Einleitung
In der Computer Vision gibt es verschiedene Techniken zur Erkennung lebender Objekte, darunter Faster R-CNN, SSD und YOLO. Jede Technik hat ihre Grenzen und Vorteile. Während Faster R-CNN möglicherweise eine hervorragende Genauigkeit aufweist, funktioniert es in Echtzeitszenarien möglicherweise nicht so gut, was zu einer Verschiebung in Richtung führt YOLO-Algorithmus.
Die Objekterkennung ist in der Computer Vision von grundlegender Bedeutung und ermöglicht es Maschinen, Objekte innerhalb eines Rahmens oder Bildschirms zu identifizieren und zu lokalisieren. Im Laufe der Jahre wurden verschiedene Objekterkennungsalgorithmen entwickelt, wobei sich YOLO als einer der erfolgreichsten herausstellte. Kürzlich wurde YOLOv8 eingeführt, wodurch die Fähigkeiten des Algorithmus weiter verbessert wurden.
In diesem umfassenden Leitfaden untersuchen wir drei wichtige Objekterkennungsalgorithmen: Faster R-CNN, SSD (Single Shot MultiBox Detector) und YOLOv8. Wir diskutieren die praktischen Aspekte der Implementierung dieser Algorithmen, einschließlich der Einrichtung einer virtuellen Umgebung und der Entwicklung einer Streamlit-Anwendung.
Lernziel
- Verstehen Sie Faster R-CNN, SSD und YOLO und analysieren Sie die Unterschiede zwischen ihnen.
- Sammeln Sie praktische Erfahrungen bei der Implementierung von Live-Objekterkennungssystemen mit OpenCV, Supervision und YOLOv8.
- Verständnis des Bildsegmentierungsmodells mithilfe der Roboflow-Annotation.
- Erstellen Sie eine Streamlit-Anwendung für eine einfache Benutzeroberfläche.
Lassen Sie uns untersuchen, wie Sie mit YOLOv8 eine Bildsegmentierung durchführen!
Inhaltsverzeichnis
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Schnelleres R-CNN
Faster R-CNN (Faster Region-based Convolutional Neural Network) ist ein auf Deep Learning basierender Objekterkennungsalgorithmus. Es wird mithilfe der Frameworks R-CNN und Fast R-CNN evaluiert und kann als Erweiterung von Fast R-CNN betrachtet werden.
Dieser Algorithmus führt das Region Proposal Network (RPN) ein, um Regionsvorschläge zu generieren und die in R-CNN verwendete selektive Suche zu ersetzen. Das RPN teilt Faltungsschichten mit dem Erkennungsnetzwerk und ermöglicht so ein effizientes End-to-End-Training.
Die generierten Regionsvorschläge werden dann zur Bounding-Box-Verfeinerung und Objektklassifizierung in ein Fast R-CNN-Netzwerk eingespeist.
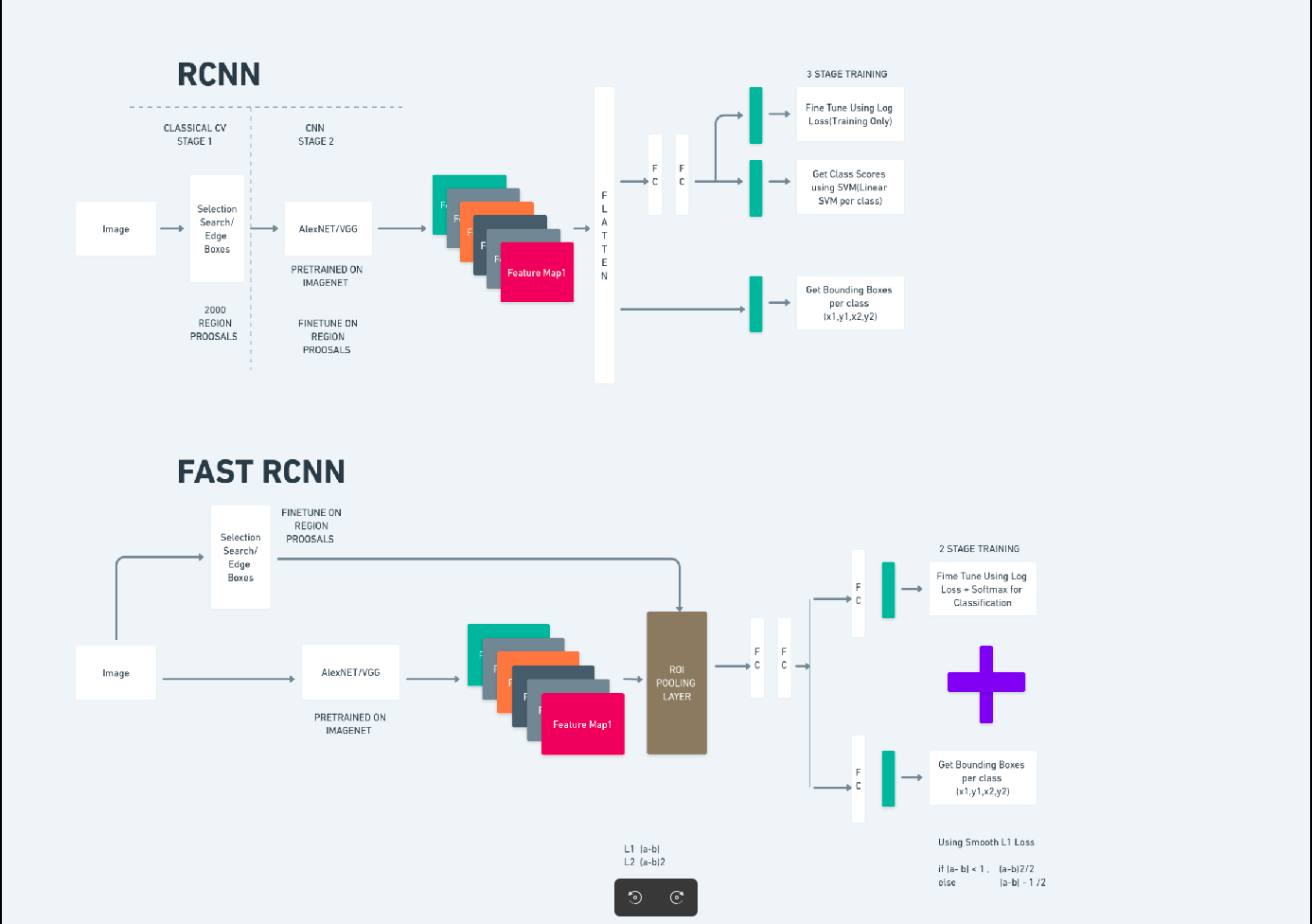
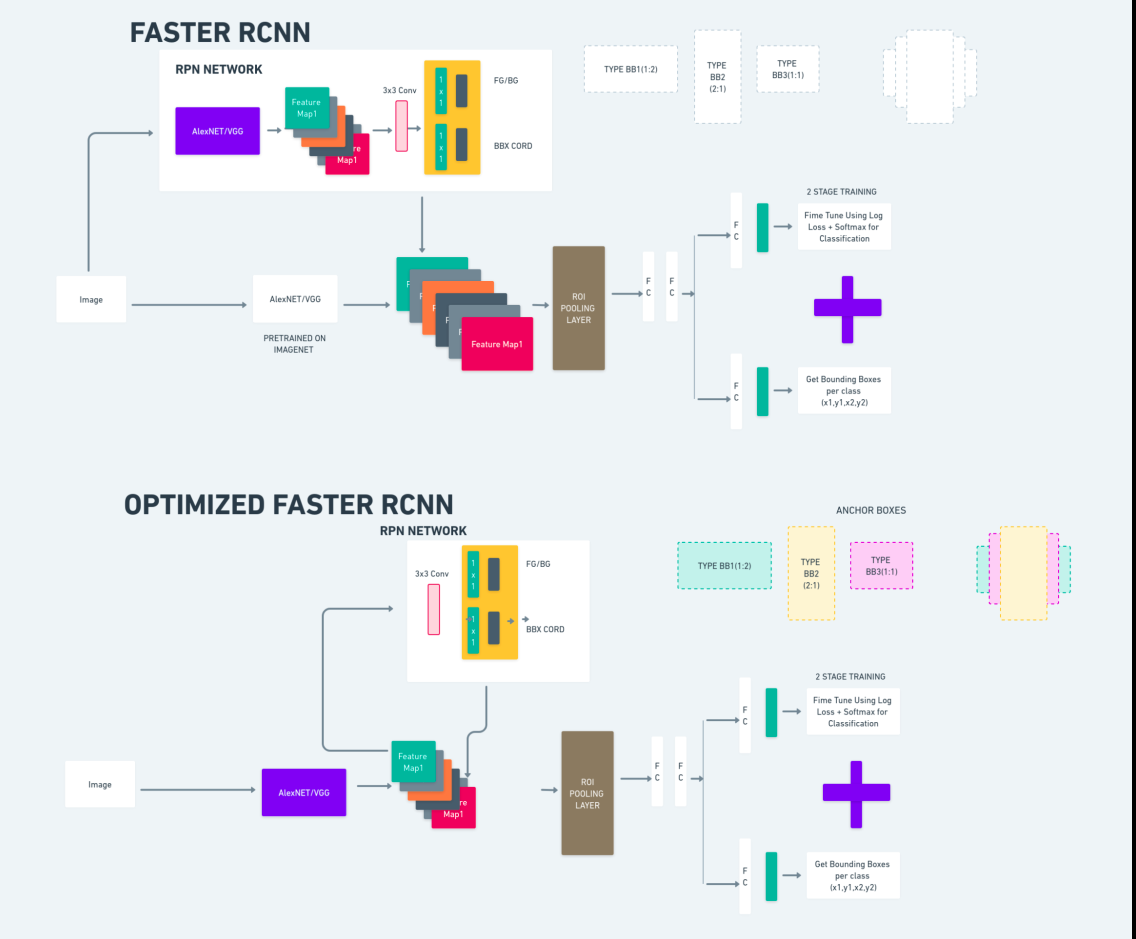
Das obige Diagramm veranschaulicht die Faster R-CNN-Familie umfassend und ist für die Bewertung jedes Algorithmus leicht verständlich.
