Beim Ausführen von Apache Flink-Anwendungen auf Amazon Managed Service für Apache Flinkhaben Sie den einzigartigen Vorteil, dass Sie die Serverlosigkeit nutzen können. Dies bedeutet, dass Kostenoptimierungsmaßnahmen jederzeit durchgeführt werden können und nicht mehr in der Planungsphase erfolgen müssen. Mit Managed Service für Apache Flink können Sie Rechenleistung per Knopfdruck hinzufügen und entfernen.
Apache Flink ist ein Open-Source-Stream-Verarbeitungsframework, das von Hunderten von Unternehmen in kritischen Geschäftsanwendungen und von Tausenden von Entwicklern verwendet wird, die Stream-Verarbeitungsanforderungen für ihre Arbeitslasten haben. Es ist hochverfügbar und skalierbar und bietet hohen Durchsatz und geringe Latenz für die anspruchsvollsten Stream-Verarbeitungsanwendungen. Diese skalierbaren Eigenschaften von Apache Flink können der Schlüssel zur Optimierung Ihrer Kosten in der Cloud sein.
Managed Service für Apache Flink ist ein vollständig verwalteter Service, der die Komplexität der Erstellung und Verwaltung von Apache Flink-Anwendungen reduziert. Managed Service für Apache Flink verwaltet die zugrunde liegende Infrastruktur und Apache Flink-Komponenten, die dauerhaften Anwendungsstatus, Metriken, Protokolle und mehr bereitstellen.
In diesem Beitrag erfahren Sie mehr über das Kostenmodell „Managed Service for Apache Flink“, Bereiche, in denen Sie bei Ihren Apache Flink-Anwendungen Kosten sparen können, und erhalten insgesamt ein besseres Verständnis Ihrer Datenverarbeitungspipelines. Wir beschäftigen uns eingehend mit dem Verständnis Ihrer Kosten, dem Verständnis, ob Ihre Anwendung überdimensioniert ist, wie Sie über die automatische Skalierung nachdenken und wie Sie Ihre Apache Flink-Anwendungen optimieren können, um Kosten zu sparen. Abschließend stellen wir wichtige Fragen zu Ihrer Arbeitslast, um festzustellen, ob Apache Flink die richtige Technologie für Ihren Anwendungsfall ist.
So werden die Kosten für Managed Service für Apache Flink berechnet
Um die Kosten für Ihre Managed Service for Apache Flink-Anwendung zu optimieren, kann es hilfreich sein, eine gute Vorstellung davon zu haben, was in die Preise für den Managed Service einfließt.
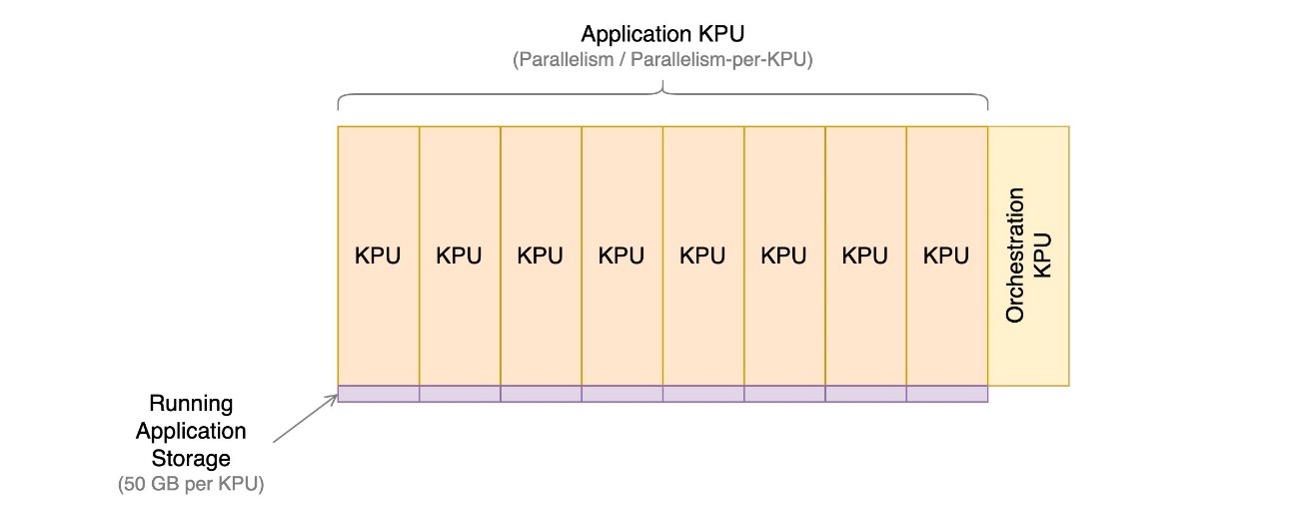
Managed Service für Apache Flink-Anwendungen bestehen aus Kinesis Processing Units (KPUs), bei denen es sich um Recheninstanzen handelt, die aus einer virtuellen CPU und 1 GB Arbeitsspeicher bestehen. Die Gesamtzahl der der Anwendung zugewiesenen KPUs wird durch Multiplikation zweier Parameter bestimmt, die Sie direkt steuern:
- Parallelität – Der Grad der Parallelverarbeitung in der Apache Flink-Anwendung
- Parallelität pro KPU – Die Anzahl der Ressourcen, die jeder Parallelität zugeordnet sind
Die Anzahl der KPUs wird durch die einfache Formel ermittelt: KPU = Parallelism / ParallelismPerKPU, aufgerundet auf die nächste ganze Zahl.
