jeder Teilung berücksichtigt werden sollen. Dies bedeutet, dass unterschiedliche Bäume unterschiedliche Sätze von Merkmalen berücksichtigen, was zu Variationen in den erlernten Bäumen führt.
Zufällige Schwellenwertauswahl: Beim Training jedes Entscheidungsbaums wählt der Algorithmus einen zufälligen Schwellenwert für jedes Merkmal aus, um die optimale Aufteilung zu bestimmen. Dies bedeutet, dass verschiedene Bäume an verschiedenen Schwellenwerten aufgeteilt werden, was zu Variationen in den gelernten Bäumen führt.
Durch die Einführung dieser Zufallsquellen können Random Forests die Überanpassung reduzieren und die Generalisierungsleistung im Vergleich zu einem einzelnen Entscheidungsbaum verbessern.
Q91. Wie entscheiden Sie, welches Feature an jedem Knoten des Baums aufgeteilt werden soll?
Antwort. Beim Trainieren eines Entscheidungsbaums muss der Algorithmus das Merkmal auswählen, auf das an jedem Knoten des Baums aufgeteilt werden soll. Es gibt mehrere Strategien, die verwendet werden können, um zu entscheiden, auf welche Funktion aufgeteilt werden soll, einschließlich:
Gierige Suche: Der Algorithmus wählt bei jedem Schritt das Merkmal aus, das ein Aufteilungskriterium (z. B. Informationsgewinn oder Gini-Verunreinigung) maximiert.
Zufallssuche: Der Algorithmus wählt bei jedem Schritt zufällig das Merkmal aus, auf das aufgeteilt werden soll.
Vollständige Suche: Der Algorithmus berücksichtigt alle möglichen Aufteilungen und wählt diejenige aus, die das Aufteilungskriterium maximiert.
Vorwärtssuche: Der Algorithmus beginnt mit einem leeren Baum und fügt Teilungen nacheinander hinzu, wobei er bei jedem Schritt die Teilung auswählt, die das Teilungskriterium maximiert.
Rückwärtssuche: Der Algorithmus beginnt mit einem ausgewachsenen Baum und spaltet einen nach dem anderen, wobei die zu entfernende Teilung ausgewählt wird, die zur kleinsten Abnahme des Teilungskriteriums führt.
Q92. Welche Bedeutung hat C in SVM?
Antwort. In dem Algorithmus der Support-Vektor-Maschine (SVM) ist der Parameter C ein Hyperparameter, der den Kompromiss zwischen der Maximierung des Spielraums und der Minimierung des Fehlklassifizierungsfehlers steuert.
Intuitiv bestimmt C die Strafe für die Fehlklassifizierung eines Trainingsbeispiels. Ein kleinerer Wert von C bedeutet eine größere Strafe für die Fehlklassifizierung, und daher versucht das Modell, alle Trainingsbeispiele korrekt zu klassifizieren (selbst wenn dies einen kleineren Spielraum bedeutet). Andererseits bedeutet ein größerer Wert von C eine geringere Strafe für die Fehlklassifizierung, und daher versucht das Modell, den Spielraum zu maximieren, selbst wenn dies zu einer Fehlklassifizierung einiger Trainingsbeispiele führt.
In der Praxis können Sie sich vorstellen, dass C die Flexibilität des Modells steuert. Ein kleinerer Wert von C führt zu einem starreren Modell, das möglicherweise anfälliger für Underfitting ist, während ein größerer Wert von C zu einem flexibleren Modell führt, das möglicherweise anfälliger für Overfitting ist.
Daher sollte der Wert von C sorgfältig unter Verwendung von Kreuzvalidierung gewählt werden, um den Bias-Varianz-Kompromiss auszugleichen und eine gute Generalisierungsleistung auf unsichtbaren Daten zu erzielen.
Q93. Wie wirken sich c und gamma auf die Überanpassung in SVM aus?
Antwort. In Support-Vektor-Maschinen (SVMs) werden der Regularisierungsparameter C und der Kernel-Parameter Gamma verwendet, um die Überanpassung zu kontrollieren.
C ist die Strafe für Fehlklassifikation. Ein kleinerer Wert von C bedeutet eine größere Strafe für eine Fehlklassifizierung, was bedeutet, dass das Modell konservativer ist und versucht, eine Fehlklassifizierung zu vermeiden. Dies kann zu einem Modell führen, das weniger anfällig für Überanpassung ist, aber auch zu einem Modell, das zu konservativ ist und eine schlechte Generalisierungsleistung aufweist.
Gamma ist ein Parameter, der die Komplexität des Modells steuert. Ein kleinerer Gammawert bedeutet ein komplexeres Modell, was zu einer Überanpassung führen kann. Ein größerer Gamma-Wert bedeutet ein einfacheres Modell, was helfen kann, eine Überanpassung zu verhindern, aber auch zu einem Modell führen kann, das zu einfach ist, um die zugrunde liegenden Beziehungen in den Daten genau zu erfassen.