Single-Shot-MultiBox-Detektor (SSD)
Das Single-Shot-MultiBox-Detektor (SSD) ist bei der Objekterkennung beliebt und wird hauptsächlich bei Computer-Vision-Aufgaben verwendet. Bei der vorherigen Methode, Faster R-CNN, folgten wir zwei Schritten: Der erste Schritt umfasste den Erkennungsteil und der zweite die Regression. Bei SSD führen wir jedoch nur einen einzigen Erkennungsschritt durch. SSD wurde 2016 eingeführt, um den Bedarf an einem schnellen und genauen Objekterkennungsmodell zu decken.

SSD hat mehrere Vorteile gegenüber früheren Objekterkennungsmethoden wie Faster R-CNN:
- Effizienz: SSD ist ein einstufiger Detektor, was bedeutet, dass er Begrenzungsrahmen und Klassenwerte direkt vorhersagt, ohne dass ein separater Schritt zur Angebotserstellung erforderlich ist. Dies macht ihn im Vergleich zu zweistufigen Detektoren wie Faster R-CNN schneller.
- End-to-End-Training: SSD kann Ende-zu-Ende trainiert werden, wodurch sowohl das Basisnetzwerk als auch der Erkennungskopf gemeinsam optimiert werden, was den Trainingsprozess vereinfacht.
- Multiskalige Feature-Fusion: SSD arbeitet mit Feature-Maps in mehreren Maßstäben und ermöglicht so die effektivere Erkennung von Objekten unterschiedlicher Größe.
SSD bietet ein gutes Gleichgewicht zwischen Geschwindigkeit und Genauigkeit und eignet sich daher für Echtzeitanwendungen, bei denen sowohl Leistung als auch Effizienz von entscheidender Bedeutung sind.
Man schaut nur einmal hin(YOLOv8)
Im Jahr 2015 wurde You Only Look Once (YOLO) als Objekterkennungsalgorithmus in einer Forschungsarbeit von Joseph Redmon, Santosh Divvala, Ross Girshick und Ali Farhadi vorgestellt. YOLO ist ein Single-Shot-Algorithmus, der ein Objekt in einem einzigen Durchgang direkt klassifiziert, indem nur ein neuronales Netzwerk mithilfe eines Vollbilds als Eingabe Begrenzungsrahmen und Klassenwahrscheinlichkeiten vorhersagt.
Betrachten wir nun YOLOv8 als modernste Weiterentwicklung der Echtzeit-Objekterkennung mit verbesserter Genauigkeit und Geschwindigkeit. Mit YOLOv8 können Sie vorab trainierte Modelle nutzen, die bereits auf einem riesigen Datensatz wie COCO (Common Objects in Context) trainiert wurden. Die Bildsegmentierung liefert Informationen auf Pixelebene zu jedem Objekt und ermöglicht so eine detailliertere Analyse und ein besseres Verständnis des Bildinhalts.
Während die Bildsegmentierung rechenintensiv sein kann, integriert YOLOv8 diese Methode in seine neuronale Netzwerkarchitektur und ermöglicht so eine effiziente und genaue Objektsegmentierung.
Funktionsprinzip von YOLOv8
YOlov8 funktioniert, indem das Eingabebild zunächst in Gitterzellen unterteilt wird. Mithilfe dieser Gitterzellen sagt YOLOv8 die Begrenzungsrahmen (bbox) mit Klassenwahrscheinlichkeiten voraus.
Anschließend verwendet YOLOv8 den NMS-Algorithmus, um Überlappungen zu reduzieren. Wenn beispielsweise mehrere Autos im Bild vorhanden sind, was zu überlappenden Begrenzungsrahmen führt, hilft der NMS-Algorithmus dabei, diese Überlappung zu reduzieren.
Unterschied zwischen den Varianten von Yolo V8: YOLOv8 ist in drei Varianten verfügbar: YOLOv8, YOLOv8-L und YOLOv8-X. Der Hauptunterschied zwischen den Varianten besteht in der Größe des Backbone-Netzwerks. YOLOv8 verfügt über das kleinste Backbone-Netzwerk, während YOLOv8-X über das größte Backbone-Netzwerk verfügt.
Unterschied zwischen schnellerem R-CNN, SSD und YOLO
| Aspekt | Schnelleres R-CNN | SSD | YOLO |
|---|---|---|---|
| Architektur | Zweistufiger Detektor mit RPN und Fast R-CNN | Einstufiger Detektor | Einstufiger Detektor |
| Vorschläge für Regionen | Ja | Nein | Nein |
| Erkennungsgeschwindigkeit | Langsamer im Vergleich zu SSD und YOLO | Schneller im Vergleich zu Faster R-CNN, langsamer als YOLO | Sehr schnelle |
| Genauigkeit | Generell höhere Genauigkeit | Ausgewogene Genauigkeit und Geschwindigkeit | Ordentliche Genauigkeit, insbesondere für Echtzeitanwendungen |
| Flexibilität | Flexibel, kann verschiedene Objektgrößen und Seitenverhältnisse verarbeiten | Kann Objekte in mehreren Maßstäben verarbeiten | Kann Schwierigkeiten mit der genauen Lokalisierung kleiner Objekte haben |
| Einheitliche Erkennung | Nein | Nein | Ja |
| Kompromiss zwischen Geschwindigkeit und Genauigkeit | Im Allgemeinen wird die Geschwindigkeit zugunsten der Genauigkeit geopfert | Gleicht Geschwindigkeit und Genauigkeit aus | Priorisiert die Geschwindigkeit und behält gleichzeitig eine angemessene Genauigkeit bei |
Was ist Segmentierung?
Wie wir wissen, bedeutet Segmentierung, dass wir das große Bild anhand bestimmter Merkmale in kleinere Gruppen unterteilen. Lassen Sie uns die Bildsegmentierung verstehen, die Computer-Vision-Technik, mit der ein Bild in verschiedene Segmente oder Regionen unterteilt wird. Da die Bilder aus Pixeln bestehen und bei der Bildsegmentierung werden Pixel entsprechend der Ähnlichkeit in Farbe, Intensität, Textur oder anderen visuellen Eigenschaften gruppiert.