Eine zusätzliche KPU pro Anwendung wird ebenfalls für die Orchestrierung berechnet und nicht direkt für die Datenverarbeitung verwendet.
Die Gesamtzahl der KPUs bestimmt die Anzahl der der Anwendung zugewiesenen Ressourcen, CPU, Arbeitsspeicher und Anwendungsspeicher. Für jede KPU erhält die Anwendung 1 vCPU und 4 GB Arbeitsspeicher, von denen 3 GB standardmäßig der laufenden Anwendung zugewiesen werden und das verbleibende 1 GB für die Verwaltung des Anwendungsstatusspeichers verwendet wird. Jede KPU verfügt außerdem über 50 GB Speicher, der mit der Anwendung verbunden ist. Apache Flink behält den Anwendungsstatus im Arbeitsspeicher bis zu einem konfigurierbaren Grenzwert bei und überträgt ihn auf den angeschlossenen Speicher.
Die dritte Kostenkomponente sind dauerhafte Anwendungs-Backups bzw Schnappschüsse. Dies ist völlig optional und hat nur geringe Auswirkungen auf die Gesamtkosten, es sei denn, Sie behalten eine sehr große Anzahl von Snapshots.
Zum Zeitpunkt des Verfassens dieses Artikels kostet jede KPU in der AWS-Region USA Ost (Ohio) 0.11 US-Dollar pro Stunde und angeschlossener Anwendungsspeicher kostet 0.10 US-Dollar pro GB und Monat. Die Kosten für eine dauerhafte Anwendungssicherung (Snapshots) betragen 0.023 USD pro GB und Monat. Beziehen auf Preise für Amazon Managed Service für Apache Flink für aktuelle Preise und verschiedene Regionen.
Das folgende Diagramm veranschaulicht die relativen Anteile der Kostenkomponenten für eine laufende Anwendung im Managed Service für Apache Flink. Sie steuern die Anzahl der KPUs über die Parameter Parallelität und Parallelität pro KPU. Dauerhafter Anwendungssicherungsspeicher ist nicht vertreten.
In den folgenden Abschnitten untersuchen wir, wie Sie Ihre Kosten überwachen, die Nutzung von Anwendungsressourcen optimieren und die erforderliche Anzahl von KPUs für die Verarbeitung Ihres Durchsatzprofils ermitteln.
AWS Cost Explorer und Verständnis Ihrer Rechnung
Um zu sehen, wie hoch Ihre aktuellen Ausgaben für Managed Service für Apache Flink sind, können Sie Folgendes verwenden: AWS-Kosten-Explorer.
In der Cost Explorer-Konsole können Sie nach Datumsbereich, Nutzungstyp und Dienst filtern, um Ihre Ausgaben für Managed Service für Apache Flink-Anwendungen zu isolieren. Der folgende Screenshot zeigt die Kosten der letzten 12 Monate, aufgeschlüsselt nach den im vorherigen Abschnitt beschriebenen Preiskategorien. Der Großteil der Ausgaben stammte in vielen dieser Monate aus interaktiven KPUs Amazon Managed Service für Apache Flink Studio.