Im Allgemeinen ist das Finden der optimalen Werte für C und Gamma ein Kompromiss zwischen Bias und Varianz, und es ist oft notwendig, verschiedene Werte auszuprobieren und die Leistung des Modells auf einem Validierungssatz zu bewerten, um die besten Werte für diese Parameter zu bestimmen.
Q94. Wie wählen Sie die Anzahl der Modelle aus, die in einem Boosting- oder Bagging-Ensemble verwendet werden sollen?
Antwort. Die Anzahl der in einem Ensemble zu verwendenden Modelle wird normalerweise durch den Kompromiss zwischen Leistung und Rechenaufwand bestimmt. Als allgemeine Faustregel gilt, dass eine Erhöhung der Anzahl von Modellen die Leistung des Ensembles verbessert, jedoch auf Kosten einer Erhöhung des Rechenaufwands.
In der Praxis wird die Anzahl der Modelle durch Kreuzvalidierung bestimmt, die verwendet wird, um die optimale Anzahl von Modellen basierend auf der gewählten Bewertungsmetrik zu bestimmen.
Q95. In welchen Szenarien werden Boosting und Bagging gegenüber einzelnen Modellen bevorzugt?
Antwort. Sowohl Boosting als auch Bagging werden im Allgemeinen in Szenarien bevorzugt, in denen die einzelnen Modelle eine hohe Varianz oder einen hohen Bias aufweisen und das Ziel darin besteht, die Gesamtleistung des Modells zu verbessern. Bagging wird im Allgemeinen verwendet, um die Varianz eines Modells zu reduzieren, während Boosting verwendet wird, um Verzerrungen zu reduzieren und den Generalisierungsfehler des Modells zu verbessern. Beide Methoden sind auch nützlich, wenn Sie mit Modellen arbeiten, die empfindlich auf die Trainingsdaten reagieren und eine hohe Wahrscheinlichkeit einer Überanpassung haben.
Q96. Können Sie die ROC-Kurve und den AUC-Score erklären und wie sie zur Bewertung der Leistung eines Modells verwendet werden?
Antwort. Eine ROC-Kurve (Receiver Operating Characteristic) ist eine grafische Darstellung der Leistung eines binären Klassifizierungsmodells. Es zeichnet die True-Positive-Rate (TPR) gegen die Falsch-Positiv-Rate (FPR) bei verschiedenen Schwellenwerten auf. AUC (Area Under the Curve) ist die Fläche unter der ROC-Kurve. Es gibt eine einzelne Zahl, die die Gesamtleistung des Modells darstellt. Die AUC ist nützlich, weil sie alle möglichen Schwellenwerte berücksichtigt und nicht nur einen einzelnen Punkt auf der ROC-Kurve.
Q97. Wie gehen Sie beim Festlegen des Schwellenwerts in einem binären Klassifizierungsproblem vor, wenn Sie die Genauigkeit und den Abruf selbst anpassen möchten?
Antwort. Beim Festlegen des Schwellenwerts in einem binären Klassifizierungsproblem ist es wichtig, den Kompromiss zwischen Genauigkeit und Erinnerung zu berücksichtigen. Präzision ist der Anteil wahrer positiver Vorhersagen an allen positiven Vorhersagen, während Recall der Anteil wahrer positiver Vorhersagen an allen tatsächlichen positiven Fällen ist.
Ein Ansatz zur Anpassung von Genauigkeit und Abruf besteht darin, zuerst ein Modell zu trainieren und dann seine Leistung an einem Validierungssatz zu bewerten. Das Validierungsset sollte eine ähnliche Verteilung positiver und negativer Fälle aufweisen wie das Testset für das Modell, das bereitgestellt wird.
Als Nächstes können Sie eine Konfusionsmatrix verwenden, um die Leistung des Modells zu visualisieren und den aktuellen Schwellenwert zu identifizieren, der zum Treffen von Vorhersagen verwendet wird. Eine Konfusionsmatrix zeigt die Anzahl der richtig positiven, falsch positiven, richtig negativen und falsch negativen Vorhersagen, die das Modell macht.
Von dort aus können Sie den Schwellenwert anpassen, um das Gleichgewicht zwischen Präzision und Rückruf zu ändern. Beispielsweise erhöht eine Erhöhung des Schwellenwerts die Präzision, verringert jedoch den Recall. Andererseits erhöht das Verringern des Schwellenwerts die Erinnerung und verringert die Präzision.