Wenn ein Bild beispielsweise Bäume, Autos oder Menschen enthält, wird das Bild durch die Bildsegmentierung in verschiedene Klassen unterteilt, die bedeutungsvolle Objekte oder Teile des Bildes darstellen. Die Bildsegmentierung wird häufig in verschiedenen Bereichen wie der medizinischen Bildgebung, der Satellitenbildanalyse, der Objekterkennung in der Computer Vision und mehr eingesetzt.

Im Segmentierungsteil erstellen wir zunächst das erste YOLOv8-Segmentierungsmodell mit Robflow. Anschließend importieren wir das Segmentierungsmodell, um die Segmentierungsaufgabe auszuführen. Es stellt sich die Frage: Warum erstellen wir das Segmentierungsmodell, wenn die Aufgabe allein mit einem Erkennungsalgorithmus erledigt werden könnte?
Durch die Segmentierung können wir das vollständige Körperbild einer Klasse erhalten. Während sich Erkennungsalgorithmen auf die Erkennung der Anwesenheit von Objekten konzentrieren, ermöglicht die Segmentierung ein genaueres Verständnis, indem sie die genauen Grenzen von Objekten abgrenzt. Dies führt zu einer genaueren Lokalisierung und einem genaueren Verständnis der im Bild vorhandenen Objekte.
Allerdings ist die Segmentierung im Vergleich zu Erkennungsalgorithmen typischerweise mit einem höheren zeitlichen Aufwand verbunden, da sie zusätzliche Schritte wie das Trennen von Anmerkungen und das Erstellen des Modells erfordert. Trotz dieses Nachteils kann die durch die Segmentierung gebotene erhöhte Präzision den Rechenaufwand bei Aufgaben überwiegen, bei denen eine präzise Objektabgrenzung von entscheidender Bedeutung ist.
Schritt-für-Schritt-Live-Erkennung und Bildsegmentierung mit YOLOv8
In diesem Konzept untersuchen wir die Schritte zum Erstellen einer virtuellen Umgebung mit Conda, zum Aktivieren von Venv und zum Installieren der Anforderungspakete mit Pip. Zuerst erstellen wir das normale Python-Skript, dann erstellen wir die Streamlit-Anwendung.
Schritt 1: Erstellen Sie eine virtuelle Umgebung mit Conda
conda create -p ./venv python=3.8 -ySchritt 2: Aktivieren Sie die virtuelle Umgebung
conda activate ./venv
Schritt 3: Anforderungen.txt erstellen
Öffnen Sie das Terminal und fügen Sie das folgende Skript ein:
touch requirements.txtSchritt 4: Verwenden Sie den Nano-Befehl und bearbeiten Sie die Datei „requirements.txt“.
Nachdem Sie die Datei „requirements.txt“ erstellt haben, geben Sie den folgenden Befehl zum Bearbeiten der Datei „requirements.txt“ ein
nano requirements.txtNachdem Sie das obige Skript ausgeführt haben, können Sie diese Benutzeroberfläche sehen.
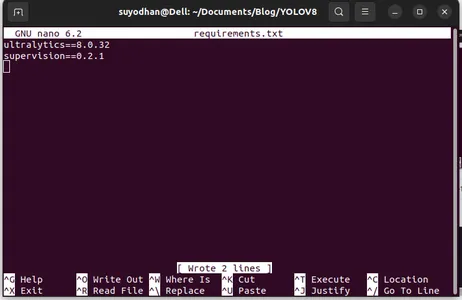
Schreiben Sie ihr die erforderlichen Pakete.
ultralytics==8.0.32
supervision==0.2.1
streamlitDrücken Sie dann die Taste „Strg+O“(Dieser Befehl speichert den Bearbeitungsteil) und drücken Sie dann die Taste "Eingeben"
Nach Drücken der „Strg+x“. Sie können die Datei verlassen. und zum Hauptweg gehen.
Schritt 5: Installation der Datei „requirements.txt“.
pip install -r requirements.txtSchritt 6: Erstellen Sie das Python-Skript
Schreiben Sie im Terminal das folgende Skript oder wir können Befehl sagen.
touch main.pyNachdem Sie main.py erstellt haben, öffnen Sie den vs-Code und verwenden Sie den Befehl write in terminal.
code Schritt 7: Schreiben des Python-Skripts
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Nachdem Sie diesen Befehl ausgeführt haben, können Sie sehen, dass Ihre Kamera geöffnet ist und einen Teil von Ihnen erkennt. wie Geschlecht und Hintergrundteile.
Schritt 7: Streamlit-App erstellen
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
In diesem Skript erstellen wir die Streamlit-Anwendung und die Schaltfläche, sodass nach dem Drücken der Schaltfläche die Kamera Ihres Geräts geöffnet ist und das Teil im Bild erkennt.
Führen Sie dieses Skript mit diesem Befehl aus.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Nehmen wir an, Sie erhalten nach der Ausführung des obigen Befehls den Reach-out-Fehler wie:
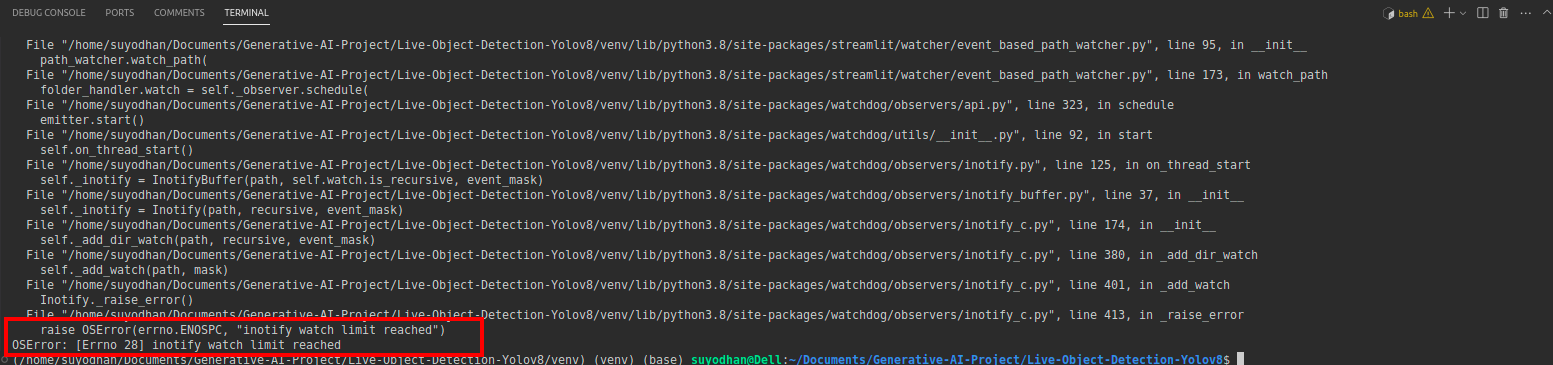
Drücken Sie dann diesen Befehl.
sudo sysctl fs.inotify.max_user_watches=524288Nachdem Sie den Befehl gedrückt haben, mit dem Sie Ihr Passwort schreiben möchten, da wir den Sudo-Befehl verwenden, ist „sudo is god“:)
Führen Sie das Skript erneut aus. und Sie können die Streamlit-Anwendung sehen.