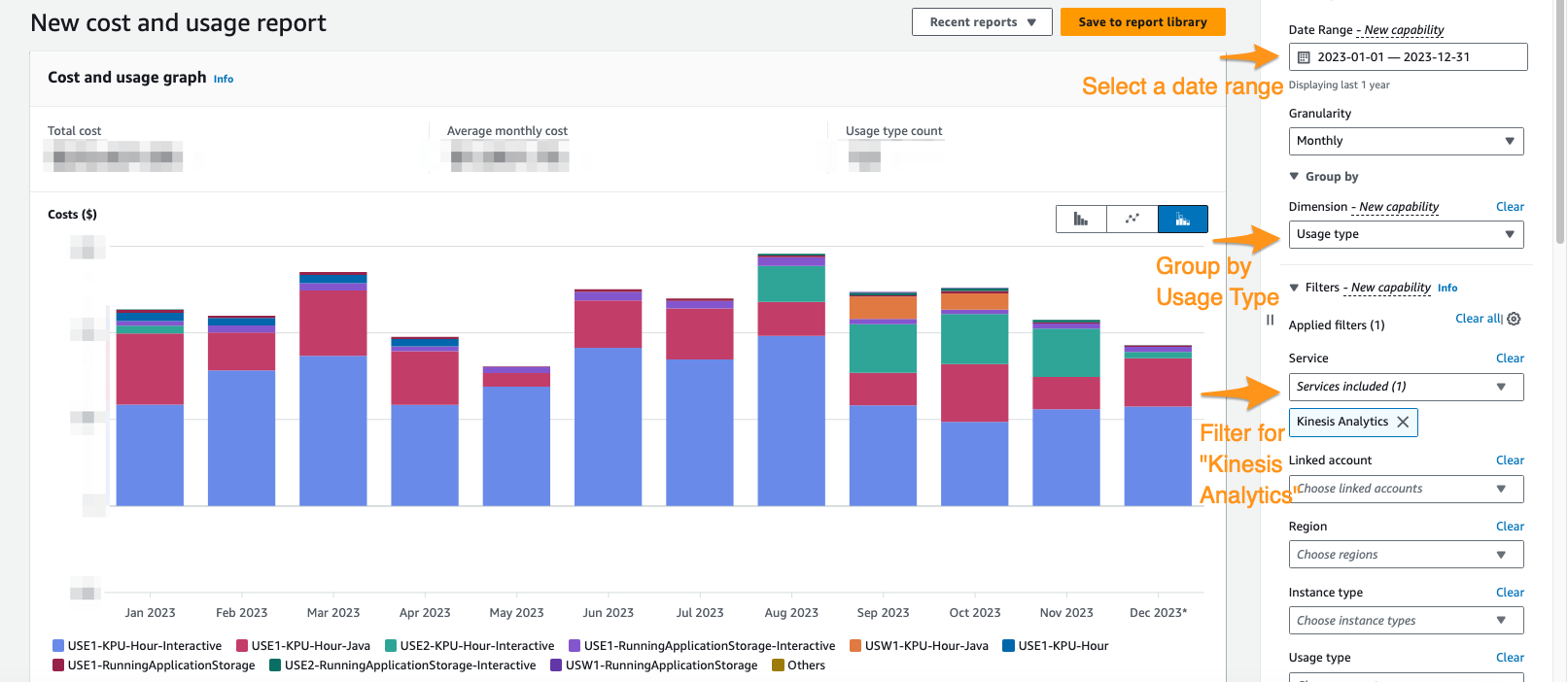
Die Verwendung von Cost Explorer kann Ihnen nicht nur helfen, Ihre Rechnung zu verstehen, sondern auch dabei helfen, bestimmte Anwendungen weiter zu optimieren, die möglicherweise automatisch oder aufgrund von Durchsatzanforderungen über den Erwartungen skaliert wurden. Mit der richtigen Anwendungskennzeichnung können Sie diese Ausgaben auch nach Anwendung aufschlüsseln, um zu sehen, welche Anwendungen die Kosten verursachen.
Anzeichen einer Überbereitstellung oder einer ineffizienten Nutzung von Ressourcen
Um die mit Managed Service für Apache Flink-Anwendungen verbundenen Kosten zu minimieren, besteht ein einfacher Ansatz darin, die Anzahl der von Ihren Anwendungen verwendeten KPUs zu reduzieren. Es ist jedoch wichtig zu erkennen, dass diese Reduzierung die Leistung beeinträchtigen könnte, wenn sie nicht gründlich bewertet und getestet wird. Um schnell zu beurteilen, ob Ihre Anwendungen möglicherweise überdimensioniert sind, untersuchen Sie Schlüsselindikatoren wie CPU- und Speicherauslastung, Anwendungsfunktionalität und Datenverteilung. Obwohl diese Indikatoren auf eine mögliche Überbereitstellung hinweisen können, ist es jedoch wichtig, Leistungstests durchzuführen und Ihre Skalierungsmuster zu validieren, bevor Sie Anpassungen an der Anzahl der KPUs vornehmen.
Metrik
Analyse Metriken für Ihre Anwendung on Amazon CloudWatch kann deutliche Anzeichen einer Überversorgung erkennen lassen. Wenn die containerCPUUtilization und containerMemoryUtilization Wenn die Metriken für die Datenverkehrsmuster Ihrer Anwendung über einen statistisch signifikanten Zeitraum hinweg konstant unter 20 % bleiben, ist es möglicherweise sinnvoll, die Skalierung zu verkleinern und mehr Daten weniger Maschinen zuzuweisen. Im Allgemeinen gehen wir davon aus, dass Anwendungen angemessen dimensioniert sind containerCPUUtilization schwankt zwischen 50 und 75 %. Obwohl containerMemoryUtilization kann im Laufe des Tages schwanken und durch Codeoptimierung beeinflusst werden; ein konstant niedriger Wert über einen längeren Zeitraum könnte auf eine mögliche Überbereitstellung hinweisen.