Es ist auch wichtig, den spezifischen Anwendungsfall und die Kosten von falsch negativen und falsch positiven Ergebnissen zu berücksichtigen. Bei bestimmten Anwendungen, wie z. B. der medizinischen Diagnose, kann es wichtiger sein, einen hohen Wiedererkennungswert zu haben (dh keine tatsächlichen positiven Fälle zu verpassen), selbst wenn dies bedeutet, eine geringere Genauigkeit zu akzeptieren. In anderen Fällen, wie z. B. der Betrugserkennung, kann es wichtiger sein, eine hohe Genauigkeit zu haben (dh keine legitimen Transaktionen als betrügerisch zu kennzeichnen), selbst wenn dies bedeutet, einen geringeren Rückruf zu akzeptieren.
Q98. Was ist der Unterschied zwischen LDA (Lineare Diskriminanzanalyse) und PCA (Hauptkomponentenanalyse)?
Antwort. LDA (Lineare Diskriminanzanalyse) und PCA (Hauptkomponentenanalyse) sind beides lineare Transformationstechniken, die verwendet werden, um die Dimensionalität eines Datensatzes zu reduzieren. Sie werden jedoch für unterschiedliche Zwecke verwendet und funktionieren auf unterschiedliche Weise.
PCA ist eine unüberwachte Technik, d. h. sie wird verwendet, um Muster in Daten ohne Bezugnahme auf bekannte Labels zu finden. Das Ziel von PCA ist es, die Richtungen (Hauptkomponenten) in den Daten zu finden, die die größte Varianz ausmachen. Diese Richtungen werden so gewählt, dass sie zueinander orthogonal (senkrecht) sind, und die erste Richtung die größte Varianz, die zweite Richtung die zweitgrößte Varianz usw. berücksichtigt. Sobald die Hauptkomponenten gefunden sind, können die Daten auf einen durch diese Komponenten definierten niederdimensionalen Unterraum projiziert werden, was zu einer neuen, niederdimensionalen Darstellung der Daten führt.
LDA hingegen ist eine überwachte Technik und wird verwendet, um einen niederdimensionalen Unterraum zu finden, der die Trennung zwischen verschiedenen Datenklassen maximiert. LDA wird häufig als Dimensionsreduktionstechnik für Klassifizierungsprobleme verwendet, beispielsweise bei der Gesichtserkennung, Iriserkennung und Fingerabdruckerkennung. Das Ziel von LDA ist es, eine Projektion der Daten zu finden, die die Klassen so gut wie möglich trennt.
Q99. Wie schneidet der Naive-Bayes-Algorithmus im Vergleich zu anderen überwachten Lernalgorithmen ab?
Antwort. Naiver Bayes ist ein einfacher und schneller Algorithmus, der gut mit hochdimensionalen Daten und kleinen Trainingssätzen funktioniert. Es funktioniert auch gut bei Datensätzen mit kategorialen Variablen und fehlenden Daten, die bei vielen realen Problemen üblich sind. Es eignet sich gut für die Textklassifizierung, Spam-Filterung und Stimmungsanalyse. Aufgrund der Annahme der Unabhängigkeit zwischen Merkmalen funktioniert es jedoch nicht gut bei Problemen mit hoher Korrelation zwischen Merkmalen. Außerdem werden die Interaktionen zwischen Funktionen häufig nicht erfasst, was bei einigen Datensätzen zu einer schlechten Leistung führen kann. Daher wird es oft als Basis oder Ausgangspunkt verwendet, und dann können andere Algorithmen wie SVM und Random Forest verwendet werden, um die Leistung zu verbessern.
Q100. Können Sie das Konzept des „Kernel-Tricks“ und seine Anwendung in Support Vector Machines (SVMs) erklären?
Antwort. Der Kernel-Trick ist eine Technik, mit der die Eingabedaten in SVMs in einen höherdimensionalen Merkmalsraum transformiert werden, wo sie linear trennbar werden. Der Kernel-Trick funktioniert, indem er das Standard-Innenprodukt im Eingaberaum durch eine Kernel-Funktion ersetzt, die das Skalarprodukt in einem höherdimensionalen Raum berechnet, ohne tatsächlich die Koordinaten der Daten in diesem Raum berechnen zu müssen. Dadurch können SVMs nichtlinear trennbare Daten verarbeiten, indem sie sie auf einen höherdimensionalen Raum abbilden, wo sie linear trennbar werden. Übliche Kernel-Funktionen, die in SVMs verwendet werden, umfassen den Polynom-Kernel, den Kern der radialen Basisfunktion (RBF) und den Sigmoid-Kernel.
Zusammenfassung
In diesem Artikel haben wir verschiedene datenwissenschaftliche Interviewfragen behandelt, die Themen wie KNN, lineare Regression, Naive Bayes, Random Forest usw. abdecken.
Die Arbeit von Data Scientists ist nicht einfach, aber sie ist lohnend und es gibt viele offene Stellen. Diese Data Science-Interviewfragen können Sie Ihrem idealen Job einen Schritt näher bringen. Bereiten Sie sich also auf die Strapazen der Interviewfragen vor und halten Sie sich über die Grundlagen der Datenwissenschaft auf dem Laufenden.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/01/top-100-data-science-interview-questions/