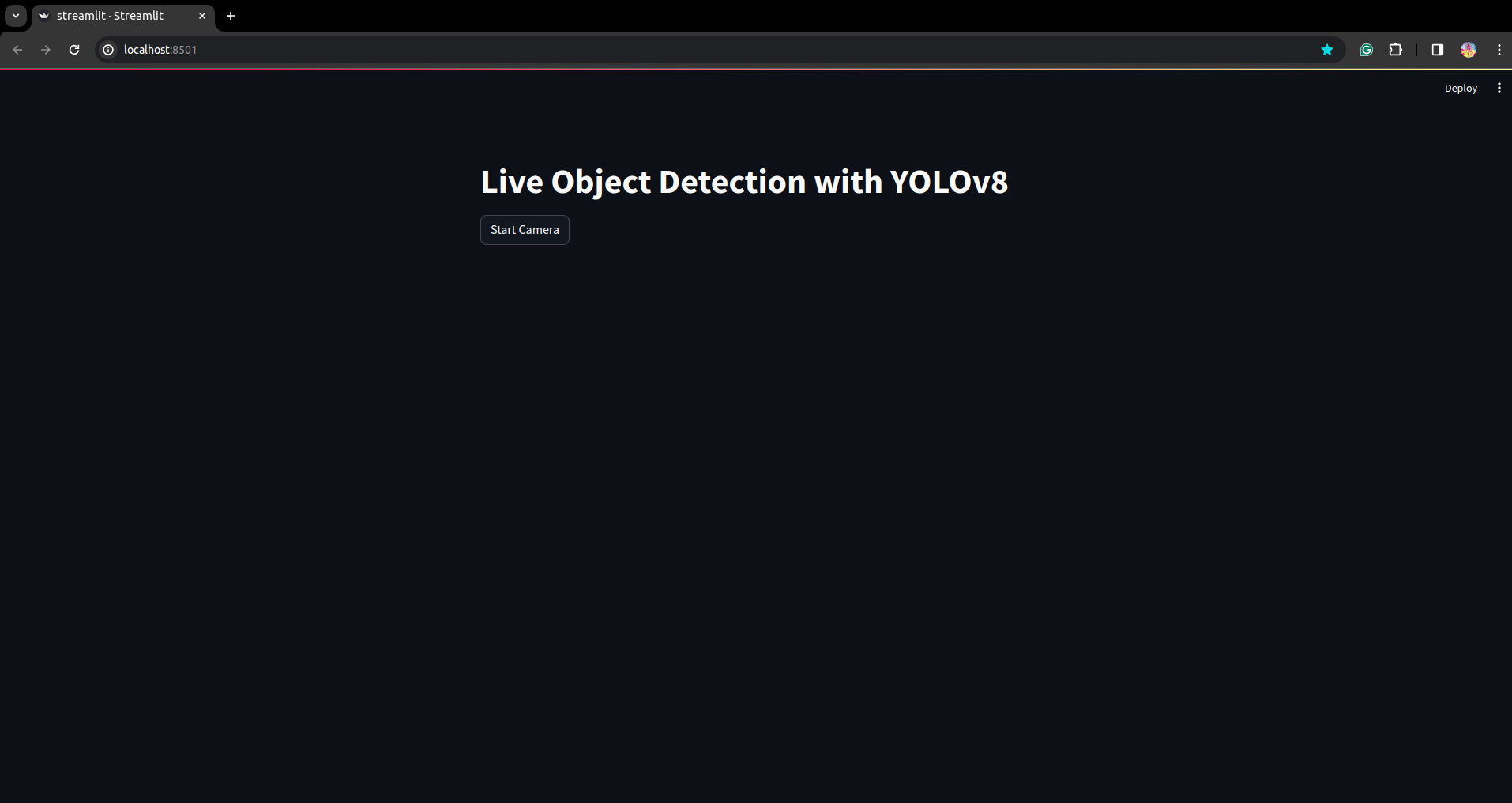
Hier können wir eine erfolgreiche Live-Erkennungsanwendung erstellen. Im nächsten Teil sehen wir uns den Segmentierungsteil an.
Schritte zur Anmerkung
Schritt 1: Roboflow-Setup
Nach der Unterzeichnung wird das „Projekt erstellen“. Hier können Sie das Projekt und die Anmerkungsgruppe erstellen.

Schritt 2: Herunterladen des Datensatzes
Hier betrachten wir das einfache Beispiel, aber Sie möchten es für Ihre Problemstellung verwenden, deshalb verwende ich hier den Duck-Datensatz.
Gehen Sie hierher Link und laden Sie den Entendatensatz herunter.

Extrahieren Sie den Ordner. Dort sehen Sie die drei Ordner: trainieren, testen und val.
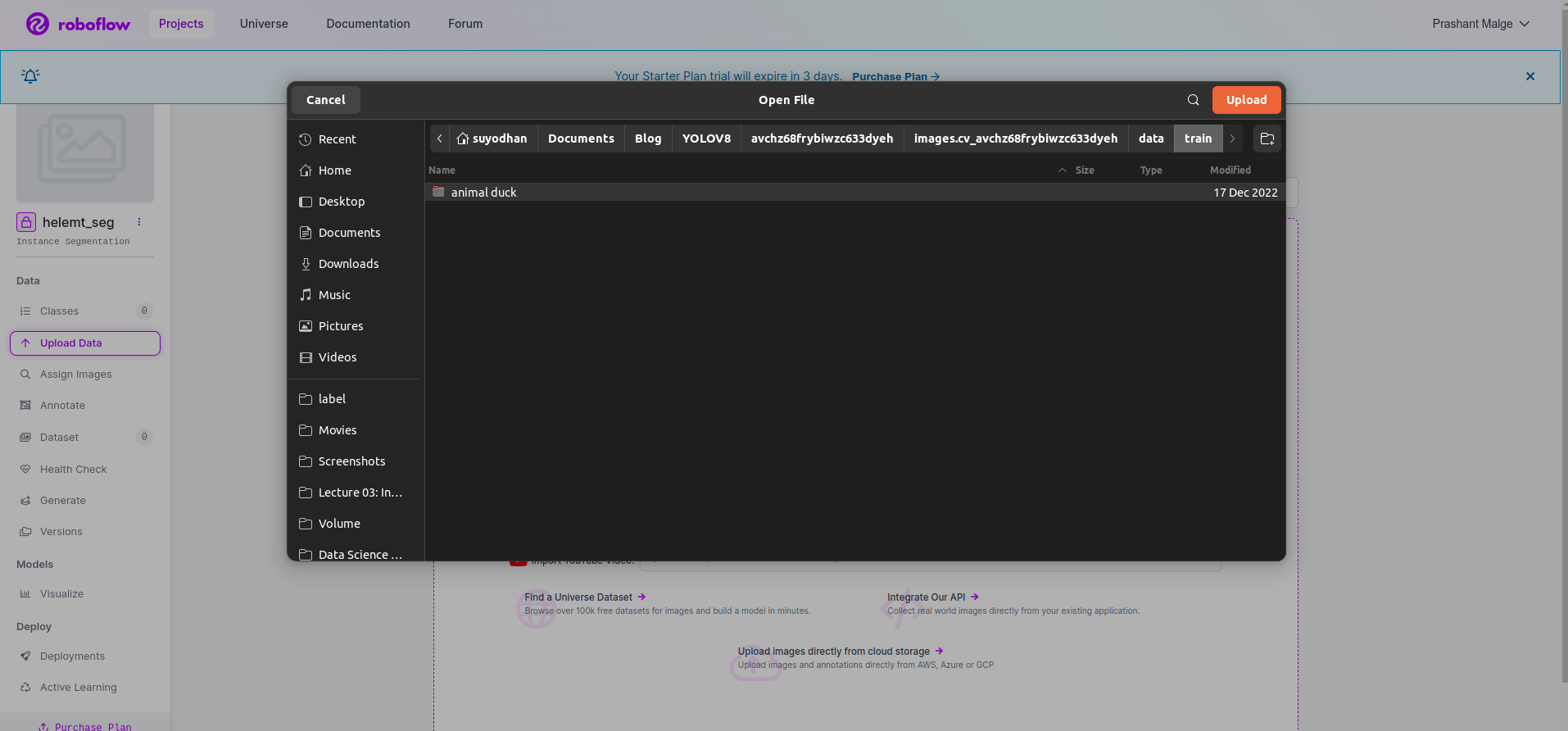
Schritt 3: Hochladen des Datensatzes auf Roboflow
Nachdem Sie das Projekt in Roboflow erstellt haben, können Sie diese Benutzeroberfläche hier sehen. Sie können Ihren Datensatz hochladen. Wenn Sie also nur Zugteilbilder hochladen möchten, wählen Sie „Ordner auswählen" .