Parallelität pro KPU nicht ausreichend ausgelastet
Ein weiteres subtiles Zeichen dafür, dass Ihre Anwendung überdimensioniert ist, ist, wenn Ihre Anwendung ausschließlich E/A-gebunden ist oder nur einfache Aufrufe an Datenbanken und nicht CPU-intensive Vorgänge ausführt. Wenn dies der Fall ist, können Sie den Parameter „Parallelität pro KPU“ im Managed Service für Apache Flink verwenden, um mehr Aufgaben auf eine einzelne Verarbeitungseinheit zu laden.
Sie können den Parameter Parallelität pro KPU als Maß für die Arbeitslastdichte pro Rechen- und Speicherressourceneinheit (KPU) anzeigen. Durch Erhöhen der Parallelität pro KPU über den Standardwert von 1 hinaus wird die Verarbeitung dichter, wodurch einer einzelnen KPU mehr parallele Prozesse zugewiesen werden.
Das folgende Diagramm zeigt, wie Ihre Anwendung bei gleichbleibender Parallelität weniger Ressourcen verbraucht (z. B. 4) und die Parallelität pro KPU erhöht (z. B. von 1 auf 2).
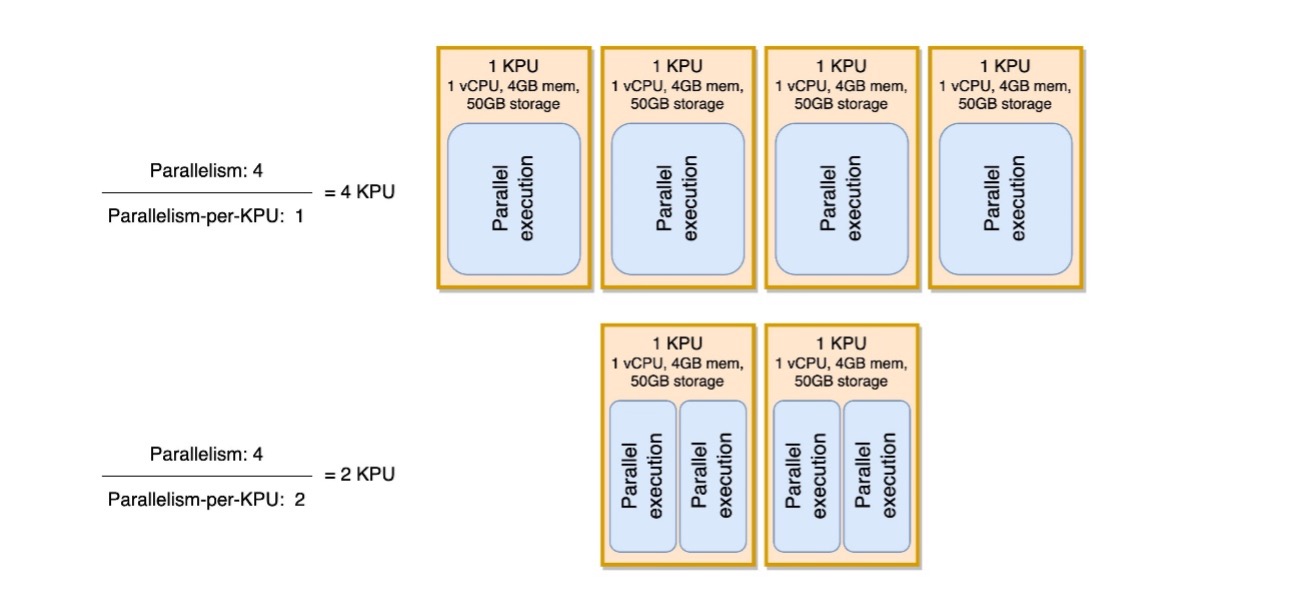
Die Entscheidung, die Parallelität pro KPU zu erhöhen, sollte, wie alle Empfehlungen in diesem Beitrag, mit großer Sorgfalt getroffen werden. Durch Erhöhen des Parallelitätswerts pro KPU kann eine einzelne KPU stärker belastet werden, und sie muss bereit sein, diese Belastung zu tolerieren. E/A-gebundene Vorgänge erhöhen die CPU- oder Speicherauslastung nicht in nennenswerter Weise, aber eine Prozessfunktion, die viele komplexe Vorgänge anhand der Daten berechnet, wäre kein idealer Vorgang für die Zusammenfassung auf einer einzelnen KPU, da sie die Ressourcen überfordern könnte. Testen Sie die Leistung und bewerten Sie, ob dies eine gute Option für Ihre Anwendungen ist.
So gehen Sie bei der Größenbestimmung vor
Bevor Sie eine Managed Service for Apache Flink-Anwendung einrichten, kann es schwierig sein, die Anzahl der KPUs abzuschätzen, die Sie Ihrer Anwendung zuweisen sollten. Im Allgemeinen sollten Sie ein gutes Gespür für Ihre Verkehrsmuster haben, bevor Sie eine Schätzung vornehmen. Das Verständnis Ihrer Verkehrsmuster auf Basis der Aufnahmerate in Megabyte pro Sekunde kann Ihnen dabei helfen, einen ungefähren Ausgangspunkt zu ermitteln.