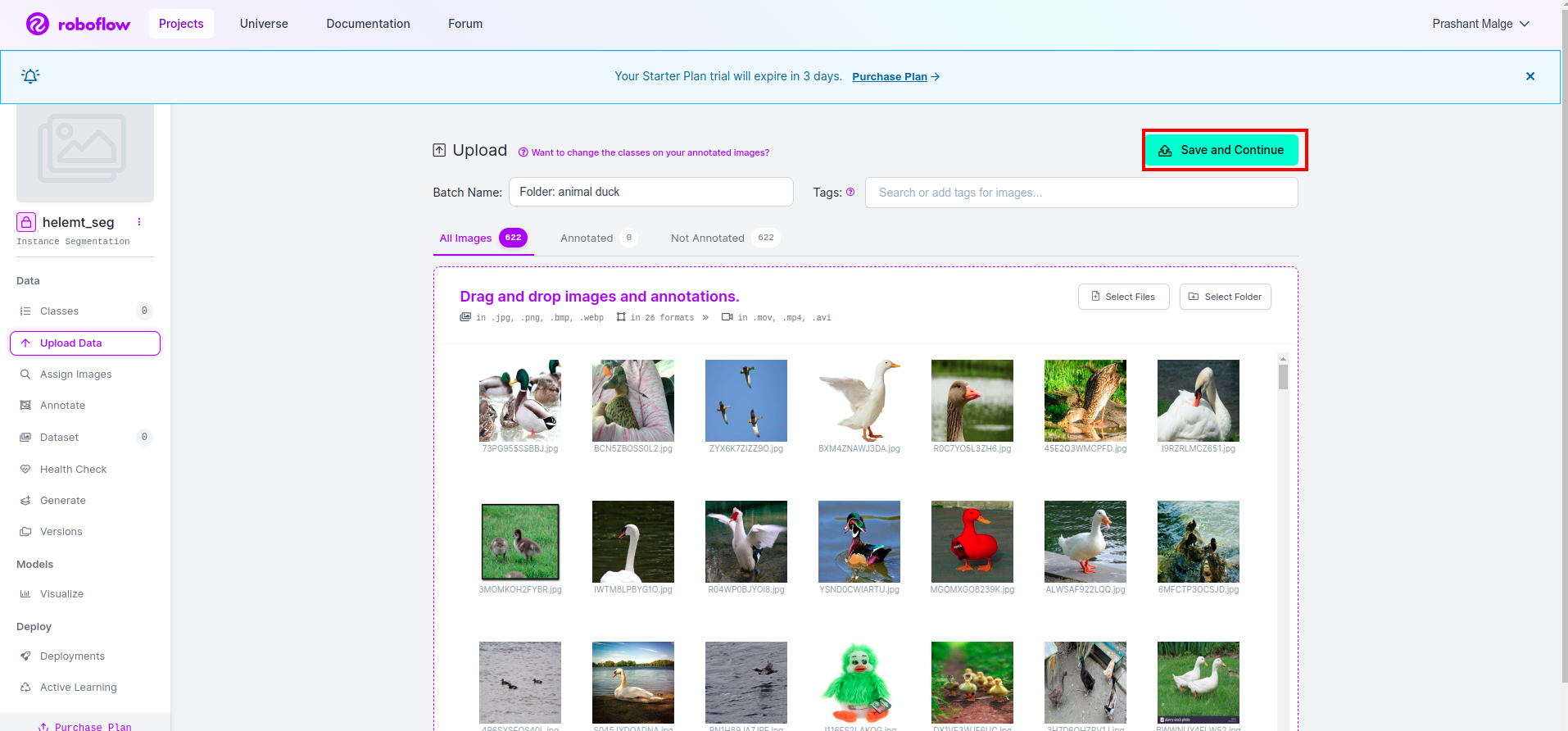
Dann klicke auf "speichern und fortfahren" Option, wie ich sie in einem roten Rechteckfeld markiere
Schritt 4: Fügen Sie den Klassennamen hinzu
Dann geh zum Klassenteil Klicken Sie auf der linken Seite auf das rote Kästchen. und schreiben Sie den Klassennamen als Ente, nachdem Sie auf das grüne Kästchen geklickt haben.
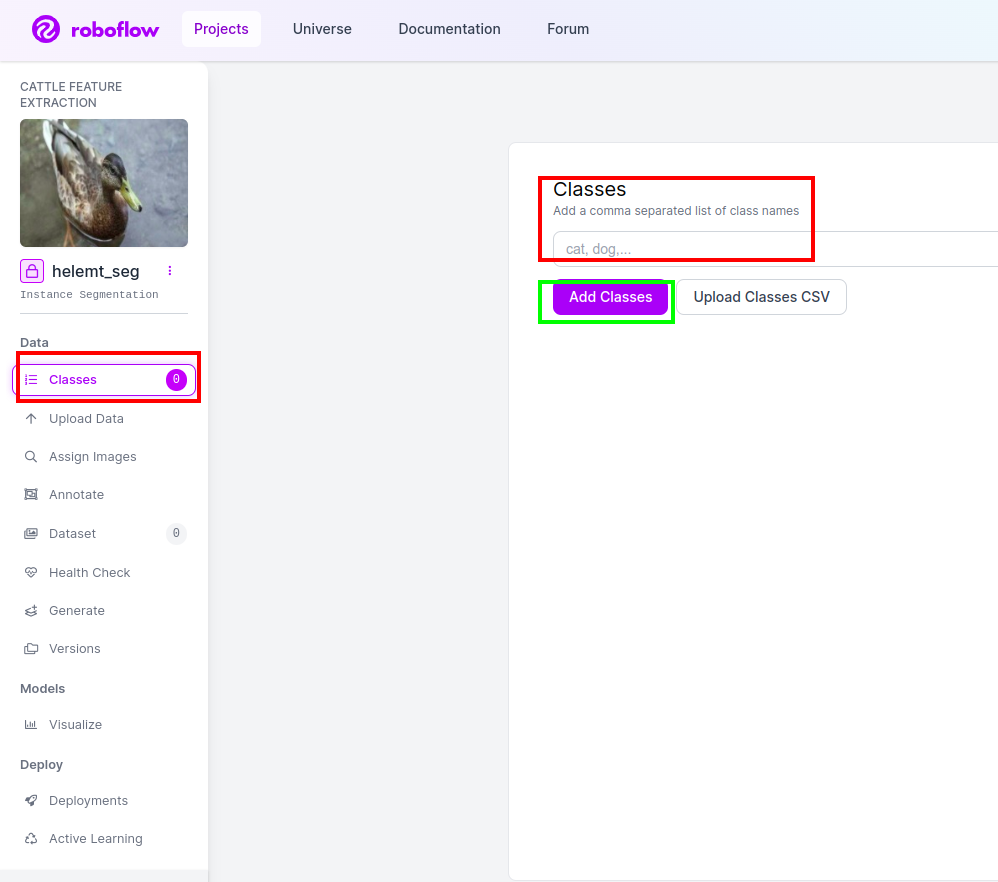
Jetzt ist unser Setup abgeschlossen und der nächste Teil wie der Anmerkungsteil ist ebenfalls einfach.
Schritt 5: Starten Sie die Anmerkungsteil
Gehen Sie zum Anmerkungsoption Ich habe im roten Feld markiert und dann auf „Starten des Anmerkungsteils“ geklickt, wie ich es im grünen Feld markiert habe.
Klicken Sie auf das erste Bild, um diese Benutzeroberfläche zu sehen. Nachdem Sie dies gesehen haben, klicken Sie auf die Option für manuelle Anmerkungen.