Als allgemeine Regel können Sie mit einer KPU pro 1 MB/s beginnen, die Ihre Anwendung verarbeiten wird. Wenn Ihre Anwendung beispielsweise durchschnittlich 10 MB/s verarbeitet, würden Sie 10 KPUs als Ausgangspunkt für Ihre Anwendung zuweisen. Bedenken Sie, dass es sich hierbei um eine Näherung auf sehr hohem Niveau handelt, die unserer Meinung nach für eine allgemeine Schätzung wirksam ist. Sie müssen jedoch auch Leistungstests durchführen und bewerten, ob dies auf lange Sicht eine angemessene Dimensionierung ist, basierend auf Metriken (CPU, Arbeitsspeicher, Latenz, allgemeine Jobleistung) über einen langen Zeitraum.
Um die passende Größe für Ihre Anwendung zu finden, müssen Sie die Apache Flink-Anwendung vergrößern und verkleinern. Wie bereits erwähnt, verfügen Sie im Managed Service für Apache Flink über zwei separate Steuerelemente: Parallelität und Parallelität pro KPU. Zusammen bestimmen diese Parameter den Grad der Parallelverarbeitung innerhalb der Anwendung und die insgesamt verfügbaren Rechen-, Arbeitsspeicher- und Speicherressourcen.
Die empfohlene Testmethode besteht darin, die Parallelität oder die Parallelität pro KPU separat zu ändern und gleichzeitig zu experimentieren, um die richtige Größe zu finden. Ändern Sie im Allgemeinen nur die Parallelität pro KPU, um die Anzahl paralleler E/A-gebundener Vorgänge zu erhöhen, ohne die Gesamtressourcen zu erhöhen. In allen anderen Fällen ändern Sie lediglich die Parallelität – KPU ändert sich entsprechend –, um die richtige Größe für Ihre Arbeitslast zu finden.
Sie können uns auch Stellen Sie die Parallelität auf Bedienerebene ein um Quellen, Senken oder andere Operatoren einzuschränken, die möglicherweise eingeschränkt werden müssen und unabhängig von Skalierungsmechanismen sind. Sie können dies für eine Apache Flink-Anwendung verwenden, die aus einem Apache Kafka-Thema mit 10 Partitionen liest. Mit dem setParallelism() Mit dieser Methode könnten Sie die KafkaSource auf 10 beschränken, aber die Managed Service for Apache Flink-Anwendung auf eine Parallelität von mehr als 10 skalieren, ohne Leerlaufaufgaben für die Kafka-Quelle zu erstellen. Für andere Datenverarbeitungsfälle wird empfohlen, die Operatorparallelität nicht statisch auf einen statischen Wert festzulegen, sondern eine Funktion der Anwendungsparallelität, damit sie sich mit der Skalierung der gesamten Anwendung skaliert.
Skalierung und automatische Skalierung
In Managed Service für Apache Flink ist das Ändern der Parallelität oder Parallelität pro KPU eine Aktualisierung der Anwendungskonfiguration. Dadurch wird die Anwendung automatisch ausgeführt Schnappschuss (sofern nicht deaktiviert), stoppen Sie die Anwendung und starten Sie sie mit der neuen Größe neu, um den Status aus dem Snapshot wiederherzustellen. Skalierungsvorgänge verursachen keinen Datenverlust oder Inkonsistenzen, unterbrechen jedoch die Datenverarbeitung für einen kurzen Zeitraum, während Infrastruktur hinzugefügt oder entfernt wird. Dies müssen Sie bei der Neuskalierung in einer Produktionsumgebung berücksichtigen.
Während des Test- und Optimierungsprozesses empfehlen wir die Deaktivierung automatische Skalierung und Modifizieren von Parallelität und Parallelität pro KPU, um die optimalen Werte zu finden. Wie bereits erwähnt, handelt es sich bei der manuellen Skalierung lediglich um eine Aktualisierung der Anwendungskonfiguration und kann über ausgeführt werden AWS-Managementkonsole oder API mit dem UpdateApplication-Aktion.
Wenn Sie die optimale Größe gefunden haben und erwarten, dass Ihr aufgenommener Durchsatz erheblich schwankt, können Sie sich für die Aktivierung der automatischen Skalierung entscheiden.
Im Managed Service für Apache Flink können Sie mehrere Arten der automatischen Skalierung verwenden:
- Sofort einsatzbereite automatische Skalierung – Sie können dies aktivieren, um die Anwendungsparallelität basierend auf dem automatisch anzupassen
containerCPUUtilizationmetrisch. Bei neuen Anwendungen ist die automatische Skalierung standardmäßig aktiviert. Einzelheiten zum automatischen Skalierungsalgorithmus finden Sie unter Automatische Skalierung. - Feinkörnige, metrische automatische Skalierung – Dies ist einfach umzusetzen. Die Automatisierung kann auf praktisch beliebigen Metriken basieren, einschließlich benutzerdefinierte Metriken Ihre Anwendung stellt bereit.