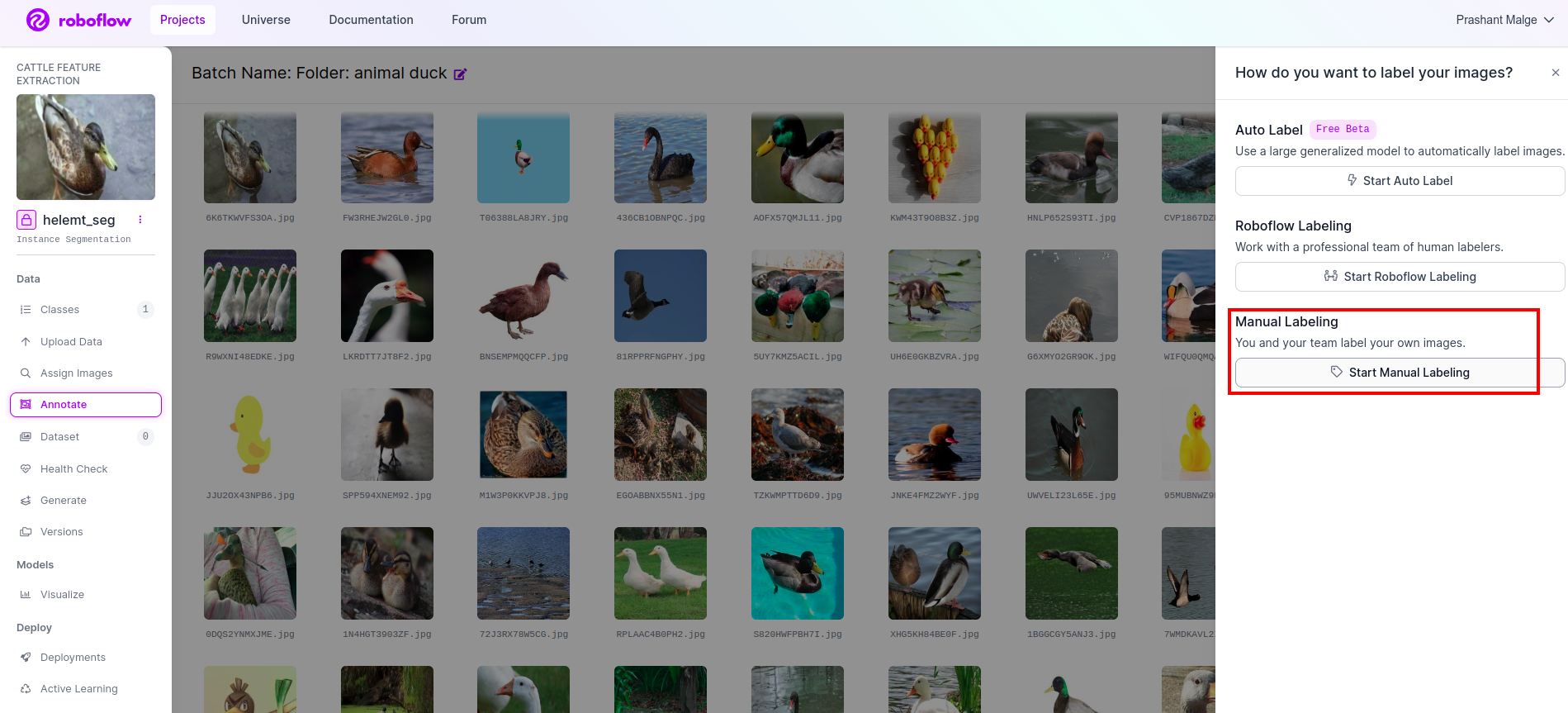
Fügen Sie dann Ihre E-Mail-ID oder den Namen Ihres Teamkollegen hinzu, damit Sie die Aufgabe zuweisen können.
Klicken Sie auf das erste Bild, um diese Benutzeroberfläche zu sehen. Klicken Sie hier auf das rote Kästchen, damit Sie das Multipolynommodell auswählen können.
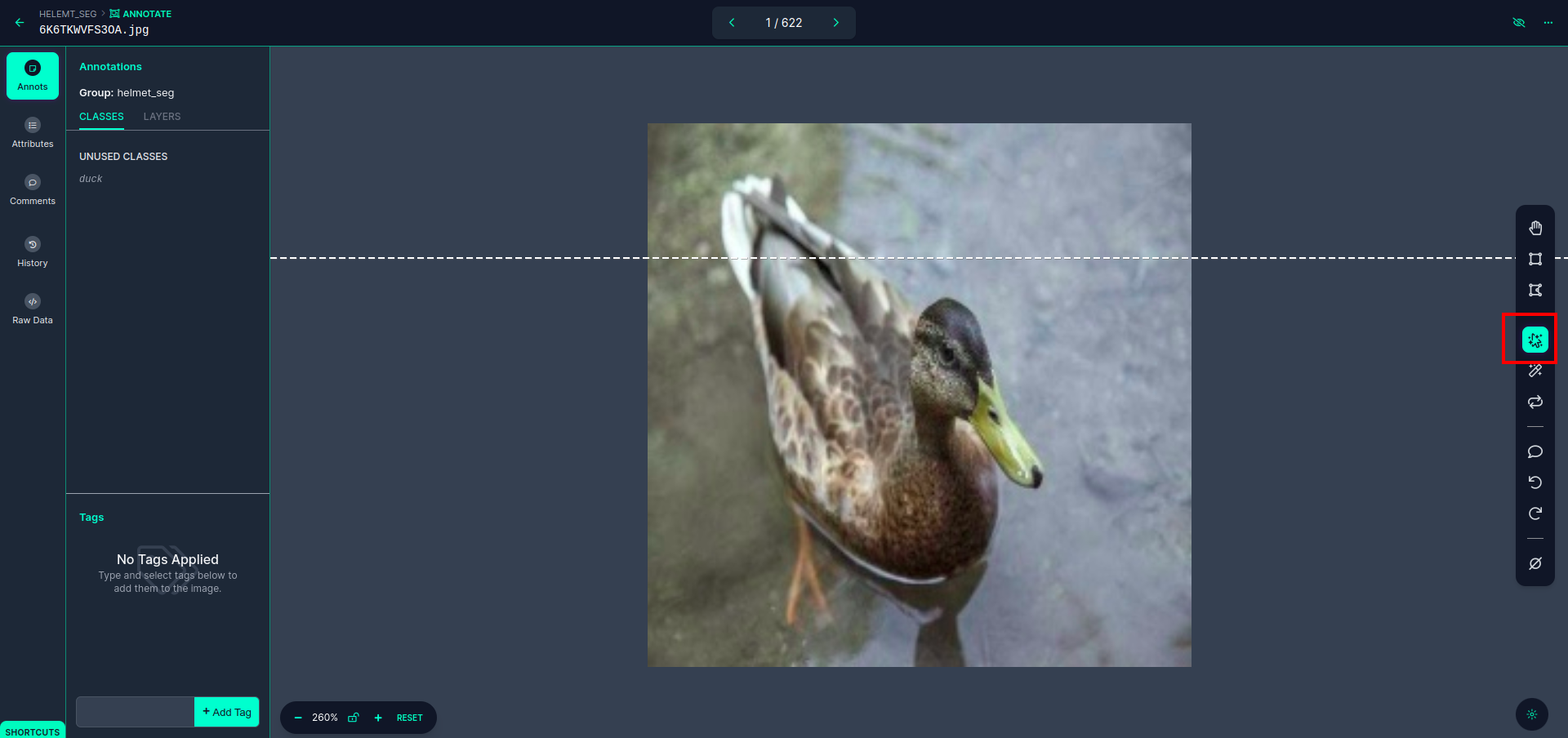
Nachdem Sie auf das rote Kästchen geklickt haben, wählen Sie das Standardmodell aus und klicken Sie auf das Entenobjekt. Dadurch wird das Bild automatisch segmentiert. Klicken Sie dann auf den nächsten Teil und speichern Sie ihn. Sie sehen dann die linke Seite, die in einem roten Feld markiert ist, wo Sie den Klassennamen sehen können.