- Geplante Skalierung – Dies kann nützlich sein, wenn Sie zu bestimmten Tageszeiten oder Wochentagen mit Arbeitsspitzen rechnen.
Standardmäßige automatische Skalierung und feinkörnige, auf Metriken basierende Skalierung schließen sich gegenseitig aus. Weitere Einzelheiten zur feinkörnigen metrikbasierten automatischen Skalierung und geplanten Skalierung sowie ein voll funktionsfähiges Codebeispiel finden Sie unter Aktivieren Sie die metrikbasierte und geplante Skalierung für Amazon Managed Service für Apache Flink.
Codeoptimierungen
Eine weitere Möglichkeit, Kosteneinsparungen für Ihren Managed Service für Apache Flink-Anwendungen zu erzielen, ist die Codeoptimierung. Für nicht optimierten Code sind mehr Maschinen erforderlich, um die gleichen Berechnungen durchzuführen. Die Optimierung des Codes könnte eine geringere Gesamtressourcenauslastung ermöglichen, was wiederum eine Skalierung und entsprechende Kosteneinsparungen ermöglichen könnte.
Der erste Schritt zum Verständnis der Leistung Ihres Codes ist das in Apache Flink integrierte Dienstprogramm namens Flammendiagramme.
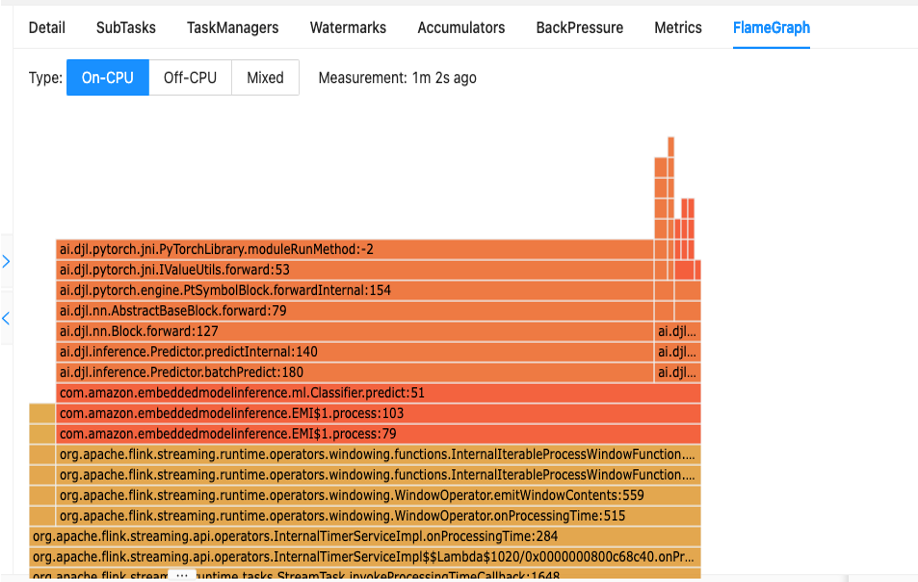
Flame Graphs, auf die Sie über das Apache Flink-Dashboard zugreifen können, bieten Ihnen eine visuelle Darstellung Ihres Stack-Trace. Jedes Mal, wenn eine Methode aufgerufen wird, wird der Balken, der diesen Methodenaufruf im Stack-Trace darstellt, proportional zur Gesamtzahl der Stichproben größer. Das heißt, wenn Sie einen ineffizienten Codeabschnitt mit einem sehr langen Balken im Flammendiagramm haben, könnte dies Anlass für eine Untersuchung sein, wie dieser Code effizienter gemacht werden kann. Darüber hinaus können Sie verwenden Amazon CodeGuru-Profiler zu Überwachen und optimieren Sie Ihre Apache Flink-Anwendungen, die auf Managed Service für Apache Flink ausgeführt werden.
Beim Entwerfen Ihrer Anwendungen wird empfohlen, die API der höchsten Ebene zu verwenden, die für einen bestimmten Vorgang zu einem bestimmten Zeitpunkt erforderlich ist. Apache Flink bietet vier Ebenen der API-Unterstützung: Flink SQL, Table API, Datastream API und ProcessFunction APIs mit zunehmender Komplexität und Verantwortung. Wenn Ihre Anwendung vollständig in der Flink SQL- oder Table-API geschrieben werden kann, kann die Verwendung dieser Funktion dazu beitragen, die Vorteile des Apache Flink-Frameworks zu nutzen, anstatt Status und Berechnungen manuell zu verwalten.
Datenverzerrung
Im Apache Flink-Dashboard können Sie weitere nützliche Informationen zu Ihren Managed Service for Apache Flink-Jobs sammeln.
Auf dem Dashboard können Sie einzelne Aufgaben innerhalb Ihres Bewerbungsdiagramms einsehen. Jedes blaue Kästchen stellt eine Aufgabe dar und jede Aufgabe besteht aus Unteraufgaben oder verteilten Arbeitseinheiten für diese Aufgabe. Auf diese Weise können Sie Datenverzerrungen zwischen Teilaufgaben erkennen.
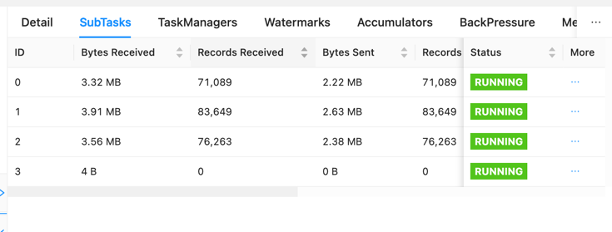
Der Datenversatz ist ein Indikator dafür, dass mehr Daten an eine Unteraufgabe gesendet werden als an eine andere und dass eine Unteraufgabe, die mehr Daten empfängt, mehr Arbeit leistet als die andere. Wenn bei Ihnen solche Symptome einer Datenverzerrung auftreten, können Sie daran arbeiten, diese zu beseitigen, indem Sie die Quelle identifizieren. Zum Beispiel ein GroupBy or KeyedStream Könnte eine Schiefe im Schlüssel haben. Dies würde bedeuten, dass die Daten nicht gleichmäßig auf die Schlüssel verteilt sind, was zu einer ungleichmäßigen Verteilung der Arbeit auf die Apache Flink-Recheninstanzen führen würde. Stellen Sie sich ein Szenario vor, in dem Sie nach gruppieren userId, aber Ihre Anwendung empfängt deutlich mehr Daten von einem Benutzer als von den anderen. Dies kann zu Datenverzerrungen führen. Um dies zu vermeiden, können Sie einen anderen Gruppierungsschlüssel wählen, um die Daten gleichmäßig auf die Teilaufgaben zu verteilen. Beachten Sie, dass hierfür eine Codeänderung erforderlich ist, um einen anderen Schlüssel auszuwählen.
Wenn der Datenversatz beseitigt ist, können Sie zum zurückkehren containerCPUUtilization und containerMemoryUtilization Metriken, um die Anzahl der KPUs zu reduzieren.
Zu den weiteren Bereichen der Codeoptimierung gehört die Sicherstellung, dass Sie über das auf externe Systeme zugreifen Asynchrone E/A-API oder über einen Datenstrom-Join, da eine synchrone Abfrage an einen Datenspeicher zu Verlangsamungen und Problemen beim Checkpointing führen kann. Weitere Informationen finden Sie unter Fehlerbehebung bei der Leistung für Probleme, die bei langsamen Prüfpunkten oder bei der Protokollierung auftreten können, was zu einem Anwendungsstau führen kann.
So ermitteln Sie, ob Apache Flink die richtige Technologie ist
Wenn Ihre Anwendung keine der leistungsstarken Funktionen des Apache Flink-Frameworks und des Managed Service für Apache Flink nutzt, können Sie möglicherweise Kosten sparen, indem Sie etwas Einfacheres verwenden.
Der Slogan von Apache Flink lautet „Stateful Computations over Data Streams“. Stateful bedeutet in diesem Zusammenhang, dass Sie das Apache Flink-Statuskonstrukt verwenden. State ermöglicht es Ihnen in Apache Flink, sich Nachrichten, die Sie in der Vergangenheit gesehen haben, über längere Zeiträume zu merken, wodurch Dinge wie Streaming-Joins, Deduplizierung, genau einmalige Verarbeitung, Fensterung und die Verarbeitung verspäteter Daten möglich werden. Dies geschieht durch die Verwendung eines In-Memory-Statusspeichers. Auf Managed Service für Apache Flink wird es verwendet RocksDB seinen Zustand aufrechtzuerhalten.
Wenn Ihre Anwendung keine zustandsbehafteten Vorgänge umfasst, können Sie Alternativen in Betracht ziehen, z AWS Lambda, Containeranwendungen oder eine Amazon Elastic Compute-Cloud (Amazon EC2) Instanz, auf der Ihre Anwendung ausgeführt wird. In solchen Fällen ist die Komplexität von Apache Flink möglicherweise nicht erforderlich. Zustandsbehaftete Berechnungen, einschließlich zwischengespeicherter Daten oder Anreicherungsverfahren, die einen unabhängigen Stream-Positionsspeicher erfordern, können die zustandsbehafteten Fähigkeiten von Apache Flink rechtfertigen. Wenn die Möglichkeit besteht, dass Ihre Anwendung in Zukunft zustandsbehaftet wird, sei es durch längere Datenaufbewahrung oder andere zustandsbehaftete Anforderungen, könnte die weitere Verwendung von Apache Flink einfacher sein. Organisationen, die Apache Flink für Stream-Verarbeitungsfunktionen bevorzugen, ziehen es möglicherweise vor, bei zustandsbehafteten und zustandslosen Anwendungen bei Apache Flink zu bleiben, damit alle ihre Anwendungen Daten auf die gleiche Weise verarbeiten. Sie sollten auch die Orchestrierungsfunktionen wie Exact-Once-Processing, Fan-Out-Fähigkeiten und verteilte Berechnungen berücksichtigen, bevor Sie von Apache Flink auf Alternativen umsteigen.