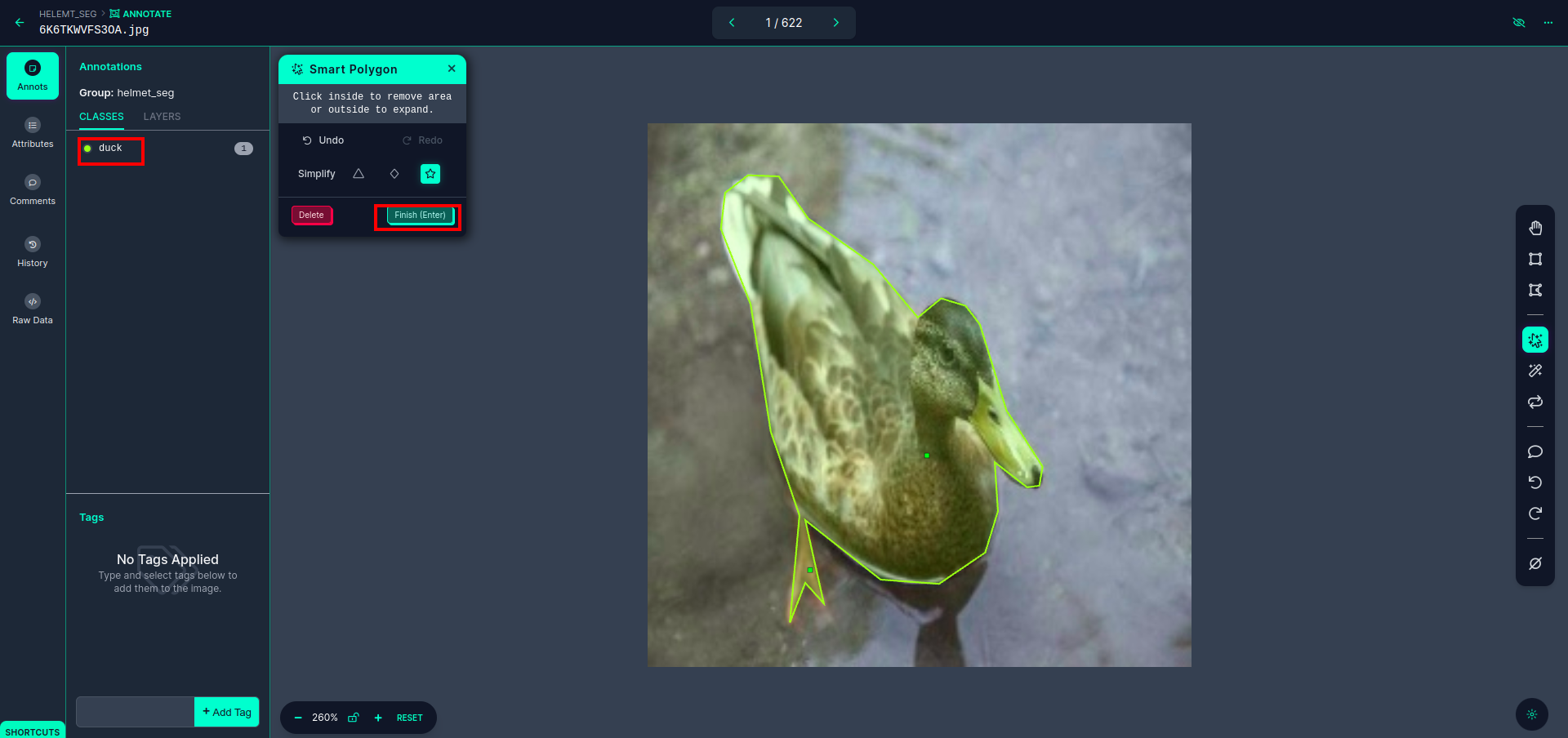
Klicken Sie auf die Speichern und eingeben Möglichkeit. Kommentieren Sie alle Bilder.
Fügen Sie die Bilder für das YOLOv8-Format hinzu. Auf der rechten Seite sehen Sie die Option zum Hinzufügen von Bildern im Anmerkungsbereich. Hier werden zwei Teile erstellt: einer für annotierte Bilder und einer für nicht annotierte Bilder.
- Klicken Sie zunächst links auf „kommentieren" Option dann hinzufügen die Bilder zum Datensatz.
- Klicken Sie dann auf „Weiter“Füge Bilder hinzu".
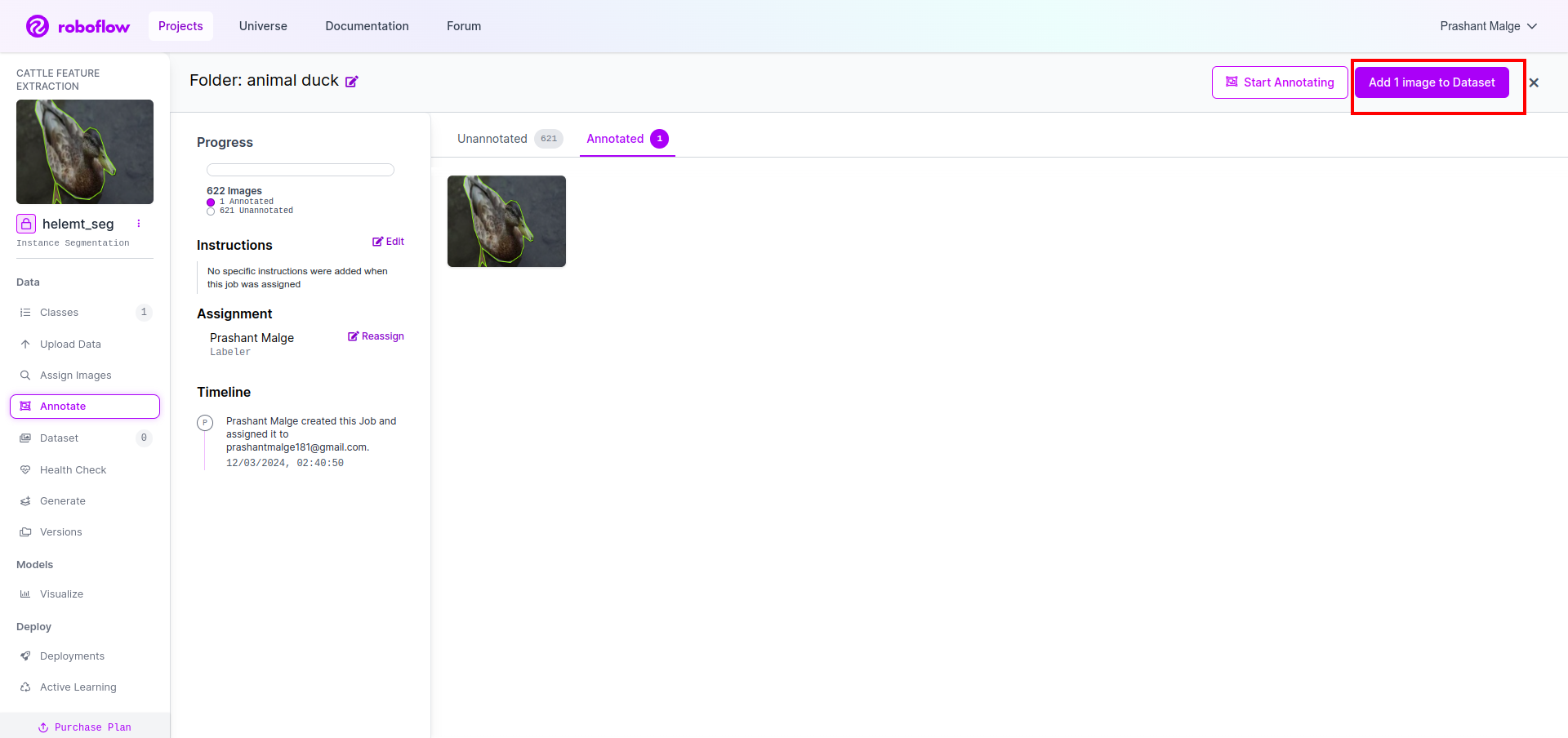
Als letztes erstellen wir nun den Datensatz. Klicken Sie also auf der linken Seite auf die Option „Generieren“, aktivieren Sie die Option und klicken Sie auf die Option „Konitieren“.