Eine weitere Überlegung sind Ihre Latenzanforderungen. Da Apache Flink sich durch die Datenverarbeitung in Echtzeit auszeichnet, macht es keinen Sinn, es für eine Anwendung mit einer Latenzanforderung von 6 Stunden oder 1 Tag zu verwenden. Die Kosteneinsparungen ergeben sich durch die Umstellung auf einen zeitlichen Batch-Prozess Amazon Simple Storage-Service (Amazon S3) wäre beispielsweise von Bedeutung.
Zusammenfassung
In diesem Beitrag haben wir einige Aspekte behandelt, die bei Kosteneinsparungsmaßnahmen für Managed Service für Apache Flink zu berücksichtigen sind. Wir haben besprochen, wie Sie Ihre Gesamtausgaben für den verwalteten Dienst ermitteln, einige nützliche Metriken zur Überwachung beim Herunterskalieren Ihrer KPUs, wie Sie Ihren Code für die Verkleinerung optimieren und wie Sie feststellen, ob Apache Flink für Ihren Anwendungsfall geeignet ist.
Die Implementierung dieser kostensparenden Strategien steigert nicht nur Ihre Kosteneffizienz, sondern sorgt auch für eine optimierte und gut optimierte Apache Flink-Bereitstellung. Indem Sie Ihre Gesamtausgaben im Auge behalten, wichtige Kennzahlen verwenden und fundierte Entscheidungen über die Reduzierung von Ressourcen treffen, können Sie einen kosteneffizienten Betrieb ohne Leistungseinbußen erzielen. Wenn Sie sich in der Landschaft von Apache Flink zurechtfinden, ist es von entscheidender Bedeutung, ständig zu bewerten, ob es zu Ihrem spezifischen Anwendungsfall passt, damit Sie eine maßgeschneiderte und effiziente Lösung für Ihre Datenverarbeitungsanforderungen finden können.
Wenn eine der in diesem Beitrag besprochenen Empfehlungen auf Ihre Arbeitsbelastung zutrifft, empfehlen wir Ihnen, sie auszuprobieren. Mit den angegebenen Metriken und den Tipps, wie Sie Ihre Arbeitslasten besser verstehen, sollten Sie nun über alles verfügen, was Sie brauchen, um Ihre Apache Flink-Arbeitslasten auf Managed Service für Apache Flink effizient zu optimieren. Im Folgenden finden Sie einige hilfreiche Ressourcen, die Sie als Ergänzung zu diesem Beitrag verwenden können:
Über die Autoren
 Jeremy Ber arbeitet seit 10 Jahren im Bereich Telemetriedaten als Software-Ingenieur, Machine-Learning-Ingenieur und zuletzt als Dateningenieur. Bei AWS ist er als Streaming Specialist Solutions Architect tätig und unterstützt sowohl Amazon Managed Streaming für Apache Kafka (Amazon MSK) als auch Amazon Managed Service für Apache Flink.
Jeremy Ber arbeitet seit 10 Jahren im Bereich Telemetriedaten als Software-Ingenieur, Machine-Learning-Ingenieur und zuletzt als Dateningenieur. Bei AWS ist er als Streaming Specialist Solutions Architect tätig und unterstützt sowohl Amazon Managed Streaming für Apache Kafka (Amazon MSK) als auch Amazon Managed Service für Apache Flink.
 Lorenzo Nicora arbeitet als Senior Streaming Solution Architect bei AWS und unterstützt Kunden in der gesamten EMEA-Region. Er entwickelt seit über 25 Jahren cloudnative, datenintensive Systeme und ist in der Finanzbranche sowohl für Beratungsunternehmen als auch für FinTech-Produktunternehmen tätig. Er hat Open-Source-Technologien umfassend genutzt und zu mehreren Projekten beigetragen, darunter Apache Flink.
Lorenzo Nicora arbeitet als Senior Streaming Solution Architect bei AWS und unterstützt Kunden in der gesamten EMEA-Region. Er entwickelt seit über 25 Jahren cloudnative, datenintensive Systeme und ist in der Finanzbranche sowohl für Beratungsunternehmen als auch für FinTech-Produktunternehmen tätig. Er hat Open-Source-Technologien umfassend genutzt und zu mehreren Projekten beigetragen, darunter Apache Flink.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