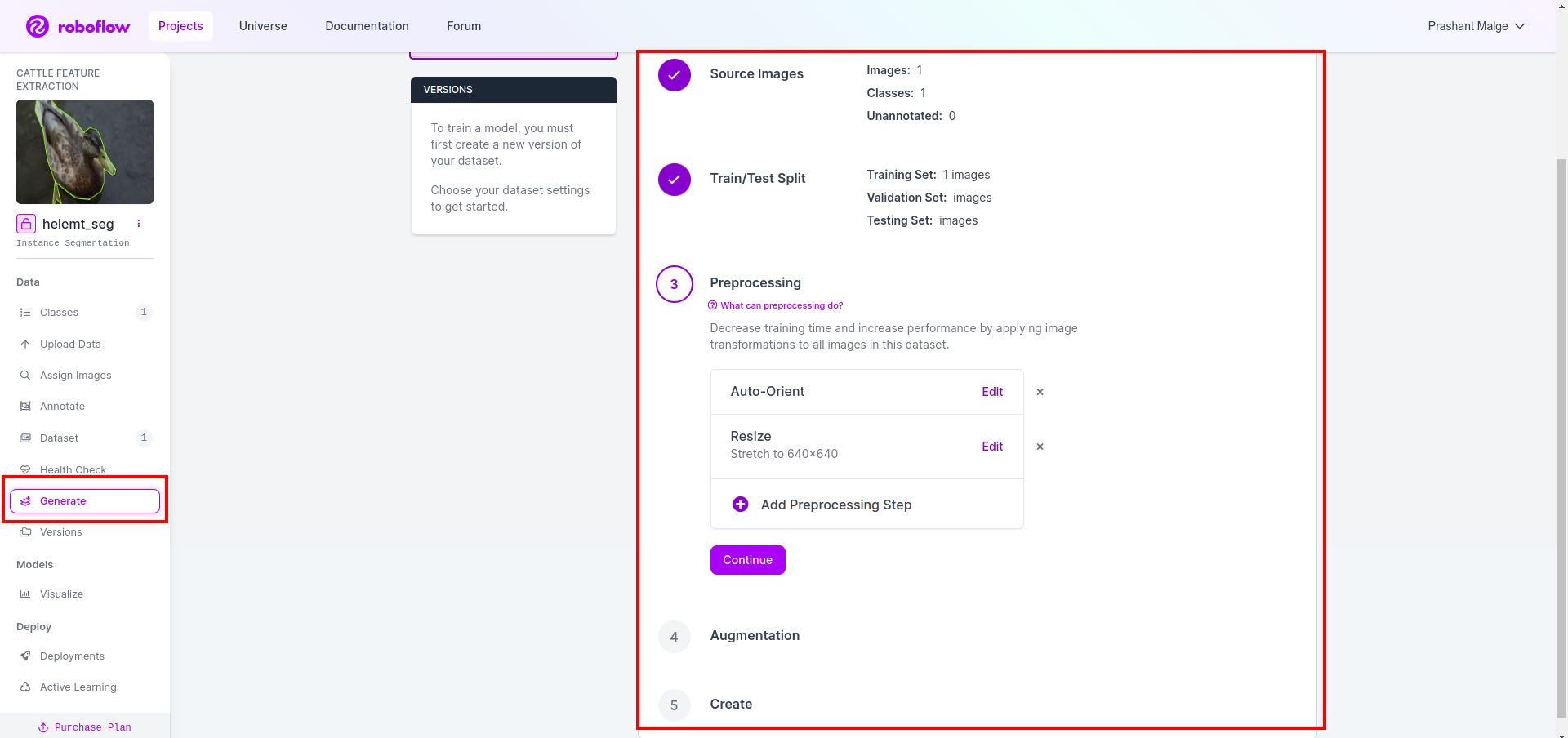
Anschließend erhalten Sie die Benutzeroberfläche der Datensatzaufteilungsoption. Hier können Sie überprüfen, ob die Bilder der Ordner „Train“, „Test“ und „Val“ automatisch aufgeteilt werden. und klicken Sie auf das rote Feld oben Option „Datensatz exportieren“. und laden Sie die ZIP-Datei herunter. Die Ordnerstruktur der ZIP-Datei ist wie folgt:
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Schritt 6: Schreiben Sie das Skript zum Trainieren des Bildsegmentierungsmodells
In diesem Teil erstellen Sie zunächst die Google Collab-Datei mit Drive und laden dann Ihren Datensatz hoch. und verbinden Sie Google Drive mit Google Collab.
1. Verwenden Sie diesen Befehl für Mounten Sie Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Datenverzeichnis definieren Verwenden Sie die Konstante-Variable.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Installieren des erforderlichen Pakets, Installieren Sie Ultralytics
!pip install ultralytics4. Importieren der Bibliotheken
import os
from ultralytics import YOLO5. Laden vorab trainiertes YOLOv8 Modell (hier haben wir ein anderes Modell, sehen Sie sich auch die offizielle Dokumentation an, dort können Sie das andere Modell sehen)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Trainiere das Modell
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Nein, überprüfen Sie Ihr Laufwerk. Der Modellnamensordner wird erstellt und das Modell wird für die Vorhersage gespeichert, die wir für dieses Modell benötigen.
7. Sagen Sie das Modell voraus
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Hier können Sie sehen, dass das Segmentierungsbild gespeichert wird.

Jetzt können wir endlich sowohl Live-Erkennungs- als auch Bildsegmentierungsmodelle erstellen.
Zusammenfassung
In diesem Blog untersuchen wir die Live-Objekterkennung und Bildsegmentierung mit YOLOv8. Für die Live-Erkennung importieren wir ein vorab trainiertes YOLOv8-Modell und nutzen die Computer-Vision-Bibliothek OpenCV, um die Kamera zu öffnen und Objekte zu erkennen. Zusätzlich erstellen wir eine Streamlit-Anwendung für eine attraktive Benutzeroberfläche.
Als nächstes beschäftigen wir uns mit der Bildsegmentierung mit YOLOv8. Wir importieren ein vorab trainiertes Modell und führen Transferlernen an einem benutzerdefinierten Datensatz durch. Zuvor haben wir Roboflow für die Annotation von Datensätzen untersucht und eine benutzerfreundliche Alternative zu Tools wie z. B. bereitgestellt LabelImg.
Schließlich sagen wir ein Bild voraus, das eine Ente enthält. Obwohl das Objekt im Bild wie ein Vogel aussieht, geben wir den Klassennamen als „Ente” zu Demonstrationszwecken.
Key Take Away
- Erfahren Sie mehr über Objekterkennungsmodelle wie Faster R-CNN, SSD und das neueste YOLOv8.
- Verständnis des Annotationstools Roboflow und seiner Rolle bei der Erstellung von Datensätzen für YOLOv8-Segmentierungsmodelle.
- Erkundung der Live-Objekterkennung mit OpenCV (cv2) und Supervision zur Verbesserung praktischer Fähigkeiten.
- Trainieren und Bereitstellen eines Segmentierungsmodells mit YOLOv8, Sammeln praktischer Erfahrungen.
Häufig gestellte Fragen
A. Bei der Objekterkennung werden mehrere Objekte in einem Bild identifiziert und lokalisiert, typischerweise durch das Zeichnen von Begrenzungsrahmen um sie herum. Bei der Bildsegmentierung hingegen wird ein Bild anhand der Pixelähnlichkeit in Segmente oder Regionen unterteilt, was ein detaillierteres Verständnis der Objektgrenzen ermöglicht.
A. YOLOv8 verbessert gegenüber früheren Versionen, indem es Fortschritte in der Netzwerkarchitektur, Trainingstechniken und Optimierung integriert. Im Vergleich zu YOLOv3 bietet es möglicherweise eine bessere Genauigkeit, Geschwindigkeit und Effizienz.
A. YOLOv8 kann abhängig von den Hardwarefunktionen und der Modelloptimierung für die Echtzeit-Objekterkennung auf eingebetteten Geräten verwendet werden. Möglicherweise sind jedoch Optimierungen wie Modellbereinigung oder Quantisierung erforderlich, um auf ressourcenbeschränkten Geräten Echtzeitleistung zu erzielen.
A. Roboflow bietet intuitive Anmerkungstools, Funktionen zur Datensatzverwaltung und Unterstützung für verschiedene Anmerkungsformate. Es rationalisiert den Annotationsprozess, ermöglicht die Zusammenarbeit und bietet Versionskontrolle, wodurch es einfacher wird, Datensätze für Computer-Vision-Projekte zu erstellen und zu verwalten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

